
BabyZen - IoT 与 Azure
4.92/5 (28投票s)
利用 Microsoft Azure 为连接的物联网设备添加高级机器学习功能,这些设备可以监测婴儿及其周围环境的活动。

下载次数
关联的网站也已上线并可访问。有关更多信息,请参阅 演示应用程序 部分。模拟器在 样本数据生成 部分有详细描述。
目录
引言
在本文中,我们讨论 BabyZen 应用程序。基本思想是监测定义婴儿环境的重要指标。这些指标可以与婴儿日常生活中的实际(或记录的)干扰因素相关联。利用 Microsoft Azure 的机器学习功能,我们可以推断出如何通过最大程度地减少负面干扰来改善婴儿生活的建议。另一个积极的附带好处是,根据当前的健康研究优化环境,可以提高对婴儿猝死综合征和多种儿童疾病的安全性。
BabyZen 这个名字蕴含了我们应用程序的一个重要方面。“Zen”一词源于中文“禅”(dʑjen)(拼音:Chán)的日语发音,而“禅”又源于梵语 dhyāna。Zen 可以大致翻译为“冥想状态”[1]。我们物联网应用程序的目标是确保最佳条件,让婴儿进入这种令人满意的、无抱怨的状态。Microsoft Azure 云通过提供使物联网成为可能的底层架构、平台和服务来提供帮助。我们将个人收集的数据和来自知名医疗中心(如 [2]-[4] 中给出的)的备受推崇的研究结果,与在 Azure 机器学习工作空间上运行的机器学习算法的评估相结合。
本文首先详细介绍应用程序的背景以及提供实时数据流的设备。虽然我们花了相当多的时间解释设备组件及其互连,但我们不会提供构建和编程设备的具体步骤说明。毕竟,本文的重点在于为 Azure 框架内的物联网应用程序设计的软件。硬件内部的详细描述将超出了本文的范围。第一节之后,我们提供架构的简要概述,其中详细介绍了不同的子模块和通信路径。接下来的三节将详细解释应用程序(ASP.NET MVC 网站)、我们使用的 Azure 服务(主要是移动后端、机器学习和网站)以及 Azure 与我们应用程序之间的连接。最后,我们将讨论一些主要问题以及可能的解决方案。
背景
动机和愿景
在本节中,我们首先阐述我们参加 Microsoft Azure 物联网竞赛的动机,并概述我们项目背后的基本理念。随后,我们将详细解释设备,详细介绍其组件以及它们之间的连接方式。
在过去的几十年里,日益增长的连接性引发了我们与环境互动方式的最大变革之一。在经历了导致 Web 2.0 的快速发展之后,我们相信物联网(IoT)将对我们的日常生活产生类似的影响。在我们看来,它目前是硬件和软件设计中最具创新性的领域之一。因此,最近涌现了许多吸引人且功能强大的快速简单原型解决方案。例如,在硬件方面,德州仪器(Texas Instruments)有专门为物联网应用设计的内置 Wi-Fi 的单芯片无线微控制器。在软件方面,Azure 提供了强大的 Web 托管和数据库工具,并结合了 Azure 机器学习等适当的分析功能。此外,还有通过移动应用程序、网站和 RemoteApp 展示内容的可能性。它基本上可以满足任何物联网项目的需求。当然,这个列表远非完整。
物联网支持下的自我追踪和家庭自动化是当今科技博客和杂志上的主要流行语。物联网技术被广泛用于保持健康的生活方式,并帮助我们更有环保意识地生活,例如通过监控我们的家庭、节约能源和减少二氧化碳排放。结合这两个想法的思考促使我们提出了 BabyZen 的概念。虽然增强我们自身的福祉相对容易,但对于婴儿来说则更为困难。他们没有能力传达不适的确切原因。尽管父母会发展出令人惊叹的直觉来猜测孩子可能在抱怨什么,但最终往往只能猜测婴儿是否真正满意于其所处的环境。BabyZen 通过跟踪所有相关参数(如温度、湿度、二氧化碳水平、环境光和噪音)来帮助提供理想的环境,从而了解婴儿福祉对这些因素的依赖性。最后,BabyZen 会生成关于如何改善情况的建议。最终目标是为婴儿的发展维持最佳条件。下一步,我们加入了婴儿的体温和心率,使数据集更加完整,并进一步改进建议。
在我们的应用程序中,我们主要尝试充分利用 Azure 提供的优秀解决方案来创建物联网应用程序。因此,我们将不同组件之间的通信问题降至最低,并享受开箱即用的巨大功能的便利。该架构围绕 Azure 托管的移动服务构建。它负责通过事件中心接收预处理的传感器数据,并与 Azure 的机器学习工具进行通信。此外,它还通过网站提供用户界面。在内部,机器学习解决方案依赖于 Azure SQL 数据库和日益流行的 R 语言进行统计分析。虽然软件方面在接下来的章节中进行了详细解释,但我们现在将重点放在设备上。
我们使用一个由电池供电的强大单芯片微控制器单元来收集和预处理来自各种低功耗传感器的 [data](数据)。这些传感器记录婴儿的温度、湿度、二氧化碳含量、环境光、声压,甚至可能是心率。传感器通过 I2C、GPIO、ADC 等不同通道与 MCU 通信。预处理后的数据随后通过 Wi-Fi 发送到 Azure Web 界面。接下来,我们将详细介绍设备的各个硬件组件。
以下是我们使用的一部分组件的快速概述
对这些部分进行相当详细的描述对于理解传感器如何实际获取相关信息并将其传输到我们的应用程序是必不可少的。HDC1000 部分还包含了对 I2C 总线的简要介绍,I2C 总线非常重要,并且是嵌入式系统中串行通信的准标准。因此,我们希望鼓励软件工程师不要害怕低级编程和简单的电路设计,因为这些技能对于物联网项目通常是必需的。
微控制器单元
让我们从核心部件微控制器单元(MCU)开始。在这里,我们决定使用德州仪器(Texas Instruments)的 CC3200MOD。它专为物联网和通用低功耗 Wi-Fi 应用而设计,是业界首款具有内置 Wi-Fi 连接功能的 FCC、IC、CE 和 Wi-Fi 认证的单芯片控制器模块。因此,我们满足了电磁干扰的所有安全标准。它集成了所有必需的系统级硬件组件,并支持 TCP/IP 和 TLS/SSL 堆栈、HTTP 服务器以及多种 Internet 协议。它具有强大的 256 位加密引擎,可确保安全连接,并支持 WPA2 和 WPS 2.0。其核心是一个强大的 ARM Cortex-M4,运行频率为 80MHz,拥有高达 256kB 的 RAM。
MCU 具有众多的串行和并行端口,从 GPIO 到特定的高速并行摄像头接口和多通道串行音频端口、通用定时器、ADC 等等。我们仅在后面详细介绍传感器使用的接口。对我们来说最重要的是完全集成的 Wi-Fi 连接,配备专用的 ARM MCU,可以完全卸载主机 MCU,并配备 802.11 b/g/n 无线电,从而即使没有 Wi-Fi 经验,也能实现相当简单的原型开发。下图概述了集成硬件。

如前所述,软件堆栈也令人印象深刻。特别是对于物联网应用程序,我们获得了一个高度优化且专业的平台,其中包含连接到云所需的一切。下图说明了提供的软件组件。

在我们的应用程序中,我们使用了安装在 TI 的 CC3200MOD LaunchPad[10] 上的 MCU。除了 CC3200MOD 之外,它还具有板载天线(带 U.FL 连接器)以及一些传感器和按钮。该板通过 USB 供电,并通过 FTDI 的 JTAG 和背板 UART 进行调试。因此,我们可以将其直接连接到计算机进行编程和监控。对于商业用途,我们会将 LaunchPad 替换为更简约的定制 PCB,因为一旦设备运行,LaunchPad 的许多有用功能就不再需要了。
温度和湿度
对于温度和湿度测量,我们使用 TI 的 HDC1000 传感器。它是一款低功耗、高精度的数字湿度和温度传感器。具有高达 14 位分辨率,可记录 0%-100% 全范围内的相对湿度,以及 -40°C 至 85°C 范围内的温度,精度分别高达 ±3% 和 ±0.2°C。由于以高于约 0.1Hz 的速率采样温度和湿度没有意义,并且以 14 位最大分辨率进行每次转换仅需不到 15 毫秒,因此传感器大部分时间将处于睡眠模式,典型电流消耗仅为 110nA。从而将功耗降至最低。
HDC1000 通过 I2C 接口连接到微控制器单元,这使得通信特别简单。我们仅连接两个标准的 I2C 信号引脚:SCL 用于时钟,SDA 用于串行数据传输。(在我们的设备中,我们还连接了 DRDYn 引脚到 MCU。但是,也可以将其直接连接到地,而不会严重限制功能。)出于教学目的,让我们更详细地阐述 I2C 协议,以这个特定的但仍然相当通用的例子。在最终设备中,我们有更多传感器连接到 I2C 总线。由于一个传感器与另一个传感器的细微差别很小,因此我们仅为 HDC1000 提供详细解释。

I2C 接口是一个相当简单的串行计算机总线,我们将其与单个主控器(MCU)和多个从属设备(HDC1000、OPT3001)一起使用,尽管它甚至允许多个主控器。(为简单起见,在以下解释中,我们假设 HDC1000 是唯一的从属设备。)如前所述,MCU 和传感器仅通过两条开漏线路连接:串行数据线(SDA)和串行时钟线(SCL)。(同样,DRDYn 引脚可以连接,也可以不连接。)总线上的每个从属设备都有一个唯一的 7 位地址,主控器使用该地址来选择不同的组件。如上图所示,HDC1000 有两个引脚称为 ADR0 和 ADR1,它们允许在不同地址之间切换,请参见下表。
请记住,地址必须是唯一的。例如,如果我们想在同一总线上使用多个 HDC1000,我们可以为第一个分配地址 1000000,为第二个分配地址 1000001,依此类推。这样,您最多可以连接四个相同的传感器到同一总线,而不会因为地址不唯一而遇到麻烦。在我们的应用程序中,两个 ADR 引脚已硬连接到地或供电电压。剩余的 DRDYn 引脚由传感器操作,用于指示它已执行测量并且数据已准备好供 MCU 读取。稍后我们将讨论这一点。
| ADR1 | ADR0 | 7 位地址 |
|---|---|---|
| 0 | 0 | 1000000 |
| 0 | 1 | 1000001 |
| 1 | 0 | 1000010 |
| 1 | 1 | 1000011 |
通常,通信从主控传输模式开始,即主控向从属发送信号。根据 I2C 协议的规范,主控在 SDA 线上传输一个起始位,然后是它要通信的从属设备的 7 位地址。紧随地址之后,主控发送另一个位,指示它是要向选定的从属节点发送数据还是从中接收数据,我们将其表示为“写入”和“读取”。“0”表示“写入”,“1”表示“读取”。因此,第一个字节用于区分总线上的通信伙伴和数据方向。如果地址存在,则选定的组件在 SDA 线路上响应一个确认信号(ACK)。因此,它会将 SDA 线拉低。
为了区分控制信号(如起始位)和数据位,使用了 SCL 线。起始位是 SDA 从高到低的转换,而 SCL 在整个转换期间保持高电平(黄色 S 区域)。停止位是 SDA 从低到高的转换,同时 SCL 在整个转换期间再次保持高电平(黄色 P 区域)。所有其他 SDA 转换,例如数据位,都是在 SCL 保持低电平(蓝色区域)时执行的。最高有效位始终首先发送。

如 HDC1000 的框图所示,它包含多个寄存器。这些寄存器用于指令,例如所需的测量精度,也用于保存测量数据。寄存器被分配了地址,我们用它们来引用它们。如果我们要写入某个特定寄存器,例如告诉传感器以 14 位分辨率记录温度,我们首先需要传输我们要写入的内部寄存器的地址。然后,该地址将保存在所谓的指针寄存器中。如果 MCU 发送的第一个命令是写入命令,那么 HDC1000 接收的下一个字节必须是我们想要写入的内部寄存器的地址,并保存在指针寄存器中。之后,我们才能在接下来的两个字节中传输实际数据。(通常我们处理的是 16 位寄存器。)
指针寄存器会保留其值以供后续读取操作。也就是说,在初始化读取通信时,您不能先发送指针,而是直接从指针寄存器当前寻址的寄存器读取。要更改读取操作的指针寄存器,您必须先执行一次写入操作到所需的寄存器,可能不发送实际数据,即在发送地址到指针寄存器后停止通信。让我们总结一下:
写入(每个步骤后,从属设备会返回 ACK 信号)
- 主控器发送一个起始位、7 位地址和一个“0”(写入模式)。
- 主控器发送一个 8 位地址。(此地址存储在 HDC1000 的指针寄存器中。)
- 可选: 主控器发送它想要写入步骤 2 中选择的寄存器的数据(通常是 16 位)。

读取(每个步骤后,从属设备会返回 ACK 信号)
- 主控器发送一个起始位、7 位地址和一个“1”(读取模式)。
- 主控器接收存储在指针寄存器中具有当前地址的寄存器中的数据(通常是 16 位)。(在读取操作中 *不能* 主动选择寄存器。需要进行另一次写入操作来更改指针寄存器。请注意,写入的步骤 1 和 2 已足够。无需传输实际数据,因此不必覆盖所选寄存器。)

