
XLL 自动生成 - 元数据驱动工具的示例
4.60/5 (6投票s)
XLL 自动生成 - 元数据驱动工具的示例
引言
库支持多种语言是很常见的。这通常需要接口层来封装核心功能。例如,在银行领域,定价库通常用 C++ 编写以提高速度,但会以 Java、Python、C#、R 以及 Excel 等多种语言提供。
尽管核心库的编写者希望技术高超,但他们可能不是跨语言开发的专家。即使他们是,编写接口代码也不是对他们时间的明智利用。
这个问题通常有两种解决方式:(i) 代码库的编写方式使其易于与客户端代码对接;(ii) 接口代码可以通过工具生成。
第一种方法很诱人。然而问题在于客户端代码可能对库的结构产生不当影响。作者见过许多据称是用 C++ 编写以提高速度的定价库,但其中充斥着 VARIANT、XML 或 COM 对象。使用这些结构所带来的妥协必然会增加复杂性并降低性能。下面展示了“正确”的架构;每个层都专注于优化自身的行为。没有数据结构会因为在某个点可能方便而从客户端代码迁移到库中,反之亦然。

第二种方法与架构一致,但如果没有现成的工具可用,可能会很昂贵。本文展示了编写此类工具的步骤。特别是,项目代码演示了如何使用元数据自动生成 C++ 库的接口代码。元数据由解析器生成,并用于生成代码——在我们的例子中,是为 XLL 生成代码,以便在 EXCEL 中暴露函数、对象和方法。
代码生成
代码生成器有几个好处:(i) 生成的代码质量应始终如一。如果库庞大且/或广泛分发,知道一个潜在的错误源(接口代码中的 bug)已被消除的好处不可低估。(ii) 代码生成比手动编写应该更快更容易。
理想情况是库作者只需简单地“标记”库代码中相关的部分作为外部可用。然后,通过运行一个解析器对(预处理后的)源代码进行解析,构建一个导出函数/方法的元数据描述,再利用元数据驱动代码生成器来生成代码。
元数据编译器
库代码以 .dll(Windows)或 .so 或 .a(Linux)文件形式提供。其本质是必须能够找出库中导出了哪些函数(可用)。要查看可用信息,请在 Windows .dll 上使用 depends.exe,在 Linux .so 或 .a 文件上使用 nm -D。然而,这些信息不足以满足我们的目的。
因此,有必要提供额外的机制来标记源代码中导出的函数/方法。我们的项目代码使用伪属性 QExport,如下所示。请注意,[[ ]] 内部没有空格。
// [[QExport]] <== This marks the following function/method as exported.
double density(double T, double P, double humidity);
数据类型限制
将复杂数据类型从一种语言映射到另一种语言是一项复杂任务。为了使自动生成可行,QExported 函数签名中使用的数据类型仅限于以下类型:
bool, char,short,int,long,long long,float,double- 上一项中指定的整数类型的无符号版本。
- 之前指定的数字类型的指针和引用。
- 对象引用。
代码生成器不支持任何字符串类型,例如 std::string(这是一种 C++ 特有构造,不应让其跨越边界进入客户端代码)。对象支持将在后面的对象包装器部分讨论。
分词器
乍一看,解析器似乎是难以想象的复杂,但事实并非如此。通常,解析分为两个步骤:
- 将字符流转换为令牌流。
- 将令牌流与语法进行匹配。
分词不是强制性的,有些解析器没有单独的步骤,但通常将令牌而非字符分开考虑会更容易。例如,以下字符串
"int main(int argc, char** argv);"
会生成以下令牌列表
int main ( int argc , char * * argv ) ;
单独的分词步骤可以简化消费语法。例如,“作用域解析运算符”:: 可以被返回为单个令牌,而无需解析器向前查看以确定每个“:”后面是否跟着另一个。
解析器
1. 解析器只关心导出函数/方法。因此,它需要检测 [[QExport]] 伪属性。将为此专门分配一个单独的令牌类型。
2. 解析器需要检测注释,包括 C 风格(/* ... */)和 C++ 风格(// ... \n),因为它们可能插入到代码中的任何位置。例如:
// [[QExport]]
double density(double T, // temperature in Celsius
double P, /* pressure in millibars */
double humidity // 0.01 = 1% humidity
);
3. 理想情况下,解析器不应引起代码的任何人为组织,因为这会在某个时刻对开发产生不利影响。QExported 函数和方法可以声明在代码库中的任何地方,包括深度嵌套在头文件中。
递归查找头文件以定位声明是一项复杂的任务。处理这种情况最简单的方法可能是调用 C++ 预处理器。即,对原始源文件进行预处理,然后将解析器运行在输出上。
4. 解析器需要检测字符串,因为它们可能包含应该被忽略但如果解析器不知道其在字符串内部就会使之混淆的令牌。
5. 解析器需要知道函数定义是否发生在类定义内部。如果发生,它就成为方法定义。因此,解析器需要跟踪 { } 对。
