
识别面向对象的类
识别面向对象类的技巧和建议。
引言
在面向对象软件设计 (OOD) 中,类是定义对象特征和操作的模板。通常,类和对象互换使用,两者同义。实际上,类是对象实现的规范。
识别类可能具有挑战性。选择不当的类会使应用程序的逻辑结构复杂化,降低可重用性,并阻碍维护。本文简要概述了面向对象类,并提供了识别内聚类的技巧和建议。
注意:以下类图是使用 Enterprise Architect 建模的。存在许多其他建模工具。请使用最适合您的目的和项目的工具。
类
面向对象类支持面向对象的抽象、封装、多态和可重用性原则。它们通过提供一个模板或蓝图来定义基于它的所有对象共有的变量和方法。类指定知识(属性)——它们知道事情——和行为(方法)——它们做事。
类是对象的规范。
从 用例 派生出的类提供了需求的抽象,并提供了应用程序的内部视图。
属性
属性定义了类的特征,这些特征共同捕获了关于类的所有信息。属性应受到其封闭类的保护。除非被类的行为更改,否则属性会保持其值。
属性可以包含的数据类型由其数据类型决定。有两种基本数据类型:原始类型和派生类型。
- 原始数据类型是基本类型。例如:整数、字符串、浮点数。
- 派生数据类型是根据原始数据类型定义的,也就是说,它们通过扩展原始数据类型来形成新的数据类型。例如,一个
Student类是由一组原始数据类型组成的派生数据类型。
当在问题域的上下文中定义时,派生数据类型称为领域特定数据类型。这些类型定义并约束属性,使其与数据的语义一致。例如,Address studentAddress 而不是 string studentAddress。
在实际可行的情况下,设计模型应使用领域特定数据类型代替原始数据类型。
在设计模型中寻找属性时,请查找这些类型:
- 描述性属性提供关于类的内在信息。例如,有关注册状态、考试成绩和教育目标的信息对
Student类来说是内在的,但对Automobile类来说不是。问:“什么特征使这个类与其他类区分开来?” - 命名属性用于唯一标识对象,并且通常在对象的生命周期内不会更改。考虑两个
Student对象,它们都包含命名属性studentName。“Jack”和“Jill”的值将标识两个不同的Student对象。问:“什么唯一地标识了这个对象与其他同类的对象?” - 引用属性包含对象链接。例如,学生的考试成绩可能存储在
Assessment类中。Student类中Assessment属性的值会将Student类链接到Assessment类。问:“这个对象如何与其他对象关联?”
职责
类具有行为和职责。职责是类知道或做的事情……是类在知道某些信息和/或执行任务方面的义务。例如,学生知道她的地址和社保号。学生会注册课程。
严格来说,职责与类的操作(行为)不完全相同,但操作可以履行职责。履行职责可能需要一个以上的操作(有时需要一个以上的对象)。
职责是类或对象执行任务或了解信息的义务。
识别类
识别面向对象类既是一门技巧,也是一门艺术。这是一个随着时间推移会变得越来越好的过程。例如,经验不足的设计师识别出过多的类是很常见的。建模过多的类会导致性能不佳、不必要的复杂性和维护成本增加。另一方面,过少的类往往会增加耦合度,并使类变得庞大而笨重。总的来说,努力实现类的内聚,即行为在多个相关类之间共享,而不是在一个非常大的类中。
内聚类可以减少耦合,实现可扩展性,并提高可维护性。
此外,看似显而易见的类最终会成为糟糕的选择,而最初隐藏的或依赖于问题域知识的类则会成为最佳选择。
因此,通过识别候选类开始类建模——一组初始类,从中将产生实际的设计类。设计类是被建模的类。候选类仅用于派生设计类。最初,会有很多候选类——这是好事。但是,通过分析,随着它们的删除、组合和合并,它们的数量会减少。
候选类为生成内聚类提供了最初的动力。
可以通过多种方式发现候选类。以下是三种方法:
- 名词和名词短语:从用例、参与者-目标列表、应用程序叙述和问题描述中识别名词和名词短语、动词(动作)和形容词(属性)。
- CRC 卡:一种非正式的、团队协作的面向对象建模方法。
- GRASP:一组正式的分配职责的原则。
这些方法中的每一种都会产生一个候选类的列表。该列表不完整,也不是每个类都合适,而且很可能混合了业务类和系统类;例如,Student 和 StudentRecord。这没关系。目标是识别主要类——显而易见的类。随着设计过程的继续,其他类也会显现出来。
创建列表后,分析候选类与其他类的关联。寻找协作类。每个类如何与彼此以及与业务流程相关?有时,问“为什么保留这个类?”会很有帮助。换句话说,假设该类是多余的或不必要的。仅当它扮演协作角色时才保留它。通常你会发现类的功能是由另一个类完成的,或者在另一个类的上下文中完成的。
当保留一个类时,将其移到设计类列表中。最终,将得到一个设计类列表,该列表为应用程序提供了基础结构。
|
候选类 |
设计类 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
设计类将从候选类的分析中涌现。
关联是识别内聚类的关键。以下各节将介绍类之间可能存在的各种关联以及识别它们的建议。
关联
应用程序系统中的类不是孤立存在的。类与其他类相关联或联系。当一个类拥有、使用、了解或熟悉一个或多个类时,就会发生这些关系。
关系是类之间的关联。
在识别关系时,从与尽可能多的其他类交互的类开始;也许是应用程序的核心类。问“谁关心这个类?”、“谁对这个类感兴趣?”、“这个类为什么是必要的?”从核心类开始将快速识别其他关系。
从核心关联开始。
关联通常使用连接两个类的实线来建模。

