
可扩展套接字服务器
4.89/5 (36投票s)
您的 PC 能多快地提供数据?
引言
这个项目是 Node.js 快速演示的结果。我开始对这个问题很感兴趣:我的 PC 能提供网络内容的最高速度是多少?如何最好地组织代码以获得最大性能?
我决定一探究竟。
Kegel 的文章 《C10K 问题》 表明,在 2001 年,一个 Web 服务器支持 10,000 个并发客户端从磁盘请求 4K 内容是合情合理的。
我将忽略互联网上有些人认为 C10K “过时了”,现在已经将目标定为使用商品硬件实现一百万并发事务。那种性能/可伸缩性需要专门的编程,包括替换网络驱动程序。
关于如何编写网络服务器和客户端,Linux 世界中有相当多的文献。Windows 世界的资料则较少。有相当多的关于 WCF 的文档,但那与 C++ 不直接相关。Windows Socket 2.0 API 有很好的文档,但也许不是使用它的最佳方式。计划是写一系列文章,涵盖
- Windows 套接字编程。
- Linux 套接字编程。
请注意
- 本文无意提供套接字编程的详尽论述。
- 本文无意提供服务器架构性能的详尽分析。
- 本文不考虑“保持连接”、巨帧或防止拒绝服务攻击的机制。
我家里没有高速网络,因此客户端和服务器应用程序都在同一台机器上进行了测试。杀毒软件已关闭,机器已断开与 Internet 的连接。IIS 和所有不必要的桌面应用程序都已关闭。假设这足以重现真实的相对性能。
第一部分 - Windows 套接字
架构
一个“高效”的套接字服务器应该是什么样的?有两种“极端”的方法
-
线程模型
每当服务器收到请求时,就会创建一个线程来服务该请求(“每个请求一个线程”)。线程会等待阻塞操作,如文件 I/O,并运行直到请求完全处理完毕。
这显然存在一个问题,即所需的总线程数是无限的。线程化还需要锁定或其他策略来协调对共享资源的访问。线程创建和锁定成本很高。这种方法的优点是开发比事件模型更容易。
-
事件模型
传入的请求被添加到队列中。在单个线程上运行的有限状态机 (FSM) 处理队列中的请求。不允许阻塞。文件 I/O 等操作使用异步调用实现。如果在请求处理期间进行了异步调用,则当前请求的处理将停止,当前状态被保存,并开始处理队列中的下一个请求。当异步调用返回时,原始请求会被重新添加到队列中,或者可能添加到另一个优先级队列中。
基于事件的系统没有与线程和锁相关的开销。但是,由于只使用单个线程,它们不能充分利用现代处理器的全部功能。FSM 也难以理解和修改。Node.js 等框架提供了更用户友好、更灵活的回调机制,允许开发人员隐式定义自己的 FSM。
许多混合架构试图结合这两种方法的优点。即便如此,可以公平地说,在 IT 界普遍存在“线程有害,事件有利”的说法。
1978 年,Lauer 和 Needhams 发表了论文《操作系统结构的对偶性》,证明了线程和事件是“对偶的”:用一种模型可以做到的事情,用另一种模型也可以做到。
因此,创建一个“高效”套接字服务器的过程归结为使用一种最小化开销(线程上下文切换、锁定、内存分页等)的架构。
环境
测试在 Dell Vostro 上进行,配备 Intel(R) Core(TM) i5-3450 CPU @3.10 GHz,8.00 GB 内存。操作系统为 Windows 8.1 Pro 64 位(以及 Mint 17)。网卡是集成 Realtek PCIe GBE,理论上支持千兆字节/秒。该机器购于 2012 年。它也沾染了各种坚持在后台运行的应用程序。任务管理器显示,在进行了一些优化后,后台任务仍稳定消耗 5% 的 CPU。
工具
Apache 基准测试工具 ab 用于测试 TCP 服务器并生成统计数据。下方显示了 ab 的典型输出。
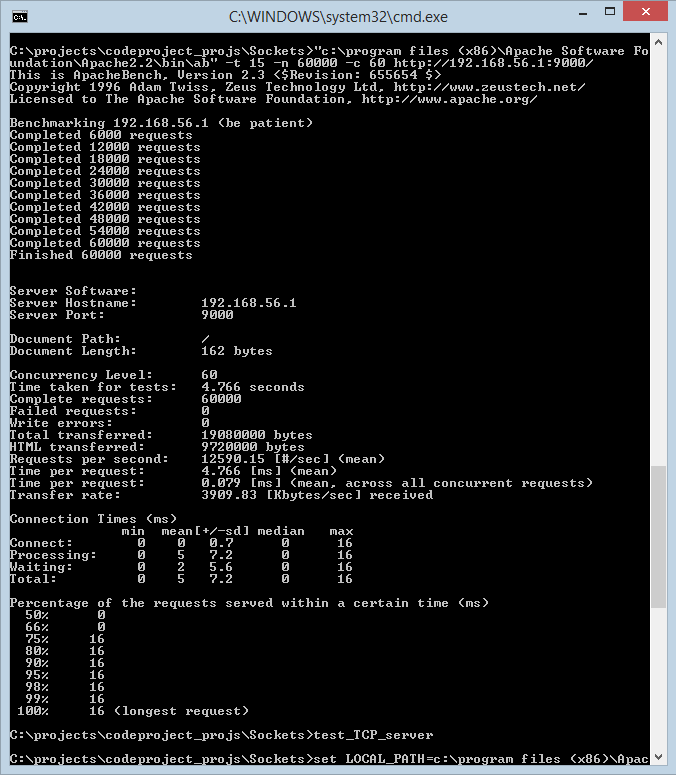
基本测试配置是 60,000 个请求,10-10,000 个并发连接。每个测试配置至少运行 4 次,以获得代表性的性能数据。
