
TERESA:一个紧凑的 WebDriver 启用器
5.00/5 (4投票s)
TERESA 是一个基于 CSS 选择器的紧凑型 Selenium WebDriver 包装器和启用器,它提供了一种更有效地开发自动化测试的模式。
引言
TERESA 是一个基于 CSS 选择器的紧凑型 Selenium WebDriver 包装器和启用器,已发布在 Github 上。TERESA 不仅包装 WebDriver 函数,更侧重于优化整个过程,包括将网页映射到类、定位元素以及以最少的代码行数执行操作的机制和过程。
一个 90 秒的演示视频(http://youtu.be/rFwQJBkbrC4)展示了如何用几乎零代码来组合 4 个片段和 1 个页面,映射 Seek.com.au 的单页应用程序,以及如何用大约 40 行代码的测试函数来执行超过 30 次操作,其中一些操作在其他情况下非常具有挑战性。
要运行示例,您需要将所有文件解压到一个文件夹,然后添加以下文件的引用,以便与 Chrome 一起运行
- Newtonsoft.dll
- nunit.framework.dll
- Teresa.dll
- WebDriver.dll
基于枚举(Enum)、统一索引器接口(用于获取/设置操作)以及大量反射(Reflection)的组合应用,TERESA 提供了一种系统化的方法来构建 WebDriver 上的测试用例。
- 使用枚举和特性(Attribute)来标识元素,CSS 选择器将自动从枚举类型名称和条目名称中推导出来,从而让 WebDriver 用户摆脱手动编写 CSS/XPath 选择器的繁琐工作。
- 通过嵌套的枚举类型直接映射元素的分层关系;一种简洁而巧妙的机制被用来更高效、更有效地定位元素。
- 统一的基于枚举的索引器接口,可以在一个自解释的语句中实现查找元素以及获取/设置操作。因此,大多数一次性函数都可以避免,并且可以极大地提高生产力。
- 提供了特殊的元素包装器(SelectLocator、TextLocator 等)、丰富的扩展方法(Control-click、Hover、Highlight 等)以及一些新颖的工具(IndexPredicate、Wait.Until…),使元素操作更加简单或直观,几乎无需额外工作。
一些功能的详细解释可以在这里找到
本文档分为四个部分
- 背景:介绍 WebDriver 和本项目。
- 实现:介绍解决方案架构、技术细节和示例。
- 教程:通过循序渐进的设计和两个示例的编码,指导如何使用 TERESA。在深入了解实现细节之前,这可能是了解该框架能为您带来什么的一个好的起点。
- 设计考量:解释为什么大量使用了三种非典型技术。
- 附录:快速参考设计枚举和执行获取/设置操作。
尽管本文主要面向 WebDriver 用户,但对于那些对自动化测试不感兴趣的人来说,本文也揭示了一些新颖的技巧和技术,可能给您带来一些启发。
背景
WebDriver 是编写网站自动化测试的强大工具。
它定义了一个接口 IWebElement(用户通过该接口控制页面上的元素),该接口在本文档中被频繁引用,包括 WebDriver 支持的 RemoteWebElement 和页面上的实际元素。
IWebElement 支持两个重要的方法(通过实现 ISearchContext):“IWebElement FindElement(By by)” 和 “ReadOnlyCollection<IWebElement> FindElements(By by)”,用于定位单个元素或一组具有相同查找策略的元素。
然而,在大多数 WebDriver 示例项目中,查找元素主要由 IWebDriver.FindElement() 来完成。这可能是由于未能以树状方式定义元素来展示页面内 HTML 元素的层级结构。因此,定义定位元素的策略总是耗时且难以维护。
TERESA 的设计宗旨是使用枚举来组合和携带元素的定位符,并通过在 Page 类的不同层级定义枚举类型来构建一个父子树,并以一种精简的方式执行操作。
实现
本节介绍 TERESA 的技术实现细节,其中涉及相当多的非典型实践。
本节包括以下内容
- 项目功能块概述;
- 回顾用于通过枚举获取 CSS 选择器的关键技术;
- Locator 类和包装的枚举的简要介绍;
- Fragment/Page 类是如何组织的以保存定位符;
- 该框架用于定位 IWebElement 的机制;
- 使用 TERESA 操作 IWebElement 的说明和示例。
功能块简述
如下图所示,有三个项目打包在一起
- TERESA 是本节讨论的库项目。
- TERESAExample 说明了如何使用该框架进行自动化测试。
- TERESAUnitTesting 包含功能测试,用于验证 TERESA 的一些基本功能。
|

为了让功能块有一个简要的印象,类/文件的关键功能总结如下
- 在 AdvancedEnum 文件夹内
- HtmlTagName 和 Mechanisms 分别定义了两个枚举类型,用于枚举大多数 HTML 元素类型和 CSS 选择机制。它们的成员被赋值了不同的格式字符串,通过调用 String.ToFormat(string, obj[]) 两次来组成与特定枚举关联的 CSS 选择器。它们的确切含义和示例可以在 HtmlTagName 和 Mechanisms 中找到。
- EnumTypeAttribute 是一个与枚举类型名称关联的属性。它解析这些类型名称,这些名称应遵循“TagnameByMechanism”的格式,并获取提示的 HtmlTagName 和 Mechanisms,并将这些信息缓冲起来供 EnumMemberAttribute 进一步使用。
- EnumMemberAttribute 是另一个与枚举类型成员关联的属性。每个 EnumMember 属性同时包含来自 EnumTypeAttribute 的信息以及仅与该成员相关的信息。有了这些信息,EnumMemberAttribute 就可以推断并缓冲与该成员关联的 IWebElement 的 CSS 选择器。
- EnumExtensions 是一个静态类,提供了枚举的一些扩展方法,并维护一个字典来引用枚举条目的字符串值,包括 HtmlTagName 和 Mechanisms 的格式字符串,以及用于构建 CSS 选择器的枚举成员键。
- 在 Locators 文件夹内
- Locator:是框架的基石。
- 首先,它不是 IWebElement 的包装器,而是包装了查找 IWebElement 所需的工具和信息,包括 CSS 选择器及其父级 Locator。
- 其次,它通过一个单一的函数(public IWebElement FindElement(Func<IWebElement,bool>, int))提供了查找机制,该函数调用底层 WebDriver 的 FindElement() 和 FindElements() 来获取预期的 IWebElement。
- 最后,Locator 提供了一个唯一的索引器(string this[Enum, string, Func<IWebElement, bool>]{set;get})来执行与枚举成员关联的 IWebElement 上的所有读/写操作。
- 用于存储 CSS 选择器的枚举成员,已经通过其类型名称(如 Tex、Button、Link、Radio、Checkbox、Table 等)标识了元素的类型。某些类型的元素应具有不同于其他元素的行为,它们的函数分别被封装为 CheckboxLocator、RadioLocator、SelectLocator、TableLocator 和 TextLocator,通过扩展 Locator 来提供对底层节点的许多高级操作。
- Fragment(通过扩展 Locator)和 Page(通过扩展 Fragment)用于定义标识各种 Web 元素的枚举成员。Fragment 可用于保存一组基本定位符,表示包含在容器元素内的 Web 元素。Fragment 的定义可以嵌套(Fragment 可以在另一个 Fragment 或 Page 中定义)并且可以重用(Fragment 可以被多个 Page 对象包含),因此通过在不同位置定义它们,所有定位符(包括 Fragments)都以层级方式组织,并且 Fragment/Page 的默认构造函数会利用反射构建定位符树:您无需编写任何代码!要访问从枚举定义生成的定位符树的节点,可以使用一个单一的入口(string this[Enum, string, Func<IWebElement, bool>]{set;get})来执行包含元素上的任何操作。
- Locator:是框架的基石。
- 在 Utility 文件夹内。
- Wait 和 GenericWait<T> 用于支持 WebDriver.support 中定义的 IWait,其机制如 轻量级的 Wait.Until() 机制 中所述。
- GenericPredicate 用于构建 Locator/Fragment/Page 中的索引器所使用的 Predicate(Func<IWebElement, bool>),尽管目前只支持一种基于索引的 Predicate。
- 在根文件夹中,IWebElementExtension 为 IWebElement 提供了一些新行为,如 Hover()、DoubleClick() 和 ControlClick(),以及一些方便生成 Predicate 的方法。
通过枚举生成 CSS 选择器
如 高级枚举用法示例 中所述,TERESA 使用一种基于方法扩展、属性和枚举类型的反射机制,使其用户能够将枚举成员与 CSS 选择器关联起来。所有相关函数都包含在“AdvancedEnum”文件夹中,此机制
- 作为一种特殊的类,Enum 拥有“EnumExtension.cs”中丰富的功能集。有一个静态字典用于存储与 EACH 枚举条目关联的唯一字符串值,并定义了许多辅助函数来检索 EACH 枚举成员的字符串值或其他扩展属性值。
提示:作为一种提示,您可以构建这样一个字典来将每个枚举条目与 ANY 类关联,然后使用该枚举条目来普遍检索丰富的信息。例如,可以使用静态字典<Enum, RichInfoSet> 来实现 SomeEnumEntry.RichInfoSet()。
- 为了在不键入过多字符的情况下传递更多信息,枚举类型名称采用“TagnameByMechanism”或“Tagname
AllByMechanism”的模式来定义 Web 元素的 Tagname 和查找它的机制。总之,您必须定义一个枚举条目作为枚举类型的一个成员,并 along with 其类型名称来引用它。这种模式下自解释的枚举类型名称不仅使解析它们非常方便,而且在您使用它们执行任何操作时提供足够的线索,并使使用正确类型实例化的 Locator 提供更多功能。 - “TagnameByMechanism”模式下的类型名称中的 Tagname 和 Mechanism 也被定义为两个枚举类型:HtmlTagName 和 Mechanisms。
- 有 18 个 Mechanisms 成员,按优先级排序:ById, ByClass, ByAdjacent, ByParent, ByAncestor, BySibling, ByUrl, ByName, ByValue, ByAttribute/ByAttr, ByOrder, ByOrderLast, ByChild, ByChildLast, ByCustom, ByTag 和 ByText。
- 您可以在“Mechanisms.cs”的源代码中找到它们的描述,并在“您必须记住的 30 个 CSS 选择器”中找到对 CSS 选择器的良好介绍,除了 Mechanisms.ByText 和 Mechanisms.ByCustom。
- “ByCustom”允许您组合一个选择器字符串,该字符串将被附加到标签名后面。
- “ByText”实际上不是一个 CSS 选择器,它会枚举所有带有指定标签的元素 HtmlTagName,然后使用 LINQ 查找包含所需文本的第一个元素。
- 在 HtmlTagName 中定义了 45 个条目,例如 HtmlTagName.Text、HtmlTagName.Button、HtmlTagName.Link、HtmlTagName.Div 等,每个条目都关联一个字符串值,以帮助构建 CSS 选择器。
- 例如,有五个常见的标签被视为按钮:<button>、<input[type=button]>、<input.button>、<input.btn> 和 <div[role=button]>。因此,正如您可以在 TERESAUnitTesting 项目的 CssComposingTest 中尝试的那样,枚举条目“ButtonById.go”将获得 CSS 选择器“button#go, input[type=button]#go, input.btn#go, input.button#go, div[role=button]#go”来匹配所有五个标签。
- 拥有 45 个 HtmlTagName 和 18 个 Mechanisms,可能有 45*18=810 种组合,尽管有些组合(如 HtmlByXXX)是无意义的,但可以通过定义枚举类型名称来覆盖您可能遇到的绝大多数情况。
- 当您确实需要复杂的 CSS 选择器时,“XXXByCustom”将使用 EnumMemberAttribute 的值作为最终的 CSS 选择器,但 IWebElement 的类型仍将由“XXX”定义,以生成特殊的 Locator 来提供额外的功能。例如,您可以定义“button#id”作为 SelectByCustom 的成员来定位 IWebElement,并将其视为 <select> 元素,即使尝试选择 <select> 的选项时会引发异常。
- 枚举类型名称的解析发生在 EnumTypeAttribute 的一个静态函数中(public static EnumTypeAttribute TypeAttributeOf(Type enumType))。
- 每个此类属性都与一个枚举类型相关联,以提供三个属性:TagName、Mechnism 和 IsCollection。前两个分别与 Tagname 和 Mechanism 相关联。
- 当类型名称的格式为“TagnameAllByMechanism”(如“ButtonAllByClass”)时,会设置“IsCollection”为 true,以通过调用 FindElements() 而不是 WebDriver 中的 FindElement() 来表示多个匹配的 IWebElement 的 CSS 选择器。
- 在指定了 IWebElement 的类型和查找机制之后,通过定义枚举类型的名称,枚举成员用于显式或隐式地携带用于生成 CSS 选择器的键。
- 枚举成员的名称将被视为其值,将‘_’(下划线)替换为‘ ’(空格)。
- 此值将用于通过两次 String.Format() 调用来组合最终的 CSS 选择器字符串,同时考虑枚举成员类型来自的枚举类型的 HtmlTagName 和 Mechanisms 属性。使用与 HtmlTagName 和 Mechanisms 关联的字符串值。
- 例如,HtmlTagName.Text 的值为“{0} input[type]{1}, {0} textarea{1}”,Mechanisms.ByName 的值为“[name*='{0}']”。因此,枚举成员“TextByName.xyz”将获得 CSS 选择器“input[type][name*='xyz'], textarea[name*='xyz']”。您可以使用 TERESAUnitTesting 项目的 CssComposingTest 来查看所有 HtmlTagName 和 Mechanisms 组合的 CSS 选择器是如何组成的。
- 我个人倾向于直接复制键(id、name、class)或其部分作为枚举成员名称,特别是如果这些键是有意义的词语,可以节省输入并直接通过搜索 HTML 源代码找到标签。
- 为了组合更复杂的选择器,或者您更喜欢为枚举成员定义更有意义或格式更好的名称,那么键必须使用 EnumMemberAttribute 显式定义。
- 顾名思义,EnumMemberAttributes 仅与枚举成员相关联,以包含来自这些成员类型的信息(通过 EnumTypeAttribute)、三个新属性(Value、IsFragment 和 Description)以及最重要的是 Css。
- IsFragment 标识枚举成员是否用于标识一个 Fragment,或包含许多子枚举成员的容器,其用法将在后面讨论。
- Value:是一个与枚举成员绑定的字符串,就像 Mechanisms.ByName 的格式字符串“[name*='{0}']”一样。而对于表示 IWebElement 的枚举成员,它包含用于组合最终 CSS 选择器的键。尽管大多数 Mechanisms 只需要一个参数,如 Mechanisms.ById,但在某些情况下,当 Value 字符串可以被‘=’分割成两个子字符串时,两个参数是至关重要的。
- 例如,假设我们需要通过类名“class1”来定位一个 <section>,但有太多这样的 <section> 标签,而我们关心的那个有一个 id 为“bar”的 <div> 兄弟元素,那么我们可以这样定义一个枚举:public enum SectionByAdjacent {[EnumMember(“div#bar=.class1”)]region1}。因此,Value 被分割为两个参数:“div#bar”和“.class1”,以组合最终的 CSS 字符串“div#bar+ section.class1”,这正是我们需要的。
- 值得注意的是,Mechanisms.ByAttribute 或简称为 Mechanisms.ByAttr 可以用来支持依赖于元素属性的多种策略,这些策略包含在“[]”中:[{A0}]、[{A0}={A1}]、[{A0}*={A1}]、[{A0}^={A1}]、[{A0}$={A1}]、[{A0}~={A1}]、[{A0}-*={A1}] 分别表示带属性、完全匹配、包含、以…开头、以…结尾、值包含、名称以 A0 开头,具体取决于 Value 是否包含“=”或“=”是否跟随‘*’、‘^’、‘$’、‘~’、‘-*’。
- 尽管这种设计可以减轻编写 CSS 选择器的痛苦,但始终最好在浏览器中手动尝试最终的 CSS 选择器,看看会发生什么。
本节回顾了在 高级枚举用法示例 中讨论的用于生成 CSS 选择器的技术。然而,这种方法旨在支持简短简单的 CSS 选择器,这些选择器应在父容器内使用,而不是在定位 IWebElements 时使用整个 HTML 文档范围。有关如何定位 IWebElement 的详细信息 covered 在 定位 IWebElement 中。
Locators:IWebElement 查找器和操作符
即使有了使用枚举类型名称和成员值有效组合 CSS 选择器的方法,如果不在 WebDriver 的 FindElement()/FindElements() 函数中使用它们,它们也只是字符串,价值不大。特别是当 CSS 选择器仅在元素树的某个分支中有效,或者页面中有多个匹配项时。
考虑到 Web 页面的层级结构,枚举成员应该组织成树状结构,以便通过调用其父元素的 FindElement()/FindElements() 来使用它们,而不是全局调用 IWebDriver 的。这显然超出了枚举类型的能力,因此定义了一个类 **Locator** 作为由枚举携带的 CSS 选择器的包装器及其父容器。它的类图如下所示。

TextLocator、RadioLocator、CheckboxLocator、SelectLocator 和 TableLocator,顾名思义,用于为由枚举成员标识的 IWebElements 提供附加功能,这些枚举成员的类型名称分别为“TextByXXX”、“RadioByXXX”、“CheckboxByXXX”、“SelectByXXX”和“TableByXXX”。这些特殊的 Locator 支持一些细微的操作差异,将在 介绍 Locator 之后 进行解释。
Fragment 和 Page 是用于保存枚举成员定义本身或子 Fragment 的类,直接或通过引用。它们的使用将在 定位 IWebElement 中讨论。
与 WebDriver 的其他包装器不同,TERESA 中的 **Locator** **不是 IWebElement 的包装器**:尽管每个 Locator 实例都有一个“lastFoundElement”字段来存储通过调用其 FindElement() 找到的最后一个 IWebElement,但如果匹配条件发生变化,该字段可以存储任何其他一个。实际上,**一个 Locator 实例封装了定位 IWebElement(CSS 选择器和父 Locator)所需的信息,并通过唯一的 Indexer 执行读取或写入操作**。
简而言之,**Locator** 有两个属性:“**Identifier**”用于保存标识 IWebElement 的枚举成员,以及“**Parent**”用于引用包含相同容器信息的 Fragment 对象。**FindElement()** 函数将通过递归调用 WebDriver 的 FindElement()/FindElements() 来返回 IWebElement,其过程和底层机制将在 通过 Locators 定位 中解释。**TryFindElement()** 函数也是如此,它也通过递归调用 FindElements() 来返回 IWebElement。
Locator:如何操作 IWebElement
尽管定义了一个 **TryExecute()** 方法来尝试操作由 **TryFindElement()** 找到的 IWebElement,但它只是通过唯一的 Indexer 接口(**public virtual string this[string extraInfo, Func<IWebElement, bool> filters = null]**)包装了由 WebDriver 提供的 IWebElement 上的所有设置/获取操作。本节讨论了这个单 Indexer 如何、为什么以及能够支持什么来通过调用底层 WebDriver 函数来操作元素。
此外,每个 Locator 的 Indexer 都可以通过 Fragment/Page 的类似 Indexer(**public string this[Enum theEnum, string extraInfo = null, Func<IWebElement, bool> filters = null]**)来调用,执行顺序将在 通过 Locators 定位 IWebElement 中讨论,更多用法将在 教程 中讨论。
获取操作
WebDriver IWebElement(由 RemoteWebElement 实现)定义了一些常用的只读属性,包括 TagName、Text、Enabled、Selected、Location、Size 和 Displayed,以及一个函数(**string GetAttribute(string attributeName)**)用于检索与 IWebElement 关联的 HTML 属性或自定义属性,例如“id”、“class”、“href”等,如 此处 定义的。通过一个字符串参数来标识它们,Indexer 的 getter 支持所有这些属性,如 附录 中所总结的。
public virtual string this[string extraInfo, Func<IWebElement, bool> filters = null]
{
get
{
IWebElement element = FindElement(filters);
if (element == null)
throw new NoSuchElementException("Failed to find element with " + Identifier.Description());
