
使用 Kibana 进行奇幻足球评论
4.83/5 (14投票s)
使用 Elasticsearch 和 Kibana 对过去三个赛季的奇幻足球进行可视化。
在本文中,我将演示如何在 Kibana 仪表板中查看过去几年的奇幻足球统计数据。更具体地说,我将记录
- 寻找数据
- 分析数据
- 将数据加载到 Elasticsearch(这是 Kibana 的要求)
- 查看数据(包括仪表板配置)
我搜索了一下,在网站上找到了一些可用的统计数据:Pro Football Reference。年度链接是 2011、2012 和 2013。点击 CSV 或导出链接将提供逗号分隔的格式,如下所示

此数据唯一的问题是列标题是两行,并且每 29 条记录重复一次。因此,我将它们合并并删除重复项。我将 Fantasy2011.txt、Fantasy2012.txt 和 Fantasy2013.txt 放在一个名为 c:\temp\Fantasy 的文件夹中。
分析数据
在处理新数据时,最好对其进行分析。为此,我使用了一个名为 Data Profiler 的开源工具。它带有一个命令行工具:Dp.exe。我给它一个文件名参数,它会分析数据并在我的 Web 浏览器中打开一个摘要。
dp.exe c:\temp\Fantasy2011.txt

一览
- 我看到只有 4 个位置(QB、RB、TE 和 WR)。
- 我不认识 VBD。所以我搜索了一下,发现它代表基于价值的选秀。它可能有助于对球员进行排名。这是来自 ESPN 的解释
“简单来说,VBD 是为了追溯性地比较不同位置球员的奇幻有用性而开发的。它试图为每个位置建立一个“基准”球员,然后衡量每个位置上最佳球员超出其各自基准的程度。它可能有一个花哨的首字母缩写,但它与花哨的截然不同。事实上,它是一种有些粗糙、笨拙的工具,可能因其预见性而获得过高的评价。但我仍然非常喜欢它。”
- 有 564 个排名而只有 561 个姓名这一事实表明可能存在重复项,但对我来说没关系。
- 有许多数字数据类型,这对于在仪表板上进行聚合很有用。
总的来说,数据看起来干净且准备好使用了。
加载数据
要将文件中的数据加载到 Elasticsearch 中,我使用了一个名为 Transformalize 的开源工具。Transformalize 需要一个配置。
我设置了 NotePad++ 来创建和执行 Transformalize 过程。您可以在此处查看如何使用 NotePad++ 执行命令。我创建了这个并将其保存为 Fantasy.xml。
<transformalize>
<processes>
<add name="Fantasy">
<connections>
<add name="input"
provider="folder"
folder="c:\temp\fantasy"
search-pattern="Fantasy*.txt"
delimiter=","
start="2" />
</connections>
<entities>
<add name="Stats"/>
</entities>
</add>
</processes>
</transformalize>
上面的配置定义了一个名为 Fantasy 的过程。它包括一个文件输入连接和一个名为 Stats 的实体。在这种情况下,Stats 代表 Fantasy*.txt 文件。为了导入文件,我必须定义它们的字段(如上面数据分析中所示)。要快速完成此操作,我以 metadata 模式运行 Transformalize,如下所示
tfl.exe c:\temp\Fantasy\Fantasy.xml {'mode':'metadata'}
在 metadata 模式下,Transformalize 会生成并打开一个名为 Metadata.xml 的文件。它包含文件的字段定义。我将它们复制并粘贴到 Fantasy.xml 中,如下所示
<transformalize>
<processes>
<add name="Fantasy">
<connections>
<add name="input"
provider="folder"
folder="c:\temp\fantasy"
search-pattern="Fantasy*.txt"
delimiter=","
start="2" />
</connections>
<entities>
<add name="Stats">
<fields>
<add name="Rank" type="int" ></add>
<add name="Name" length="23" ></add>
<add name="Team" length="4" ></add>
<add name="Age" type="int" ></add>
<add name="Games" type="int" ></add>
<add name="GamesStarted" type="int" ></add>
<add name="PassingCmp" type="int" ></add>
<add name="PassingAtt" type="int" ></add>
<add name="PassingYds" type="int" ></add>
<add name="PassingTD" type="int" ></add>
<add name="PassingInt" type="int" ></add>
<add name="RushingAtt" type="int" ></add>
<add name="RushingYds" type="int" ></add>
<add name="RushingYA" type="single" ></add>
<add name="RushingTD" type="int" ></add>
<add name="ReceivingRec" type="int" ></add>
<add name="ReceivingYds" type="int" ></add>