6. 如果发生错误,解析器需要知道错误的行号和字符位置。因此,分词器需要跟踪换行符和字符位置。请注意,字符串 "\tA" 中 'A' 的位置是 2,尽管某些编辑器可能会报告该字符在位置 3,5 或 9,具体取决于制表符的扩展方式。
分词器由 parser_base 类在项目中实现。
语法
语法用于描述可接受的令牌流并触发适当的操作(例如,代码生成)。语法通过产生式进行描述,这些产生式指定了高级语法结构是如何由其他语法片段组成的。
下面是项目解析器的语法(EBNF):
Data types
type-decl = [ "const" ] [ undecorated-type | [ "class" ] class-type ] [ "*" | "&" ]
undecorated-type = boolean-type
| signed-type
| floating-type;
boolean-type = "bool";
signed-type = [ "unsigned" | "signed" ] ( "wchar_t" | "char" | integer-type );
integer-type = [ "short" | "long" [ "long" ] ] [ "int" ];
floating-type = "float" | "double";
Function declarations
export-decl = QExport-decl [ api-decl ] exported
QExport-decl = "///[[QExport]]" <== special token.
api-decl = export_tag | "__declspec" "(" "dllexport" ")" <== for the moment this is hard coded.
exported = class-decl | function-decl
function-decl = [ "static" ] type-decl declarator
declarator = name [ "::" method-name ] "(" [ parameter-decl ] { "," parameter-decl } ")"
parameter-decl = type-decl name
Class declaration
class-decl = "class" class-name [ ":" baseclass {[ "," baseclass]} ] class-body
class-body = "{" tokens "}"
main
code = export-decl | persist-decl | class-decl | token code
语法通常有两种类型:LL(n) 和 LALR(n) ——“n”表示解析语法所需的“前瞻”令牌数量。
LL 语法
LL 解析器从识别高级产生式开始,然后将后续令牌与规则进行匹配。这是一个简化,但基本上我们的项目解析器会查找两种语句类型之一:
-
class classname : baseclasses { -
//[[QExport]] Keyhole_API datatype classname :: methodname ( datatype1 param1, ... datatypen paramn)
一旦解析器遇到第一个令牌(第 1 条产生式的 class,第 2 条产生式的 //[[QExport]]),解析器就知道匹配的产生式,因此知道接下来会是什么。
我们的项目语法是LL(1) 语法——解析器在任何时候都不需要查看超过 1 个令牌,即使我们将上面 2 条简化的高级产生式分解为更小的(子)产生式。此外,该解析器是一个LL(n) 的例子,它不需要回溯(处理一个以上可能性然后放弃任何不正确的),因此它是一个预测性解析器。
解析器实现通常是基于表的,但LL(n) 解析器也可以实现为递归下降解析器,使用“相互递归过程通常实现语法的一个产生式。因此,生成的程序结构密切反映了它所识别的语法”[1],这使得它们适合手工编码。
我们的解析器是一个手工编码的递归下降解析器。
LL(n) 解析器不能处理左递归;尝试解析以下语法的后果将是无限递归。
number = number | number digit
解析器会检查 LHS 的数字产生式是否与输入匹配,方法是检查它是否与 RHS 的产生式的第一个部分匹配——这意味着它会检查它是否是数字,……
语法可以进行左因子分解,以使其成为LL(n)。例如,以下语法
sum = number "+" number | number "-" number
不能被LL(1) 语法解析,而下面的语法可以。
sum = number ( "+" | "-" ) number
LALR 语法
LALR 解析器处理令牌并使用状态机来跟踪可能的产生式匹配。例如,考虑使用下面的语法解析字符流“1234.56”。
integer = [ sign ] { digit }
number = [ sign ] { digit } "." { digit } "E" digit [digit]
... other productions ...