代码
代码使用 Visual Studio 2013 社区版编译。项目附带 Visual Studio 解决方案和项目文件,用于在我的机器上构建项目。您需要确保
- 已安装 boost 并构建了库(使用 bootstrap)。
- VC++ Include 目录包含 boost 库。
- VC++ Library 目录包含包含已构建 boost 库的目录(撰写本文时是 stage/lib)。
示例使用了以下类
socket- 对经典套接字 API 的薄封装。并非所有套接字 API 都被封装。并未尝试做到优雅。目的是提供套接字 RAII 管理。如果您想要功能齐全的套接字类,网络上有很多。例如 SocketCC、CSocket、PracticalSocket、SocketCC、SimpleSockets、RudeSocket 等。dedicated_heap- 用于管理缓冲区内存的专用堆;与重载的new和delete一起使用。该类可以编译为使用std::vector或VirtualAlloc。thread_pool- 用于处理 HTML 请求的轻量级线程池类。
没有任何代码经过商业级别的测试。请报告错误并给我时间修复,而不是给我差评!
基本配置
用于性能测试的基本配置是
- 默认 HTML 响应(4K)
- Windows 防火墙关闭。Windows Defender 关闭。
- 卸载杀毒软件,断开计算机与 Internet 的连接。
可以通过在 Web 浏览器中键入服务器 URL 来检查服务器的 HTML 响应。(服务器 URL 在初始化期间打印到 std::cout)
该项目不太关心处理 HTML 请求所需的任何代码的效率;一旦启动,服务器将始终返回相同的 HTML。可以通过在命令行上传递包含新 HTML 的文件名来定制服务器返回的 HTML。
Content
已实现并考虑了以下模式
- UDP 客户端和服务器。
- 使用
listen和accept的多线程 TCP 服务器。 - 使用
select和accept的单线程 TCP select 服务器。 - Windows I/O 完成端口套接字服务器。
- asio 同步和异步服务器。
UDP 客户端和服务器
这些应用程序的目的是查看可以生成和处理数据包的速度。简单的 UDP 客户端 + 服务器能够每秒生成和消耗 230,000 条消息。没有进行代码优化。由于客户端和服务器应用程序都在同一台机器上运行,因此很可能在具有良好网卡的专用服务器上,每秒可能实现高达 460,000 个数据包的指标。
基于 UDP 性能的 TCP/IP 性能估算。
以下数据包用于服务一个简单的单数据包 HTML 请求,响应也是一个简单的单数据包 HTML。
- SYN
- SYN + ACK
- ACK
- HTML 请求
- ACK
- HTML 响应
- ACK
- FIN
- ACK
- FIN
- ACK
单个 HTML 请求至少会产生 11 个 TCP/IP 数据包在网络上传输。假设数据包大小实际上约为 1500 字节,对 4K 的请求会生成 3 个数据包和 3 个低级 ACK 数据包,总共 15 个数据包。如果我们假设 UDP 是高效的(它没有任何 TCP/IP 服务器的复杂性),并且我们可以使用原始套接字实现自己的超高效 TCP/IP 协议,那么我们可以预期每秒 230,000/15 = 15,333 个请求(rps)。(Windows 不支持原始套接字,除非在 Windows 服务器上,以防止恶意桌面代码滥用此功能)。
多线程 TCP 服务器
此服务器使用线程池来最小化线程创建的成本。传入的请求被添加到任务/请求队列中,然后按到达顺序处理。从这个意义上说,可以说服务器是一个混合体,它使用了线程模型和事件模型的某些方面。
在没有错误处理的情况下,调用序列如下
thread_pool.start_up()
bind() // to local end point.
listen() // for incoming connections.
