
查询 SQL Server 2012:第二部分
4.91/5 (49投票s)
两部分中的第二部分;创建最精彩查询所需的一切!
1. 目录
第一部分
- 目录
- 引言
- 安装示例数据库
- 定义查询
- 我们的第一个查询;SELECT 语句
- 5.1. 别名
- 消除重复项;DISTINCT
- 过滤数据;WHERE 子句
- 7.1. NOT 关键字
- 7.2. 组合谓词
- 7.3. 过滤字符串
- 7.4. 过滤日期
- 7.5. IN 和 BETWEEN 关键字
- 排序数据;ORDER BY
- 进一步限制结果;TOP 和 OFFSET-FETCH
- 9.1. TOP
- 9.2. OFFSET-FETCH
- 聚合数据;GROUP BY 和 HAVING
- 从多个表中选择;使用 JOIN
- 11.1. CROSS JOIN
- 11.2. INNER JOIN
- 11.3. OUTER JOIN
- 11.4. 自连接 (Self JOIN)
- 11.5. 多个 JOIN
- 多个分组;GROUPING SETS
- 12.1. GROUPING SETS
- 12.2. CUBE
- 12.3. ROLLUP
- 12.4. GROUPING
- 12.5. GROUPING_ID
- 窗口函数;OVER 子句
- 13.1. 聚合函数
- 13.2. 框架
- 13.3. 排名函数
- 13.4. 偏移函数
- 还没完...
第二部分
- 目录
- 欢迎回来!
-
查询中的查询;子查询
- 3.1. 用不同的方式编写相同的查询
- 3.2. 更多过滤选项;IN, ANY, SOME, ALL 和 EXISTS
- 3.2.1. IN
- 3.2.2. ANY 和 SOME
- 3.2.3. ALL
- 3.2.4. EXISTS
- 从子查询中查询;派生表
- 通用表表达式,也称为 CTE
-
集合运算符;UNION, INTERSECT 和 EXCEPT
- 6.1. 组合集合;UNION 和 UNION ALL
- 6.2. 使用 CTE 和 UNION ALL 进行递归
- 6.3. INTERSECT
- 6.4. EXCEPT
- 推送到表;PIVOT 和 UNPIVOT
-
表表达式的更多用法;APPLY
- 8.1. CROSS APPLY
- 8.2. OUTER APPLY
-
查询的其他方面
- 9.1. 类型转换;CAST 和 CONVERT, PARSE 和 FORMAT
- 9.1.1 CAST 和 CONVERT
- 9.1.2 PARSE
- 9.1.3 FORMAT
- 9.2. VARCHAR 函数
- 9.3. DATETIME 函数
- 9.4. CASE 和 IIF
- 9.5. COALESCE, ISNULL 和 NULLIF
- 结论
2. 欢迎回来!
正如您在本文标题中读到的,这实际上是关于查询 Microsoft SQL Server 数据库的文章的第二部分,也是最后一部分。如果您还没有阅读过,我强烈建议您阅读第一篇文章,查询 SQL Server 2012 第一部分。
第一篇文章侧重于构建您的查询。它从简单的 SELECT 语句开始,通过添加过滤、分组和窗口函数来逐步增加查询的难度。
本文的第二部分侧重于组合多个 SELECT 语句并仍然返回单个结果集。此外,我们将了解如何使用函数和操作数据,以便我们可以组合数据库中的值并对值应用函数。
3. 查询中的查询;子查询
所以正如我所说,本文将重点介绍在查询中使用多个 SELECT 语句。最简单也是最常见的方法是使用子查询。子查询是查询中的查询,它返回在放置子查询的位置所期望的结果。我们在这篇文章的第一部分中使用的一些窗口函数返回的结果也可以通过使用子查询来返回。假设我们想查询订单表,并且想为每个订单显示最昂贵的订单和最便宜的订单。为了获得此结果,我们可以使用以下查询,正如我们在第一部分中所看到的。
SELECT
SalesOrderID,
SalesOrderNumber,
CustomerID,
SubTotal,
MIN(SubTotal) OVER() AS LeastExpensive,
MAX(SubTotal) OVER() AS MostExpensive
FROM Sales.SalesOrderHeader
ORDER BY SubTotal
我们也可以使用子查询获得相同的结果。子查询为每一行返回一个结果。所以让我向您展示上面用子查询重写的查询。
SELECT
SalesOrderID,
SalesOrderNumber,
CustomerID,
SubTotal,
(SELECT MIN(SubTotal)
FROM Sales.SalesOrderHeader) AS LeastExpensive,
(SELECT MAX(SubTotal)
FROM Sales.SalesOrderHeader) AS MostExpensive
FROM Sales.SalesOrderHeader
ORDER BY SubTotal
您可能会认为,为了获得相同的结果,这需要更多的代码。此外,这种方法比使用窗口函数更容易出错。如果我们忘记了聚合函数怎么办?子查询将返回订单表中的所有小计,但我们不能将一个以上的值放入,嗯,一个值!自己看看会发生什么。我认为错误消息很清楚。

所以,如果子查询需要更多代码并且更容易出错,那么我们为什么要使用子查询呢?嗯,子查询可以比我刚才展示的复杂得多。只要它返回在您使用它的位置所期望的结果集,您就可以从任何地方查询任何内容。在 SELECT 语句中,这将是一个单一的值。您可以从 Person 表中查询,但仍然包含最昂贵和最便宜的订单。
SELECT
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName,
(SELECT MIN(SubTotal)
FROM Sales.SalesOrderHeader) AS LeastExpensive,
(SELECT MAX(SubTotal)
FROM Sales.SalesOrderHeader) AS MostExpensive
FROM Person.Person
ORDER BY FirstName, MiddleName, LastName
现在这已经很不错了,但是等等,还有更多。我刚才展示的子查询是自包含子查询。这意味着子查询可以在没有外部查询的情况下执行,并且仍然返回结果。这些可能很有用,但很多时候您可能想基于外部查询的值选择某些内容。在这种情况下,我们可以使用相关子查询。这很简单,意味着我们在子查询中使用外部查询中的值。让我们使用上面的查询,但现在显示该特定人员最昂贵和最便宜的订单。请记住,一个人不进行订单。客户进行订单,而客户与人相关。我们将需要为此进行连接……或另一个子查询!
SELECT
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName,
(SELECT MIN(SubTotal)
FROM Sales.SalesOrderHeader AS s
WHERE s.CustomerID = (SELECT
c.CustomerID
FROM Sales.Customer AS c
WHERE c.PersonID = p.BusinessEntityID)
) AS LeastExpensive,
(SELECT MAX(SubTotal)
FROM Sales.SalesOrderHeader AS s
WHERE s.CustomerID = (SELECT
c.CustomerID
FROM Sales.Customer AS c
WHERE c.PersonID = p.BusinessEntityID)
) AS MostExpensive
FROM Person.Person AS p
ORDER BY FirstName, MiddleName, LastName
好的,现在看起来很复杂!实际上并非如此。两个子查询除了 MIN 和 MAX 函数外是相同的,所以专注于一个子查询。请注意,我使用了列别名,因为 CustomerID 是 SalesOrderHeader 和 Customer 表中的列。所以让我们隔离子查询并仔细查看它。请注意,您无法运行它,因为它引用了外部查询中的列。
(SELECT MAX(SubTotal)
FROM Sales.SalesOrderHeader AS s
WHERE s.CustomerID = (SELECT
c.CustomerID
FROM Sales.Customer AS c
WHERE c.PersonID = p.BusinessEntityID)
) AS MostExpensive
所以就是这样。请注意,您实际上可以在 WHERE 子句中使用子查询?这很酷!请记住,窗口函数不能用于除 ORDER BY 之外的任何子句。因此,在 WHERE 子句中,我们从 Customer 表中选择 CustomerID,其中 PersonID 等于外部查询中的 BusinessEntityID。到目前为止一切顺利,对吧?查询返回的 CustomerID 用于从 SalesOrderHeader 表中选择该客户最昂贵的(或最便宜的)订单。请注意,当子查询未返回值时,该行不会被丢弃,而是显示 NULL。
3.1 用不同的方式编写相同的查询
这是一个不错的挑战,如果您准备好了。使用 no subselects 重写最后一个查询。实际上,有多种方法可以解决这个问题。我使用了 JOINS 而不是子查询。还有许多其他方法,但它们不在此文章中涵盖或尚未涵盖。以下是两种可能的解决方案,一种使用 GROUP BY 子句,另一种是使用窗口函数和 DISTINCT 而不是 GROUP BY。
SELECT
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName,
MIN(s.SubTotal) AS LeastExpensive,
MAX(s.SubTotal) AS MostExpensive
FROM Person.Person AS p
LEFT JOIN Sales.Customer AS c ON c.PersonID = p.BusinessEntityID
LEFT JOIN Sales.SalesOrderHeader AS s ON s.CustomerID = c.CustomerID
GROUP BY
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
ORDER BY FirstName, MiddleName, LastName
SELECT DISTINCT
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName,
MIN(s.SubTotal) OVER(PARTITION BY s.CustomerID) AS LeastExpensive,
MAX(s.SubTotal) OVER(PARTITION BY s.CustomerID) AS MostExpensive
FROM Person.Person AS p
LEFT JOIN Sales.Customer AS c ON c.PersonID = p.BusinessEntityID
LEFT JOIN Sales.SalesOrderHeader AS s ON s.CustomerID = c.CustomerID
ORDER BY FirstName, MiddleName, LastName
所以,如果所有三个查询都返回相同的结果,您应该使用哪一个!?查询优化超出了本文的范围,但我确实想提及这一点。通过在查询窗口中运行以下语句,可以看到 IO 统计信息。
SET STATISTICS IO ON
接下来,您可以在“查询”菜单选项下打开“包含实际查询计划”选项。

