
最快的哈希函数用于 C 中的表查找?!
用于通用表查找的极度优化的哈希函数
引言
本文献给那些需要最快哈希函数来处理其小键的用户。
更新 2019-10-30
系好安全带,最快的速度通过减少3条指令得到了提升……
// Dedicated to Pippip, the main character in the 'Das Totenschiff' roman, actually the B.Traven himself, his real name was Hermann Albert Otto Maksymilian Feige.
// CAUTION: Add 8 more bytes to the buffer being hashed, usually malloc(...+8) - to prevent out of boundary reads!
// Many thanks go to Yurii 'Hordi' Hordiienko, he lessened with 3 instructions the original 'Pippip', thus:
//#include <stdlib.h>
//#include <stdint.h>
#define _PADr_KAZE(x, n) ( ((x) << (n))>>(n) )
uint32_t FNV1A_Pippip_Yurii(const char *str, size_t wrdlen) {
const uint32_t PRIME = 591798841; uint32_t hash32; uint64_t hash64 = 14695981039346656037;
size_t Cycles, NDhead;
if (wrdlen > 8) {
Cycles = ((wrdlen - 1)>>4) + 1; NDhead = wrdlen - (Cycles<<3);
#pragma nounroll
for(; Cycles--; str += 8) {
hash64 = ( hash64 ^ (*(uint64_t *)(str)) ) * PRIME;
hash64 = ( hash64 ^ (*(uint64_t *)(str+NDhead)) ) * PRIME;
}
} else
hash64 = ( hash64 ^ _PADr_KAZE(*(uint64_t *)(str+0), (8-wrdlen)<<3) ) * PRIME;
hash32 = (uint32_t)(hash64 ^ (hash64>>32)); return hash32 ^ (hash32 >> 16);
} // Last update: 2019-Oct-30, 14 C lines strong, Kaze.
// https://godbolt.org/z/i40ipj x86-64 gcc 9.2 -O3
/*
FNV1A_Pippip_Yurii: FNV1A_Pippip(char const*, unsigned int):
mov rax, QWORD PTR [rdi] mov rax, QWORD PTR [rdi]
cmp rsi, 8 cmp esi, 8
jbe .L2 jbe .L2
lea rax, [rsi-1] lea ecx, [rsi-1]
shr rax, 4 xor edx, edx
lea rdx, [8+rax*8] shr ecx, 4
movabs rax, -3750763034362895579 add ecx, 1
sub rsi, rdx lea eax, [0+rcx*8]
add rdx, rdi sub esi, eax
movabs rax, -3750763034362895579
movsx rsi, esi
add rsi, rdi
.L3: .L4:
xor rax, QWORD PTR [rdi] xor rax, QWORD PTR [rdi+rdx*8]
add rdi, 8 imul rax, rax, 591798841
imul rax, rax, 591798841 xor rax, QWORD PTR [rsi+rdx*8]
xor rax, QWORD PTR [rdi-8+rsi] add rdx, 1
imul rax, rax, 591798841 imul rax, rax, 591798841
cmp rdi, rdx cmp ecx, edx
jne .L3 jg .L4
.L4: .L3:
mov rdx, rax mov rdx, rax
shr rdx, 32 shr rdx, 32
xor eax, edx xor eax, edx
mov edx, eax mov edx, eax
shr edx, 16 shr edx, 16
xor eax, edx xor eax, edx
ret ret
.L2: .L2:
movabs rdx, -3750763034362895579 movabs rdx, -3750763034362895579
mov ecx, 8 mov ecx, 8
sub ecx, esi sub ecx, esi
sal ecx, 3 sal ecx, 3
sal rax, cl sal rax, cl
shr rax, cl shr rax, cl
xor rax, rdx xor rax, rdx
imul rax, rax, 591798841 imul rax, rax, 591798841
jmp .L4 jmp .L3
*/
Yann 套件(xxHash)中的五个基准测试有两个表明这3条指令很重要!
注意:使用的是GCC 7.3.0可执行文件,在i5-7200U @3.1GHz睿频下进行测试。


让我们看看,减少上述3条指令,同时告诉Intel v19.0不要进行循环展开,在我的i5-7200U上的表现如何。
KAZE_www.byronknoll.com_cmix-v18.zip_english.dic:
44880 lines read
131072 elements in the table (17 bits)
Pippip_Yurii: 2325 [ 6822] ! Speed Brutality !
Pippip: 3046 [ 6822]
Totenschiff: 3308 [ 6818]
Yorikke: 2672 [ 6883]
wyhash: 5072 [ 6812]
FNV-1a: 4310 [ 6833]
CRC-32: 5251 [ 6891]
iSCSI CRC: 3631 [ 6785]
"KAZE_IPS_(3_million_IPs_dot_format).TXT":
2995394 lines read
8388608 elements in the table (23 bits)
Pippip_Yurii: 407608 [476410]
Pippip: 443241 [476410]
Totenschiff: 511103 [476467]
Yorikke: 530381 [506954]
wyhash: 551765 [476412]
FNV-1a: 716070 [477067]
CRC-32: 605808 [472854]
iSCSI CRC: 391876 [479542] ! Still 1st !
"KAZE_Word-list_12,561,874_wikipedia-en-html.tar.wrd":
12561874 lines read
33554432 elements in the table (25 bits)
Pippip_Yurii: 2018116 [2084750] ! Speed Brutality !
Pippip: 2148478 [2084750]
Totenschiff: 2313835 [2084381]
Yorikke: 2383182 [2099673]
wyhash: 2787755 [2081865]
FNV-1a: 3123546 [2081195]
CRC-32: 2998909 [2075088]
iSCSI CRC: 2154190 [2077725]
KAZE_www.gutenberg.org_ebooks_100.txt:
138578 lines read
524288 elements in the table (19 bits)
Pippip_Yurii: 17178 [31196] ! Speed Brutality !
Pippip: 18174 [31196]
Totenschiff: 20336 [31134]
Yorikke: 23733 [31139]
wyhash: 28118 [31260]
FNV-1a: 49246 [31178]
CRC-32: 41789 [31210]
iSCSI CRC: 22606 [31248]
KAZE_www.maximumcompression.com_english.dic:
354951 lines read
1048576 elements in the table (20 bits)
Pippip_Yurii: 41439 [53393] ! Speed Brutality !
Pippip: 44554 [53393]
Totenschiff: 48462 [53546]
Yorikke: 49988 [53782]
wyhash: 61612 [53996]
FNV-1a: 68586 [53896]
CRC-32: 65252 [54020]
iSCSI CRC: 46324 [53915]
KAZE_enwiki-20190920-pages-articles.xml.SORTED.wrd:
42206534 lines read
134217728 elements in the table (27 bits)
Pippip_Yurii: 8253384 [5996107] ! Speed Brutality !
