
Apriori 算法
4.91/5 (84投票s)
C# 中 Apriori 算法的实现。

引言
在 数据挖掘中,Apriori 是一种经典的用于学习 关联规则的算法。Apriori 旨在对包含事务的数据库进行操作(例如,客户购买的物品集合,或网站访问的详细信息)。
其他算法旨在查找不包含事务的数据中的关联规则(Winepi 和 Minepi),或不包含时间戳的数据(DNA 测序)。
概述
该算法(以及数据挖掘,通常而言)的全部意义在于从大量数据中提取有用的信息。例如,客户购买键盘时也倾向于同时购买鼠标的信息是从下面的关联规则中获得的
支持度:模式为真的与任务相关的数据事务的百分比。
支持度 (键盘 -> 鼠标) = ![]()
置信度:与每个发现的模式相关的确定性或可信度度量。
置信度 (键盘 -> 鼠标) = ![]()
该算法旨在找到同时满足最小支持度阈值和最小置信度阈值的规则(强规则)。
- 项:篮子中的物品。
- 项集:在单个事务中一起购买的一组物品。
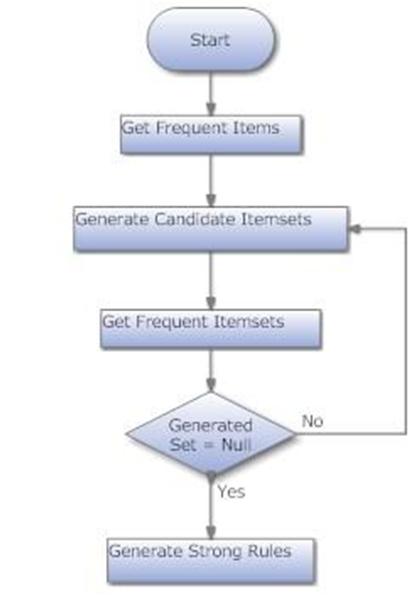
Apriori 的工作原理
- 查找所有频繁项集
- 获取频繁项
- 数据库中出现的次数大于或等于最小支持度阈值的项。
- 获取频繁项集
- 从频繁项生成候选集。
- 修剪结果以找到频繁项集。
- 从频繁项集生成强关联规则
- 满足最小支持度和最小置信度阈值的规则。
高层设计
低层设计

示例
一个数据库有五个事务。设最小支持度 = 50%,最小置信度 = 80%。

解决方案
步骤 1:查找所有频繁项集

频繁项集
{A} {B} {C} {E} {A C} {B C} {B E} {C E} {B C E}
步骤 2:从频繁项集中生成强关联规则

格点
封闭项集:所有父项的支持度不等于该项集的支持度。
最大项集:该项集的所有父项都必须是不频繁的。
请记住:


项集 {c} 是封闭的,因为父项(超集){A C}:2, {B C}:2, {C D}:1, {C E}:2 不等于 {c} 的支持度:3。
对于 {A C}、{B E} 和 {B C E} 也是如此。
项集 {A C} 是最大的,因为所有父项(超集){A B C}、{A C D}、{A C E} 都是不频繁的。
对于 {B C E} 也是如此。