
XML 入门 - 第 2 章:格式正确的 XML
4.60/5 (44投票s)
2000 年 11 月 28 日
234306
XML 语法和编写格式正确的 XML
 |
|
格式正确的XML
我们已经讨论了一些XML在数据通信方面的优势,现在让我们动手实践,学习如何创建自己的XML文档。本章将涵盖创建“格式正确”的XML所需的一切知识。
格式正确的XML是指符合XML 1.0规范中定义的某些语法规则的XML。
你将学到
- 如何使用开始标签和结束标签创建XML元素
- 如何通过属性进一步描述元素
- 如何声明你的文档为XML
- 如何向处理XML文档的应用程序发送指令
- 哪些字符在XML中不允许使用,以及如何将它们包含进去
由于XML和HTML看起来非常相似,并且你可能已经熟悉HTML,因此在本章中,我们将对这两种语言进行比较。但是,如果你对HTML一无所知,应该也不会发现很难跟上。
如果你有Internet Explorer 5,你可能会发现将本章中的一些示例保存在硬盘上并在浏览器中查看结果很有用。如果你没有IE5,一些示例将配有截图,展示最终结果的样子。
标签、文本和元素,天哪!
是时候停止仅仅称呼事物为“项”和“文本”了;我们需要为构成XML文档的各个部分命名。为了开始,让我们来分解一下我们在第一章创建的简单<name>文档。
<name>
<first>John</first>
<middle>Fitzgerald Johansen</middle>
<last>Doe</last>
</name>
位于<和>字符之间的词语是XML标签。我们文档中的信息(我们的数据)包含在构成文档标记的各种标签中。这使得区分文档中的信息和标记变得容易。
正如你所见,标签是成对出现的,因此任何开始标签都有一个匹配的结束标签。在XML行话中,这些被称为开始标签(start-tags)和结束标签(end-tags)。结束标签与开始标签相同,只是在开头的<字符后面有一个“/”。
在这方面,XML标签的工作方式与HTML中的开始标签和结束标签相同。例如,你会这样创建一个HTML段落:
<P>This is a paragraph.</P>
正如你所见,有一个<P>开始标签和一个</P>结束标签,就像我们用于XML一样。
从开始标签的开头到结束标签的结尾,以及其间包含的所有内容,都被称为一个元素。所以:
- <first> 是一个开始标签
- </first> 是一个结束标签
- <first>John</first> 是一个元素
元素开始标签和结束标签之间的文本称为元素内容。我们标签之间的内容通常只是数据(而不是其他元素)。在这种情况下,元素内容被称为解析字符数据(Parsed Character DATA),通常使用其缩写PCDATA。
每当你遇到像PCDATA这样看起来奇怪的术语时,它很可能继承自SGML。因为XML是SGML的子集,所以有很多这样的继承术语。
整个文档,从<name>开始到</name>结束,也是一个元素,它恰好包含了其他元素。(在这种情况下,该元素被称为根元素,我们稍后会讨论。)
为了将这些新获得的知识付诸实践,让我们创建一个包含比名字更多信息的示例。
实践一下——描述怪诞
我们将构建一个XML文档来描述有史以来最伟大的CD之一——Weird Al Yankovic的《Dare to be Stupid》。但在我们拿出记事本开始打字之前,我们需要知道我们要捕获哪些信息。
在第一章中,我们了解到XML本质上是分层的;信息结构像一棵树,具有父/子关系。这意味着我们也必须将我们的CD信息组织成树状结构。
1. 既然这是一张CD,我们将需要捕获诸如艺术家、标题、发行日期以及音乐类型等信息。我们还需要有关CD上每首歌曲的信息,例如标题和时长。而且,由于Weird Al以其模仿而闻名,我们将包含有关此歌曲模仿哪首歌曲(如果有的话)的信息。这是我们将要创建的层次结构:
|
|

其中一些元素,如<artist>,只会出现一次;而另一些,如<song>,会在文档中出现多次。另外,有些将只包含PCDATA,而有些将包含子元素来进一步细分信息。例如,<artist>元素将包含标题的PCDATA,而<song>元素将不包含任何PCDATA,但将包含子元素来进一步分解信息。
2. 考虑到这一点,我们现在准备开始输入XML。如果你在机器上安装了Internet Explorer 5,请在记事本中输入以下内容,并将其保存到硬盘上,文件名为cd.xml。
<CD>
<artist>"Weird Al" Yankovic</artist>
<title>Dare to be Stupid</title>
<genre>parody</genre>
<date-released>1990</date-released>
<song>
<title>Like A Surgeon</title>
<length>
<minutes>3</minutes>
<seconds>33</seconds>
</length>
<parody>
<title>Like A Virgin</title>
<artist>Madonna</artist>
</parody>
</song>
<song>
<title>Dare to be Stupid</title>
<length>
<minutes>3</minutes>
<seconds>25</seconds>
</length>
<parody></parody>
</song>
</CD>
为了简洁起见,我们只输入CD上的两首歌曲,但这个思路仍然存在。
3. 现在,在IE5中打开该文件。(在资源管理器中找到该文件并双击,或打开浏览器并在URL栏中输入路径。)如果你输入的标签与所示完全一致,cd.xml文件将如下所示:
|
|

工作原理
在这里,我们创建了CD信息的层次结构,因此我们相应地命名了根元素。
<CD>元素包含艺术家、标题、类型和日期的子元素,以及唱片上每首歌曲的一个子元素。<song>元素包含标题、时长以及(因为我们讨论的是Weird Al)模仿歌曲的信息。同样,为了本例的缘故,<length>元素被进一步细分,以包含分钟和秒的子元素,而<parody>元素被细分以包含被模仿歌曲的标题和艺术家。
你可能已经注意到IE5浏览器将<parody></parody>变成了<parody/>。我们稍后会讨论这种简写语法,但不用担心:它是完全合法的。
如果我们编写一个CD播放器应用程序,我们可以利用这些信息来创建CD的播放列表。它可以读取我们<song>元素下的信息,以获取每首歌曲的名称和时长并显示给用户,在标题栏中显示CD的类型等。基本上,它可以利用我们XML文档中包含的任何信息。
元素规则
显然,如果我们想以任何方式 创建元素,我们就无法比上一章的文本文件示例更进一步。元素必须有一些规则,这是理解XML的基础。
XML文档必须遵守这些规则才能格式正确。
我们先简要列出它们,然后再详细介绍:
- 每个开始标签都必须有一个匹配的结束标签
- 标签不能重叠
- XML文档只能有一个根元素
- 元素名称必须遵守XML命名约定
- XML区分大小写
- XML会保留你文本中的空格
每个开始标签都必须有一个结束标签
解析SGML文档的一个问题是并非所有元素都需要开始标签和结束标签。以以下HTML为例:
<HTML>
<BODY>
<P>Here is some text in an HTML paragraph.