HDC1000 包含八个寄存器,其中五个只读寄存器仅包含序列 ID、制造商 ID 和设备 ID 等信息。因此,它们对我们不感兴趣。其余三个 16 位寄存器列于下表。
| 指针 | 重置值 | 描述 |
|---|---|---|
0x00 |
0x0000 |
温度输出 |
0x01 |
0x0000 |
湿度输出 |
0x02 |
0x1000 |
配置和状态 |
自然而然的步骤是,将所需的设置写入配置寄存器,然后触发测量,最后从温度和湿度输出寄存器读取测量数据。配置寄存器的 16 位按以下方式命名。
| 15 | 14 | 13 | 12 | 11 | 10 | 9 : 8 | 7 : 0 |
| RST | 保留 | HEAT | MODE | BTST | TRES | HRES | 保留 |
我们不想详细解释每个引脚,只想给出以 14 位最大分辨率测量温度和湿度的必要值。(有关详细解释,请参阅数据手册。)因此,我们首先将 0x10 作为最高有效字节(MSB),即位 15:8,写入配置寄存器,然后在最低有效字节(LSB),即位 7:0 后面写入零字节 0x00。
现在我们已经设置了配置,我们需要触发一次测量。这通过向温度输出寄存器(即地址 0x00)执行写入操作来完成。只需按照上述步骤执行写入操作,其中步骤二中的 8 位地址为零字节 0x00。省略步骤三。这会启动温度和湿度测量,在我们的配置下大约需要 13 毫秒。一旦完成,HDC1000 会将 DRDYn 线设置为低电平,指示 MCU 可以读取测量数据。
DRDYn 线连接到 MCU 的一个 GPIO 引脚,该引脚可以确切地知道何时读取测量结果。通过将 MCU 的 GPIO 引脚拉低,我们可以触发中断,让中断服务例程处理数据读取,或者我们可以通过轮询定期检查数据就绪信号。由于此应用程序对时间或性能要求不高,因此任何一种方式都可以正常工作。

最后,在 0x00 执行一次普通读取操作将返回两个测量值。首先是一个 16 位值,包含温度,紧接着是一个 16 位值,包含湿度。请记住,我们必须先将指针寄存器设置为温度寄存器 0x00。因此,我们执行一次写入操作到地址 0x00,而不实际传输任何数据。之后,我们可以启动读取请求。尽管温度和湿度分别仅包含 14 位,但我们每个可观测值接收两个字节。在这两种情况下,两个最低有效位 [1:0] 默认都将为零。其余 14 位 [15:2] 包含相关值。有一些简单的公式可以将获得的数字转换为实际温度和相对湿度。给定传感器返回的值 T[15:0],则温度(摄氏度)为:
对于百分比的相对湿度,我们应用:

环境光
显然,环境光是影响婴儿环境的一个重要因素。在涉及光的测量时,必须非常小心。通常,很难确定记录的究竟是正确的量。在此应用程序中,我们不关心例如电磁辐射的总功率,而只关心环境对我们人类来说有多亮。普通的受光晶体管或光电二极管在我们的应用中可能不够,因为它们对所有波长的电磁辐射都有响应。特别是,它们无法可靠地区分红外辐射和可见光。人眼的灵敏度在很大程度上取决于波长,并由所谓的亮度函数或 V-lambda 曲线给出。它描述了不同波长在我们眼中出现的强度(同时保持辐射的总功率不变)。显然,V-lambda 曲线仅对可见光谱部分非零。最大值介于 555nm 和 570nm 之间,具体取决于眼睛是适应日光还是夜视。
为了对环境光进行合理且现实的分析,我们需要一个对不同频率的响应方式与人眼完全相同的传感器。这就是为什么我们决定使用 TI 的 OPT3001。下图显示了该传感器响应与 V-lambda 曲线的惊人一致性。该图已经表明了强大的红外抑制能力,这可能是与使用受光晶体管或光电二极管测量环境光的朴素方法相比最突出的特点。OPT3001 过滤了约 99% 的红外辐射,而光电二极管和晶体管通常对红外光非常敏感。

此外,OPT3001 对于不同的光源表现得相当通用,如下图所示。我们看到输入照度会触发一个线性响应,其斜率与光源的来源无关。

OPT3001 也连接到 I2C 总线,因此通信方式与我们之前为 HDC1000 讨论的类似。我们不再详细介绍通信协议,而是只介绍重要的区别。与 HDC1000 一样,OPT3001 是一款低功耗设备,大部分时间处于睡眠模式。它允许各种复杂的运行模式,例如在特定时间间隔执行测量,并通过下图所示的 INT 引脚通知处理器有关特定事件的信息。但是,我们不希望只注册特殊事件,而是以 MCU 指定的精确采样率收集数据。因此,我们使用 MCU 外部触发测量,并让 OPT3001 通过 INT 引脚在测量完成后回馈。同样,INT 引脚连接到 MCU 的 GPIO 引脚。当然,SDA 和 SCL 引脚一如既往地连接到 I2C 总线。

同样,OPT3001 允许我们选择四个从属地址中的一个,方法是将 ADDR 引脚连接到 GND、VDD、SDA 或 SCL。(注意与 HDC1000 的细微差别。我们仍然有四个不同的地址,但只使用一个引脚。)可能的地址如下表所示。我们可以推断出,在同一总线上与 HDC1000 不会有任何冲突。
| 地址 | ADDR 引脚 |
|---|---|
| 1000100 | GND |
| 1000101 | VDD |
| 1000110 | SDA |
| 1000111 | SCL |
OPT3001 包含六个内部 16 位寄存器。读写操作与 HDC1000 类似。除了包含序列 ID 和制造商信息的两个只读寄存器外,我们还有以下四个寄存器。
| 指针 | 描述 |
|---|---|
0x00 |
结果输出 |
0x01 |
配置和状态 |
0x02 |
低限 |
0x03 |
高限 |
低限和高限可用于手动选择操作范围,如果您只想在值超出给定区域时收到警报。OPT3001 的总测量范围为 0.01 至 83000 lux。由于这是一个巨大的范围,您需要在进行实际测量之前指定十二个刻度之一。幸运的是,该传感器提供完全自动的动态范围选择。在此模式下,OPT3001 会在每次实际测量之前进行一次快速的约 10 毫秒的参考测量来确定合适的范围。有了这个选择,我们就可以使用低限寄存器进行进一步配置,而在我们的应用程序中不对高限寄存器进行修改。将 0xC000 写入低限寄存器会选择转换结束模式,即传感器一旦数据可用就会报告每次测量。(其他选项包括传感器本身过滤某些测量。)
剩下结果寄存器和配置寄存器。同样,在写入低限后,我们首先将所需的配置写入配置寄存器。对于自动全量程设置、800 毫秒的转换时间(而不是 100 毫秒,后者对噪音更敏感)、单次拍摄模式(即不执行连续转换)以及通过 INT 引脚报告每次转换的结束,我们将配置寄存器设置为 0xCA10。(相对较长的 800 毫秒转换时间对于平均掉可能来自市电的 50Hz 或 60Hz 波动是必要的。)此写入操作也会触发测量。一旦 OPT3001 通过将 INT 引脚拉低来报告转换结束,我们就可以读取结果寄存器。
我们将结果寄存器的引脚 [15:12] 称为 E[3:0]。它们表示测量中使用的范围。引脚 [11:0] 包含实际结果,并称为 R[11:0]。为了获得以 lux 为单位的环境光 L,我们应用以下公式:
让我们总结一下测量环境光的步骤。
- 一次性操作:在最开始时将
0xC000写入低限寄存器。 - 重复操作:对于每次测量,将
0xCA10写入配置寄存器。 - 重复操作:等待直到 INT 引脚被传感器拉低。
- 重复操作:读取结果寄存器并计算相应的环境光(以 lux 为单位)。
气体传感器
虽然温度、湿度和环境光传感相对简单,得益于出色的集成电路解决方案,但二氧化碳检测更为复杂。一种成熟的测量技术称为非分散红外(NDIR)传感。它基本上依赖于将光通过介质并测量传输光谱。吸收度与波长的关系可以得出关于介质中存在的物质和浓度的结论。例如,CO2 在 4.26µm 处有一个强吸收线。测量此波长的吸收度使我们能够计算出百万分率(ppm)中的 CO2 浓度。
这种测量存在许多噪音源和干扰因素。光源应覆盖宽光谱,但也需要非常稳定。特别是宽光谱暗示使用基于金属加热发光的灯,而不是例如节能 LED。这与我们在无线应用中偏爱低功耗设备的宗旨截然不同。因此,灯不应连续工作,而应定期关闭和重新开启。需要稳压干净的电源。需要参考信号来消除未知的测量伪影。整个过程对温度变化非常敏感,因此会受到测量本身的影响。(开关灯会引起温度波动。)在 NDIR 传感过程中,需要以高精度测量快速变化的电压水平。市电会进一步增加系统噪声,任何用于节省电力的开关也会产生噪声。通常需要干净的频率滤波来抑制这些干扰。最终,所有这些因素使得精确测量 CO2 含量非常具有挑战性,但使用高度优化的集成电路确实很有帮助。
市场上可以买到现成的 CO2 传感解决方案。但是,为了获得最适合最终设备的定制布局设计,并且出于教学目的,我们选择从更基本的集成电路构建 NDIR 传感器。主要部分是 TI 为 NDIR 传感应用设计的一个可配置模拟前端,即 LMP91051。请注意,尽管 LMP91051 本身无法测量 CO2 含量,但它仍然是一个高度复杂的集成电路,它提供了精确 NDIR 测量的基本功能,请参见下图。

右侧是同步串行外设接口(SPI)总线的四个引脚。它与 I2C 非常相似,并且在嵌入式系统中广泛用作短距离连接。除了时钟引脚 SCLK 和数据引脚 SDIO 外,还有一个芯片选择引脚 CSB 和一个称为 VIO 的独立数字输入/输出电源引脚。我们不打算详细讨论 SPI 协议,因为它在理解 I2C 协议后很容易掌握。引脚 A1 和 A0 可用于连接外部滤波器(见上图),但也可以暂时将它们置空。CMOUT 与 IN1 和 IN2 一起用于实际的气体传感器单元。LMP91051 非常适合与连接到 IN1 和 IN2 的两个热敏电阻传感器一起使用,如下图所示。其中一个是用于实际测量的有源热敏电阻,另一个提供参考测量以减少误差。CMOUT(共模电压输出)为两个热敏电阻提供干净的电源。从而在很大程度上减少了由变化的电源引起的干扰。最后一个剩余引脚是测量的模拟输出,它由 MCU 的模数转换器(ADC)读取。

从这个基本设置到可靠测量空气中真实 CO2 浓度的距离仍然很长,但通过大量的耐心和调试,这是可能的,因为这些组件完全有能力胜任这项工作。通常,ppm 中 CO2 的确切值并非必需,只需要其演变过程,例如突然的波动,或与平均值的极端偏差,就足以得出有用的结论。一旦达到这一点,就可以通过在 CO2 浓度已知的环境中进行参考测量来轻松校准传感器以获得绝对值。如果需要气体传感,我们建议阅读一些应用报告并严格按照说明操作以使基本设置正常工作。然后,您需要投入大量时间进行优化和校准,直到可以预期获得可靠的值。
心率
在未来的项目中,不仅可以包含环境数据,还可以包含婴儿本身的健康数据,以补充数据流,从而生成更好、更完整的数据。体温可以通过另一个温度传感器轻松获得,该传感器靠近婴儿,例如直接接触其皮肤,戴在手环上,或集成到其服装中。然而,测量心率并不那么简单。TI 再次提供了一个出色的 IC,称为 AFE4400,它是一款用于心率监测器和低成本脉搏血氧仪的模拟前端。其基本功能与我们上面介绍的气体传感器类似。
该设备需要直接接触婴儿的皮肤。LED 灯会照射婴儿的血管。同时,反射的光线被光电二极管记录。当血液在血管中因心跳而被压缩时,其光学特性会发生变化,这反过来又会影响光电二极管的响应。从这些周期性变化中,我们可以计算出婴儿的心率。AFE4400 通过 SPI 与 MCU 通信,提供具有精确电流控制的 LED 驱动器,以及用于光电二极管的连接引脚。AFE4400 的简化框图如下图所示。请注意,它有 40 个引脚,算是一个大家伙,我们可能需要很长时间才能让它正确工作。

现在我们大致了解了我们的传感器是如何工作的,是时候看看大局了。在下一章中,我们将更详细地了解如何连接所有内容。由于本文主要侧重于软件方面,因此我们不会详细介绍如何连接环境或婴儿追踪器。本章基本上包含了我们想要分享的所有与硬件相关的信息。(在本介绍之后,对于大多数传感器来说,接线实际上非常简单。)
架构概述
在前一章中,我们仔细研究了硬件方面。这在项目的整体架构中起着重要作用。为了在一个简单的图示中汇总上一章的信息,我们提供了以下图示。该图勾画了 MCU 与各种传感器之间的交互。我们使用两种不同的设备——一种用于追踪婴儿数据,另一种用于追踪婴儿环境的属性。我们将后者称为房间追踪器。
但这只是大局的一小部分。在现实中,我们还需要一个强大的云服务,能够聚合和评估所有数据。评估工具的正确设计是强制性的。我们架构的 10,000 英尺鸟瞰图如下所示。我们将一切围绕一个 Web 服务构建,该服务将由 Azure Mobile 服务提供。后端主要负责将数据传输到 Azure Machine Learning 工作区并对数据进行评估。

