
MongoDB 教程 - 第 3 天(性能 - 索引)
MongoDB中的性能 - 索引
引言
欢迎来到 MongoDB 教程的第三天。这是 MongoDB 教程系列的第三部分。在这一部分,我们将探讨性能的各个方面。性能始终是任何数据库的重要组成部分。在任何数据库中,无论是关系型数据库还是 NoSQL 数据库,我们总是考虑如何提高查询响应时间,因为数据库的性能始终是应用程序整体性能的关键部分。当我们谈论性能时,索引总是排在首位。在本文中,我们将涵盖 MongoDB 中不同类型的索引。
背景
在阅读本文之前,最好先回顾一下本文的前两部分(第一天和第二天)。
到目前为止,我们已涵盖:
- NoSQL 简介(NoSQL 下的不同数据库类型)
- 如何在您的计算机上安装和设置 MongoDB。
- Robomongo 简介(MongoDB 开源管理工具)
- MongoDB 术语
- 如何在 MongoDB 中插入文档
- 如何在 MongoDB 中选择文档
Where子句,大于和小于Like,逻辑AND和逻辑OR- MongoDB 中的
in操作符,MongoDB 中的Count和Sort记录 - MongoDB 中的
Update、Delete、Remove和Drop - MongoDB 中的
Top、Distinct和Backup - 无模式行为
$exists、$in、$all、$nin- MongoDB 中的数据类型
- 嵌入式文档和点符号
我将涵盖的内容
索引
我们可以将索引想象成书的目录。假设我们在书中查找一个主题,而没有目录,那么我们需要浏览每一页,直到找到该页。如果您的书有 100 页,那么您可以应付(如果您有足够的时间),但假设您的书有 100 万页,那么通过翻阅每一页来搜索主题将是一项非常繁琐的工作。MongoDB 中也有相同的概念。
如果没有索引,MongoDB 将执行完整的集合扫描来选择匹配 query 语句的文档。如果集合中的文档数量很高,那么这将是性能的致命打击。
假设我们在 Names 集合中有如下文档:
db.Names.insert({"Name":"Ajay"})
db.Names.insert({"Name":"Manoj"})
db.Names.insert({"Name":"Preeti"})
db.Names.insert({"Name":"Anuj"})
db.Names.insert({"Name":"Tony"})
db.Names.insert({"Name":"Steve"})
db.Names.insert({"Name":"Smith"})
db.Names.insert({"Name":"David"})
db.Names.insert({"Name":"William"})

Names 集合中的文档将以任意顺序存储。如果没有 Index,如果我们查找如下文档,则会进行完整的集合扫描,这将降低性能。
db.Names.find({"Name":"Smith"})
如果我们想了解 MongoDB 如何处理上述查询,只需像这样使用 explain():

这里有几点需要注意:
cursor : BasicCursor:这意味着 MongoDB 将执行完整的集合扫描。nscannedObjects:MongoDB 扫描了九个对象来匹配此查询。
那么现在问题出现了:
什么是索引:Index 是一个有序的项目集合。Index 以特定顺序存储值。
默认索引
当我们创建 MongoDB 中的集合时,MongoDB 会自动在 _id 字段上创建 唯一索引。由于它是一个 唯一索引,因此可以防止我们在 _id 字段中输入重复值。我们无法在 MongoDB 中删除此 索引。
如何创建索引
要在 MongoDB 中创建 索引,我们有两种方法:
createIndex():createIndex()方法的语法是:db.CollectionName.createIndex({"Key":1 or -1})1表示升序,-1表示降序。因此,如果我们想在Names集合中的 Name 键上创建索引,我们将创建如下索引:db.Names.createIndex({"Name":1})ensureIndex():ensureIndex()方法的语法是:db.CollectionName.ensureIndex({"key": 1 or -1})ensureIndex()方法自 3.0.0 版本起已弃用。此方法是createIndex()的别名。
MongoDB 中不同类型的索引
1. 单字段索引
除了 MongoDB 创建的 _id 字段上的默认索引外,用户还可以为单个字段创建升序或降序索引。
我们创建单键索引如下:
db.Names.createIndex({"Name":1})
现在,只需运行 explain():

哦,哇!现在我们有一个定义的索引(BtreeCursor Name_1),而不是 Basic Cursor,最重要的是,看看 nscannedObjects,它现在是 1,这意味着 MongoDB 只扫描了我们在查询中提到的 1 个文档。
假设我们有一个名为 users 的另一个集合,其中包含以下文档:
db.Users.insert({"Name":"Ajay","Age":30})
db.Users.insert({"Name":"Manoj","Age":60})
db.Users.insert({"Name":"Preeti","Age":20})
db.Users.insert({"Name":"Anuj","Age":70})
db.Users.insert({"Name":"Tony","Age":25})
db.Users.insert({"Name":"Steve","Age":18})
db.Users.insert({"Name":"Smith","Age":33})
db.Users.insert({"Name":"David","Age":53})
db.Users.insert({"Name":"William","Age":65})
现在,假设我们想找出所有 Age 大于 30 且小于 60 的文档。