大多数时候,单条线提供的不足以满足需求。养成给每个关联命名的习惯,以Clarify关系。使用动词或简单的动词短语作为关联名称。

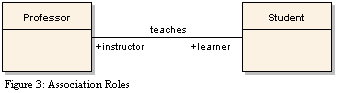
关联角色
关联也有角色。关联中的每个类都有一个角色,描述其在关系中的含义。角色是可选的,如果使用,则应将角色描述为名词。例如,Professor 是 Student 的导师,而 Student 是学习者或学生。
多重性指示器
角色可以具有多重性——指示有多少个对象参与关系。多重性指示器可以是条件性的或无条件的。
多重性指示器的例子是:

在图 4 中,前两个指示器(以“0...”开头)是条件性的,意味着关系中不需要存在任何对象。最后两个指示器(以“1..”开头)是无条件的,意味着关系中至少必须存在一个对象。例如:

在图 5 中,Professor 可以在没有 Student 的存在的情况下存在。因此,Student 的多重性为 0…*。但是,对于 Student 则不然。Student 至少必须有一个 Professor。因此,Professor 的指示器为 1…*。
多重性指示器也称为基数。
无条件指示器可能强制执行参照完整性约束。考虑以下示例:

类 A 和类 B 依赖于对方的存在。由于多重性是无条件的,因此暗示以下内容:
- 当移除类
A(或类B)时,必须同时移除相应的类B(或类A)。 - 当添加类
A(或类B)时,必须同时添加相应的类B(或类A)。
必须检查无条件指示器以了解参照完整性约束。
关联类
关联也可以具有自己的属性和行为——就像类一样。有时,存在的数据并不严格属于任何参与类。在这些情况下,会创建一个关联类,将数据映射到参与类。然后,该类成为关联。关联类将包含包含指向两个类实例的指针或引用的属性。
例如,Student 类与 Course 类有联系。一个学生可以上许多课程,一门课程可以被许多学生上。但是,谁负责成绩?将成绩放在 Student 类中会导致一个学生对所有课程的成绩相同。将成绩放在 Course 类中会导致所有上同一门课程的学生成绩相同。

关联类通过将成绩(和其他属性)链接(或映射)到 Student 和 Course 类来解决此问题。现在,一个 Student 可以有许多课程的许多成绩,但 StudentClassAssociation 中的每个成绩都与单个学生和课程相关联。

