
以 25% 的内存成本快速进行十次 malloc() 和 free()
4.89/5 (24投票s)
深入了解堆“C”内存系统。
介绍
C 程序(许多其他编程语言的基础)中的主要操作之一是内存管理。当此资源的范围是全局的(在函数退出后仍然存在)但在编译时未知时,我们使用 malloc()、calloc()、realloc() 资源集,或它们的 new() dispose() C++ 化身。如果我们正在编写 Java 代码,一个隐藏的小精灵会为我们完成这项工作。
为了充分理解这个主题的重要性,让我们思考“垃圾回收”、“智能指针”或“Java”本身等术语。这些非常高效,但耗时且容易出错的技术,除了其他原因外,就是为了解决这个问题而构建的。
背景
“C”语言从何而来?“C”语言比汇编语言略高,最初运行在低资源计算机上,内存非常宝贵。即使在今天,您仍然可以在微小的微控制器(如您的汽车钥匙扣、洗衣机或剃须刀)中找到“C”或“C++”代码的子集。对我来说,编程微控制器是极大的乐趣,但我们必须明白,当您只有 2,000 字节内存时节省 32 字节与您拥有 4,000,000,000 字节时是不同的。嗯,编译器似乎不介意这个问题,两种情况下的算法几乎相同。优化很少。实际上,malloc() 以不小于 2 的幂(16、32、64...字节)的块获取内存,主要是为了对齐目的,这使得处理器效率更高。您必须将内部控制数据的大小包含在块中。这是您的程序在您请求的内存比您需要的少一点时(例如,忘记字符串末尾的空字符大小)不会挂起的原因之一,也是像 valgrind 这样的软件包检测到您的代码中存在这种情况的原因。
新内存分配不是问题。libc 只需要在堆顶部分取一块内存并缩短剩余的块。问题在于当您释放一个已使用的内存块,但该块不在顶部时。这会创建一个必须重新使用的“洞”。堆通过维护一个已删除块的链表来解决这个问题。当您需要一个新的块时,malloc() 必须遍历这个列表,寻找您的块。此外,相邻的块会合并在一起,以尽可能地保持堆不碎片化。
基准测试
为了防止您停止阅读,并确保您完成作业,这里是我的测试程序的快照(包含在文章中)。请看**改进**列。它显示了与标准内存函数相比的速度提升,而**使用**是我们版本中程序使用的内存量。
一个有趣的事实是,VC6 比标准 malloc() 快 120 倍,而 MinGW “只”快 21 倍,但在 realloc() 中,比例是 45 到 300 倍。原因将在下面探讨,但 realloc() 不像 malloc()、free() 那样重要,因为在实际程序中(尤其是在 C++ 中 new() 和 delete() 的底层)几乎不使用。
在 Visual Studio 下编译

在 MinGW 下编译
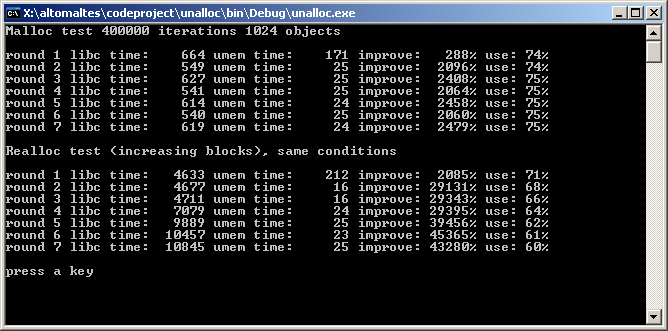
如您所见,Visual Studio 也进行了快速的 realloc,这让我怀疑它们也没有进行“真实”的 realloc,而总是进行增长的 realloc。
建议的改进。
让我们对这个问题采取一种推测性的方法。malloc()-free() 通常以一种特定的方式使用,而不是所有可能的情况。这两个函数都是 new() 和 delete() 运算符的基础,并且我们在实际程序中拥有的对象类型是有限的。对 C++ 程序“预热”时堆的检查将表明,块的大小被组织成固定大小的集合,对应于对象。这些大小的空闲内存块交替出现,形成已删除的对象。当您请求一个块时,malloc() 会遍历已删除的链表以寻找足够大的块。free() 关注保持内存不碎片化,合并相邻的空闲块很多时候变得无用,因为请求的块具有固定的性质。
我建议只使用固定大小(2 的幂)的块,并将释放的块以 LIFO 方式保存在单链表中。这使得块的插入(free)和移除(alloc)都可以在一个步骤中完成,极大地提高了操作速度。当所需内存块不存在时,将向标准 malloc() 请求,一旦进入列表就永不退出(直到程序结束)。
这种方式的代价是,每个块中未使用的内存或多或少占总块大小的 25%。作为附带影响,realloc() 在基准测试中快了一百倍。

这是一种基于 2 的幂次分块大小的内存布局。还有其他可能的布局,具有更大的分块表,从而减少未使用的填充内存。这张表显示了几种组合的可能性,允许分配从 32 字节到 8 MB 的内存块大小。
| 块表大小 | 平均已用内存 |
| 10 个指针 | 75%(本例) |
| 20 个指针 | 88% |
| 40 个指针 | 93% |
| 80 个指针 | 97% |
