
在 Hadoop Map-Reduce 中实现 Join
5.00/5 (8投票s)
如何在 Reduce 和 Map 阶段的 Hadoop Map-Reduce 应用程序中实现 Join
引言
在 HADOOP 中连接两个数据集可以通过两种技术来实现
- 在
Map阶段进行 Join - 在
Reduce阶段进行 Join
在本文中,我将演示这两种技术,从在 Map-Reduce 应用程序的 Reduce 阶段进行 Join 开始。当两个数据集都很大时,推荐使用此技术。
然后,我将在示例查询中再加入另一个 join,并在 Map 阶段实现。那么,我们开始吧。
下载数据集
我将用于演示 Join 的数据集是微软流行的 Adventure Works 数据集。在本文中,我将使用 Adventure Works 数据集的 .csv 版本,可以从 此处 下载。
对于这个例子,请下载 Adventure Works 2012 OLTP 脚本,其中包含一个将 .csv 文件加载到 SQL Server 数据库的脚本,当然还有这个例子中将使用的 .csv 文件。这个例子中使用的三个文件是
- SalesOrderDetails.csv
- Products.csv
- ProductSubCategory.csv
这些文件包含制表符分隔的数据,并且不包含标题行,因此可以使用 此参考 来查看每列包含什么数据。
在 Reduce 阶段进行 Join
解释 join 的目标最好的方法是使用 SQL 来解释。参考 dataset,这里的目标是将 SalesOrderDetail 数据与 Product 数据连接起来,并获取每种产品的总销售数量以及每种产品的总金额(LineTotal 的总和)。等效的 SQL 查询是
select P.ProductID, P.Name, P.ProductNumber, Sum(S.OrderQty), Sum(S.LineTotal)
from SalesOrderDetails S join Products P
on S.ProductID = P.ProductID
where S.OrderQty > 0
那么,让我们看看这个查询在 Map-Reduce 中是如何实现的。
项目初始设置
在本例中,我使用的是带有 Maven 插件的 Eclipse。Maven 消除了手动包含依赖项的需要,使过程更简单快捷。如何在 Eclipse 中安装 Maven 插件超出了本文的范围,但它很简单,快速的 Google 搜索应该足以将您指向正确的方向。
因此,开始一个名为 HadoopJoinExample 的新 Maven 项目。

确保选中 Simple Project 复选框。接下来,使用 Maven 在项目中包含 Hadoop 2.5.1 依赖项。打开 pom.xml 文件,在 dependencies 中添加新依赖项

在字段中添加以下内容
Grpup Id: org.apache.hadoop
Artifact Id: hadoop-client
Version: 2.5.1

接下来,右键单击项目,选择 Run As → Maven Install。它会包含依赖项,并显示成功消息。在 Maven Dependencies 中的项目浏览器中可以看到已添加的依赖项。

实现 Mapper 键类
Mapper 键类将有两个字段:ProductId 和 RecordType(指示记录来自 Products 还是 Sales Order 数据。本例使用两个 mapper,一个用于 Products 数据,另一个用于 Sales Order 数据。
该类称为 ProductIdKey,它实现了 WritableComparable<ProductIdKey>,这使其能够被序列化和反序列化,并且还能与其他记录进行比较。这种比较对于稍后的记录排序和分组很重要。
此外,ProductIdKey 还有一个 hashCode 方法,返回将由分区器使用的哈希码。我将在过程中解释所有这些,所以,创建一个实现 WritableComparable<ProductIdKey> 接口的新类,名为 ProductIdKey。
WritableComparable<T> 接口要求从它扩展的 Writable 接口实现以下方法
public void write(DataOutput out)
public void readFields(DataInput in)
这些 write 和 readFields 方法来自 WritableComparable<T> 接口所扩展的 Writable 接口,它们允许数据被序列化和反序列化。这是必需的,因为数据通过网络从 Mapper 发送到 Reducer 节点,因此,Mapper 键和值类必须是可序列化的,并且为键类实现 WritableComparable<T> 是实现这一目标的一种简单方法(还有其他方法,如使用 RawComparator,但它们不属于本文的讨论范围)。Mapper 值类只需要实现 Writable,因为排序和分组仅在键类上进行,因此值(或数据)类不需要可比较部分。Hadoop 默认提供的绝大多数重要键类,如 IntWritable、Text 都实现了 WritableComparable<T>。
write 方法将所有属性写入 Java 的 java.io.DataOutput 流。而 read 方法则从 java.io.DataInput 流中读取。字段的读取顺序必须与写入顺序相同。
接下来是 Comparable<T> 接口,WritableComparable<T> 扩展了该接口,该接口提供了方法