<add name="ReceivingYR" type="single" ></add>
<add name="ReceivingTD" type="int" ></add>
<add name="FantPos" length="3" ></add>
<add name="FantPoints" type="int" ></add>
<add name="VBD" type="int" ></add>
<add name="PosRank" type="int" ></add>
<add name="OvRank" type="int" ></add>
</fields>
</add>
</entities>
</add>
</processes>
</transformalize>
定义了字段后,我执行 Transformalize 来测试导入过程
tfl.exe c:\temp\Fantasy\Fantasy.xml
它会产生如下的日志输出
00:14:13 | Info | Fantasy | All................. | Detected configuration update.
00:14:14 | Warn | Fantasy | All................. | No output connection detected. Defaulting to internal.
00:14:14 | Info | Fantasy | All................. | Adding TflHashCode primary key for Stats.
00:14:14 | Info | Fantasy | Stats............... | Reading Fantasy2011.txt
00:14:14 | Info | Fantasy | Stats............... | Completed 564 rows in ConcatOperation (TflHashCode): 0 seconds.
00:14:14 | Info | Fantasy | Stats............... | Completed 564 rows in GetHashCodeOperation (TflHashCode): 0 seconds.
00:14:14 | Info | Fantasy | Stats............... | Completed 564 rows in TruncateOperation: 0 seconds.
00:14:14 | Info | Fantasy | Stats............... | Processed 0 inserts, and 0 updates in Stats.
00:14:14 | Info | Fantasy | All................. | Process affected 0 records in 00:00:00.2831019.
这是正常的 Transformalize 输出。它确认我可以从文件中导入 564 行。
此时,它不存储它们。此外,它只加载一个文件(而不是三个)。因此,我添加了一个到 Elasticsearch 的输出连接以进行存储,并将输入连接从 file 提供程序更改为 folder 提供程序。我设置了一个搜索模式来导入所有三个 Fantasy*.txt 文件。这是更新的连接
<connections>
<add name="input"
provider="folder"
folder="c:\temp\fantasy"
search-pattern="Fantasy*.txt"
delimiter=","
start="2" />
<add name="output"
provider="elasticsearch"
server="localhost"
port="9200" />
</connections>
Elasticsearch 设置
Elasticsearch 的开发人员使其设置非常容易。您只需
- 拥有 Java 运行时
- 设置您的
JAVA_HOME变量 - 下载 Elasticsearch
- 解压缩它
- 切换到其 bin 文件夹并运行
elasticsearch
它甚至带有一个便捷的实用程序来安装和运行 32 位或 64 位服务。
Transformalize 需要初始化 Elasticsearch 输出。为此,它会
- 创建一个以进程命名的索引:
fantasy - 创建一个以实体命名的类型映射:
stats。
默认情况下,Elasticsearch 将对文本使用 standard 全文分析器。相反,我想使用 keyword 分析器。因此,在 <connections/> 集合下方,我添加了此内容
<search-types>
<add name="default" analyzer="keyword" />
</search-types>
keyword 分析器将所有文本视为单个术语,即使有多个单词。这正是我想要的,因为我计划通过 Kibana 导航数据,而不是搜索它。
我已经准备好初始化输出了,所以我以 init 模式运行 Transformalize。
tfl.exe c:\temp\Fantasy\Fantasy.xml {'mode':'init'}
它会产生一个简短的输出日志
00:35:14 | Info | Fantasy | All................ | Adding TflHashCode primary key for Stats.
00:35:14 | Info | Fantasy | All................ | Initialized TrAnSfOrMaLiZeR output connection.