Pippip: 8734972 [5996107]
Totenschiff: 9215109 [5996598]
Yorikke: 9271283 [6011605]
wyhash: 11241704 [5991525]
FNV-1a: 12017273 [5980248]
CRC-32: 11570725 [5843653]
iSCSI CRC: 8433784 [5803092]
事实证明,在任何大小的英文词汇列表上,没有哈希函数能够超越 **FNV1A-Pippip-Yurii** :P
三个基准测试套件
- Peter Kankowski 的 **hash.c**,使用Intel v19.0编译;
- Yann Collet 的 **xxHash-0.7.2**,使用GCC v7.3.0编译;
- Sanmayce 的 **Lookuperorama.c**,使用Intel v19.0和GCC v7.3.0编译;
**Lookuperorama.c_r7-.zip** (252,329,722 字节)
https://drive.google.com/file/d/1Uote1BFXJNwvMep13jlIfGyUAJlO1v20/view?usp=sharing
更新 2019-10-27
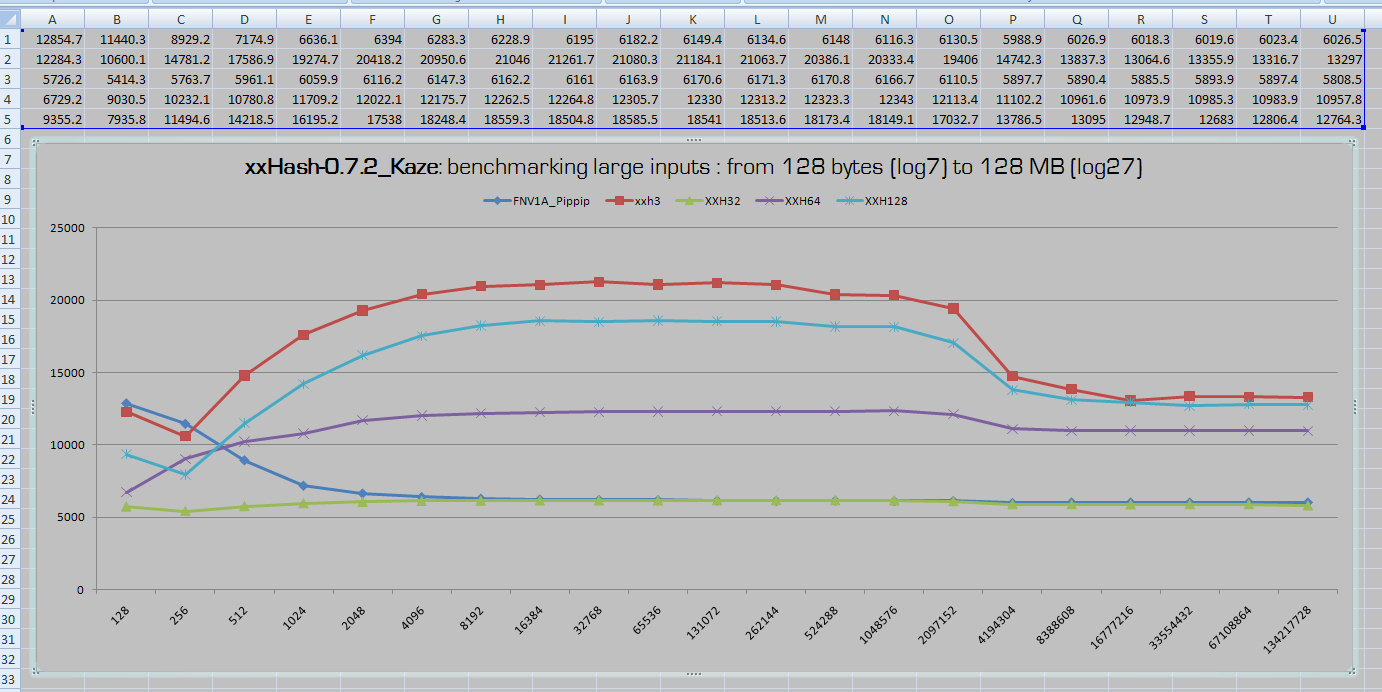
想澄清“小”这个词的含义,运行Yann的hashBench套件(来自他的github仓库),该套件目前包含5种不同的场景/基准测试。更多深入测试请看他的博客: http://fastcompression.blogspot.com/2019/03/presenting-xxh3.html
在我的笔记本电脑(i5-7200U @3.1GHz睿频)上运行结果如下:
E:\Lookuperorama.c_r6\xxHash-0.7.2_Kaze\tests\bench>main --list
available hashes :
FNV1A_Pippip, xxh3, XXH32, XXH64, XXH128
E:\Lookuperorama.c_r6\xxHash-0.7.2_Kaze\tests\bench>main --maxs=384 --minl=7
=== benchmarking 5 hash functions ===
benchmarking large inputs : from 128 bytes (log7) to 128 MB (log27)
FNV1A_Pippip, 12854.7, 11440.3, 8929.2, 7174.9, 6636.1, 6394.0,
6283.3, 6228.9, 6195.0, 6182.2, 6149.4, 6134.6, 6148.0, 6116.3,
6130.5, 5988.9, 6026.9, 6018.3, 6019.6, 6023.4, 6026.5
xxh3 , 12284.3, 10600.1, 14781.2, 17586.9, 19274.7, 20418.2,
20950.6, 21046.0, 21261.7, 21080.3, 21184.1, 21063.7, 20386.1,
20333.4, 19406.0, 14742.3, 13837.3, 13064.6, 13355.9, 13316.7, 13297.0
XXH32 , 5726.2, 5414.3, 5763.7, 5961.1, 6059.9, 6116.2,
6147.3, 6162.2, 6161.0, 6163.9, 6170.6, 6171.3, 6170.8,
6166.7, 6110.5, 5897.7, 5890.4, 5885.5, 5893.9, 5897.4, 5808.5
XXH64 , 6729.2, 9030.5, 10232.1, 10780.8, 11709.2, 12022.1,
12175.7, 12262.5, 12264.8, 12305.7, 12330.0, 12313.2, 12323.3, 12343.0,
12113.4, 11102.2, 10961.6, 10973.9, 10985.3, 10983.9, 10957.8
XXH128 , 9355.2, 7935.8, 11494.6, 14218.5, 16195.2, 17538.0,
18248.4, 18559.3, 18504.8, 18585.5, 18541.0, 18513.6, 18173.4,
18149.1, 17032.7, 13786.5, 13095.0, 12948.7, 12683.0, 12806.4, 12764.3
...
我希望“Pippip”能一直保持优势,直到280字节长的键。是的,推特上的最大长度。碰巧,XXH3的强大统治力大约在这个标记处开始。
更新 2019-10-26
是时候追求最快的速度了!
在调整我的匹配查找器时,我发现旧的哈希函数中还有很多未被利用的想法,利用起来。
首先,在 https://www.strchr.com/hash_functions 上的Peter Kankowski的哈希套件(一个非常精确的微基准测试)的控制台运行结果,它显示了Pippip在哈希互联网上最强大的压缩器 CMIX 的字典时具有优势。

最后一列(方括号中)显示了冲突数,冲突数之前的数字是最高时间。
如果你碰巧需要哈希英文单词(约1200万个不同词)或莎士比亚的诗句,“Pippip”会让你惊叹。
KAZE_www.byronknoll.com_cmix-v18.zip_english.dic:
44880 lines read
131072 elements in the table (17 bits)
Pippip: 2463 [ 6822] ! Screaming speed !