public int compareTo(ProductIdKey other)
根据比较返回一个整数。比较器(用于对 mapper 发送的键/值对进行排序的排序比较器,以及将它们分组的分组比较器)使用此比较来在发送到 reducer 节点时对数据进行排序和分组。
因此,正如前面解释的,我们的 ProductIdKey 类有两个字段,ProductId 和 RecordType(0 = Product 记录,1 = Sales Order 数据记录)。将它们声明为
public IntWritable productId = new IntWritable();
public IntWritable recordType = new IntWritable();
为了方便起见,我们提供一个构造函数来初始化两者,以及一个 Hadoop 所需的默认无参构造函数
public ProductIdKey(){}
public ProductIdKey(int productId, IntWritable recordType) {
this.productId.set(productId);
this.recordType = recordType;
}
接下来是 WritableComparable 接口的 Writable 部分,字段的写入和读取方式如下
public void write(DataOutput out) throws IOException {
this.productId.write(out);
this.recordType.write(out);
}
public void readFields(DataInput in) throws IOException {
this.productId.readFields(in);
this.recordType.readFields(in);
}
接下来是 Comparable 接口方法
public int compareTo(ProductIdKey other) {
if (this.productId.equals(other.productId )) {
return this.recordType.compareTo(other.recordType);
} else {
return this.productId.compareTo(other.productId);
}
}
这是一个重要的概念,因为排序比较器和分组比较器,如果未在外部提供,它们的默认实现都会调用此方法。分组比较器会分组键,并将每个键(及其所有值包装在 Iterable<T> 中)发送到 reducer 的一个 reduce 调用,而排序比较器则确定键的排序顺序。
我们的目标是捕获两个 mapper 的输出(一个用于 Product 数据,另一个用于 Sales Order 数据),并将每个 Product Id 发送到同一个 reduce 调用,而不考虑记录来自 Product 还是 Sales Order 数据(即忽略 RecordType 字段),并且此示例中的排序方式是使 Product 记录先于数据记录出现,因此可以使用默认的 compareTo,无需使用自定义排序比较器,因为默认方法会调用它,但为了解释,我将提供自定义排序和分组比较器。
接下来,我们需要 equals 方法和 hashCode 方法。hashCode 方法将由分区器用于确定哪个记录将发送到哪个 reducer。在这种情况下,我们希望具有相同 ProductId 的所有记录到达同一个 reducer,因此,hashCode 方法将仅使用键的 ProductId 字段来生成哈希,这得益于 IntWritable 已经提供了此功能,所以只需调用它即可
public boolean equals (ProductIdKey other) {
return this.productId.equals(other.productId) && this.recordType.equals(other.recordType );
}
public int hashCode() {
return this.productId.hashCode();
}
最后,两个常量
public static final IntWeriable PRODUCT_RECORD = new IntWritable(0);
public static final IntWritable DATA_RECORD = new IntWritable(1);
这样,Mapping 键类就完成了。这将由两个 Mapper 发出。下一步是定义 Data 类。
SalesOrderDataRecord 和 ProductRecord 类
如前所述,数据类只需要实现 Writable 以允许序列化和反序列化。
SalesOrderDataRecord 将由处理 Sales Order 数据的 mapper 发出,它将包含一个名为 orderQty 的字段中的数量,以及一个名为 lineTotal 的字段中的行总计。该类变为
public class SalesOrderDataRecord implements Writable {
public IntWritable orderQty = new IntWritable();
public DoubleWritable lineTotal = new DoubleWritable();
public SalesOrderDataRecord(){}