string resultString;
if (string.IsNullOrEmpty(extraInfo))
{
resultString = element.Text;
Console.WriteLine("\"{0}\"=[{1}]", resultString, Identifier.FullName());
return resultString;
}
switch (extraInfo.ToLower())
{
case Operation.TextOf:
resultString = element.Text;
break;
case Operation.TagName:
resultString = element.TagName;
break;
case Operation.Selected:
resultString = element.Selected.ToString();
break;
case Operation.Enabled:
resultString = element.Enabled.ToString();
break;
case Operation.Displayed:
resultString = element.Displayed.ToString();
break;
case Operation.Location:
resultString = element.Location.ToString();
break;
case Operation.Size:
resultString = element.Size.ToString();
break;
case Operation.Css:
resultString = Identifier.Css();
break;
case Operation.ParentCss:
resultString = Parent==null ? "" : Parent.Identifier.Css();
break;
case Operation.FullCss:
resultString = Identifier.FullCss();
break;
default:
resultString = element.GetAttribute(extraInfo);
break;
}
Console.WriteLine("\"{0}\"=[{1}, {2}]", resultString, Identifier.FullName(), extraInfo);
return resultString;
}
}
Indexer 的 Getter 会
- 首先,使用标识符和 Predicate(Func<IWebElement, bool>)中携带的 CSS 选择器找到目标 IWebElement。
- 检查是否提供了“extraInfo”字符串来标识请求的信息类型,或者在“extraInfo”缺失/为 null/为空时默认返回 IWebElement 的 Text;
- 简单地比较“extraInfo”的值来检索相应的属性或调用底层 WebDriver 的 IWebElement 的 GetAttribute。
- 匹配一些其他常量字符串值以获取其他自定义值,例如,当 extraInfo 是“CSS”或“ParentCss”时,获取 CSS 选择器和其父级 Locator 的 CSS 选择器。
“extraInfo”的用法示例如下,更多用法列在 附录 中
- SomeLocator[null] 或 SomeLocator[“”] 或 SomeLocator[“text”] 都会返回由标识符枚举标识的 IWebElement 的 Text。
- SomeLocator[“selected”] 会返回“True”或“False”来显示 IWebElement 是否被选中。
- SomeLocator[“href”] 会调用 GetAttribute() 并获取与链接关联的链接字符串。
- SomeLocator[“onclick”] 会返回脚本字符串,如果它确实存在的话。
- SomeLocator[“meaningless”] 会为不存在的属性返回 null。
- SomeLocator[“onclick”] 会返回脚本字符串,如果它确实存在的话。
- SomeLocator[“css”] 会返回由 Enum Identifier 组成的 CSS 选择器。
为了启用 .NET 中广泛使用的“**Try**Doing()”机制,Getter() 会简单地检测“extraInfo”参数是否以“Try”开头:如果为“false”,则按上述顺序执行,假设元素是可操作的;如果为“true”,则逻辑会首先检查 FindElement() 是否返回有效的 IWebElement,然后执行预期的命令或静默返回。
通过这种有些非典型的方式,通过 Indexer 的 Getter,您可以方便地以字符串形式访问 Web 页面源代码中显示的任何属性或特性,并通过更改单个字符串参数来修改它。
设置操作
IWebElement 支持的常见操作包括:Clear()、Click()、SendKeys() 和 Submit()。原则上,您可以对任何有效的 IWebElement 执行这 4 种操作,但这可能并不总是合适的。例如,在找到一个 Tag 为 <button> 的 Button 之后,调用它的 Clear() 会抛出 InvalidElementStateException。
然而,使用 TERESA,与由有意义的枚举类型名称标识的 IWebElements 相关联的特定行为,那么由枚举类型名称隐含的 HtmlTagName 可以用来构建特殊的 Locator 实例(**TextLocator**、**RadioLocator**、**CheckboxLocator**、**SelectLocator** 和 **TableLocator**,在下一节中涵盖),以提供更定制化的行为。此外,一些常见操作,如 **Hover()**、**DoubleClick()**、**ControlClick()**,在 Locator 类中都得到了支持,并作为 IWebElement 的扩展方法。
这些通用 IWebElement 上的所有函数也由 Indexer(**virtual string this[string, Func<IWebElement, bool>]**)通过其 Setter 支持。
set
{
if (value == null)
throw new ArgumentNullException();
IWebElement element = FindElement(filters);
if (string.Compare(extraInfo, Operation.SendKeys, StringComparison.InvariantCultureIgnoreCase)==0)
{
if (element == null || !element.IsValid())
throw new NoSuchElementException("Failed to find element with " + Identifier.FullName());
element.SendKeys(value);
Console.WriteLine("[{0}, \"{1}\"]=\"{2}\";", Identifier.FullName(), extraInfo, value);
return;
}
string action = value.ToLowerInvariant();
bool isTry = action.StartsWith(Operation.Try);
if (isTry)
{
LastTrySuccess = false;
if (element == null || !element.IsValid())
return;
action = action.Substring(Operation.TryLength);
}
if (element == null || !element.IsValid())
throw new NoSuchElementException("Failed to find element with " + Identifier.FullName());
switch (action)
{
case Operation.True:
case Operation.Click:
element.Click();
break;
case Operation.Submit:
element.Submit();
break;
case Operation.ClickScript:
element.ClickByScript();
break;
case Operation.Hover:
element.Hover();
break;
case Operation.ControlClick:
element.ControlClick();
break;
case Operation.ShiftClick:
element.ShiftClick();
break;
case Operation.DoubleClick:
element.DoubleClick();
break;
case Operation.Show:
element.Show();
break;
case Operation.HighLight:
element.HighLight();
break;
default:
Console.WriteLine("Failed to parse command associated with '{0}'.", value);
return;
}
if (isTry)
LastTrySuccess = true;
Console.WriteLine("[{0}]=\"{1}\"", Identifier.FullName(), value);
}
与 Getter() 类似,Setter() 使用其 Identifier 和 Predicate(**Func<IWebElement, bool>**)定位目标 IWebElement 以找到正确的元素。虽然“extraInfo”仅用于支持 WebDriver 的 SendKeys(),但值字符串被解析以尝试支持更多类型的操作。如果它确实意味着某个操作,则执行相应的函数调用,如下所示。
- 如果值字符串是 **“true”** 或 **“click”**,则执行 IWebElement.Click();
- 如果值字符串是 **“submit”**,则执行 IWebElement.Submit();
- 如果值字符串是 **“clicksript”**,则在 IWebElement 上执行 ScriptClick();此函数是一个扩展方法,与其他以下方法一样定义在“IWebElementExtension.cs”,用于使用 JavaScript 来执行点击元素的操作,该元素被其他元素隐藏。
- 如果值字符串是 **“controlclick”** 或 **“shiftclick”**,则分别调用相应的扩展方法来执行目标元素的“Ctrl+Click”和“Shift+Click”。如果目标是链接,则它们将分别在新选项卡或新窗口中打开链接。
- 如果值字符串是 **“hover”**,则执行“public static void Hover(this IWebElement element, int remainMillis = 1000)”的代码,该代码调用“Actions.MoveToElement(element)”并停留一段时间(由 remainMillis 指定),以模拟鼠标悬停在 IWebElement 上;
- 如果值字符串是 **“doubleclick”**,则调用相应的扩展方法来调用“Actions.DoubleClick(element)”;
- 如果值字符串是 **“show”**,则调用 Show() 方法,通过调用“ILocatable.LocationOnScreenOnceScrolledIntoView”将浏览器滚动到可见部分,该方法“滚动浏览器以显示元素”。
- 如果值字符串是 **“highlight”**,则调用具有默认值的扩展方法 HighLight(string, int) 来用提供的样式(作为字符串参数)渲染目标 IWebElement,然后在恢复之前样式的一段时间(由 int 参数指定)。它可用于使测试执行更直观。
- 如果“extraInfo”指定的值在 switch() 块中不匹配,则不会对 IWebElement 执行任何操作,只会显示一条消息“Failed to parse command associated with '{0}'.”。
- 支持的命令在 设置操作 中进行了总结。更多有用的方法将在“IWebElementExtension.cs”中定义为 IWebElement 的扩展方法,并稍后通过“extraInfo”指定的关键字触发。
为了启用 .NET 中广泛使用的“**Try**Doing()”机制,Setter() 会简单地检测“extraInfo”参数是否以“Try”开头:如果为“false”,则按上述顺序执行,假设元素是可操作的;如果为“true”,则逻辑会首先检查 FindElement() 是否返回有效的 IWebElement,然后执行预期的命令或静默返回。
Indexer 的用法将在 教程 中的示例中演示。
通过特殊 Locator 进行更定制化的操作
您可能已经注意到,Locator 类中根本没有调用“SendKeys()”。实际上,在 WebDriver 自动化测试中,这个重要函数应该只用于键盘交互式元素,例如由 HtmlTagName.Select(匹配标签为 <input type='checkbox'> 的 IWebElement)和 HtmlTagName.Text(匹配标签为 <input> 或 <textarea> 的 IWebElement,注意您必须避免将其分配给 Button 等 HTML 元素,其标签为 <input type=button>)标识的输入元素。在初始化阶段,HtmlTagName 为 HtmlTagName.Text 和 HtmlTagName.Select 的 IWebElements 会在 Locator 类的工厂方法(public static Locator LocatorOf(Enum id, Fragment parent))中生成为 TextLocator 和 SelectLocator。
TextLocator 重写了 Locator 的 Indexer,如下所示
get { return base[extraInfo??"value", filters]; }
set
{
IWebElement element = FindElement(filters);
if (!string.IsNullOrEmpty(extraInfo))
{
base[extraInfo, filters] = string.IsNullOrEmpty(value) ? extraInfo : value;
}
else if (string.IsNullOrEmpty(value))
{
element.Clear();
Console.WriteLine("[{0}]=\"{1}\";", Identifier.FullName(), "");
}
else
{
//Input "Ctrl+A" to select the text within the element.
element.SendKeys(Keys.Control + "a");
//Input "Tab" after the value to select item filled by AJAX, notice that filters is not explicitly
//used here because it is stored due to the above call of FindElement(filters).
element.SendKeys(value + Keys.Tab);
Console.WriteLine("[{0}]=\"{1}\";", Identifier.FullName(), value);
}
}
Getter() 默认返回“value”属性,该属性用于存储 <input type="text"> 等元素中的文本值。(对于这类元素,IWebElement.Text 始终返回空。)
Setter() 会清除文本输入元素或用字符串值填充它,方法是选择现有文本,然后输入字符串值,最后附加一个额外的“Tab”。如 高效操作 WebDriver 元素 [技巧/窍门] 中所述,额外的“Ctrl+A”和“Tab”不会影响正常输入,但当元素通过 AJAX 自动填充时,它们会非常有用,“Tab”会选择匹配度最高的项并用它填充元素,这意味着您只需输入前几个字符即可,而不是完整句子,就能处理自动填充的文本。
输入几个字符加上“Tab”的相同技巧也可以用于从下拉列表中选择项,这在包含多个选项的 <optiongrp> 被使用时特别有用,如 高效操作 WebDriver 元素 [技巧/窍门] 中讨论的。作为常用的组件,HTML <select> 元素在您需要按值或索引选择选项时值得关注。“SelectElement” of WebDriver.Support.UI 提供了一些有用的实用程序,例如“void SelectByText(stringtext)”、“void SelectByValue(stringvalue)”和“void SelectByIndex(intindex)”,它们也由 SelectLocator 支持,并具有名称/签名相似的函数,但有一个布尔值“bool toSelect = true”来指示选项是应该被选中还是取消选中,以避免像 DeselectByText() 这样的函数。以 SelectByIndex() 为例
public void SelectByIndex(string indexKey, bool toSelect = true)
{
if (indexKey == null)
throw new ArgumentNullException("indexKey", "indexKey must not be null");
//Try to match the option with attribute of "index" and its valueKey is matched without assumption the indexKey is a number
IWebElement targetOption = Options.FirstOrDefault(x => x.GetAttribute("index") == indexKey);
if (targetOption != null)
{
if (targetOption.Selected != toSelect)
targetOption.Click();
return;
}
//When options don't have "index" attribute, then their order (index of first one is '0') is used to get the right one
int index = -1;
if (!int.TryParse(indexKey, out index))
throw new NoSuchElementException("Failed to locate option with index of " + indexKey);
if (index < 0 || index >= Options.Count)
throw new IndexOutOfRangeException("Index is out of range: '{0}'.", indexKey);
targetOption = Options[index];
if (targetOption.Selected != toSelect)
targetOption.Click();
}
此函数假设选项具有“index”属性,并尝试首先匹配它们与“indexKey”,然后通过 Click() 选择或取消选中匹配的选项。只有当这种匹配失败时,它才会将“indexKey”视为数字,并尝试按其在“Options”中的顺序定位选项。
“**Options**”实际上是一个“ReadOnlyCollection<IWebElement>”属性,在查找与枚举标识符关联的 <select> 元素后,在每次执行 FindElement() 时进行初始化,因为与 <select> 的操作总是与 <option> 标签相关,所以“bool IsMultiple”属性也是如此。上述初始化发生在重写的 FindElement() 中,稍后将进行解释。
public override IWebElement FindElement(Func<IWebElement, bool> filters = null, int waitInMills = DefaultWaitToFindElement)
{
IWebElement lastFound = lastFoundElement;
IWebElement result = base.FindElement(filters, waitInMills);
if (result == null)
throw new NoSuchElementException();
if (result != lastFound)
{
bool isMultiple = false;
string valueOfMultipleAttribute = result.GetAttribute(MULTIPLE);
bool.TryParse(valueOfMultipleAttribute, out isMultiple);
IsMultiple = isMultiple;
Options = result.FindElementsByCss(OPTION);
}
return result;
}
如代码所示,“Options”和“IsMultiple”仅在找到新的 IWebElement 时更新,然后 SelectLocator 作为缓存,以便更高效地执行“Select”或“Deselect”操作,并忽略 <optiongrp> 标签。
Locator 类(string this[string extraInfo, Func<IWebElement, bool> filters = null])的 Indexer 被相应地重写,以通过其 Setter 支持这些额外功能。
set
{
IWebElement element = FindElement(filters);
string prefix = string.IsNullOrEmpty(extraInfo) ? null :
ReservedPrefixes.FirstOrDefault(s => extraInfo.StartsWith(s, StringComparison.InvariantCultureIgnoreCase));
if (prefix == null)
{
//By default, when "extraInfo" is not specified, SendKeys(valueKey+Tab) to let browser click the target option
//Notice: this click would happen no matter if the valueKey is "true" or "false", and it doesn't select multiple options.