for(;;)
{
incoming_socket = accept() // wait on/accept incoming connections
create task to process incoming connection.
Task is:
{
recv();
... // process the request
send(); // the appropriate response
}
}
线程池在线程数约等于处理器核心数(我的机器是 4 个)时工作效果最好。
Windows 支持的线程数量是有限制的。默认情况下,每个线程分配 1MB 的堆栈空间,这使得线程数量的上限略低于 2048。可以更改堆栈大小,但 Windows 至少会分配 64K - 这给了不到 31,250 个线程的限制。实际上,服务器的限制会远低于此,因为需要为堆分配内存来执行服务器的正常功能。
可以通过使用用户线程包将最大线程数增加到 Windows 限制之外,该包还可以通过协程等技术避免上下文切换的成本。然而,这类库并不常见,多线程服务器总是会比等效的事件驱动服务器使用更多的资源,仅仅因为每个线程都需要自己的堆栈空间。使用大量线程的实际服务器还将面临其他限制,例如对最大打开文件数的限制、对最大打开数据库连接数的限制等。
这种模式易于实现,适用于计算内容,如图表和数学计算。添加阻塞 I/O 会严重降低性能。
单线程 TCP Select 服务器
此模式在 Linux 套接字编程文献中很常见
bind() // to local end point.
listen() // for incoming connections.
fd_set known_sockets;
add listen_socket to known_sockets
for(;;)
{
fd_set ready_to_read;
select(known_sockets, ready_to_read); // find which sockets are ready to read.
foreach(socket in ready_to_read)
{
if(socket == listening_socket)
{
incoming_socket = accept() // wait on/accept incoming connections
add incoming_socket to known_sockets
}
else
{
recv();
... // process the request
send(); // the appropriate response
}
}
}
该模式可以实现为阻塞/非阻塞。
尽管 Microsoft 支持熟悉的套接字 API,但 Microsoft 的实现与“标准”Unix/Linux 实现不同。例如,select 的第一个参数被忽略。FD_SET、FD_CLR 宏使用(缓慢的)循环在套接字集中搜索所需的套接字;Linux 实现使用文件描述符作为索引。
Microsoft 表示,“诸如 WSAAsyncSelect 和 select 函数之类的机制是为了方便从 Windows 3.1 和 Unix 移植而提供的,但并非为可伸缩性而设计”[1],因此可以预期其性能不如其他架构。Microsoft 有另一种他们更希望您用于高性能应用程序的模式。
I/O 完成端口 (IOCP) 服务器
Microsoft 推荐使用 I/O 完成端口服务器来构建可伸缩的高性能服务器应用程序,该技术可追溯到 20 世纪 90 年代中期。IOCP 服务器比之前的服务器复杂得多。伪代码如下
class connection
{
enum completion_key { none, IO, shutdown }
enum connection_state { recv, send, accept, reset } operation;
...
