
使用 C# 进行 Web Scraping
4.91/5 (142投票s)
如何使用 C# 从网站上抓取数据。
引言
本文是四部分系列文章的第一部分。
- 第一部分 - 如何使用 C# 进行网页抓取 (本文)
- 第二部分 - 使用 .NET 进行网页爬虫 - 概念
- 第三部分 - 使用 C# 进行网页抓取 - 点点抓取!
- 第四部分 - 使用 .NET 进行网页爬虫 - 示例代码 (待续)
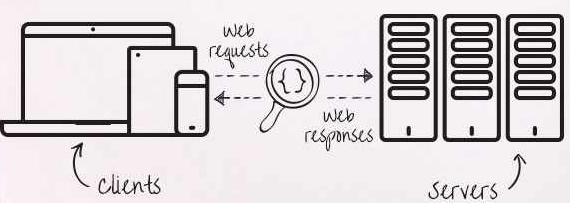
当我们考虑不同的数据来源时,我们通常会想到以 SQL、Web 服务、CSV 等格式呈现给我们的结构化或半结构化数据。然而,有大量的宝贵数据并非以这些易于解析的格式提供,其中许多数据存在于网站上。然而,网站上的数据问题在于,通常情况下,数据并没有以易于获取的方式呈现。通常,它们被混合并融合在 CSS 和 HTML 中。网页抓取的工作是深入底层,使用代码自动化从网站提取数据,以便我们可以将其转换为可用的格式。