<BR>
Here is some more text in the same paragraph.
<P>And here is some text in another HTML paragraph.</p>
</BODY>
</HTML>
请注意,第一个<P>标签没有关闭的</P>标签。这在HTML中是允许的——有时甚至被鼓励——因为大多数网页浏览器可以自动检测段落的结束位置。在这种情况下,当浏览器遇到第二个<P>标签时,它就知道第一个段落结束了。然后是<BR>标签(换行),根据定义它没有结束标签。
另外,请注意第二个<P>开始标签与小写的</p>结束标签匹配。HTML浏览器必须足够智能,才能意识到这两个标签界定了同一个元素,但正如我们很快将看到的,这对XML解析器来说会是个问题。
问题在于这使得编写HTML解析器更加困难。必须包含代码来考虑所有这些因素,这通常会使解析器更加庞大,并且更难调试。更重要的是,文件的解析方式并未标准化——不同的浏览器以不同的方式解析,导致不兼容。
现在,只需记住在XML中,结束标签是必需的,并且必须与开始标签完全匹配。
标签不能重叠
由于XML是严格分层的,所以你必须小心在关闭父元素之前关闭子元素。(这被称为正确地嵌套你的标签。)让我们看另一个HTML示例来演示这一点:
<P>Some <STRONG>formatted <EM>text</STRONG>,
but</EM> no grammar no good!</P>
这将在网页浏览器上产生以下输出:
Some formatted text, but no grammar no good!
正如你所见,<STRONG>标签覆盖了“formattedtext”文本,而<EM>标签覆盖了“text,but”文本。
但是,<em>是<strong>的子元素,还是<strong>是<em>的子元素?或者它们都是同级元素,并且是<p>的子元素?根据我们更严格的XML规则,答案都不是。HTML代码,如其所写,无法组织成一个 proper hierarchy,因此不能格式正确。
如果你不确定你的XML标签是否重叠,试着在视觉上重新排列它们,使它们成为分层的。如果树形结构有意义,那么你就没问题了。否则,你必须重新修改你的标记。
例如,我们可以通过以下方式获得与上面相同效果:
<P>Some <STRONG>formatted
<EM>text</EM></STRONG><EM>, but</EM> no grammar
no good!</P>
可以将其正确地格式化为一棵树,如下所示:
<P>
Some
<STRONG>
formatted
<EM>
text
</EM>
</STRONG>
<EM>
, but
</EM>
no grammar no good!
</P>
XML文档只能有一个根元素
在我们的<name>文档中,<name>元素被称为根元素。它是文档的顶级元素,所有其他元素都是它的子元素或后代元素。XML文档必须有一个且只有一个根元素:事实上,即使它没有任何内容,也必须有一个根元素。
例如,以下XML格式不正确,因为它有多个根元素:
<name>John</name>
<name>Jane</name>
为了使其格式正确,我们需要添加一个顶级元素,如下所示:
<names>
<name>John</name>
<name>Jane</name>
</names>
所以,虽然这可能看起来有些不方便,但事实证明遵循这个规则非常容易。如果你有一个具有多个根状元素的文档结构,只需创建一个更高级别的元素来包含它们。
元素名称
如果我们 要创建元素,我们就必须 给它们命名,XML在允许我们使用的名称方面非常慷慨。例如,XML中没有需要避免的保留字,就像大多数编程语言一样,所以我们在这一点上有很多灵活性。
但是,有一些规则我们必须遵守:
- 名称可以以字母(包括非拉丁字符)或“_”字符开头,但不能以数字或其他标点字符开头。
- 第一个字符之后,允许使用数字,以及“-”和“.”字符。
- 名称不能包含空格。
- 名称不能包含“:”字符。严格来说,这个字符是允许的,但XML规范说它是“保留的”。除非你正在使用命名空间(在第八章中介绍),否则你应该避免在文档中使用它。
- 名称不能以“xml”字母开头,不区分大小写——你不能以“xml”、“XML”、“XmL”或任何其他组合开头一个名称。
- 在开头的“<”字符后面不能有空格;元素名称必须紧跟在后面。但是,如果需要,可以在结尾的“>”字符之前有空格。
以下是一些有效名称的示例:
<first.name>
<résumé>
以下是一些无效名称的示例:
<xml-tag>
以xml开头,
<123>
以数字开头,
<fun=xml>
因为“=”符号是非法的,并且
<my tag>
包含空格。
记住这些元素名称的规则——它们也适用于命名XML中的其他事物。
区分大小写
另一个需要牢记的重要一点是,XML中的标签是区分大小写的。(这是与HTML的一个重要区别,HTML不区分大小写。)这意味着<first>不同于<FIRST>,也不同于<First>。
这有时对XML的英语使用者来说显得奇怪,因为英语单词可以轻松地转换为大写或小写而不丢失含义。但在世界上几乎所有其他语言中,大小写的概念要么不适用(换句话说,b的大写是什么?或者小写又是什么?),要么极其重要(é的大写是什么?答案可能不同,取决于上下文)。在XML规范中加入智能的大小写转换规则可能会使规范的体积翻倍或翻三倍,并且仍然只使讲英语的人受益。幸运的是,习惯了区分大小写的名称并不需要太长时间。
这就是为什么我们之前关于<P></p>的HTML示例在XML中不起作用的原因;由于标签区分大小写,XML解析器将无法将</p>结束标签与任何开始标签匹配,也无法将<P>开始标签与任何结束标签匹配。
警告!由于XML区分大小写,你可能合法地创建一个同时具有<first>和<First>元素,且它们具有不同含义的XML文档。这是一个糟糕的主意,只会造成混乱!为了你自己的理智,以及为了那些后来者,你应该始终尝试为你的元素起不同的名称。
为了帮助解决这些问题,最好选择一种命名风格并坚持下去。一些常见的样式示例是:
- <first_name>
- <firstName>
- <first-name> (有些人不喜欢这种约定,因为“-”字符在许多编程语言中用于减法,但它是合法的)
- <FirstName>
你选择哪种风格并不重要;重要的是你坚持使用它。命名约定只有在一致使用时才有帮助。在这本书中,我通常会使用<FirstName>约定,因为我已经习惯了。
PCDATA中的空格
有一类 特殊的字符,称为空格。这包括空格字符、换行符(按Enter键时产生的)和制表符。空格用于分隔单词,以及使文本更易读。
熟悉HTML的人可能很清楚空格去除的做法。在HTML中,任何被认为不重要的空格在处理文档时都会被去除。例如,请看以下HTML:
<p>This is a paragraph. It has a whole bunch
of space.</p>
就HTML而言,<p>标签中单词之间任何 超过一个空格的空格都是不重要的。所以第一个句号和“It”这个词之间的所有空格都会被去除,只留下一个。同样,“bunch”这个词之后的换行以及“of”之前的空格都会被压缩成一个空格。结果,前面的HTML将在浏览器中渲染为:
|
|

为了获得与上面HTML中显示的结果相同,我们必须在源代码中添加特殊的HTML标记,如下所示:
<p>This is a paragraph. It has a whole bunch<br>
of space.</p>
表示应插入一个空格(nbsp代表Non-Breaking SPace),而<br>标签表示应有一个换行符。这将格式化输出为:
|
|

或者,如果我们希望文本像在源文件中那样精确显示,我们可以使用<pre>标签。这会专门告诉HTML解析器不要去除空格,所以我们可以编写以下内容并获得期望的结果:
<pre>This is a paragraph. It has a whole bunch
of space.</pre>
然而,在大多数网页浏览器中,<pre>标签还有一个额外效果,即文本以固定宽度的字体渲染,就像本书中用于代码的Courier字体一样。
空格去除对于HTML这样的语言非常有益,HTML已经主要成为一种显示信息的方式。它允许HTML文档的源代码以可读的方式呈现给编写HTML的人,同时以一种可读的、可能相当不同的方式呈现给用户。
然而,在XML中,对于PCDATA,不会进行空格去除。这意味着对于以下XML标签:
<tag>This is a paragraph. It has a whole bunch
of space.</tag>
PCDATA是:
This is a paragraph. It
has a whole bunch
of space.
就像我们第二个HTML示例一样,没有空格被去除。就空格去除而言,所有XML元素都像HTML的<pre>标签一样被处理。这使得XML的规则比HTML的更容易理解:
不幸的是,如果你在IE5中查看上面的XML,空格会被去除——或者看起来是被去除的。这是因为IE5实际上并没有直接显示XML;它使用一种称为XSL的技术将XML转换为HTML,然后显示HTML。然后,因为IE5是HTML浏览器,它会去除空格。
行尾空格
然而,XML对PCDATA执行的一种空格去除是处理换行符。问题在于有两种字符用于换行——换行符(line feed)和回车符(carriage return),运行Windows的计算机、运行Unix的计算机和Macintosh计算机都以不同的方式使用这些字符。
例如,要在Windows中换行,一个应用程序会同时使用换行符和回车符,而在Unix上则只使用换行符。这在创建XML文档时可能会非常麻烦,因为Unix机器处理文档中的换行方式与Windows机器不同,而Windows机器又与Macintosh机器不同,我们的XML互操作性就会丢失。
因此,决定XML解析器将在处理前将所有换行符转换为单个换行符。这意味着无论XML应用程序运行在哪个操作系统上,它都知道换行将由单个换行符表示。这使得在运行不同操作系统的多台计算机之间交换数据更加容易,因为程序员不必处理(有时很烦人)的行尾逻辑。
标记中的空格
除了我们数据中的空格外,XML文档中还可能存在空格,这些空格实际上不是文档的一部分。例如:
<tag>
<another-tag>This is some XML</another-tag>
</tag>
虽然<another-tag>的PCDATA中包含的任何空格都是数据的一部分,但<tag>后面还有一个换行符,以及<another-tag>之前的一些空格。这些空格可能只是为了使文档更易于阅读,而实际上并不是其数据的一部分。“可读性”空格称为多余空格。
虽然XML解析器必须将所有空格传递给应用程序,但它也可以告知应用程序哪些空格实际上不是元素PCDATA的一部分,而只是多余空格。
那么解析器如何决定这是否是多余空格呢?这取决于我们指定<tag>应该包含什么类型的数据。如果<tag>只能包含其他元素(没有PCDATA),那么空格将被视为多余。但是,如果<tag>允许包含PCDATA,那么空格将被视为该PCDATA的一部分,因此会被保留。
不幸的是,仅从该文档来看,XML解析器无法判断<tag>是否应该包含PCDATA,这意味着它必须假设所有空格都不是多余的。我们将在第九章讨论内容模型时,看看如何让解析器识别出这是多余空格。
属性
除了标签和元素之外,XML 文档还可以包含属性。
属性是与元素关联的简单名称/值对。
它们附加到开始标签上,如下所示,但不附加到结束标签上:
<name nickname='Shiny John'>
<first>John</first>
<middle>Fitzgerald Johansen</middle>
<last>Doe</last>
</name>
属性必须有值——即使该值只是一个空字符串(如“”,它也必须用引号括起来。所以,以下是一个常见的HTML标签的一部分,在XML中是不合法的:
<input checked>
这个也不合法:
<input checked=true>
单引号或双引号都可以,但必须匹配。例如,要使XML格式正确,你可以使用以下两种方式之一:
<input checked='true'>
<input checked="true">
但你不能使用:
<input checked="true'>
由于单引号或双引号都允许,因此很容易在属性值中包含引号字符,例如“John's nickname”或‘Isaid"hi"tohim’。你只需注意不要意外地关闭你的属性,例如'John'snickname';如果XML解析器看到像这样的属性值,它会认为你在第二个单引号处关闭了该值,并在看到紧随其后的“s”时引发错误。
为属性命名的规则与为元素命名的规则相同:名称区分大小写,不能以“xml”开头,等等。此外,一个元素上不能有多个同名属性。所以,如果我们创建一个像这样的XML文档:
<bad att="1" att="2"></bad>
我们将在IE5中收到以下错误:
|
|

实践一下——给Al的CD添加属性
在我们之前的“实践一下”中记录的所有关于我们CD的信息中,我们忘了包含CD的序列号或唱片时长。让我们添加一些属性,以便我们假设的CD播放器应用程序可以轻松地找到这些信息。
1. 打开之前创建的cd.xml文件,并将其另存为cd2.xml。
2. 利用我们新学的属性知识,向<CD>元素添加两个属性,如下所示:
<CD serial=B6B41B
disc-length='36:55'>
<artist>"Weird Al" Yankovic</artist>
<title>Dare to be Stupid</title>
<genre>parody</genre>
<date-released>1990</date-released>
<song>
<title>Like A Surgeon</title>
<length>
<minutes>3</minutes>
<seconds>33</seconds>
</length>
<parody>
<title>Like A Virgin</title>
<artist>Madonna</artist>
</parody>
</song>
<song>
<title>Dare to be Stupid</title>
<length>
<minutes>3</minutes>
<seconds>25</seconds>
</length>
<parody></parody>
</song>
</CD>
3. 如果你输入了上面写的确切内容,当你在IE5中显示它时,应该看起来像这样:
|
|

4. 现在编辑第一个属性,如下所示:
<CD serial='B6B41B' disc-length='36:55'>
5. 重新保存文件,并在IE5中查看它。它看起来应该像这样:
|
|

工作原理
通过使用属性,我们向文档中添加了CD序列号和时长的信息。
<CD serial=B6B41B disc-length='36:55'>
当XML解析器遇到序列属性后面的“=”字符时,它期望一个开引号,但却找到了一个B。这是一个错误,导致解析器停止并向用户报告错误。
所以我们改变了序列属性声明:
<CD serial='B6B41B'
这次浏览器正确地显示了我们的XML。
我们添加的信息可能很有用,例如,在我们之前考虑过的CD播放器应用程序中。我们可以编写我们的CD播放器来使用CD的序列号来加载用户之前可能保存的任何设置(例如自定义播放列表)。
为什么要使用属性?