public SalesOrderDataRecord(int orderQty, double lineTotal) {
this.orderQty.set(orderQty);
this.lineTotal.set(lineTotal);
}
public void write(DataOutput out) throws IOException {
this.orderQty.write(out);
this.lineTotal.write(out);
}
public void readFields(DataInput in) throws IOException {
this.orderQty.readFields(in);
this.lineTotal.readFields(in);
}
}
而 ProductRecord 类,正如开头 SQL 语句所明确的,应该是
public class ProductRecord implements Writable {
public Text productName = new Text();
public Text productNumber = new Text();
public ProductRecord(){}
public ProductRecord(String productName, String productNumber){
this.productName.set(productName);
this.productNumber.set(productNumber);
}
public void write(DataOutput out) throws IOException {
this.productName.write(out);
this.productNumber.write(out);
}
public void readFields(DataInput in) throws IOException {
this.productName.readFields(in);
this.productNumber.readFields(in);
}
}
扩展 GenericWritable 类
由于两个 mapper 发出不同的类,reducer 需要一个通用类型,最明显的选择是 Writable,两者都实现了该接口,但事实证明,Hadoop reducer 需要精确的类型,并且我们需要在设置作业时使用 setMapOutputValue 方法来指定这一点。否则,在运行作业时会出现类似 “Expected Writable, getting SalesOrderDataRecord” 的错误。Hadoop 提供了 GenericWritable 类,它可以包装由多个 mapper 发出的类,并可用于按我们需要的类型获取和设置 Writable 实例。
有关 GenericWritable 的详细信息,请参阅 此文档。
GenericWritable 通过扩展它并重写 getTypes 方法来使用,该方法指示将包装哪些类型。此处指定的所有类型必须实现 Writable。
代码如下
public class JoinGenericWritable extends GenericWritable {
private static Class<? extends Writable>[] CLASSES = null;
static {
CLASSES = (Class<? extends Writable>[]) new Class[] {
SalesOrderDataRecord.class,
ProductRecord.class
};
}
public JoinGenericWritable() {}
public JoinGenericWritable(Writable instance) {
set(instance);
}
@Override
protected Class<? extends Writable>[] getTypes() {
return CLASSES;
}
}
Partitioner (分区器)
在本例中,我们需要所有具有相同 ProductId 的记录发送到同一个 Reducer,以便可以计算总数。Partitoner 类的 getPartition 函数在 Mapper 输出的每个键/值对上被调用,并相应地将其发送到 Reducer。如果没有指定分区器,则使用默认分区器,就像本例一样。由于我们在 getHashCode 函数的定义中使其仅基于我们键类的 productId 字段返回键,因此默认分区器满足我们的需求,无需定义自定义分区器。
默认的 org.apache.hadoop.mapreduce.lib.partition.hashPartitioner 具有以下 getPartition 函数实现
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
逻辑 & 和 hashCode 的目的是防止在 key.getHashCode 函数返回 -2147483648 时返回负值。
驱动程序
创建一个新类,我将其命名为 Driver,它将包含 main 函数,以及 Comparators、Mapper 和 Reducer 作为内部类。
分组和排序比较器
