
对 .NET 4.0 并行代码示例效率的简要测试
4.71/5 (16投票s)
验证一系列简短的 .NET 4.0 并行编程样本的执行效率
引言
在上一篇文章中,我介绍了一系列关于 CUDA 代码和使用 Thrust 库代码计算效率的简要测试。在测试中,执行了整数数组(0到9的随机数)的平方和运算,并记录了代码的执行效率。简而言之,结论是 GPU 芯片上的并行处理潜力巨大,特别是对于包含海量并行元素的计算。
然而,另一方面,我进行测试的计算机还配备了 Intel Q6600 四核 CPU。显然,单线程的普通循环代码无法充分利用多核 CPU 的全部潜力。因此,我编写了一些 C# 代码来重新执行平方和运算,并通过比较不同并行算法策略的效率,得出一些可能对从事类似主题的开发者有帮助的观点。
[本文可视为与文章“CUDA 和 Thrust 代码效率简要测试”的配套作品。]
背景
串行执行的普通循环(计算平方和)是基准测试的基础。毫不奇怪,C# 代码编写如下:
var watch = Stopwatch.StartNew();
int final_sum = 0;
for (var i = 0; i < DATA_SIZE; i++)
{
final_sum += data[i] * data[i];
}
watch.Stop();
elapsed_time = (double)watch.ElapsedMilliseconds / 1000;
其中 data 是一个预先生成的、包含 DATA_SIZE 个随机整数的数组。
// generate random number ranged in [0, 9]
static void GenerateNumbers(int[] number)
{
Random ro = new Random();
for (var i = 0; i < number.Length; i++)
{
number[i] = ro.Next(0, 9);
}
}
.NET 4.0 中的 System.Threading.Tasks.Parallel
我选择 C# 是因为我对该语言比较熟悉。另一个重要原因是,最近发布的 Visual Studio 2010 和 .NET 4.0 对并行编程提供了新的支持。由于关于此功能的信息很多,例如 CodeProject 上的文章《Introducing .NET 4.0 Parallel Programming》,我就不赘述了,只提供相应的代码来进行计算。
借助 .NET 4.0 提供的新的 System.Threading.Tasks 命名空间,for 循环被替换为对名为 System.Threading.Tasks.Parallel.For 方法的调用。这是一个 static 方法。一个匿名函数 delegate 定义了实际工作,它实际上对应于前面普通 for 循环中编写的代码块。线程池通常用于孵化线程来执行工作;然而,我们很幸运,不需要了解任何细节,因为 Tasks 命名空间会处理所有事情。最后,实际代码如下:
final_sum = 0;
Parallel.For(0, DATA_SIZE, i =>
{
Interlocked.Add(ref final_sum, data[i] * data[i]);
});
然后对加法操作进行并行化。另一点需要注意的是,使用 Interlocked.Add 方法来使之前的 final_sum += data[i] * data[i]; 加法操作变得线程安全。
就是这样。很简单,不是吗?然而,使用我的四核 CPU,并行代码并没有显示出任何优势。例如,如果处理 1M(1M 等于 1 * 1024 * 1024)个整数,串行代码使用了 7 毫秒,而并行代码消耗了 113 毫秒,时间长了 15 倍。
为什么?:( 然后就到了有趣的点。
关注点
请记住,我们使用了 Interlocked.Add 方法来锁定线程分配的共享资源 final_sum。(data[i] 没问题,因为每个线程只访问数组的一个元素,而且这些元素在不同线程之间是不同的。)这对于考虑代码执行效率至关重要,因为所有线程都必须排队等待访问 final_sum。换句话说,尽管代码是并行化的,但对 final_sum 的访问仍然是串行的。这基本上就是为什么代码执行时间没有缩短的原因。此外,由于分配和管理线程的开销,执行时间甚至更长。
考虑到我 CUDA 程序中用于相同目的的并行算法,我们实际上不需要将求和操作并行化到数组的每个单独元素。一种建议的方法是将数组分成一定数量的块。每个块包含相同数量的元素,并且不同块的元素不重叠。理论上,我们可以使用一定数量的线程,建立线程与块的一一对应关系,然后:
- 由相应的线程计算每个块中的子和,并记录结果
- 对所有子和结果进行求和