Totenschiff: 2619 [ 6818]
Yorikke: 2674 [ 6883]
wyhash: 4371 [ 6812]
YoshimitsuTRIAD: 4035 [ 7006]
FNV-1a: 4283 [ 6833]
Larson: 4297 [ 6830]
CRC-32: 4342 [ 6891]
Murmur2: 4393 [ 6820]
Murmur3: 4320 [ 6874]
XXHfast32: 4573 [ 6812]
XXHstrong32: 4660 [ 6819]
iSCSI CRC: 3600 [ 6785]
"KAZE_Word-list_12,561,874_wikipedia-en-html.tar.wrd":
12561874 lines read
33554432 elements in the table (25 bits)
Pippip: 2143388 [2084750] ! iSCSI CRC in the mirror,
are you kidding me, what a beautiful brutality !
Totenschiff: 2300133 [2084381]
Yorikke: 2367380 [2099673]
wyhash: 2790935 [2081865]
YoshimitsuTRIAD: 2517971 [2084931]
FNV-1a: 3119297 [2081195]
Larson: 3017590 [2080111]
CRC-32: 2976146 [2075088]
Murmur2: 2858856 [2081476]
Murmur3: 2864098 [2082084]
XXHfast32: 3084063 [2084164]
XXHstrong32: 3191575 [2084514]
iSCSI CRC: 2155141 [2077725]
KAZE_www.gutenberg.org_ebooks_100.txt:
138578 lines read
524288 elements in the table (19 bits)
Pippip: 18195 [31196] ! Commentless I am !
Totenschiff: 20313 [31134]
Yorikke: 23758 [31139]
wyhash: 28252 [31260]
YoshimitsuTRIAD: 27014 [31316]
FNV-1a: 49282 [31178]
Larson: 48770 [31406]
CRC-32: 41691 [31210]
Murmur2: 31558 [31203]
Murmur3: 31336 [31308]
XXHfast32: 24637 [31146]
XXHstrong32: 27266 [31118]
iSCSI CRC: 22487 [31248]
KAZE_www.maximumcompression.com_english.dic:
354951 lines read
1048576 elements in the table (20 bits)
Pippip: 44669 [53393] ! Fastest on all major English words,
a tear is falling !
Totenschiff: 48633 [53546]
Yorikke: 49951 [53782]
wyhash: 61668 [53996]
YoshimitsuTRIAD: 54825 [53658]
FNV-1a: 68106 [53896]
Larson: 67358 [54076]
CRC-32: 64756 [54020]
Murmur2: 62863 [53857]
Murmur3: 62782 [53983]
XXHfast32: 68146 [53411]
XXHstrong32: 70334 [53391]
iSCSI CRC: 46122 [53915]
总之,我所有的基准测试经验都导向了为微小键(1..64字节长)编写最快的哈希函数 - `FNV1A-Pippip`。让我们看看数字说明什么,在这次较量中,其他参赛者是:
- Wang 的 `WYHASH` - 根据`SMHASHER`,目前速度方面的头号选手。
- Yann 的 `XXH`(来自最新的v0.7.2)系列 - 根据`SMHASHER`,位居前列。
- SSE4.2 iSCSI `CRC32`
SHA3-224
硬件CRC32曾经是长期以来的佼佼者,但现在不再是了。现在,超级怪物“Pippip”已经取代了它。有关更多通用的基准测试,请参阅 **IDZ** Intel Developer Zone论坛(下面有链接)。
我写了 *Lookuperorama.c* - 第一个用于哈希表查找的合成和真实世界基准测试。当前版本6已作为 *.ZIP* 附加在顶部。
*.C* 源代码以及如何在GCC和ICC下编译它
_MakeEXE_Lookuperorama_GCC.bat
gcc -O3 -msse4.1 -fomit-frame-pointer Lookuperorama.c
-o Lookuperorama_GCC-7.3.0_WY_64bit.exe -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -DHashInBITS=24 -DHashChunkSizeInBITS=24
-DRAMpoolInKB=5120 -DBtreeHEURISTIC -D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_WY
gcc -O3 -msse4.1 -fomit-frame-pointer Lookuperorama.c
-o Lookuperorama_GCC-7.3.0_Pippip_64bit.exe -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -DHashInBITS=24 -DHashChunkSizeInBITS=24
-DRAMpoolInKB=5120 -DBtreeHEURISTIC -D_WIN32_ENVIRONMENT_
-DLongestLineInclusive=64 -D_N_Pippip
gcc -O3 -msse4.1 -fomit-frame-pointer Lookuperorama.c xxhash.c
-o Lookuperorama_GCC-7.3.0_XXH64_64bit.exe -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -DHashInBITS=24 -DHashChunkSizeInBITS=24
-DRAMpoolInKB=5120 -DBtreeHEURISTIC -D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_XXH64
gcc -O3 -msse4.1 -fomit-frame-pointer Lookuperorama.c xxhash.c
-o Lookuperorama_GCC-7.3.0_XXH3_64bit.exe -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -DHashInBITS=24 -DHashChunkSizeInBITS=24
-DRAMpoolInKB=5120 -DBtreeHEURISTIC -D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_XXH3
gcc -O3 -msse4.1 -fomit-frame-pointer Lookuperorama.c
-o Lookuperorama_GCC-7.3.0_CRC32C_64bit.exe -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -DHashInBITS=24 -DHashChunkSizeInBITS=24
-DRAMpoolInKB=5120 -DBtreeHEURISTIC -D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_CRC32C
gcc -O3 -msse4.1 -fomit-frame-pointer Lookuperorama.c
-o Lookuperorama_GCC-7.3.0_SHA3_64bit.exe -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -DHashInBITS=24 -DHashChunkSizeInBITS=24
-DRAMpoolInKB=5120 -DBtreeHEURISTIC -D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_SHA3
_MakeEXE_Lookuperorama_ICL.bat
icl /TP /O3 /arch:SSE4.1 Lookuperorama.c -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -D_icl_mumbo_jumbo_ /FAcs -DHashInBITS=24
-DHashChunkSizeInBITS=24 -DRAMpoolInKB=5120 -DBtreeHEURISTIC
-D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_WY
copy Lookuperorama.exe Lookuperorama_ICC-v19.0_WY_64bit.exe /y
icl /TP /O3 /arch:SSE4.1 Lookuperorama.c -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -D_icl_mumbo_jumbo_ /FAcs -DHashInBITS=24
-DHashChunkSizeInBITS=24 -DRAMpoolInKB=5120 -DBtreeHEURISTIC