00:35:14 | Info | Fantasy | All................ | Initialized output in 00:00:00.3962501.
日志输出说它初始化了输出,但我需要证据,所以我用浏览器检查映射。我指示索引(fantasy)和类型名称(stats)并指定 _mapping ,如下所示
https://:9200/fantasy/stats/_mapping
Elasticsearch 返回 JSON 响应,如下所示
{
"fantasy" : {
"mappings" : {
"stats" : {
"properties" : {
"age" : {
"type" : "integer"
},
"fantpoints" : {
"type" : "integer"
},
"fantpos" : {
"type" : "string",
"analyzer" : "keyword"
},
"games" : {
"type" : "integer"
},
"gamesstarted" : {
"type" : "integer"
},
"name" : {
"type" : "string",
"analyzer" : "keyword"
},
"ovrank" : {
"type" : "integer"
},
"passingatt" : {
"type" : "integer"
},
"passingcmp" : {
"type" : "integer"
},
"passingint" : {
"type" : "integer"
},
"passingtd" : {
"type" : "integer"
},
"passingyds" : {
"type" : "integer"
},
"posrank" : {
"type" : "integer"
},
"rank" : {
"type" : "integer"
},
"receivingrec" : {
"type" : "integer"
},
"receivingtd" : {
"type" : "integer"
},
"receivingyds" : {
"type" : "integer"
},
"receivingyr" : {
"type" : "double"
},
"rushingatt" : {
"type" : "integer"
},
"rushingtd" : {
"type" : "integer"
},
"rushingya" : {
"type" : "double"
},
"rushingyds" : {
"type" : "integer"
},
"team" : {
"type" : "string",
"analyzer" : "keyword"
},
"tflbatchid" : {
"type" : "long"
},
"tflhashcode" : {
"type" : "integer"
},
"vbd" : {
"type" : "integer"
}
}
}
}
}
}
映射看起来是正确的。所以我以常规(默认)模式运行 Transformalize
tfl.exe c:\temp\Fantasy\Fantasy.xml
00:49:20 | Info | Fantasy | All........... | Adding TflHashCode primary key for Stats.
00:49:21 | Info | Fantasy | Stats......... | Reading Fantasy2011.txt
00:49:21 | Info | Fantasy | Stats......... | Reading Fantasy2012.txt
00:49:21 | Info | Fantasy | Stats......... | Reading Fantasy2013.txt
00:49:21 | Info | Fantasy | Stats......... | Completed 1740 rows in ConcatOperation (TflHashCode): 1 second.
00:49:21 | Info | Fantasy | Stats......... | Completed 1740 rows in GetHashCodeOperation (TflHashCode): 1 second.
00:49:21 | Info | Fantasy | Stats......... | Completed 1740 rows in TruncateOperation: 1 second.
00:49:21 | Info | Fantasy | Stats......... | Processed 1740 inserts, and 0 updates in Stats.
00:49:21 | Info | Fantasy | All........... | Process affected 1740 records in 00:00:01.1119670.
它似乎已正确加载了所有内容。我将在 Elasticsearch 中快速检查一下。这次我指定 _search 操作,查询所有内容 (q=*:*),并将大小设置为零,表示我不希望返回任何行
https://:9200/fantasy/stats/_search?q=*:*&size=0
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1740,
"max_score" : 0.0,
"hits" : []
}
}
是的,1740 次命中。这与 Transformalize 导入的数量一致。
查看数据
Kibana 设置
Kibana 是一个客户端 Web 应用程序。它全部是 HTML、JavaScript 和 CSS。将其放在 Web 服务器上即可开始使用。我将最新版本放在我的 c:\inetpub\wwwroot\kibana 文件夹中并进行访问。

