
高级文本搜索
使用 OR 和 AND 布尔运算符构建简单的查询语言

引言
当处理大量数据(无论是网站还是其他专业程序)时,为用户提供缩小他们需要查看的数据子集的功能是非常有益的。避免这种情况但又不让用户感到困惑的唯一方法是将数据划分为小块(例如,按姓名的首字母呈现通讯录)。但这并非总是可能,因此搜索系统会很有帮助。
解决方案描述
我开发了一个实现简单查询语言的类。语法通过一些基本示例及其解释在下面呈现
| abc cde fgh | 字符串“abc”、“cde”和“fgh”必须全部存在,但它们的顺序无关紧要(因此 cdeabcfgh 是此规则的有效序列)。每个空白字符都被视为分隔符(实际上我使用 Char.IsSeparator 方法来确定字符是否为分隔符)。 |
| "abc cde""" | 字符串abc cde" 必须存在。请注意,要包含引号字符("),您必须将其加倍。除了组合单词外,引号字符还有助于插入特殊字符( ( , ) , [ , ] )。 |
| [a b c] | 字符串必须包含至少一个元素(OR)。 |
| (a b c) | 字符串必须包含所有元素(顺序无关紧要!)。 |
| [(a b) (c "[")] | 括号可以嵌套。该表达式的意思是 字符串要么包含a 和b(顺序无关紧要)。 或者 它包含c 和[(注意特殊字符[ 如何必须放在引号中)。 |
语法的更正式描述将是
queryString ::= <queryPart>[<empty characters><queryString>]queryPart ::= <keyword>|<orComposition>|<andComposition>
orComposition ::= [<queryPart>{<empty characters><queryPart>}]
andComposition ::= (<queryPart>{<empty characters><queryPart>})
emptyCharacters ::= 由
Char.IsSeparator 方法定义keyword ::= "<characters>"|<non empty, non special characters>
此语法可能显得有些奇怪,并且有一个缺点,即它不是标准的。因此,从用户的角度来看,可能需要一些时间来适应。我不建议将其用作网站上的默认搜索语言,但它可以作为替代方案(例如,用于高级搜索)。此外,我发现它比常规方法更明显(如果您写“Anna and Betty”,您想搜索什么:是精确的字符串还是包含这两个词的字符串?),并且更容易实现。
要使用此代码进行搜索,您必须执行以下简单步骤:
- 创建一个搜索树并记住它的根。
Dim x As SearchTreeNode = SearchTreeNode.ContructSearchTree("[a b] [c d]") - 现在,对于您要验证的每个元素,调用
.MatchesString(string to match, root)函数。它返回 true 或 false,具体取决于提供的字符串是否与规则匹配。
实现细节
SearchTreeNode 是一个多叉树的节点,它记住它的第一个子节点和下一个兄弟节点,如下所示。
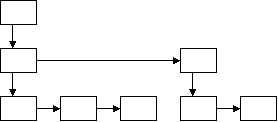
树的节点可以是三种类型:AND 节点、OR 节点和 KEYWORD 节点(或叶子)。AND 节点当其所有子节点都匹配字符串时,则匹配该字符串。OR 节点当其至少一个子节点匹配字符串时,则匹配该字符串。关键字节点当字符串包含它时,则匹配该字符串。例如,以下规则被翻译成下面的树:"[(a b) (c d)] e"
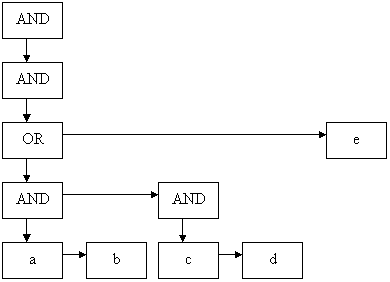
您可能已经注意到多了一个 AND 节点。这是为了避免在例程中处理特定情况,并且对运行没有影响。上面的树是通过静态(共享)方法 ConstructSearchTree 构建的。如果无法构建树,该方法将抛出异常。异常的消息会尝试暗示语法错误的可能原因。
MatchesString 静态方法需要一个字符串,它将与规则和树的根进行比较。然后,它使用 MatchString 私有方法执行对树的递归遍历,并返回 true 或 false。
关于性能的一些说明
实际上我对代码的性能很满意。它可以在 16 毫秒内使用规则 "[a b] [c d]" 搜索 10000 个包含 100 个“x”字符的字符串。这代表了叶子节点的最坏情况(其中实际搜索是使用 indexOf 方法完成的),因为没有找到匹配项。在这种情况下,还必须遍历整个树,因此对于实际匹配规则的字符串,搜索可能会更早中止。测试是在一台运行 WinXP SP2 的 AMD Sempron 2200+ 机器上进行的,内存为 256 MB。
提高匹配速度的一种方法是实现更快的字符串匹配算法,如 Boyer-Moore 或 TurboSearch。这些算法的辅助表可以在树创建期间生成。问题是字符串是 Unicode 编码的,因此辅助表(例如,对于 TurboSearch 算法)可能会达到非常大的尺寸(64K 个元素)。还有一点是关键字可能相对较小(5-10 个字符),而 indexOf 方法的性能相当不错。
附加功能
有两种方法:一种用于从树构建 SQL 查询的过滤部分,另一种用于从树构建正则表达式。它们都是静态(共享)方法,其语法如下:BuildSQLQuery(field name, root element) 返回一个类似于 (<field name> LIKE "%keyword%" AND ... 的字符串。在关键字中,引号字符(")的所有出现都被替换为反斜杠引号(\")。
第二种方法从搜索树构建正则表达式:BuildRegEx(root element) 并将正则表达式作为字符串返回。此方法的一个限制是它不生成处理提供的参数的所有可能顺序或出现的正则表达式,只生成树中定义的。我使用了这种方法,因为考虑到正则表达式的限制,完整的实现将生成非常长且复杂的表达式(必须在表达式中显式指定所有可能的排列)。
最后说明
我希望您觉得这篇文章很有用。如果您觉得这篇文章很愚蠢、令人讨厌、不正确等等,请通过适当的评分来表达。但是,如果您能留下评论解释您的原因,我将不胜感激,以便我(希望)能从我的错误中学习。