现在再次运行您的查询。在消息窗口中,您将看到详细的 IO 信息。根据经验法则,读取次数越少越好。您现在还将找到一个名为“执行计划”的第三个窗口,它确切地显示了 SQL Server 为获得结果所执行的步骤。从右到左阅读它。步骤少不总是最好,有些步骤比其他步骤需要更多的 SQL Server 工作。
那么哪个查询实际执行得最好?带有 GROUP BY 的那个。哪个最差(远远不是)?包含子查询的那个。
这并不意味着子查询一定慢或不好。它仅仅意味着存在更多用于获得相同结果的查询,并且在一个场景中最好的东西不一定在另一个场景中是最好的。此外,有时子查询可以用在其他函数不能用的地方。
3.2 更多过滤选项;IN, ANY, SOME, ALL 和 EXISTS
3.2.1 IN
我已经展示了一个在 WHERE 子句中的子查询。您可以使用它来检查值是否大于、小于、等于另一个值等。下面的查询显示了一个有点乏味的子查询和 LIKE 运算符的示例。它选择第一个名字以“Z”开头的所有人。
SELECT *
FROM Person.Person
WHERE FirstName LIKE (SELECT 'Z%')
现在还记得 IN 函数吗?它实际上可以接受一系列值作为输入。我们可以轻松地将其与子查询结合起来。我们只需要确保我们的子查询返回单个列和任意数量的行。到目前为止,我们只看到返回单个值的子查询。让我们说我们想找到所有也是客户的人。如果一个 Person 是一个 Customer,我们知道有一个 Customer 的 PersonID 与该 Person 的 PersonID 相同。所以下面的查询将轻松解决这个问题。
SELECT *
FROM Person.Person AS p
WHERE p.BusinessEntityID IN (SELECT PersonID
FROM Sales.Customer)
这等同于
SELECT *
FROM Person.Person AS p
WHERE p.BusinessEntityID = x OR p.BusinessEntityID = y OR p.BusinessEntityID = z... etc.
如果我们想知道哪些人不是客户,我们使用关键字 NOT。在这种情况下,我们还必须检查 NULL。
SELECT *
FROM Person.Person AS p
WHERE NOT p.BusinessEntityID IN (SELECT PersonID
FROM Sales.Customer
WHERE PersonID IS NOT NULL)
请记住,NULL 也可以解释为 UNKNOWN,因此如果子查询返回单个 NULL,SQL Server 将不会返回任何行,因为它不知道值是否包含在结果中。毕竟,它可能是那个 NULL 值。前面的查询等同于以下内容。
SELECT *
FROM Person.Person
WHERE BusinessEntityID <> x AND BusinessEntityID <> y AND BusinessEntityID <> z... etc.
3.2.2 ANY 和 SOME
ANY 运算符的工作方式类似于 IN 运算符,不同之处在于您可以使用 >、<、>=、<=、= 和 <> 运算符来比较值。如果子查询返回的至少一个值使谓词为真,则 ANY 返回 true。因此,下面的查询返回所有人员,除了 BusinessEntityID 为 1 的人员,因为 1 > 1 返回 FALSE。
SELECT *
FROM Person.Person
WHERE BusinessEntityID > ANY (SELECT 1)
在这些类型的查询中,ANY 可能不是很有用,即使您指定了一个更有意义的子查询。在某些情况下,ANY 可能会很有用。例如,如果您想知道所有订单(来自特定日期)是否至少具有某种状态。下面的查询说明了这一点。
DECLARE @OrderDate AS DATETIME = '20050517'
DECLARE @Status AS TINYINT = 4
IF @Status > ANY(SELECT Status
FROM Purchasing.PurchaseOrderHeader
WHERE OrderDate = @OrderDate)
PRINT 'Not all orders have the specified status!'
ELSE
PRINT 'All orders have the specified status.'
如果 @Status 大于子查询的任何结果,则结果为 TRUE(因为有一些/任何订单的状态不至少为 4。查询打印 "Not all orders have the specified status!")。
您可以使用 SOME 代替 ANY,它们具有相同的含义。
DECLARE @OrderDate AS DATETIME = '20050517'
DECLARE @Status AS TINYINT = 4
IF @Status > SOME(SELECT Status
FROM Purchasing.PurchaseOrderHeader
WHERE OrderDate = @OrderDate)
PRINT 'Not all orders have the specified status!'
ELSE
PRINT 'All orders have the specified status.'
3.2.3 ALL
与 ANY 不同,ALL 查看子查询返回的所有结果,并且仅当与所有结果的比较使谓词为真时才返回 TRUE。前面的查询可以重写如下。
DECLARE @OrderDate AS DATETIME = '20050517'
DECLARE @Status AS TINYINT = 4
IF @Status < ALL(SELECT Status
FROM Purchasing.PurchaseOrderHeader
WHERE OrderDate = @OrderDate)
PRINT 'All orders have the specified status.'
ELSE
PRINT 'Not all orders have the specified status!'
3.2.4 EXISTS
EXISTS 的用法类似于 ANY 和 ALL,但仅当子查询返回至少一条记录时才返回 true。它非常有用,您可能会更频繁地使用它。假设我们想要所有下过至少一个订单的客户。
SELECT *
FROM Sales.Customer AS c
WHERE EXISTS(SELECT *
FROM Sales.SalesOrderHeader AS s
WHERE s.CustomerID = c.CustomerID)
现在我们可能对从未下过订单的客户更感兴趣。
SELECT *
FROM Sales.Customer AS c
WHERE NOT EXISTS(SELECT *
FROM Sales.SalesOrderHeader AS s
WHERE s.CustomerID = c.CustomerID)
请注意,EXISTS 函数仅返回 TRUE 或 FALSE,而不返回任何列。因此,在 SELECT 语句中放置什么并不重要。事实上,这是您可以无所顾忌地使用 SELECT * 的唯一地方!
4. 从子查询中查询;派生表
在上一章中,我们看到了子查询。我们在 SELECT 语句、WHERE 语句中看到了它们,并将它们作为参数传递给函数。您可以将子查询放在几乎任何您想要的地方,包括 HAVING 和 ORDER BY 子句。这也包括 FROM 子句。
当我们在 FROM 子句中使用子查询时,结果称为派生表。派生表是命名的表表达式,与子查询一样,它仅对定义它的查询可见。它与子查询不同之处在于它返回一个完整的表结果。这实际上可以解决我们之前遇到的一些问题!还记得我们不能在 ORDER BY 子句之外的任何地方使用窗口函数吗?如果我们先选择值,然后在外部查询中过滤它们怎么办?这是完全有效的!
SELECT *
FROM (SELECT
SalesOrderID,
SalesOrderNumber,
CustomerID,
AVG(SubTotal) OVER(PARTITION BY CustomerID) AS AvgSubTotal
FROM Sales.SalesOrderHeader) AS d
WHERE AvgSubTotal > 100
ORDER BY AvgSubTotal, CustomerID, SalesOrderNumber
有几件事需要牢记。子查询的结果需要是关系型的。这意味着它返回的每一列都必须有一个名称。AVG(SubTotal)... 将没有名称,因此我们必须为其指定别名。我们还必须为派生表本身指定别名。
此外,关系不是有序的,因此我们不能在派生表中指定 ORDER BY。最后一个规则有一个例外。每当您在派生表中指定 TOP 或 OFFSET-FETCH 子句时,您都可以使用 ORDER BY。在这种情况下,查询不会返回有序的结果,但它会返回结果应该包含的顶部 x 行(如果结果已排序)。因此,ORDER BY 被用作过滤器而不是排序。下一个查询说明了这一点。
SELECT *
FROM (SELECT TOP 100 PERCENT
SalesOrderID,
SalesOrderNumber,
CustomerID,
Freight
FROM Sales.SalesOrderHeader
ORDER BY Freight) AS d
这是结果。

请注意,我正在对整个表进行选择,因为让 SQL Server 不返回排序数据非常困难。在任何其他情况下,它必须先对数据进行排序,然后才能检查哪些行应该返回,哪些不应该返回。当数据排序后,SQL Server 不会取消排序它们然后再返回结果。在这种情况下,不需要排序,因为无论如何都需要返回整个表。这里的底线是 ORDER BY 实际上没有对我们的结果集进行排序。
下一个查询说明了结果可能已排序。
SELECT *
FROM (SELECT TOP 10000
SalesOrderID,
SalesOrderNumber,
CustomerID
FROM Sales.SalesOrderHeader
ORDER BY CustomerID) AS d
这是结果。