基本上,整个应用程序分为三个部分:
- 将数据引入应用程序(到中间位置,然后到 Azure 机器学习工作区)
- 进行实验并将数据存储在 Azure SQL 中
- 通过与提供的 Azure Mobile 服务通信的应用程序访问数据
如果我们把架构看作一个应用程序,我们主要关心的是数据流。毕竟,任何应用程序都只关注将初始数据集转换为最终数据集。我们的初始数据集是原始传感器数据。我们的最终数据存储在 Azure SQL 数据库中,或者按需通过某个 API 计算。
应用程序
首先,我们来看看提供的应用程序。普通用户只能看到并与表示终端交互,即移动应用程序和网页。对于竞赛,我们只使用网页,因为移动应用程序的分发、安装和维护更加分散、麻烦且个人化。网页包含正常用户关心的一切。主要是用户提供的数据。然而,我们以评估过的、具有教育意义的方式呈现数据,使其成为一次个性化、愉悦且信息丰富的体验。
对于程序员来说,RESTful Web 服务是我们解决方案中最重要的一部分。由于 Web 服务也是我们架构的核心,我们将首先介绍这部分。我们还将讨论一个用作样本数据生成器的特殊应用程序。数据生成器是唯一需要下载并在本地运行的应用程序。在实际应用程序中,数据是由追踪设备收集和提供的。为了进行测试和演示,样本数据生成器模拟了追踪器的功能。
Web 服务
Web 服务是通过 Azure Mobile 服务实现的。这有几个优点。它与 Azure 的集成非常出色,具有良好的灵活性,并且所有内容都已为我们设置好。由于我们希望利用 .NET,因此我们可以使用最新的 Visual Studio 版本获得非常好的 API 和工具支持。(细心的读者可能会注意到下面代码片段中的内容,我们还在考虑为婴儿追踪器添加加速度计。因此,我们已经在这里提供了必要的接口。)
当然,我们会提供一些关于传输数据的见解,但展示所有传输数据可能有点太多了。如果我们每秒采样一次,那么每天就有 86,400 次测量。这每周超过半百万条消息。这对于标准客户端来说处理起来实在太多了。因此,服务将仅允许访问已经平均过的数据。我们将使用移动平均(有关更多信息,请参阅 Wikipedia)来获得一个滑动窗口。这将由稍后将要讨论的机器学习 API 提供。移动服务可以直接访问批处理平均值,这些平均值代表在特定时间段内的聚合。我们使用 5 分钟的时间跨度。这是精度和消息数量之间的良好折衷。在这里,我们节省了 300 倍的因子。因此,一年可以仅用 700,000 条消息完整加载。但通常情况下,我们不会将所有(聚合的)消息发送到客户端,而是再次发送平均值。我们始终会发送数量或多或少恒定的消息,其中消息的精度通过请求的时间跨度计算。一年将仅用不到 200 条消息加载,每条消息代表约 48 小时,即 2 天。一天将由 144 条消息表示,这意味着每条消息代表 10 分钟。

我们期望从这些传感器获得什么样的数据?请注意,给出的值不代表原始传感器数据,而是传输的传感器数据。原始传感器数据必须由 MCU 进行预处理。
- 加速度计 [g],存储为
double,我们期望 [0 → 5]。通常约为 1。 - 心率 [bpm],存储为
double,我们期望 [0 → 250]。通常约为 135。 - 温度 [°C],存储为
double,我们期望 [0 → 70]。通常约为 34。
上图展示了我们用于婴儿追踪器的三个传感器。我们将接收心率、皮肤温度和可选加速度计的数据。心率是婴儿压力水平的明显指标。应强调的是,基础水平因婴儿而异。因此,我们的机器学习算法必须能够识别基线水平。皮肤温度与人体核心温度不同。这是一个重要的观察。尽管如此,皮肤温度应与核心温度仅通过固定的偏移量相关。偏移量实际上由油脂层的厚度决定。当然,温度也高度依赖于测量点。我们的算法依赖于始终在同一位置进行测量的条件。
Fransson、Karlsson 和 Nilsson 的一项研究表明,皮肤温度可能独立于环境温度而变化[15]。该研究还证实,腹部是进行皮肤温度测量的良好位置,因为这里的变化最小。最后,他们得出结论,对于婴儿来说,在出生后的最初几天与母亲进行亲密的身体接触对于体温调节非常重要。
让我们看一下聚合测量模型
/// <summary>
/// Contains an averaged measurement of the baby.
/// </summary>
public class BabyItem : EntityData
{
/// <summary>
/// Gets or sets the associated user id.
/// </summary>
public String UserId { get; set; }
/// <summary>
/// Gets or sets the heart rate in bpm.
/// </summary>
public Double HeartRate { get; set; }
/// <summary>
/// Gets or sets the total acceleration in g.
/// </summary>
public Double Acceleration { get; set; }
/// <summary>
/// Gets or sets the skin temperature in °C.
/// </summary>
public Double Temperature { get; set; }
/// <summary>
/// Gets or sets the center time of the considered measurements.
/// </summary>
public DateTime Time { get; set; }
}
Time 属性表示所有测量值的中心时间。这意味着对于单次测量,获取测量时间。对于两次测量,我们获得第一次测量的 [time],并附加一个偏移量,该偏移量是第二次测量到第一次测量之间时间跨度的一半。
所以,让我们来看一个与之前相似的图:说明房间追踪器的传感器。