对于前 4 位数字,解析器不知道哪个产生式可以应用于该流。解析状态是已处理令牌可能为整数或数字的状态。一旦遇到“.”,解析状态会更改为期望数字的状态。
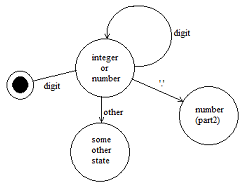
与LL 解析器不同,LALR 解析器“不知道接下来会是什么”;它们从“底部向上”构建表达式,而不是“顶部向下”。
状态机很复杂;LALR 解析器几乎总是由表驱动,并且通过将语法输入到 yacc 等工具来生成。
解析器操作
为了有用,解析器需要在特定点执行操作。特别是,以下产生式的完成会触发指定的操作(并非完整的描述)。
{ -> increase the tracked indent level.
} -> increase the tracked indent level.
class-decl -> remember the indent level.
Used to determine whether a function is a class method or not.
function_decl -> create new function_info object; update return type
declarator -> update the function_info with the classname, function name and
parameter info.
type_decl -> create, update and return new dtype_info
parameter -> create, update and return new parameter_info
实现
注意:我们的解析器实现不够优化。例如,更复杂的解析器通常会为令牌分配数值,这使得比较快速且易于进行表驱动的逻辑。项目实现使用少量令牌并经常进行字符串比较。该项目的目的不是生成最高效或理论上正确的解析器,而是演示它们在有用的软件开发工具中的用途。
XLL 生成器
XLL 是 DLL,它们将用户定义的函数公开给 Excel,就像它们是由 Excel 本身提供一样。
XLL 通常用 C 或 C++ 编写。它们提供了一种快速高效的方式将 C/C++ 代码与 Excel 对接。
XLL 代码的自动生成突出了底层库语言(C++)与客户端语言(xls)不匹配时出现的许多问题。
XLL 数据类型
下表显示了 XLL 中的数据类型。请注意,许多 C++ 数据类型具有双重用途。EXCEL 通过查看 xlAutoOpen 函数中执行的函数注册来确定如何解释参数。
| 数据类型 | 值 | 指针 |
|---|---|---|
| char | null 终止字符串。 | |
| unsigned char | 字节计数字符串。 | |
| short | 用于数值和布尔值 | 指向数值的指针。 |
| unsigned short | 数值 | 用于 null 终止和长度计数字符串。 |
| 长(整型) | 数值 | 指向数值的指针。 |
| double | 数值 | 指向数值的指针。 |
| XLOPER12 | 变体结构,用于管理内存。 |
元数据编译器支持的数据类型数量已经进一步减少。例如,没有 float 或独立的 bool 数据类型。
生成的 XLL 代码只能使用支持的元数据类型——这意味着它必须将 EXCEL 未使用的类型映射到使用的类型。float 被映射到 double,bool 被映射到 short。所有引用类型都被映射到等效的指针类型。
EXCEL API 广泛使用 XLOPER12 数据类型。XLOPER12 类似于 EXCEL 版本的 VARIANT,并由 XLL 用于管理内存。项目对 UDF(用户定义函数)应用以下规则:
-
输入参数被视为只读,因为它们的最终来源未知。
-
返回存储在静态内存中的数据是可以的——Excel 不会尝试删除它,但该函数将不是线程安全的。
-
如果为字符串或其他动态结构分配了内存,则必须在使用后释放。函数在 DLL 分配的
XLOPER12结构中返回(值),XLOPER12具有xlbitDLLFree位集。当 Excel 完成处理数据后,它将通过xlAutoFree12回调 XLL,通知 XLL 应删除数据。 -
如果 Excel 返回字符串或数组值(在 XLOPER12 中),则内存通过调用
Excel12(xlFree, 0, 1, &xloper12)来回收。
XLL 函数
导出的 XLL 函数与从包装库导出的函数非常相似。类型需要转换为 Excel 可用的类型,返回值被包装在 XLOPER12(s) 中,并且需要遵守内存管理规则,否则 XLL 函数的生成相对直接。例如,库函数
float calculate_sphere_volume(float radius);
被包装为 XLL 函数
XLOPER12* xl_calculate_sphere_volume(double radius);
处理对象