网页抓取出于各种原因进行,但主要是因为数据无法通过更简单的方式获得。例如,从事价格和产品比较业务的公司大量使用网页抓取。这些公司通过为将客户导向特定网站收取少量推荐费来获利。在浩瀚的互联网世界中,如果操作得当,少量推荐费可以迅速累积成可观的利润。
网站的构建方式多种多样,有些非常简单,有些则是复杂的动态巨兽。网页抓取与其他事物一样,既是技能,也是调查。我参与过的一些抓取项目非常棘手,它们结合了本文将涵盖的基础知识,以及我们将在后续文章中介绍的高级“单页应用程序”数据采集技术。我完成的其他项目几乎只使用了此处讨论的技术,因此如果您以前从未进行过抓取,本文是一个不错的起点。从网站抓取数据的原因有很多,但无论原因如何,作为程序员,我们可能会被要求这样做,所以值得学习。让我们开始吧。
背景
例如,如果我们想获取欧盟国家列表,并且有一个国家数据库,我们可以像这样获取数据
'select CountryName from CountryList where Region = "EU"
但这假设您手头有一个国家列表。
另一种方法是访问一个列出了国家名称的网站,导航到包含欧洲国家列表的页面,然后从那里获取列表 - 这就是网页抓取发挥作用的地方。网页抓取是编写结合 HTTP 调用和 HTML 解析的代码的过程,以提取有意义的 (ref) 内容,从,嗯,乱码中!
网页抓取帮助我们将这个
<tbody> <tr> <td>AJSON </td><td> <a href="/home/detail/1"> view </a> </td></tr><tr>
<td>Fred </td><td> <a href="/home/detail/2"> view </a> </td></tr><tr> <td>Mary </td>
<td> <a href="/home/detail/3"> view </a> </td></tr><tr> <td>Mahabir </td>
<td> <a href="/home/detail/4"> view </a> </td></tr><tr> <td>Rajeet </td>
<td> <a href="/home/detail/5"> view </a> </td></tr><tr> <td>Philippe </td>
<td> <a href="/home/detail/6"> view </a> </td></tr><tr> <td>Anna </td>
<td> <a href="/home/detail/7"> view </a> </td></tr><tr> <td>Paulette </td>
<td> <a href="/home/detail/8"> view </a> </td></tr><tr> <td>Jean </td>
<td> <a href="/home/detail/9"> view </a> </td></tr><tr> <td>Zakary </td>
<td> <a href="/home/detail/10"> view </a> </td></tr><tr> <td>Edmund </td>
<td> <a href="/home/detail/11"> view </a> </td></tr><tr> <td>Oliver </td>
<td> <a href="/home/detail/12"> view </a> </td></tr><tr> <td>Sigfreid </td>
<td> <a href="/home/detail/13"> view </a> </td></tr></tbody>
变成这样
- AJSON
- Fred
- Mary
- Mahabir
- Rajeet
- Philippe
- 等等。
现在,在我们继续之前,重要的是要注意,您应该只在获得许可或开放访问等允许的情况下抓取数据。请务必阅读任何条款和条件,并绝对遵守适用于您的任何相关法律。孩子们,让我们小心点!
当您设计一个网站时,您拥有代码,您知道连接到哪些数据源,您知道事物是如何组合在一起的。但是,当您抓取一个网站时,您通常会抓取一个您不太了解的网站,因此需要经历一个涉及以下过程的步骤:
- 调查/发现
- 流程图
- 逆向工程
- HTML/数据解析
- 脚本自动化
一旦您理解了它,网页抓取就是一项非常有用的技能,可以添加到您的工具包和简历中 - 所以让我们开始吧。
网页抓取工具
有许多工具可用于网页抓取。在本文中,我们将重点介绍两个工具 - 用于逆向工程我们要提取数据的网站/页面的“Fiddler”,以及用于访问数据本身的非常出色的开源“Scrapy sharp”库。当然,您也会发现您喜欢的浏览器中的开发人员工具在这种情况下也非常有用。
Scrapy Sharp
Scrapy Sharp 是一个开源抓取框架,它结合了一个能够模拟网页浏览器的 Web 客户端,以及一个 HtmlAgilityPack 扩展,可以使用 CSS 选择器(如 JQuery)来选择元素。Scrapysharp 大大减轻了抓取网页通常涉及的工作量、前期痛苦和设置。通过模拟浏览器,它负责 cookie 跟踪、重定向以及使用浏览器从服务器资源获取数据时预期的常规高级功能。ScrapySharp 的强大之处不仅在于其浏览器模拟能力,还在于它与 HTMLAgilitypack 的集成 - 这使得我们可以像在浏览器内的 DOM 上使用 JQuery 一样轻松地访问下载的 HTML 中的数据。
Fiddler
Fiddler 是一个位于本地计算机上的开发代理,它会拦截您浏览器发出的所有请求,并使您能够对其进行分析。
Fiddler 不仅有助于逆向工程 Web 流量以执行网页抓取,还有助于 Web 会话操作、安全测试、性能测试以及流量记录和分析。Fiddler 是一个功能极其强大的工具,不仅在逆向工程方面,而且在解决抓取工作中的问题方面,都能为您节省大量时间。请在此处下载并安装 Fiddler,然后按“F12”切换拦截模式。我们将逐步介绍 Fiddler,了解基础知识,以便我们可以开始工作。
以下屏幕截图显示了我们感兴趣的主要区域

- 左侧显示了 Fiddler 捕获的任何流量。这包括您的主网页以及用于下载图片、支持的 CSS/JS 文件、心跳保持连接等的所有线程。顺便说一句,只需运行 Fiddler 一小段时间,看看您的计算机上有什么正在发送 HTTP 流量,这会非常有趣(也非常有启发性!)
- 当您在左侧选择一个流量源/项目时,您可以在右侧的不同面板中查看该项目的详细信息。
- 我最常使用的面板是“
Inspectors”区域,我可以在其中查看发送到服务器和从服务器传输的内容。 - 过滤器区域允许您过滤掉 HTTP 传输中的大量“噪音”。例如,在这里,您可以告诉 Fiddler 仅过滤并显示来自特定 URL 的流量。
举例来说,这里我同时打开了 Bing 和 Google,但由于我对 Bing 设置了过滤器,因此只显示了 Bing 的流量。

这里是设置过滤器

在我们继续之前,让我们检查一下检查器区域 - 这是我们将检查流量详细信息的地方,并确保我们可以在需要执行抓取本身时镜像并重放正在发生的事情。
检查器部分分为两部分。上半部分提供了有关正在发送的请求的信息。在这里,我们检查请求标头、正在发布的任何表单数据、cookie、JSON/XML 数据以及当然还有原始内容。下半部分列出了与服务器响应相关的信息。这可能包括网页本身的多种不同视图(如果这是返回的内容)、cookie、身份验证标头、JSON/XML 数据等。

