
AWS .NET SDK 扩展:有效使用 EMR
0/5 (0投票)
Amazon .NET API 的一个扩展,允许您将 EMR 作业的流程描述存储在文件或对象中,在本地运行和管理流程,支持出现错误时的备用流程
引言
此项目提供了一个 API,用于描述、运行和管理 Amazon Elastic Map/Reduce Service 的自定义工作流。
使用此 API,您可以
- 启动和配置新的 EMR 作业;
- 为正在运行的作业添加步骤;
- 在需要时重新运行步骤;
- 在运行时控制和更改步骤的顺序;
- 控制集群的生命周期。
此外,它允许您将作业流模板存储在 xml 文件中,类似于 oozie-workflow。此外,它还支持在运行时解析的占位符。
此解决方案是一个使用Microsoft .NET Framework 4.5编写的 .NET 程序集。它包含三个项目
- 一个 AwsEmrWorkflow.dll,公开上述 API;
- 一个 API 的单元测试项目;
- 一个 API 的演示项目。
您始终可以从我的网站 supperslonic.com 下载最新的修复版本。
要构建和运行它,您需要安装 AWS SDK for .NET。
数据模型
对于 EMR 作业流程的描述,API 提供了
- 对象模型 – 一组描述 EMR 作业的类;
- XSD 模式,用于 XML 模型。
两者都可以互换且易于扩展。对象模型可以序列化为 XML 模型,XML 模型也可以反序列化为对象模型。您还可以使用混合模型,像“乐高”一样,从不同的组件(XML 文件或对象)构建最终对象。
XML 文件中作业流程的示例
<?xml version="1.0" encoding="utf-16"?>
<jobFlow xmlns="urn:supperslonic:emrWorkflow">
<name>Job1-by-{userName}</name>
<logUri>{myBucket}/logs</logUri>
<ec2KeyName>testEC2Key</ec2KeyName>
<amiVersion>3.0.3</amiVersion>
<hadoopVersion>2.2.0</hadoopVersion>
<masterInstanceType>m1.medium</masterInstanceType>
<slaveInstanceType>m3.2xlarge</slaveInstanceType>
<instanceCount>34</instanceCount>
<config>
<hadoopConfig>
<arg>-s</arg>
<arg>mapreduce.user.classpath.first=true</arg>
</hadoopConfig>
<hBaseConfig start="true">
<jar>/home/hadoop/lib/hbase-0.94.7.jar</jar>
<arg>--site-config-file</arg>
<arg>{myBucket}/hBase/config.xml</arg>
<hBaseDaemondsConfig>
<arg>--hbase-master-opts=-Xmx6140M -XX:NewSize=64m</arg>
<arg>--regionserver-opts=-XX:MaxNewSize=64m -XX:+HeapDumpOnOutOfMemoryError</arg>
</hBaseDaemondsConfig>
</hBaseConfig>
</config>
<bootstrapActions>
<bootstrapAction>
<name>bootstrap action 1</name>
<path>{myBucket}/bootstrap/UploadLibraries.sh</path>
</bootstrapAction>
</bootstrapActions>
<steps>
<restoreHBase path="{myBucket}/hBaseRestore" />
<jarStep>
<name>step 1</name>
<jar>{myBucket}/jars/test.jar</jar>
<actionOnFailure>CANCEL_AND_WAIT</actionOnFailure>
<mainClass>com.supperslonic.emr.Step1Driver</mainClass>
<arg>true</arg>
<arg>12.34</arg>
</jarStep>
<backupHBase path="{myBucket}/hBaseBackup" />
<jarStep>
<name>step 2</name>
<jar>{myBucket}/jars/test2.jar</jar>
</jarStep>
</steps>
</jobFlow>
模型包含以下部分
作业流描述,您可以在其中设置作业名称、日志位置、实例类型、标签等。
配置描述,您可以在其中配置 Hadoop、HBase 和调试设置。支持以下配置
- Hadoop 配置;
- HBase 配置;
- HBase 守护进程配置;
- 调试配置。
引导操作,您可以在其中指定任意数量的自定义引导操作。
Jar 步骤,您可以在其中指定任意数量的步骤。支持以下类型
- 自定义 Jar 步骤;
- 恢复 HBase 步骤;
- 备份 HBase 步骤;
占位符
模型还支持任何自定义占位符,这些占位符在运行时解析。要做到这一点,用户必须通过填充用于构建任何 EMR 服务请求的构建阶段的 BuilderSettings 类实例来定义占位符替换。