如果将数组分成 1k(1k 等于 1 * 1024)个块,即线程数也为 1k,实际代码可能如下:
// initial value for thread number
long THREAD_NUM = 1024;
// buffer for the threads
int[] result = new int[THREAD_NUM];
// piece size for each thread
long unit = DATA_SIZE / THREAD_NUM;
watch.Restart();
Parallel.For(0, THREAD_NUM, t =>
{
for (var i = t * unit; i < (t + 1) * unit; i++)
{
result[t] += data[i] * data[i];
}
});
final_sum = 0;
for (var t = 0; t < THREAD_NUM; t++)
{
final_sum += result[t];
}
watch.Stop();
elapsed_time = (double)watch.ElapsedMilliseconds / 1000;
在CUDA 版本中,我使用了 16k 个线程进行计算。如何确定适合四核 CPU 的线程数以获得最佳性能?我对此进行了敏感性研究。我分别使用 TN(线程数)等于 1k、16k 和 256k,并测试了代码执行时间;记录的值(单位:秒)如下表所示:
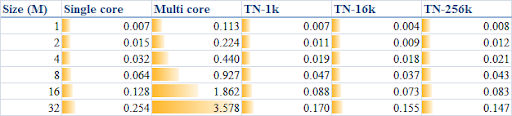
下表还列出了串行代码和未分割数组的并行代码所消耗的时间。简而言之,项目的描述是:
- 单核:串行执行的普通循环的执行时间
- 多核:使用
System.Threading.Tasks.Parallel.For方法而不将数组分割成块的执行时间 - TN-1k:将数组
data分成 1k 个组并使用Parallel.For方法进行管理的执行时间。在每个组中,使用内部普通循环来计算子和 - TN-16k:同上,但将数组分成 16k 个组
- TN-256k:同上,但将数组分成 256k 个组
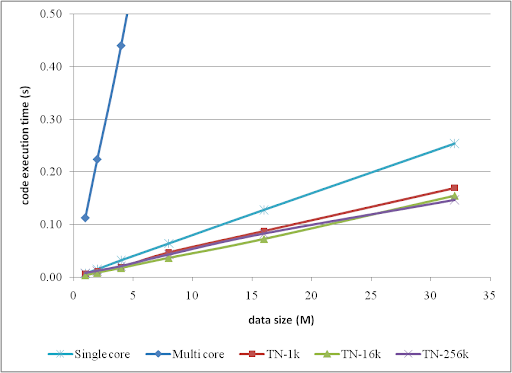
相应的趋势可以总结为:
或者通过直方图进行比较:
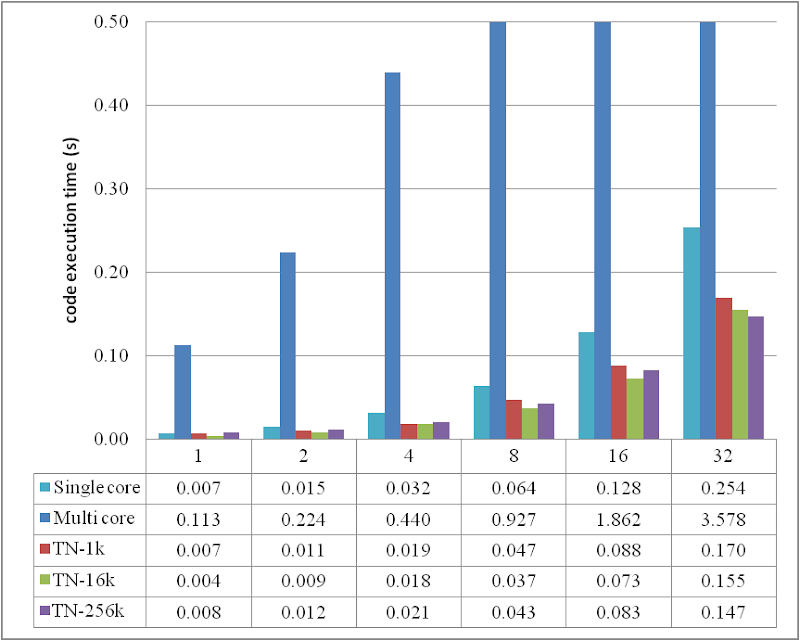
将数据分组到一定数量的并行单元后,执行性能得到了显著提高,并且已经优于串行执行循环,尽管提高的幅度未能达到四核处理器应有的 4 倍。
图表也显示,只使用 1k 个线程并非理想。16k 在大多数情况下效果更好,除非 DATA_SIZE = 32 M。这可能意味着,对于更多的数据,可能需要更多的线程来处理它们。
结论
我进行测试的最初目的是比较CUDA 计算效率与多核效率。然而,在此过程中,我发现将串行循环移植到并行代码并不像简单地用 Parallel.For 方法替换 for 循环那样简单,尽管这本来是可以预期的。实际上,与设计 CUDA 程序一样,必须仔细考虑线程数。
基于测试,我发现,对于 1M 到 32M 个整数,使用 16k 个线程可以实现非常均衡的性能。虽然对于 DATA_SIZE = 32 M,16k 线程的效率低于 32k 线程,但损失约 5%。
此外,通过将这些 C# 结果与上一篇文章中的 CUDA 结果进行比较,我还发现:
- 与串行代码(即普通循环代码)相比,C++ 代码的性能优于 C# 代码;两者代码都在同一 Q6600 CPU 上运行。
- CUDA 代码的性能优于并行 C# 代码,尽管两者都使用了 16k 个线程。CUDA 在 9800 GTX+ 芯片上运行,C# 代码在 Q6600 处理器上运行。
我们知道,使用 CUDA 时,CPU 和 GPU 之间的内存传输成本非常高。即使有内存传输开销,CUDA 代码的性能仍然优于利用 CPU 四核(2.40 GHz)的并行 C# 代码。至少对于这个平方和计算来说,情况是如此。这是否意味着 CUDA 确实为我们带来了巨大的潜力?
代码说明
zip 包中包含的代码文件 ParallelExample.cs,包含了本文提到的不同策略的串行和并行方法的测试代码。请注意,为了提取实用的基准测试的平均值,计算执行必须重复足够多次;为了清晰和简化。我没有将此功能包含在附带的代码中,但肯定很容易添加。
代码在 Windows 7 32 位和 Visual Studio 2010 中构建和测试。测试计算机的主要配置是 Intel Q6600 四核 CPU,加上 3G DDR2 800M 内存。虽然使用的硬盘不好(Windows 7 评分为 5.1),但我不认为它在测试中起重要作用。
历史
- 2010/07/01:本文初版发布。