这些结果可能看起来已排序,但请记住,SQL Server 不能保证排序。在这种情况下,SQL Server 在返回行之前需要按 CustomerID 对行进行排序。只需记住,任何关系结果中的 ORDER BY 都用于过滤,而不是排序。
使用派生表不能做的一件事是与派生表进行连接。您可能想做我在文章第一部分关于自连接的示例中所做的事情。然而,这是无效的。
SELECT *
FROM (SELECT
SalesOrderID,
SalesOrderNumber,
CustomerID,
AVG(SubTotal) OVER(PARTITION BY CustomerID) AS AvgSubTotal
FROM Sales.SalesOrderHeader) AS d
JOIN d AS d2 ON d2.CusomerID = d.CustomerID + 1
WHERE AvgSubTotal > 100
ORDER BY AvgSubTotal, CustomerID, SalesOrderNumber
这不是有效语法,您唯一能够连接派生表的方法是在 JOIN 子句中重复派生表!
SELECT *
FROM (SELECT
SalesOrderID,
SalesOrderNumber,
CustomerID,
AVG(SubTotal) OVER(PARTITION BY CustomerID) AS AvgSubTotal
FROM Sales.SalesOrderHeader) AS d
JOIN (SELECT
SalesOrderID,
SalesOrderNumber,
CustomerID,
AVG(SubTotal) OVER(PARTITION BY CustomerID) AS AvgSubTotal
FROM Sales.SalesOrderHeader) AS d2 ON d2.CustomerID = d.CustomerID + 1
WHERE d.AvgSubTotal > 100
ORDER BY d.AvgSubTotal, d.CustomerID, d.SalesOrderNumber
天哪!这还暴露了派生表和子查询的另一个问题。它们会让您的查询变得庞大、复杂且难以阅读。
5. 通用表表达式,也称为 CTE
与派生表一样,通用表表达式(也通常缩写为 CTE)是仅对其定义它的查询可见的命名表表达式。CTE 弥补了派生表的一些不足。首先,CTE 在您的查询开始时定义,或者更确切地说,在顶部。这使得它比派生表更具可读性。您首先命名和定义您的 CTE,然后在后续查询中使用它。我使用派生表展示的第一个示例可以使用 CTE 重写。
WITH CTE
AS
(
SELECT
SalesOrderID,
SalesOrderNumber,
CustomerID,
AVG(SubTotal) OVER(PARTITION BY CustomerID) AS AvgSubTotal
FROM Sales.SalesOrderHeader
)
SELECT *
FROM CTE
WHERE AvgSubTotal > 100
ORDER BY AvgSubTotal, CustomerID, SalesOrderNumber
语法清晰简洁。但 CTE 并非只能做到这些。您可以使用多个 CTE 并将它们连接到最终的 SELECT 语句中。以下实际上是我在生产环境中遇到过几次的情况。我们有一个头表和一个明细表。明细表有一个总计(总价或总重量),所有行产品的总和存储在头表中。有时事情并不如预期那样,您的头总计实际上并不反映您所有明细的总和。
WITH SOH
AS
(
SELECT
s.SalesOrderID,
s.SalesOrderNumber,
s.CustomerID,
p.FirstName,
p.LastName,
s.SubTotal
FROM Sales.SalesOrderHeader AS s
JOIN Sales.Customer AS c ON c.CustomerID = s.CustomerID
JOIN Person.Person AS p ON p.BusinessEntityID = c.PersonID
),
SOD AS
(
SELECT
SalesOrderID,
SUM(LineTotal) AS TotalSum
FROM Sales.SalesOrderDetail
GROUP BY SalesOrderID
)
SELECT *
FROM SOH
JOIN SOD ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SubTotal <> SOD.TotalSum
注意几点。第一个 CTE 侧重于获取我们需要的数据并执行必要的连接。第二个 CTE 侧重于获取所有销售订单明细的总和。最终查询连接这两个 CTE,并且只过滤那些订单总计与明细总计不相等的行。我们可以不使用 CTE 来编写它。下面的查询显示了如何实现。
SELECT
s.SalesOrderID,
s.SalesOrderNumber,
s.CustomerID,
p.FirstName,
p.LastName,
s.SubTotal,
sd.SalesOrderID,
SUM(sd.LineTotal) AS TotalSum
FROM Sales.SalesOrderHeader AS s
JOIN Sales.Customer AS c ON c.CustomerID = s.CustomerID
JOIN Person.Person AS p ON p.BusinessEntityID = c.PersonID
JOIN Sales.SalesOrderDetail AS sd ON sd.SalesOrderID = s.SalesOrderID
GROUP BY
s.SalesOrderID,
s.SalesOrderNumber,
s.CustomerID,
p.FirstName,
p.LastName,
s.SubTotal,
sd.SalesOrderID
HAVING SUM(sd.LineTotal) <> s.SubTotal
那么您应该使用哪一个呢?实际上,这无关紧要。就读取次数而言,两个查询的性能完全相同。唯一的区别是最后一个查询的查询计划为 HAVING 子句执行了额外的步骤。
您可以使用 CTE 来执行更复杂的操作,甚至可以在单独的 CTE 中执行最后的连接。这说明了 CTE 的一个很好的用途。您可以在另一个 CTE 中引用一个 CTE。下面的查询编译为与“只有”两个 CTE 的查询完全相同的查询。
WITH SOH
AS
(
SELECT
s.SalesOrderID,
s.SalesOrderNumber,
s.CustomerID,
p.FirstName,
p.LastName,
s.SubTotal
FROM Sales.SalesOrderHeader AS s
JOIN Sales.Customer AS c ON c.CustomerID = s.CustomerID
JOIN Person.Person AS p ON p.BusinessEntityID = c.PersonID
),
SOD AS
(
SELECT
SalesOrderID,
SUM(LineTotal) AS TotalSum
FROM Sales.SalesOrderDetail
GROUP BY SalesOrderID
),
TOTAL AS
(
SELECT
SOH.SalesOrderID,
SOH.SalesOrderNumber,
SOH.CustomerID,
SOH.FirstName,
SOH.LastName,
SOH.SubTotal,
SOD.TotalSum
FROM SOH
JOIN SOD ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE SOH.SubTotal <> SOD.TotalSum
)
SELECT *
FROM TOTAL
与派生表不同,CTE 可以用于 JOIN,并且也可以进行自连接。我在 AdventureWorks2012 中仍然没有自连接的用例,所以我会使用我在第一部分中使用的相同示例,但这次使用 CTE。
WITH CTE AS
(
SELECT
BusinessEntityID,
Title,
FirstName,
LastName
FROM Person.Person
)
SELECT
CTE1.BusinessEntityID AS CurrentID,
CTE1.Title AS CurrentTitle,
CTE1.FirstName AS CurrentFirstName,
CTE1.LastName AS CurrentLastName,
CTE2.BusinessEntityID AS NextID,
CTE2.Title AS NextTitle,
CTE2.FirstName AS NextFirstName,
CTE2.LastName AS NextLastName
FROM CTE AS CTE1
LEFT JOIN CTE AS CTE2 ON CTE2.BusinessEntityID = CTE1.BusinessEntityID + 1
ORDER BY CurrentID, CurrentFirstName, CurrentLastName
CTE 实际上在 SQL 中还有另一个用途,那就是递归。我将在下一节中介绍。
6. 集合运算符;UNION, INTERSECT 和 EXCEPT
6.1 组合集合;UNION 和 UNION ALL
有几个运算符可用于将多个结果集组合成一个集合。UNION 运算符就是其中之一。UNION 获取两个结果集并将它们连接在一起。有两种类型的 UNION,UNION 和 UNION ALL。两者的区别在于 UNION 会消除两个集合中都存在的行(即重复行),而 UNION ALL 则保留这些行。下面的示例清楚地说明了如何使用 UNION 和 UNION ALL 以及它们之间的区别。
SELECT TOP 1
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
UNION
SELECT TOP 2
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
ORDER BY BusinessEntityID
结果如下。

请注意,我们实际上选择了总共三条记录,但结果只显示两条。这是因为第一条记录被 UNION 删除了,因为所有属性都具有相同的值(它们是重复的)。请注意,NULL 被视为相等。
如果我们想保留第三行,我们可以使用 UNION ALL。
SELECT TOP 1
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
UNION ALL
SELECT TOP 2
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
ORDER BY BusinessEntityID

这次重复行没有从结果中删除。
UNION 运算符可以对具有相同数量的列且每列索引类型相同的任何两个集合进行操作。
SELECT
'Sales order' AS OrderType,
SalesOrderID AS OrderID,
SalesOrderNumber,
CustomerID AS CustomerOrVendorID,
SubTotal,
NULL AS RevisionNumber
FROM Sales.SalesOrderHeader
WHERE SubTotal < 2
UNION
SELECT
'Purchase order',
PurchaseOrderID,
NULL,
VendorID,
SubTotal,
RevisionNumber
FROM Purchasing.PurchaseOrderHeader
WHERE RevisionNumber > 5
ORDER BY OrderType, OrderID
如您所见,我们可以从任何两个表中进行选择,但两个查询的列数必须相同,并且返回值的类型(文本、数字、日期等)也必须相同。
除此之外,还有几点需要注意。使用了第一个查询的列名。对于当前选择中不适用的列,我们可以使用 NULL(或其他正确类型的任何值)作为占位符。每个查询都有自己的 WHERE 子句(以及任何其他子句),除了 ORDER BY。ORDER BY 放在最后,用于对整个结果集进行排序。
您可以使用多个 UNION 来组合更多集合。下面的查询为每种订单类型的总小计添加了一行。
SELECT
'Sales order' AS OrderType,
SalesOrderID AS OrderID,
SalesOrderNumber,
CustomerID AS CustomerOrVendorID,
SubTotal,
NULL AS RevisionNumber
FROM Sales.SalesOrderHeader
WHERE SubTotal < 2
UNION
SELECT
'Purchase order',
PurchaseOrderID,
NULL,
VendorID,
SubTotal,
RevisionNumber
FROM Purchasing.PurchaseOrderHeader
WHERE RevisionNumber > 5
UNION
SELECT
'Sales order total',
NULL,
NULL,
NULL,
SUM(SubTotal),
NULL
FROM Sales.SalesOrderHeader
WHERE SubTotal < 2
UNION
SELECT
'Purchase order total',
NULL,
NULL,
NULL,
SUM(SubTotal),
NULL
FROM Purchasing.PurchaseOrderHeader
WHERE RevisionNumber > 5
ORDER BY OrderType, OrderID
6.2 使用 CTE 和 UNION ALL 进行递归
我已经提到 CTE 可用于递归函数。还记得第一部分中的自连接示例吗?员工可能有 ManagerID,它引用另一个 Employee。当然,任何经理都可以有自己的经理,一直到最高经理。我们无法知道层次结构中有多少经理。为此,我们可以使用递归。只需给我们经理的经理的经理……一直到经理没有经理为止。这可以通过 UNION ALL 实现。这种递归 CTE 由两个或多个查询组成,其中一个是锚成员,另一个是递归成员。锚成员调用一次并返回一个关系结果。递归成员被调用,直到它返回一个空结果集,并且它引用 CTE。
不幸的是,我在 AdventureWorks2012 中没有递归的用例,所以我将只使用递归来从 Person 表中选择 BusinessEntityID 比上一个低一的任何 Person,直到没有更低的 ID 了。
WITH REC AS
(
SELECT
BusinessEntityID,
FirstName,
LastName
FROM Person.Person
WHERE BusinessEntityID = 9
UNION ALL
SELECT
p.BusinessEntityID,
p.FirstName,
p.LastName
FROM REC
JOIN Person.Person AS p ON p.BusinessEntityID = REC.BusinessEntityID - 1
)
SELECT *
FROM REC
运行此查询以获取 BusinessEntityID 为 9 的结果如下。