有两个保留设置
- jobFlowId – 用于标识当前作业。在作业启动期间自动填充,或由用户手动填充。
- hBaseJarPath – 用于指定当前 HBase 版本。从 HBase 配置信息自动填充,或由用户手动填充。
API 结构
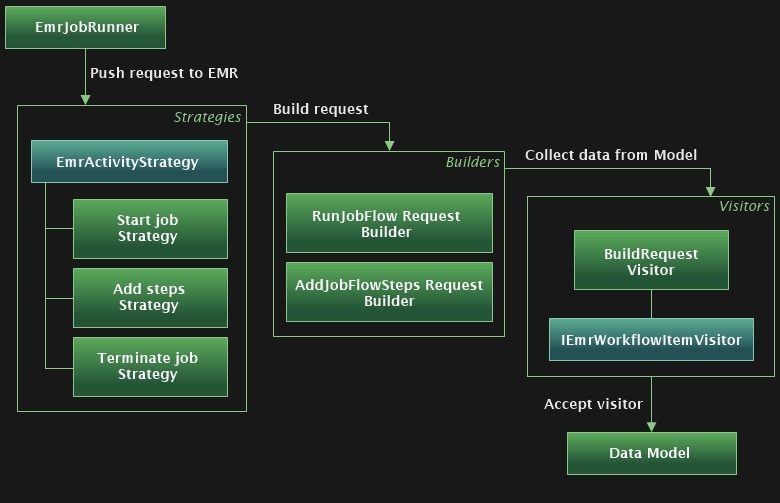
Runner – 操作用户提供的策略列表,并验证作业的当前状态。
Strategy – 向 Amazon EMR 服务发送特定请求。
Builder – 根据提供的对象模型构建特定于 Amazon EMR 服务的请求。
Visitor – EMR 数据模型与 API 数据模型之间的主要抽象层。Visitor 将特定请求的构建算法与 API 的对象模型结构分离。
序列化实现
所有序列化支持都实现在基类 EmrWorkflowItemBase 中,该类公开了一些虚拟方法,用于根据特定对象的需要进行具体实现。
还有几个 XML 工厂可以序列化/反序列化对象集合
StepsXmlFactory;ConfigsXmlFactory;BootstrapActionsXmlFactory;TagsXmlFactory.
Visitor 实现
选择了访问者设计模式来处理 API 的数据模型结构。这允许将任何处理算法与对象的结构完全解耦,并允许在需要时轻松扩展。Visitor 实现了一个 IEmrWorkflowItemVisitor 接口,该接口被 API 数据模型中的每个对象接受。
BuildRequestVisitor 类是 IEmrWorkflowItemVisitor 接口的具体实现,它根据访问的数据创建 EMR 服务请求的各个部分。它与请求构建过程完全解耦。它只是通过引发特定事件来通知观察者,某个请求部分已被创建。
支持以下事件
- OnRunJobFlowRequestCreated;
- OnJobFlowInstancesConfigCreated;
- OnTagCreated;
- OnBootstrapActionConfigCreated;
- OnStepConfigCreated。
BuildRequestVisitor 类还负责在创建 EMR 服务请求时进行占位符替换。
Builder 实现
Builder 负责构建最终的 EMR 服务请求。在内部,它使用访问者来访问提供的对象的结构。它订阅了访问者的事件来构建最终的 EMR 服务请求。
API 包含两个 Builder
RunJobFlowRequestBuilder– 根据JobFlow类实例构建启动和配置 EMR 作业的请求;AddJobFlowStepsRequestBuilder– 根据StepBase类实例列表构建向正在运行的作业添加新步骤的请求。
Strategy 实现
使用策略设计模式向 EMR 服务发送不同类型的请求。EmrActivityStrategy 策略隐藏了构建和发送特定 EMR 请求的算法。
这种方法允许将作业流分解为逻辑部分(活动),从而让您对作业流的顺序及其行为进行更多控制。无论使用哪种类型的活动,它们都被统一对待并且可以互换。因此,用户可以更专注于工作流的设计部分,而不是其实现。
public class StartJobStrategy : EmrActivityStrategy
{
private JobFlow jobFlow;
public StartJobStrategy(string name, JobFlow jobFlow)
: base(name)
{
this.jobFlow = jobFlow;
}
public override async Task<bool> PushAsync(EmrJobRunner emrJobRunner)
{
RunJobFlowRequestBuilder builder = new RunJobFlowRequestBuilder(emrJobRunner.Settings);
RunJobFlowRequest request = builder.Build(this.jobFlow);
RunJobFlowResponse response = await emrJobRunner.EmrClient.RunJobFlowAsync(request);
if (!this.IsOk(response))
return false;
emrJobRunner.JobFlowId = response.JobFlowId;
return true;
}
}
在每个 EmrActivityStrategy 内部,所有请求都使用基于任务的异步模式发送。这允许线程不被阻塞,并立即返回到线程池以获取新的待处理工作。要了解更多关于基于任务的异步模式的信息,请参阅 MSDN 上的基于任务的异步模式 (TAP)。
Runner 实现
EmrJobRunner 类负责协调 EMR 活动并检查作业的状态。
它使用抽象类 EmrActivitiesEnumerator 来遍历活动列表。用户应实现此类的两个方法
- GetNormalFlow – 方法返回一个在正常流程中执行的活动列表;
- GetFailedFlow – 方法是可选的。返回在发生错误时执行的备用活动列表。
活动列表可以是预定义的活动序列,也可以是选择下一个活动的任何复杂逻辑。当 EmrJobRunner 通知迭代器发生了错误时,会自动切换到失败流程,但用户仍需决定如何处理:运行备用活动序列,还是停止迭代并终止作业。
public class DemoEmrActivitiesEnumerator : EmrActivitiesEnumerator
{