安装
为了以受控的方式呈现本文,我创建了一个简单的 MVC 服务器项目,我们可以用它作为抓取的依据。设置如下:
名为 SampleData 的类存储了一些我们可以用来抓取数据的简单数据。它包含一个人员列表和一个国家列表,两者之间有一个简单的链接。
public class PersonData
{
public int ID { get; set; }
public string PersonName { get; set; }
public int Nationality { get; set; }
public PersonData(int id, int nationality, string Name)
{
ID = id;
PersonName = Name;
Nationality = nationality;
}
}
public class Country
{
public int ID { get; set; }
public string CountryName { get; set; }
public Country(int id, string Name)
{
ID = id;
CountryName = Name;
}
}
然后在构造函数中添加了 Data
public class SampleData
{
public List<country> Countries;
public List<persondata> People;
public SampleData()
{
Countries = new List<country>();
People = new List<persondata>();
Countries.Add(new Country ( 1, "United Kingdom" ));
Countries.Add(new Country ( 2, "United States" ));
Countries.Add(new Country(3, "Republic of Ireland"));
Countries.Add(new Country(4, "India"));
..etc..
People.Add(new PersonData(1, 1,"AJSON"));
People.Add(new PersonData(2, 2, "Fred"));
People.Add(new PersonData(3, 2, "Mary"));
..etc..
}
}
我们设置了一个控制器来提供数据
public ActionResult FormData()
{
return Redirect("/home/index");
}
以及一个页面视图以呈现给用户
@model SampleServer.Models.SampleData
<table border="1" id="PersonTable">
<thead>
<tr>
<th>
<pre lang="html">
Persons name</pre>
</th>
<th>
<pre>
View detail</pre>
</th>
</tr>
</thead>
<tbody>
@foreach (var person in @Model.People)
{
<tr>
<td>
@person.PersonName
</td>
<td>
<pre>
<a href="/home/detail/@person.ID">view </a>
</td>
</tr>
}
</tbody>
</table>
我们还创建了一个简单的表单,我们可以用它来测试发布。
<form action="/home/FormData" id="dataForm" method="post"><label>Username</label>
<input id="UserName" name="UserName" value="" />
<label>Gender</label> <select id="Gender" name="Gender">
<option value="M">Male</option><option value="F">Female</option></select>
<button type="submit">Submit</button></form>
最后,为了完成我们的设置,我们将构建两个控制器/视图页面对
- 以接受数据发布并指示表单数据发布成功,以及
- 一个控制器来处理详情页面视图
控制器
public ActionResult ViewDetail(int id)
{
SampleData SD = new SampleData();
SD.SetSelected(id);
return View(SD);
}
public ActionResult FormData()
{
var FD = Request.Form;
ViewBag.Name = FD.GetValues("UserName").First();
ViewBag.Gender = FD.GetValues("Gender").First();
return View("~/Views/Home/PostSuccess.cshtml");
}
视图
Success! .. data received successfully.
@ViewBag.Name
@ViewBag.Gender
@model SampleServer.Models.SampleData
<label>Selected person: @Model.SelectedName</label>
<label>Country:
<select>
@foreach (var Country in Model.Countries)
{
if (Country.ID == Model.SelectedCountryID)
{<option selected="selected" value="@Country.ID">@Country.CountryName</option>
}
else
{<option value="@Country.ID">@Country.CountryName</option>
}
}
</select></label>
运行我们的服务器,现在我们有了一些基本的抓取和测试数据。

