
利用 MySQL 存储引擎和 API 构建, 使用 SQL 查询语言进行复杂分析: 第二部分
4.60/5 (3投票s)
利用 MySQL 存储引擎和 API 构建,
引言
在本系列文章的第 1 部分中,我介绍了从 API 检索数据并将其提供给 MySQL 的 MySQL 存储引擎的概念。具体来说,我需要一个最新的系统正在运行的进程列表在 MySQL 控制台上。本文在前一部分的基础上,提供了一种无需更改 MySQL 解析器即可解决此问题的方法。
ProcessInfoEngine
这个 MySQL 存储引擎与 MyISAM 和 InnoDB 等普通存储引擎不同,它从 Windows 进程相关 API 检索数据并将其提供给 MySQL。创建了一个名为 runningprocesslist ,引擎为 ProcessInfoEngine 的表。
CREATE TABLE `runningprocesslist` (
`PROCESSNAME` varchar(2048) DEFAULT NULL,
`ProcessID` int(11) DEFAULT NULL,
`Threadcount` int(11) DEFAULT NULL,
`ParentprocessID` int(11) DEFAULT NULL,
`Priorityclass` int(11) DEFAULT NULL
) ENGINE= ProcessInfoEngine
当用户在 runningprocesslist 上输入 select 查询时,控制权会转到 rnd_init 方法中的 ProcessInfoEngine 。此方法会检查表名是否确实是“RunningProcessList”。然后检查是否存在 where 子句解析树。如果存在,则遍历 where 子句解析树以将其转换为 OpenProcess 调用。否则,创建进程快照并将所有进程详细信息提供给 MySQL。
int ha_example::rnd_init(bool scan)
{
DBUG_ENTER("ha_example::rnd_init");
if(_stricmp(table_share->table_name.str,"RunningProcessList")==0)
{
THD *thd=this->ha_thd();
SELECT_LEX *select_lex=&thd->lex->select_lex;
m_processListIndex=0;
if(select_lex->where==0)
{
GetAllProcessList(m_processList);
}
else
{
stack<parsestackelement> parseStack;
select_lex->where->traverse_cond(My_Cond_traverser,(void*)&parseStack,Item::traverse_order::POSTFIX);
if(!parseStack.empty()&&parseStack.size()==1)
{
GetProcessListSpecifiedInWhereClause(m_processList,parseStack.top().setOfProcessIds);
}
else
{
GetAllProcessList(m_processList);
}
}
}
DBUG_RETURN(0);
}
在 where 子句解析树的后缀遍历过程中,会创建并维护 ParseStackElement struct 的堆栈。
struct ParseStackElement
{
set<int> setOfProcessIds;
Item *item;
};
rnd_init 调用 traverse_cond 在 where 子句解析树的根节点上,以进行后缀遍历。指定在遍历过程中调用 My_Cond_traverser 函数。将解析堆栈传递给此函数。此函数会检查以下内容:
- In 操作符:在这种情况下,会调用
Item_func_in_case来获取“in 子句”中指定的进程 ID 集并推送到堆栈。 - Equality 操作符:在这种情况下,会调用
Item_func_eq_case来获取指定的进程 ID 并将其推送到堆栈。 - And/Or 操作符:在这种情况下,会弹出堆栈直到出现项(
My_Cond_traverser的第一个参数)的子项。在弹出过程中,将进程 ID 集进行 AND 和 OR 运算以获得结果集。
void My_Cond_traverser (const Item *item, void *arg)
{
stack<ParseStackElement> *parseStack=(stack<ParseStackElement> *)arg;
set<int> setOfProcessIds;
if(dynamic_cast<const Item_func_in*>(item))
{
setOfProcessIds=Item_func_in_case(item);
ParseStackElement elem;
elem.setOfProcessIds=setOfProcessIds;
elem.item=(Item *)item;
parseStack->push(elem);
}
else if(dynamic_cast<const Item_func_eq*>(item))
{
setOfProcessIds=Item_func_eq_case(item);
ParseStackElement elem;
elem.setOfProcessIds=setOfProcessIds;
elem.item=(Item *)item;
parseStack->push(elem);
}
else if(dynamic_cast<const Item_cond*>(item))
{
const Item_cond *itemCondC=dynamic_cast<const Item_cond*>(item);
Item_cond *itemCond=(Item_cond *)itemCondC;
set<int> result;
bool isAnd=false;
if(dynamic_cast<const Item_cond_and*>(item))
{
isAnd=true;
}
if (!parseStack->empty()&&isChildOf((Item_cond*)item,parseStack->top().item))
{
result=parseStack->top().setOfProcessIds;
parseStack->pop();
}
while (!parseStack->empty()&&isChildOf((Item_cond*)item,parseStack->top().item))
{
if(isAnd)
{
result=And(result,parseStack->top().setOfProcessIds);
}
else
{
result=Or(result,parseStack->top().setOfProcessIds);
}
parseStack->pop();
}
ParseStackElement elem;
elem.setOfProcessIds=result;
elem.item=(Item *)item;
parseStack->push(elem);
}
}
以下函数提取用户在相等子句中输入的进程 ID。代码会检查项是否为 Item_func 类型。然后它会检查第一个参数是字段而第二个参数不是字段。然后它会检查该字段是否为 ProcessID。
set<int> Item_func_eq_case(const Item *item)
{
set<int> setOfProcessIds;
const Item_func * itemFunction=dynamic_cast<const Item_func*>(item);
Item **arguments=0;