为了证明这确实有效,这是相同查询的结果,但 BusinessEntityID 为 1704。它在 1699 停止,因为显然没有 BusinessEntityID 为 1698 的 Person。

一个小小的警告:SQL Server 中的最大递归次数是 100。因此,下面的查询将正常运行(最多递归 100 次)。
WITH REC AS (
SELECT 100 AS SomeCounter
UNION ALL
SELECT SomeCounter - 1
FROM REC
WHERE SomeCounter - 1 >= 0
)
SELECT *
FROM REC再加一个将导致溢出!

使用查询提示 MAXRECURSION 可以帮助克服此限制。下面的查询将再次正常运行(最多递归 200 次)。
WITH REC AS (
SELECT 101 AS SomeCounter
UNION ALL
SELECT SomeCounter - 1
FROM REC
WHERE SomeCounter - 1 >= 0
)
SELECT *
FROM REC
OPTION (MAXRECURSION 200)
6.3 INTERSECT
INTERSECT 是另一个集合运算符,其语法和规则与 UNION 运算符相同。两者之间的区别在于返回的结果。UNION 返回所有行并删除重复行。INTERSECT 只返回重复行(一次)。让我们以我为 UNION 使用的第一个示例为例,但将 UNION 替换为 INTERSECT。
SELECT TOP 1
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
INTERSECT
SELECT TOP 2
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
ORDER BY BusinessEntityID
由于两个查询都只返回 TOP 1 条记录,因此这也是 INTERSECT 返回的结果。
![]()
与 UNION 一样,在 INTERSECT 中,NULL 被视为相等。
6.4 EXCEPT
EXCEPT 是第三个集合运算符,其语法和规则也与 UNION 运算符相同。EXCEPT 只返回第一个查询中未被第二个查询返回的记录。换句话说,EXCEPT 返回仅存在于第一个查询中的行。我们应该注意到,对于 UNION 和 INTERSECT,哪个查询在前哪个查询在后并不重要,结果保持不变。对于 EXCEPT,查询的顺序很重要。我将通过使用我为 UNION 和 INTERSECT 使用的相同示例,但改用 EXCEPT 来展示这一点。下面的查询不返回任何行。
SELECT TOP 1
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
EXCEPT
SELECT TOP 2
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
ORDER BY BusinessEntityID
没有返回行,因为第一个查询没有返回第二个查询未返回的任何行。现在让我们切换 TOP。现在第二个记录仅由第一个查询返回。
SELECT TOP 2
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
EXCEPT
SELECT TOP 1
BusinessEntityID,
Title,
FirstName,
MiddleName,
LastName
FROM Person.Person
ORDER BY BusinessEntityID
此查询返回结果。
![]()
您可以在同一个查询中使用 UNION、INTERSECT 和 EXCEPT。在这种情况下,INTERSECT 的优先级高于 UNION 和 EXCEPT。UNION 和 EXCEPT 被视为相等,并按它们出现的顺序执行。
7. 推送到表;PIVOT 和 UNPIVOT
7.1 透视
透视和逆透视是分组和聚合数据的专门情况。透视是将行创建为列的过程,而逆透视为将列创建为行的过程。我们从透视数据开始。例如,我们想知道客户按销售人员分组订购的总小计。但是,出于某种原因,我们想将销售人员创建为列。所以我们会得到列 CustomerID、SalesPerson1、SalesPerson2 等,行显示客户 ID,然后显示按 SalesPerson1、SalesPerson2 等订购的总小计。这正是 PIVOT 运算符的作用。为了更好地理解这一点,让我们看一个例子。
WITH PivotData AS
(
SELECT
s.CustomerID,
s.SalesPersonID AS SpreadingCol,
s.SubTotal AS AggregationCol
FROM Sales.SalesOrderHeader AS s
)
SELECT
CustomerID,
[274] AS StephenJiang,
[275] AS MichaelBlythe,
[276] AS LindaMitchell
FROM PivotData
PIVOT(SUM(AggregationCol) FOR SpreadingCol IN ([274], [275], [276])) AS P
WHERE [274] IS NOT NULL OR [275] IS NOT NULL OR [276] IS NOT NULL
这是结果的一部分(请注意,我没有显示从第一行开始)。