XML社区中就属性是否真的必要,以及如果必要,应该在哪里使用,存在许多争论。以下是争论的一些要点:
属性可以提供对大多数处理我们XML的应用程序可能不相关的元数据
例如,如果我们知道某些应用程序可能关心CD的序列号,但大多数不关心,那么将其设为属性可能是有意义的。这在逻辑上将大多数应用程序需要的数据与大多数应用程序不需要的数据分离开来。
实际上,“纯粹的元数据”并不存在——所有信息对某个应用程序来说都是“数据”。想想HTML;你可以将HTML中的信息分为两类数据:要显示给人类的数据,以及要由网页浏览器用来格式化人类可读数据的数据。从一个角度来看,用来格式化数据的数据就是元数据,但对浏览器或编写HTML的人来说,元数据就是数据。因此,当我们将一种信息与另一种信息分开时,属性是有意义的。
属性能给我带来元素所不能带来的什么?
难道元素不能做 属性能做的事情吗?
换句话说,表面上看,它们之间真的没有区别:
<name nickname='SJohn'></name>
和
<name>
<nickname>Shiny John</nickname>
</name>
那么为什么要用两种方式去做同样的事情来污染语言呢?
XML被发明的主要原因是因为SGML可以做一些很棒的事情,但如果不配备一个全能的SGML专家,它就太难使用了。所以XML背后的一个理念是更简单、更友好、更温和的SGML。因此,许多人不喜欢属性,因为它们增加了语言的复杂性,而他们认为这是不必要的。
另一方面,有些人觉得属性更容易使用——例如,它们不需要嵌套,你也不必担心标签交叉。
为什么要使用属性,如果属性占用的空间少得多?
难道不应该用属性来节省带宽吗?
例如,如果我们用属性重写我们的<name>文档,它可能看起来像这样:
<name nickname='Shiny John' first='John' middle='Fitzgerald Johansen' last='Doe'></name>
这比我们之前使用元素的代码占用的空间少得多。
但是,在尺寸确实是一个问题的系统中,事实证明简单的压缩技术比试图优化XML要好得多。而且由于压缩的工作方式,无论使用属性还是元素,你最终得到的文件大小几乎相同。
此外,当你试图以这种方式优化XML时,你会失去XML提供的许多好处,例如可读性和描述性标签名。而且在某些情况下,使用元素可以提供更大的灵活性和扩展空间。例如,如果我们将来决定first需要额外的元数据,那么如果我们使用了元素而不是属性,修改代码会容易得多。
为什么在元素看起来更好时使用属性?我的意思是,为什么在属性看起来更好时使用元素?
许多人对属性或子元素哪个“看起来更好”有不同的看法。在这种情况下,这取决于个人偏好和风格。
事实上,关于属性与元素的争论大部分都源于个人偏好。许多(但不是全部)论点都归结为“我更喜欢其中一个而不是另一个”。但由于XML同时拥有元素和属性,而且两者都不会消失,所以你可以自由地使用两者。选择最适合你应用程序的,对你来说看起来更好的,或者你最舒适的。
注释
注释提供 了一种方法,可以将不属于文档内容而是为阅读XML源本身的人准备的文本插入到XML文档中。
任何使用过编程语言的人都会熟悉注释的概念:你想能够注解你的代码(或你的XML),以便后来者能够弄清楚你在做什么。(而且要记住:后来者也可能是你自己!你六个月前写的代码可能和你写过的别人的代码一样陌生。)
当然,注释对于XML可能不像对于编程语言那么相关;毕竟,这只是数据,而且它是自描述的。但你永远不知道它们何时会派上用场,而且在某些情况下,注释可能非常有益,即使是在数据中。
注释以字符串<!-- 开始,并以字符串-->结束,如下所示:
<name nickname='Shiny John'>
<first>John</first>
<!--John lost his middle name in a fire-->
<middle></middle>
<last>Doe</last>
</name>
关于注释,我们需要注意几点。首先,你不能在标签内放置注释,所以以下是无效的:
<middle></middle <!--John lost his middle name in a fire--> >
其次,你不能在注释中使用字符串--,所以以下也是无效的:
<!--John lost his middle name -- in a fire-->
XML规范指出,XML解析器不需要将这些注释传递给应用程序,这意味着你不应该指望从你的应用程序中使用注释内的信息。
HTML程序员经常使用在注释中插入脚本代码的技巧,以保护不支持<script>标签的旧版浏览器的用户。这种技巧在XML中是行不通的,因为注释不一定能传递给应用程序。因此,如果你有稍后需要访问的文本,将其放入元素或属性中!