protected override IEnumerable<EmrActivityStrategy> GetNormalFlow(EmrJobRunner emrRunner)
{
if (String.IsNullOrEmpty(emrRunner.JobFlowId))
yield return this.CreateStartActivity();
yield return this.CreateAddStepsActivity();
yield return new TerminateJobStrategy("Job succeeded. terminate cluster");
}
protected override IEnumerable<emractivitystrategy> GetFailedFlow(EmrJobRunner emrRunner)
{
yield return new TerminateJobStrategy("Job failed. terminate cluster");
}
private EmrActivityStrategy CreateStartActivity()
{
XmlDocument jobFlowXml = new XmlDocument();
jobFlowXml.Load("Workflow/JobConfig.xml");
JobFlow jobFlow = JobFlow.GetRecord(jobFlowXml.OuterXml);
return new StartJobStrategy("start and configure job", jobFlow);
}
private EmrActivityStrategy CreateAddStepsActivity()
{
XmlDocument stepsXml = new XmlDocument();
stepsXml.Load("Workflow/Steps.xml");
IList<stepbase> steps = new StepsXmlFactory().ReadXml(stepsXml.OuterXml);
return new AddStepsStrategy("first activity", steps);
}
}
在内部,EmrJobRunner 使用 System.Threading.Timer 调用 CheckStatus 方法来检查作业状态并在需要时推送新活动。此方法是线程安全的:一次只有一个线程保证执行它。在方法入口处有一个原始的用户模式同步构造,它会简单地拒绝其他线程,直到当前调用完成。
计时器是特意实现的,以避免类似“... while(checkStatus) thread.sleep ...”的构造。
Thread.sleep 对于您不关心资源的演示目的来说是好的,但对于架构设计解决方案来说则不然。因为即使时间调度器不给您的线程 CPU 时间,它仍然效率低下:您将线程“休眠”而不是做其他工作,并强制线程池创建新的工作线程,这有时会导致许多运行中的线程并进行持续的上下文切换。
如何使用
要使用该 API,用户应执行两项操作
- 通过实现抽象类
EmrActivitiesEnumerator来定义活动序列; - 调用
EmrJobRunner来运行活动。
public class Program
{
public static void Main(string[] args)
{
BuilderSettings settings = Program.CreateSettings();
AmazonElasticMapReduceClient emrClient = Program.CreateEmrClient();
DemoEmrActivitiesEnumerator activitiesIterator = new DemoEmrActivitiesEnumerator();
using (EmrJobRunner emrRunner = new EmrJobRunner(settings, emrClient, activitiesIterator))
{
//explicitly set an existing jobFlowId, if you want to work with an existing job
//emrRunner.JobFlowId = "j-36G3NHTVEP1Q7";
emrRunner.Run();
while (emrRunner.IsRunning)
{
Thread.Sleep(5000);
}
}
}
/// <summary>
/// Create settings to replace placeholders
///
/// <returns>Settings</returns>
public static BuilderSettings CreateSettings()
{
BuilderSettings settings = new BuilderSettings();
settings.Put("s3Bucket", "s3://myBucket/emr");
return settings;
}
public static AmazonElasticMapReduceClient CreateEmrClient()
{
String accessKey = "";
String secretKey = "";
return new AmazonElasticMapReduceClient(accessKey, secretKey, RegionEndpoint.USEast1);
}
}