如前所述,Grouping 比较器比较键,并将相似的键分组到单个 reduce 调用中。在这种情况下,要求是将 ProductIdKey 类中具有相同 productId 值的所有记录发送到同一个 reduce 调用,而不管 recordType 值如何,以便 ProductRecord(包含 Product Name 和 Product Number)可以与具有相同 productId 作为键的 SalesOrderDataRecord 实例合并(或在 SQL 术语中称为 Join)。可以按如下方式定义名为 JoinGroupingComparator 的分组比较器
public static class JoinGroupingComparator extends WritableComparator {
public JoinGroupingComparator() {
super (ProductIdKey.class, true);
}
@Override
public int compare (WritableComparable a, WritableComparable b){
ProductIdKey first = (ProductIdKey) a;
ProductIdKey second = (ProductIdKey) b;
return first.productId.compareTo(second.productId);
}
}
WritableComparator 的 compare 方法仅使用 productId,确保具有相同 productId 的记录被发送到同一个 reduce 调用。
排序比较器的定义如下
public static class JoinSortingComparator extends WritableComparator {
public JoinSortingComparator()
{
super (ProductIdKey.class, true);
}
@Override
public int compare (WritableComparable a, WritableComparable b){
ProductIdKey first = (ProductIdKey) a;
ProductIdKey second = (ProductIdKey) b;
return first.compareTo(second);
}
}
这会排序记录,确保第一条记录是 Product 记录,然后是所有数据。
这里,理解一个重要的假设很重要,即 ProductId 对每个产品都是唯一的,就像关系型数据库表中的主键一样,因此只有一个 Product 记录与包含特定 product 的数据记录相关联。因此,在 reducer 的每次调用中(遵循我们刚刚定义的排序和分组比较器所做的排序和分组),传递的数据将包含一个 Product 记录和零个或多个 Sales Order 数据记录。
也可以通过其他方式实现这一点,例如完全删除 ProductIdKey 类中的 recordType 字段,并使用默认的排序和分组比较器,这将把相同键的所有记录发送到同一个 reduce 调用,因为键中没有 recordType 字段,因此具有特定 Product 的键和具有该键(相同 ProductId)的 Sales Order 数据记录的键是相同的。在 reducer 中,我们可以从 JoinGenericWritable 对象获取 Writable,并使用类型标识来识别数据记录中的产品记录。我选择这样实现,因为它涵盖了排序比较器和分组比较器的概念。
现在,下一步是创建 Mapper 和 Reducer。
Mappers (映射器)
此功能需要两个 mapper。一个将处理 SalesOrderData.csv 文件并发出 ProductIdKey 和 SalesOrderDataRecord 实例,另一个将处理 Products.csv 文件,并发出 ProductIdKey 和 ProductRecord 实例。两个 mapper 都很简单,为每个记录创建 key 类和 value 类实例。解释它们的最好方法是展示代码
public static class SalesOrderDataMapper extends Mapper<LongWritable,
Text, ProductIdKey, JoinGenericWritable>{
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] recordFields = value.toString().split("\\t");
int productId = Integer.parseInt(recordFields[4]);
int orderQty = Integer.parseInt(recordFields[3]);
double lineTotal = Double.parseDouble(recordFields[8]);
ProductIdKey recordKey = new ProductIdKey(productId, ProductIdKey.DATA_RECORD);
SalesOrderDataRecord record = new SalesOrderDataRecord(orderQty, lineTotal);
JoinGenericWritable genericRecord = new JoinGenericWritable(record);
context.write(recordKey, genericRecord);
}
}
public static class ProductMapper extends Mapper<LongWritable,