我点击 Blank Dashboard 链接,然后点击齿轮(设置)按钮。我现在只设置索引

然后,我添加一个带表格面板的行。这将使我能够看到数据点
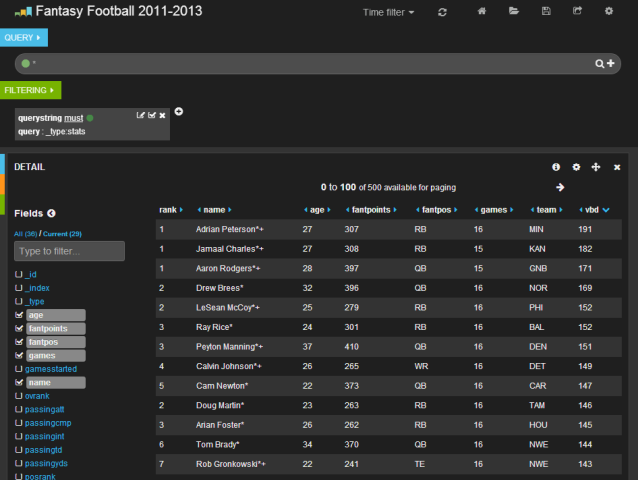
我立即看到年份丢失了。此外,我不希望在姓名旁边出现星号和加号。
加载数据(再次)
因为我想要新的字段并且想修改 name 字段,所以我需要重新访问我的 Transformalize 配置。
事实上,当您使用 Transformalize 加载文件时,它会在行中添加一个 TflFileName。因此,我可以从文件名中提取年份。我将进一步将其转换为实际日期,因为我知道 Kibana 在某些面板中需要日期。
<fields>
<add name="Rank" type="int" ></add>
<add name="Name" length="24" >
<transforms>
<add method="trimend" trim-chars="*+" />
</transforms>
</add>
...
</fields>
<calculated-fields>
<add name="Year" type="int">
<transforms>
<add method="trimend" trim-chars=".txt" parameter="TflFileName" />
<add method="right" length="4" />
<add method="convert" to="int" />
</transforms>
</add>
<add name="YearDate" type="datetime">
<transforms>
<add method="csharp" script="return new DateTime(Year,1,1);" parameter="Year" />
</transforms>
</add>
</calculated-fields>
...
这是上面添加的转换的概述
- 名称
- 删除
*和+字符。
- 删除
- 年份
- 从
TflFileName中删除 .txt 扩展名"c:\temp\fantasy\Fantasy2011.txt"变为"c:\temp\fantasy\Fantasy2011"
- 提取最后 4 个字符。
"c:\temp\fantasy\Fantasy2011"变为"2011"
- 将其转换为整数。
"2011"变为 2011
- 从
- YearDate
- 使用新创建的
Year和 C# 代码创建一个日期。2011变为2011-01-01
- 使用新创建的
现在我已经清理了数据,我回到仪表板并将时间选择器设置为使用 yeardate。


在我忘记之前,我想提一下,表格面板中的每一行都可以展开以显示所有数据

看到数据给我带来了想法。我决定为年份、年龄、球队和位置创建一些 term 图表


大多数面板的优点是它们是交互式的。在上面的图表中,看起来新奥尔良是得分最高的球队,25 岁是最佳年龄。但是,如果我点击 RB 位置,情况就会发生变化。显然,四分卫在 26 岁时表现更好

点击面板的图表后,您可以随时从绿色“Filtering”部分删除过滤器。作为最后一个示例,这里有两种查看球员(按分数或 VBD)的方法

将鼠标悬停在条形图上会显示他们的姓名。我选择 keyword 分析器的主要原因是为了让这些显示为全名。standard 分析器会将它们分解为名字和姓氏。在这种情况下,姓氏 Johnson 可能表现出色,因为 Calvin 和 Chris 的数字很高,但这无助于我们区分最佳球员。
我上面只演示了 term 和 table 面板。如果您在 histogram 面板上有许多带有时间戳的事件实时发生,或者您拥有经纬度可以在 bettermap 面板上绘制其位置,仪表板会变得更好。此外,仪表板还可以响应您的屏幕尺寸,因此您可以使用大屏幕显示器或手机来查看它。
结论
在四种免费工具的帮助下,我演示了如何可视化过去三个赛季的奇幻足球统计数据。没有涉及任何编码;只有配置。一个重要的收获是,我演示的内容可以应用于任何结构化数据。您会惊讶于几个图表可以使您的用户多么开心 :-)
感谢阅读。希望您喜欢这篇文章。