string keysToBeSend = extraInfo ?? value;
//Sometime, even when it works in debugging, SendKeys() to multiple select may fail to select the option
foreach (char ch in keysToBeSend)
{
element.SendKeys(ch.ToString());
Thread.Sleep(100);
}
element.SendKeys(Keys.Tab);
Thread.Sleep(500);
Console.WriteLine("[{0}]=\"{1}\";", Identifier.FullName(), keysToBeSend);
return;
}
string key = extraInfo.Substring(prefix.Length);
//The valueKey string shall be "True" or "False" to indicate the concerned option shall be selected or deselected
bool toSelect = false;
if (!bool.TryParse(value, out toSelect))
{ //Do nothing if the valueKey is not a boolean valueKey
Console.WriteLine("Failed to parse command associated with '{0}'.", value);
return;
}
if (prefix.EndsWith(KEY_PREFIX))
prefix = prefix.Substring(0, prefix.Length - KEY_PREFIX.Length);
switch (prefix)
{
case Operation.TextOf:
SelectByText(key, toSelect);
break;
case Operation.IndexOf:
case Operation.IndexSign:
SelectByIndex(key, toSelect);
break;
case Operation.ValueOf:
case Operation.ValueSign:
SelectByValue(key, toSelect);
break;
case Operation.AllOptions:
SelectAll(toSelect);
break;
}
Console.WriteLine("[{0}, \"{1}\"]=\"{2}\";", Identifier.FullName(), extraInfo, value);
}
Setter() 首先调用重写的 FindElement(),该方法(如果需要)会刷新“Options”和“IsMultiple”。然后,根据“extraInfo”是否被使用以及使用什么值
- 如果为 null 或空,则 SelectLocator 将执行 SendKeys(),并允许浏览器在按下“Tab”后选择最佳匹配项,如 高效操作 WebDriver 元素 [技巧/窍门] 中所述。
- 否则,它将通知 Setter 匹配策略
- “**text=textKey**”将触发 SelectByText(string textKey, bool toSelect);
- “**index=indexKey**”或“**#indexKey**”将触发 SelectByIndex(string indexKey, bool toSelect);
- “**value=valueKey**”或“**$valueKey**”将触发 SelectByValue(string valueKey, bool toSelect);
- “**alloptions**”:根据“value”选择或取消选择 <select multiple> IWebElement 的所有选项,方法是调用 SelectAll(bool toSelect)。
Getter() 也被重写,用于检索额外信息,特别是第一个选定选项的信息。
get
{
IWebElement element = FindElement(filters);
string resultString;
if (string.IsNullOrEmpty(extraInfo))
{
resultString = Selected==null ? FindElement().Text : Selected.Text;
Console.WriteLine("\"{0}\"=[{1}];", resultString, Identifier.FullName());
return resultString;
}
switch (extraInfo.ToLowerInvariant())
{
case Operation.TextOf:
resultString = Selected == null ? FindElement().Text : Selected.Text;
break;
case Operation.IndexOf:
case Operation.IndexSign:
if (Selected == null)
resultString = "-1";
else
{
resultString = Selected.GetAttribute(INDEX);
resultString = resultString == null ? Options.IndexOf(Selected).ToString() : resultString;
}
break;
case Operation.ValueOf:
case Operation.ValueSign:
resultString = Selected==null ? null : Selected.GetAttribute("value");
break;
case Operation.IsMultiple:
resultString = IsMultiple.ToString();
break;
case Operation.AllOptions:
var optionTexts = Options.Select(e => e.Text);
resultString = string.Join(", ", optionTexts);
break;
case Operation.AllSelected:
{
var allSelectedText = AllSelected.Select(e => e.Text);
resultString = string.Join(", ", allSelectedText);
break;
}
default:
return base[extraInfo, filters];
}
Console.WriteLine("\"{0}\"=[{1}, \"{2}\"];", resultString, Identifier.FullName(), extraInfo);
return resultString;
}
Getter() 也会首先尝试调用 FindElement() 来查找 Select 元素,这可能不全是 WebDriver 的 FindElement(),将在下一部分披露,但会确保“IsMultiple”和“Options”已更新。然后,根据“extraInfo”是否被使用以及使用什么值
- 如果为 **null、空或“text”**,则 SelectLocator 会尝试获取选定选项的文本;如果没有选定选项,则返回 select 的文本,或将所有选项的文本合并在一起。
- 否则,它将通知 Setter 匹配策略
- **“index”或“#”** 将返回选定选项的“index”属性的值,或其在“Options”中的顺序(第一个返回“0”);
- **“value”或“$”** 将返回选定选项的“value”属性的值(如果存在),或者在不存在时返回 null;
- **“alloptions”** 将返回所有选项的文本,合并为一个字符串。
- “allselected” 将返回所有选定选项的文本,合并为一个字符串。
- “ismultiple” 将返回“true”或“false”,以显示 select IWebElement 是否支持多选。
CheckboxLacator 和 RadioLocator 非常简单且相似,通过重写 Locator 的 Indexer Getter(),它们只支持新的键“checked”:将其设置为“extraInfo”将获得选定项的文本;通过重写 Indexer Setter(),它们将检查/取消检查目标 IWebElement。
另一方面,TableLocator 非常有趣,并且可以进一步优化以重写 Locator 的 Indexer 来提供更方便的功能。但对于那些喜欢直接调用 WebDriver 函数的人来说,当处理标准 <table>(每行单元格数量相同)时,它提供了一些辅助函数,可以通过返回 table 单元格 IWebElement 来实现。
定义了四个额外的属性,它们在 <table> 元素首次找到时,在重写的 FindElement() 方法中进行初始化。
public int RowCount { get; private set; }
public int ColumnCount { get; private set; }
public List<string> Headers { get; private set; }
public bool WithHeaders { get; private set; }
...
public override IWebElement FindElement(Func<IWebElement, bool> filters = null, int waitInMills = DefaultWaitToFindElement)
{
IWebElement lastFound = lastFoundElement;
IWebElement result = base.FindElement(filters, waitInMills);
if (result == null)
throw new NoSuchElementException();
if (result != lastFound)
{
var rows = result.FindElementsByCss("tr").ToList();
IWebElement firstRow = rows.FirstOrDefault();
if (firstRow==null)
throw new NoSuchElementException("Failed to found table rows.");
var headers = firstRow.FindElementsByCss("th").ToList();
RowCount = rows.Count();
if (headers.Count() != 0)
{
WithHeaders = true;
ColumnCount = headers.Count();
Headers = headers.Select(x => x.Text).ToList();
}
else
{
RowCount += 1;
WithHeaders = false;
Headers = null;
firstRow = rows.FirstOrDefault();
ColumnCount = firstRow == null ? 0 : firstRow.FindElementsByCss("td").Count();
}
}
return result;
}
该函数将计算行数和列数,检测是否存在包含 <th> 标签的行,并在存在包含 <th> 的 <tr> 时记录出现在标题中的字符串。
然后有三个只读的 Indexer 来辅助定位表格单元格:IWebElement CellOf(int rowIndex, int columnIndex)、IWebElement CellOf(int rowIndex, string headerKeyword)、IWebElement CellOf(string headerKeyword, Func<string, bool> predicate)。
public IWebElement CellOf(int rowIndex, int columnIndex)
{
if (columnIndex < 0 || columnIndex >= ColumnCount)
throw new Exception("Column Index ranges from 0 to " + (ColumnCount - 1));
if (rowIndex < 0 || rowIndex >= RowCount)
throw new Exception("Row Index ranges from 0 to " + (RowCount - 1));
if (rowIndex == 0 && !WithHeaders)
throw new Exception("No headers (rowIndex=0) defined for this table.");
return FindElement().FindElementByCss(
string.Format("tr:nth-of-type({0}) {1}:nth-of-type({2})",
rowIndex + 1,
rowIndex == 0 ? "th" : "td",
columnIndex)
);
}
public IWebElement CellOf(int rowIndex, string headerKeyword)
{
int columnIndex = Headers.FindIndex(s => s.Contains(headerKeyword));
return CellOf(rowIndex, columnIndex);
}
第一个函数将在检查索引后组合一个 CSS 选择器,以调用底层 FindElement(),并具有正确的 <tr> 和 <td> 标签顺序。第二个函数将在调用第一个函数之前获取特定列标题的列索引。
第三个函数列在下面
public IWebElement CellOf(string headerKeyword, Func<string, bool> predicate)
{
int columnIndex = Headers.FindIndex(s => s.Contains(headerKeyword));
var allRows = FindElement().FindElementsByCss("tr").ToList();
if (WithHeaders)
{
allRows.RemoveAt(0);
}
foreach (var row in allRows)
{
var td = ((IWebElement)row).FindElementByCss(string.Format("td:nth-of-type({0})", columnIndex + 1));
if (predicate(td.Text))
return row;
}
return null;
}
它将搜索一个由其标题标识的列,以查找具有特定文本的列。
正如您所见,自动化测试中大多数常规操作都已封装在单个 Indexer() 中。这种方法避免了定义大量原子函数来对每个 IWebElement 执行简单功能,而是使用自解释的枚举成员来让人们推断其目标和功能;此外,通过一个“extraInfo”字符串,Indexer 的 Getter() 和 Setter() 可以支持丰富的一系列获取和设置操作。
将 Locators 组合在一起
在 通过枚举生成 CSS 选择器 中,介绍了基于枚举的 CSS 选择器生成机制。在 Locators:IWebElement 查找器和操作符 中,介绍了枚举成员的包装器,它们也是这些 CSS 选择器的使用者,而没有披露这些 CSS 选择器如何用于定位 IWebElements。然而,这些 Locators 本身并不足够有效,有时甚至不足以通过调用 WebDriver 的 IWebElement.FindElement() 来定位 IWebElement,因为这需要父 IWebElement 来执行。因此,并且也是为了有效地描述页面的文档树,我们需要一些 Locators 的容器:**Fragment** & **Page**,来构建一个层级树来描述它们之间的父子/兄弟关系。
Locator 容器:Fragment & Page
Web 页面的元素以层级方式组织为文档树:叶子 IWebElements,例如 <button>、<label>、checkbox(<input type=’checkbox’>) 和链接(<a>),由容器 IWebElements(如 <div>、<form> 或 <segement>)包含,这些容器 IWebElements 被它们的父级包含,直到 <body> 被 <html> 包含。以同样的方式组织 Locators 对于映射被测内容非常自然,这意味着应该有一些 Locators 像容器一样,像它们关联的 IWebElement 容器。在 TERESA 中,定义了两个这样的 Locators:**Fragment** 和 **Page**。
正如 Locator 的类图所示,Fragment 继承了 Locator,Page 继承了 Fragment,它们就像 HTML 页面中的 <html> 一样充当根容器。除了存储“Identifier”枚举和“Parent” Locator,并像普通 Locator 一样使用它们来查找 IWebElement 之外,Fragment 提供了两个重要功能来支持此框架:通过反射构建和保留其 Locator/Fragment 子项,并通过单一的 Indexer 接口路由子 Locator 的调用:string this[Enum theEnum, string extraInfo = null, Func<IWebElement, bool> filters = null]。
有一些实用方法支持通过反射保留子 Locator,GetNestedElementIds() 是其中最重要的一个。
protected static List<Enum> GetNestedElementIds(Type fragmentType)
{
if (fragmentType != FragmentType && !fragmentType.IsSubclassOf(FragmentType)
&& fragmentType != FragmentTypeInCallingAssembly && !fragmentType.IsSubclassOf(FragmentTypeInCallingAssembly))
throw new Exception("This shall only be called from Fragment classes");
var types = fragmentType.GetNestedTypes().Where(t => t.IsEnum).ToList();
if (types.Count == 0)
return null;
var result = new List<Enum>();
foreach (var type in types)
{
var enumValues = type.GetEnumValues().OfType<Enum>().ToList();
result.AddRange(enumValues);
}
return result;
}
此函数解析所有嵌套的枚举类型,并记录这些枚举类型的所有成员,这些成员稍后将用于构造 Locator/Fragment。**FragmentTypeInCallingAssembly** 是您项目中的 Fragment 类型,它与 TERESA 执行库中的 Fragment 类型仅 AppDomain 名称不同,它在 Fragment 的静态构造函数中进行初始化,其中使用 从堆栈跟踪获取调用程序集 技术来获取调用程序集。
与基类 Locator 相比,Fragment 具有两个额外的属性
-
public Dictionary<Enum, Locator> Children { get; protected set; } -
public virtual ICollection<Enum> FragmentEnums { get { return null; }}
ICollection<Enum> **FragmentEnums** 应被重写,以提供当前 Fragment 类之外定义的其他 Fragment 的枚举 ID,然后相应地构造 Fragment 实例,其 Parent 指向该 Fragment 实例;此外,这些 Fragment 实例及其子 Locator 会被 Dictionary<Enum, Locator> Children 保留。这个 Dictionary 存储了 Fragment 所引用的 IWebElement 内的所有 Locator,然后用于将 Index(**string this[Enum, string, Func<IWebElement, bool>]**)的调用路由到由 Enum ID 引用的 Locator 的 Index(**string this[string, Func<IWebElement, bool>]**)以执行预期的操作。
Fragment 的构造函数
- 不仅像普通的 Locator 那样实例化自己;
- 还创建其直接子 Locator/Fragments 的实例,以及在 中引用的外部 Fragments,并将这些 Locator/Fragments 初始化,将它们的 Parent 设置为自身。
这主要发生在 Populate() 函数中。
protected void Populate()
{
Type thisType = this.GetType();
//Load Enum Identifiers directly defined within this Fragment
var nestedIds = GetNestedElementIds(thisType);
if (nestedIds != null && nestedIds.Count != 0)
{
//No need to store a reference to Fragment itself
nestedIds.Remove(Identifier);
foreach (var id in nestedIds)
{
Locator childLocator = id.IsFragment() ?