};
IOCP = CreateIoCompletionPort()
bind() // to local end point.
listen() // for incoming connections.
CreateIoCompletionPort(list_socket, IOCP) // Associate listen socket with IOCP.
Load AcceptEx function
create WSAOVERLAPPED and buffer pool.
create threads.
foreach(thread):
{
for (int i=0; i<max_connection; i++)
create_connection()
while(!stopping())
{
get completion port status // via GetQueuedCompletionStatusEx()
key = OVERLAPPED_ENTRY.lpCompletionKey
if(key == shutdown)
close connection;
else
{
connection = key;
app_state_machine.on_IO_complete(...) // Do whatever should be done next.
// Inside the state machine...
switch(operation)
{
case accept:
on_accept(); // also includes recv operation.
break;
case recv:
on_recv_complete(); // calls WSASend()
break;
case send:
on_send_complete(); // finished.
break;
}
if(finished)
{
delete_connection()
call create_connection()
}
}
}
}
create_connection()
{
// Create connection object and block until AcceptEx returns.
create a connection object.
create accept socket for connection.
CreateIoCompletionPort(accept_socket, IOCP, key = pointer to connection) // Associate accept socket with IOCP.
Call AcceptEx(...) passing in the connection (derived from WSAOVERLAPPED) and a completion key = IO
}
代码遵循套接字服务器的模式,即通过使用 AcceptEx 进行侦听来创建新连接。该模式不同之处在于(i)在调用 AcceptEx 之前预先创建了一个新套接字;(ii)套接字通过 CreateIOCompletionPort 与一个 ULONG_PTR 键值相关联;(iii)AcceptEx 被视为任何异步函数,不会阻塞,而是执行阻塞在 GetQueuedCompletionStatusEx 上,后者将通知调用线程任何新连接。