房间追踪器测量体积、二氧化碳水平、光照强度、湿度和温度。湿度和温度水平尤其有趣。在这里,我们可以直接得出与婴儿传感器相关的结论。但体积和光照也非常有趣。光照更多地是一种确认传感器。除了昼夜变化之外,我们很可能会确认婴儿的主要睡眠时间。就二氧化碳而言,我们还不知道可以计算出什么样的有趣相关性。
我们期望从这些传感器获得什么样的数据?请注意,给出的值不代表原始传感器数据,而是传输的传感器数据。原始传感器数据必须由 MCU 进行预处理。
- 湿度 [%],存储为
double,我们期望 [0 → 1]。通常约为 0.5。 - 温度 [°C],存储为
double,我们期望 [-20 → 50]。通常约为 20。 - 音量 [dB],存储为
double,我们期望 [0 → 120]。通常约为 60。 - 环境光 [lx],存储为
double,我们期望 [0 → 15000]。通常约为 150。 - 二氧化碳 [ppm],存储为
double,我们期望 [0 → 1000000]。通常约为 400。
让我们看一下聚合测量模型
/// <summary>
/// Contains an averaged measurement of the room.
/// </summary>
public class RoomItem : EntityData
{
/// <summary>
/// Gets or sets the associated user id.
/// </summary>
public String UserId { get; set; }
/// <summary>
/// Gets or sets the humidity in percent (0-1).
/// </summary>
public Double Humidity { get; set; }
/// <summary>
/// Gets or sets the room temperature in °C.
/// </summary>
public Double Temperature { get; set; }
/// <summary>
/// Gets or sets the volume level in dB(A).
/// </summary>
public Double Volume { get; set; }
/// <summary>
/// Gets or sets the ambient light in lx.
/// </summary>
public Double Light { get; set; }
/// <summary>
/// Gets or sets the carbon dioxide level in ppm.
/// </summary>
public Double CarbonDioxide { get; set; }
/// <summary>
/// Gets or sets the center time of the considered measurements.
/// </summary>
public DateTime Time { get; set; }
}
现在我们解释了聚合测量模型,我们也需要看看一些其他模型。例如,我们还有一个模型来描述 BabyZen 用户添加的设备。设备的名称也是发送传感器数据时应使用的名称。否则,数据将被立即丢弃。这里 UserId 和设备的 Name 必须匹配。
/// <summary>
/// Represents a registered device.
/// </summary>
public class DeviceItem : EntityData
{
/// <summary>
/// Gets or sets the associated user id.
/// </summary>
public String UserId { get; set; }
/// <summary>
/// Gets or sets if the device is still active.
/// </summary>
public Boolean Active { get; set; }
/// <summary>
/// Gets or sets a name for the device.
/// </summary>
public String Name { get; set; }
/// <summary>
/// Gets or sets a description for the device.
/// </summary>
public String Description { get; set; }
}
另一个模型是 UserItem,它反映了关于特定 BabyZen 用户的附加信息。我们将存储一个随机生成的盐以及加盐和哈希后的密码。即使有人拥有盐,也无法解密密码。暴力破解实际上是检索用户密码的唯一方法(即使那样,也有可能匹配是重叠,而不是原始提供的密码)。
对于本文,我们不需要有效的电子邮件地址。在应用程序的生产版本中,肯定需要有效的电子邮件,但是,由于我们不使用任何邮件服务或邮件服务器,因此我们无法可靠地验证用户的电子邮件地址。但是,应该注意的是,Azure 提供了可以在这种情况下工作的邮件服务。最后,IsReadOnly 属性为用户启用只读模式。在此模式下,用户仍然可以登录,但无法更改任何数据。这种模式显然是为已准备好的演示帐户强制提供的。在此处应避免修改,否则恶意用户可能会破坏其他访问者的体验。
/// <summary>
/// Describes a user in more detail.
/// </summary>
public class UserItem : EntityData
{
/// <summary>
/// Gets or sets the associated user id.
/// </summary>
public String UserId { get; set; }
/// <summary>
/// Gets or sets the salt.
/// </summary>
public Byte[] Salt { get; set; }
/// <summary>
/// Gets or sets the salted and hashed password.
/// </summary>
public Byte[] SaltedAndHashedPassword { get; set; }
/// <summary>
/// Gets or sets the first name of the user.
/// </summary>
public String FirstName { get; set; }
/// <summary>
/// Gets or sets the last name of the user.
/// </summary>
public String LastName { get; set; }
/// <summary>
/// Gets or sets the email of the user.
/// </summary>
public String Email { get; set; }
/// <summary>
/// Gets or sets if the user cannot modify data.
/// </summary>
public Boolean IsReadOnly { get; set; }
}
那么用户如何在系统中进行身份验证呢?微软的团队对此有一个明确的答案:OAuth!但是,如果某个用户不想共享他们的 Twitter / Facebook / Google 或 Microsoft 帐户怎么办?如果他们没有这些公司之一的帐户怎么办?所以我们想从自定义登录程序开始。将来我们也可以提供 OAuth 登录,但目前我们将其保持开放。由于项目仍处于实验阶段,我们认为这种方法没有缺点。事实上,自定义登录有很多优点。
我们需要做的第一件事是自定义登录提供程序。这只是一个继承自 LoginProvider 的类。任何 Mobile Services 应用程序都使用此类提供程序来生成身份验证令牌,这些令牌在内部用于确保用户的身份验证。实现自定义登录提供程序最重要的事情是提供一个唯一的名称。
public class CustomLoginProvider : LoginProvider
{
public static readonly String ProviderName = "custom";
public CustomLoginProvider(IServiceTokenHandler tokenHandler)
: base(tokenHandler)
{
this.TokenLifetime = new TimeSpan(30, 0, 0, 0);
}
public override String Name
{
get { return ProviderName; }
}
public override void ConfigureMiddleware(IAppBuilder appBuilder, ServiceSettingsDictionary settings)
{
// Not Applicable - used for federated identity flows
return;
}
public override ProviderCredentials ParseCredentials(JObject serialized)
{
if (serialized == null)
throw new ArgumentNullException("serialized");
return serialized.ToObject<CustomLoginProviderCredentials>();
}
public override ProviderCredentials CreateCredentials(ClaimsIdentity claimsIdentity)
{
if (claimsIdentity == null)
throw new ArgumentNullException("claimsIdentity");
var username = claimsIdentity.FindFirst(ClaimTypes.NameIdentifier).Value;
var credentials = new CustomLoginProviderCredentials { UserId = TokenHandler.CreateUserId(Name, username) };
return credentials;
}
}
登录提供程序的唯一自定义依赖项是 CustomLoginProviderCredentials。这个类更简单。我们只需要使用标识自定义登录提供程序的相同名称。这也是我们之前创建该名称为 static readonly 字段的原因。
public class CustomLoginProviderCredentials : ProviderCredentials
{
public CustomLoginProviderCredentials()
: base(CustomLoginProvider.ProviderName)
{
}
}
有了自定义登录提供程序,我们只需要创建注册和登录方法。我们可能还需要创建其他方法来重置密码、获取电子邮件字段或其他辅助功能。但这些都只是为了方便,而不是关键。
让我们看看自定义注册会是什么样子。
static readonly String userAlreadyExists = "The username already exists";
static readonly String userNameInvalid = "Invalid username (at least 4 chars, alphanumeric only)";
static readonly String passwordSecurity = "Invalid password (at least 8 characters, lowercase characters, uppercase characters, numbers and special symbols required)";
// POST api/registration
public HttpResponseMessage Post(RegistrationAttempt data)
{
if (!Regex.IsMatch(data.UserName, "^[a-zA-Z0-9]{4,}$"))
{
return Request.CreateResponse(HttpStatusCode.BadRequest, userNameInvalid);
}
if (!Regex.IsMatch(data.Password, "^(?=.*?[A-Z])(?=.*?[a-z])(?=.*?[0-9])(?=.*?[#?!@$%^&*-]).{8,}$", RegexOptions.ECMAScript))
{
return Request.CreateResponse(HttpStatusCode.BadRequest, passwordSecurity);
}
var context = new MobileServiceContext();
var account = context.UserItems.Where(a => a.UserId == data.UserName).SingleOrDefault();
if (account == null)
{
var salt = LoginProviderUtilities.GenerateSalt();
var newAccount = new UserItem
{
Id = Guid.NewGuid().ToString(),
UserId = data.UserName,
Salt = salt,
SaltedAndHashedPassword = LoginProviderUtilities.Hash(data.Password, salt)
};
context.UserItems.Add(newAccount);
context.SaveChanges();
return Request.CreateResponse(HttpStatusCode.Created);
}
return Request.CreateResponse(HttpStatusCode.BadRequest, userAlreadyExists);
}
该方法没有什么特别之处。传入的模型仅包含 UserName 和 Password。将来这可能会扩展到电子邮件地址,但是,目前该地址未经验证,因此只是可选的。为什么在登录时要求输入可选数据?
关于注册方法还可以说些什么?也许检查给定密码是否满足安全设置的正则表达式很有趣。我们要求混合使用小写字母、大写字母、数字和符号字符。还需要提供 8 个字符。这应该迫使用户仅提供强密码。
细心的读者可能会注意到使用了自定义的 LoginProviderUtilities 类。这是一个实用程序类,它为我们提供了生成随机字节序列、使用此类序列哈希字符串或比较两个哈希密码的方法。生成盐基本上封装了 .NET Framework 提供的 RNGCryptoServiceProvider 类。出于安全原因,不在此文章中解释 Hash 函数的确切形式。
为了让用户登录,我们还需要提供一个自定义方法。
// POST api/CustomLogin
public HttpResponseMessage Post(LoginRequest data)
{
var context = new MobileServiceContext();
var account = context.UserItems.Where(a => a.UserId == data.UserName).SingleOrDefault();
if (account != null)
{
var incoming = LoginProviderUtilities.Hash(data.Password, account.Salt);
if (LoginProviderUtilities.SlowEquals(incoming, account.SaltedAndHashedPassword))
{
var claimsIdentity = new ClaimsIdentity();
claimsIdentity.AddClaim(new Claim(ClaimTypes.NameIdentifier, data.UserName));
var loginResult = new CustomLoginProvider(Handler).CreateLoginResult(claimsIdentity, Services.Settings.MasterKey);
return Request.CreateResponse(HttpStatusCode.OK, loginResult);
}
}
return Request.CreateResponse(HttpStatusCode.Unauthorized, "Invalid username or password");
}
这几乎是直截了当的。同样,LoginRequest 模型非常简单。实际上,它只包含一个用户名和一个密码,与之前的 RegistrationAttempt 模型类似。但是,将这两个模型合并不是一个好主意。它们将来可能会有所不同,并且会混淆其他开发人员。它们目前具有相同的结构,这是真的,但它们不是同一回事。
目前,我们的后端已经完成。现在它变成了一个简单的“应该提供什么 API?”到“让我们集成它”的游戏。后端将稍后扩展 Azure ML 集成和其他功能。
Web 应用程序
再次,我们使用一个提供微软强大支持的解决方案:ASP.NET MVC。我们选择单页应用程序(SPA),因为它在一个非常现代且轻量级的容器中提供了我们所需的一切。SPA 将使用 Knockout 和 Sammy.js 等前端脚本构建。前者是一个 MVVM 框架,它为来自 WPF 的用户提供了极大的灵活性和熟悉度。它倡导数据绑定应该如此。后者是一个非常小巧且有用的核心框架库。它基本上包含一个路由器。但这确实是我们所需的核心。 Manish Sharma 在 C# Corner 上的博客 提供了一个关于使用 Sammy.js 的 SPA 的小型教程。
我们得到的是一个 ASP.NET 网站,它带有 OWIN 兼容的实现。OWIN 是 Open Web Interface for .NET 的缩写,它标准化了 .NET Web 服务器和 Web 应用程序之间的接口。使用 OWIN 兼容实现的一个巨大优势是灵活性。我们可以将我们的 Web 应用程序托管在 IIS 上,但我们也可以将其托管在 Linux 环境中。有 .NET Web 服务器可以从一开始就在 Linux 上运行。一个很好的例子是 Kestrel HTTP 服务器项目,它提供了一个建立在流行的 libuv 库之上的 Web 服务器。libuv 库实际上是为 Node.js 提供异步 IO 事件的核心库。
到目前为止,这一切都是真实的。尽管如此,我们不会使用太多。ASP.NET MVC 部分很有用,但对于我们的 Web 应用程序,我们实际上只会提供静态内容。其余的一切都将完全在客户端完成。这需要付出代价:我们将编写大量的 JavaScript,而没有(启用)JavaScript 的用户将看不到任何令人惊叹的东西。
从头开始编写这样一个庞大的 SPA 应用程序是可能的,但我们希望通过使用优秀的第三方库来提高我们的开发效率。我们将使用:
- jQuery,用于抽象 DOM 操作的标准库
- crossroads.js,一个用于路由的库(与
hasher结合使用) - signals,拥有强大的事件处理功能很有用
- Knockout,它将 MVVM 与(Web)组件结合到 JavaScript 中
- Bootstrap,一个响应式演示框架
- morris.js,因为好看的图表很重要
- Font Awesome,因为 Web 字体很棒,图标需要可缩放
- RequireJS,它使依赖管理成为可能
我们还使用了一些流行的 jQuery 库,例如 DataTables、ASP.NET MVC 自带的标准验证库,或 metisMenu。总而言之,这相当多,目前尚不清楚所有这些库的功能中有多少将被使用。最终,我们需要考虑一些指标来删除未使用的代码。目前,我们将接受可能的开销,并欢迎使用大量预制函数、出色的助手和专业设计的灵活性。
计划是创建 Web 应用程序而不依赖于 Web 服务。我们将设置所有模板,定义视图模型,并创建内部路由。最后,我们将用我们的后端连接替换虚拟提供程序/API。此时一切应该都正常。这样,我们也可以同时做两件事:创建 Web 应用程序并独立增强 Web 服务。稍后我们将关注将 Mobile Services API 集成到 SPA 中。
我们想要提供什么样的服务和视图?
- 更改您的用户信息
- 重置您的密码
- 查看所有传感器的状态
- 添加、删除和更改传感器
- 添加有关您婴儿的信息
- 获取 **Zen** 因子
- 当前评估和建议
- 下次通风时间
除了上面列出的可能性之外,我们还显示了一些数据。以下是我们提供的内容:
- 带评估的时间线
- 随时间变化的皮肤和环境温度
- 随时间变化的湿度、心率和加速度
- 婴儿日志数据
婴儿日志是整个传感器数据的宝贵补充。由于每个传感器代表一个婴儿,用户可以提供称为日志的附加数据。这些数据主要用于记账目的,但也可以绘制图表。此外,它在未来可能很有用。相关性总是很有趣。
婴儿的 Zen 因子是衡量孩子幸福度的尺度。我们将其评分为 0 到 10,0 表示不平衡且不 Zen,而 10 表示一个超级积极的婴儿,通常非常安静、活跃和平衡。目前评分应在 6 到 9 之间。我们还不知道是否有什么能证明 10 级评分(这样的婴儿是什么样的?)是合理的。我们也不知道是否真的有超级不快乐的婴儿。在所有这些情况下,我们需要扩大我们的训练数据集。
在内部,我们将所有内容拆分为 Knockout 组件。这些是可重用的,并满足我们的约束。让我们看看我们的 RequireJS 配置。
var require = {
baseUrl: '.',
paths: {
'bootstrap': 'scripts/bootstrap.min',
'crossroads': 'scripts/crossroads.min',
'hasher': 'scripts/hasher.min',
'jquery': 'scripts/jquery-1.10.2.min',
'knockout': 'scripts/knockout-3.3.0',
'knockout-projections': 'scripts/knockout-projections.min',
'signals': 'scripts/signals.min',
'text': 'scripts/text',
'MobileService': 'scripts/MobileServices.Web-1.2.5.min',
'context': 'scripts/app/context',
'morris': 'scripts/morris.min',
'metisMenu': 'scripts/metisMenu.min'
},
shim: {
'bootstrap': { deps: ['jquery'] },
'metisMenu': { deps: ['jquery', 'bootstrap'] },
'morris': { exports: 'Morris' }
}
};
我们的启动脚本看起来并不那么复杂。我们只注册一些尚未注册为页面的组件。这些是可重用的,并在传输的 HTML 代码中广泛使用。
define(['jquery', 'knockout', './router', 'bootstrap', 'knockout-projections'], function ($, ko, router) {
ko.components.register('area-chart', { require: 'components/AreaChart/model' });
ko.components.register('bar-chart', { require: 'components/BarChart/model' });
/* ... */
// Activate Knockout
ko.applyBindings({ route: router.currentRoute });
});
那么路由器是如何创建的呢?嗯,像往常一样,我们有一个 JavaScript 文件来完成这项工作。在之前的依赖项中,我们列出了 './router',它实际上是一个名为 router.js 的文件。该文件再次需要其他 JavaScript 文件,如下所示:
define(["knockout", "crossroads", "hasher"], function (ko, crossroads, hasher) {
var activateCrossroads = function () {
var parseHash = function (newHash, oldHash) {
crossroads.parse(newHash);
};
crossroads.normalizeFn = crossroads.NORM_AS_OBJECT;
hasher.initialized.add(parseHash);
hasher.changed.add(parseHash);
hasher.init();
};
var Router = function (config) {
var currentRoute = this.currentRoute = ko.observable({});
ko.utils.arrayForEach(config.routes, function (route) {
crossroads.addRoute(route.url, function (requestParams) {
currentRoute(ko.utils.extend(requestParams, route.params));
});
});
activateCrossroads();
};
ko.components.register('Login', { require: 'components/Login/model' });
/* ... */
return new Router({
routes: [
{ url: '', params: { page: 'Login' } },
{ url: 'Login', params: { page: 'Login' } },
/* ... */
]
});
});
目前,我们完全专注于 Login 组件。我们这样做是为了说明编写这种解耦的 JavaScript 代码是多么容易,它允许使用可交换的组件。首先,我们有一些组件的视图。视图基本上只是 HTML 代码。我们还包含了一些 Knockout 注释。这些注释非常不显眼——它们只是特殊的 data-bind 属性。
以下代码负责渲染登录表单。
<div class="container">
<div class="card card-container">
<img id="profile-img" class="profile-img-card" src="//ssl.gstatic.com/accounts/ui/avatar_2x.png" />
<p id="profile-name" class="profile-name-card"></p>
<form class="form-signin" data-bind="submit: doLogin">
<span id="reauth-email" class="reauth-email"></span>
<input type="text" data-bind="value: username" class="form-control" placeholder="Username" required autofocus>
<input type="password" data-bind="value: password" class="form-control" placeholder="Password" required>
<div id="remember" class="checkbox">
<label><input type="checkbox" data-bind="checked: remember" value="remember-me"> Remember me</label>
</div>
<button class="btn btn-lg btn-primary btn-block btn-signin" type="submit">Sign in</button>
</form>
<p><a href="#/Forgot/Password" class="forgot-password">Forgot the password?</a></p>
<p><a href="#/Register" class="forgot-password">Register a new account.</a></p>
<div class="alert alert-danger alert-error" data-bind="visible: errorMessage">
<a href="#" class="close" data-dismiss="alert">×</a>
<span data-bind="text: errorMessage"></span>
</div>
</div>
</div>
代码看起来可能有点冗长。我们使用了流行的 UI 框架 Bootstrap,它带来了一些缺点。该框架的通用性是以需要编写更多代码为代价的。然而,最终 Bootstrap 页面也是高度响应式的,这反过来又是一个优势。
每个组件实际上都由一个 JavaScript 文件驱动。前面发布的 HTML 代码只是一个模板,它是可选的。那么模型对应的 JavaScript 代码是什么样的呢?我们再次使用 RequireJS 来确保所有依赖项都已加载。
在下面的代码中,我们创建了一个名为 LoginViewModel 的视图模型,它具有与先前绑定值连接的属性。每个属性都是一个 ko.observable 实例,但是,对于表单提交回调,我们只使用一个简单的函数。
define(['knockout', 'text!./view.html', 'context'], function (ko, template, context) {
function LoginViewModel(params) {
var self = this;
self.username = ko.observable('');
self.password = ko.observable('');
self.remember = ko.observable(false);
self.errorMessage = ko.observable('');
self.doLogin = function () {
context.signIn({
username: self.username(),
password: self.password(),
remember: self.remember(),
success: function () {
/* ... */
},
error: function (msg) {
self.errorMessage(msg);
}
});
};
self.route = params.route;
}
return { viewModel: LoginViewModel, template: template };
});
这里没有什么特别之处。哦,等等。唯一值得注意的事情也是我们一直深入研究这段 JavaScript 的原因。我们只依赖于一个叫做 context 的东西。context 是真实 API 的抽象。我们使用 Azure Mobile Services 库来连接到真实 API。但是,抽象允许我们完全替换选定的文件。我们只需要在 require.config.js 文件中将 context.js 替换为 context.mock.js,然后一切都会运行在一个模拟器上,而不是真实文件。
能够轻松地交换依赖项是一个巨大的优势,也是 RequireJS 应该首先使用的原因之一。它不仅可以最小化加载时间(是的,可能有更多的请求,但是,这些请求可以并行运行,并从标题开始 - 最终给出更好的屏幕显示时间),而且它非常结构化且方便。否则,您将永远不知道某个 JavaScript 文件的依赖项是什么。
样本数据生成器
在演示我们对本次竞赛的贡献时遇到的一个问题是缺乏一个完全运行的设备。即使有了上面描述的所有组件,我们仍然需要更多时间才能让一切达到不需要进一步修改的最终状态。我们的解决方案具有易于编程和访问的优点。官方设备很可能是使用我们 Azure 物联网应用程序的最佳方式,但它不是唯一的方式。任何人都可以构建一些设备,连接到我们的服务并开始提交数据,然后进行评估。
为了说明这个过程,我们提供了一个可下载的简单“模拟”设备。它是一个控制台应用程序,可以模拟数据,就像数据是从我们追踪设备中的 MCU 发送过来一样。该应用程序的魅力在于可以对其进行脚本化并修改其输出。例如,您可以轻松地模拟室内温度的升高。因此,该软件不仅代表传感器,还代表环境。可以修改环境。这种修改也会直接影响传感器读数。这样,我们可以非常准确地模拟实际行为。
可以提供自定义脚本,这些脚本会在特定事件时触发。该应用程序支持创建计划,在特定时间点(如果需要,可以定期)更改某些环境变量。该应用程序是用 JavaScript 编写的。自然,JavaScript 为评估其他 JavaScript 文件提供了出色的支持。我们的应用程序需要的一个要求是运行 Node.js 的某种设备。出于测试目的,我们在 Raspberry Pi B 型上运行该应用程序。当然,该应用程序也可以在标准台式计算机上执行。
我们选择 Node.js 平台的原因如下:
- Node.js 开箱即用地提供了事件循环。这极大地简化了单线程异步编程。
- 该应用程序具有出色的跨平台功能。
- 有许多有用的模块用于终端输入/输出(颜色、密码等)。
- 与 Azure EventHubs 等 Web 服务的通信工作得非常出色。
- 我们可以直接评估用户脚本,这使得运行时注入非常容易。
在接下来的段落中,我们将详细介绍仿真软件的开发。我们将从通用应用程序的概述开始,然后探讨某些方面,例如 Shell 实现、调度程序以及与 Azure EventHubs 的连接。
仿真软件基本上是一个简单的 JavaScript 文件,它将尝试修改以下两个对象的数据
var room = {
humidity: 0.5,
temperature: 20.0,
volume: 30.0,
light: 80.0,
carbonDioxide: 200.0,
};
var baby = {
heartRate: 120.0,
acceleration: 1.0,
temperature: 33.0,
};
这两个对象代表了房间和婴儿的属性。测量值只是这两个对象在某个时间点的快照。事件循环会定期触发一个调度程序,然后该调度程序会调用可能修改房间和/或婴儿属性的函数。
应用程序在一个自定义 Shell 中运行。Shell 是通过以下几行创建的
var rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
rl.setPrompt('>>> ');
rl.prompt();
rl.on('line', function(line) {
var input = line.split(' ').filter(function(item) {
return !!item;
});
var parameters = input.splice(1);
var cmd = input[0];
var command = allCommands[cmd];
if (command) {
var arguments = [scheduler, room, baby].concat(parameters);
command.apply(this, arguments);
} else if (cmd !== undefined) {
console.log(chalk.red('Command not found. The following commands are available:'));
console.log(Object.keys(allCommands).join(', '));
}
rl.prompt();
}).on('close', function() {
process.exit(0);
});
有多个命令行选项可以阻止 Shell 模式并执行自定义定义的仿真。但是,通常在运行时修改仿真要方便得多,这就是为什么运行 Shell(例如,在 screen 实例中)比将仿真作为后台进程更有意义。尽管如此,正如已经提到的,这两种方式都是可行的,在某些情况下我们甚至可能更喜欢后台进程。
该应用程序已附带一组预定义的可能性,用于更改房间和/或婴儿的属性。这些可能性称为命令。许多通用命令可以在 general.js 文件中找到。这也能说明这些插件通常是如何工作的。我们导出一个简单的对象,其中包含所需的命令。每个命令都通过其命令名称和命令执行来定义。后者只是一个接受至少三个参数的简单函数。更多参数是可选的,如果指定,将提供。应用程序无法知道某个参数需要被传递,但是,我们可以随时抛出异常或打印错误消息。
module.exports = {
'exit': function(scheduler, room, baby) {
process.exit(0);
},
/* ... */
};
前三个参数是特殊的。它们不是由用户提供的,而是由应用程序本身提供的。第一个参数是调度程序。第二个和第三个参数分别包含房间和婴儿的当前状态。那么调度程序是什么?调度程序是模拟真实硬件跟踪器的应用程序的一部分。硬件跟踪器会尝试定期获取更新的传感器信息。通过使用调度程序,我们可以实际操纵传感器信息。然而,调度程序的作用远不止于此。顾名思义,我们可以使用它来调度环境的修改。在某种程度上,调度程序类似于计划任务或 cron。
让我们看看如何使用调度程序来统一改变温度。heatup-baby 命令是一个很好的例子。首先,我们还考虑了可选参数 temperature 和 time。如果提供了这些参数,它们就是字符串。因此,我们需要一些默认值和转换逻辑。一切设置就绪后,我们在调度程序中安装一个作业。在每个调度程序检查点,我们都想提高婴儿的温度(无论其他更改如何)。最后,我们不想永远运行下去,这就是为什么我们指定了一个额外的 until 条件。
module.exports = {
'heatup-baby': function(scheduler, room, baby, temperature, time) {
var current = baby.temperature;
var desired = typeof temperature === 'undefined' ? current + 1.0 : temperature * 1;
var time = typeof time === 'undefined' ? 0 : time * 1;
var step = (desired - current) / (time || 1);
scheduler.always(function(dt) {
baby.temperature += step;
}).until(function(dt) {
return --time <= 0;
});
},
/* ... */
};
一旦函数评估为 true,条件就会删除该作业。
那么命令是如何读取和更新的呢?好吧,考虑以下片段
fs.readdir(commandDirectory, function(err, files) {
for (var i = 0; i < files.length; i++) {
var file = './' + commandDirectory + '/' + files[i];
extractCommands(file);
}
});
在这里,我们读取包含命令的目录的内容。我们基本上假设每个文件都是一个有效的命令定义。extractCommands 函数也很简单
var extractCommands = function(file) {
var path = require.resolve(file);
delete require.cache[path];
var mod = require(file);
var cmds = Object.keys(mod);
for (var j = 0; j < cmds.length; j++) {
var cmd = cmds[j];
commands[cmd] = mod[cmd];
}
};
前两行稍后将变得重要。暂时忽略它们。其余部分涉及将文件加载到模块中,提取所有命令,并将提取的命令安装到现有的命令字典中。这一切都很简单,而且没什么特别的。那么前两行是怎么回事呢?这是允许在运行时更新命令所必需的。当我们希望包含更新的命令或一组新命令时,我们不想停止模拟器。
魔幻发生在以下片段中
fs.watch(commandDirectory, function(evt, filename) {
if (evt === 'change') {
var file = './' + commandDirectory + '/' + filename;
extractCommands(file);
}
});
如果我们遇到 change 事件(唯一的其他事件是 rename),我们希望更新该特定模块的内容。没有文件创建的事件,这意味着在复制或移动的情况下,我们需要再次触摸(即更改)文件。简单的重命名不会触发模块重新加载周期。现在,我们为什么要使缓存中的给定文件无效就显而易见了。否则,我们就无法更新已包含的模块。问题来自 Node.js 系统,它使用此设置来提高性能并减少所需的模块加载。
安装应用程序需要 Node.js 和 node 包管理器 (npm)。然后在应用程序目录中运行以下命令
npm install
这将安装所有依赖项。运行应用程序就像输入 node index.js 一样简单。启动时,应用程序将检查凭据。这些需要被提供。它们也可以通过命令行参数提供。
其他应用程序
对于比赛来说,一个中央 Web 应用程序似乎是理想的解决方案。尽管如此,在实践中,移动应用程序是可行的方法。在这里,我们将选择 Xamarin 来使用 C# 作为我们的编程语言。此外,每个平台都应保持其自己的外观和感觉。
桌面版本也可能很有趣。但是,由于程序严重依赖在线数据,因此 Web 应用程序很可能与桌面版本一样易于访问。此外,它不受任何平台的限制,并避免了所有安装问题。
理论上,我们也可以用原生应用程序(例如,使用 Apache Cordova)包装 Web 应用程序,但目前与一个制作精良的 Web 应用程序相比,结果不会提供任何实质性的优势。我们不使用任何智能手机传感器或摄像头。也许这以后(可选)会添加。这将是我们能想到的唯一一个真正原生的解决方案会更胜一筹的方面。一些智能手机操作系统有非常定制的 API,或者与其他大多数操作系统非常不同,导致在使用相同的 API 进行多平台开发时,解决方案平庸。
设置 Azure
让我们回顾一下我们想从 Microsoft Azure 产品中使用的服务类型
- 机器学习(分析和推荐)
- 事件中心(处理传感器数据)
- 工作角色(持续数据分发)
- 移动服务(前端 API)
- SQL(存储前端数据,例如学习内容、用户数据)
- 存储(同步事件中心,存储用于机器学习的数据)
- 网站(托管连接到移动服务的 ASP.NET MVC 网站)
接下来,我们将介绍这些服务的设置和基本配置。我们将根据情况使用 Azure 管理门户、Visual Studio 和 PowerShell。通常,Azure 管理门户足以创建和配置一切。然而,在 Visual Studio 中创建合适的项目有时可以提供一个好处,即它也会为我们提供相关的云资源。但话说回来,在某些特殊情况下,PowerShell 中的几个字符可以为我们节省大量的点击。
让我们从设置 Azure 机器学习工作区开始。
设置机器学习
Azure 管理门户为我们提供了创建新的机器学习工作区的可能性。这基本上是一个将数据组合起来进行分析的画布。Microsoft 使用术语 experiment 来表示设置的每个数据分析流程。我们看到,创建机器学习 (ML) 服务也意味着创建存储服务。我们应该将此存储服务视为与其他服务隔离。稍后我们还将创建另一个存储服务用于不同目的。
现在,让我们简单填写表格并请求一个新的 ML 工作区。