-D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_Pippip
copy Lookuperorama.exe Lookuperorama_ICC-v19.0_Pippip_64bit.exe /y
icl /TP /O3 /arch:SSE4.1 Lookuperorama.c xxhash.c -D_N_XMM
-D_N_prefetch_4096 -D_N_alone -D_N_HIGH_PRIORITY -D_icl_mumbo_jumbo_ /FAcs
-DHashInBITS=24 -DHashChunkSizeInBITS=24 -DRAMpoolInKB=5120
-DBtreeHEURISTIC -D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_XXH64
copy Lookuperorama.exe Lookuperorama_ICC-v19.0_XXH64_64bit.exe /y
icl /TP /O3 /arch:SSE4.1 Lookuperorama.c xxhash.c -D_N_XMM
-D_N_prefetch_4096 -D_N_alone -D_N_HIGH_PRIORITY -D_icl_mumbo_jumbo_ /FAcs
-DHashInBITS=24 -DHashChunkSizeInBITS=24 -DRAMpoolInKB=5120 -DBtreeHEURISTIC
-D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_XXH3
copy Lookuperorama.exe Lookuperorama_ICC-v19.0_XXH3_64bit.exe /y
icl /TP /O3 /arch:SSE4.1 Lookuperorama.c -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -D_icl_mumbo_jumbo_ /FAcs -DHashInBITS=24
-DHashChunkSizeInBITS=24 -DRAMpoolInKB=5120 -DBtreeHEURISTIC
-D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_CRC32C
copy Lookuperorama.exe Lookuperorama_ICC-v19.0_CRC32C_64bit.exe /y
icl /TP /O3 /arch:SSE4.1 Lookuperorama.c -D_N_XMM -D_N_prefetch_4096
-D_N_alone -D_N_HIGH_PRIORITY -D_icl_mumbo_jumbo_ /FAcs -DHashInBITS=24
-DHashChunkSizeInBITS=24 -DRAMpoolInKB=5120 -DBtreeHEURISTIC
-D_WIN32_ENVIRONMENT_ -DLongestLineInclusive=64 -D_N_SHA3
copy Lookuperorama.exe Lookuperorama_ICC-v19.0_SHA3_64bit.exe /y
有趣的是,我尝试了最新的Intel v19.0编译器和GCC 7.3.0。GCC团队选择不进行循环展开被证明更优,因为测试是针对短键的。ICC决定进行循环展开,请自行尝试并查看结果。
对于“1001夜”(15,583,440字节)和10个24位哈希表,使用ICC v19.0,i7-3630QM,Windows 10。
Hasher | Collisions | Synthetic/Taxed Hashing Speed for ALL keys |
----------------------------------------------------------------------------------
SSE4.2 iSCSI CRC32 | 23,737,621 | 208,334,772 KEYS-PER-SECOND / 5,565,507 Keys/s |
SHA3-224 | 23,737,389 | 104,465 KEYS-PER-SECOND / 102,052 Keys/s |
----------------------------------------------------------------------------------
对于“1001夜”(15,583,440字节)和10个24位哈希表,使用GCC 7.3.0,i7-3630QM,Windows 10。
Hasher | Collisions | Synthetic/Taxed Hashing Speed for ALL keys |
----------------------------------------------------------------------------------
FNV1A-Pippip | 23,738,813 | 269,144,006 KEYS-PER-SECOND / 5,026,910 Keys/s |
WYHASH | 23,738,215 | 134,688,314 KEYS-PER-SECOND / 5,026,910 Keys/s |
XXH64 | 23,737,218 | 115,861,992 KEYS-PER-SECOND / 4,869,819 Keys/s |
XXH3 | 23,735,377 | 174,702,219 KEYS-PER-SECOND / 5,026,910 Keys/s |
----------------------------------------------------------------------------------
**注意1**:冲突是所有10个哈希表的累积值。
**注意2**:“Taxed”(征税)意味着它被大量随机/未缓存的RAM访问所污染。
这是“Pippip”的控制台输出的样子。
F:\Lookuperorama.c_r6>Lookuperorama_GCC-7.3.0_Pippip_64bit.exe
"Arabian_Nights_complete.html" x 24 7500 i
Current priority class is REALTIME_PRIORITY_CLASS.
Allocating Source-Buffer 14 MB ...
Allocating Source-Buffer 14 MB (REVERSED) ...
Allocating Target-Buffer 46 MB ...
Allocating Verification-Buffer 14 MB ...
Leprechaun: Memory pool for B-tress is 7,500 MB.
Leprechaun: In this revision 128MB 10-way hash is used which results in
10 x 16,777,216 internal B-Trees of order 3.
Leprechaun: In this revision, 1 pass is to be executed.
Leprechaun: Allocating HASH memory 1,342,177,345 bytes ... OK
Leprechaun: Allocating memory for B-tress 7501 MB ... OK
Leprechaun: Size of input file: 15,583,440
RAW Hashing Speed for key 15,583,440 bytes long = 6,600,355,781 6,
691,043,366 6,688,171,673 6,691,043,366 6,691,043,366 | 6,691,043,366 BYTES-PER-SECOND
RAW Hashing Speed for keys 04 bytes long = 916,672,764 KEYS-PER-SECOND; all in 17 clocks
RAW Hashing Speed for keys 06 bytes long = 916,672,647 KEYS-PER-SECOND; all in 17 clocks
RAW Hashing Speed for keys 08 bytes long = 973,964,562 KEYS-PER-SECOND; all in 16 clocks
RAW Hashing Speed for keys 10 bytes long = 486,982,218 KEYS-PER-SECOND; all in 32 clocks
RAW Hashing Speed for keys 12 bytes long = 486,982,156 KEYS-PER-SECOND; all in 32 clocks
RAW Hashing Speed for keys 14 bytes long = 486,982,093 KEYS-PER-SECOND; all in 32 clocks
RAW Hashing Speed for keys 16 bytes long = 486,982,031 KEYS-PER-SECOND; all in 32 clocks
RAW Hashing Speed for keys 18 bytes long = 324,654,645 KEYS-PER-SECOND; all in 48 clocks
RAW Hashing Speed for keys 36 bytes long = 247,355,634 KEYS-PER-SECOND; all in 63 clocks
RAW Hashing Speed for keys 64 bytes long = 197,257,936 KEYS-PER-SECOND; all in 79 clocks
The hash scanner - hashing in one pass all orders - TESTING CUMULATIVE PERFORMANCE...