Text, ProductIdKey, JoinGenericWritable>{
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] recordFields = value.toString().split("\\t");
int productId = Integer.parseInt(recordFields[0]);
String productName = recordFields[1];
String productNumber = recordFields[2];
ProductIdKey recordKey = new ProductIdKey(productId, ProductIdKey.PRODUCT_RECORD);
ProductRecord record = new ProductRecord(productName, productNumber);
JoinGenericWritable genericRecord = new JoinGenericWritable(record);
context.write(recordKey, genericRecord);
}
}
可以看到,两个 mapper 都按制表符分割 csv 文件的每条记录,并提取所需的列,然后将它们写入 context。
两个 Mapper 的输入键类是 LongWritable,输入值类是 Text。这是因为我们将 org.apache.hadoop.mapreduce.lib.input.TextInputFormat 类指定为作业的输入格式类,该类逐行读取文件,并将行号作为键,将行本身作为值发送给 mapper 类。
Reducer (归约器)
接下来,我们看看 reducer,它查看键中的 recordType 字段来确定传递给它的值(包装在 JoinGenericWritable 对象中的 Writable 实例)是 ProductRecord 还是 SalesOrderDataRecord 类型。然后,它将 Product Id、Product Name 和 Product Number(ProductMapper 在 map 阶段提取的字段)以及 orderQty 和 lineTotal 的总和一起写入 context。
代码如下
public static class JoinRecuder extends Reducer<ProductIdKey,
JoinGenericWritable, NullWritable, Text>{
public void reduce(ProductIdKey key, Iterable<JoinGenericWritable> values,
Context context) throws IOException, InterruptedException{
StringBuilder output = new StringBuilder();
int sumOrderQty = 0;
double sumLineTotal = 0.0;
for (JoinGenericWritable v : values) {
Writable record = v.get();
if (key.recordType.equals(ProductIdKey.PRODUCT_RECORD)){
ProductRecord pRecord = (ProductRecord)record;
output.append(Integer.parseInt(key.productId.toString())).append(", ");
output.append(pRecord.productName.toString()).append(", ");
output.append(pRecord.productNumber.toString()).append(", ");
} else {
SalesOrderDataRecord record2 = (SalesOrderDataRecord)record;
sumOrderQty += Integer.parseInt(record2.orderQty.toString());
sumLineTotal += Double.parseDouble(record2.lineTotal.toString());
}
}
if (sumOrderQty > 0) {
context.write(NullWritable.get(), new Text(output.toString() +
sumOrderQty + ", " + sumLineTotal));
}
}
}
最后步骤
最后一步是让 Driver 类 extend org.apache.hadoop.conf.Configured,这允许 Driver 类使用 org.apache.hadoop.conf.Configuration 对象进行配置,并实现 org.apache.hadoop.util.Tool 接口,该接口根据其描述“支持处理通用命令行选项”。
Tool 接口有一个 run 方法,它将如下所示
public int run(String[] allArgs) throws Exception {
String[] args = new GenericOptionsParser(getConf(), allArgs).getRemainingArgs();
Job job = Job.getInstance(getConf());