new Fragment(id, this)
: Locator.LocatorOf(id, this);
Children.Add(id, childLocator);
}
}
//Load Enum Identifiers of the nested Fragment class
var nestedFragmentTypes = thisType.GetNestedTypes().Where(t => t.IsSubclassOf(FragmentType));
foreach (Type nestedFragmentType in nestedFragmentTypes)
{
Load(nestedFragmentType);
}
//Load Enum Identifiers from the Contained Fragments identified by their Enum IDs
if (FragmentEnums == null || FragmentEnums.Count == 0)
return;
foreach (Enum fragmentEnum in FragmentEnums)
{
Load(fragmentEnum);
}
}
它将调用 GetNestedElementIds() 来检索所有嵌套的枚举成员,除了标识此 Fragment 本身的成员之外,然后根据成员的 IsFragment() 创建新的 Fragment 或合适的 Locator 实例,然后将它们保存在“**Children**”字典中。对于嵌套的 Fragment 类型,将调用 Load(type) 来不仅实例化它们,还将这些 Fragments 和它们的子 Locators 保存在 Dictionary 中。最后,为了共享在父 Fragment 之外定义的 Fragments,“**FragmentEnums**”被枚举并使用 Load(Enum) 加载相应的子 Fragments。Load(Enum) 函数还使用反射来构造新实例,并用当前 Fragment 的 Parent 进行初始化。这样,通过 Fragment 类中定义的所有函数,您只需要在扩展自 Page 或 Fragment 的类中以层级方式定义枚举类型&成员,而无需一行可执行代码,即可获得一个 Locator 树。
Page 类,顾名思义,是 HTML 页面的自然映射,所以它的 Parent 为 null,Identifier 为 <html>。出于效率考虑,所有 Page 扩展类都在其静态构造函数中实例化,Page 实现 IEquatable<Uri> 接口,以通过与当前浏览器 URL 进行比较,自动选择正确的 Page 实例作为 **Page.CurrentPage**。为了使 Page 实例能够与多个 Web 内容一起使用(例如:google.com、google.com.uk 和 google.com.au 可以匹配到同一个 Page 实例),**bool Equals(Uri other)** 函数应被重写,并且 Page.CurrentPage 的切换将触发唯一的 Page 实例加载 ActualUri,该 ActualUri 可用于提取地址 Uri 的“?”之后的 QueryNameValues。
以下示例图显示了 Locators 如何在一些想象的页面/片段类中组织在一起。
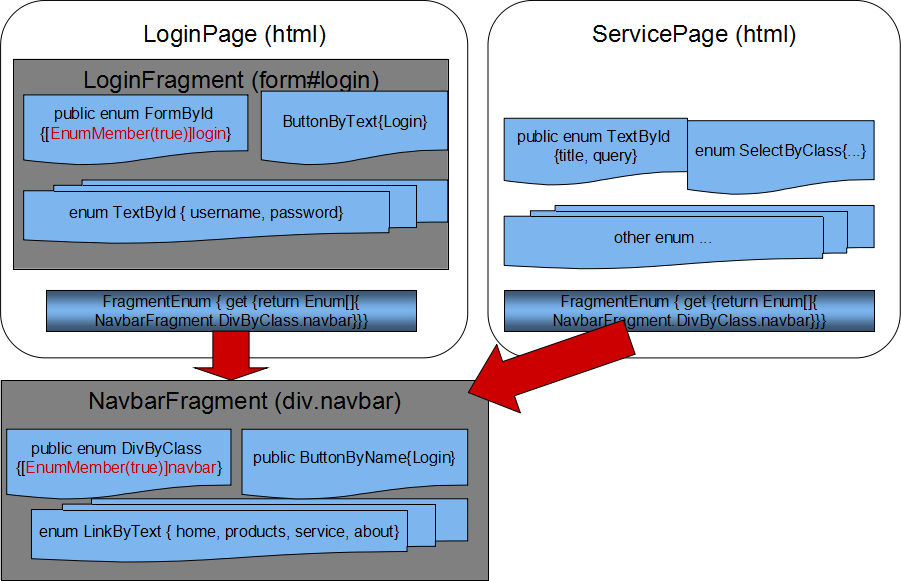
正如名称所示,LoginPage 和 ServicePage 都继承自 Page,而 LoginFragment 和 NavbarFragment 继承自 Fragment。这些 Fragment/Page 类是定义文档树的唯一场所,通过声明各种枚举成员,其类型名称遵循“**TagnameByMechanism”的模式,这些枚举成员随后用于构造 Locator 对象,并作为 Fragment/Page 的子项存储在 Enum 到 Locator 的字典(public Dictionary<Enum, Locator> **Children** { get; protected set; })中。
例如,“FormById.login”与包含用于输入密码和名称的 <input> 标签的 <form> 相关联,因为 EnumMemberAttribute 的 **IsFragment** 为“true”(如红色字体突出显示),它也是 LoginFragment 的 Locator。作为 LoginPage 的嵌套类,LoginFragment 的实例在构造阶段生成,并且可以通过其完整名称看起来像“LoginPage.LoginFragment.FormById.login”的枚举来访问。LoginPage 内部的 Locators 也是如此,例如 ButtonByText.Login 和 TextById.username:尽管 NavbarFragment 的构造函数只会为每个 Enum 初始化一个实例,但这些 Enum 和相应的 Locators 也存储在 LoginPage 和 ServicePage 中。
枚举类型名称除了帮助组合 CSS 选择器之外,隐含的 HtmlTagName 也用于提示可能不同的行为。例如,具有 <select> 标签的元素应支持通过点击或键入来选择一组选项,而尝试键入到链接中是没有意义的。枚举成员不是暴露为一种 Locator,而是可以用来创建最合适的 Locator 对象。例如,SelectLocator、TextLocator 或此示例中的普通 Locator 将为名称为 SelectByXYZ、TextByXYZ 和 ButtonByXYZ 的枚举构造。这些不同的 Locator 类型将通过调用 WebDriver 的 FindElement()/FindElements() 函数来查找 IWebElement,方法是使用与枚举成员嵌入的 CSS,但可能会执行不同的操作,即使函数相同。
您可能已经注意到,LoginPage 和 ServicePage 的 FragmentEnum 都引用了 NavbarFragment,它们都会实例化一个 NavbarFragment 实例,其 Parent 分别是 LoginPage 和 ServicePage。
因此,以 LoginPage 为例,Locators/Fragaments/Page 的逻辑关系如下:后代 Locators 保留其 Parent 信息,而父级 Locator(Fragment 或 Page)保留其所有直接/间接子项的引用,在“Dictionary<Enum, Locator> **Children**”中,因此父级 Locator 可以通过其 Enum Identifier 访问任何同级 Locator。

值得注意的是,Locator 只是查找 IWebElement 的手段的包装器,而不是 IWebElement 本身,即使有一个字段用于存储使用与枚举关联的 CSS 选择器找到的最后一个 IWebElement。这意味着您可以将任何枚举成员包含在 Page 中,即使没有元素可以用相应的 CSS 选择器找到,但只有当您尝试通过 WebDriver 函数查找 IWebElement 并对其进行操作时,您才会收到通知。
定位过程
在操作之前找到正确的 IWebElement 可能是使用 WebDriver 设计测试用例中最具挑战性的部分。现在是时候解释 TERESA 用来查找正确的 IWebElement 并对其执行预期操作的概念设计、逻辑过程和技术了。
唯一地定位 IWebElement
假设有一个继承自 Page 的 SomePage 实例,它有三层后代,其中一个最内层的子项是一个 Link,由 'enum3' 标识,CSS 选择器为 'a.class3',那么执行点击命令的过程如下图所示。

此命令组合为“SomePage[enum3]=”click”;如 设置操作 中所述,有 8 个步骤来完成它。
- Page 实例 SomePage 包含对其内部所有与枚举成员相关的 Locator 的引用,直接或间接,如我们在 Locator 容器:Fragment & Page 中所讨论的,因此它可以找到与 'enum3' 关联的 'Locator3' 并执行 locator[extraInfo, filters] = “click”。
- Locator3 将执行“IWebElement element = FindElement(filters);”来尝试获取与其自身关联的正确 IWebElement,但在使用“**a.class3**”的 CSS 选择器进行搜索之前,FindElement() 需要其父 IWebElement,该父 IWebElement 与 Fragment3 关联,即它的容器。
- Fragment3 由 Fragment2 包含,因此它会向其父级 Fragment2 提出相同的请求。
- Fragment2 尚未执行 FindElement(),意识到其父级实际上是根节点 <html>,它将直接调用 IWebDriver 的 FindElement(),并使用其 CSS 选择器“**div#container**”。由于“container”的 id 是唯一的,所以 IWebDriver 立即找到 <div1>。
- <div1> 作为对其在步骤 3 中请求的响应返回给 Fragment3。
- Fragment3 将调用 <div1> 的 FindElement() 而不是 IWebDriver,以将“part”id 的 <div> 元素搜索限制在有限范围内,因此即使 Fragment1 或 SomePage 还有其他 id 为“part”的 <div>,FindElement() of <div1> 也会返回其自身包含的那个。
- <div2> 作为对其在步骤 2 中请求的响应返回给 Locator3。
- 最后,在获取包含链接的 IWebElement <div2> 后,Locator3 将调用 <div2> 的 FindElement(),使用其 CSS 选择器“**a.class3**”来获取链接并执行“SomePage[enum3]=”click”;要求的点击操作。
在此命令执行期间,大多数步骤(步骤 2 - 步骤 8)仅在 Locator 类中定义的 FindElement() 函数中递归发生,如下所示。
public virtual IWebElement FindElement(Func<IWebElement, bool> filters = null, int waitInMills = DefaultWaitToFindElement)
{
//*/ Perform some simple operation to validate that the lastFoundElement is still valid
if (lastFoundElement != null && (filters == null || filters == lastFilters)
&& lastFoundElement.IsValid())
return lastFoundElement;
IWebElement parentElement = null;
if (Parent != null && ! Parent.Identifier.Equals(HtmlByCustom.Root))
{
parentElement = Parent.FindElement(filters, waitInMills);
if (parentElement == null || !parentElement.IsValid())
{
return null;
}
}
string css = Identifier.Css();
//When CSS matches multiple IWebElements, further selection shall be applied by filters
//Or, When selection is based on ByText mechanism, then EnumMember.Value is used
if (Identifier.IsCollection() || Identifier.Mechanism().Equals(Mechanisms.ByText))
{
Func<string, ReadOnlyCollection<IWebElement>> findFunc = (parentElement == null) ?
(Func<string, ReadOnlyCollection<IWebElement>>)DriverManager.FindElementsByCssSelector : parentElement.FindElementsByCss;
//Select the candidate element by calling FindElementsByCssSelector(css) of either the parentElement or the Driver
var candidates = WaitToFindElements(findFunc, css, waitInMills);
if (Identifier.IsCollection())
{
//Store the filters if it is not null, otherwise use the last filters
lastFilters = filters ?? lastFilters;
if (lastFilters == null)
throw new NullReferenceException();
var filtered = candidates.Where(lastFilters);
lastFoundElement = filtered.FirstOrDefault();
}
else
{
lastFoundElement = candidates.FirstOrDefault(item => item.Text.Equals(Identifier.Value()));
}
}
//When CSS select one IWebElement, then filter is ignored
//Notice the GenericWait.Until() would keeps running until timeout or no Exception is thrown
else
{
Func<string, IWebElement> find = (parentElement == null)
? (Func<string, IWebElement>)DriverManager.FindElementByCssSelector
: parentElement.FindElementByCss;
lastFoundElement = GenericWait<IWebElement>.TryUntil( () => find(css),
x => x != null & x.IsValid(), ImmediateWaitToFindElement );
}
//if(lastFoundElement == null)
// throw new NoSuchElementException("Failed to find Element by CSS: " + css);
//Keeps the moment of this opertion
//lastTick = Environment.TickCount;
return lastFoundElement;
}
此函数的第一块检查 IWebElement 是否已被定位,如果它仍然有效且无需再次查找,则仅返回最后找到的那个。
递归调用 Parent.FindElement(filters, waitInMills) 发生在代码的第二块中。
IWebElement parentElement = null;
if (Parent != null && ! Parent.Identifier.Equals(HtmlByCustom.Root))
{
parentElement = Parent.FindElement(filters, waitInMills);
if (parentElement == null || !parentElement.IsValid())
return null;
}
如果父级引用 <html>,则 parentElement 仍然为 null,它用于选择父级元素或 IWebDriver 的函数委托,如下所示。
Func<string, ReadOnlyCollection<IWebElement>> findFunc = (parentElement == null) ? (Func<string, ReadOnlyCollection<IWebElement>>)DriverManager.FindElementsByCssSelector : parentElement.FindElementsByCss;
或者
Func<string, IWebElement> find = (parentElement==null)?(Func<string, IWebElement>)DriverManager.FindElementByCssSelector:parentElement.FindElementByCss;
第一种选择发生在枚举标识符用于使用相同的 CSS 选择器定位多个 IWebElement 时,这将在 下一节 中介绍。当枚举标识符可以唯一地定位一个 IWebElement 并且在父级的范围内时,第二种委托用于定位 IWebElement 并将其保存到 lastFoundElement。
lastFoundElement = GenericWait<IWebElement>.Until(() => find(css), x => x != null & x.IsValid());
在像这种情况中,每个枚举 ID 唯一标识一个 IWebElement,不考虑搜索效率,除了直接调用 IWebDriver 的 FindElement() 之外,没有明显的其他好处。然而,当下一节中存在具有相同 ID、Class、Name 和属性的重复元素时,这种方法将显示其价值。
从集合中定位
面临的挑战
两个核心类,RemoteWebDriver 和 RemoteWebElement,都有两组方法(FindElementById/ClassName/Tag...),基于两种具有非常相似签名的签名。
-
protected IWebElement FindElement(string mechanism, string value)
-
protected ReadOnlyCollection<IWebElement> FindElements(string mechanism, string value)
第一个返回单个 IWebElement,而第二个可以通过“string mechanism”和“string value”定义的特定查找策略返回多个。
为了将这两个函数封装在 Locator 类中,在项目的前一个版本中,我还定义了两个函数委托来包装它们,签名如下。
-
public Func<string, Options, IWebElement> FindDelegate { get; protected set; } -
public Func<string, Options, IEnumerable<IWebElement>> FindAllDelegate { get; protected set; }
然后 Locator 只需要根据枚举标识符是表示一个唯一的 IWebElement 还是一个集合来初始化和调用其中一个。然而,这种直接的方法对我来说很尴尬:首先,通过单个 Indexer(**string this[Enum, string, Func<IWebElement, bool>]**)公开 IWebElement 的所有操作现在非常困难;第二,必须有额外的代码来从 FindAllDelegate 返回的 IEnumerable<IWebElement> 中选择一个,这意味着开发测试用例需要更多的工作;最后,获取 IWebElement 的集合实际上并不是真正需要的,因为我们通常只需要其中一个来操作。
从一组元素中查找并操作 IWebElement 的逻辑方法是
- 直接或间接调用 WebDriver 的 FindElements()(FindElementsById()、FindElementsByClass() 等);
- 执行一些选择标准,从返回的 ReadOnlyCollection<IWebElement> 中获取所需的 IWebElement;
- 然后对该 IWebElement 执行命令,或使用它来定位其子 IWebElement 以执行操作;
- 如果需要,重复步骤 1)- 3)。
通过检查上述过程和使用 FindElement() 来唯一标识 CSS 选择器来定位 IWebElement 的过程,似乎只需要一个 Predicate(Func<IWebElement, bool>)来满足从集合中选择一个的要求。但是如何将其传递给正确的 Locator/Fragment?
使用 Predicate 作为参数
答案来自定位 IWebElement 本身的过程,但首先让我们看一些关于 Predicate 的东西。
在步骤 2)中强制执行的标准与“**IWebElement FindElement(Func<IWebElement, bool> filters)**”和 Fragment 的 Indexer(**string this[Enum theEnum, string extraInfo=null, Func<IWebElement, bool> filters=null]**)的签名中出现的“**Func<IWebElement, bool> filters**”完全相同。此参数“**Func<IWebElement, bool> filters**”已在 FindElement() 的三个地方使用。
- 在代码的前两行中,检查是否已用于定位“**lastFoundElement**”,如果匹配标准未更改,则返回它。这部分用法将在 Google 搜索示例:由 Locator 缓存的 Filter 中讨论。
- 在以下几行中获取“**parentElement**”,此 Predicate 用于通过递归调用父 Fragment 的 FindElement() 来定位父 IWebElement。这非常重要,也解释了为什么参数名称是“**filters**”而不是“**filter**”:同一个 Predicate 将用于匹配目标 IWebElement 及其所有父容器。这将在 Google 搜索示例:用于多个 Locator 的 Filter 中显现。
- “filters”的消耗仅发生在“Identifier.IsCollection()”为 true 时,或者与 Identifier 关联的 Mechanism 是 Mechanisms.ByText 时,就像 Predicate 在 Where 和 FirstOrDefault 子句中的常见用法一样。
if (Identifier.IsCollection() || Identifier.Mechanism().Equals(Mechanisms.ByText))
{
Func<string, ReadOnlyCollection<IWebElement>> findFunc = (parentElement == null) ?