RAW Hashing Speed for keys 4,6,8,10,12,14,16,18,36,64 bytes long = 269,
144,006 KEYS-PER-SECOND; all in 579 clocks
Leprechaun: Inserting keys/BBs of order 004 into B-trees, free RAM in B-tree pool is
00,007,500 MB; Pass #001 of 1 ... DONE; 00,000,185,110 B-trees have been rooted so far;
HashtableS_Utilization = 000%; Keys/s = 012,456,784
Leprechaun: Inserting keys/BBs of order 006 into B-trees, free RAM in B-tree pool is
00,007,491 MB; Pass #001 of 1 ... DONE; 00,001,330,364 B-trees have been rooted so far;
HashtableS_Utilization = 000%; Keys/s = 007,495,639
Leprechaun: Inserting keys/BBs of order 008 into B-trees, free RAM in B-tree pool is
00,007,432 MB; Pass #001 of 1 ... DONE; 00,004,317,931 B-trees have been rooted so far;
HashtableS_Utilization = 002%; Keys/s = 006,734,413
Leprechaun: Inserting keys/BBs of order 010 into B-trees, free RAM in B-tree pool is
00,007,264 MB; Pass #001 of 1 ... DONE; 00,009,402,389 B-trees have been rooted so far;
HashtableS_Utilization = 005%; Keys/s = 005,631,886
Leprechaun: Inserting keys/BBs of order 012 into B-trees, free RAM in B-tree pool is
00,006,952 MB; Pass #001 of 1 ... DONE; 00,016,178,252 B-trees have been rooted so far;
HashtableS_Utilization = 009%; Keys/s = 005,246,945
Leprechaun: Inserting keys/BBs of order 014 into B-trees, free RAM in B-tree pool is
00,006,492 MB; Pass #001 of 1 ... DONE; 00,024,085,199 B-trees have been rooted so far;
HashtableS_Utilization = 014%; Keys/s = 004,911,259
Leprechaun: Inserting keys/BBs of order 016 into B-trees, free RAM in B-tree pool is
00,005,903 MB; Pass #001 of 1 ... DONE; 00,032,694,767 B-trees have been rooted so far;
HashtableS_Utilization = 019%; Keys/s = 005,246,944
Leprechaun: Inserting keys/BBs of order 018 into B-trees, free RAM in B-tree pool is
00,005,208 MB; Pass #001 of 1 ... DONE; 00,041,744,572 B-trees have been rooted so far;
HashtableS_Utilization = 024%; Keys/s = 004,594,169
Leprechaun: Inserting keys/BBs of order 036 into B-trees, free RAM in B-tree pool is
00,004,424 MB; Pass #001 of 1 ... DONE; 00,051,646,708 B-trees have been rooted so far;
HashtableS_Utilization = 030%; Keys/s = 004,003,958
Leprechaun: Inserting keys/BBs of order 064 into B-trees, free RAM in B-tree pool is
00,003,120 MB; Pass #001 of 1 ... DONE; 00,061,668,508 B-trees have been rooted so far;
HashtableS_Utilization = 036%; Keys/s = 003,598,932
Leprechaun: (Total Hashing Speed) plus Searches-n-Inserts Per Second: 5,026,910 SNIPS
Number Of Bits (Slots=1<<Bits): 24
Number Of Hash Collisions(Distinct WORDs - Number Of Trees): 23,738,813
Number Of Trees(GREATER THE BETTER): 61,668,508
Number Of LEAFs(littler THE BETTER) not counting ROOT LEAFs: 8,688,301
Highest Tree not counting ROOT Level i.e. CORONA levels(littler THE BETTER): 2
“Pippip”被基准测试的一些链接
- https://github.com/rurban/smhasher/issues/73#issuecomment-543378852
- https://github.com/Cyan4973/xxHash/issues/275#issuecomment-546071295
- https://software.intel.com/en-us/forums/intel-moderncode-for-parallel-architectures/topic/824947#comment-1946707
以及 *.C* 和 *.ASM* 源代码
// Dedicated to Pippip, the main character in the 'Das Totenschiff' roman,
// actually the B.Traven himself, his real name was Hermann Albert Otto Maksymilian Feige.
// CAUTION: Add 8 more bytes to the buffer being hashed,
// usually malloc(...+8) - to prevent out of boundary reads!
// #include <stdint.h> // uint8_t needed
#define _PADr_KAZE(x, n) ( ((x) << (n))>>(n) )
uint32_t FNV1A_Pippip(const char *str, uint32_t wrdlen) {
const uint32_t PRIME = 591798841; uint32_t hash32;
uint64_t hash64 = 14695981039346656037; const char *p = str;
int i, Cycles, NDhead;
if (wrdlen > 8) {
Cycles = ((wrdlen - 1)>>4) + 1; NDhead = wrdlen - (Cycles<<3);
for(i=0; i<Cycles; i++) {
hash64 = ( hash64 ^ (*(uint64_t *)(p)) ) * PRIME;
hash64 = ( hash64 ^ (*(uint64_t *)(p+NDhead)) ) * PRIME;
p += 8;
}
} else
hash64 = ( hash64 ^ _PADr_KAZE(*(uint64_t *)(p+0), (8-wrdlen)<<3) ) * PRIME;
hash32 = (uint32_t)(hash64 ^ (hash64>>32)); return hash32 ^ (hash32 >> 16);
} // Last update: 2019-Oct-18, 15 C lines strong, Kaze.
// https://gcc.godbolt.org/z/gvfK8b x86-64 gcc 9.2 -O3
/*
FNV1A_Pippip(char const*, unsigned int):
mov rax, QWORD PTR [rdi]
cmp esi, 8
jbe .L2
lea ecx, [rsi-1]
xor edx, edx
shr ecx, 4
add ecx, 1
lea eax, [0+rcx*8]
sub esi, eax
movabs rax, -3750763034362895579
movsx rsi, esi
add rsi, rdi
.L4:
xor rax, QWORD PTR [rdi+rdx*8]
imul rax, rax, 591798841
xor rax, QWORD PTR [rsi+rdx*8]
add rdx, 1
imul rax, rax, 591798841
cmp ecx, edx
jg .L4
.L3:
mov rdx, rax
shr rdx, 32
xor eax, edx
mov edx, eax
shr edx, 16
xor eax, edx
ret
.L2:
movabs rdx, -3750763034362895579
mov ecx, 8
sub ecx, esi
sal ecx, 3
sal rax, cl
shr rax, cl
xor rax, rdx
imul rax, rax, 591798841
jmp .L3
*/
// And some visualization:
/*
kl= 9..16 Cycles= (kl-1)/16+1=1; MARGINAL CASES:
2nd head starts at 9-1*8=1 or:
012345678
Head1: [Q-WORD]
Head2: [Q-WORD]
2nd head starts at 16-1*8=8 or:
0123456789012345
Head1: [Q-WORD]
Head2: [Q-WORD]
kl=17..24 Cycles= (kl-1)/16+1=2; MARGINAL CASES:
2nd head starts at 17-2*8=1 or:
01234567890123456
Head1: [Q-WORD][Q-WORD]
Head2: [Q-WORD][Q-WORD]
2nd head starts at 24-2*8=8 or:
012345678901234567890123
Head1: [Q-WORD][Q-WORD]
Head2: [Q-WORD][Q-WORD]
kl=25..32 Cycles= (kl-1)/16+1=2; MARGINAL CASES:
2nd head starts at 25-2*8=9 or:
0123456789012345678901234
Head1: [Q-WORD][Q-WORD]
Head2: [Q-WORD][Q-WORD]
2nd head starts at 32-2*8=16 or:
01234567890123456789012345678901
Head1: [Q-WORD][Q-WORD]
Head2: [Q-WORD][Q-WORD]
kl=33..40 Cycles= (kl-1)/16+1=3; MARGINAL CASES:
2nd head starts at 33-3*8=9 or:
012345678901234567890123456789012
Head1: [Q-WORD][Q-WORD][Q-WORD]
Head2: [Q-WORD][Q-WORD][Q-WORD]
2nd head starts at 40-3*8=16 or:
0123456789012345678901234567890123456789
Head1: [Q-WORD][Q-WORD][Q-WORD]
Head2: [Q-WORD][Q-WORD][Q-WORD]
kl=41..48 Cycles= (kl-1)/16+1=3; MARGINAL CASES:
2nd head starts at 41-3*8=17 or:
01234567890123456789012345678901234567890
Head1: [Q-WORD][Q-WORD][Q-WORD]
Head2: [Q-WORD][Q-WORD][Q-WORD]
2nd head starts at 48-3*8=24 or:
012345678901234567890123456789012345678901234567
Head1: [Q-WORD][Q-WORD][Q-WORD]
Head2: [Q-WORD][Q-WORD][Q-WORD]
*/
如果“Pippip”被另一个函数超越,请在评论区告诉我。
Enfun!
