
C++ 中具有整数键的映射的快速实现。
4.81/5 (9投票s)
本文介绍了带有整数键的映射的算法和实现,并包含基准测试结果。
引言
在许多应用程序中,我们必须处理稀疏数组或带有整数键的映射。当元素数量相当少(例如,不超过一千个)时,使用标准的 std::map 或 std::unordered_map 就足够了。当键的数量增加时,这些映射的表现不佳:我们希望考虑更快的容器。在本文中,我将尝试研究实现整数键映射的各种方法并测量它们的性能。
代码已在 Microsoft Visual C++ 14 CTP 和 GNU C++ 4.9 中测试。
现有映射容器有问题吗?
现有的 std::map 和 std::unordered_map 将元素分散在堆中,这导致对元素的访问效率低下(由于缓存未命中),尤其是当它们的数量接近 100,000 时。这显然取决于元素的大小。衡量效率的两个主要标准可以是:
- 随机访问的速度
- 扫描整个列表的速度
其他标准可能是元素的创建和删除速度。如果我们真的想实现高效的随机访问,我们不妨用值数组替换映射,并将其索引用作键。只有满足以下两个条件,这才能很好地工作:
- 有足够的内存空间来容纳给定键值范围的整个数组。
- 我们要么不需要扫描所有元素,要么对扫描速度感到满意,如果值中存在大间隔,扫描速度可能不会很快。
另一种选择是使用扁平映射 (flat map),它不在 C++ STL 中,但在 Boost [1] 中可用。(我也提供了我自己的扁平映射实现。)扁平映射是一个“键值”对的有序数组,按照它们的键排序。扁平映射的优点是它提供了按键顺序扫描元素的最快方式。它也是所有映射中最紧凑的。但它存在以下问题:
- 随机访问速度不是很快。
- 当元素数量超过 100,000 时,添加和删除元素相当慢。
我将尝试考虑一些其他方法,并将其性能与已知映射容器进行比较。
建议的映射容器
扁平索引映射 (Flat Index Map)
此容器尝试通过使用 std::vector<bool> 类型的额外变量来解决扁平映射的一些缺陷,该变量告诉我们具有给定索引的元素是否存在于扁平映射中。这种方法提高了随机访问的速度,因为在检查元素是否存在时,算法首先查看此向量,如果元素不存在,则无需进一步查找。这在未命中的情况下节省了大量时间,当映射中存在大量间隙时。您必须付出的代价是 std::vector<bool> 的大小,它应该能够包含映射中使用的所有可能索引范围。
无序索引映射 (Unordered Index Map)
此映射类似于 [2,3,4] 中讨论的无序稀疏集。该映射通过两个数组实现。一个称为密集 (dense)(无间隙),包含“索引-值”对。另一个称为稀疏 (sparse),包含存在元素的第二个数组的索引。规则是:
dense[sparse[i]].first = i
此映射提供非常快速的扫描功能,因为密集数组的性质——没有间隙。随机访问也相当快:dense[sparse[i]] 给出所需的对。缺点是密集数组的值是无序的,并且该映射需要大量的内存空间,大致与映射中使用的索引范围成比例。
稀疏映射 (Sparse Map)
这是一个有序映射,有点类似于无序索引映射:它由一个稀疏数组和一个密集列表(有序对)组成。稀疏数组包含指向(实现中的迭代器)密集列表的指针。每次算法尝试添加新元素时,它都会将其放入密集列表中的正确位置,并设置稀疏数组中的相关指针:稀疏数组有助于使其更高效。与无序索引映射相比,优点是它是有序的。
两级映射 (Two-Level Map)
两级映射试图通过使用映射的映射方法来解决扁平映射生成速度的问题。在此实现中,我使用了两个扁平映射:它们是最紧凑的。第一级映射是第二级映射的映射。每个第二级映射可以具有 [0-4095] 范围内的索引。与扁平映射相比,此映射提供了更快的映射生成算法。
基准测试
一般评论
在这些基准测试中,我使用了索引范围固定为 [0; 9,999,999] 的映射。元素数量在 20 到 10,000,000 之间变化。每个元素都包含一个无符号键和一个双精度浮点值。
此索引范围影响了某些映射所需的内存大小。std::map、std::unordered_map 和扁平映射使用的内存确实取决于可能的索引范围:它仅取决于映射中实际存在的元素。在某种程度上,两级映射也是如此:但它增长的速度取决于范围。其他映射的内存使用量严重依赖于可能的索引范围。
映射生成
结果如图 1 所示。您可能会看到扁平映射和扁平索引映射的生成速度特别慢。两级映射不是最快的,但它设法将其“控制在可控范围内”。稀疏集在元素数量小于 10,000 时速度较慢,但当数量增加时,它开始超越其他映射。