(Func<string, ReadOnlyCollection<IWebElement>>) DriverManager.FindElementsByCssSelector : parentElement.FindElementsByCss;
//Select the candidate element by calling FindElementsByCssSelector(css) of either the parentElement or the Driver
var candidates = WaitToFindElements(findFunc, css, waitInMills);
if (Identifier.IsCollection())
{
//Store the filters if it is not null, otherwise use the last filters
lastFilters = filters ?? lastFilters;
if (lastFilters == null)
throw new NullReferenceException();
var filtered = candidates.Where(lastFilters);
lastFoundElement = filtered.FirstOrDefault();
}
else
{
lastFoundElement = candidates.FirstOrDefault(item => item.Text.Equals(Identifier.Value()));
}
}
这些简单的代码行随后可以有效地用于定位每个 IWebElement,正如 Google 搜索示例在接下来的 6 个部分中演示的。
Google 搜索示例:引言
以 Google 搜索为例(也在教程部分中使用),解释 TERESA 中定位 IWebElement 的详细过程。在下图中,您可以看到显示的文本、HTML 源代码中的相应元素以及用于以不同颜色标识它们的枚举条目及其 CSS 选择器。

GooglePage.cs 的相关部分列出以显示枚举标识符是如何定义的。
public class GooglePage : Page
{...
public class ResultItemFragment : Fragment
{
public enum ListItemAllByClass
{
[EnumMember(true)]
g,
[EnumMember("action-menu-item")]
action_menu_item
}
public enum LinkByParent
{
[EnumMember("h3")]
Title,
//This is the Arrow right of the LinkAddress
[EnumMember("div.action-menu")]
DownArrow
}
public enum AnyByCustom
{
//Notice that the value starts with " " to compose CSS of "* cite" finally
[EnumMember(" cite")]
LinkAddress
}
public enum SpanByClass
{
[EnumMember("st")]
Description
}
}
}
此处解释了一些 IWebElements 及其枚举标识符。
- 每个结果项都包含在一个 ListItem <li class=”g”> 中,如红框所示,其枚举标识符为“**ListItemAllByClass.g**”。使用“ListItem**All**ByClass”而不是“ListItemByClass”作为类型名称,是因为存在多个类为“g”的 <li> 元素,并且它们可以使用相同的 CSS 选择器“li.g”来定位。类型名称“ListItemAllByClass”表示其“**IsCollection**”为“**true**”,如 通过枚举生成 CSS 选择器 中所述。此外,“[EnumMember(true)]g”表示“**g**”标识一个包含一些子 Locator 的 Fragment。
- <li class=”g”> 中包含五种类型的项,它们被故意定义了不同的 Mechanisms 枚举 ID,如下所示。
- LinkByParent.Title("h3" => CSS: **h3>a**): 每个结果的标题在蓝色框中;
- AnyByCustom.LinkAddress(" cite"=> CSS: **cite**): 标题下方显示地址的行。
- LinkByParent.DownArrow("div.action-menu"=> CSS: **div.action-menu>a**): 绿色框中可点击的向下箭头;
- SpanByClass.Description("st"=> CSS:span.st): 紫色框中的项目描述;
- ListItemAllByClass.action_menu_item(EnumMember("action-menu-item")=> CSS:li.action-menu-item): 包含可点击链接的容器,例如图片中显示的“Cached”和“Similar”。“ListItemAllByClass”中的“All”表示此枚举条目具有“IsCollection”=“true”,以演示更复杂的元素查找过程;
值得注意的是,在整个页面中可能匹配多个“Title”、“LinkAddress”、“Description”。但是,**在它们由“ListItemAllByClass.g”标识的容器内,它们是唯一的,因此可以通过调用父 IWebElement 的 FindElement() 来定位**,而不是 FindElements()。另一方面,尽管 ListItemAllByClass.action_menu_item 可以定义为“ListItemByText”,但它是一种很好的方式来展示如何在涉及多个 IWebElement 集合时使用 FindElement(),如 Google 搜索示例:用于多个 Locator 的 Filter 中所述。
当“**Func<IWebElement, bool> filters**”应用于目标 IWebElement 本身时,当它由 **IsCollection 为“true”** 的枚举标识时,FindElement() 的工作方式类似于 ReadOnlyCollection<IWebElement>>.Where(filters) 的简单包装器。然而,Fragment 可能并不指向我们真正打算操作的 IWebElement;更有可能的是,它只用作包含 Locator 来操作目标 IWebElement 的容器,就像本例中的 <li class=”g”> 一样。
现在假设我们需要点击由 Predicate“somePredicate”指定的结果项的链接,直接使用 WebDriver 的简化代码可能如下所示。
//Find all search result items returned as ReadOnlyCollection<IWebElement>
var resultItems = driver.FindElements(By.ClassName("g"));
//Find the IWebElement with the predicate
var oneItem = resultItems.FirstOrDefault(somePredicate);
//Search the IWebElement to find the link
IWebElement title = oneItem.FindElement(By.CssSelector("h3 > a"));
//Click it
title.Click();
使用 TERESA,只需要一行代码即可执行这 4 个步骤。
SomePage[GooglePage.ResultItemFragment.LinkByParent.Title, null,filters]="click";
在此单行代码中应注意:只引用了目标 IWebElement 的枚举 ID(**GooglePage.ResultItemFragment.SpanByClass.Description**),并且 Locator.FindElement() 的内部机制确保了 **filters (Func<IWebElement, bool>)** 实际上被其父级(ResultItemFragment,由 ListItemAllByClass.g 标识)所消耗,如下图所示。

调用流程与 中讨论的示例相同,注意“**filters**”(红色)是如何沿路线传递的。对于 Locator1,它将在步骤 2 中将“filters”转发给其父级(ResultItemFragment)。但因为它的 IsCollection 为 false,所以当它调用 IWebElement.FindElement(By.CssSelector(“h3>a”)) 来定位容器 <li.g> 元素内的唯一 IWebElement 时,不需要在步骤 5 中使用它。
Google 搜索示例:用于计数 IWebElements 的 Filter
通过调用 FindElements() 获取 ReadOnlyCollection<IWebElement>> 后,使用 Predicate 选择 IWebElement 的一个常见场景是按其在集合中的顺序进行选择。
例如,如果我们点击 Google 搜索的第二个结果项,那么简化的实现可能是
var resultItems = driver.FindElements(By.ClassName("g"));
//Find the second IWebElement with the predicate
var secondItem = resultItems.Where((x, index)=>index==2).FirstOrDefault();
//Search the IWebElement to find the link
IWebElement title = secondItem.FindElement(By.CssSelector("h3 > a"));
//Click it
title.Click();
“Where((x, index)=>index==2)” 使用的 Predicate 的签名是“Func<IWebElement, int, bool>”,而不是“Func<IWebElement, bool>”。为了支持这种从集合中定位一个元素的便捷方式,我甚至考虑过将 Indexer 的签名(string this[Enum, string, Func<IWebElement, bool>])替换为(string this[Enum, string, Func<IWebElement, int, bool>]),直到我找到了在 Utility.GenericPredicate.cs 中实现的那样,使用 Func<IWebElement, bool> 来完成 Func<IWebElement, int, bool> 工作的替代方法。
public class GenericPredicate<T>
{
public static Func<T, bool> IndexPredicateOf(int index) {
return new GenericPredicate<T>(index).Predicate;
}
public readonly int Index;
private int count = -1;
public Func<T, bool> Predicate {
get
{
return (T t) =>
{
count++;
return count == Index;
};
}
}
public GenericPredicate(int index)
{
Index = index;
}
}
这个 Generic 类的工厂方法会创建一个带有预设值“Index”的实例。每次调用 Predicate 时,“count”会加 1,只有当它在“Index”定义的预期次数被调用时才会返回“true”。对于上面的例子,要点击第二个结果项的链接,我们仍然可以使用一行代码(索引设置为 1,因为第一次调用会将“count”设置为 0)。
SomePage[GooglePage.ResultItemFragment.LinkByParent.Title, null, GenericPredicate<IWebElement>.IndexPredicateOf(1)]="click";
Google 搜索示例:涉及其他 IWebElement 的过滤器
虽然我们可以通过容器 IWebElement 的顺序来选择正确的操作目标,但更常见的是,容器本身可能不是应用“filters”的正确对象:可能需要检查其子 Locator 的某些内容以进行验证,此时 IWebElementExtension.cs 中的一些扩展方法可以获取“filters”,从而使任务更加轻松。
public static bool HasChildOf(this IWebElement element, Enum childEnum, Func<IWebElement, bool> predicate)
{
string childLocatorCss = childEnum.Css();
IWebElement child = null;
try
{
ReadOnlyCollection<IWebElement> candidates = null;
candidates = GenericWait<ReadOnlyCollection<IWebElement>>.Until(
() => candidates = element.FindElementsByCss(childLocatorCss),
x => x.Count != 0, 200);
var qualified = candidates.Where(predicate).ToList();
bool result = qualified.Count != 0;
return result;
}
catch (Exception)
{
return false;
}
}
public static bool HasChildOfText(this IWebElement element, Enum childEnum, string partialText)
{
return element.HasChildOf(childEnum, x => x.Text.Contains(partialText));
}
public static bool HasChildOfLink(this IWebElement element, Enum childEnum, string partialText)
{
Func<IWebElement, bool> predicate = (x) =>
{
string link = x.GetAttribute("href");
return link.Contains(partialText);
};
return element.HasChildOf(childEnum, predicate);
}
HasChildOf(Enum childEnum, Func<IWebElement, bool> predicate) 提供了一个统一的接口来检查由 childEnum 标识的 IWebElement 是否满足 predicate 的条件。HasChildOfText(Enum childEnum, string partialText) 和 HasChildOfLink(Enum childEnum, string partialText) 分别指定了用于检查 Text 和“href”属性的 predicate。
例如,参考 Google 搜索示例:简介 中截取的图片,假设我们希望点击以“stackoverflow.com”开头的链接,而不是结果项标题中出现的文本(“WebDriver : Compilation ...”),那么仍然只需一行代码即可完成。
SomePage[GooglePage.ResultItemFragment.LinkByParent.Title, null, (e) => e.HasChildOfText(GooglePage.ResultItemFragment.AnyByCustom.LinkAddress,"stackoverflow.com")] = "click";
LINQ 组成的 Predicate 意味着:只有包含子元素的 IWebElement,可以通过与 ResultItemFragment.AnyByCustom.LinkAddress 关联的 CSS 选择器找到,并且该子元素包含“stackoverflow.com”文本,才会返回“true”。
调用流程与 Google 搜索示例:简介 中讨论的相同。即使“LinkByParent.Title” Locator 本身忽略了这些过滤器,它也会将其转发给其父项 ResultItemFragment。后者将使用此 Predicate 检查每个结果项容器,每个容器将使用 CSS“AnyByCustom.LinkAddress”调用其 FindElements() 来查看是否有任何一个具有“stackoverflow.com”文本,然后再返回“true”或“false”。最后,与 ResultItemFragment 关联的第一个匹配的 <li.g> 将使用 CSS“LinkByParent.Title”调用 FindElement() 并执行点击操作。
这段代码背后涉及相当多的定位和匹配操作,但现在可以通过它们的 Enum 标识符来引用这些 IWebElement,这可能足以让您猜测其意图。
Google 搜索示例:带缓冲的过滤器
在 将 Predicate 用作参数 中,提到了 Predicate“Func<IWebElement, bool> filters”在三个块中使用,首先用于检查“lastFoundElement”是否已使用相同的过滤器定位,以避免不必要的定位。Locator 中的相关代码如下所示:
protected IWebElement lastFoundElement = null;
private Func<IWebElement, bool> lastFilters = null;
...
public virtual IWebElement FindElement(Func<IWebElement, bool> filters = null, int waitInMills = DefaultWaitToFindElement)
{
if (lastFoundElement != null && (filters == null || filters == lastFilters)
&& lastFoundElement.IsValid())
return lastFoundElement;
...
if (Identifier.IsCollection() || Identifier.Mechanism().Equals(Mechanisms.ByText))
{
...
if (Identifier.IsCollection())
{
//Store the filters if it is not null, otherwise use the last filters
lastFilters = filters ?? lastFilters;
if (lastFilters == null)
throw new NullReferenceException();
var filtered = candidates.Where(lastFilters);
lastFoundElement = filtered.FirstOrDefault();
}
else
{
lastFoundElement = candidates.FirstOrDefault(item => item.Text.Equals(Identifier.Value()));
}
}
//When CSS select one IWebElement, then filter is ignored
else
{
Func<string, IWebElement> find = (parentElement == null)
? (Func<string, IWebElement>)DriverManager.FindElementByCssSelector
: parentElement.FindElementByCss;
lastFoundElement = GenericWait<IWebElement>.TryUntil( () => find(css),
x => x != null & x.IsValid(), ImmediateWaitToFindElement );
}
return lastFoundElement;
}
lastFoundElement 由 Locator 用于缓存调用 FindElement(Func<IWebElement, bool>, int) 定位的最后一个 IWebElement,而 lastFilters 仅由 IsCollection 为“true”的 Locator 使用,以保留最近的 Predicate。有了这样的设计,如果 lastFoundElement 仍然有效(通过检查它是否显示),并且在提供了新的过滤器时没有新的过滤器(当 lastFilters 已经保留了一个时),那么就不需要执行新的定位,并且会立即返回 lastFoundElement。
这种设计不仅提高了性能和效率,还可以使测试用例开发更加便捷。当我们在一个页面上进行测试时,通常是批量进行的。例如,当我们尝试向一个包含许多行 (<tr>) 的 <table> 输入数据时,并且每一行都有多个单元格 (<td>) 需要填写,那么我们自然而然地会在移动到下一行之前填写完一行的所有单元格。使用 WebDriver,这意味着首先保留行 IWebElement,然后使用其 FindElement() 定位其子单元格以执行操作。TERESA 中也发生着同样的事情,但这是在后台进行的。
现在假设在点击以“stackoverflow.com”开头的链接之前,我们希望高亮显示定位的源(结果项标题下的链接地址),如下所示,然后再点击显示“WebDriver : Compilation error...”的链接。

这时需要两行代码。
SomePage[GooglePage.ResultItemFragment.AnyByCustom.LinkAddress, null, (e) => e.HasChildOfText(GooglePage.ResultItemFragment.AnyByCustom.LinkAddress,"stackoverflow.com")] = "highlight";
SomePage[GooglePage.ResultItemFragment.LinkByParent.Title] = "click";
第一行通过调用 IWebElementExtension.cs 中定义的 IWebElement.HighLight() 来改变由“AnyByCustom.LinkAddress”标识的 IWebElement 的背景和边框样式。“filters”仅被 IsCollection 为“true”的 Locator 使用,因此链接标识符将忽略它,并且 LINQ 必须使用“HasChildOfText()”而不是“string.Contains()”。
值得注意的是,第二行代码非常简洁,没有使用任何“filters”来定位高亮项上方的链接。这是因为当“LinkByParent.Title”的 Locator 调用 FindElement() 时,FindElement() 会递归调用其父项 ResultItemFragment。在 ResultItemFragment 中,由于上一行代码已经触发了其 FindElement() 并将“(e) => e.HasChildOfText(AnyByCustom.LinkAddress,"stackoverflow.com")”的“filters”存储在“lastFilters”中,所以第一个 FindElement() 调用:“if (lastFoundElement != null && (filters == null || filters == lastFilters) && lastFoundElement.IsValid())” 为“true”,因此函数直接返回存储在 lastFoundElement 中的 IWebElement 作为结果。
通过这种方式,在定位了 IsCollection=”true”的 Enum 标识的容器内的 IWebElement 后,您无需提供相同的“filters”即可访问该容器内的另一个 IWebElement。就像此示例中的“高亮”效果一样:只需额外一行代码,就可以让浏览器更明显地显示测试进度,甚至在 UAT 中给客户留下深刻印象,而无需付出太多额外努力。
Google 搜索示例:多个 Locators 的过滤器
在 将 Predicate 用作参数 中,我提到相同的 Predicate 将用于匹配目标 IWebElement 及其所有父容器。现在我将解释为什么 Predicate 被命名为“filters”而不是“filter”,并再次使用 Google 搜索示例来展示如何使用它来选择需要调用 WebDriver 的 FindElements() 的两种不同类型的 IWebElement。
在 GooglePage.cs 中,“ListItemAllByClass”的 Enum 类型定义如下:
public class GooglePage : Page
{...
public class ResultItemFragment : Fragment
{
public enum ListItemAllByClass
{
[EnumMember(true)]
g,
[EnumMember("action-menu-item")]
action_menu_item
}
...