大型软件项目倾向于处理对象,而不是仅依赖函数。对象接口遵循 C/C++——类方法被替换为具有与它们所替换的方法相同签名的函数,除了 (i) 转换为 Excel 数据类型,(ii) 一个额外的、取 objectstr 的前导参数,以及 (iii) LPXLOPER12 的返回类型。例如,下面类中的方法
class A
{
public:
static A* create() { return new A; }
double R;
void put_R(double _R) { R = _R; }
double calc_circumference() { return 2*M_PI*R; }
};
在 XLL 中使用以下函数实现。
__declspec(dllexport) LPXLOPER12 A__create() { ... }
__declspec(dllexport) LPXLOPER12 A__put_R(objectstr str, double R) { ... }
__declspec(dllexport) LPXLOPER12 A__calc_circumference(objectstr str) { ... }
流程控制
传统的命令式语言按顺序执行源文件中列出的指令。例如,在下面的 C++ 程序中,执行从“编译单元”的顶部开始,并顺序向下进行。
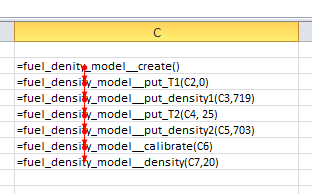
fuel_density_model* calc = fuel_density_model::create();
calc->put_T1(0.0);
calc->put_denisty2(719.0);
calc->put_T1(25.0);
calc->put_denisty2(703.0);
calc->calibrate();
double density = calc->density(20.0); // 25 Celsius
delete calc;
density)都返回对底层对象的引用,则代码可以这样编写: fuel_density_model* calc = fuel_density_model::create();
double denisty = (*calc).put_T1(0.0)
.put_denisty1(719.0)
.put_T1(25.0)
.put_denisty2(703.0)
.calibrate().
.density(20.0); // 20 Celsius
delete calc;
实现
实现对象方法的最佳方法是什么?
考虑下面图表中所示的一个简单的报表生成对象。
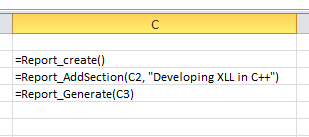
我们可能会倾向于像 C++ 一样,在后台创建一个报表对象的单个实例;然后 Report_AddSection 和 Report_Generate 会更新该实例。问题在于每个单元格都可能随时被重新计算。如果 Report_AddSection 被重新计算多次会发生什么?
这种方法需要对象方法是幂等的。即,多次调用方法与调用一次的效果相同。然而,不能要求被包装的库函数是幂等的。更糟的是,多次重新计算导致的任何错误很可能不被注意。正是出于这个原因,这种方法是行不通的。
隐藏名称
有一种使用函数式编程技术的替代方法。对象创建后,永不修改。像 fuel_density_model__put_T1 这样的方法会创建原始对象的另一个副本,并更新 T1 属性。由于任何单元格重新计算的起点始终相同(对象的先前实例),因此单元格的重新计算不会改变其值。
对象在不同状态下的多个副本显然会产生内存使用方面的开销。
我们如何将对象附加到单元格?一种可能的方案是将内存中的对象存储在哈希表中,并将哈希键存储为单元格文本。然而,更标准的方法是为包含对象的每个单元格编程命名,并将对象以序列化的形式存储,以名称作为“大数据”;名称和大数据在工作簿保存时自动存储,并在工作簿打开时自动加载。通过 C API 添加的名称是隐藏的,不会出现在(并污染)正常的名称对话框中。名称也提供一些防止剪切-粘贴等操作的保护。
持久化
如果关闭然后重新打开工作簿,则需要重新创建底层对象网络。即,电子表格对象需要是持久的。
XLL 代码生成器不负责为被包装的库提供持久性服务。这项任务过于侵入性和复杂;持久性代码经常访问私有数据成员,并且必须就持久性应该有多“深”做出判断。持久性必须内置到底层库中,如下所示。
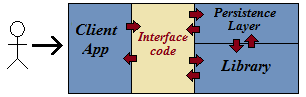
话虽如此,原始 XLL 生成器解析器已被修改,可用于驱动持久性代码生成(不推荐)。两个解析器服务于不同的目的,并且确实应该分开。持久性代码生成器使用伪属性,如 XLL 生成器一样,并且被 'CarbyCalcLib' 项目使用。请注意,它仅支持值类型(非引用)数据成员的序列化。
XLL 支持代码假定对于任何类 A,都存在以下持久性函数:
A* A__load(const unsigned char* buffer, size_t size);
persistence_provider_type* get_persistence_provider__A(A& obj);