这看起来相当困难。让我们将其分解成更简单的部分。首先,我正在使用 CTE 来标识我想在 PIVOT 中使用的列。然后我做一个相当奇怪的 SELECT 语句,我选择看起来像随机数的数字。实际上,这些是所谓的展开列的值,在 PIVOT 子句中定义。因此,274、275 和 276 实际上是 SalesPerson ID,我希望它们显示为列而不是行中的值。在 PIVOT 子句中,我指示要使用的聚合运算符,在这种情况下是 SUM,以及要聚合的列。然后我指定展开列,或者其值应该成为列而不是行中值的那一列。最后,但同样重要的是,您的 PIVOT 必须有一个别名,即使您不使用它。WHERE 子句是可选的。这确实很重要,所以花些时间研究语法并让它沉浸其中。
您可能注意到我没有在 PIVOT 子句中使用 CustomerID。这是因为使用 PIVOT 时,分组元素是通过消除来识别的。由于我既不使用聚合函数也不使用展开元素中的 CustomerID,因此它自动成为分组元素。这也是使用 CTE 最佳的原因。如果您直接从 Sales.SalesOrderHeader 表中选择,SalesOrderHeaderID 将成为分组的一部分,您将得到每行一个订单,而不是每个 CustomerID!
现在使用 PIVOT 运算符存在一些限制。其中之一是您不能使用表达式来定义聚合或展开列值。另一个限制是 COUNT(*) 不允许作为 PIVOT 使用的聚合函数。相反,您需要使用 COUNT(ColumnName)。您可以通过在 CTE 中选择一个常量值并对其列使用 COUNT 来解决此限制。此外,您只能使用一个聚合函数。
最后一个限制,也是我认为让您不想经常使用 PIVOT 的限制,是展开值必须是静态值的列表。在我们的示例中,这些值是 SalesPerson ID。那么这是什么意思呢?这意味着您实际上在查询中硬编码了值!我只展示了三个 SalesPersons,因为列出所有这些会使查询变得更大。只需假设我查询了我们的前三名销售人员。下个月会不会有其他人卖得更好?我们将不得不修改我们的查询!或者,如果一个 SalesPerson 离开了公司怎么办?又要重写您的查询……实际上,我必须手动查找 SalesPerson 的姓名并使用它们作为列别名才能使这些列有意义(尽管我可以使用名称进行连接并使用它们作为展开值)。您可以通过使用动态 SQL 来绕过此限制,但这超出了本文的范围。当然,当您为真正(某种程度上)静态的值编写查询时,例如增值税百分比或状态 ID,这根本不是问题。
7.2 逆透视
在某种意义上,逆透视是透视的相反或反向。我们不是将行值创建为列,而是将列值创建为行值。事实上,UNPIVOT 的起点通常是透视数据。所以让我们以 PIVOT 示例为例,并再次对其进行 UNPIVOT。对于这个例子,我将把 PIVOT 示例的结果包装在一个 CTE 中,并使用它来逆透视数据。这在实际应用中用处不大(毕竟,为什么先 PIVOT 然后直接 UNPIVOT?),但当透视数据存储在表中或 VIEW 或 STORED PROCEDURE 的结果时,它会变得更有用。
WITH DataToPivot AS
(
SELECT
s.CustomerID,
s.SalesPersonID AS SpreadingCol,
s.SubTotal AS AggregationCol
FROM Sales.SalesOrderHeader AS s
),
DataToUnpivot AS
(
SELECT
CustomerID,
[274] AS StephenJiang,
[275] AS MichaelBlythe,
[276] AS LindaMitchell
FROM DataToPivot
PIVOT(SUM(AggregationCol) FOR SpreadingCol IN ([274], [275], [276])) AS P
WHERE [274] IS NOT NULL OR [275] IS NOT NULL OR [276] IS NOT NULL
)
SELECT
CustomerID,
SalesPerson,
SubTotal
FROM DataToUnpivot
UNPIVOT(SubTotal FOR SalesPerson IN(StephenJiang, MichaelBlythe, LindaMitchell)) AS U
ORDER BY CustomerID
我将 PIVOT 示例的结果包装在 DataToUnpivot CTE 中。请注意,在此示例中,您应该得到比 PIVOT 结果多三倍的行。毕竟,PIVOT 结果中的每一行都应用于 StephenJiang 值、MichaelBlythe 值和 LindaMitchell 值。然而,事实并非如此,因为 UNPIVOT 会删除对于给定 SalesPerson 来说 SubTotal 会是 NULL 的行。下面的同一客户的透视和逆透视结果示例可能会让事情更清楚。
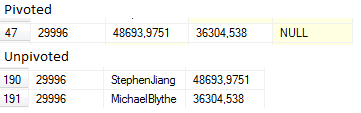
在逆透视结果中,LindaMitchell 被删除了,因为在透视结果中她的值缺失了。
让我们再看一个例子,其中我们逆透视一个实际上没有透视的表。Sales.SpecialOffer 表有特殊优惠,包含 Description、MinQty 和 MaxQty。我们希望显示 MinQty 和 MaxQty 的单独行,而不是在一行中显示所有三个。
SELECT
SpecialOfferID,
Description,
QtyType,
Qty
FROM Sales.SpecialOffer
UNPIVOT(Qty FOR QtyType IN (MinQty, MaxQty)) AS U
如您所见,QtyType 获取 MinQty 或 MaxQty(之前的列名)的值,而 Qty 现在显示该值,该值以前在 MinQty 列或 MaxQty 列中,取决于 QtyType。
同样,不能为新值列或新列名值列的值使用表达式。
8. 表表达式的更多用法;APPLY
APPLY 运算符可用于将表表达式“连接”到您的查询。我使用“连接”一词是因为 APPLY 实际上看起来像 JOIN,您可以在其中将多个表合并到同一个结果集中。有两种 APPLY 运算符,即 CROSS APPLY 和 OUTER APPLY。APPLY 运算符有趣之处在于它可以有一个引用外部查询值的表表达式。您应该记住的一点是,CROSS APPLY 实际上最像 INNER JOIN,而 OUTER APPLY 类似于 OUTER JOIN。除此之外,当 JOIN 条件非常复杂时,APPLY 运算符的性能可能远优于 JOIN。
8.1 CROSS APPLY
CROSS APPLY 运算符的工作方式类似于 INNER JOIN,它可以匹配两个表中的行,并在结果中省略未被另一个表匹配的行。所以让我们看一个例子。我们想选择所有下过 SalesOrder 的 Persons,并显示该 Person 下过的最昂贵订单的某些订单信息。
SELECT
p.BusinessEntityID,
p.FirstName,
p.LastName,
a.*
FROM Person.Person AS p
CROSS APPLY (SELECT TOP 1
s.SalesOrderID,
s.CustomerID,
s.SubTotal
FROM Sales.SalesOrderHeader AS s
JOIN Sales.Customer AS c ON c.CustomerID = s.CustomerID
WHERE c.PersonID = p.BusinessEntityID
ORDER BY s.SubTotal DESC) AS a
ORDER BY p.BusinessEntityID
因此,CROSS APPLY 运算符将表表达式作为输入参数,并简单地将结果与外部查询的每一行连接起来。请注意,我们可以使用 TOP 1,通过使用 WHERE 子句将 CustomerID 与 BusinessEntityID 匹配来过滤,并通过 ORDER BY DESC 来获取该特定客户最昂贵的订单。这仅使用 JOIN 是无法实现的!请注意,未下过订单的 Persons 不会被返回。与 PIVOT 和 UNPIVOT 一样,我们需要为 APPLY 运算符的结果指定别名。
由于我们可以在 APPLY 运算符中引用外部查询中的值,因此也可以将函数与 APPLY 运算符一起使用。AdventureWorks2012 数据库实际上有一个用户定义的表值函数,名为 ufnGetContactInformation,它以 PersonID 作为输入并返回关于 Person 的信息(姓名以及他们是否是供应商、客户等)。因此,使用 APPLY 运算符,我们可以通过将外部查询的 BusinessEntityID 传递给函数的输入来在我们的结果集中显示此信息。由于调用此函数 19972 次(每个 Person 调用一次)实际上非常耗时,因此我们只选择 TOP 1000。
SELECT TOP 1000
p.BusinessEntityID,
a.*
FROM Person.Person AS p
CROSS APPLY ufnGetContactInformation(p.BusinessEntityID) AS a
ORDER BY p.BusinessEntityID
请注意,我们必须在不带括号或 SELECT... FROM 的情况下指定函数。
当然,我们可以在单个查询中使用多个 APPLY 运算符。
SELECT TOP 1000
p.BusinessEntityID,
a.*,
s.*
FROM Person.Person AS p
CROSS APPLY ufnGetContactInformation(p.BusinessEntityID) AS a
CROSS APPLY (SELECT TOP 1
s.SalesOrderID,
s.CustomerID,
s.SubTotal
FROM Sales.SalesOrderHeader AS s
JOIN Sales.Customer AS c ON c.CustomerID = s.CustomerID
WHERE c.PersonID = p.BusinessEntityID
ORDER BY s.SubTotal DESC) AS s
ORDER BY p.BusinessEntityID
您不必将外部查询中的行与 APPLY 结果匹配。下面的 APPLY 只是返回最昂贵的订单,因此会显示该订单以及每个 Person,而不管该订单是否由该 Person 下单。
SELECT
p.BusinessEntityID,
p.FirstName,
p.LastName,
a.*
FROM Person.Person AS p
OUTER APPLY (SELECT TOP 1
s.SalesOrderID,
s.CustomerID,
s.SubTotal
FROM Sales.SalesOrderHeader AS s
ORDER BY s.SubTotal DESC) AS a
ORDER BY p.BusinessEntityID
并且行不必是一对一匹配。下面的查询获取前三个最昂贵的订单,而不考虑客户,因此每个 Person 在结果中都会重复三次(每个订单一次,无论该订单是否由该 Person 下单)。
SELECT
p.BusinessEntityID,
p.FirstName,
p.LastName,
a.*
FROM Person.Person AS p
OUTER APPLY (SELECT TOP 3
s.SalesOrderID,
s.CustomerID,
s.SubTotal
FROM Sales.SalesOrderHeader AS s
ORDER BY s.SubTotal DESC) AS a
ORDER BY p.BusinessEntityID
8.2 OUTER APPLY
OUTER APPLY 的工作方式与 CROSS APPLY 非常相似,不同之处在于,即使 APPLY 运算符没有返回相应的行,它也会返回行。我们可以通过使用上一节的第一个示例来看到这一点,但将 CROSS APPLY 更改为 OUTER APPLY。通过运行此查询,您可以看到未下过订单的 Person 现在也包含在结果集中。
SELECT
p.BusinessEntityID,
p.FirstName,
p.LastName,
a.*
FROM Person.Person AS p
OUTER APPLY (SELECT TOP 3
s.SalesOrderID,
s.CustomerID,
s.SubTotal
FROM Sales.SalesOrderHeader AS s
JOIN Sales.Customer AS c ON c.CustomerID = s.CustomerID
WHERE c.PersonID = p.BusinessEntityID
ORDER BY s.SubTotal DESC) AS a
ORDER BY p.BusinessEntityID
除此之外,适用于 CROSS APPLY 运算符的所有规则也适用于 OUTER APPLY。
9. 查询的其他方面
到目前为止,我们只查询了数据,并按原样返回了数据库中的值。然而,我们还可以对这些值做更多的事情。例如,假设一个订单有一个 SubTotal 列和一个 TotalDue 列。我们想知道客户在一个订单上支付了多少百分比的税。然而,Freight 也被添加到 TotalDue 中,所以我们必须先减去它。通常,我们会通过计算 SubTotal 和 TotalDue 之间的差值,将其除以 TotalDue,然后乘以 100 来计算。
我们可以在 SQL Server 中进行这种数学计算。下面的查询显示了如何做到这一点。
SELECT
SalesOrderID,
CustomerID,
SubTotal,
TaxAmt,
Freight,
TotalDue,
(((TotalDue - Freight) - SubTotal) / (TotalDue - Freight)) * 100 AS TaxPercentage
FROM Sales.SalesOrderHeader
当然,我们可以使用 SubTotal、TaxAmt 和 Freight 来自己计算 TotalDue。您应该记住的是,将数字值加到 NULL 始终会得到 NULL。
SELECT
SalesOrderID,
CustomerID,
SubTotal,
TaxAmt,
Freight,
TotalDue,
SubTotal + TaxAmt + Freight AS TotalDueCalc
FROM Sales.SalesOrderHeader
如果我们想给每个客户的订单打九折(可能不是个好主意,但我们这样做)。
SELECT
SalesOrderID,
CustomerID,
SubTotal,
SubTotal - (SubTotal * 0.10) AS SubTotalAfterDiscount
FROM Sales.SalesOrderHeader
我们还可以使用 FLOOR、CEILING 和 ROUND 等函数来进一步操作我们的数据。
SELECT
SalesOrderID,
CustomerID,
SubTotal,
FLOOR(SubTotal) AS SubTotalRoundedDown,
CEILING(SubTotal) AS SubTotalRoundedUp,
ROUND(SubTotal, 2) AS RoundedToTwoDecimals
FROM Sales.SalesOrderHeader
还有许多其他函数可以用于以各种方式操作数据。我不可能在这里一一讨论。以下各节将概述一些用于在 SQL Server 中操作数据的重要且最常用的函数。
9.1 类型转换;CAST 和 CONVERT, PARSE 和 FORMAT
9.1.1 CAST 和 CONVERT
类型转换和转换值是同一件事,即更改一种数据类型为另一种数据类型。例如,我们可以将数字转换为字符串,将字符串转换为数字(前提是文本实际表示一个数字值),将日期转换为字符串,将字符串转换为日期等。
SQL Server 实际上有四个用于类型转换和转换值的函数。CAST, CONVERT、TRY_CAST 和 TRY_CONVERT。
让我们先看看 CAST 函数。首先,您可以将任何内容转换为 VARCHAR(x),因为每一个值都可以显示为纯文本。这是一个将一些值转换为不同类型的简单示例。
SELECT
CAST('123' AS INT) AS VarcharToInt,
CAST('20131231' AS DATETIME2) AS VarcharToDateTime2,
CAST(1.2 AS INT) AS FloatToInt,
CAST(1234 AS VARCHAR(4)) AS IntToVarchar
我们可以将 SubTotal 转换为 VARCHAR(20),并按字母数字顺序排序,而不是按数字顺序排序(这意味着 10 在 2 之前等)。
SELECT
SalesOrderID,
SubTotal,
CAST(SubTotal AS VARCHAR(20)) AS SubTotalAsAlphaNum
FROM Sales.SalesOrderHeader
ORDER BY SubTotalAsAlphaNum
不幸的是,SQL Server 会为我们格式化结果,字母数字结果在小数点后只有两位。使用 CONVERT,我们可以更好地控制值的格式。
CONVERT 函数接受三个参数。第一个参数是要转换成的类型,第二个是要转换的值,第三个是可选的样式参数。在这种情况下,我们希望我们的货币具有样式编号 2。
SELECT
SalesOrderID,
SubTotal,
CONVERT(VARCHAR(20), SubTotal, 2) AS SubTotalAsAlphaNum
FROM Sales.SalesOrderHeader
ORDER BY SubTotalAsAlphaNum
我怎么知道格式?在 TechNet 的CAST 和 CONVERT 页面上查找它们。
使用 CONVERT,我们可以将 DATETIME 值转换为 VARCHAR,并使用样式参数显示本地日期格式。
SELECT
SalesOrderID,
OrderDate,
CONVERT(VARCHAR, OrderDate, 13) AS OrderDateAsEur,
CONVERT(VARCHAR, OrderDate, 101) AS OrderDateAsUS
FROM Sales.SalesOrderHeader
当然,您也可以将 VARCHARS 转换为 DATETIMES。为此,您应始终使用 yyyyMMdd 的文本格式,如以下查询所示。任何其他格式都不能保证是区域无关的,在欧洲运行的查询,结果为 7 月 6 日,在美国可能结果为 6 月 7 日!
SELECT CONVERT(DATETIME, '20131231')
一些类型转换可能与您期望的有所不同。例如,您可以将 DATETIME 值转换为 INT。返回的值实际上是指定值与 SMALLDATETIME 类型的最小日期(即 1900 年 1 月 1 日)之间的天数差异。下面的查询显示了这一点。
以下函数在本篇文章后面会讨论,但目前请关注结果。
SELECT CONVERT(INT, CONVERT(DATETIME, '17530101')) AS MinDateAsInt,
CONVERT(INT, GETDATE()) AS TodayAsInt,
DATEADD(d, CONVERT(INT,
CONVERT(DATETIME, '17530101')), '19000101')
AS MinSmallDateTimePlusMinDateAsInt,
DATEADD(d, CONVERT(INT, GETDATE()), '19000101')
AS MinSmallDateTimePlusTodayAsInt
这是结果(您的结果看起来会不同,因为我使用的是当前日期时间,我写这篇文章时的时间与您阅读时的时间不同)。
![]()
那么,当我们将一个无法转换为指定类型的值进行转换时会发生什么?在这种情况下,我们会进行无效转换,并引发异常。