job.setJarByClass(Driver.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapOutputKeyClass(ProductIdKey.class);
job.setMapOutputValueClass(JoinGenericWritable.class);
MultipleInputs.addInputPath(job, new Path(args[0]),
TextInputFormat.class, SalesOrderDataMapper.class);
MultipleInputs.addInputPath(job, new Path(args[1]),
TextInputFormat.class, ProductMapper.class);
job.setReducerClass(JoinRecuder.class);
job.setSortComparatorClass(JoinSortingComparator.class);
job.setGroupingComparatorClass(JoinGroupingComparator.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(allArgs[2]));
boolean status = job.waitForCompletion(true);
if (status) {
return 0;
} else {
return 1;
}
}
可以看到,它使用了 Configuration 基类的 getConf 方法,并将 Configuration 传递给 org.apache.hadoop.mapreduce.Job 的实例,这将是我们设置和运行的 Job。
最后,main 类,它初始化 Configuration 对象,并通过调用 ToolRunner.run 方法来运行作业
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
int res = ToolRunner.run(new Driver(), args);
}
运行 Job
作业可以在 Eclipse 中以本地模式运行,也可以部署到集群。本地模式允许在有限数据集上快速测试作业。
构建应用程序以确保没有错误。然后右键单击 Project Explorer 中的项目,选择 Run As → Run Configurations。右键单击 Java Application,然后选择 New。在 main 选项卡中将配置命名为 “Java Run Config”。项目应该已经选中。在 main class 标题下,单击搜索按钮,然后从列表中选择“hadoopJoinExample.Driver”。这会告诉程序的主类。接下来,单击 Arguments 选项卡,在 Program Arguments 中,我们需要传递两个文件(SalesOrderDetails.csv 和 Products.csv)以及输出文件夹。从 run 方法的编写方式可以看出,第一个路径是 SalesOrderData.csv 文件的路径,第二个路径是 Products.csv 文件的路径。在我的系统中,string 如下所示
/home/hduser/Desktop/sales_data/SalesOrderDetail.csv /home/hduser/Desktop/sales_data/Product.csv /home/hduser/Desktop/sales_data/output/output3
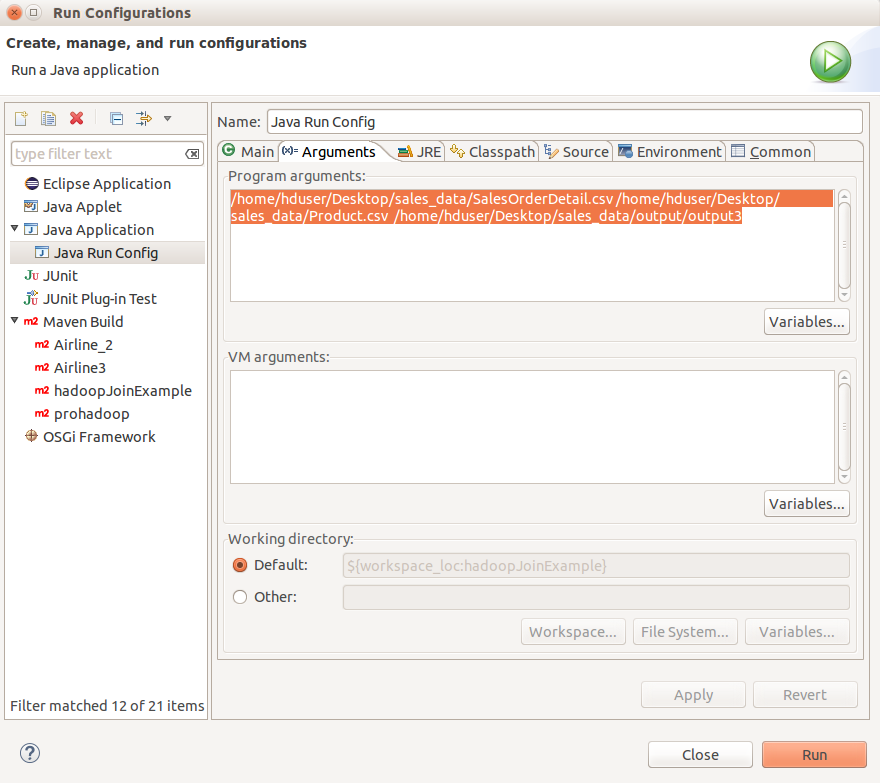
单击 Apply,然后单击 Run。作业应该运行,并且在完成后,输出路径应包含输出。其快照如下

使用 gedit 打开 part-r-00000 文件,您应该能够看到如下结果

可以看到,除了每个 Product 的总数外,还包含我们从 Products.csv 文件连接的详细信息。
此时,仅在本地模式下运行作业以查看一切是否正常应该足够了,最后,我将向您展示如何将其部署到集群。
Map 阶段的 Join
现在,让我们转向 Map 阶段的 Join。当要连接的数据较小时,推荐使用此方法。在 map 阶段进行 Join 可以在一个集合较小时快速连接,并且还可以在具有多个集合的不同键上进行连接,或者重复与单个集合进行连接(例如,在仓库到仓库的产品数据转移中,“from warehouse”和“to warehouse”可以映射),这在使用 Reduce 阶段 Join 时无法在一个作业中完成。
因此,对于本例,让我们想象我们需要更多关于 Product 的信息,例如 Product 子类别,那么等效的 SQL 语句应该是
select P.ProductID, P.Name, P.ProductNumber, C.Name, Sum(S.OrderQty), Sum(S.LineTotal)
from SalesOrderDetails S
join Products P on S.ProductID = P.ProductID
join ProductSubCategory C on P.ProductSubcategoryId = C.ProductSubcategoryId
where S.OrderQty > 0
Product 子类别存在于 ProductSubCategory.csv 文件中。