2019-10-26更新结束
这个坏小子是谁?
`FNV1A_YoshimitsuTRIAD` - 一个C语言的练习曲,在i7-4770K上以14GB/s的速度哈希了一个256字节块。
此外,在PowerPC 440和Cortex-A8处理器上,“Luckylight”(日语含义)的光芒简单地盖过了我所知道的一切。
长话短说,我将最需要的范围(7..255字节长的键)进行哈希的经验是,“YoshimitsuTRIAD”的性能惊人,它以惊人的速度吞噬着键。
直到最近,我才看到Haswell的表现。如果XMM寄存器可用,`FNV1A_YoshimitsuTRIADiiXMM` 值得特别关注。这个“YoshimitsuTRIAD”的96字节步长变种以18GB/s的速度哈希了256字节块,太棒了。
在我看来,“YoshimitsuTRIAD”是处理英文短语/句子哈希的首选武器,这是一个非常重要的领域。
首先,我感谢Fantasy(迪拜)、Mr.Eiht(德国)、m^2(波兰)和Harold(荷兰)。
他们帮助了我,我还没有报答,所以通过分享我最好的哈希表查找练习曲的最终版本,我希望让他们高兴。
或者,正如一位(充满个性的)令人难忘的角色在俄罗斯/格鲁吉亚/亚美尼亚经典电影《MIMINO》中所说:
“当他感到高兴时,我也会感到高兴。当我高兴时,我会以一种让你也感到高兴的方式来传递。”
下面是使用Intel 12.1编译器(使用/Ox)运行32位代码的结果。
Harold的设备(i7-4770K, 3500MHz)上的线性速度
Allocating HASH memory 512MB ... OK
Memory pool starting address: 00F40040 ... 64 byte aligned, OK
Info1: One second seems to have 1,000 clocks.
Info2: This CPU seems to be working at 3,499 MHz.
Copying a 256MB block 1024 times i.e. 256GB READ + 256GB WRITTEN ...
memcpy(): (256MB block); 262144MB copied in 19843 clocks or 13.211MB per clock
Fetching/Hashing a 64MB block 1024 times i.e. 64GB ...
BURST_Read_4DWORDS: (64MB block); 65536MB fetched in 4009 clocks or 16.347MB per clock
BURST_Read_8DWORDSi: (64MB block); 65536MB fetched in 4009 clocks or 16.347MB per clock
FNV1A_penumbra: (64MB block); 65536MB hashed in 3121 clocks or 20.998MB per clock
FNV1A_YoshimitsuTRIADiiXMM: (64MB block); 65536MB hashed in 3198 clocks or 20.493MB per clock
FNV1A_YoshimitsuTRIADii: (64MB block); 65536MB hashed in 5288 clocks or 12.393MB per clock
FNV1A_YoshimitsuTRIAD: (64MB block); 65536MB hashed in 4430 clocks or 14.794MB per clock
FNV1A_farolito: (64MB block); 65536MB hashed in 5726 clocks or 11.445MB per clock
FNV1A_Yorikke: (64MB block); 65536MB hashed in 4929 clocks or 13.296MB per clock
FNV1A_Yoshimura: (64MB block); 65536MB hashed in 5788 clocks or 11.323MB per clock
CRC32_SlicingBy8: (64MB block); 65536MB hashed in 36083 clocks or 1.816MB per clock
Fetching/Hashing a 2MB block 32*1024 times ...
BURST_Read_4DWORDS: (2MB block); 65536MB fetched in 2761 clocks or 23.736MB per clock
BURST_Read_8DWORDSi: (2MB block); 65536MB fetched in 2433 clocks or 26.936MB per clock
FNV1A_penumbra: (2MB block); 65536MB hashed in 1591 clocks or 41.192MB per clock
FNV1A_YoshimitsuTRIADiiXMM: (2MB block); 65536MB hashed in 1716 clocks or 38.191MB per clock
FNV1A_YoshimitsuTRIADii: (2MB block); 65536MB hashed in 3853 clocks or 17.009MB per clock
FNV1A_YoshimitsuTRIAD: (2MB block); 65536MB hashed in 3713 clocks or 17.650MB per clock
FNV1A_farolito: (2MB block); 65536MB hashed in 4087 clocks or 16.035MB per clock
FNV1A_Yorikke: (2MB block); 65536MB hashed in 4462 clocks or 14.688MB per clock
FNV1A_Yoshimura: (2MB block); 65536MB hashed in 4415 clocks or 14.844MB per clock
CRC32_SlicingBy8: (2MB block); 65536MB hashed in 35864 clocks or 1.827MB per clock
Fetching/Hashing a 128KB block 512*1024 times ...
BURST_Read_4DWORDS: (128KB block); 65536MB fetched in 2684 clocks or 24.417MB per clock
BURST_Read_8DWORDSi: (128KB block); 65536MB fetched in 3104 clocks or 21.113MB per clock
FNV1A_penumbra: (128KB block); 65536MB hashed in 1529 clocks or 42.862MB per clock
FNV1A_YoshimitsuTRIADiiXMM: (128KB block); 65536MB hashed in 1763 clocks or 37.173MB per clock
FNV1A_YoshimitsuTRIADii: (128KB block); 65536MB hashed in 4180 clocks or 15.678MB per clock
FNV1A_YoshimitsuTRIAD: (128KB block); 65536MB hashed in 3729 clocks or 17.575MB per clock
FNV1A_farolito: (128KB block); 65536MB hashed in 4539 clocks or 14.438MB per clock
FNV1A_Yorikke: (128KB block); 65536MB hashed in 4462 clocks or 14.688MB per clock
FNV1A_Yoshimura: (128KB block); 65536MB hashed in 4586 clocks or 14.290MB per clock
CRC32_SlicingBy8: (128KB block); 65536MB hashed in 35974 clocks or 1.822MB per clock
Fetching/Hashing a 16KB block 4*1024*1024 times ...
BURST_Read_4DWORDS: (16KB block); 65536MB fetched in 2247 clocks or 29.166MB per clock
BURST_Read_8DWORDSi: (16KB block); 65536MB fetched in 2277 clocks or 28.782MB per clock
FNV1A_penumbra: (16KB block); 65536MB hashed in 1528 clocks or 42.890MB per clock
FNV1A_YoshimitsuTRIADiiXMM: (16KB block); 65536MB hashed in 1607 clocks or 40.782MB per clock
FNV1A_YoshimitsuTRIADii: (16KB block); 65536MB hashed in 3729 clocks or 17.575MB per clock
FNV1A_YoshimitsuTRIAD: (16KB block); 65536MB hashed in 3666 clocks or 17.877MB per clock
FNV1A_farolito: (16KB block); 65536MB hashed in 4102 clocks or 15.977MB per clock
FNV1A_Yorikke: (16KB block); 65536MB hashed in 4587 clocks or 14.287MB per clock
FNV1A_Yoshimura: (16KB block); 65536MB hashed in 4461 clocks or 14.691MB per clock
CRC32_SlicingBy8: (16KB block); 65536MB hashed in 35834 clocks or 1.829MB per clock
Fetching/Hashing a 256bytes block 256*1024*1024 times ...