实践一下——为Al的CD添加注释
由于我们在这个精美的专辑中只包含了少数几首歌曲,也许我们应该告知其他人这是情况。这样,好心人可能会为我们完成这项工作!
1. 打开cd2.xml文件,进行以下更改,并将修改后的XML文件保存为cd3.xml:
<CD serial='B6B41B'
disc-length='36:55'>
<artist>"Weird Al" Yankovic</artist>
<title>Dare to be Stupid</title>
<genre>parody</genre>
<date-released>1990</date-released>
<!--date-released is the date released to CD, not to record-->
<song>
<title>Like A Surgeon</title>
<length>
<minutes>3</minutes>
<seconds>33</seconds>
</length>
<parody>
<title>Like A Virgin</title>
<artist>Madonna</artist>
</parody>
</song>
<song>
<title>Dare to be Stupid</title>
<length>
<minutes>3</minutes>
<seconds>25</seconds>
</length>
<parody></parody>
</song>
<!--there are more songs on this CD, but I didn't have time to include
them-->
</CD>
2. 在IE5中查看它:
|
|

工作原理
有了新的注释,任何阅读我们XML文档源代码的人都可以看到,“Dare To Be Stupid”实际上不止两首歌曲。此外,他们还可以看到有关<date-released>元素的一些信息,这可能有助于他们编写处理这些信息的应用程序。
在本例中,IE5附带的XML解析器确实将注释传递给了应用程序,因此IE5显示了我们的注释。但请记住,很多时候,就所有意图和目的而言,这些信息只对阅读源文件的人可用。注释中的信息可能或可能不会传递给我们的应用程序,具体取决于我们使用的解析器。我们不能指望它,除非我们特别选择一个会传递它们的解析器。这意味着应用程序无法知道包含的歌曲列表是否是完整的。
实践一下——确保注释被看到
如果我们确实需要这些信息,我们应该添加一些真正的标记来指示它。
1. 将cd3.xml修改如下,并将其保存为cd4.xml:
<CD><!--our attributes used to be here-->
<songs>11</songs>
<!--the rest of our XML...-->
<artist>"Weird Al" Yankovic</artist>
<title>Dare to be Stupid</title>
<genre>parody</genre>
<date-released>1990</date-released>
<song>
<title>Like A Surgeon</title>
<length>
<minutes>3</minutes>
<seconds>33</seconds>
</length>
<parody>
<title>Like A Virgin</title>
<artist>Madonna</artist>
</parody>
</song>
<song>
<title>Dare to be Stupid</title>
<length>
<minutes>3</minutes>
<seconds>25</seconds>
</length>
<parody></parody>
</song>
</CD>
2. 此XML在IE5中的格式如下:
|
|

这样,应用程序就可以编写成,如果它只找到两个<song>元素,但它找到一个包含文本“11”的<songs>元素,它就可以推断出还缺少9首歌曲。
空元素
有时元素没有数据。回顾我们之前的示例,其中中间元素不包含名称:
<name nickname='Shiny John'>
<first>John</first>
<!--John lost his middle name in a fire-->
<middle></middle>
<last>Doe</last>
</name>
在这种情况下,你还可以选择使用特殊的空元素语法来编写此元素:
<middle/>
这是开始标签不需要单独结束标签的唯一情况,因为它们都合并到了这个单独的标签中。在所有其他情况下,它们都需要。
回想我们关于元素名称的讨论,我们可以在标签内放置空格的唯一位置是在关闭的“>”字符之前。对于空元素,此规则略有不同。斜杠“/”和“>”字符必须始终在一起,所以你可以创建这样的空元素:
<middle />
但不能这样:
<middle/ >
<middle / >
空元素实际上并没有给你带来任何好处——除了它们需要打字更少——所以你可以根据自己的意愿使用它们,也可以不使用。但是请记住,就XML而言,<middle></middle>与<middle/>完全相同;因此,XML解析器有时会将你的XML从一种形式更改为另一种形式。你不应该期望你的空元素是某种形式,但由于它们在语法上完全相同,所以没关系。(这就是为什么IE5可以随意将我们之前的<parody></parody>语法改为<parody/>的原因。)
有趣的是,XML社区似乎没有人介意空元素语法,尽管它没有给语言增加任何东西。考虑到关于属性是否真的有必要的激烈辩论,这一点尤其令人感兴趣。
空元素经常使用的一种情况是对于没有(或可选)PCDATA,但其所有信息都存储在属性中的元素。所以,如果我们改写我们的<name>示例而不使用子元素,而不是使用开始标签和结束标签,我们可能会使用一个空元素,如下所示:
<name first="John" middle="Fitzgerald Johansen" last="Doe"/>
另一个常见示例是仅元素名称就足够的情况;例如,HTML的<BR>标签可以转换为XML的空元素,例如XHTML的<br/>标签。(XHTML是HTML最新的“符合XML”版本。)
XML声明
能够将文档标识为特定类型通常非常方便。XML提供了XML声明,用于将文档标记为XML,并向解析器提供一些其他信息。你不需要XML声明,但最好还是包含它。
典型的XML声明如下所示:
<?xml version='1.0' encoding='UTF-16' standalone='yes'?>
<name nickname='Shiny John'>
<first>John</first>
<!--John lost his middle name in a fire-->
<middle/>
<last>Doe</last>
</name>
关于XML声明需要注意的一些事项:
- XML声明以字符<?xml开始,并以字符?>结束。
- 如果你包含它,则必须包含version,但encoding和standalone属性是可选的。
- version、encoding和standalone属性必须按此顺序排列。
- 目前,version应为1.0。如果你使用的数字不是1.0,那么为1.0规范编写的XML解析器应该会拒绝该文档。(截至目前,还没有宣布对XML规范的其他版本有任何计划。如果将来有,XML声明中的版本号将用于指示你的文档声称支持哪个版本的规范。)
- XML声明必须位于文件的最开始。也就是说,文件中的第一个字符应该是“<”;不能有换行符或空格。有些解析器对此比较宽容。
因此,XML声明可以像上面那样完整,也可以像这样简单:
<?xml version='1.0'?>
接下来的两个部分将更全面地描述XML声明的encoding和standalone属性。
编码
不出所料, 文本在计算机中是使用数字存储的,因为数字是计算机真正能理解的一切。
字符代码是字符集与表示这些字符的相应数字之间的一对一映射。字符编码是用于在数字中表示字符代码的方法(换句话说,每个数字使用多少字节,等等)。
你可能遇到过的一种字符代码/编码是美国信息交换标准代码(ASCII)。例如,在ASCII中,“a”字符用数字97表示,而“A”字符用数字65表示。