一旦建立连接,每次 I/O 完成都会调用应用程序特定的状态机,以确定下一步应采取什么操作(发送/接收数据或关闭套接字)。所有对 WSASend 和 WSARecv 的调用都是异步的——它们立即返回。线程通过调用 GetQueuedCompletionStatusEx 来检查完成端口状态,当 I/O 完成(或出现错误条件)时,该函数将返回。GetQueuedCompletionStatusEx 提供与发送/接收套接字关联的键——在我们的例子中,该键用于确定服务器是否应关闭。
该实现使用 GetQueuedCompletionStatusEx,因为它能够一次性解除队列中的多个完成包,从而减少上下文切换次数并可能提高性能。
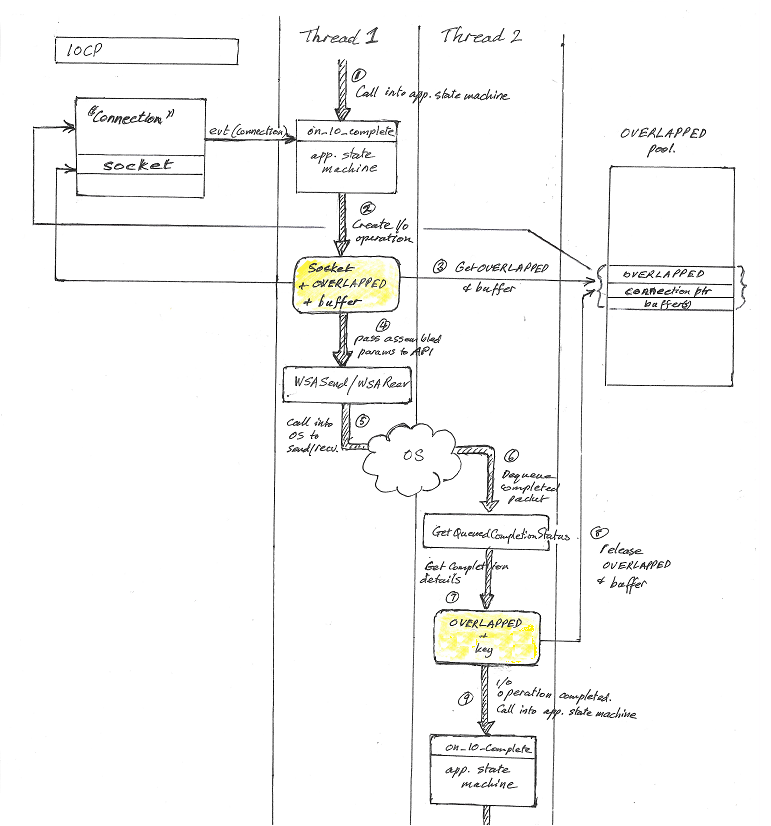
下图显示了处理过程中通常会发生的步骤
-
线程 1 调用应用程序状态机以确定下一步该做什么。
-
状态机决定执行 I/O 操作,并组装所需数据(套接字 +
WSAOVERLAPPED+ 数据缓冲区) -
从
WSAOVERLAPPED池中获取WSAOVERLAPPED结构和数据缓冲区。WSAOVERLAPPED池是一个类似堆的结构,包含多个预先分配的三元组(WSAOVERLAPPED+ 数据缓冲区 + 连接指针)。三元组被更新,以便连接指针指向关联的连接。 -
组装好的数据传递给
WSASend或WSARecv,后者立即返回。线程 1 继续处理其他工作。 -
Windows 安排数据传输(
WSASend)或等待数据从网络到达(WSARecv)。 -
I/O 操作完成,一个完成包被排队,然后由线程 2 中的
GetQueuedCompletionStatusEx检索。 -
GetQueuedCompletionStatusEx函数返回指向原始WSAOVERLAPPED结构和与发送/接收套接字关联的键的指针。 -
如果不再需要
WSAOVERLAPPED结构和缓冲区,可以将它们释放回 OVERLAPPED 池。否则,它们会立即被重新使用。 -
线程 2 调用应用程序状态机以确定下一步该做什么。
服务器使用 VirtualAlloc 分配内存,并使用 VirtualLock 将虚拟内存锁定到物理内存中。在初始化期间会计算缓冲区和 WSAOVERLAPPED 结构所需的内存量,并调整工作集大小以确保 VirtualAlloc 和 VirtualLock 函数不会失败。在早期测试中,使用 VirtualAlloc 和 VirtualLock 使吞吐量提高了约 10%。
应注意,当前代码中虚拟内存的使用效率不高且不完整。项目使用了我多年前编写的代码。我可能将来会重写代码。(这些文章是一项重大工程,主要是因为需要进行大量的检查和代码测试)
设计考虑因素
服务器不使用 WSASend/WSARecv 在单次调用中发送/接收来自多个缓冲区数据的能力。如果需要此功能,则需要单独的 WSAOVERLAPPED 和缓冲区池,因为它们将不再是一对一对应的关系。
当前设计允许应用程序逻辑对套接字(连接)执行多个重叠的 WSASend 和 WSARead 操作,因此 WSAOVERLAPPED/缓冲区和套接字(连接)之间不再是一对一的关系,也不能将它们合并到单个结构中。
简单的 Echo 服务器每个连接只会有一个 I/O 操作待处理,因此在这种情况下,可以不用 WSAOVERLAPPED 池,并将 WSAOVERLAPPED + 数据缓冲区 + connection 对象合并到同一个结构中(通常是一个扩展的 WSAOVERLAPPED)。