项目
项目代码组织成多个目录和解决方案。
-
include、lib 和 bin 目录包含项目之间共享的头文件、库和可执行文件。
-
CarbyCalcLib 解决方案包含 3 个子项目。
- 'CarbyCalcLib'——一个用于计算空气密度和其他用于调整化油器数量的简单 DLL。
- 'Simple_Persistence_Provider'——一个简单的持久性提供者可执行文件,它根据方法属性生成序列化代码。Simple Persistence Provider 为 CarbyCalcLib 提供序列化代码。
- 'Simple_Persistence_Test'——简单的持久性提供者的测试代码。
-
元数据工具包解决方案包含 2 个子项目。
- 元数据编译器——通过读取库源代码生成元数据的解析器。
- API 报告创建一个基于文本的元数据报告,并用于确认解析器生成了对输入文件中描述对象的忠实表示。
- 'XLL_Generator'生成器解决方案包含 3 个子项目。
- 'XLL_Generator'项目——一个可执行文件,它根据输入文件中定义的属性和类定义生成 XLL 代码来包装 DLL。使用 'Metadata_toolkit' 库。
- 'XLL_support'项目——由生成的 XLL 代码调用的支持函数。
- 'XLL_Generator_Test'——一个简单的测试 XLL,用于计算圆的周长。
-
'CarbyCalcLib_XLL'生成器解决方案只包含 1 个项目。'CarbyCalcLib_XLL'项目为从 'CarbyCalcLib.dll' 导出的函数和对象提供了 XLL 包装器。该项目只包含 5 个可编辑文件:
- CarbCalcLib_XLL.h——一个通用头文件。
- dllmain.cpp——包含标准的 XLL 入口点。
- air_fuel_wrapper.cpp——#includes 生成的代码。
- air_fuel_iface_defn.h, air_fuel_iface_defn.h——用作 XLL 生成的输入。
鼓励读者浏览 'CarbyCalcLib_XLL' 项目中的源代码文件,以了解包装 DLL 所需的工作量。
原始 'CarbyCalcLib' 项目中的头文件本可以用来驱动 XLL 生成器。文件 air_fuel_wrapper.h 和 air_fuel_wrapper.cpp 只包含驱动生成器所需的类和方法定义;实际上,'CarbyCalcLib' 头文件甚至不包含 //[[QExport]] 属性;'CarbyCalcLib' 库完全“不知道”它被包装了。
必备组件
此项目需要:
- EXCEL XLL SDK (2007+)。
- KB 2459118 中描述的热修复。
这些项目是使用 Visual Studio Community 2013 和 EXCEL 2013 XLL SDK 开发的。
VC++ 目录
您需要为每个项目设置 Include、Library 和 Executable VC++ 目录。它们应包括共享的 include、lib 和 bin 目录,以及相关的 EXCEL SDK 目录。
关注点
EXCEL SDK 框架
该项目不使用 2007 EXCEL SDK 附带的框架,因为内存池会占用内存并且不会释放。它会生成以下特征性的内存“泄漏”消息。(因为它是有意为之,所以并非真正的泄漏)。
Detected memory leaks!
Dumping objects ->
{88} normal block at 0x04D750E8, 10240 bytes long.
Data: < > CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD
{87} normal block at 0x04D728A8, 10240 bytes long.
Data: < > CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD
{86} normal block at 0x04D70068, 10240 bytes long.
Data: < > CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD
{85} normal block at 0x03FFC008, 10240 bytes long.
Data: < > 18 C0 FF 03 CD CD CD CD 02 00 CD CD CD CD CD CD
{84} normal block at 0x03FF2EC8, 52 bytes long.
Data: < x > 04 00 00 00 78 11 00 00 08 C0 FF 03 00 00 00 00
{83} normal block at 0x03FF2E80, 12 bytes long.
Data: < . > 01 00 00 00 04 00 00 00 CC 2E FF 03
Object dump complete.