有七位和八位ASCII编码方案。8位ASCII每个字符使用一个字节(8位),最多只能存储256个不同的值,因此ASCII限制为256个字符。这足以轻松处理英语所需的所有字符,这就是为什么ASCII在过去许多年里一直是英语世界个人计算机上占主导地位的字符编码。但世界上所有语言中的字符远不止256个,所以显然ASCII只能处理其中的一小部分。这就是Unicode被发明的原因。
Unicode
Unicode是一种从根本上为国际化设计的字符代码,旨在拥有足够多的可能字符来覆盖任何人类语言中的所有字符。Unicode有两种主要的字符编码:UTF-16和UTF-8。UTF-16采取了简单的方法,即为每个字符使用两个字节(两个字节=16位=65,356个可能的值)。
UTF-8更巧妙:它为7位ASCII覆盖的字符使用一个字节,然后使用一些技巧,使任何其他字符可以用两个或更多字节表示。这意味着ASCII文本实际上可以被视为UTF-8的子集,并以此方式处理。对于用英语编写的文本,其中大部分字符将符合ASCII字符编码,UTF-8可以减小文件大小;但对于其他语言的文本,UTF-16通常会更小。
由于Unicode在使其国际化方面所做的工作,XML规范规定所有XML处理器都必须在内部使用Unicode。不幸的是,世界上只有极少数文档是用Unicode编码的。大多数是用ISO-8859-1、windows-1252、EBCDIC或大量的其他字符编码编码的。(许多这些编码,如ISO-8859-1和windows-1252,实际上是ASCII的变体。然而,它们不像“纯粹”ASCII那样是UTF-8的子集。)
指定XML的字符编码
这正是我们XML声明中的encoding属性的作用。它允许我们向XML解析器指定我们的文本使用什么字符编码。然后,XML解析器可以以正确的编码读取文档,并在内部将其转换为Unicode。如果未指定encoding,则假定为UTF-8或UTF-16(解析器必须支持至少UTF-8和UTF-16)。如果未指定encoding,并且文档不是UTF-8或UTF-16,则会导致错误。
有时,XML处理器可以忽略XML声明中指定的encoding。如果文档是通过HTTP等网络协议发送的,可能会有协议特定的头文件指定了与文档中指定的encoding不同的encoding。在这种情况下,HTTP头将优先于XML声明中指定的encoding。但是,如果没有外部encoding来源,并且指定的encoding与文档的实际encoding不同,则会导致错误。
如果你在运行Microsoft Windows操作系统的机器上使用记事本创建XML文档,你默认使用的字符编码是windows-1252。所以你文档中的XML声明应该如下所示:
<?xml version="1.0" encoding="windows-1252"?>
然而,并非所有XML解析器都理解windows-1252字符集。如果是这样,尝试替换ISO-8859-1,它碰巧非常相似。或者,如果你的文档不包含任何特殊字符(例如,重音字符),你可以改用ASCII,或者省略encoding属性,让XML解析器将文档视为UTF-8。
如果你运行的是Windows NT或Windows 2000,记事本还提供了将文本文件保存为Unicode的选项,在这种情况下,你可以在XML声明中省略encoding属性。
Standalone
如果XML声明中包含了standalone属性,它必须是“yes”或“no”。
- “yes”指定该文档完全独立存在,不依赖于任何其他文件。
- “no”表示该文档可能依赖于其他文件。
这个小属性实际上有自己的名称:Standalone Document Declaration,或SDD。XML规范实际上并不要求解析器对SDD做任何事情。它被认为是给解析器的一个提示,而不是别的。
这是SDD的非完整描述。如果它激发了你更多的兴趣,你必须等到第11章,届时一切都会明朗。
现在是时候看看XML声明是如何在实践中工作的了。
实践一下——向世界声明Al的CD
让我们声明我们的XML文档,以便任何解析器都能立即识别它。同时,让我们处理第二个<parody>元素,它没有任何内容。
1. 打开cd3.xml文件,并进行以下更改:
<?xml version='1.0' encoding='windows-1252' standalone='yes'?>
<CD serial='B6B41B'
disc-length='36:55'>
<artist>"Weird Al" Yankovic</artist>
<title>Dare to be Stupid</title>
<genre>parody</genre>
<date-released>1990</date-released>
<!--date-released is the date released to CD, not to record-->
<song>
<title>Like A Surgeon</title>
<length>
<minutes>3</minutes>
<seconds>33</seconds>
</length>
<parody>
<title>Like A Virgin</title>
<artist>Madonna</artist>
</parody>
</song>
<song>
<title>Dare to be Stupid</title>
<length>
<minutes>3</minutes>
<seconds>25</seconds>
</length>
<parody/>
</song>
<!--There are more songs on this CD, but I didn't have time
to include them!-->
</CD>
2. 将文件保存为cd5.xml,并在IE5中查看它。
|
|

工作原理
通过我们的新XML声明,任何XML解析器都可以立即识别它确实是一个XML文档,并且该文档声称符合XML规范的1.0版本。
此外,该文档表明它使用windows-1252字符编码。同样,许多XML解析器不理解windows-1252,所以你可能需要尝试不同的编码。幸运的是,Internet Explorer 5使用的解析器确实理解windows-1252,所以如果你在IE5中查看示例,你可以将XML声明保持为原样。
此外,由于Standalone Document Declaration声明这是一个独立文档,解析器就知道这个文件是它完全处理信息所需的一切。
最后,因为“Dare to be Stupid”不是任何特定歌曲的模仿,<parody>元素已被更改为空元素。这样我们可以直观地强调没有信息。但是请记住,对解析器而言,<parody/>与<parody></parody>完全相同,这就是为什么我们文档的这部分看起来与我们之前的截图相同。
处理指令
虽然并不常见, 但有时你需要将应用程序特定的指令嵌入到你的信息中,以影响其处理方式。XML提供了一种机制来实现这一点,称为处理指令(processing instructions),或更常见的PI。这些允许你在XML中输入不属于实际文档一部分的指令,但会传递给应用程序。
<?xml version='1.0' encoding='UTF-16' standalone='yes'?>
<name nickname='Shiny John'>
<first>John</first>
<!--John lost his middle name in a fire-->
<middle/>
<?nameprocessor SELECT * FROM blah?>
<last>Doe</last>
</name>
PI并没有太多规则。它们基本上就是一个“<?”,要接收PI的应用程序的名称(PITarget),以及直到结束的“?>”为止的任何内容,都是你想要的指令。PITarget受与元素和属性相同的命名规则约束。所以,在这个例子中,PITarget是nameprocessor,而PI的实际文本是SELECT*FROMblah。
PI相当罕见,并且常常被XML社区鄙视,尤其是在被随意使用时。但如果你有正当理由使用它们,那就去做吧。例如,PI可以是放置在HTML注释中的信息(如脚本代码)的绝佳位置。虽然你不能假设注释会传递给应用程序,但PI总是会。
XML声明是处理指令吗?
