
用于“两层列表”GUI的有排名文本搜索算法及其应用
5.00/5 (4投票s)
我将“短语相似性计算”算法应用于一个显示我称之为“两层列表”的GUI窗体。
引言
本文进一步发展了我之前的一篇文章““短语相似性计算”算法及其在“自动补全”功能中的应用”中描述的算法(https://codeproject.org.cn/Articles/638280/An-algorithm-of-phrases-similarity-calculation-and)。
这一次,我将“短语相似性计算”算法应用于一个GUI窗体,该窗体显示了我称之为*双层列表*的内容

如上图所示,GUI要求用户选择一种媒体格式 - 例如“Apple iPhone MPEG-4 Movie (*.mp4)”、“Apple iPhone 4 MPEG-4 Movie (*.mp4)”、“Apple iPad MPEG-4 Movie (*.mp4)”等。媒体格式被分组到类别中:类别“Apple iPhone”包含“Apple iPhone MPEG-4 Movie (*.mp4)”、“Apple iPhone 4 MPEG-4 Movie (*.mp4)”等。用户在类别列表框中选择一个类别;然后,在格式列表框中选择一个格式;最后,点击APPLY按钮,该按钮应该对选定的格式执行某些操作。因此,“双层列表”这个名称意味着屏幕上的信息组织在两个级别上:类别是层次结构的“上层”,格式是层次结构的“下层”。也可以将这种方法称为“具有2个层次的层级结构”;但我更喜欢更简洁的“双层列表”定义。
这种层级GUI组织是一种相当标准的方法;但我在此基础上增加了*快速文本搜索*功能,通过输入的关键字进行搜索——这就是上面屏幕截图中的“按以下方式查找格式:”搜索框。搜索会根据输入的关键字过滤掉类别列表框和过滤器列表框的内容;(最重要的是本文的内容)根据内容与搜索查询的匹配程度来显示过滤后的内容。换句话说,类别列表框和过滤器列表框中的项目将按与搜索查询的匹配度递减的顺序排列。
本文附带了一个包含该算法实现的演示应用程序。该演示是以C# WPF应用程序的形式实现的。
目标读者
本文的潜在读者是那些实现具有大量“项目”的GUI的开发人员——这些项目足够多,以至于
- 这些项目需要层级组织(按“类别”/“组”/“文件夹”/“章节”等分组)
- 引入“快速搜索”(或“按关键字过滤”——随你怎么称呼)功能
此方法的示例是Windows 7的控制面板

Windows 7控制面板中大量的“项目”促使微软很早以前(可能自1980年代的第一个Windows版本以来)就将它们组合到组中(“显示”、“字体”等)。但随着项目数量的不断增长,层级组织已不足以提供对所需项目的快速访问。微软也不得不引入“快速搜索”功能:你输入一个关键字,控制面板的内容就会被过滤掉。
如果你的GUI,就像Windows控制面板一样,有数十个“项目”被组织到许多“类别”中——那么是时候考虑添加“快速搜索”功能了。“快速搜索”将帮助你的最终用户只需输入一个关键字(或几个初始字母)就能找到他们需要的东西。我的算法还能按匹配度递减的顺序对搜索结果进行排序,从而在列表顶部显示“最有价值”的搜索结果。
免责声明和限制
在阅读本文之前,必须阅读之前的“短语相似性计算”算法及其在“自动补全”功能中的应用一文。
附带的演示不是一个可以直接“拖放”到你的应用程序中的现成“控件”。它只是一个如何实现本文所述方法的示例。
演示是关于“媒体格式”按“类别”分组的特定示例;但你可以在任何“项目”按任何“类别”分组的GUI中使用这种方法。
附带的演示是WPF应用程序;但当然,这种方法几乎可以在任何类型的GUI应用程序中使用——例如,在网页上(使用JavaScript)。
演示中的算法实现包含一些仅适用于英语的“硬编码”事实(例如“the”等“第二类词”列表)。因此,演示只能用于英文查询。如果你想为其他语言使用该算法,请用你语言特有的“第二类词”来填充该列表。
算法的输入、输出和使用场景
搜索算法假设信息组织为以下2级层级结构:“文件夹”,其中可能(也可能不)包含“子文件夹”。就附带的演示而言,文件夹是媒体格式类别,子文件夹是媒体格式。例如,文件夹(类别)“Apple iPhone”包含子文件夹(媒体格式)“Apple iPhone MPEG-4 Movie (*.mp4)”、“Apple iPhone 4 MPEG-4 Movie (*.mp4)”等。
每个文件夹/子文件夹都有一个[非空]文本描述(“Apple iPhone”、“Apple iPhone MPEG-4 Movie (*.mp4)”)。关键字搜索在此类文本(我们称之为“文本属性”)上进行。每个文件夹/子文件夹还可以关联一个任意的“数据对象”。搜索算法不考虑“数据对象”;它们是为了关联开发人员需要的任何类型的对象(可能是一个复杂的对象)而引入的。例如,这可能是一个应在GUI中显示的图标,或者其他任何东西。
当用户在GUI中输入(或修改)搜索短语(查询)时,算法会执行搜索——它会查找“匹配”该查询的文件夹/子文件夹。找到的文件夹/子文件夹将按其匹配度(相对于给定的查询)返回。如果文件夹#1比文件夹#2“更匹配”,算法会将文件夹#1放在结果列表的前面,而不是文件夹#2。
匹配度被考虑在子文件夹在文件夹内的排序中。例如,如果搜索找到了一个文件夹#1,其中包含子文件夹#1和子文件夹#2;并且子文件夹#1(在文件夹#1的范围内)比子文件夹#2“更匹配”,算法会将子文件夹#1放在(文件夹#1的子文件夹列表中的)子文件夹#2之前。
GUI应该按照搜索返回的匹配度顺序显示找到的文件夹/子文件夹。以下面为例