如果您不希望在无效转换时引发异常,可以使用 TRY_CAST 和 TRY_CONVERT 函数。它们的功能与 CAST 和 CONVERT 完全相同,只是 TRY_ 变体在转换无效时不会引发错误,而是返回 NULL。
SELECT TRY_CAST('Hello' AS INT),
TRY_CONVERT(INT, 'Hello')
SQL Server 可能会给您一个警告,即 TRY_CAST 未被识别为内置函数名。这似乎是一个错误,您可以忽略它,查询将正常运行。
9.1.2 PARSE
解析是一种特殊的类型转换,它总是将 VARCHAR 值转换为另一种数据类型。在 SQL Server 中,我们可以使用 PARSE 或 TRY_PARSE 函数,它接受 VARCHAR 值、数据类型和可选的区域代码作为参数,以指定值所用区域的格式。例如,我们可以解析一个表示日期的 VARCHAR 值,该日期值以荷兰标准格式化为 DATETIME 值。
SELECT PARSE('12-31-2013' AS DATETIME2 USING 'en-US') AS USDate,
PARSE('31-12-2013' AS DATETIME2 USING 'nl-NL') AS DutchDate
我们也可以将 PARSE 用于数字或货币类型。下面的示例展示了两种不同格式的货币样式如何产生相同的 PARSE 输出。请注意,美国人使用点作为小数点分隔符,而荷兰人使用逗号。
SELECT PARSE('$123.45' AS MONEY USING 'en-US') AS USMoney,
PARSE('€123,45' AS MONEY USING 'nl-NL') AS DutchMoney
如果我们省略货币符号和区域信息,我们会得到非常不同的结果!
SELECT PARSE('123.45' AS MONEY) AS USMoney,
PARSE('123,45' AS MONEY) AS DutchMoney
当然,解析也可能失败。与 CAST 和 CONVERT 一样,我们会收到错误。

同样,您可以使用 TRY_PARSE 在 PARSE 失败时返回 NULL。
SELECT TRY_PARSE('Hello' AS MONEY USING 'nl-NL')
建议仅将 PARSE 用于将表示为文本的日期和数字值解析为其相应的数据类型。对于更通用的类型转换,请使用 CAST 和 CONVERT。
9.1.3 FORMAT
FORMAT 函数实际上并没有提供在数据类型之间转换的方法。相反,它提供了一种以给定格式输出数据的方式。
例如,我们可以将日期格式化为只显示日期而不显示时间,或者我们可以将数字格式化为显示前导零,并始终显示 x 位小数。
SELECT
SalesOrderID,
FORMAT(SalesOrderID, 'SO0') AS SalesOrderNumber,
CustomerID,
FORMAT(CustomerID, '0.00') AS CustomerIDAsDecimal,
OrderDate,
FORMAT(OrderDate, 'dd-MM-yy') AS FormattedOrderDate
FROM Sales.SalesOrderHeader
您还可以指定区域以该指定区域的格式进行格式化。
SELECT
SalesOrderID,
OrderDate,
FORMAT(OrderDate, 'd', 'en-US') AS USShortDate,
FORMAT(OrderDate, 'd', 'nl-NL') AS DutchShortDate,
FORMAT(OrderDate, 'D', 'en-US') AS USLongDate,
FORMAT(OrderDate, 'D', 'nl-NL') AS DutchLongDate
FROM Sales.SalesOrderHeader
ORDER BY CustomerID
这是某些结果。

当然,我们也可以格式化数字值。
SELECT
SalesOrderID,
SubTotal,
FORMAT(SubTotal, 'C', 'nl-NL') AS DutchCurrency
FROM Sales.SalesOrderHeader
您可能想知道是否有 TRY_FORMAT
SELECT
SalesOrderID,
SubTotal,
FORMAT(SubTotal, 'Hello', 'nl-NL') AS DutchCurrency
FROM Sales.SalesOrderHeader
对于格式值,我再次将您重定向到 TechNet 的FORMAT 页面。
9.2 VARCHAR 函数
您将经常使用 (VAR)CHAR 类型。在上一节中,我们看到了 FORMAT,它可用于获取某些值的特定、区域相关的输出。但这并不是您能用文本数据做的所有事情。
首先,很多时候您想连接文本。例如,Person 表有一个 FirstName 和一个 LastName 列。将它们组合起来,用空格分隔,就可以成为一个 FullName 字段。
SELECT
BusinessEntityID,
FirstName + ' ' + LastName AS FullName
FROM Person.Person
ORDER BY FullName
当连接字符串到 NULL 时,结果是 NULL,除非称为 CONCAT_NULL_YIELDS_NULL_INPUT 的会话选项被关闭。这超出了本文的范围。
关于连接的警告。请确保您连接的是文本到文本或数字到数字。下面的连接会导致错误。
SELECT
BusinessEntityID,
BusinessEntityID + FirstName AS IDName
FROM Person.Person
ORDER BY IDName
这是错误。