乍一看,你可能会认为XML声明是一个以xml开头的PI。它使用了相同的“<??>”符号,并为解析器(但不是应用程序)提供指令。那么它是一个PI吗?
实际上,不是:XML声明不是PI。但在大多数情况下,它是否是PI并没有什么区别,所以如果你愿意,可以随意将其视为一个。你可能会遇到麻烦的地方如下:
- 尝试从XML解析器获取XML声明的文本。一些解析器错误地将XML声明视为PI,并像PI一样传递它,但许多解析器不会。事实是,在大多数情况下,你的应用程序不需要XML声明中的信息;这些信息只供解析器使用。一个显著的例外可能是想要向用户显示XML文档的应用程序,就像我们使用IE5显示本书中的文档一样。
- 将XML声明包含在XML文档开头之外的任何位置。虽然你可以在任何地方放置PI,但XML声明必须位于文件的开头。
实践一下——Dare to be Processed
为了看看它的样子,让我们在我们的Weird Al XML中添加一个处理指令:
1. 对cd5.xml进行以下更改,并将文件保存为cd6.xml:
<?xml version='1.0' encoding='windows-1252' standalone='yes'?>
<CD serial='B6B41B'
disc-length='36:55'>
<artist>"Weird Al" Yankovic</artist>
<title>Dare to be Stupid</title>
<genre>parody</genre>
<date-released>1990</date-released>
<!--date-released is the date released to CD, not to record-->
<song>
<title>Like A Surgeon</title>
<length>
<minutes>3</minutes>
<seconds>33</seconds>
</length>
<parody>
<title>Like A Virgin</title>
<artist>Madonna</artist>
</parody>
</song>
<song>
<title>Dare to be Stupid</title>
<length>
<minutes>3</minutes>
<seconds>25</seconds>
</length>
<parody/>
</song>
<?CDParser MessageBox("There are songs missing!")?>
</CD>
2. 在IE5中,它看起来像这样:
|
|

工作原理
在我们的例子中,我们针对一个虚构的应用程序CDParser,并给它指令MessageBox("Therearesongsmissing!")。我们给它的指令在XML本身上下文中没有意义,只对我们的CDParser应用程序有意义,所以CDParser应该如何处理它取决于CDParser。
PCDATA中的非法字符
有一些 保留字符,你不能包含在你的PCDATA中,因为它们在XML语法中使用。
例如,“<”和“&”字符:
<!--This is not well-formed XML!-->
<comparison>6 is < 7 & 7 > 6</comparison>
在IE5中查看上述XML会产生以下错误:
|
|
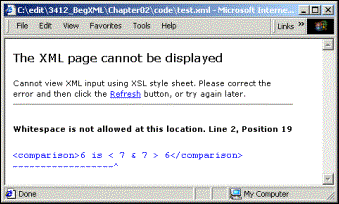
这意味着XML解析器遇到了“<”字符,并期望一个标签名,而不是空格。(即使它过去了,在“&”字符处也会发生同样的错误。)
有两种方法可以解决这个问题:转义字符,或将文本括在CDATA部分中。
转义字符
要转义这两个字符,只需将任何“<”字符替换为<,将任何“&”字符替换为&。上面的XML可以通过这样做格式正确:
<comparison>6 is < 7 & 7 > 6 </comparison>
在浏览器中正确显示:
|
|

请注意,IE5在显示文档时会自动为你取消转义字符,换句话说,它将<和&字符串替换为<和&字符。
<和&被称为实体引用。XML中定义了以下实体:
- & – &字符
- < – <字符
- > – >字符
- ' – '字符
- " – "字符
其他字符也可以通过使用字符引用来转义。这些字符串如&#nnn;,其中“nnn”将被替换为你要插入的字符的Unicode编号。(或者&#xnnn;,前面有一个“x”,其中“nnn”是你想要插入的Unicode字符的十六进制表示。Unicode规范中的所有字符都使用十六进制指定,因此允许XML使用十六进制数字意味着XML作者不必在十六进制和十进制之间转换。)
以这种方式转义字符非常方便,如果你正在编写使用XML编辑器无法理解或无法输出的字符的XML文档,因为转义的字符总是Unicode字符,无论文档使用的编码是什么。例如,你可以通过插入©或©来包含版权符号(©)到XML文档中。
CDATA部分
如果你 有大量的需要转义的“<”和“&”字符,你可能会发现你的文档很快就变得非常丑陋且难以阅读。幸运的是,还有CDATA部分。
CDATA是另一个从SGML继承来的术语。它代表Character DATA。
使用CDATA部分,我们可以告诉XML解析器不要解析文本,而是让它全部通过,直到它到达该部分的末尾。CDATA部分看起来像这样:
<comparison><![CDATA[6 is < 7 & 7 > 6]]></comparison>
从<![CDATA[开始到]]>结束的所有内容都会被解析器忽略,并按原样传递给应用程序。在这个微不足道的例子中,CDATA部分可能看起来比转义更混乱,但在其他情况下,它可能更易读。例如,考虑以下示例,它使用CDATA部分来防止XML解析器解析一部分JavaScript:
<script language='JavaScript'><![CDATA[
function myFunc()
{
if(0 < 1 && 1 < 2)
alert("Hello");
}
]]></script>
如果你不熟悉JavaScript,想知道上面的脚本做了什么,可以看看附录D的教程。
这在IE5浏览器中显示为:
|
|

注意CDATA部分左侧的垂直线。这表明虽然CDATA部分缩进是为了提高可读性,但实际数据本身从这条垂直线开始。这是为了让我们能够直观地看到哪些空格包含在CDATA部分中。
如果你熟悉JavaScript,你可能会觉得if语句比以下代码更容易阅读:
if(0 < 1 && 1 < 2)
实践一下——在XML中谈论HTML
假设我们要创建XML文档,来描述一些现有的HTML标签。
1. 我们可能会开发一种简单的文档类型,如下所示:
<HTML-Doc>
<tag>
<tag-name></tag-name>