}
}
正如在“CSS 选择器从 Enum 生成”中所讨论的,“ListItemAllByClass”中的关键字“All”将被解释为“IsCollection = true”,其成员“g”和“action_menu_item”用于定位两个 IWebElement 集合,如下图所示:

请注意,尽管“ListItemAllByClass.g”定义在 ResultItemFragment 中,但其属性定义(“[EnumMember(true)]”)将其标记为 ResultItemFragment 本身的标识符。在初始化过程中,“ListItemAllByClass.g”不会出现在 ResultItemFragment 的子项中,而只会出现在 GooglePage 的 Children 字典中,因此它将仅用于调用 IWebDriver 的 FindElements() 来根据“filters”定位正确的 ResultItemFragment。
如果我们尝试点击图片中高亮显示的“Similar”菜单项,则可以执行以下代码:
Func<IWebElement, bool> predicate = (e) =>
{
return e.HasChildOfText(GooglePage.ResultItemFragment.AnyByCustom.LinkAddress,
"stackoverflow.com") || e.Text == "Similar";
};
Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.DownArrow, null, predicate] = "click";
Page.CurrentPage[GooglePage.ResultItemFragment.ListItemAllByClass.action_menu_item, null, predicate] = "click";
“predicate”被定义为由两部分组成:第一部分用于匹配 LinkAddress,如前一节所述;第二部分用于查找文本为“Similar”的 Action Menu Item。为了更清晰,可以定义“predicate”如下:
Func<IWebElement, bool> predicate = (e) =>
{
string elementClass = e.GetAttribute("class");
return (elementClass=="g" && e.HasChildOfText(GooglePage.ResultItemFragment.AnyByCustom.LinkAddress, "stackoverflow.com") || (elementClass.Contains("action-menu-item") &&e.Text == "Similar"));
};
因为“filters”总是被每个 Locator 使用,并在调用“IWebElement FindElement(Func<IWebElement, bool>, int)”时作为参数传递给其父项,所以沿途的每个 Locator 都可以:如果 Locator 的 IsCollection=’false’,则忽略它;如果 IsCollection=’true’,则在 Where() 子句中使用它并将其保存到“lastFilters”。因此,您可以并且必须定义 predicate 来过滤此示例中的 BOTH 结果项(图片中的粉色块)和菜单项(蓝色框),才能实现对“Similar”项的点击。
还需要强调的是,在操作“ListItemAllByClass.action_menu_item”时,最后一行代码不能省略“null, predicate”,因为当点击“LinkByParent.DownArrow”时,关联的 Locator 尚未被访问,因此无法将“filters”作为参数保存到局部变量“lastFilters”中。结果,无法在此示例中决定是选择“Similar”还是“Cached”项。
正如您所见,TERESA 提供了一种简单的方法来处理一些最困难的元素查找,以及一个 Indexer 作为统一的接口,将查找元素和操作元素合并在一句话中。
教程
本部分介绍如何通过概述构建新项目的步骤,演示 Facebook 示例中的基本操作,以及 Google 搜索示例中的更高级功能,来使用 TERESA 简化自动化测试。
使用 TERESA 的步骤
在此我假设您有一些使用 WebDriver 和 NUIT 开发 UAT 用例的经验。
与直接使用 WebDriver 的方式类似,您可能需要遵循以下步骤来构建一个新项目来测试网页:
- 检查待测网页,高亮用于获取或设置的元素,并获取区分它们的关键信息,以便组合 CSS 选择器。对于不熟悉 CSS 选择器的用户,必须记住的 30 个 CSS 选择器 是一个介绍 TERESA 中使用的所有机制的好文章。
- 如果“id”、“class”在整个页面或您用 Enum(IsCollection=”true”)识别的某个片段中是唯一使用的,那么它们是最佳选择;
- 对于那些出现在更容易定位的其他元素之下或邻近的元素,使用它们与更重要的元素的关系有时非常可靠。
- 如果目标元素要映射到 Locator 实例而不是 TexLocator/SelectLocator/...,并且它们是其容器唯一可见的子项,那么定位父项就足以支持“click”、“hover”和“highlight”等操作。前面章节中的“ListItemAllByClass.action_menu_item”是一个很好的例子,对它引用的 IWebElement 的“click”操作实际上发生在它唯一的子元素 <a class=”f1” href=...> 上。
- 一些常用的属性,如“name”/“href”/“value”,在显示定位的含义或原因时非常有帮助,特别是当您有一些代码使用它们时。
- 有时,元素可能缺乏区分它们的显著特征,这时其他不常用的属性可能会非常有用。例如,导航栏项通常具有由“onclick()”定义的、可通过调用 IWebElement.GetAttribute(string) 访问的不同功能,然后后面的关键字可以直接复制用于定位,并具有清晰的意图。
- 您可能会遇到的另一种情况是,当一系列非常相似的元素以固定顺序定位时,而它们的文本、类名、值要么完全相同,要么随文化而变化,就像 Google 搜索结果上方的导航栏一样。那么使用它们的顺序可以非常方便地避免不时修改 CSS 选择器。
- 有时,您还需要根据元素的文本来定位它,尽管 CSS 选择器不支持这一点,但作为一种有效的方式,它仍然可以被考虑。
- 然后您需要定义一个 Enum 类型/成员的树,该树包含在一个扩展自 Page 类的类中。 HtmlTagName 和 Mechanisms 的快速参考可能有助于您决定定位策略。
- 通常,您不需要实现任何其他函数或构造函数,只需实现“Uri SampleUri”属性,您可以指定要测试的目标页面的地址。
- Enum 类型,遵循“CSS 选择器从 Enum 生成”中讨论的规则,用于标识元素类型和使用的机制(格式为“TagnameByMechanism”或“Tagname
AllByMechanism”),应定义为扩展 Page 类的嵌套类型,就像嵌套在网页中的目标元素一样。 - 这些 Enum 类型的每个成员都用作网页中目标元素的标识符和定位相应 IWebElement 的 CSS 选择器。您可以使用有意义的字符串作为它们的名称,但必须在 EnumMemberAttribute 中包含 CSS 选择器机制所需的关键字。此外,如果 Enum 成员用于标识一个 Fragment(一个特殊的 Locator,充当其子 Locator 的容器),则还应在其 EnumMemberAttribute 中明确“IsFragment=true”。
- 注意:这些 Enum 成员生成的 Locator 是用于查找某种 IWebElement 的工具的包装器,而不是 IWebElement 本身。因此,您可以自由地定义具有不同机制的多个 Enum 成员来定位一个 IWebElement,或者您可以在此 Page 文件中定义任何 Enum 成员,即使它们的 CSS 选择器只能在其他网页中使用,只要您不尝试使用它们来定位不存在的 IWebElement。
- 最后是时候设计测试用例了,获取操作和设置操作的快速参考可能会有用。
- 目标页面的唯一接口:Indexer(string this[Enum theEnum, string extraInfo = null, Func<IWebElement, bool> filters = null])将简单地选择由“Enum theEnum”标识的 Locator,然后使用其唯一的 Indexer 接口(string this[string extraInfo, Func<IWebElement, bool> filters = null])来执行在获取操作和设置操作中介绍的任何操作,并且总是优先使用。例如,Getter() 的调用如下将获取文本输入元素的“style”:
string attribute = Page.CurrentPage[GooglePage.TextByName.textToBeSearched, "style"];
而以这种方式使用 Setter() 将点击一个文本为“Web”的链接。
Page.CurrentPage[SearchNavFragment.LinkByText.Web] = "click";
- 尽管总是优先使用 Indexer,但 TERESA 可能尚未支持 WebDriver 的某些功能。但是,您仍然可以使用基于 Locator 的机制来查找 IWebElement 并直接对其执行操作。要执行上述点击操作,可以使用以下代码:
Locator web = Page.CurrentPage.LocatorOf(SearchNavFragment.LinkByText.Web);
IWebElement element = web.FindElement();
element.Click();
接下来,我将通过两个示例向您展示如何一步一步使用 TERESA。
Facebook 注册中的基本操作
此示例旨在演示通过使用 Page 实例的唯一 Indexer 接口(string this[Enum theEnum, string extraInfo, Func<IWebElement, bool> filters = null])支持的基本获取/设置操作。
标记页面源代码
正如截取的图片所示,此示例中要使用的大多数元素都已根据源代码和 Enum 标识符进行了标记。

映射元素的 Page 类
然后我们需要定义一个 FacebookPage 类,遵循“组织 Locators 在一起”的指南,如下所示:
public class FacebookLoginPage : Page
{
public override Uri SampleUri
{
get { return new Uri("https://#"); }
}
public enum TextByName
{
firstname,
lastname,
[EnumMember("reg_email__")]
regEmail,
[EnumMember("reg_email_confirmation__")]
regEmailConfirmation,
[EnumMember("reg_passwd__")]
regPassword
}
public enum SelectById
{
month,
day,
year
}
//For demo purposes: to show how different Css Selector can be used to cope with complex cases
public enum RadioByCustom
{
[EnumMember("[name='sex'][value='1']")]
female,
[EnumMember("span#u_0_g span:nth-of-type(2) input")]
male
}
public enum LabelByText
{
Female,
Male
}
//For demo purposes: ByText should always be avoided
public enum ButtonByText
{
[EnumMember("Sign Up")]
SignUp
}
}
它仅包括重写的“Uri SampleUri”属性以及一系列 Enum 类型及其成员。对于五个文本框(<input type=”text”...> 类似于“First Name”),有三种直接便捷的方式来构建 CSS 选择器:ID“u_0_1”,名称“firstname”,以及属性“aria-label”=”First Name”。“aria-label”对我来说似乎不是一个流行的属性,所以我尽量避免使用它。尽管 Mechanisms.ById 总是首选,但“u_0_1”的含义过于模糊,因此所有五个元素都需要手动定义一个有意义的名称。所以最后,我选择 Mechanisms.ByName,为这五个文本输入字段 collectively 定义 Enum 类型名称为“TextByName”。然后我直接复制“firstname”和“lastname”的名称作为其成员,但对于剩余的三个(“Your Email”、“Re-enter Email”和“New Password”),它们的“name”属性看起来太长了,所以我做了一些额外的工作,定义了“regEmail”、“regEmailConfirmation”和“regPassword”来传达“reg_email__”、“reg_email_confirmation__”和“reg_passwd__”的真实值。
对于“Birthday”的三个 select 输入,它们的 ID “month”、“day”和“year”非常适合直接复制粘贴,所以我将它们定义在一个新的 Enum 类型“SelectById”中。
对于“Female”和“Male”两个单选按钮,定义了两个 Enum 集合来分别定位单选按钮本身和附带的标签。尽管直接使用 ID(“u_0_d”和“u_0_e”)非常方便,但这里使用了 Mechanisms.ByCustom 来展示如何自己定义整个 CSS 选择器。“Female”单选元素被赋值为“[name='sex'][value='1']”,而“Male”被赋值为“span#u_0_g span:nth-of-type(2) input”。但是,您必须确保 CSS 选择器指向 <input type=”radio”> 元素。我花了相当长的时间,因为我忘了在第二个值后面附加“input”,结果,“Male”可以被选中,但“Selected”始终返回“False”。
总之,这基本上就是您需要为被测试页面上的每个元素定义定位策略的操作。现在我将解释在附加的“TERESAExample”项目中的“FacebookLoginTest.cs”中执行基本获取/设置操作的步骤。
获取/设置代码
第一块代码旨在演示如何读取由其 Enum 标识符定位的目标 IWebElements 的属性/值,如下所示:
//When "extraInfo" is missing, the default value of "null" would make Locator return its text
string valueString = Page.CurrentPage[FacebookLoginPage.ButtonByText.SignUp];
Assert.AreEqual(valueString, "Sign Up");
//To verify the Indexer can get the "class" attribute appeared within the button
valueString = Page.CurrentPage[FacebookLoginPage.ButtonByText.SignUp, "class"];
Assert.AreEqual(valueString, "_6j mvm _6wk _6wl _58mi _3ma _6o _6v");
//Assure no exception is throw when querying a meaningless "extraInfo",
// which would call IWebElement.GetAttribute() and returns null
valueString = Page.CurrentPage[FacebookLoginPage.ButtonByText.SignUp, "non-existed"];
Assert.IsNull(valueString);
//verify the name of the element is accessible
valueString = Page.CurrentPage[FacebookLoginPage.TextByName.firstname, "name"];
Assert.AreEqual("firstname", valueString);
//verify the Css selector is composed as expected
valueString = Page.CurrentPage[FacebookLoginPage.TextByName.firstname, "css"];
Assert.IsTrue(valueString.Contains(@"input[type][name*='firstname']"));
//verify the ParentCss() returns null when the Enum is defined directly in a page
valueString = Page.CurrentPage[FacebookLoginPage.TextByName.firstname, "parentcss"];
页面实例的 Indexer(string this[Enum theEnum, string extraInfo, Func<IWebElement, bool> filters = null])的含义和用法可以在“获取操作”中找到。通过 Indexer 进行的这些获取操作的输出如下:
"Sign Up"=[TERESAExample.Pages.FacebookLoginPage+ButtonByText.SignUp]; "_6j mvm _6wk _6wl _58mi _3ma _6o _6v"=[TERESAExample.Pages.FacebookLoginPage+ButtonByText.SignUp, "class"]; ""=[TERESAExample.Pages.FacebookLoginPage+ButtonByText.SignUp, "non-existed"]; "firstname"=[TERESAExample.Pages.FacebookLoginPage+TextByName.firstname, "name"]; " input[type][name*='firstname'], textarea[name*='firstname']"=[TERESAExample.Pages.FacebookLoginPage+TextByName.firstname, "css"]; ""=[TERESAExample.Pages.FacebookLoginPage+TextByName.firstname, "parentcss"];
第二部分用于向五个文本框输入数据。请注意,您仍然可以使用 TERESA 仅用于定位 IWebElement,然后直接封装对 IWebElement 的操作,正如将“Tom”输入“First Name”的清晰示例所示。
Page.CurrentPage[FacebookLoginPage.TextByName.firstname] = "Jack";
//With extraInfo="sendkeys" to call IWebElement.SendKeys() via Indexer of the Locator class
Page.CurrentPage[FacebookLoginPage.TextByName.firstname, "sendkeys"] = "Tom";
Assert.AreEqual("JackTom", Page.CurrentPage[FacebookLoginPage.TextByName.firstname]);
//Example to show how to use the locating mechanism to find the element and perform operation in traditional way
Locator firstNameLocator = Page.CurrentPage.LocatorOf(FacebookLoginPage.TextByName.firstname);
IWebElement firstNameElement = firstNameLocator.FindElement();
firstNameElement.Clear();
firstNameElement.SendKeys("Tom");
Page.CurrentPage[FacebookLoginPage.TextByName.lastname] = "Smith";
Page.CurrentPage[FacebookLoginPage.TextByName.regEmail] = "youremail@hotmail.com";
Page.CurrentPage[FacebookLoginPage.TextByName.regEmailConfirmation] = "youremail@hotmail.com";
Page.CurrentPage[FacebookLoginPage.TextByName.regPassword] = "Password#$@0";
第三部分演示了如何通过 SendKeys() 操作 <input type=”select”>,文本出现、值或索引,如在“特殊 Locators 的更定制化操作”中所讨论的。
最后一部分处理两个单选按钮和“Sign Up”按钮,如下所示:
//Choose radio by clicking associated lable
Page.CurrentPage[FacebookLoginPage.LabelByText.Female] = "true";
Assert.AreEqual(true.ToString(), Page.CurrentPage[FacebookLoginPage.RadioByCustom.female, "selected"]);
Assert.AreEqual(false.ToString(), Page.CurrentPage[FacebookLoginPage.RadioByCustom.male]);
//Choose radio directly
Page.CurrentPage[FacebookLoginPage.LabelByText.Male] = "true";
Assert.AreEqual(true.ToString(), Page.CurrentPage[FacebookLoginPage.RadioByCustom.male, ""]);
//Click the sign-up button
Page.CurrentPage[FacebookLoginPage.ButtonByText.SignUp] = "true";
如您所见,上述每行代码都可以通过调用 Indexer 及其 Enum 标识符来对特定元素执行一组获取/设置操作,封装了 FindElement()/SendKeys()/Click()/GetAttributes 等原子操作。由于 Enum 类型名称上强制执行了严格的规则,您可以避免手动组合 CSS 选择器,并且具有有意义的 Enum 成员名称,其他人应该很容易猜测出这些代码的含义。
在此示例中,所有 Enum 类型都直接定义在 FacebookPage 类中,而不是嵌套在某个 Fragment 类中,并且这些 Enum 成员用于标识唯一的元素,因此不会调用 WebDriver 的 FindElemenets()。在下一个示例中,我将使用 Google 搜索来展示如何利用这个框架以及更高级的技巧。
Google 搜索中的高级用法
大多数示例操作已在“使用 Locators 定位 IWebElement”中讨论过。
映射元素的类
为了演示 Locator 树的分层结构,如“组织 Locators 在一起”中所讨论的,GooglePage 实例中包含两个 Fragment:SearchNavbarFragment 和 ResultItemFragment。前者通过其 Enum 标识符“SearchNavFragment.DivById.hdtb”引用“ICollection<Enum> FragmentEnums”,并定义在一个单独的文件中,用于映射搜索结果上方的按钮式链接,如下所示:
public class SearchNavFragment : Fragment
{
public enum DivById
{
[EnumMember(true)]
hdtb
}
public enum DivByCustom
{
[EnumMember(".hdtb_mitem:nth-of-type(1)")]
Web,
[EnumMember(".hdtb_mitem:nth-of-type(2)")]
Images,
[EnumMember(".hdtb_mitem:nth-of-type(3)")]
Videos,
[EnumMember(".hdtb_mitem:nth-of-type(4)")]
Shopping,
[EnumMember(".hdtb_mitem:nth-of-type(5)")]
News,
[EnumMember(".hdtb_mitem:nth-of-type(6)")]
More,
[EnumMember(".hdtb_mitem:nth-of-type(7)")]
SearchTools
}
public enum LinkByText
{
Web,
Images,
Videos,
Shopping,
News,
More,
[EnumMember("Search tools")]
SearchTools
}
}
正如您可能已经注意到的,Enum 类型 DivByCustom 和 LinkByText 共享一组相同的成员。实际上,如果您只需要点击链接,那么 DivByCustom 可以更安全地使用,因为 LinkByText 标识的链接在被点击时会消失。但是,使用简单的“tryclick”机制并检查其是否成功可能是一个优雅的选择,如后面所述。
ResultItemFragment,正如我们在“Google 搜索示例:简介”中讨论过的,定义了结果项,正如截取的图片所示:

GooglePage 类还定义了一些 Enum 类型作为其子项,如下所示:
public class GooglePage : Page
{
public enum TextByName
{
[EnumMember("q")]
textToBeSearched
}
public enum LinkByClass
{
[EnumMember("gsst_a")]
SearchByVoice
}
public enum ButtonByName
{
[EnumMember("btnK")]
SearchBeforeInput,
[EnumMember("btnG")]
Search,
}
public enum LinkByUrl
{
[EnumMember("options")]
Options,
[EnumMember("Login")]
Login
}
public enum LinkById
{
[EnumMember("pnnext")]
Next
}
public class ResultItemFragment : Fragment
{
...