SQL Server 尝试将 FirstName 转换为 INT,因为 BusinessEntityID 是 INT。交换值也无济于事。有帮助的是 CAST。
SELECT
BusinessEntityID,
CAST(BusinessEntityID AS VARCHAR(6)) + FirstName AS IDName
FROM Person.Person
ORDER BY IDName
或者您可以使用 CONCAT 函数,它将传递给函数的所有值作为字符串连接起来。使用 CONCAT 时,会忽略 NULL。
SELECT
BusinessEntityID,
CONCAT(BusinessEntityID, FirstName) AS IDName,
CONCAT(NULL, LastName) AS LastName
FROM Person.Person
ORDER BY IDName
其他时候,您只想返回字符串的一部分。例如,第一个或最后一个字母。这可以通过 LEFT 和 RIGHT 函数来实现。
SELECT
BusinessEntityID,
LEFT(FirstName, 1) + '. ' + LastName AS AbbrvName,
RIGHT(FirstName, 3) AS LastThreeLetters
FROM Person.Person
ORDER BY AbbrvName
您还可以使用 SUBSTRING 通过(从 1 开始的)索引获取字符串的一部分。下面的查询输出与最后一个查询相同的数据。请注意,我还使用 LEN 函数来确定给定输入的长度。
SELECT
BusinessEntityID,
SUBSTRING(FirstName, 1, 1) + '. ' + LastName AS AbbrvName,
SUBSTRING(FirstName, LEN(FirstName) - 2, 3) AS LastThreeLetters
FROM Person.Person
ORDER BY AbbrvName
要获取字符串中特定字符的索引,您可以使用 CHARINDEX 函数,它返回指定字符第一次出现的位置。使用此函数,我们可以例如格式化一个数字值,并单独返回小数点前的部分和小数点后的部分。
SELECT
SubTotal,
SUBSTRING(
FORMAT(SubTotal, 'G', 'en-US'),
0,
CHARINDEX('.', FORMAT(SubTotal, 'G', 'en-US'))) AS DigitsBeforeDecimal,
SUBSTRING(
FORMAT(SubTotal, 'G', 'en-US'),
CHARINDEX('.', FORMAT(SubTotal, 'G', 'en-US')) + 1,
4) AS DigitsAfterDecimal
FROM Sales.SalesOrderHeader
有时您想以 FORMAT 函数不支持的方式格式化字符串。您可以使用 UPPER 和 LOWER 函数将字符串全部转换为大写或小写。LTRIM 和 RTRIM 函数删除字符串的前导和尾随空格(在处理旧应用程序时特别有用!)。
SELECT
UPPER(FirstName) AS UpperName,
LOWER(FirstName) AS LowerName,
LTRIM(' abc ') AS AbcWTrailing,
RTRIM(' abc ') AS AbcWLeading,
LTRIM(RTRIM(' abc ')) AS Abc
FROM Person.Person
还有一些有用的函数可以用来修改字符串。使用 REPLACE,您可以将字符串中的字符或子字符串替换为另一个字符或字符串。使用 STUFF,您可以根据索引替换字符串的一部分。使用 REVERSE,当然,您可以反转字符串。在下面的示例中,我们反转 SalesOrderNumber,将 SalesOrderNumber 中的 'SO' 替换为 'SALE',并用 'PURC' 替换 PurchaseOrderNumber 的前两个字符。
SELECT
SalesOrderNumber,
REVERSE(SalesOrderNumber) AS ReversedOrderNumber,
REPLACE(SalesOrderNumber, 'SO', 'SALE') AS NewOrderFormat,
PurchaseOrderNumber,
STUFF(PurchaseOrderNumber, 1, 2, 'PURC') AS NewPurchaseFormat
FROM Sales.SalesOrderHeader
您还可以使用更多函数来格式化、修改或获取有关字符串值的信息。您可以在 TechNet 上找到它们。
9.3 DATETIME 函数
在 SQL Server(或任何语言)中处理日期和时间从未容易过。没有没有时间的日期,没有没有日期的时间,如果两个值相差一毫秒,比较就会失败,每个区域都有自己的格式,我们有夏令时,时区,甚至不是每个区域都有相同的日历!幸运的是,SQL Server 为我们提供了许多函数(和数据类型)来处理日期和时间。
我推荐阅读 TechNet 上的以下页面:日期和时间数据类型和函数。
首先,我们如何获取当前时间?SQL Server 有几个函数可供您使用。GETDATE 和 CURRENT_TIMESTAMP 获取当前日期和时间(在运行 SQL Server 实例的计算机上)作为 DATETIME 数据类型,GETUTCDATE 获取协调世界时 (UTC) 的当前日期和时间作为 DATETIME 数据类型,SYSDATETIME 也返回当前日期和时间,但作为 DATETIME2(7) 数据类型,SYSUTCDATETIME 以 DATETIME2(7) 数据类型返回协调世界时的当前日期和时间,而 SYSDATETIMEOFFSET 以 DATETIMEOFFSET(7) 数据类型返回当前日期和时间,包括时区偏移。以下查询显示了这些函数。
SELECT
GETDATE() AS [GetDate],
CURRENT_TIMESTAMP AS CurrentTimestamp,
GETUTCDATE() AS [GetUtcDate],
SYSDATETIME() AS [SysDateTime],
SYSUTCDATETIME() AS [SysUtcDateTime],
SYSDATETIMEOFFSET() AS [SysDateTimeOffset]
要获取不带时间部分的日期,只需将 DATETIME 值转换为 DATE。同样,如果您想要不带日期的时间,可以转换为 TIME。
SELECT
SYSDATETIME() AS DateAndTime,
CAST(SYSDATETIME() AS DATE) AS [Date],
CAST(SYSDATETIME() AS TIME) AS [Time]
您可能还对日期的某个部分感兴趣,例如日、月或年。您可以使用 DATEPART 函数,或者使用“快捷方式”函数 YEAR、MONTH 和 DAY。请注意,您实际上可以使用 DATEPART 提取更多内容。此外,还有一个 DATENAME 函数,其工作方式与 DATEPART 相同,但它以字符串形式返回日期的部分。DATENAME 对于返回月份名称特别有用。请注意,月份名称会根据您的会话语言进行翻译。
SELECT
DATEPART(DAY, SYSDATETIME()) AS DayFromDatePart,
DATEPART(WEEK, SYSDATETIME()) AS WeekFromDatePart,
DATEPART(MONTH, SYSDATETIME()) AS MonthFromDatePart,
DATEPART(YEAR, SYSDATETIME()) AS YearFromDatePart,
DATEPART(SECOND, SYSDATETIME()) AS SecondFromDatePart,
DATEPART(NANOSECOND, SYSDATETIME()) AS NanoSecondFromDatePart,
DAY(SYSDATETIME()) AS DayFromFunc,
MONTH(SYSDATETIME()) AS MonthFromFunc,
YEAR(SYSDATETIME()) AS YearFromFunc,
DATENAME(DAY, SYSDATETIME()) AS DayFromDateName,
DATENAME(MONTH, SYSDATETIME()) AS MonthFromDateName,
DATENAME(YEAR, SYSDATETIME()) AS YearFromDateName
有时您想为日期添加特定的时间间隔。例如,今天的订单最晚的送货日期是七天后。或者,当某件商品缺货时,可能需要一个月。要添加或减去日期,您可以使用 DATEADD 函数。在下面的示例中,我通过转换为日期来删除时间部分。
SELECT
DATEADD(DAY, -1, CAST(SYSDATETIME() AS DATE)) AS PreviousDay,
DATEADD(DAY, 1, CAST(SYSDATETIME() AS DATE)) AS NextDay,
DATEADD(WEEK, 1, CAST(SYSDATETIME() AS DATE)) AS NextWeek,
DATEADD(MONTH, 1, CAST(SYSDATETIME() AS DATE)) AS NextMonth,
DATEADD(YEAR, 1, CAST(SYSDATETIME() AS DATE)) AS NextYear
您还可以获取两个日期之间的差值。例如,我们想知道 SalesOrderHeader 表中订单的订单日期和送货日期之间的天数差。这可以通过使用 DATEDIFF 函数来实现。
SELECT
OrderDate,
ShipDate,
DATEDIFF(DAY, OrderDate, ShipDate) AS DiffBetweenOrderAndShipDate
FROM Sales.SalesOrderHeader
ORDER BY DiffBetweenOrderAndShipDate DESC
请注意,DATEDIFF 函数仅查看您想知道差值的那一部分。因此,当您想知道年份之间的差值时,该函数只查看日期的年份部分。因此,下一个查询的结果是天、月和年为 1,即使日期之间的实际差异只有一天。
SELECT
DATEDIFF(DAY, '20131231', '20140101') AS DiffInDays,
DATEDIFF(MONTH, '20131231', '20140101') AS DiffInMonths,
DATEDIFF(YEAR, '20131231', '20140101') AS DiffInYears
如前所述,我们生活在一个被划分为时区的世界。使用 SWITCHOFFSET 函数,您可以显示任何给定偏移量的日期,无论您当前处于什么时区。例如,我住在荷兰,是 UTC/GMT+1,现在我想知道夏威夷时间,它是 UTC/GMT-10,以及悉尼时间,它是 UTC/GMT+10,或者在夏令时时为 +11。不幸的是,没有简单的方法可以纠正夏令时,所以您可能需要自己弄清楚(并进行谷歌搜索)。下面的查询显示了本地时间、悉尼时间(未校正夏令时)和夏威夷时间。
SELECT
SYSDATETIMEOFFSET() AS LocalTime,
SWITCHOFFSET(SYSDATETIMEOFFSET(), '+10:00') AS SydneyTime,
SWITCHOFFSET(SYSDATETIMEOFFSET(), '-10:00') AS HawaiianTime
到目前为止,我们只用特定格式的字符串或通过调用返回当前日期的函数来构建日期。还有几个函数可以从各种日期部分构造日期值。这些函数是 DATEFROMPARTS、DATETIME2FROMPARTS、DATETIMEFROMPARTS、DATETIMEOFFSETFROMPARTS、SMALLDATETIMEFROMPARTS 和 TIMEFROMPARTS。函数名称很好地描述了它们的作用,所以我不做进一步扩展。这里有一些使用各种函数的示例。
SELECT
DATEFROMPARTS(2013, 12, 31) AS [DateFromParts],
DATETIME2FROMPARTS(2013, 12, 31, 14, 30, 0, 0, 0) AS [DateTime2FromParts],
DATETIMEOFFSETFROMPARTS(2013, 12, 31, 14, 30, 0, 0, 1, 0, 0) AS [DateTimeOffsetFromParts],
TIMEFROMPARTS(14, 30, 0, 0, 0) AS [TimeFromParts]
SQL Server 还有更多有用的函数,您可以在处理日期和时间时使用。其中一个函数是 EOMONTH,它返回一个日期,代表传递给参数的日期(时间)所在月份的最后一天。另一个是 ISDATE,它检查一个字符串是否可以转换为有效日期。您可以在 TechNet 上找到这些以及其他函数。
我最近偶然发现了一篇相当不错的 CP 文章,其中解释了 SQL Server 所有版本中关于日期、时间和函数的所有知识。推荐阅读:日期和时间数据类型和函数 - SQL Server (2000, 2005, 2008, 2008 R2, 2012)
9.4 CASE 和 IIF
9.4.1 CASE
有时您想根据另一个值返回一个值。例如,当一个位是 1 或 true 时,您想返回“Yes”,否则返回“No”。或者您只想在值不为空时包含一个值到结果中。使用 CASE,这些场景变得可能。使用 CASE,您可以测试一个列的值并根据该值返回另一个值,或者您可以包含更高级的条件来测试要显示哪个值。
让我们看一下第一个 CASE 变体,即简单形式。我们知道 Person 表中的 Person 可能有头衔 'Mr.'、'Mrs.'、'Ms.' 或 'Ms'。而不是这些值,我们想为 'Mr.' 返回 'Mister',为所有 'Ms.' 变体返回 'Miss'。如果头衔是其他值,例如 'Sr.',那么我们想显示它。
SELECT
BusinessEntityID,
CASE Title
WHEN 'Mr.' THEN 'Mister'
WHEN 'Mrs.' THEN 'Miss'
WHEN 'Ms.' THEN 'Miss'
WHEN 'Ms' THEN 'Miss'
ELSE Title
END AS Salutation,
FirstName,
LastName
FROM Person.Person
因此,简单 CASE 语句有一个输入表达式,在本例中是 Title,它与 WHEN 子句中定义的值进行比较。如果找到匹配项,则返回 THEN 子句中的值。如果找不到匹配项,则返回 ELSE 子句中的值。当值在任何 WHEN 子句中未匹配且未指定 ELSE 子句时,将返回 NULL。
CASE 表达式的另一个变体是搜索形式。使用搜索形式的 CASE 表达式,我们在 when 子句中有更大的灵活性。现在我们可以使用谓词来测试特定条件。第一个返回 true 的 WHEN 子句决定返回哪个值。下面的查询显示了如何使用搜索的 CASE 表达式,并提供了使用 CONCAT 的替代方案。
SELECT
BusinessEntityID,
CASE
WHEN Title IS NULL AND MiddleName IS NULL
THEN FirstName + ' ' + LastName
WHEN Title IS NULL AND MiddleName IS NOT NULL
THEN FirstName + ' ' + MiddleName + ' ' + LastName
WHEN Title IS NOT NULL AND MiddleName IS NULL
THEN Title + ' ' + FirstName + ' ' + LastName
ELSE Title + ' ' + FirstName + ' ' + MiddleName + ' ' + LastName
END AS FullNameAndTitle,
CONCAT(Title + ' ', FirstName, ' ', MiddleName + ' ', LastName) AS FullNameAndTitleConcat
FROM Person.Person
ORDER BY FullNameAndTitle
这是另一个无法使用其他函数编写的示例。
SELECT
SalesOrderID,
CustomerID,
SubTotal,
CASE
WHEN SubTotal < 100
THEN 'Very cheap order'
WHEN SubTotal < 1000
THEN 'Cheap order'
WHEN SubTotal < 5000
THEN 'Moderate order'
WHEN SubTotal < 10000
THEN 'Expensive order'
ELSE 'Very expensive order'
END AS OrderType
FROM Sales.SalesOrderHeader
请注意,在第二个 WHEN 子句中,我们不必检查订单是否比 100 更贵。如果第一个 WHEN 子句返回 true,则返回相应 THEN 子句中的值,并且后续的 WHEN 子句不会被评估。
9.4.2 IIF
有时您只想知道某个属性是否有值或是否为 NULL,并根据该谓词返回值。使用 CASE 表达式可能会使您的查询非常冗长,如果我们有一个快捷方式就好了。好吧,我们有了。使用 IIF,您可以测试一个谓词,如果它求值为 true,则指定一个值,如果它求值为 false,则指定另一个值。下面的示例展示了 IIF 的用法,它可以替换 CASE 表达式。
SELECT
BusinessEntityID,
CASE
WHEN Title IS NULL THEN 'No title'
ELSE Title
END AS TitleCase,
IIF(Title IS NULL, 'No title', Title) AS TitleIIF,
FirstName,
LastName
FROM Person.Person
当然,也可以使用其他类型的谓词。
SELECT
SalesOrderID,
CustomerID,
SubTotal,
IIF(SubTotal > 5000, 'Expensive order', 'Not so expensive order')
AS OrderType
FROM Sales.SalesOrderHeader
甚至可以使用以下内容。
SELECT
BusinessEntityID,
FirstName,
LastName,
IIF(EXISTS(SELECT *
FROM Sales.SalesOrderHeader AS s
JOIN Sales.Customer AS c ON c.CustomerID = s.CustomerID
WHERE c.PersonID = BusinessEntityID),
'Has orders', 'Does not have orders')
FROM Person.Person
9.5 COALESCE, ISNULL 和 NULLIF
使用 COALESCE,我们可以指定一系列值,并返回第一个非 NULL 的值。它实际上可以让我们的 IIF 检查上一节中的 NULL 变得更短。
SELECT
BusinessEntityID,
COALESCE(Title, 'No title'),
FirstName,
LastName
FROM Person.Person
可以指定更多值。
SELECT
ProductID,
Name,
ProductNumber,
COALESCE(Style, Class, ProductLine) AS Style
FROM Production.Product
当然,现在我们不知道结果代表的是样式、类别还是产品线,但您可以通过添加 CASE 表达式来解决此问题。
如果传递给 COALESCE 的所有值都是 NULL,则 COALESCE 返回 NULL。
ISNULL 的功能与 COALESCE 相同,但有一些区别。第一个区别是 ISNULL 只能有两个值。因此,如果第一个值是 NULL,它将返回第二个值(该值也可能是 NULL)。
SELECT
BusinessEntityID,
ISNULL(Title, 'No title'),
FirstName,
LastName
FROM Person.Person
您可以通过嵌套 ISNULL 来获得与 COALESCE 相同的影响。
SELECT
ProductID,
Name,
ProductNumber,
ISNULL(Style, ISNULL(Class, ProductLine)) AS Style
FROM Production.Product
那么,为什么您会选择一个而不是另一个呢?嗯,COALESCE 是一个 ANSI SQL 标准函数,因此它比 ISNULL 更具可移植性。然而,更重要的区别在于这两个函数的返回类型。COALESCE 返回的类型由返回的元素决定,而对于 ISNULL,类型由第一个元素决定。在以下查询中,ISNULL 的返回值会被截断以适应第一个元素的类型。COALESCE 则保持值不变。
DECLARE @first AS VARCHAR(4) = NULL
DECLARE @second AS VARCHAR(5) = 'Hello'
SELECT
COALESCE(@first, @second) AS [Coalesce],
ISNULL(@first, @second) AS [IsNull]
结果如下。
![]()
两者之间的另一个区别是 COALESCE 的底层类型始终是 NULLABLE,即使永远不会返回 NULL。ISNULL 会识别永远不会返回 NULL 的场景,并为底层值定义 NOT NULLABLE 属性。当您创建 VIEWS 或 STORED PROCEDURES 时,这个区别可能很重要。
虽然这不在本文的讨论范围内,但我还是想展示一下区别,以使其清晰明了。
我使用以下定义创建了一个视图。
CREATE VIEW dbo.CoalesceVsIsNull
AS
SELECT
BusinessEntityID,
COALESCE(Title, 'No title') AS TitleIsCoalesce,
ISNULL(Title, 'No title') AS TitleIsNull,
FirstName,
LastName
FROM Person.Person
这是视图的列定义。