网页抓取基础
在本文前面,我提到抓取是一个多阶段的过程。除非您正在进行简单的抓取(就像我们将在此处看到的示例一样),否则通常您会经历一个调查网站呈现的内容/发现其中有什么并将其映射出来的系统。这就是 Fiddler 发挥作用的地方。
打开浏览器,让 Fiddler 拦截您要抓取的网站的流量,您在该网站上浏览,让 Fiddler 捕获流量和工作流程。然后,您可以保存 Fiddler 数据,并将其用作工作流程,您可以根据此流程对您的抓取工作进行逆向工程,将您知道在浏览器中有效的内容与您尝试在抓取代码中生效的内容进行比较。当您运行您的抓取代码和您保存的浏览器 Fiddler 会话时,您可以轻松地发现差距,了解发生了什么,并逻辑地构建您自己的自动化代码脚本。
抓取很少像指向一个页面并下载数据那样容易。通常,数据会以特定方式分散在网站上,您需要分析用户与网站交互的工作流程来进行逆向工程。您会发现在表格、下拉列表和 div 中找到数据。您同样会发现数据可能是间接加载的,而不是通过服务器端页面渲染,而是通过 Ajax 调用或其他 JavaScript 方法加载的。所有这些时候,Fiddler 都是您的朋友,可以监控浏览器中发生的情况与后台发生的网络流量。我经常发现,对于复杂的抓取,构建一个流程图来显示如何围绕网站的不同数据进行移动非常有用。
在分析和尝试在您的网页抓取中复制一个过程时,请注意网站用于管理状态的非显性因素。例如,会话状态和用户在网站内的位置通常由服务器端维护。在这种情况下,您不能随意从页面跳转到页面抓取数据,而必须遵循网站希望您“行走”的“面包屑”路径,因为您执行操作的顺序和调用的页面最有可能触发服务器端的内容。关于这一点的最后一个想法是,您应该检查您收到的页面数据是否符合您的预期。我的意思是,如果您从一个页面导航到另一个页面,您应该留意页面上的一些独特之处,您可以尝试依赖它来确认您所在的页面是您请求的页面。这可能是一个页面标题、一段特定的 CSS、一个选中的菜单项等。我发现,在抓取过程中,意想不到的事情可能会发生,当您面对原始 HTML 进行筛选时,找到问题所在可能会非常繁琐。
在网页抓取方面提高效率最重要的事情是将任务分解成小的、易于重现的步骤,并遵循您在 Fiddler 中构建的模式。
网页抓取客户端
对于本文,我创建了一个简单的控制台项目,它将充当抓取客户端。第一件事是使用 nuGet 添加 ScrapySharp 库,并链接到我们入门所需的命名空间。
PM> Install-Package ScrapySharp using ScrapySharp.Network;
using HtmlAgilityPack;
using ScrapySharp.Extensions;
为了使事情顺利进行,请运行我们将用作抓取实验对象的 MVC 示例服务器。就我而言,它运行在“Localhost:51621”上。如果我们在浏览器中加载服务器并查看源代码,我们将看到页面标题具有唯一的类名。我们可以利用这一点来抓取值。让我们将其作为我们的“网页抓取世界的你好...”。

在我们的控制台中,我们创建一个 ScrapingBrowser 对象(我们的虚拟浏览器)并设置所需的任何默认值。这可能包括允许(或不允许)自动重定向、设置浏览器代理名称、允许 cookie 等。
ScrapingBrowser Browser = new ScrapingBrowser();
Browser.AllowAutoRedirect = true; // Browser has settings you can access in setup
Browser.AllowMetaRedirect = true;
下一步是告诉浏览器加载一个页面,然后,利用 CssSelect 的魔力,我们进入并选择我们唯一的页面标题。正如我们的调查所示,标题有一个唯一的类名,我们可以使用类选择器表示法“.NAME”来导航并获取值。我们对项目的初始访问通常使用 HTMLNode 或 HTMLNode 集合。我们通过检查返回节点的 InnerText 来获取实际值。
WebPage PageResult = Browser.NavigateToPage(new Uri("https://:51621/"));
HtmlNode TitleNode = PageResult.Html.CssSelect(".navbar-brand").First();
string PageTitle = TitleNode.InnerText;
然后,它就在那里...