搜索算法通过查询“ip”进行了搜索,并返回了两个文件夹——“Apple iPad”和“Apple iPhone”。算法认为“Apple iPad”的匹配度等级比“Apple iPhone”高;因此,GUI将“Apple iPad”显示在“Apple iPhone”之前。
搜索返回的“Apple iPhone”包含两个子文件夹——“Apple iPhone MPEG-4 Movie (*.mp4)”和“Apple iPhone 4 MPEG-4 Movie (*.mp4)”。算法认为“Apple iPhone MPEG-4 Movie (*.mp4)”的匹配度等级(在“Apple iPad”文件夹的范围内)高于“Apple iPhone 4 MPEG-4 Movie (*.mp4)”;因此,GUI将“Apple iPhone MPEG-4 Movie (*.mp4)”显示在“Apple iPad”子文件夹列表中的第一个位置。
注意:正如我上面已经说过的,搜索返回的子文件夹的等级仅在其[父]文件夹的范围内才重要。换句话说,GUI应该按照子文件夹的等级来显示它们的列表。但无论子文件夹的等级如何,都不会影响它们在自己列表(演示中的“类别”列表框)中的显示顺序。
算法概述
我们使用文章““短语相似性计算”算法及其在“自动补全”功能中的应用”中描述的算法作为基础。我们分别计算每个文件夹及其所有子文件夹的等级。然后,我们将它们(文件夹的等级和所有子文件夹的等级)“合并”成文件夹的“最终”等级。
算法细节
我们使用文章““短语相似性计算”算法及其在“自动补全”功能中的应用”中描述的算法作为基础。我们分别计算每个文件夹及其所有子文件夹的等级。然后,我们将它们(文件夹的等级和所有子文件夹的等级)“合并”成文件夹的“最终”等级。
当搜索开始时,我们有一个文件夹列表和一个查询。一个文件夹可以表示为以下数据结构
- ID 属性——文件夹的唯一ID;
- Text 属性——文件夹的文本描述(例如,“Apple iPad”);
- DataObject 属性——文件夹的“数据对象”;对搜索算法而言,其本质无关紧要;
- Weight - 一个在]0,….]范围内的数字,它是文件夹相对于其他文件夹的“相对权重”。使用Weight允许我们将某个文件夹与其他文件夹相比“更重要”或相反“不那么重要”。如果你不需要此功能——只需为你拥有的所有文件夹分配1.0;
- Sub-Folders 列表——文件夹的子文件夹列表(可能为空)。
子文件夹可以表示为以下数据结构
- ID 属性——子文件夹的唯一ID;
- Text 属性——子文件夹的文本描述(例如,“Apple iPhone 4 MPEG-4 Movie (*.mp4)”);
- Weight - 一个在]0,….]范围内的数字,它是子文件夹相对于其他子文件夹的“相对权重”。使用Weight允许我们将某个子文件夹与其他子文件夹相比“更重要”或相反“不那么重要”。如果你不需要此功能——只需为你拥有的所有子文件夹分配1.0;
- DataObject 属性——文件夹的“数据对象”;对搜索算法而言,其本质无关紧要。
该算法返回一个Output Folders列表。“Output Folder”可以表示为以下数据结构
- ID 属性——与Output Folder相对应的输入文件夹的ID;
- Rank 属性——一个数字,表示Output Folder的“匹配度等级”;
- Sub-Folders 列表——Output Folder的Output Sub-Folders列表(可能为空)。
“Output Sub-Folder”可以表示为以下数据结构
- ID 属性——与Output Sub-Folder相对应的输入子文件夹的ID;
- Rank 属性——一个数字,表示子文件夹的“匹配度等级”;
我们还引入以下常量
- SubfolderReducingRate = 0.5.
我们对每个文件夹执行以下操作
1. 将““短语相似性计算”算法及其在“自动补全”功能中的应用”算法应用于文件夹(更确切地说是其Text属性),并将返回的值表示为FolderRank。
执行以下操作
FolderRank = FolderRank*Weight [文件夹的Weight]。
2. 定义一个变量FinalRank并将其初始值设为0.0。
3. 迭代所有子文件夹,并对每个子文件夹执行以下操作
将““短语相似性计算”算法及其在“自动补全”功能中的应用”算法应用于子文件夹(更确切地说是其Text属性),并将返回的值表示为SubfolderRank。
执行以下操作
SubfolderRank = SubfolderRank * Weight [子文件夹的Weight];
SubfolderRank = SubfolderRank * SubfolderReducingRate
如果FolderRank和SubfolderRank都为0(换句话说,文件夹和子文件夹均无匹配),则我们跳过该子文件夹,不将其添加到Output Folder对象的Sub-Folders列表中。
否则,我们将新的Output Sub-Folder项添加到Output Folder对象的Sub-Folders列表中。ID属性将用输入子文件夹ID填充。Rank属性将用计算出的SubfolderRank填充。
执行以下操作
FinalRank = FinalRank + SubfolderRank
4. 迭代完所有子文件夹后,查看计算出的FinalRank。
如果为0——则表示未检测到文件夹匹配。
否则,我们返回Output Folder对象。
其Sub-Folders列表已在步骤3中构建(可能为空)。现在我们按Rank值递减的顺序对列表进行排序。
其ID属性将用Folder ID填充。
其Rank属性将用FinalRank值填充。
注意:正如你从算法中看到的,我们在创建Output Folder项时使用了以下逻辑
- 如果文件夹的文本与查询匹配——则足以将所有子文件夹包含在子文件夹列表中(即使它们的文本与查询完全不匹配);
- 只有当子文件夹不匹配查询且文件夹文本也不匹配查询时,子文件夹才不会被包含在Output Folder的子文件夹列表中。
迭代完所有文件夹后,我们按Rank值递减的顺序对Output Folder对象的列表进行排序。排序后的列表将作为算法的搜索结果返回。
实现
附带的演示是C#/WPF上的算法简单实现。它关于“媒体格式”(算法中的子文件夹)按“类别”(算法中的文件夹)分组的特定示例。用户应该在“按以下方式查找格式:”字段中输入查询来过滤类别和格式列表。