可以将 connection object 的地址作为与接受套接字关联的完成端口键传递。这意味着当 GetQueuedCompletionStatusEx 返回时,可以将键转换为 connection 对象,从中可以找到所有其他数据结构。然而,这对 AcceptEx 不起作用,因为 GetQueuedCompletionStatusEx 返回的是与侦听套接字关联的键,而不是与接受套接字关联的键。
服务器无法检测客户端是否突然崩溃或以其他方式未能正确关闭连接。“死连接”可能是一个问题,因为它们会消耗资源,并最终(有时相当快地)导致服务器内存不足。它们可用于实现拒绝服务攻击。处理这种情况的建议方法是,如果连接在一定时间内未收到数据包,则终止该连接。Windows 也会这样做,但默认超时时间为 10 分钟,这对于高性能/高容量服务器来说是不合适的。死连接的解决方案是特定于应用程序的——在我们的例子中,问题通过在发送响应后关闭连接来部分避免。
Asio
性能
那么,哪种服务器架构能提供最佳性能?该服务器使用标准配置进行了测试,涉及 10 到 10,000 个并发用户。每秒响应数显示在下图中。
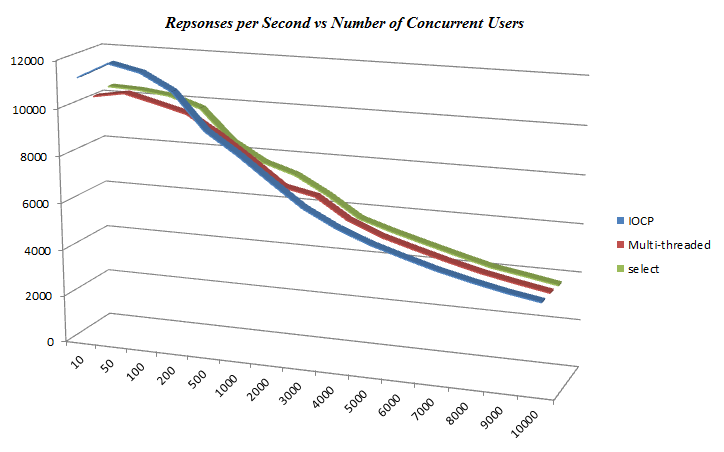
在 200 个并发用户以下,IOCP 服务器提供了最佳性能。超过 200 个并发用户后,所有架构的性能几乎相同。每个请求时间(跨所有并发请求)显示了相似的模式,从约 0.09 毫秒开始,并在各个架构之间收敛到 0.267 毫秒。
这不对。
似乎性能实际上受到套接字服务器软件本身以外的其他因素的限制。显而易见的可能性是
-
Windows 在处理套接字请求的速度上存在根本限制,而我们的应用程序正在触及这个限制。虽然存在这种限制,但似乎该限制会受到服务器架构的影响,因为它们以非常不同的方式使用内核,所以这种可能性似乎不太可能。
-
ab.exe(本身就是一个套接字应用程序)无法胜任服务所需数量数据包的任务,在超过 200 个用户后,它实际上是在报告自己的性能;这一论断得到了互联网上各种帖子的支持。
我们最初关于可以在单台机器上进行可靠性能比较的假设被证明是不正确的。测试方案不足。
我无论如何都需要一台更强大的机器(我一直在使用 Android 模拟器开发软件)。届时,我将/可能会回顾本文并尝试一种更复杂的基准测试方法。
200 个并发用户以下的测试表明
-
调整编译器选项和锁定虚拟内存对性能有轻微影响。重用套接字似乎没有多大区别。这可能是因为服务器并未真正以最大容量运行。
-
调整线程数、每个线程的缓冲区数甚至
OVERLAPPED_ENTRIES的数量可以对性能产生显著影响。这些可以在命令行上设置,以进行实验和优化。 -
很难确信服务器的性能没有受到任何台式 PC 背景中大量应用程序/服务的干扰。杀毒软件可能报告已关闭,但实际上并未完全关闭。通过使用“控制面板/管理工具/服务”窗口实际关闭服务,可以获得显著的性能提升。
没有提供 asio 服务器的性能数据。
结论
如果您想使用 Windows 编写高性能套接字服务器,最好不要逆流而上——编写一个 I/O 完成端口服务器——但这只是基于非常有限的证据。
在我们低配置的 PC 上,IOCP 服务器在约 100 个并发用户时,对于 1K 的数据包产生了约 12,600 次每秒响应。考虑到结果是在一台运行客户端和服务器的机器上获得的,并且 ab.exe 可能低报了性能,这是相当可观的。
最后的提醒是,我的数据是在我的机器上获得的,不应被视为可靠。您的测试结果几乎肯定会与我的不同。