随机访问
结果如图 2 所示。这里的“赢家”是:稀疏映射、无序索引映射和 std::unordered_map。当存在大量未命中时,扁平索引映射表现非常好,但当大多数间隙被填满时,它开始变慢。您可能认为扁平索引映射相当快:当只处理成功命中时,它会很慢。

扫描整个元素范围
结果比较如图 3 所示。每次扫描所需的时间除以元素数量:我们得到了每个元素以纳秒为单位的时间。这里的赢家显然是:扁平映射、扁平索引映射和无序索引映射,因为它们使用成对的密集数组进行扫描。两级映射也接近。稀疏映射和无序映射在元素数量小于 10,000 时表现良好。

元素删除
在某种程度上,大多数映射的删除速度与生成速度相似。例外是稀疏映射。结果如图 4 所示。这里最大的“输家”是扁平映射和扁平索引映射,就像生成速度的情况一样。

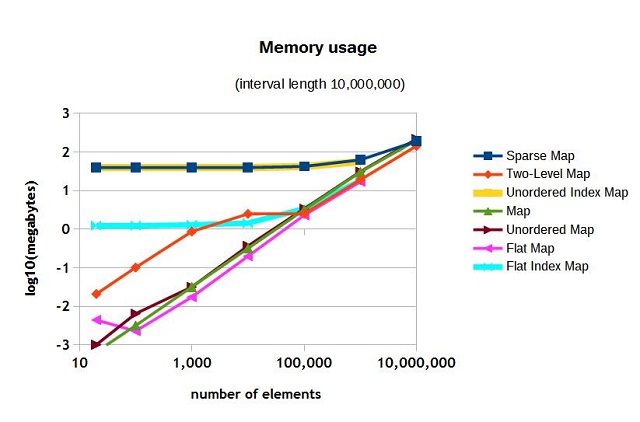
内存使用
范围 [0;9,999,999] 的内存使用量如图 5 所示。这里的“输家”是稀疏映射、无序索引映射和扁平索引映射。
结论
问题是:哪个映射是最好的?答案并非如此简短。如果您处理的元素少于 1000 个,我不会太在意。在这种情况下,扁平映射可能是最有效的,而且非常紧凑,此外它将提供最快的扫描算法。如果范围更大,问题在于什么更重要:
- 如果是随机访问,那么您可以使用
std::unordered_map、稀疏映射或无序索引映射(这三者中只有稀疏映射是有序的); - 如果扫描更重要,那绝对是两级映射(扁平映射在生成方面慢得多)。
参考文献
- [1]。https://boost.ac.cn/
- [2]。Briggs, P., Torczon, L.: An efficient representation for sparse sets. ACM Letters on Programming Languages and Systems 2(1–4), 59–69 (1993)
- [3]。http://cp2013.a4cp.org/sites/default/files/uploads/trics2013_submission_3.pdf
- [4]。https://codeproject.org.cn/Articles/859324/Fast-Implementations-of-Sparse-Sets-in-Cplusplus