上述表格的可能性需要更多的编码(本文未涵盖),这会稍微降低 unalloc() 的速度。realloc() 函数在增长块时也会受到影响,因为在更精确的块上移动的需求增加了。free() 几乎不受影响。理论很简单。更多的块大小选择意味着对请求大小的调整更精确,从而减少未使用的填充大小。
使用代码
这真的很简单。您必须使用 unalloc()、unfree() 和 unrealloc() 来代替 malloc()、free() 和 realloc()。这是我用于测试的代码,它可能是一个很好的工作示例。Win32 缺少 times() 函数,因此您在演示代码中有一个模拟它的变通方法。
#define POOL_SIZE 1024
#define ITERATIONS 1000000
#define ROUNDS 7
unsigned randSize( ) { unsigned rnd= rand(); return(( rnd & 0x7FFF ) << 1 ); }
unsigned randIdx( ) { unsigned rnd= rand(); return( rnd & (POOL_SIZE-1) ); }
void mallocTest( int round )
{ static void * buffer[ POOL_SIZE ]; // Zero init
static void * unbuffer[ POOL_SIZE ];
int loop;
unsigned tm1,tm2;
for( loop= 0, tm1= times( NULL )
; loop < ITERATIONS
; loop++ )
{ int idx= randIdx();
if ( buffer[ idx ] )
{ free( buffer[ idx ] );
}
buffer[ idx ]= malloc( randSize() );
}
tm1= times( NULL ) - tm1;
for( loop= 0, tm2= times( NULL )
; loop < ITERATIONS
; loop++ )
{ int idx= randIdx();
if ( unbuffer[ idx ] )
{ unfree( unbuffer[ idx ] );
}
unbuffer[ idx ]= unalloc( randSize() );
}
tm2= times( NULL ) - tm2;
printf("round %d libc ticks: %6u umem ticks: %6u ", round, tm1, tm2 );
tm1 *= 100; tm1 /= tm2; tm1-=100;
printf("improving: %5u%%\n", tm1 );
}您可以尝试 POOL_SIZE 1024 和 ITERATIONS 以及 randSize() 的几个值来测试改进效果。
我认为 realloc() 在 VC6 中如此之快的原因是这个编译器仍然使用“非收缩大小”优化,因此无需移动内存块,这很耗时。这只是一个理论。
您可以运行 MinGW 和 VC6 可执行文件,并因此指责微软。
文件列表
包含在 ualloc_source.zip 中的文件:
- main.c:测试程序
- memory.c:源代码
- memory.h:上述文件的头文件
- windows.c:用于 UNIX
times()函数的 Windows 仿真 - unalloc.cbp:code:::blocks 的项目文件
- build.bat:Windows 的构建文件。
- build:UNIX 的构建文件。
- bin/debug/unalloc.exe:MinGW 32 位可执行文件
- vc6:Visual Studio 项目
- vc6/debug/unalloc.exe:Visual Studio 32 位可执行文件
包含在 ualloc_demo.zip 中的文件:
- mingw.exe:MinGW 32 位可执行文件
- vc6.exe:MinGW 32 位可执行文件
兴趣点
这是一个更大项目的子集。完整代码的主要目标是向“C”代码提供“C++”的 delete() 概念(在释放内存资源之前执行关闭代码),还通过在对象之间建立父子关系来实现“级联销毁”树,当您销毁其中一个项目时,其所有子项也将被销毁,以及一个用于回收不再需要的全局分配对象的内存的系统,但这又是另一个故事了。
历史
在这个程序员论坛上撰写文章的原因之一是加强我的沟通能力。这是一项我在母语中成功完成的工作,但使用另一种语言而不失细微差别和精髓是具有挑战性的。我希望能在国外拥有几年的技术工作经验,并展示一些我的隐藏技能可能会有所帮助。