<description></description>
<example></example>
</tag>
</HTML-Doc>
在这种情况下,我们确切地知道我们的<example>元素将需要包含HTML语法,这意味着将包含大量“<”字符。这使得<example>成为使用CDATA部分的理想位置,意味着我们不必在所有HTML代码中搜索非法字符。为了演示,让我们来记录几个HTML标签。
2. 创建一个新文件并输入以下代码:
<HTML-Doc>
<tag>
<tag-name>P</tag-name>
<description>Paragraph</description>
<example><![CDATA[
<P>Paragraphs can contain <EM>other</EM> tags.</P>
]]></example>
</tag>
<tag>
<tag-name>HTML</tag-name>
<description>HTML root element</description>
<example><![CDATA[
<HTML>
<HEAD><TITLE>Sample HTML</TITLE></HEAD>
<BODY>
<P>Stuff goes here</P
</BODY>/HTML>
]]></example>
</tag>
<!--more tags to follow...-->
</HTML-Doc>
3. 将此文档保存为html-doc.xml并在IE5中查看:
|
|

工作原理
由于我们的CDATA部分,我们可以将任何我们想要的内容放入<example>元素中,而不必担心文本与文档的实际XML标记混淆。这意味着即使第二个<example>元素中有错别字(</P>缺少>,/HTML>缺少<),我们的XML也不会受到影响。
解析XML
编写格式正确的XML文档 的所有规则的主要原因,是为了让我们能够创建一个计算机程序来读取数据,并轻松地区分标记和信息。
根据XML规范(http://www.w3.org/TR/1998/REC-xml-19980210#sec-intro):“一个称为XML处理器的软件模块用于读取XML文档并提供对其内容和结构的访问。假定XML处理器代表另一个称为应用程序的模块进行工作。”
XML处理器通常称为解析器,因为它只是解析XML并向应用程序提供它所需的所有信息。有相当多的XML解析器可用,其中许多是免费的。下面列出了一些比较知名的:
Microsoft Internet Explorer Parser
微软的第一个XML解析器随Internet Explorer 4发布,并实现了XML规范的一个早期草案。随着IE5的发布,XML实现已升级以反映XML 1.0规范。最新版本的解析器(2000年3月技术预览版)可从http://msdn.microsoft.com/downloads/webtechnology/xml/msxml.asp下载。在本书中,我们将主要使用IE5版本。
James Clark的Expat
Expat是一个用C语言编写的XML 1.0解析器工具包。更多信息可以在http://www.jclark.com/xml/expat.html找到,并且Expat可以从ftp://ftp.jclark.com/pub/xml/expat.zip下载。它对私人和商业使用都是免费的。
Vivid Creations ActiveDOM
Vivid Creations(http://www.vivid-creations.com)提供了几种XML工具,包括ActiveDOM。ActiveDOM包含一个类似于Microsoft解析器的解析器,并且,尽管它是一个商业产品,但可以在Vivid Creations网站上下载演示版本。
DataChannel XJ Parser
DataChannel是一家业务解决方案软件公司,与Microsoft合作生产了早期用Java编写的XML解析器。他们的网站(http://xdev.datachannel.com/directory/xml_parser.html)提供了获取其最新版本的链接。但是,他们不再进行解析器开发。他们选择改用IBM的xml4j解析器。
IBM xml4j
IBM的AlphaWorks网站(http://www.alphaworks.ibm.com)提供了许多XML工具和应用程序,包括xml4j解析器。这是另一个用Java编写的解析器,免费提供,但有一些关于其使用的许可限制。
Apache Xerces
Apache软件基金会的Apache XML项目(http://xml.apache.org/)的Xerces子项目产生了Java和C++的XML解析器,以及C++解析器的Perl封装。这些工具处于Beta阶段,是免费的,代码的发布受GNU通用公共许可证控制。
XML中的错误
除了规定解析器应如何从XML文档中获取信息外,还规定了解析器应如何处理XML中的错误。XML规范中有两种错误:错误(errors)和致命错误(fatal errors)。
- 错误只是对规范规则的违反,其结果是未定义的;XML处理器可以从错误中恢复并继续处理。
- 致命错误更为严重:根据规范,当解析器遇到致命错误时,它不允许正常继续。(但是,它可以继续处理XML文档以查找更多错误。)任何导致XML文档不再格式正确的错误都是致命错误。
这种对非格式正确XML的严厉处理的原因很简单:对于解析器编写者来说,处理“格式正确性”错误会非常困难,而使XML格式正确则非常简单。(HTML并不强制文档像XML那样严格,但这是导致网页浏览器如此不兼容的原因之一;它们必须处理所有可能遇到的错误,并尝试弄清楚文档编写者真正想编写的代码。)
但严厉的错误处理不仅使解析器编写者受益;它也使我们受益。如果我编写了一个不正确遵循XML语法的XML文档,我可以立即发现并纠正我的错误。另一方面,如果XML解析器试图从这些错误中恢复,它可能会误解我的意图,但我不会知道,因为不会发出错误。在这种情况下,我的软件中的错误将更难追踪,而不是在创建数据之初就被捕获。
摘要
本章提供了编写格式正确XML文档的基本语法。
我们已经看到:
- 元素和空元素
- 如何在XML中处理空格
- 属性
- 如何包含注释
- XML声明和编码
- 处理指令
- 实体引用、字符引用和CDATA部分
我们还了解到,为什么XML语法的严格规则最终对我们有益,以及HTML创作的一些规则与格式正确的XML创作规则有何不同。
不幸的是——或者也许是幸运的——你可能不会花很多时间仅仅编写XML文档。但是一旦你将数据以XML形式处理,你仍然需要能够使用这些数据。在接下来的章节中,我们将学习XML周围的一些其他技术,这些技术将帮助你利用你的数据,首先是其中最常见的:显示。