此时,我们基本上就完成了。我们可以登录 ML 工作区并设置一个或另一个实验以备将来使用。

我们的计划是使用创建的存储服务作为我们(即将进行的)实验的输入数据流。输出以 API 的形式提供,该 API 由工作角色自动使用,并按需由 Web 应用程序使用。我们将在下面关于连接所有内容的章节中更详细地介绍整个想法。目前,我们在机器学习方面完成了:我们设置了目前需要设置的所有内容。因此,我们可以继续创建事件中心,最终将被 IoT 设备用于传输其数据。
设置事件中心
通过 Azure 管理门户或通过代码(例如 PowerShell、C# 等)可以创建和配置新的事件中心。我们将展示如何通过管理门户进行操作。在这里,我们遵循入门指南[11]中的说明。
要创建新的事件中心,我们单击“应用服务”,然后单击“服务总线”,然后单击“事件中心”,最后单击“快速创建”。此时,我们只需要提供新服务的标识符和目标。将事件中心放在与存储服务相同的数据中心是一个明智的选择,我们稍后也会需要它。如果我们已经有一个现有的存储帐户(可以使用的),那么将事件中心放在相同的数据中心是很聪明的。

事件中心成功创建后,我们仍需进行配置。我们实际上需要两个角色:一个用于从事件中心读取(仅内部使用),另一个用于向事件中心发送新消息。后者将分发给客户,包括下载模拟器的用户。因此,区分这两个角色是有意义的。对于每个角色,我们都设置一个标识符并获得一个密钥(秘密),用于对特定角色的用户进行身份验证。

完成所有这些之后,我们就基本上完成了事件中心的工作。其余的只是将服务连接起来,例如连接到我们的跟踪器模拟器、真实跟踪器或侦听器。
设置移动服务
为了创建移动服务,我们可以使用 Azure PowerShell 工具
azure mobile create <service-name> <server-admin> <server-password> --location <data-center-name>
或者,当然,我们也可以使用 Azure 管理门户。在这种情况下,我们选择了第三种方法。我们使用 Visual Studio 在启动新项目时方便地自动创建移动服务。我们在 Visual Studio 中从熟悉的“新建项目”对话框开始。在我们选择的语言(C#/VB)中,我们将选择一个新的 ASP.NET Web 项目。我们应该看到以下对话框或类似的界面。

在这里,我们注意到我们已经选择了一个 Web API。我们不能更改此选择。但是,我们可以选择“云托管”。这将为我们提供一些方便的选项,例如直接从 Visual Studio 发布项目,而无需额外配置。
由于我们愿意在云中托管我们的移动服务,Visual Studio 会弹出一个新的对话框,询问我们有关服务细节的问题。我们想将它部署到哪里?我们想使用什么数据库?我们要创建一个新的吗?也许我们想更改负责的订阅。另一个重要选项:服务的标识符(名称)应该是什么?
以下对话框包含提供上述所有问题答案的字段。运行时是固定的,因为我们已经创建了一个 .NET 项目。