if(itemFunction)
{
arguments=itemFunction->arguments();
}
else
{
return setOfProcessIds;
}
Item *field=0;
Item *value=0;
if(dynamic_cast <Item_field*>(arguments[0]))
{
field = arguments[0];
}
else
{
return setOfProcessIds;
}
if(dynamic_cast <Item_field*>(arguments[1]))
{
return setOfProcessIds;
}
else
{
value = arguments[1];
}
if(field&&field->item_name.ptr()&&_stricmp(field->item_name.ptr(),"ProcessID")==0)
{
setOfProcessIds.insert(value->val_int());
}
return setOfProcessIds;
}
以下函数提取“in 子句”中指定的进程 ID 集。首先检查项是否为 Item_func 类型。然后检查第一个参数是字段 ProcessID ,而后续参数不是字段类型。
set<int> Item_func_in_case(const Item *item)
{
set<int> setOfProcessIds;
const Item_func * itemFunction=dynamic_cast<const Item_func*>(item);
Item **arguments=0;
int inArgcount=0;
if(itemFunction)
{
arguments=itemFunction->arguments();
inArgcount=itemFunction->arg_count;
}
else
{
return setOfProcessIds;
}
Item *field=0;
Item *value=0;
if(dynamic_cast <Item_field*>(arguments[0]))
{
field = arguments[0];
}
else
{
return setOfProcessIds;
}
if(field&&field->item_name.ptr()&&_stricmp(field->item_name.ptr(),"ProcessID")==0)
{
LONG index;
for (index = 1; index < inArgcount; index++)
{
if(dynamic_cast <Item_field*>(arguments[index]))
{
continue;
}
else
{
value = arguments[index];
}
setOfProcessIds.insert(value->val_int());
}
}
return setOfProcessIds;
}
以下是 My_Cond_traverser 用于检查父子关系的辅助函数。
bool isChildOf(Item_cond *parent,Item *child)
{
List_iterator<Item> li(*(parent->argument_list()));
Item *it= NULL;
while ((it= li++))
{
if(child==it)
return true;
}
return false;
}
以下函数对进程 ID 的集合 A 和 B 进行 AND 运算。
set<int> And(set<int> setAOfProcessIds,set<int> setBOfProcessIds)
{
set<int> setOfProcessIds;
set_intersection(setAOfProcessIds.begin(),setAOfProcessIds.end(),
setBOfProcessIds.begin(),setBOfProcessIds.end(),inserter(setOfProcessIds,setOfProcessIds.end()));
return setOfProcessIds;
}
以下函数对进程 ID 的集合 A 和 B 进行 OR 运算。
set<int> Or(set<int> setAOfProcessIds,set<int> setBOfProcessIds)
{
set<int> setOfProcessIds;
set_union(setAOfProcessIds.begin(),setAOfProcessIds.end(),setBOfProcessIds.begin(),
setBOfProcessIds.end(),inserter(setOfProcessIds,setOfProcessIds.end()));
return setOfProcessIds;
}
考虑以下查询的示例:
select * from runningprocesslist where ProcessID=0x1C8C or ProcessID in (0xD6C,0x1D3C);
以下是上述查询的解析树:
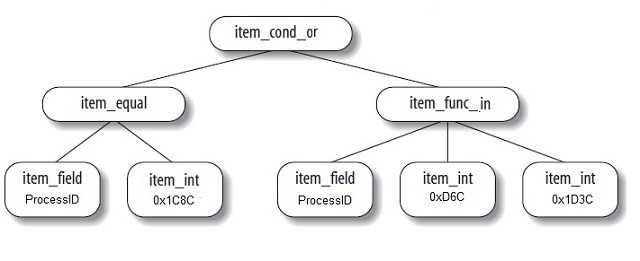
此解析树已转换为以下进程 ID 集:{0x1C8C,0xD6C,0x1D3C}
如何运行
- 请从以下链接安装 MySQL 5.6.16:
- 请确保在安装过程中选择 32 位版本。
- 从 ProcessInfoEngineBinaries.zip 复制 ha_example.dll
- 转到安装 MySQL 的目录。
- 找到子目录 lib 并打开它。
- 找到并打开里面的 plugin 目录。
- 粘贴 ha_example.dll。
- 转到 MySQL 控制台并运行以下命令。
- Install plugin
ProcessInfoEnginesoname 'ha_example.dll'; - 这将安装
ProcessInfoEngine。 - 创建一个名为 test 的数据库。
- 现在创建一个名为
runningprocesslist的表,并将ProcessInfoEngine指定为存储引擎。CREATE TABLE `runningprocesslist` ( `PROCESSNAME` varchar(2048) DEFAULT NULL, `ProcessID` int(11) DEFAULT NULL, `Threadcount` int(11) DEFAULT NULL, `ParentprocessID` int(11) DEFAULT NULL, `Priorityclass` int(11) DEFAULT NULL ) ENGINE= ProcessInfoEngine
- 输入以下查询
select * from runningprocesslist;
- 这将显示系统中运行的所有进程。
- 现在输入您选择的任何查询,然后查看结果。
在哪里获取源代码
- 从以下链接下载 MYSQL 源代码。
- 将源代码提取到 C:/mysql-5.6.16。
如何构建源代码
- 请按照以下地址提供的说明进行操作:
- 我使用 Visual Studio 2012 按照以下说明构建了源代码:
- cmake . -G "Visual Studio 11"
- 下载本文附带的名为 ProcessInfoEngineSourceCode.zip 的附件。
- 它包含
ProcessInfoEngine的源代码,位于 example 文件夹中。 - 将 example 文件夹复制到 mysql-5.6.16\storage
结论
您可能在想为什么需要解析 where 子句,为什么不直接将所有进程提供给 MySQL?但当数据量非常大时,这种方法将很有益。下一部分将在 MySQL 控制台上公开 Facebook 数据。具体来说,您将能够对您的朋友进行复杂的分析。