BURST_Read_4DWORDS: (256bytes block); 65536MB fetched in 2698 clocks or 24.291MB per clock
BURST_Read_8DWORDSi: (256bytes block); 65536MB fetched in 3136 clocks or 20.898MB per clock
FNV1A_penumbra: (256bytes block); 65536MB hashed in 3666 clocks or 17.877MB per clock
FNV1A_YoshimitsuTRIADiiXMM: (256bytes block); 65536MB hashed in 3470 clocks or 18.886MB per clock
FNV1A_YoshimitsuTRIADii: (256bytes block); 65536MB hashed in 4840 clocks or 13.540MB per clock
FNV1A_YoshimitsuTRIAD: (256bytes block); 65536MB hashed in 4516 clocks or 14.512MB per clock
FNV1A_farolito: (256bytes block); 65536MB hashed in 5522 clocks or 11.868MB per clock
FNV1A_Yorikke: (256bytes block); 65536MB hashed in 5117 clocks or 12.808MB per clock
FNV1A_Yoshimura: (256bytes block); 65536MB hashed in 5195 clocks or 12.615MB per clock
CRC32_SlicingBy8: (256bytes block); 65536MB hashed in 36004 clocks or 1.820MB per clock
下面是使用Intel 12.1编译器(使用/Ox)运行32位代码的结果。
Fantasy的“红黑”设备(i7-3930K, 4500MHz, CPU总线: 125MHz, RAM总线: 2400MHz 四通道)上的线性速度
FNV1A_YoshimitsuTRIAD: (64MB block); 65536MB hashed in 5728 clocks or 11.441MB per clock
CRC32_SlicingBy8: (64MB block); 65536MB hashed in 37544 clocks or 1.746MB per clock
FNV1A_YoshimitsuTRIAD: (2MB block); 65536MB hashed in 4560 clocks or 14.372MB per clock
CRC32_SlicingBy8: (2MB block); 65536MB hashed in 36394 clocks or 1.801MB per clock
FNV1A_YoshimitsuTRIAD: (16KB block); 65536MB hashed in 4390 clocks or 14.928MB per clock
CRC32_SlicingBy8: (16KB block); 65536MB hashed in 36210 clocks or 1.810MB per clock
下面是使用Intel 12.1编译器(使用/Ox)运行32位代码的结果。
Mr.Eiht的“救赎”设备(i7 3930K 3.2GHz 8x4GB @1337MHz)上的线性速度
FNV1A_YoshimitsuTRIAD: (64MB block); 65536MB hashed in 7307 clocks or 8.969MB per clock
CRC32_SlicingBy8: (64MB block); 65536MB hashed in 44693 clocks or 1.466MB per clock
FNV1A_YoshimitsuTRIAD: (2MB block); 65536MB hashed in 5374 clocks or 12.195MB per clock
CRC32_SlicingBy8: (2MB block); 65536MB hashed in 43143 clocks or 1.519MB per clock
FNV1A_YoshimitsuTRIAD: (16KB block); 65536MB hashed in 5206 clocks or 12.589MB per clock
CRC32_SlicingBy8: (16KB block); 65536MB hashed in 42888 clocks or 1.528MB per clock
下面是使用Intel 12.1编译器(使用/Ox)运行32位代码的结果。
Sanmayce的“Bonboniera”笔记本电脑(Core 2 T7500, 2200MHz)上的线性速度
FNV1A_penumbra: (64MB block); 65536MB hashed in 14445 clocks or 4.581MB per clock
FNV1A_YoshimitsuTRIAD: (64MB block); 65536MB hashed in 16115 clocks or 4.087MB per clock
CRC32_SlicingBy8: (64MB block); 65536MB hashed in 71573 clocks or 0.916MB per clock
FNV1A_penumbra: (2MB block); 65536MB hashed in 6568 clocks or 10.025MB per clock
FNV1A_YoshimitsuTRIAD: (2MB block); 65536MB hashed in 9750 clocks or 6.722MB per clock
CRC32_SlicingBy8: (2MB block); 65536MB hashed in 69763 clocks or 0.940MB per clock
FNV1A_penumbra: (16KB block); 65536MB hashed in 5819 clocks or 11.293MB per clock
FNV1A_YoshimitsuTRIAD: (16KB block); 65536MB hashed in 8986 clocks or 7.294MB per clock
CRC32_SlicingBy8: (16KB block); 65536MB hashed in 69467 clocks or 0.949MB per clock
作为AMD粉丝(自从出色的“Barton”)以来,这里有“Zambezi”和“Thuban”的性能。
AMD FX-8120, 4515MHz = 21x215, L1 Data Cache: 8x16KB:
FNV1A_YoshimitsuTRIAD: (16KB block); 65536MB hashed in 5859 clocks or 11.186MB per clock
CRC32_SlicingBy8: (16KB block); 65536MB hashed in 44437 clocks or 1.475MB per clock
AMD Phenom II X6 1600T, 4000MHz = 16x250, FSB Frequency: 250MHz, L1 Data Cache: 6x64KB:
FNV1A_YoshimitsuTRIAD: (16KB block); 65536MB hashed in 5769 clocks or 11.360MB per clock
CRC32_SlicingBy8: (16KB block); 65536MB hashed in 34650 clocks or 1.891MB per clock
关于冲突性能:没有任何问题。
一段折磨测试的摘录

Purpose: to compare FNV1A_Yoshimura and CRC32 by giving the highest number of collisions,
i.e. the deepest nest/layer, the-lesser-the-better.
Keys are all BINARY strings from 0..18446744073709551615, i.e. all 64bit values at some step,
look the sample below.
1111111111111111111111111111111111111111111111111111111111111111
=
18446744073709551615
18,446,744,073,709,551,616 = 2^64
thousand
million
billion
trillion
quadrillion
quintillion
Note1: On T7500 2200MHz the full cycle took 240h with step 111,111,111:
for (QUADR = 0; QUADR <= ((unsigned long long)1<<32)*((unsigned long long)1<<32)-1;
QUADR=QUADR+3111111111) {...}
Note2: The keys look like (at step 3,111,111,111) these:
0000,0000,0000,0000,0000,0000,0000,0000,0000,0000,0000,0000,0000,0000,0000,0000
0000,0000,0000,0000,0000,0000,0000,0000,1011,1001,0110,1111,1100,1001,1100,0111 i.e. 3111111111
0000,0000,0000,0000,0000,0000,0000,0001,0111,0010,1101,1111,1001,0011,1000,1110 i.e. 6222222222
0000,0000,0000,0000,0000,0000,0000,0010,0010,1100,0100,1111,0101,1101,0101,0101
0000,0000,0000,0000,0000,0000,0000,0010,1110,0101,1011,1111,0010,0111,0001,1100
0000,0000,0000,0000,0000,0000,0000,0011,1001,1111,0010,1110,1111,0000,1110,0011
0000,0000,0000,0000,0000,0000,0000,0100,0101,1000,1001,1110,1011,1010,1010,1010
仅仅是为了好玩,我用我的分散度测试工具“TRISMUS”进行了类似的基准测试,该工具包含1万亿+个1Kb文本块的测试包(源代码在主页)。
这1,000,000,000,000个键是128字节长的骑士巡游衍生物。
D:\_KAZE>Knight-Tour_FNV1A_YoshimitsuTRIADii_vs_CRC32_TRISMUS.exe a8 4000000000
...