导出 C 函数
导出的 C 函数声明为 extern "C" 并以宏 Keyhole_API 为前缀,该宏展开为 __declspec(dllexport)。阅读文档,人们可能会认为这足以确保导出的函数具有与源代码中声明的相同的名称。并非如此。下面的函数 foo 以名称 _foo@8 导出(8 是参数在堆栈上使用的字节数)。如果希望函数 foo 以其自身的名称导出,则需要一个 .def 文件。
#define Keyhole_API __declspec(dllexport) extern "C" short foo(double x);
UTF8
我喜欢在源代码中使用希腊符号。我发现

比...更具可读性
Pressure = density*R*Temperature
非 ASCII 源代码是 C++ 标准允许的,并且编译器部分支持。
有多种表示非 ASCII 符号的方法,从使用 128-255 值范围的代码页到 Unicode 编码,如 UTF8、UCS-2、UTF16、UTF16BE、UTF16LE、UTF32。似乎 UTF8 是最明智的选择,并且(截至 2015 年)它的使用正开始超越其竞争对手。
代码生成器经过工程设计,能够处理包含 ASCII 和希腊字符的 UTF8 源文件,但这会带来一些潜在的不稳定性。它不接受任何其他非 ASCII 字符。之所以做出妥协:正如我所说,我喜欢希腊符号,而 Unicode 是一个雷区。
项目代码遵循 utf8everywhere.org 的建议。
我无法让 C++ 预处理器或链接器与 2013 Community MSVC 的 UTF8 一起工作。这意味着希腊符号可以在被包装的代码中使用,但不能在导出函数、方法或类的名称中使用。
通过钥匙孔
本文不仅仅是关于编写 XLL;还有更多 C++ 元数据驱动工具的示例。作者多年前在一个大型投资银行遇到了一个有趣的例子。该工具生成了一个 Quant(定价)库的包装器,该包装器阻止了对导出函数的直接访问。库只有一个入口点,类似于 VB 的 IDispatch::Invoke,并被称为钥匙孔。
为什么要这样做?Quant 库导出的函数和方法在每个版本之间都会改变,而且变化相对不受控制。(银行太大了,不可能“控制”库的开发)如果应用程序代码直接链接到 Quant 库中的函数/方法,那么应用程序在链接新版本时很可能失败,从而造成很大的麻烦。单一入口点意味着库始终可以链接,即使少量调用失败,应用程序也可以构建。
请注意,我并不一定推荐这种方法。它存在几个问题:(i) 缺失/更改的函数/方法问题并未真正通过此方法解决,只是最小化了;(ii) 代码的复杂性使得调试成为一场噩梦;(iii) 性能下降明显。
注意事项
项目中的代码均未经过商业级别的测试或审查。 许多功能缺失,包括:
- 代码生成器不可配置。没有配置文件,命令行选项很少。
- C++ 预处理器写入磁盘。通过写入内存流可以实现显著的速度提升。预处理器逻辑在当前代码版本中已被禁用,但支持预处理的代码存在于代码库中。
- EXCEL 不便于捕获所有必需的事件来完全支持用户定义的对象方法。XLL 支持代码需要进一步工作。如果您剪切-粘贴单元格、在工作表之间跳转等,您无疑会混淆支持代码并生成错误。
- 没有直接支持使用向量和数组的 UDF 函数。
- 对非 ASCII 字符的支持非常有限。对 UTF8 的完全支持可能需要使用第三方库。
- 错误处理非常基础,警告生成也是如此。
- 缺少额外的“流程控制”和函数式编程构造,如 map/reduce。
- 一个用于显示单元格内容的“对象查看器”将很受欢迎。
请向我报告主要错误,而不是给我差评。如果 XLL 生成器有足够的兴趣,我将把最新代码移到一个存储库,甚至可能编写一些正式的文档或另一篇文章!如果您希望进一步开发代码,请随时这样做或与我联系。
注释
接口代码的自动生成是跨多种语言和环境提供库代码功能的首选方法。该方法确保代码质量均匀并提高生产力。没有元数据驱动的代码生成器,这一切都无法实现。
C++ 缺乏其他语言中的反射能力。即使解析器是有趣且功能强大的工具,我也期待 C++ 能够拥有标准且强大的内置元数据功能,这样对于许多任务来说,解析器将不再是必需的。
参考文献
1. Burge, W.H. (1975). Recursive Programming Techniques. ISBN 0-201-14450-6.