关闭对话框后,Visual Studio 将与 Azure 通信并配置新的移动服务。此时,我们可以开始实际编程了。稍后我们将详细介绍 Azure 与我们的应用程序的连接。现在,我们在 Azure 和移动服务方面已经完成了。整个服务已经在应用程序部分有所描述。

在给定配置中使用 Azure 移动服务的一个可能问题是删除数据库表的默认规则。Azure 将为提供的 Azure SQL 数据库中的移动服务 API 添加一个特殊用户。但是,该用户没有足够的权限来删除表。相反,必须应用另一条规则。
由于我们在模型更改的情况下重新创建数据库(当然这仅适用于当前项目阶段——在生产环境中,这将是不可接受的),我们将选择特殊的 ClearDatabaseSchemaIfModelChanges 类。这个类与普通的 DropCreateDatabaseIfModelChanges 类非常相似,但它也能够使用已安装的 Azure SQL 用户提供的权限来更改一切。
public class MobileServiceInitializer : ClearDatabaseSchemaIfModelChanges<MobileServiceContext>
{
protected override void Seed(MobileServiceContext context)
{
/* Populate with some data */
base.Seed(context);
}
}
剩下的就是简要讨论一下运行工作角色而不是移动服务应用程序附带的 Web 作业的可能性。实际上,项目模板附带一个预定义的 Web 作业,因此一开始选择 Web 作业似乎要简单得多。但是,Web 作业的灵活性较低,因为它受到移动服务提供的界限的限制。因此,比如一个由自动或手动触发的后台任务,它使用与移动服务相同的资源。由于事件中心服务未包含在移动服务应用程序中,因此我们无法轻松完成此操作。添加最新版本的 ServiceBus 库实际上会导致错误。这有利于工作角色,工作角色在扩展性方面也有一些优势。
尽管如此,我们还是将 Web 作业用于其他事情。稍后我们将看到,我们如何通过调用 Web 作业来计算将 Azure 机器学习结果集成到我们的数据库中。这里我们不需要移动服务方面的很多资源,但是我们喜欢在代码优先数据库设计的基础上进行构建。将所有表都定义在代码中,我们可以直接利用与移动服务应用程序紧密集成的强大功能。
设置 Azure 存储
设置 Azure 存储非常迅速。由于配置存储是许多 Azure 服务的重要组成部分,因此有多种(自动/API 驱动)方法来实现这一点应该是显而易见的。但是,在本节中,我们希望通过 Azure 管理门户来说明基本方案。
首先,我们登录管理门户。然后,我们在底部导航栏中单击“新建”,然后选择“数据服务” -> “存储”。最后,我们为新的 Azure 存储指定一个名称并将其固定到数据中心。可选地,我们可以为我们的新 Azure 存储选择复制类型。“地理冗余”是默认的复制模式。这没问题,因为它提供了最大的持久性。

Azure 存储帐户支持多种存储类型。我们可以使用它来存储 BLOB 形式的二进制对象,在表中存储和查询文档,设置队列进行处理或处理文件。在我们的应用程序中,我们处理测量数据,这些数据以文档形式表示。因此,我们将使用表存储提供的功能。
使用 Azure 表存储就像添加 NuGet 包 WindowsAzure.Storage 一样简单。在这里,我们获得了完整的 API。唯一需要做的是提供到 Azure 存储帐户的连接字符串。这包括获取特定服务的名称和密钥。名称是我们设置时输入的。但是,密钥不是我们提供的。但是,我们可以在管理门户底部栏的“管理密钥”命令中查找它。选择 Azure 存储帐户时,此命令可用。
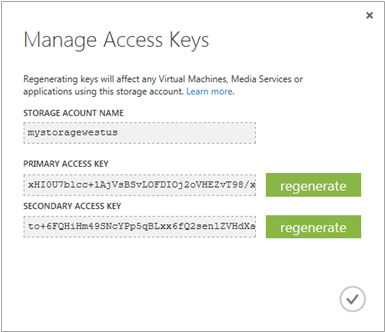
为什么有两个密钥?使用哪个密钥并不重要。有两个密钥是为了支持更多场景。例如,出于安全原因,我们可以每周重新生成一个密钥。为了避免任何停机时间或问题,我们可以随时在主密钥和次密钥之间进行切换。在更改主密钥(例如)之前,我们会将所有服务设置为使用次密钥。然后在下一周更改次密钥之前,我们会再次将所有服务设置为事先使用主密钥。
还有其他场景,例如将主密钥用于外部,将次密钥用于内部。在这种场景中,我们将只重新生成外部使用的密钥。我们假设内部密钥是安全的,并且没有人能够访问它。
让我们继续讨论一种特殊类型的存储,这种存储根本不在存储类别中列出:SQL 数据库。
设置 Azure SQL 数据库
我们将需要大量(预处理)数据。这些数据将是高度规则的,会随时间变化,并会多次读取。SQL 数据库似乎是个好主意。SQL 数据库系统有很多选项。我们可以随意运行虚拟机,任何东西都可以在其中运行。我们也可以使用第三方服务之一,例如使用准备好的 MongoDB 实例。也可以选择租用完整的 Microsoft SQL Server 实例。
为了我们的实验目的,我们不需要 TB 级的磁盘空间和数百 GB 的内存。我们需要经济实惠的东西。我们需要提供良好性能并提供集成良好的 API 的东西。自然,我们将选择 Azure SQL 实例。我们可以通过门户、以编程方式或与新的 Visual Studio 解决方案结合来创建一个新实例。我们决定选择第三个选项。
在我们的情况下,我们在创建移动服务 Web 服务时有机会在 Azure 上发行新的 SQL 数据库。会出现一个类似于下图的对话框。

填完该对话框后,Visual Studio 将向 Azure 发送请求,这将创建一个新的 Azure SQL 数据库。该数据库已经预先配置好,可以与默认包含的 Entity Framework 库一起使用。为了提高效率,我们采用代码优先的方法。这会促进我们的设计和开发过程。唯一需要记住的是,ClearDatabaseSchemaIfModelChanges 规则在生产环境中可能非常具有破坏性。在这里,我们肯定需要一个更好的答案。
数据库管理(通常)不需要(太频繁)。但是,检查数据库结构以查看代码优先方法是否按预期工作是合理的。在出现任何错误时尤其如此。连接到 Azure SQL 实例有多种方法。最常见的有:
- 使用 Azure 管理门户中的 Silverlight 客户端
- 通过 SQL Server Management Studio 连接
- 直接从 Visual Studio 的服务器资源管理器
在任何情况下,我们都需要添加一个防火墙规则。否则,我们无法从本地计算机连接到 Azure SQL 数据库。直接从 Azure 访问 SQL 数据库会提醒我们这一点。另外,如果需要,还会自动添加一个例外。
将来,Visual Studio 也可以通过 HTTP 隧道连接。但是,目前 SQL 数据库不支持 Visual Studio 中的 OAuth 登录。因此,它们仍然需要管理证书才能在 VS 中进行交互。如果我们右键单击服务器资源管理器树中的 Windows Azure 节点并选择“管理订阅”,然后切换到“证书”选项卡并导入管理证书。证书可以保存在 Azure 管理门户中。
设置网站
使用 Microsoft Azure 和 Visual Studio 设置 ASP.NET MVC 网站几乎是瞬间完成的。在这里,我们可以充分利用 Visual Studio 来完成我们在 Azure 管理门户中通常准备和执行的所有工作。与之前的移动服务一样,我们选择一个 ASP.NET Web 应用程序。这次,我们不选择“Azure 移动服务”,而是选择一个普通的“MVC”应用程序。最重要的是,我们选中“云托管”复选框。这将为我们提供与之前看到的类似选项。同样,Visual Studio 将为我们完成繁重的工作。
对于我们的特殊应用程序,我们不需要任何身份服务,因为整个身份验证将由 Web 服务处理。我们也不需要任何数据库,因为所有相关的调用也将由服务处理。特别想部署具有身份验证的 ASP.NET MVC Web 应用程序的读者应该查看 Azure 应用服务文档中的 Rick Anderson 的教程。他很好地描述了你可以做什么以及应该怎么做。我们还可以学习如何为我们的页面启用 SSL。
SSL 对我们来说也很重要,但不如 Rick Anderson 描述的场景那么重要。我们只加载一次静态资源。没有针对 ASP.NET MVC 应用程序的安全敏感流量。只有针对移动服务 API。而这默认是 HTTPS 安全的。所以我们是安全的。拥有 HTTPS 仍然是一件好事,并且向潜在客户表明了安全意识。
对于 Web 应用程序,我们可以获得与移动服务后端相同的功能。我们在 Visual Studio 中有一个特殊的命令 Publish。单击上下文菜单中的命令将为我们提供指定确切目标的选项。

我们也可以通过 FTP 上传我们的 Web 应用程序。或者我们可以使用 git(或其他支持的 VCS)来轻松同步,例如 git push azure master。无论我们想做什么,Microsoft 都已覆盖。当然,我们选择了 Visual Studio 的方式。还有什么比直接从 IDE 进行编码和部署更简单的呢?而且我们的大多数其他项目也设置为使用 Visual Studio 部署。一致性绝对是关键点。
连接服务
既然我们已经创建了各种应用程序,我们就需要将它们连接起来。其中一些已经“生活”在云中,另一些已经发布为云服务。而且它们都需要连接在一起。为了尽可能高效地完成这项工作,我们应该有一个(安全的)文档,其中包含所有密钥、连接字符串、名称和位置。这确实非常有帮助。
在接下来的几个部分中,我们将从模拟器(以提供的模拟器形式)到机器学习工作区。从那里,我们将查看从工作区到移动服务的管道,该管道被所有公共应用程序(如 Web 应用程序)使用。Web 应用程序已经通过依赖于通过 RESTful API 使用的移动服务完全连接。
以下两张图片显示了两个主要管道。我们可以绘制更多类似的图片,但这两种管道是本文档中最重要的一种。一方面,我们有一个从传感器到 SQL 数据库的完整处理线。

另一方面,有执行(HTTP)请求的用户。我们可能会收到这些请求,这开始了第二个管道。在这里,我们想找到我们之前存储的数据。

在接下来的几个部分中,我们将处理这两个管道中各种项目之间的连接。毕竟,每个项目至少有 1 个邻居。所以需要通信。我们将从概述我们的模拟器如何与事件中心通信开始。这种通信方案与真实设备中使用的方案类似,但是,真实设备是用 C 实现的。
通过 Node.js 向事件中心发送消息
我们之前已经描述了软件数据生成器的原理。但是,应用程序的一个重要部分被故意省略了:发送数据。
最后,我们还需要不时发送数据。这里我们选择了一个相当通用的方法,它在博客文章“使用 REST API 从 Node.JS 向 Azure 事件中心发送数据”[12]中有描述。基本上,这个解决方案绕过了使用 1.0 规范中的 AMQP 协议,而是使用了通过 HTTP(S) 协议公开的可选 REST API。
这样,我们只需要实现一个简单的函数来执行实际的请求。我们使用流行的 https 模块来实际处理 HTTPS 协议。最重要的是,我们需要发布消息。在这里,我们倾向于使用 JSON 编码格式,其中包含用户的标识符以及婴儿和房间的当前测量值,而不是其他选项。
var sendData = function(namespace, hub, device, rule, key, user) {
var path = ['/', hub, '/publishers/', device, '/messages'].join('');
var hostname = namespace + '.servicebus.windows.net';
var connectionString = ['https://', hostname, path].join('');
var sasToken = createSasToken(connectionString, rule, key);
var payload = JSON.stringify({
userId: user,
baby: baby,
room: room,
});
var options = {
hostname: hostname,
port: 443,
path: path,
method: 'POST',
headers: {
'Authorization': sasToken,
'Content-Length': payload.length,
'Content-Type': 'application/atom+xml;type=entry;charset=utf-8'
},
};
var req = https.request(options, function(res) {
// Log and close response
});
req.on('error', function(e) {
// Log
});
req.write(payload);
req.end();
};
只有一个小细节需要进一步解释:createSasToken 是什么?显然,该函数不属于 https 模块,也不属于任何其他(标准或非标准)模块。我们实际上已将其添加到源代码中。
SAS 是 共享访问签名 的缩写。它是向其他客户端授予对 blob、表和队列的有限访问权限的强大方法,而无需暴露我们的帐户密钥。对于事件中心 REST API,我们需要以特殊形式使用 SAS 作为授权机制。即使传输被某种方式拦截和解密(HTTPS 已经加密),攻击者也可能无法长时间使用连接。我们基本上会生成不同的字符串并将到期时间设置为一小时。到期时间是 SAS 不再有效的后时间。
var createSasToken = function(uri, name, key) {
// Token expires in one hour
var expiry = moment().add(1, 'hours').unix();
var stringToSign = [encodeURIComponent(uri), '\n', expiry].join('');
var hmac = crypto.createHmac('sha256', key);
hmac.update(stringToSign);
var signature = hmac.digest('base64');
return ['SharedAccessSignature sr=', encodeURIComponent(uri),
'&sig=', encodeURIComponent(signature),
'&se=', expiry,
'&skn=', name].join('');
};
最后,我们只需要将发送数据功能集成到调度程序中。整个过程实际上很简单,因为我们只需要在特定时间间隔触发发送操作。由于调度程序已经调整为通常的发送频率,我们将简单地在每次迭代中传输数据。
以下代码片段说明了集成。
scheduler.always(function() {
sendData(queuens, hubname, deviceId, ruleName, secretKey, userId);
});
这样,我们就可以轻松地模拟我们真实跟踪器的行为。上述过程也表明了设备实际需要做什么。除了设置 Wi-Fi 连接(由于 CC3200MOD 是专门为 IoT 应用设计的芯片,这并不难)之外,用户只需要连接到我们的 Web 服务,并以给定的格式发送用户标识符以及婴儿和房间数据。MCU 负责平均和预处理传感器数据,将其渲染成所需的格式,并定期通过我们的事件中心向 Web 服务执行发送操作。
为了最大限度地降低模拟器的能耗,我们决定将模拟器放在 Raspberry Pi 上。在这里,我们获得了很多好处,只消耗几瓦。在实践中,我们将使用 ssh 连接到 Raspberry Pi。然后我们将打开一个 screen 实例,执行模拟器并分离 screen 实例。此时,我们可以安全地注销而不会终止进程。稍后重新连接时,我们可以轻松地重新附加 screen 实例并使用 Shell,就好像我们从未离开过一样。
在 Raspberry Pi 上安装 Node.js 不如 Windows、Linux 或 Mac 版本那样直接。目前 ARM 分支的维护确实不那么好。而且从源代码编译将花费很长时间,因为 Pi 的性能不足(而且 V8 非常庞大)。幸运的是,如果我们使用 Raspbian 发行版,我们可以使用 adafruit.com 上提供的说明。最终,以下命令应该可以达到目的
sudo apt-get update
sudo apt-get upgrade
wget http://node-arm.herokuapp.com/node_latest_armhf.deb
sudo dpkg -i node_latest_armhf.deb
因此,我们已将系统更新到最新版本(这总是有益的),从某个(受信任的)服务器获取最新的预编译 Node.js 版本(适用于 ARMv6),并通过 Debian 包管理器安装 Debian 包。太棒了!以下屏幕截图显示了正在运行的模拟器。