}
public override ICollection<Enum> FragmentEnums
{
get { return new Enum[]{SearchNavFragment.DivById.hdtb}; }
}
public override Uri SampleUri
{
get { return new Uri("http://www.google.com/"); }
}
public override bool Equals(Uri other)
{
return other.Host.Contains("google.com");
}
...
}
有了这个结构,像 SearchNavFragment 这样的共享 Fragment 可以被多个 Page 类共享,尽管每个 Page 实例都需要构建它自己的一个实例来指向 Page 本身。同时,嵌入的 Fragment 也会通过 Reflection 技术构建。通过将 Enum 类型放在不同的 Page/Fragment 中,它们的 Enum 成员以分层的方式组织起来,因此通过 Reflection 技术生成的 Locators 将呈现一个精确的分层模式,从而能够使用 IWebElement.FindElement() 而不是 IWebDriver.FindElement()。
还需要提到的是,当我尝试打开“http://www.google.com/”时,浏览器会被重定向到“http://www.google.com.au/”。所以,我不得不覆盖默认的 Equals(Uri) 方法,以便该 Page 可以在任何地方使用。
获取/设置代码
为了演示定位机制,我包含了两个测试用例,您可以在“GoogleSearchTest.cs”中找到源代码。第一个测试“public void SearchTest()”的代码按顺序在此处解释。
前三个句子:
Page.CurrentPage[GooglePage.TextByName.textToBeSearched] = "WebDriver wrapper";
Assert.AreEqual("WebDriver wrapper", Page.CurrentPage[GooglePage.TextByName.textToBeSearched]);
Page.CurrentPage[GooglePage.TextByName.textToBeSearched, "highlight"] = "";
它们用于展示输入关键字并确认后,如何使用 IWebElementExtension.cs 中定义的“HighLight(string)”以 JavaScript 高亮目标元素。

应该注意的是,对文本框执行“highlight”的格式与其他 Locators 不同,实际上 TextLocator 会交换“value”和“extraInfo”字符串参数,然后调用 Locator 类的 Setter,输出如下:
[TERESAExample.GooglePages.GooglePage+TextByName.textToBeSearched]="WebDriver wrapper";
"WebDriver wrapper"=[TERESAExample.GooglePages.GooglePage+TextByName.textToBeSearched, "value"];
[TERESAExample.GooglePages.GooglePage+TextByName.textToBeSearched]="highlight";
输入关键字后,现在我们必须点击蓝色按钮。但是,这个按钮与空白页面上出现的“Google Search”按钮(名称为“btnK”)是完全不同的,这个按钮的名称是“btnG”。假设您需要执行某个操作但无法保证其成功,那么“try”+“action”可以用来避免抛出异常。
Page.CurrentPage[GooglePage.ButtonByName.SearchBeforeInput] = "tryclick";
if (!Page.LastTrySuccess)
Page.CurrentPage[GooglePage.ButtonByName.Search] = "click";
“tryclick”会失败,因为由“ButtonByName.SearchBeforeInput”标识的按钮已不存在。通过检查“Page.LastTrySuccess”,我们可以确认它失败了,然后“click”与“ButtonByName.Search”关联的按钮,这将成功。
Page.CurrentPage[GooglePage.LinkByClass.SearchByVoice] = "hover";
//Scroll page to bottom to show the link of "Next"
Page.CurrentPage[GooglePage.LinkById.Next] = "show";
以上两个句子只是用于展示 Hover() 和 Show() 的效果。第一个句子会将鼠标悬停在麦克风图片上,然后会出现“Search by voice”。“Next”按钮通常在页面的最底部,可以通过脚本滚动页面到底部使其可见。
Assert.Catch<NoSuchElementException>(() =>
Page.CurrentPage[SearchNavFragment.LinkByText.Web] = "click");
Page.CurrentPage[SearchNavFragment.LinkByText.Web] = "tryclick";
Page.CurrentPage[SearchNavFragment.DivByCustom.Web] = "click";
如前所述,与 LinkByText.Web 相关的链接“<a>”在像 Google 这样的动态页面中不存在,因此点击它会抛出 NoSuchElementException。但是,您始终可以点击与 DivByCustom.Web 关联的空容器,这样什么也不会发生,或者就像您点击了一个链接一样。在不存在的元素上执行“tryclick”命令,比如 LinkByText.Web 标识的链接,是安全的,尽管需要一些时间来等待其执行。顺便说一句,如果您更喜欢直接使用 Locator 实例,Locator 中的两个函数(bool TryExecute(string, string, Func<IWebElement, bool>) 和 IWebElement TryFindElement(Func<IWebElement, bool>, int))可以获得类似的结果。
到目前为止,“Func<IWebElement, bool> filters”的 Indexer(string this[Enum theEnum, string extraInfo, Func<IWebElement, bool> filters = null])还没有被使用。但以下代码将向您展示它如何有助于处理集合元素/容器。
以下几行代码用于展示当“filters”参数是定位集合中具有相同 CSS 选择器的元素之一,或者包含在其中之一的元素时,是如何强制使用的。
//Shall throw () if there is no filters applied to choose parent of LinkByParent.Title
Assert.Catch<NullReferenceException>(() =>
Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.Title] = "click");
//Click the Downward Arrow of the third result item (index = 2)
Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.DownArrow, null,
GenericPredicate<IWebElement>.IndexPredicateOf(2)] = "click";
//Validate now the above Downward Arrow can still be highlighted when "filters" is missing
Page.CurrentPage[GooglePage.ResultItemFragment.AnyByCustom.LinkAddress] = "highlight";
Page.CurrentPage[GooglePage.ResultItemFragment.ListItemAllByClass.g] = "highlight";
“LinkByParent.Title”指的是可点击的页面标题,例如“horejsek/python-webdriverwrapper · GitHub”和“WebDriver : Compilation error in custom created Wrapper ...”,它们显示在您的浏览器中。尽管 Enum 类型名称意味着 IWebElement 是唯一的,但这种唯一性仅在其容器内有效——由“ListItemAllByClass.g”标识的 ResultItemFragment。由于定位 IWebElement 的级联过程实际上是从定位父 IWebElement 开始的,因此“LinkByParent.Title”的 Locator 在没有“filters”指定的条件的情况下,将无法获取父 IWebElement。因此,第一句话“Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.Title] = "click"”将抛出 NullReferenceException。
然后第二句话提供了一个 IndexPredicate(在 Google 搜索示例:过滤计数 IWebElements 中介绍),如下所示:
“Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.DownArrow, null, GenericPredicate<IWebElement>.IndexPredicateOf(2)] = "click"”
结果是,“ListItemAllByClass.g”的 Locator 将在调用 IWebDriver.FindElemens() 获取“ReadOnlyCollection<IWebElement>”后选择第三个结果项,并将其传递回“LinkByParent.Title”的 Locator 以获取由“LinkByParent.DownArrow”标识的唯一 IWebElement 并点击它。
因为“filters”是粘性的(使用它的 Locator 将保留它,直到提供另一个非 null 的“filters”)接下来的两句话将高亮显示容器(由“ListItemAllByClass.g”标识的 ResultItemFragment)和另一个兄弟 IWebElement(通过 AnyByCustom.LinkAddress),如下图所示,您可以在 Google 搜索示例:带缓冲的过滤器中找到更多解释。


接下来的两句话用于展示在 Google 搜索示例:涉及其他 IWebElement 的示例中讨论的、在同一容器内匹配其兄弟 IWebElement 的条件的更实际用法。
Page.CurrentPage[GooglePage.ResultItemFragment.AnyByCustom.LinkAddress, null, (e)=>e.HasChildOfText(GooglePage.ResultItemFragment.AnyByCustom.LinkAddress,"stackoverflow.com")] = "highlight";
Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.Title] = "click";
因为“AnyByCustom”的类型名称不包含像“AnyAllByCustom”这样的“All”,所以“AnyByCustom.LinkAddress”将在其 FindElement() 中简单地忽略任何过滤器,“filters”((e)=>e.HasChildOfText(GooglePage.ResultItemFragment.AnyByCustom.LinkAddress,"stackoverflow.com") 实际上被由“ListItemAllByClass.g”标识的容器所消耗,并且扩展方法 HasChildOfText(Enum childEnum, string partialText) 和 HasChildOfLink(Enum childEnum, string partialText) 封装了基于其子项查找 IWebElement 所需的逻辑。因此,与其比较容器的所有文本,只关注部分内容可以提高匹配效率和准确性。
第一句话将高亮显示结果项的链接地址,如下图所示,然后点击其上方的实际链接组件。

如果您不需要指示匹配的来源,则不需要这个两步过程:您可以使用一个句子来根据与另一个关联的匹配项来点击结果项,就像这样:
Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.Title, null,(e) => e.HasChildOfText(GooglePage.ResultItemFragment.AnyByCustom.LinkAddress,"code.google")] = "controlclick";
它将在另一个标签页中打开网页,其链接地址包含“code.google”。
如果我们需要在与 Locator 关联的相似集合中对一个 IWebElement 执行操作,并且它也包含在另一个集合容器中,那么实际上我们需要将两个 predicate 组合成 Indexer 中使用的“filters”,如 Google 搜索示例:多个 Locators 的过滤器中所讨论的。相关的代码在此列出:
Func<IWebElement, bool> predicate = (e) =>
{
string elementClass = e.GetAttribute("class");
return (elementClass=="g" && e.HasChildOfText(GooglePage.ResultItemFragment.AnyByCustom.LinkAddress, "stackoverflow.com") || (elementClass.Contains("action-menu-item") &&e.Text == "Similar"));};
Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.DownArrow, null, predicate] = "click";
Page.CurrentPage[GooglePage.ResultItemFragment.ListItemAllByClass.action_menu_item, null, predicate] = "tryhighlight";
if (Page.LastTrySuccess)
Page.CurrentPage[GooglePage.ResultItemFragment.ListItemAllByClass.action_menu_item] = "click";
因为操作菜单项“Similar”确实存在,所以它被高亮显示然后点击,如下图所示:

设计考虑因素
与大多数规范项目不同,TERESA 中广泛使用了三种我最喜欢的技术:Enum 结合 Attribute、Indexer 带有 Function 委托作为参数以及 Reflection。其背后的主要原因是为了提高编码效率:我总是试图输入更少的代码来支持尽可能多的功能。
Enum vs. Class
Enum 类型,作为一种特殊的类,是充当标识符的良好媒介,可以承载大量静态信息。正如您在之前的示例中所看到的,它们的类型名称、成员名称以及特别是关联的属性可以提取大量信息,而无需定义众多的 Dictionary 和复杂的查询机制来获取它。与 JAVA 中的 Enum 类型不同,Enum 类型内部不能定义方法,但是,由于其独特性和类本质,可以通过定义扩展方法甚至链接某些静态类来提供额外的服务逻辑,这并不困难。因此,我一直很乐意尝试利用其潜力,将 Enum 用作存储/检索各种信息的键,并且其简洁的定义风格、强类型和常量性质在整个过程中总是有帮助的。
相比之下,Class 可以配备一套丰富的方法/属性/属性来做几乎所有事情,在许多情况下可以替代 Enum。但是,定义和初始化总是意味着要编写和维护大量的代码。对我来说,在 TERESA 中使用类而不是 Enum,似乎意味着 Page 类中定义的每个 Enum 类型都应该被定义为一个类,并且每个 Enum 成员都需要被定义为扩展类,这将使整个解决方案毫无意义。
Indexer 而不是 Functions
使用 WebDriver 执行任何任务总是需要两个步骤:先找到元素,然后调用一些函数/属性来读取或写入它,因此最好将事务的元素查找和操作合并到一行代码中。
对我来说,最好的解决方案是有一个函数或 Indexer 作为唯一的读/写接口,当使用 TERESA 执行操作时,通过调用各种 WebDriver 方法。Indexer 非常适合这个角色,特别是当我发现很难为这样一个拥有如此多角色的函数命名时。通过将查找和执行合并在一起,TERESA 的代码更易于维护:服务逻辑在一个块中,因此修改更方便。
更重要的是,以这种方式使用 Indexer 消除了定义大量原子函数的需要,这些函数仅用于执行诸如 inputFirstName()、selectAge() 等非常微不足道的任务。这些一次性的函数耗时,并且严重依赖于底层的 WebDriver API 和元素查找策略。
我使用 Indexer 的另一个重要原因是由于测试执行的可重复性。我开发了另一个库,该库基于 Enum 标识符的名称伪随机生成数据。例如,名称为“email”的 Enum 成员将被分配一个 email 格式的字符串,“phone”将被随机分配一个固定电话或手机,“firstName”将被赋予一个常见的英文名字。因此,与其指定要输入到字段中的内容,大多数项目都可以随机填充,以减少输入量,并使 WebDriver 能够通过一些预定义的逻辑自动测试用户行为的各种组合。然而,我遇到的一个挑战是如何在某个用例失败时重现失败。当您执行示例测试时,您可能会注意到控制台会输出类似这样的内容:
[TERESAExample.GooglePages.GooglePage+TextByName.textToBeSearched]="WebDriver wrapper";
"WebDriver wrapper"=[TERESAExample.GooglePages.GooglePage+TextByName.textToBeSearched, "value"];
[TERESAExample.GooglePages.GooglePage+TextByName.textToBeSearched]="highlight";
[TERESAExample.GooglePages.GooglePage+ButtonByName.Search]="click";
...