在此方法中,我将演示缓存文件的使用,这些文件可供 Hadoop Map-Reduce 应用程序使用。它们在作业开始时被复制到每个节点,并在 setup 方法中检索。缓存文件可以位于本地文件系统或 Hadoop 的 HDFS 中。在本例中,我将演示使用本地文件系统中的缓存文件(并使用 Java.io.File),最后,简要解释读取 HDFS 中的缓存文件的方法。
在此示例中,ProductSubCategories.csv 文件被传递给 ProductMapper 类,该文件在 setup(Context) 方法中读取,该方法在每个 Mapper 任务开始时被调用。每个 ProductSubCategoryId 都存储在 java.util.HashMap<Integer, String> 实例中。
然后在 mapper 的 map 方法中,我们将读取每个产品的 productCategoryId 字段(在 Adventure Works 数据库中这是一个可为空的字段),并基于此获取子类别的名称并将其存储在 ProductRecord 实例中。第一步是将 ProductSubCategoryName 添加到 ProductRecord 类中。
修改后的 ProductRecord 类如下
public class ProductRecord implements Writable {
public Text productName = new Text();
public Text productNumber = new Text();
public Text productSubcategoryName = new Text();
public ProductRecord(){}
public ProductRecord(String productName, String productNumber,
String productSubcategoryName){
this.productName.set(productName);
this.productNumber.set(productNumber);
this.productSubcategoryName.set(productSubcategoryName);
}
public void write(DataOutput out) throws IOException {
this.productName.write(out);
this.productNumber.write(out);
this.productSubcategoryName.write(out);
}
public void readFields(DataInput in) throws IOException {
this.productName.readFields(in);
this.productNumber.readFields(in);
this.productSubcategoryName.readFields(in);
}
}
更新后的 ProductMapper 如下
public static class ProductMapper extends Mapper
<LongWritable, Text, ProductIdKey, JoinGenericWritable> {
private HashMap<Integer, String> productSubCategories = new HashMap<Integer, String>();
private void readProductSubcategoriesFile(URI uri) throws IOException{
List<String> lines = FileUtils.readLines(new File(uri));
for (String line : lines) {
String[] recordFields = line.split("\\t");
int key = Integer.parseInt(recordFields[0]);
String productSubcategoryName = recordFields[2];
productSubCategories.put(key, productSubcategoryName);
}
}
public void setup(Context context) throws IOException{
URI[] uris = context.getCacheFiles();
readProductSubcategoriesFile(uris[0]);
}
public void map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException{
String[] recordFields = value.toString().split("\\t");
int productId = Integer.parseInt(recordFields[0]);
int productSubcategoryId = recordFields[18].length() > 0 ?
Integer.parseInt(recordFields[18]) : 0;
String productName = recordFields[1];
String productNumber = recordFields[2];
String productSubcategoryName = productSubcategoryId > 0 ?