过时的 Node.js 或 npm 可执行文件可能存在一些奇怪的问题。我们要么在调用 npm 时看到“非法指令”之类的东西,要不就是找不到路径,或者 npm install 找不到依赖项(或者只找到过时版本)。在任何情况下,查看 Ubuntu 论坛 都是明智的。错误很可能与 Node.js 版本混合有关。该线程解释了如何正确删除它们以及如何重新构建系统绑定,以便当前版本也是按需执行的版本。
一切运行后,我们可以通过打开一些事件处理器或通过 Azure 管理门户来观察传入的消息。使用情况图将指示额外的使用情况。当然,在生产环境中,我们无法控制传入消息的数量。这里我们确实需要依赖 Azure 的扩展机制。幸运的是,使用事件中心,我们已经处于安全的一面。

此时,一些数据正在流入。问题是:这些数据会发生什么?Azure 将数据保存在其分区中。如果我们愿意,数据最多可以保存 30 天。默认设置是将数据存储到传输后一天。尽管如此,这些数据实际上应该被使用。在下一步中,我们将集成工作角色,将数据从其当前位置移动到 Azure 存储表,这将作为我们机器学习应用程序的输入。
使用工作角色移动数据
对于这部分,我们将主要遵循 Kirk Evans 的 MSDN 博客[Advice and Tutorial]中的建议和教程。此外,我们还使用 Azure 关于如何在我们的应用程序[16]中使用表存储的信息。有了这些信息,我们就可以集成服务来让数据流动。对于 Azure 工作角色的良好介绍视频,我们推荐 Channel9[17]。
我们首先使用 Visual Studio 启动一个新的云服务解决方案。云服务实际上是一个运行专用服务的虚拟机。其中一项服务可以是 Web 应用程序。另一项可以是工作角色。我们选择后者。

在输入了云服务的基本数据之后,我们还需要配置其他设置。在这里,我们有经典选项,例如名称和位置。但我们也有其他更具体的选项。云服务为我们提供了分阶段部署的可能性。这使我们能够区分生产应用程序、预生产应用程序和其他版本。我们可以轻松地交换代表版本更改的内容。如果我们真的发现了什么可疑之处,我们仍然可以回退。

设置完成后,我们可以选择要包含的各种服务。我们只选择工作角色。稍后我们可以添加更多服务。目前,工作角色是我们唯一感兴趣的。完成后,将创建一个新的 Visual Studio 解决方案。新的 Visual Studio 解决方案实际上分为两个项目。第一个是云服务。这对于提供配置和部署项目很重要。第二个是实际的工作角色。
工作角色类读取配置,创建一个新的接收器,该接收器启动事件中心聚合。通过 DataEventProcessor 类接收事件中心的数据,该类实现了 IEventProcessor。我们这里的代码相当直接,但是,请注意,我们使用自定义提供程序来访问 Azure 表存储,该存储由我们的 Azure 机器学习工作区访问。
我们的处理方案迭代所有消息,反序列化每条消息。如果消息无法反序列化或包含无效数据,则将其丢弃。如果消息不对应于有效的用户/设备组合,则也将其丢弃。在任何其他情况下,我们将其添加到表上下文中,这会排队所有内容以最大化效率。
sealed class DataEventProcessor : IEventProcessor
{
readonly TableContext repository;
public DataEventProcessor()
{
repository = new TableContext();
}
async Task IEventProcessor.CloseAsync(PartitionContext context, CloseReason reason)
{
if (reason == CloseReason.Shutdown)
await SaveAsync(context);
}
Task IEventProcessor.OpenAsync(PartitionContext context)
{
return Task.FromResult<Object>(null);
}
Task IEventProcessor.ProcessEventsAsync(PartitionContext context, IEnumerable<EventData> messages)
{
foreach (var eventData in messages)
{
var data = Encoding.UTF8.GetString(eventData.GetBytes());
var item = JsonConvert.DeserializeObject<DataItem>(data);
// Check items, create and add entities to context
/* ... */
}
return SaveAsync(context);
}
async Task SaveAsync(PartitionContext context)
{
try
{
await repository.SaveChangesAsync();
await context.CheckpointAsync();
}
catch (Exception ex)
{
Trace.TraceError(ex.Message);
}
}
}
传入的 DataItem 被转换为两个实体:BabyEntity 和 RoomEntity。例如,婴儿跟踪器测量值的实体如下所示。我们看到实体使用了一些与聚合器中相同的键。但是,UserId 作为 PartitionKey 存储。这意味着我们首先按用户聚合。使用高效方案有利于通过 ML 工作区进行快速访问。
public class BabyEntity : TableEntity
{
public Double Acceleration { get; set; }
public Double HeartRate { get; set; }
public Double Temperature { get; set; }
public String DeviceId { get; set; }
}
最后,我们还需要查看与我们的自定义 TableContext 相关的一个有趣的点。TableContext 对每个感兴趣的表使用 StorageTableBuffer<T> 的实例。因此,我们有用于婴儿测量值的 StorageTableBuffer<BabyEntity> 和用于房间测量值的 StorageTableBuffer<RoomEntity>。
唯一的访问点是 Include 方法。我们使用此方法来允许将项目添加到缓冲区。但是,在某个时候,缓冲区需要被清空。ProcessAllAsync 方法触发此操作。但是,我们需要确保插入正确进行。因此,我们不允许在批次中执行超过 100 次操作,并且不允许表中存在重复键。后者按设计不应该发生。另一个要求是批次中的所有实体共享相同的分区键。
以下代码满足了这些要求
sealed class StorageTableBuffer<T>
where T : ITableEntity
{
readonly List<T> _entities;
readonly CloudTable _table;
public StorageTableBuffer(CloudTable table)
{
_entities = new List<T>();
_table = table;
_table.CreateIfNotExists();
}
public void Include(T item)
{
_entities.Add(item);
}
public async Task ProcessAllAsync()
{
while (_entities.Count > 0)
{
var partition = _entities[0].PartitionKey;
var operations = new TableBatchOperation();
for (int i = _entities.Count - 1; i >= 0; i--)
{
if (_entities[i].PartitionKey == partition)
{
operations.Insert(_entities[i]);
_entities.RemoveAt(i);
if (operations.Count == 100)
break;
}
}
await _table.ExecuteBatchAsync(operations);
}
}
}
每个 StorageTableBuffer<T> 实例的 ProcessAllAsync 方法都由我们 TableContext 对象的 SaveChangesAsync 方法调用。因此,所有实体都被缓冲并分批执行,正如我们所希望的那样。此外,还满足了要求,应该可以正常工作。最后,我们只需要设置配置,启用日志(非常有用!)并部署我们的云服务。
最初的步骤相当简单,但是,有时我们无法部署我们的工作角色。我们实际上遇到了定期的回收、重启和崩溃。对所有这些问题的初步反应是修复我们包含的库的版本。似乎使用的 Azure 存储库已过时。我们想使用最新版本,即 4.3.0.0。因此,我们在 app.config 中包含了一个程序集绑定。这个解决方案在此 处 进行了更详细的讨论。
<runtime>
<assemblyBinding xmlns="urn:schemas-microsoft-com:asm.v1">
<dependentAssembly>
<assemblyIdentity name="Microsoft.WindowsAzure.Storage" publicKeyToken="31bf3856ad364e35" />
<bindingRedirect oldVersion="0.0.0.0-4.3.0.0" newVersion="4.3.0.0" />
</dependentAssembly>
</assemblyBinding>
</runtime>
这并没有完全解决问题。在本地调试应用程序显示配置无法读取。这很糟糕。在那里,我们发现 Azure ConfigurationManager 库仍为 1.8.0.0 版本,已过时。我们升级到 2.0.0.0 版本,这是一次部分成功。此时,可以成功读取配置,但是,运行批处理查询会引发异常。此操作的灵感来自于 StackOverflow 上的这个帖子。
那么批处理查询错误的根本原因是什么?嗯,事实证明主键实际上是重复的。我们错误地选择了允许重复的分区键 - 行键组合。这实际上很愚蠢。最后,我们决定使用一个非常可靠的组合。

在此阶段,确认数据确实流入所需的 Azure 存储表似乎是合理的。一个用于查看和查询 Azure 存储表的良好工具是 Azure 存储资源管理器。它也可以与流行的包管理器 Chocolatey 一起安装。下面的截图显示了该程序。我们还可以使用 Azure 存储资源管理器来创建、编辑、删除或查看条目。这当然也适用于表。这对于删除表的所有条目非常有用。与其直接删除所有条目,不如使用应用程序一次性删除整个表要容易得多。这效率也更高。

通过探索 Azure 存储目标和负责的云服务的仪表板,也可以获得另一个有用的见解。对于云服务,我们可能还对工作角色的状态感兴趣。我们要求一个忙碌的服务,没有任何异常。其他任何情况都可能表明存在问题。
有时我们也可能想重启服务。这也可以从管理门户进行。如果一切正常且我们有工作负载,重启服务可能没有意义,但是,在没有工作负载时这样做可能是明智的。

最后,我们完成了将数据从事件中心移动到 Azure 表存储的工作,我们的机器学习算法将在此处接收数据。这将在下一节中讨论。
发布机器学习 API
下一步,我们需要回到数据,创建实验并将这些实验发布为 Web 服务。所有这些步骤都可以通过机器学习工作区完成。我们在这里做的第一件事是插入一个 Reader 对象,该对象可以连接到 Azure 表存储。真正的挑战从这里开始。我们需要弄清楚应该执行哪些操作(以及按什么顺序)。在设置完一个实验后,我们会用(当前)数据运行它,并评估结果是否符合预期,或者仅仅是足够好。
现在我们可以单击按钮,准备将实验公开为 Web 服务。我们在底部有命令按钮来开始创建 Web 服务。

唯一改变的是,我们在实验中包含了两项新操作。一项操作是 Web 服务请求的可选收入。另一项操作是实验的结果。我们将使用收入来区分,例如,不同的用户、不同的设备或不同的时间跨度。这完全取决于具体的实验。
学习实验或获取精彩样板的绝佳资源是提供的示例。可用的集合很大且足够好。它包含例如基本的推荐样本,这些样本足以创建一个类似链接推荐系统的东西。Channel9 的人提供了一个成功采用的例子。他们写了一篇关于 Channel 9 实现 Azure 机器学习推荐 API 的博客。在大多数情况下,我们遵循他们的方法。我们提供服务,这些服务会定期被我们移动服务中的 Web 作业调用。
但是,在我们进入我们实现的细节之前,我们仍然必须发布 Web 服务。准备好 Web 服务发布后,底部的命令栏将发生变化。现在,可以通过标记在红色方块中的按钮从机器学习工作区发布 Web 服务。

我们为每个发布的机器学习 Web 服务都会获得一个 API 密钥。这对于管理我们 API 的访问很重要。最终,执行实验的调用与租用 Azure 计算时间相关。因此,如果任何人都可以发出无限数量的 API 调用,我们可能会遇到麻烦。这是只从内部调用 API 的论据之一。结果将被缓存,并且只能通过移动服务 API 访问,该 API 是公开可用的,并限制为 BabyZen 应用程序的用户。
成功创建 Web 服务后,我们还会获得该服务的概述信息。我们看到 Web 服务基本上构建在 ASP.NET MVC Web API 之上。该 Web 服务还附带与其他 ASP.NET MVC 应用程序相同的帮助页面。我们也可以针对 Web 服务运行测试。

让我们来看一下将这种 Web 服务集成到我们的移动服务中。
将机器学习集成到移动服务中
事实上,将机器学习集成到移动服务中,就像将 Azure ML 工作区公开的 Web 服务集成到现有 C# 应用程序中一样简单。我们已经获得了用于与生成的 C#、R 和 Python 服务通信的片段。我们只需要转到我们 API 的帮助页面,就可以找到所有三个平台的代码片段。
下图展示了实际效果。我们总是会得到很多样板代码。Needless to say that we will most probably change the code a lot.