这不是很像测试函数的代码吗?输出文件可以方便地转换为代码,通过“Copy&Paste”以完全相同的顺序和目标执行,或者通过一个简单的函数转换,如果所有操作都通过 Indexer 执行。
实际上,即使 Indexer 中使用的 Predicate(Func<IWebElement, bool>) 通常也很简单且有限,因此可以用一些脚本字符串来描述。如果确实如此,那么测试用例可以写在 WORD 中,并轻松地作为代码执行。
Reflection vs Performance
虽然 Reflection 的开销很大,但对我来说,让 CPU 更忙碌以节省程序员输入重复代码是一个不错的选择,尤其是在自动化测试中,WebDriver 会花费大量时间等待页面加载/渲染时。
对我而言,重复的代码意味着扩展类的构造函数、特定类型的迭代、类实例的初始化以及可以由基类实现的函数。如您所见,在此项目中,我使用了 Reflection 来避免前三种代码。
另一方面,我也采取了一些措施来限制对性能的影响:
- 尽可能使用 Dictionary 来存储相关的静态项,例如 EnumMemberAttribute、Enum 的值。
- 定义 Locator/Fragment/Page 作为 IWebElement 搜索工具的包装器,而不是 IWebElement 的包装器。
- 仅使用 Reflection 一次,通常在相关类的静态构造函数中,并一次性获取所有需要的信息。
- 构造所有 Page 类的实例,并使用 Page.CurrentPage 的静态属性来使用它们。
总之,在我看来,当有很多类/枚举具有相似性时,Reflection 可以极大地帮助获取一套完整的函数实体。
附录
HtmlTagName
下表列出了“CSS 选择器从 Enum 生成”中讨论的 HtmlTagName 的 Enum 成员、在“static EnumTypeAttribute()”中定义的值、相关的 HTML 标签和描述。
|
HtmlTagName |
值 |
标签 |
描述 |
|
任意 |
{0} {1} |
|
任何元素 |
|
Html |
html |
定义 HTML 文档的根 |
|
|
标题 |
title |
定义文档的标题 |
|
|
正文 |
body |
定义文档的主体 |
|
|
文本 |
{0} input[type]{1}, {0} textarea{1} |
输入控件或多行输入控件(文本区域) |
|
|
图像 / Img |
{0} img{1} |
定义图像 |
|
|
Button |
{0} button{1}, {0} input[type=button]{1}, {0} input.btn{1}, {0} input.button{1}, {0} div[role=button]{1} |
任何充当可点击按钮的元素。 |
|
|
链接 / A |
{0} a{1} |
定义超链接 |
|
|
Select |
{0} select{1} |
定义下拉列表 |
|
|
Label |
{0} label{1} |
为 <input> 元素定义标签 |
|
|
复选框 / Check |
{0} input[type=checkbox]{1} |
类型为“checkbox”的 <input> 控件 |
|
|
单选按钮 |
{0} input[type=radio]{1} |
类型为“radio”的 <input> 控件 |
|
|
Div |
{0} div{1} |
定义文档中的一个区域 |
|
|
Span |
{0} span{1} |
定义文档中的一个区域 |
|
|
节 |
{0} section{1} |
定义文档中的一个区域 |
|
|
段落 / P |
{0} p{1} |
定义一个段落 |
|
|
字段集 |
{0} fieldset{1} |
在表单中分组相关元素 |
|
|
ListItem |
{0} li{1} |
定义列表项 |
|
|
列表 |
{0} ol{1}, {0} ul{1} |
定义无序或有序列表 |
|
|
标题 |
{0} header{1} |
定义文档或区域的标题 |
|
|
H1/H2/H3/H4/H5/H6 |
{0} h1{1} / ... |
定义 HTML 标题 |
|
|
表单 |
{0} form{1} |
定义用于用户输入的 HTML 表单 |
|
|
表格 |
{0} table{1} |
定义表 |
|
|
表头 / Thead |
{0} thead{1} |
在表中分组表头内容 |
|
|
表体 / Tbody |
{0} tbody{1} |
在表中分组表体内容 |
|
|
表脚 / Tfoot |
{0} tfoot{1} |
在表中分组表脚内容 |
|
|
表行 / Tr |
{0} tr{1} |
在表中定义一行 |
|
|
单元格 / Td |
{0} td{1} |
在表中定义一个单元格 |
|
|
表头单元格 / Th |
{0} th{1} |
在表中定义一个表头单元格 |
下表列出了“CSS 选择器从 Enum 生成”中讨论的 Mechanisms 的 Enum 成员、在“static EnumTypeAttribute()”中定义的值、相关的 CSS 选择器原型、含义和示例。
要理解这些机制的含义,访问 必须记住的 30 个 CSS 选择器 会很有帮助。表中出现的 {T}、{A}、{A0}、{A1} 是 EnumMemberAttribute 的占位符值。
- {T} 是由 HtmlTagName 确定的标签名。
- {A} 由 EnumMemberAttribute.Value() 指定,当没有 "=" 时。
- {A0} 由 EnumMemberAttribute.Value() 的第一个部分指定,在 "=" 之前。
- {A1} 是 EnumMemberAttribute.Value() 的可选第二部分,在 "=" 之后。
|
Mechanisms |
值 |
CSS 原型 |
含义 |
示例 |
|
ById |
#{0} |
{T}#{A} |
使用 Id 进行元素查找 |
SelectById.x: select#YYY |
|
ByClass |
.{0} |
{T}.{A} |
使用 Classname 进行查找 |
SelectByClass.x: select.x |
|
ByAdjacent |
{0}+{1} |
{A}+{T} |
仅选择紧跟在前面元素 {A} 之后的元素 {T}。 |
SelectByAdjacent.x(“A0=A1”): A0+ selectA1 |
|
ByParent |
{0}>{1} |
{A}>{T} |
查找作为某个父标签 {A} 的直接子标签 {T}。 |
SelectByParent.x(“A0=A1”): A0> selectA1 |
|
ByAncestor |
{0} {1} |
{A} {T} |
查找作为某个父标签 {A} 的后代标签 {T}。 |
SelectByAncestor.x(“A0=A1”): A0 selectA1 |
|
BySibling |
{0}~{1} |
{A}~{T} |
仅选择在前面元素 {A} 之后出现的元素 {T}。 |
SelectBySibling.x(“A0=A1”): A0~ selectA1 |
|
ByUrl |
[href*='{0}'] |
{T}[href*={A}] |
选择包含关键字的链接的标签,当属性是“href”时,等于 ByAttribute。 |
SelectByUrl.x: select[href*='x'] |
|
ByName |
[name*='{0}'] |
{T}[name*={A}] |
选择包含关键字的名称的标签,当属性是“name”时,等于 ByAttribute。 |
SelectByName.x: select[name*='x'] |
|
ByValue
|
[value*='{0}'] |
{T}[value*={A}] |
选择包含关键字的值的标签,当属性是“value”时,等于 ByAttribute。 |
SelectByValue.x: select[value*='x'] |
|
ByAttribute / ByAttr |
[{0}='{1}'] |
{T}[{A}] |
[{A}] 也可以代表以下任何选择器:[{A0}]、[{A0}={A1}]、[{A0}*={A1}]、[{A0}^={A1}]、[{A0}$={A1}]、[{A0}~={A1}]、[{A0}-*={A1}] 含义是 分别表示带有属性、精确匹配、包含、以...开头、以...结尾、值包含、名称以 A0 开头。 |
SelectByAttr.x(“A0=A1”): select[A0='A1'] |
|
ByOrder |
{0}:nth-of-type({1}) |
{A0} {T}:nth-of-type({A1}) |
选择类型的第 N 个(从 1 开始)。 |
SelectByOrder.x(“A0=A1”): A0 select:nth-of-type(A1) |
|
ByOrderLast |
{0}:nth-last-of-type({1}) |
{A0} {T}:nth-last-of-type({A1}) |
从末尾选择类型的第 N 个(从 1 开始)。 |
SelectByOrderLast.x(“A0=A1”): A0 select:nth-last-of-type(A1) |
|
ByChild |
{0}:nth-child({1}) |
{A0} {T}:nth-child({A1}) |
按嵌套子项的第 N 个(从 1 开始)。 |
SelectByChild.x(“A0=A1”): A0 select:nth-child(A1) |
|
ByChildLast |
{0}:nth-last-child({1}) |
{A0} {T}:nth-last-child({A1}) |
从末尾选择嵌套子项的第 N 个(从 1 开始)。 |
SelectByChildLast.x(“A0=A1”): A0 select:nth-last-child(A1) |
|
ByCustom |
{0} |
{A} |
EnumMemberAttribute.Value() 中定义的所有 CSS 文本。 |
SelectByCustom.x(“select[A0=A1]”): select[A0=A1] |
|
ByTag |
none |
{T} |
仅使用默认标签名来定位 IWebElement。 |
SelectByTag.x(“select[A0=A1]”): select |
|
ByText |
none |
{T} |
使用 LINQ 代替来选择目标元素。 |
SelectByText.x(“A0=A1”): select |
Indexer 支持的操作
本节中的表格总结了通过 Page 类的 Indexer(string this[Enum, string, Func<IWebElement, bool>])支持的操作,这些操作由相应 Locators 的 Indexer(string this[string, Func<IWebElement, bool>])执行,您可以将它们用作设计自己的测试用例的快速参考。
获取操作
下表列出了获取操作,通过这些操作,您可以获取特定 IWebElement 的属性或值,以及它们的格式和含义。
|
键 |
示例 |
描述 |
|
通过 Locator 进行的获取操作 |
|
|
|
Null / "" |
string text = Page.CurrentPage[SearchNavFragment.DivByCustom.Web]; |
获取由“DivByCustom.Web”标识的 <div> 元素的文本“Web”。 |
|
"text" |
string text = Page.CurrentPage[SearchNavFragment.DivByCustom.Web, "text"]; |
获取由“DivByCustom.Web”标识的 <div> 元素的文本“Web”。 |
|
"tagname" |
string tagname = Page.CurrentPage[SearchNavFragment.DivByCustom.Web, "tagname"]; |
获取由“DivByCustom.Web”标识的 <div> 元素的标签名“div”。 |
|
"selected" |
string selected = Page.CurrentPage[SearchNavFragment.DivByCustom.Web, "selected"]; |
获取由“DivByCustom.Web”标识的 <div> 元素的“Selected”属性,值为“True”或“False”。 |
|
"enabled" |
string valueString = Page.CurrentPage[FacebookLoginPage.ButtonByText.SignUp, "enabled"]; |
获取由“ButtonByText.SignUp”标识的 <div> 元素的“Enabled”属性,值为字符串“True”。 |
|
"displayed" |
string valueString = Page.CurrentPage[FacebookLoginPage.ButtonByText.SignUp, "displayed"]; |
获取由“ButtonByText.SignUp”标识的 <div> 元素的“Displayed”属性,值为字符串“True”。 |
|
"location" |
string valueString = Page.CurrentPage[FacebookLoginPage.ButtonByText.SignUp, "location"]; |
获取由“ButtonByText.SignUp”标识的 <div> 元素的“Location”属性,值为字符串“{X=765,Y=556}”。 |
|
"size" |
string valueString = Page.CurrentPage[FacebookLoginPage.ButtonByText.SignUp, "size"]; |
获取由“ButtonByText.SignUp”标识的 <div> 元素的“Size”属性,值为字符串“{Width=194, Height=39}”。 |
|
"css" |
string css = Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.Title, "css"]; |
获取由“LinkByParent.Title”标识的链接的 CSS 选择器字符串,即“h3> a”。 |
|
"parentcss" |
string parentCss = Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.Title, "parentcss"]; |
获取由“LinkByParent.Title”标识的链接的父项的 CSS 选择器字符串,即“ li.g”。 |
|
"fullcss" |
string fullCss = Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.Title, "fullcss"]; |
获取由“LinkByParent.Title”标识的链接的完整 CSS 选择器字符串:“ li.g h3> a”。 |
|
其他 |
string href = Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.Title, "href"]; |
获取由“LinkByParent.Title”标识的链接的“href”属性:“http://...”。 |
|
通过 TextLocator 的额外获取操作 |
|
|
|
Null / "" |
Assert.AreEqual("WebDriver", Page.CurrentPage[GooglePage.TextByName.textToBeSearched]); |
获取由“TextByName.textToBeSearched”标识的 <input> 元素的文本“WebDriver”。 |
|
通过 SelectLocator 的额外获取操作 |
|
|
|
Null / "" |
string temp = Page.CurrentPage[SelectExamplesPage.SelectByName.food]; |
获取由“SelectByName.food”标识的 <select> 元素的选定选项的文本。 |
|
"text" |
string temp = Page.CurrentPage[SelectExamplesPage.SelectByName.food, "text"]; |
获取由“SelectByName.food”标识的 <select> 元素的选定选项的文本。 |
|
"index" / "#" |
string temp = Page.CurrentPage[SelectExamplesPage.SelectByName.food, "index"]; |
获取由“SelectByName.food”标识的 <select> 元素的选定选项的“index”属性(如果已定义),或选定选项的顺序(从 0 开始)。 |
|
"value" / "$" |
string temp = Page.CurrentPage[SelectExamplesPage.SelectByName.food, "value"]; |
获取由“SelectByName.food”标识的 <select> 元素的选定选项的“value”属性(如果已定义)。 |
|
"ismultiple" |
string temp = Page.CurrentPage[SelectExamplesPage.SelectByName.food, "ismultiple"]; |
指示 <select> 元素是否可以选择多个选项的“True”或“False”。 |
|
"alloptions" |
string temp = Page.CurrentPage[SelectExamplesPage.SelectByName.food, "alloptions"]; |
获取由“SelectByName.food”标识的 <select> 元素的所有选项,用“,”分隔。 |
|
"allselected" |
string temp = Page.CurrentPage[SelectExamplesPage.SelectByName.food, "allselected"]; |
获取由“SelectByName.food”标识的 <select> 元素的所有选定选项,用“,”分隔。 |
|
通过 CheckboxLocator 的额外获取操作 |
|
|
|
Null / "" |
string temp = Page.CurrentPage[SomePage.CheckboxById.ok]; |
指示 <input type=checkbox> 元素是否被选中的“True”或“False”。 |
|
"selected" / "checked" |
string temp = Page.CurrentPage[SomePage.CheckboxById.ok, "checked"]; |
获取由“SelectByName.food”标识的 <select> 元素的选定选项的文本。 |
|
通过 RadioLocator 的额外获取操作 |
|
|
|
Null / "" |
Assert.AreEqual(true.ToString(), Page.CurrentPage[FacebookLoginPage.RadioByCustom.male, ""]); |
指示由“RadioByCustom.male”标识的 <input type=radio> 元素是否被选中的“True”或“False”。 |
|
"selected" |
Assert.AreEqual(true.ToString(), Page.CurrentPage[FacebookLoginPage.RadioByCustom.female, "selected"]); |
指示由“RadioByCustom.female”标识的 <input type=radio> 元素是否被选中的“True”或“False”。 |
下表列出了设置操作,通过这些操作,您可以操作或设置特定 IWebElement 的属性或值,以及它们的格式和含义。
|
键 |
示例 |
描述 |
|
通过 Locator 进行的获取操作 |
|
|
|
"try" + "actionname" |
Page.CurrentPage[SearchNavFragment.LinkByText.Web] = "tryclick"; |
仅当 IWebElement 被成功定位时尝试执行某个操作,否则只是静默返回。 |
|
"sendkeys" |
Page.CurrentPage[GooglePage.ButtonByName.Search, "sendkeys"] = Keys.Enter; |
调用由“ButtonByName.Search”标识的 <button> 元素的 SendKeys() 来模拟按下“Enter”。 |
|
"true" / "click" |
Page.CurrentPage[SearchNavFragment.DivByCustom.Web] = "click"; |
点击由“DivByCustom.Web”标识的元素。 |
|
"submit" |
Page.CurrentPage[FacebookLoginPage.ButtonByText.SignUp] = "submit" |
调用由“ButtonByText.SignUp”标识的元素的 Submit()。 |
|
"clickscript" |
Page.CurrentPage[GooglePage.ButtonByName.Search] = "clickscript"; |
通过脚本点击由“ButtonByName.Search”标识的元素。 |
|
"hover" |
Page.CurrentPage[GooglePage.LinkByClass.SearchByVoice] = "hover"; |
将鼠标悬停在由“LinkByClass.SearchByVoice”标识的元素上,并等待一段时间。 |
|
"controlclick" |
Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.Title] = "controlclick"; |
Ctrl+Click 由“LinkByParent.Title”标识的链接,这将使其在另一个标签页中打开。 |
|
"shiftclick" |
Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.Title] = "shiftclick"; |
Shift+Click 由“LinkByParent.Title”标识的链接,这将使其在一个新窗口中打开。 |
|
"doubleclick" |
Page.CurrentPage[GooglePage.ResultItemFragment.LinkByParent.Title] = "doubleclick"; |
双击由“LinkByParent.Title”标识的链接。 |
|
"show" |
Page.CurrentPage[GooglePage.LinkById.Next] = "show"; |
滚动页面以使由“LinkById.Next”标识的元素可见。 |
|
"highlight" |
Page.CurrentPage[SearchNavFragment.DivByCustom.Web] = "highlight"; |
通过更改样式来高亮显示由“DivByCustom.Web”标识的元素,并保持一段时间后通过脚本恢复原状。 |
|
通过 SelectLocator 的额外获取操作 |
|
|
|
"text=" |
Page.CurrentPage[SelectExamplesPage.SelectByName.cars, "text=Volvo"] = "true"; |
如果由 SelectByName.cars 标识的 select 元素尚未选中“Volvo”选项,则点击文本为“Volvo”的选项。 |
|
"index=" / "#" |
Page.CurrentPage[SelectExamplesPage.SelectByName.food, "#8"] = "true"; |
如果由 SelectByName.food 标识的 select 元素尚未选中索引为“8”的选项,则点击该选项。 |
|
"value=" / "$" |
Page.CurrentPage[SelectExamplesPage.SelectByName.food, "value=2"] = "true"; |
从由 SelectByName.food 标识的 select 元素中选择“value”属性为“2”的选项。 |
|
"alloptions" |
Page.CurrentPage[SelectExamplesPage.SelectByName.sports, "alloptions"] = "true"; |
选择由 SelectByName.sports 标识的 select 元素的所有选项。 |
|
otherwise |
Page.CurrentPage[SelectExamplesPage.SelectByName.sports, "soc"] = "true"; |
调用由“SelectByName.sports”标识的元素的 SendKeys() 输入“soc”+TAB,这将选择第一个匹配的选项。 |
历史
在此处保持您所做的任何更改或改进的实时更新。