然后,用户应该在类别列表框中选择一个类别;然后,在格式列表框中选择一个格式;最后,点击APPLY按钮,该按钮(如果这是一个真实应用程序而不是演示)应该对选定的格式执行某些操作。
在该示例中,文件夹/子文件夹的“数据对象”和权重实际上未使用:搜索算法支持它们,但GUI不填充它们。因此,所有文件夹/子文件夹的Weight属性都具有相同的默认值1.0。
GUI在更新类别和格式列表时,采用“尝试保存用户选择”的原则,当用户输入查询时。我的意思是以下几点。假设用户输入了“touch”查询,屏幕上的当前情况如下
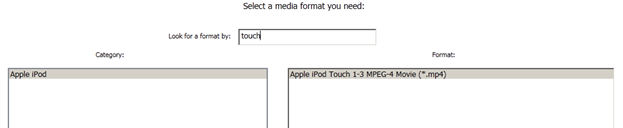
然后,用户将查询“touch”替换为“i”

如上图所示,**先前选定的**类别和格式项目仍然被选中,尽管类别和格式列表已用几个新项目重新加载。
现在让我们考虑一个更复杂的情况。假设屏幕上的情况如下

然后,用户将查询“wmv”替换为“mp4”

如上图所示,**先前选定的**类别(“Microsoft Zune”)在替换后仍然被选中。在这种情况下,无法保留先前选定的格式(“Microsoft Zune WMV Movie (*.wmv)”)的选中状态,因为它已消失(被新查询过滤掉了)。但GUI至少保留了类别的选中状态;并自动选择新查询显示的其另一个格式——“Microsoft Zune MPEG-4 Movie (*.mp4)”。
换句话说——当查询字段更改并且由于更改而重新加载类别和格式列表时,GUI会尝试(如果可能)保留先前使用的格式和/或类别列表的选定状态。这是在MainWindow.txtQuery_TextChanged方法中实现的。
文件夹AutocompletionEngine包含了搜索算法的所有逻辑。
静态列表AutocompletionEngine.Processor.Word.ArticlesEtc包含“第二类”单词的硬编码列表(参见相似性因子)。如果你想让算法正确处理非英文查询,请用你语言的“第二类词”来填充该列表。
文件夹UnitTest包含一组基于NUnit的对AutocompletionEngine.Processor类的自动化测试。因此,该项目需要nunit.framework.dll库。