接下来,我们将抓取项目集合,在本例中是表格中的姓名。为此,我们将创建一个 string 列表来捕获数据,并查询我们的页面结果以查找特定节点。在这里,我们正在寻找 ID 为“PersonTable”的表格的顶层。然后,我们遍历其子节点,在路径“/tbody/tr”下查找“TD”的集合。我们只想要包含个人姓名的第一个单元格数据,所以我们使用 [1] 索引参数来引用它。
List<string> Names = new List<string>();
var Table = PageResult.Html.CssSelect("#PersonTable").First();
foreach (var row in Table.SelectNodes("tbody/tr"))
{
foreach (var cell in row.SelectNodes("td[1]"))
{
Names.Add(cell.InnerText);
}
}
以及预期的输出结果
AJSON
Fred
Mary
Mahabir
Rajeet
Philippe...etc...
目前我们要做的最后一件事是捕获并发送一个表单。正如您现在可能预期的那样,技巧是导航到您想要的表单并对其进行一些操作。
要使用表单,我们需要添加一个命名空间
using ScrapySharp.Html.Forms;
虽然在大多数情况下,您只需查看 HTML 源即可找到表单字段名称等,但在某些情况下,由于混淆或 JavaScript 拦截,您会发现查看 Fiddler 以了解正在发送的名称和值非常有用,这样您在发布数据时就可以进行模拟。
在此 Fiddler 屏幕截图中,我们可以看到请求中发送的表单数据,以及服务器发送回的响应。

定位表单、填充字段数据并提交的代码非常简单
// find a form and send back data
PageWebForm form = PageResult.FindFormById("dataForm");
// assign values to the form fields
form["UserName"] = "AJSON";
form["Gender"] = "M";
form.Method = HttpVerb.Post;
WebPage resultsPage = form.Submit();
提交表单数据时需要注意的关键点是
- 确保您发送回的表单字段与您在 Fiddler 中捕获的*完全*相同,并且
- 确保检查响应值(如上面的
resultsPage),以确保服务器已成功接受您的数据。
从网站下载二进制文件
获取和保存 PDF 等二进制文件非常简单。我们指向 URL 并抓取“原始”响应正文中发送给我们的流。这是一个示例(其中 SaveFolder 和 文件名称 之前已设置)
WebPage PDFResponse = Browser.NavigateToPage(new Uri("MyWebsite.com/SomePDFFileName.pdf"));
File.WriteAllBytes(SaveFolder + FileName, PDFResponse.RawResponse.Body);
2016 年 5 月 - 关于网页抓取和法律的更新
最近我参加了一个法律讲座,了解到一起非常有趣且相关的网页抓取法律案件。Ryanair 是欧洲(截至 2016 年)最大或最(如果不是最大)的廉价航空公司之一。该航空公司最近对多家机票比价公司/网站提起了法律诉讼,声称它们非法抓取 Ryanair 网站上的价格数据。案件中有许多不同的方面,在法律上技术性很强,如果您喜欢这类东西(尽管来吧!),阅读一下是值得的。然而,底线是,一项判决认为 Ryanair 可以对网页抓取者提起诉讼,*因为他们违反了他们的条款和条件*。Ryanair 的条款和条件明确禁止“使用自动化系统或软件为商业目的提取网站数据,除非 Ryanair 同意该活动”。该案的一个有趣方面是,为了实际查看定价信息,网站用户必须隐式同意 Ryanair 的条款和条件 - 这是一个网页抓取器显然通过编程方式完成的事情,从而助长了法律上的争论。这意味着现在有了具体的判例法(至少在欧洲),允许网站使用条款和条件中的条款来合法阻止抓取器。这具有重大的影响,其影响尚待确定 - 因此,一如既往,如有疑问,请咨询您的法律专家!
更多相关阅读
总结
基本内容就讲到这里。更多内容即将推出,敬请关注。
如果您喜欢这篇文章,请在上方投票!
历史
- 版本 1 - 2015 年 10 月 20 日
- 版本 2 - 2015 年 12 月 10 日 - 添加了文件下载代码
- 版本 3 - 2016 年 3 月 26 日 - 添加了相关文章链接
- 版本 4 - 2016 年 5 月 10 日 - 添加了关于网页抓取法律影响和新判例法的更新