提供的代码片段中唯一缺少的是 API 密钥。这是出于安全原因。因此,即使我们想保留原始复制的源代码,我们仍然需要插入密钥。否则,一切都不会正常工作。
那么,我们在本节中做了什么?我们设置了一些机器学习算法,并选择了它们有用的参数作为 API 调用公开。然后,我们创建了一些 ScheduledJob 类,它们使用数据库中的信息访问这些 API。例如,当前可用的用户形成了一个有趣的输入参数。最后,我们将输出写入一些表中。
我们离完成还很远。实际上,还有很多细致的调整工作,我们现在还不知道一切是否如预期的那样工作。基础设施方面似乎没问题,但是,机器学习算法可能需要更多的调整才能按预期工作。
将移动服务集成到 ASP.NET MVC 中
对于移动服务 API,我们还集成了自定义身份验证,如 Azure 文档[13]中所述。优点是任何人都可以登录。我们的 MVC 主页基本上简化为仅客户端网站。这确保了服务器端的高速和更少的重复。大多数 API 调用都可以直接使用移动服务 API,但其他调用必须通过更通用的 API。
在我们可以使用移动服务 JavaScript 库进行任何操作之前,我们需要创建一个新的 MobileServiceClient。构造函数需要 API 的主机和访问密钥。代码可能类似于以下内容
var client = new WindowsAzure.MobileServiceClient(
"https://babyzen.azure-mobile.net/",
"The API key"
);
API 区分更通用的 API 调用(由 ApiController 子类表示)和表 API 调用。后者基于 TableController 实例。请注意,可以使用通用 API 方法调用所有 API。调用更通用的 API 示例如下代码
var apiName = 'test';
var options = { method: 'GET' };
client.invokeApi(apiName, options, function(error, response) {
console.log(response.responseText);
});
invokeApi 方法需要 API 名称和一些选项。如果未提供选项,则假定使用 POST 方法。在某些情况下这是正确的,但绝非总是如此。因此,无论如何都要提供选项是一个好习惯。
更通用的 API 对于我们的登录过程也至关重要。由于我们使用自定义登录,因此我们必须使用一种更晦涩的方式来执行登录。我们需要手动设置 currentUser。
var signIn = function(username, password) {
var apiName = 'signin';
var data = {
username: username,
password: password
};
var options = {
body: data,
method: 'POST'
};
client.invokeApi(apiName, options, function(error, response) {
// Check if response is 200 and no error is given
var user = JSON.parse(response.responseText);
client.currentUser = user;
client.mobileServiceAuthenticationToken = user.authenticationToken;
});
};
提供的 login 方法无法与我们的自定义登录过程配合使用。至少我无法使其正常工作,但是,也许我没有正确设置自定义登录过程。至少使用提供的代码,它似乎有效,尽管不是很优雅。
测试整个过程将非常有益。当然,业务逻辑的单元测试和一些集成测试很重要,但现在我们只对一些小的、直接的测试感兴趣。我们能访问我们的移动服务吗?我们可以插入和检索数据吗?我们可以使用包含的在线 API 文档进行一些测试调用。但是,由于我们几乎所有的调用都受到限制,因此我们需要提供用户信息。这似乎并不简单,至少没有官方指南说明如何做到这一点。尽管如此,这是可能的,通过提供自定义 HTTP 标头。要向我们的 API 发出经过身份验证的请求,我们需要在请求中包含一个名为 X-ZUMO-AUTH 的 HTTP 标头作为身份验证令牌。
以下屏幕截图说明了这一点。请注意,标头的值实际取决于先前的登录请求。我们不能总是使用相同的值。

现在真正的重点是读取表。我们的大多数 API 都由这些表提供。而且大多数都只是可查询的。要从特定表(例如 device)中获取所有数据,我们可以发出类似以下的语句。我们可以从一些 where、select、skip 或类似方法开始。使用提供的代码,我们可以获取表中的所有项目。结果是一个 JavaScript 数组。
var dev = client.getTable("device");
dev.read().done(function(res) {
console.log(res);
});
我们将方法集成到我们现有的应用程序中。现在数据会自动填充。我们之前已经附加了所有 Knockout 可观察对象,这意味着应用程序自动处于良好状态。不再需要数据管道。
连接所有内容
在我们的过程中,我们做了一些决定,在某种程度上提供了捷径,或者适应了现实世界的情况。尽管在生产环境中应该只追求后者,但我们都知道捷径总会被走。尽管如此,我们希望我们总是正确地指出了捷径,并且我们总是建议了更稳定、可靠和安全的功能实现方式。ASP.NET 网站上提供了一本关于编写 Azure 真实世界应用程序的绝佳指南[14]。
现在我们已经接近大结局了。我们所有的服务都已启动并运行。我们已将它们全部连接起来。唯一缺少的是一个演示应用程序的画布。好吧,下一节将展示演示应用程序的结果。目前,我们更关心内部发生的事情。Azure 管理门户显示了我们的服务状态。它们看起来都不错。

让我们再次回顾一下数据流。我们有未知数量的设备在发送数据。通常我们会说每个用户最多只有一个设备,但是,我们都知道有些人即使没有帐户也可能发送数据。也许只是机器人。也许是邪恶的用户。我们所知道的是,任何人都可以向端点发送数据。我们的事件中心在那里收集所有数据并将其放入某个分区。
这就是我们的工作角色发挥作用的地方。工作角色尝试(因此可能正在扩展)处理接收到的数据。它检查传输的有效性,并将数据存储在 Azure 表存储中。只有有效且已批准的数据才会被保存。这也是可以直接从 Azure 机器学习工作区访问的地方。
我们设置了一些可以通过 Web 服务访问的实验。密钥仅在内部分发。目前唯一的消费者是移动服务后端,它会不时调用一些计划任务。计划任务从其 API 中运行机器学习实验,输入来自 Azure SQL 数据库。结果存储在 Azure SQL 数据库中。该数据库的唯一访问者是 Azure 移动服务后端。
后端是我们的 Web 服务。它是每个 BabyZen(前端)应用程序都必须使用的 API。它可以是移动应用、桌面应用或任何其他连接到我们服务的应用程序。目前,我们已经设置了一个简单的 ASP.NET MVC 页面,它被简化为一个单页应用程序。我们直接从客户端调用移动服务,而 ASP.NET MVC 后端不介入。这保证了速度、安全性和敏捷性。摩擦越少,能耗就越低。然而,为了完成一些工作,我们总是需要一些摩擦。
应用程序(演示)
Web 应用程序是基础设施的现场演示。可能会出现停机或意外错误。这仍然是一个实验项目,我们希望进一步发展它。会有一些测试,所以请不要期望它一直可用。而且功能可能会在短时间内中断。
下图显示了仪表板。仪表板是每个用户成功登录后看到的视图。它显示了最重要的值。

为了提供良好的用户体验,我们还提供了一个登录对话框。将来人们可能还会要求重置密码。目前此功能尚未实现。有一些缺失的功能,但这些功能应该很快可用。将来还会添加其他功能。

如果您想试用模拟器,您还必须注册您自己的帐户。注册表单如下所示。

最重要的是,Web 应用程序可用于确定当前的“Zen 因子”。Zen 因子已在 Web 应用程序 部分中进行了说明。在截图的示例中,我们显示了 8 的得分,这相当高。

Web 应用程序可以访问 babyzen.azurewebsites.net。
提供了一个用户名为 Demo,密码为 Demo$123 的演示帐户。该帐户如前所述是只读的,即无法修改任何内容。该帐户仅作为概念验证,证明这里描述的一切都能正常工作并且在线。
TL;DR
我们构建了一个名为 BabyZen 的应用程序的基础设施。该应用程序由一个可访问的前端和一个结合了各种传感器的跟踪器组成。该应用程序背后的想法是识别婴儿环境中的某些模式。识别这些模式可以提出改进建议。这些改进应该可以预防疾病,增强孩子的发育,并通过最小化孩子的需求直接使父母受益。毕竟,如果包裹已经送达,就不需要任何请求了。
在辛普森一家剧集“Brother, Can You Spare Two Dimes?”[18]中,可以找到我们项目的绝佳类比。在该剧集中,Homer 的同父异母的兄弟 Herb Powell 正在制造一个婴儿翻译器。这是一种将婴儿的咿呀学语翻译成需求或请求的设备。我们的设备类似,但它不依赖于婴儿的咿呀学语,而是依赖于他们周围的环境。此外,我们将设备分为三个部分:发送器(跟踪器)、接收器(Microsoft Azure)和显示器,它可以是任何东西,从网站到移动设备或任何其他连接到我们服务的应用程序。

该设备可能看起来不时髦,但它只是一个原型。由于此类设备无法下载,因此我们决定编写一个可以下载的模拟器。可以创建一个帐户并开始发送模拟数据。但是,请注意,模拟数据不受真实边界的限制,因此可能导致无效的建议。我们尝试检测无效数据,但目前我们的算法训练得还不够好。

通过使用机器学习算法,我们可以使用已插入、分类和结构化的数据来训练我们的应用程序。最终,我们能够做出某些预测。目前,这些预测由于训练数据不足而受到影响,但在未来,这种情况肯定会改变。
兴趣点
BabyZen 应用程序为希望通过暴露孩子于不当环境条件来最小化风险的父母提供了愉快的体验。当然,需要具备先进功能的大型设备才能可靠地监控所需数据,但如果没有灵活而强大的后端,就无法进行必要的分析。Microsoft Azure 平台提供了我们设置真正出色的 IoT 解决方案所需的所有功能。
使用设备模拟器绝对是一次有趣的体验,它已经可以给我们宝贵的见解。包含的命令为模拟普通婴儿生活中相当有趣的一周打下了基础。有一个命令模拟发烧,另一个处理腹泻等等。当然,我们也包含了模拟正常白天和夜晚的命令。但最终,模拟的关键目标之一是决定是否可以检测到边缘情况。在我们自己的模拟中,我们对从真实婴儿收集的数据进行了运行。我们发现建议的有效性完全符合预测。然而,推荐系统不应仅针对正常或预期数据进行测试,而应针对各种意外数据和边缘情况进行测试。
如果您想玩模拟器,请不要忘记调整 settings.json 文件。它包含用户信息。这些信息尚未为您或您的 BabyZen 帐户进行调整。无效数据将从事件中心删除,如前所述。
当然,仍然有一些遗留问题,很可能将在未来几个月内得到解答:扩展是否如预期那样工作?真实的跟踪设备能否无缝集成到普通父母和婴儿的日常生活中,而不会造成任何实际问题和不便?(当然,这将在很大程度上取决于设备的具体技术规格和设计。)还有哪些数据可能对改进建议有用?我们的建议有何影响?实际推荐行动的最佳方法是什么?考虑到我们宏伟的目标,这个问题列表基本上是无穷无尽的。
我们要感谢所有支持此项目的人。我们特别感谢德州仪器公司的人员,他们为我们提供了样本 IC 和免费工具。我们还要感谢 Microsoft 提供免费(至少是非商业用途)的精湛工具、库、服务和基础设施。
参考文献
- 维基百科:禅
- 斯坦福大学:婴儿研究中心
- 耶鲁大学:儿童研究中心
- 国际婴儿研究学会
- CC3200MOD SimpleLink Wi-Fi 和物联网模块解决方案,单芯片无线 MCU
- HDC1000 低功耗、高精度数字湿度传感器带温度传感器(Rev. A)
- OPT3001 环境光传感器 (ALS) (Rev. B)
- LMP91051 用于 NDIR 传感应用的配置式 AFE (Rev. B)
- AFE4400 适用于心率监测器和低成本脉搏血氧仪的集成模拟前端 (Rev. H)
- CC3200MOD SimpleLink Wi-Fi 和物联网解决方案带 MCU-模块 LaunchPad 用户指南
- 开始使用事件中心
- 使用 REST API 从 Node.js 向 Azure 事件中心发送数据
- 开始使用自定义身份验证
- 使用 Azure 构建真实世界云应用程序
- 新生儿体温变化:与母亲进行身体接触的重要性
- 如何从 .NET 使用表存储
- Channel9:Windows Azure 工作角色入门
- 维基百科:Brother, Can You Spare Two Dimes?
历史
- v0.9.0 | 初始发布 | 2015 年 3 月 30 日
- v0.9.1 | 布局更新 | 2015 年 3 月 30 日
- v1.0.0 | 添加了缺失的部分 | 2015 年 3 月 31 日
- v1.0.1 | 包括了联合作者 Niki Kilbertus | 2015 年 6 月 8 日