Polynomial used:
CRC32: 0x8F6E37A0
KEYS to be hashed = 4,000,000,000x4x64
HashSizeInBits = 27
ReportAtEvery = 134,217,727
Allocating HASH memory 512MB ... OK
Allocating HASH memory 512MB ... OK
The first KT:
A8C7E8G7H5G3H1F2H3G1E2C1A2B4A6B8D7F8H7G5F7H8G6H4G2E1C2A1B3A5B7D8C6A7C8E7G8
H6G4H2F1D2B1A3B5D6F5D4F3E5C4B2D3F4E6C5A4B6D5F6E4C3D1E3
...
FNV1A_YoshimitsuTRIADii: Keys = 0,000,134,217,729;
1 x MAXcollisionsAtSomeSlots = 0,012; FeeSlots = 50,530,128
CRC32 0x8F6E37A0, iSCSI: Keys = 0,000,134,217,729;
4 x MAXcollisionsAtSomeSlots = 0,011; FeeSlots = 49,561,215
FNV1A_YoshimitsuTRIADii: Keys = 0,000,268,435,457;
3 x MAXcollisionsAtSomeSlots = 0,015; FeeSlots = 19,089,321
CRC32 0x8F6E37A0, iSCSI: Keys = 0,000,268,435,457;
4 x MAXcollisionsAtSomeSlots = 0,014; FeeSlots = 18,307,048
FNV1A_YoshimitsuTRIADii: Keys = 0,000,402,653,185;
1 x MAXcollisionsAtSomeSlots = 0,019; FeeSlots = 07,194,504
CRC32 0x8F6E37A0, iSCSI: Keys = 0,000,402,653,185;
8 x MAXcollisionsAtSomeSlots = 0,017; FeeSlots = 06,762,415
FNV1A_YoshimitsuTRIADii: Keys = 0,000,536,870,913;
2 x MAXcollisionsAtSomeSlots = 0,021; FeeSlots = 02,708,588
CRC32 0x8F6E37A0, iSCSI: Keys = 0,000,536,870,913;
2 x MAXcollisionsAtSomeSlots = 0,020; FeeSlots = 02,496,170
FNV1A_YoshimitsuTRIADii: Keys = 0,000,671,088,641;
2 x MAXcollisionsAtSomeSlots = 0,023; FeeSlots = 01,022,485
CRC32 0x8F6E37A0, iSCSI: Keys = 0,000,671,088,641;
2 x MAXcollisionsAtSomeSlots = 0,023; FeeSlots = 00,922,884
...
FNV1A_YoshimitsuTRIADii: Keys = 1,000,056,291,329;
1 x MAXcollisionsAtSomeSlots = 7,930; FeeSlots = 00,000,000
CRC32 0x8F6E37A0, iSCSI: Keys = 1,000,056,291,329;
2 x MAXcollisionsAtSomeSlots = 7,910; FeeSlots = 00,000,000
正如你所见,理想的分散度将是1,000,056,291,329/134,217,727 = 7451 `MAXcollisionsAtSomeSlots`。YoshimitsuTRIADii 和 CRC32 都表现不错。
对于那些想尝试编写自己的哈希函数的人,我在(下载区)包含了两个简单的工具(Fury & YoYo),分别允许测试速度性能和分散度性能。
名为“~300万IP(点格式)”的冲突基准测试已包含在内。
D:\_KAZE>YoYo_r2.exe IPS.TXT 20
YoYo - [CR]LF lines hasher, r.2 copyleft Kaze.
Note1: Incoming textual file can exceed 4GB and lines can be up to 1048576 chars long.
Note2: FNV1A_YoshimitsuTRIADiiXMM needs SSE4.1, so if not present YoYo will crash.
Polynomial(s) used:
CRC32C2_8slice: 0x8F6E37A0
HashSizeInBits = 20
Allocating KEY memory 1024KB ... OK
Allocating HASH memory 4MB ... OK
Allocating HASH memory 4MB ... OK
Allocating HASH memory 4MB ... OK
Hashing all the LF ending lines encountered in 42,892,307 bytes long file ...
Keys vs Slots ratio: 2:1 or 2,995,394:1,048,576
FNV1A_YoshimitsuTRIADiiXMM : Keys = 2,995,394; 1 x MAXcollisionsAtSomeSlots = 15;
HASHfreeSLOTS = 0,059,943; HashUtilization = 094%; Collisions = 2,006,761
FNV1A_YoshimitsuTRIADii : Keys = 2,995,394; 1 x MAXcollisionsAtSomeSlots = 15;
HASHfreeSLOTS = 0,059,943; HashUtilization = 094%; Collisions = 2,006,761
CRC32C2_8slice : Keys = 2,995,394; 1 x MAXcollisionsAtSomeSlots = 15;
HASHfreeSLOTS = 0,062,064; HashUtilization = 094%; Collisions = 2,008,882
Physical Lines: 2,995,394
Shortest Line : 7
Longest Line : 15
Performance: 38126.495 bytes per clock
背景
哈哈,背景是,我记得在写“YoshimitsuTRIAD”的时候,我连续听了这首心爱的歌曲几个小时。
就这一次
让我告诉你,你是最甜蜜的
我唱的每一首歌里的爱
我耳中的音乐和一切
快乐写成白色
今晚也许不那么真实
你可能忘记的事情
以及我还没告诉你的其他事情
闭上眼睛
数到十
转过身
回来
跌倒
再来一次
我还在
这一切都是真实的
这一切都是真实的
我们不需要任何盛大的游行
就这一次,一首小夜曲
来庆祝我们这份爱
我们不需要
不需要盛大的宣传
这只是我敞开的心扉
给任何可能关心的人
离开
环游世界
和各种各样的女孩聊天
但找不到我
而你是我的
闭上眼睛
数到十
转过身
回来
跌倒
再来一次
我还在
这一切都是真实的,这一切都是真实的,你也有同感吗?
这一切都是真实的,这一切都是真实的,告诉我你也有同感吗?
/Tracey Thorn - It's All True/
函数主页: http://www.sanmayce.com/Fastest_Hash/index.html
最后两件事:不要抱怨这个坏家伙的主页太长了;第二,许可证,没有许可证,它是100%免费的。
尽情享用!
关注点
在玩乐的同时,找到过度和不足之间的实际和最有用的平衡,并充满活力。
一个人走进一家酒吧,看到一只狗坐在桌子旁和三个人打扑克。
“哇,多么聪明的狗!”他惊叹道。
“不,他不是一个好的玩家,每次拿到好牌他都会摇尾巴。”一个旁观者说。
这只狗让我想起了……我自己。
历史
- `FNV1A_Pippip` 编写于 2019-10-26
- `FNV1A_YoshimitsuTRIAD` 编写于 2012-10-29