正如您所见,TitleIsCoalesce 可以包含 NULL,即使这是不可能的。TitleIsNull 永远不会有 NULL。如果您已创建 VIEW,则可以使用以下命令将其删除。
DROP VIEW dbo.CoalesceVsIsNull
在处理 COALESCE、ISNULL 或 CASE 时,您还应该注意的一点是,每个返回值都应该具有相同的数据类型,否则可能会发生转换错误。例如,以下查询会引发错误,因为 @second 参数将被转换为 INT。
DECLARE @first AS INT = NULL
DECLARE @second AS VARCHAR(5) = 'Hello'
SELECT
ISNULL(@first, @second)
最后我想提一下函数 NULLIF。此函数接受两个参数,如果两个值不同则返回第一个值,如果两个值相等则返回 NULL。
SELECT
NULLIF(1, 1) AS Equal,
NULLIF(1, 2) AS NotEqual
10. 结论
这标志着本文的这一部分结束了,也意味着整个文章的结束。我希望您在阅读本文时有所收获,就像我在写作时一样。本文的两个部分都讨论了大量关于查询数据的内容。然而,这仅仅是 SQL Server 中可能实现的冰山一角。例如,我没有讨论的一些内容包括查询 XML 和全文数据以及优化查询。当然还有如何创建数据库、表、索引、约束、触发器,如何插入、更新和删除数据。如果您想了解更多关于这些主题的内容,我建议您阅读 2012 Microsoft SQL Server 查询 70-461 考试培训套件。我也推荐您进行实践并阅读各种来源,例如 TechNet、MSDN,当然还有 CodeProject。
我很乐意回答任何问题或评论。
祝您编码愉快!