productSubCategories.get(productSubcategoryId) : "";
ProductIdKey recordKey = new ProductIdKey(productId, ProductIdKey.PRODUCT_RECORD);
ProductRecord record = new ProductRecord
(productName, productNumber, productSubcategoryName);
JoinGenericWritable genericRecord = new JoinGenericWritable(record);
context.write(recordKey, genericRecord);
}
}
在这里,在 setup 方法中,我们逐行读取文件并填充 HashMap。缓存文件的 URI 从参数在 run 方法中读取,并设置作业的缓存文件。在 run 方法中添加以下行
job.addCacheFile(new File(args[2]).toURI());
这里,我们假设传递给作业的第三个文件是包含 ProductSubCategories 的缓存文件。最后,我们相应地更新 JoinReducer 类,更新后的代码如下
public static class JoinRecuder extends Reducer
<ProductIdKey, JoinGenericWritable, NullWritable, Text>{
public void reduce(ProductIdKey key, Iterable<JoinGenericWritable> values,
Context context) throws IOException, InterruptedException{
StringBuilder output = new StringBuilder();
int sumOrderQty = 0;
double sumLineTotal = 0.0;
for (JoinGenericWritable v : values) {
Writable record = v.get();
if (key.recordType.equals(ProductIdKey.PRODUCT_RECORD)){
ProductRecord pRecord = (ProductRecord)record;
output.append(Integer.parseInt(key.productId.toString())).append(", ");
output.append(pRecord.productName.toString()).append(", ");
output.append(pRecord.productNumber.toString()).append(", ");
output.append(pRecord.productSubcategoryName.toString()).append(", ");
} else {
SalesOrderDataRecord record2 = (SalesOrderDataRecord)record;
sumOrderQty += Integer.parseInt(record2.orderQty.toString());
sumLineTotal += Double.parseDouble(record2.lineTotal.toString());
}
}
if (sumOrderQty > 0) {
context.write(NullWritable.get(), new Text(output.toString() +
sumOrderQty + ", " + sumLineTotal));
}
}
}
运行 Job
在本地模式下运行作业与之前相同,唯一的改变是在 run 配置的程序参数中添加 ProductSubCategories.csv 路径。更新后的程序参数如下
/home/hduser/Desktop/sales_data/SalesOrderDetail.csv
/home/hduser/Desktop/sales_data/Product.csv
/home/hduser/Desktop/sales_data/ProductSubCategory.csv
/home/hduser/Desktop/sales_data/output
接下来,最后一步是在 hadoop 集群上运行作业。我已经设置了一个单节点集群,我将用它来演示过程。
首先,如果集群尚未运行,请启动它。然后,在集群中创建一个名为 JoinExample 的文件夹,运行以下命令
hadoop dfs -mkdir /JoinExample
然后使用 copyFromLocal 命令将文件从本地文件系统复制到 HDFS 中新创建的文件夹
hadoop dfs -copyFromLocal /home/hduser/Desktop/sales_data/*.csv /JoinExample
接下来,Maven 会在项目的 target 文件夹中创建一个 .jar 文件,如图所示,可以在 Eclipse 中的项目浏览器中看到

我们将使用这个 .jar 文件,在使用前我将把它复制到桌面。
最后,可以使用以下命令运行作业
hadoop jar /home/hduser/Desktop/hadoopJoinExample-0.0.1-SNAPSHOT.jar
hadoopJoinExample.Driver /JoinExample/SalesOrderDetail.csv
/JoinExample/Product.csv /home/hduser/Desktop/sales_data/ProductSubCategory.csv
/JoinExample/output/

将输出复制到本地文件系统,并检查输出
cd Desktop
mkdir output
hadoop dfs -copyToLocal /JoinExample/output/* /home/hduser/Desktop/output/

可以看到缓存文件的位置在本地文件系统上。或者,为了完成示例,让我们简要介绍一下如何使用 HDFS 中的缓存文件
文件可以使用 FSFileInputStream 如下读取
URI[] uris = context.getCacheFiles();
FSDataInputStream dataIn = FileSystem.get(context.getConfiguration()).open(new Path(uris[0]));
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(dataIn));
然后,在循环中调用 read lines,如下所示
String line = bufferedReader.readLine();
while (line != null) {
bufferedReader.readLine();
}
并将它们保存在 String 数组中,并在 readProductSubcategoriesFile 方法中使用它们。作为练习,尝试在读取后实现它。
结论
总而言之,我们研究了在 Map-Reduce 应用程序中执行 join 的两种方法
Join在Reduce阶段进行Join在Map阶段进行
我希望我能够清晰地解释这个过程。一如既往,欢迎任何反馈、批评、更正、评论。
历史
- 2015年1月25日:初始版本