关联类经常出现在多对多关联中。
组成
有时一个类由其他类组成。组合关联形成整体-部分关系。在这种关系中,部分的生命周期取决于整体。换句话说,当整体被销毁或移除时,部分也会。此外,部分不能属于一个以上的整体。这意味着整体与部分的多重性始终为“1”。
在组合关联中,整体管理部分的生命周期。
要识别组合关联,请寻找那些不能独立于其他类而存在的类。寻找“整体”和“部分”。问:“这个类是另一个类的部分吗?”例如,Sentence 类是 Paragraph 类的一部分,Paragraph 类是 Chapter 类的一部分,Chapter 类是 Book 类的一部分。“这个类是否依赖于另一个类?”
关键问题是:“当另一个类被销毁时,这个类是否也被销毁?”
聚合
聚合是组合的一种较弱形式。聚合与组合之间的关键区别在于,在聚合中,当整体被销毁时,部分不会被销毁。在聚合关系中,部分可能独立于整体,但整体需要部分。例如,汽车由发动机、底盘、车轮等组成。车轮是汽车定义所必需的,但它们是独立的,并且不一定在汽车被销毁时被销毁。聚合通常被称为“拥有”关系,例如,汽车拥有发动机。
要识别聚合关联,请问:“这个类是另一个类的部分并且它独立于另一个类吗?”
为避免混淆,当不确定使用组合/聚合关联的决定时,最好将关系建模为简单关联。
泛化/特化
泛化/特化关联存在于一个类是另一个类的特化版本时。在这种关系中,一个公共的、基类为更专业化或派生类奠定了基础。这种关联通常被称为继承,因为派生类继承了其基类的功能以提供特化的行为。
继承提供了一种机制,用于从现有类的属性和行为中形成新类。
随着基类特化为派生类,形成层次结构,表示“是”或“种类”关系。例如,代数课程是数学课程的一种特化;学生是一种人。
要识别继承关系,请问:“这个类是一个更通用类的特化吗?”
注意将所有关联都视为继承的倾向。这会导致复杂且深层的类层次结构,难以开发。经验法则:将层次结构限制在六个或更少的级别。
继承最适合相对较浅的类层次结构。
使用继承的情况:
- 继承层次结构表示“是”关系,而不是“拥有”(组合/聚合)关系。
- 不同的数据类型应用相同的行为。
- 类层次结构相对较浅,并且不太可能随着时间的推移而变得更深。
接口继承
与继承密切相关的是接口继承的概念。与继承的类一样,接口提供了行为的通用规范,但与继承的类不同,接口不能被创建。接口仅指定其他类继承但实现方式不同的通用行为。这意味着不相关的类可以为相同的行为规范提供独立的实现(多态)。
例如,.NET 框架提供了 IComparable 接口,该接口定义了一个通用的比较方法。该接口通常用于排序目的。继承 IComparable 接口的类会根据其自身的需求实现特定的行为。因此,使用相同的 IComparable 接口,Integer 类可以对整数进行排序,Byte 类可以对字节进行排序,Student 类可以对学生进行排序,依此类推。
行为已从任何特定类中抽象出来,并由所有需要它的类专门实现。
使用接口继承的情况:
- 不相关的对象类型需要提供相同的行为。
- 需要多重继承(使用继承关联实现非常困难)。
- 禁止继承。例如,C# 结构不能继承自类,但它们可以实现接口。
策略设计模式是接口继承的一个绝佳候选。
结论
有时,开发人员不知道从哪里或如何开始识别类。通常,类的选择仅基于开发人员认为有意义的内容,而忽略了类关联或内聚性。结果,应用程序的逻辑结构可能包含不必要且复杂的类,导致应用程序难以扩展和维护。本文提供了技巧和指导,以识别面向对象的、内聚的类,这些类协同工作以完成应用程序的业务功能。
其他链接
- Allen Holub 的 UML 快速参考
- Scott Ambler 的 如何创建类图。
- Scott Ambler 的 UML 类图指南。
- OMG 的 UML 资源页面.
- Craig Larman 的 应用 UML 和模式 是必读之作。