所以我们有 BasicCursor, 因此这将是完整的表扫描,查询扫描的总文档数为 9。现在我在 Age 上定义一个索引:
db.Users.createIndex({"Age":1})
现在再次运行查询,该查询将找出所有 Age 大于 30 且小于 60 的文档。

在 Index 之后,MongoDB 将不再进行完整的表扫描,它只会扫描 4 行。

2. 复合索引
有时,我们希望根据 Name 和 Age 进行搜索。在这种情况下,我们必须同时在 Name 和 Age 上应用 index,这将被称为复合索引。
语法:db.CollectionName({"Key1":1 or -1,"Key2": 1 or -1,"KeyN":1 or -1})
我们将同时在 Users 集合的 Name 和 Age 上创建 Index,如下所示:
db.Users.createIndex({"Name":1,"Age":-1})
注意:复合索引仅在搜索 Name 或 Name 和 Age 时才有效。如果我们仅通过 Age 进行搜索,则复合索引将不起作用。
假设我们通过 Name 进行搜索,那么我们可以看到复合索引正在使用。

如果我们通过 Name 和 Age 进行搜索,那么我们可以再次看到复合索引正在使用。

但如果仅搜索 Age,那么我们可以看到复合索引未在使用中。
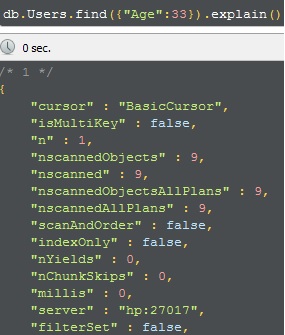
在这种情况下,没有使用 Index。
3. 多键索引
从 Users 集合中删除现有文档,并插入一些带有 interest 的文档,如下所示:
db.Users.remove({})
db.Users.insert({"Name":"Ajay","Age":30,Interest : ["cricket","music"] })
db.Users.insert({"Name":"Manoj","Age":60,Interest : ["cricket","driving"]})
db.Users.insert({"Name":"Preeti","Age":20,Interest : ["music","driving"]})
db.Users.insert({"Name":"Anuj","Age":70,Interest : ["cooking","music"]})
db.Users.insert({"Name":"Tony","Age":25,Interest : ["swimming","cooking"]})
db.Users.insert({"Name":"Steve","Age":18,Interest : ["dancing","music"]})
db.Users.insert({"Name":"Smith","Age":33,Interest : ["tennis","tv"]})
db.Users.insert({"Name":"David","Age":53,Interest : ["music","swimming"]})
db.Users.insert({"Name":"William","Age":65,Interest : ["dancing","swimming"]})
现在,如果我们想对数组(在我这里是 Interest)的内容进行 Index,那么我们将使用 Multikey Index。
语法:db.CollectionName.createIndex({"Array": 1 or -1})
我们将创建如下的 MultiKey Index 在 Interest 中:
db.Users.createIndex({Interest : 1})
4. 文本索引
如果我们正在执行文本搜索,那么为了获得更好的性能,我们可以对字符串内容应用 Text Index。
我们只能在字符串字段上创建文本索引。
语法:db.CollectionName.createIndex({Field Name:"text"})
假设我们想在 Name 字段上创建 Index,那么我们将创建如下的 text index:
db.Users.createIndex({Name : "text"})
注意:一个集合最多可以有一个 text index。
除了这些索引之外,MongoDB 还支持其他一些索引,包括 Geospatial 和 Hashed 索引。
Geospatial 索引用于对地理空间坐标数据进行更有效的查询,而 Hashed Index 对字段值的哈希进行索引。
MongoDB 索引属性
1. Unique (唯一)
index 字段上的 unique 属性允许 MongoDB 不接受索引字段的重复值。换句话说,unique 属性将阻止对 Index 字段插入重复值。
我在 Users 集合中添加了另一个名为 "SSN" 的列,并在 "SSN" 字段上添加了一个具有 Unique 属性的索引,如下所示:
db.Users.drop()
db.Users.createIndex({SSN:1},{unique:true})
db.Users.insert({"Name":"Ajay","Age":30,
Interest : ["cricket","music"] ,"SSN" : "12345"})
db.Users.insert({"Name":"Manoj","Age":60,
Interest : ["cricket","driving"],"SSN" : "54321"})
我删除了 Users 集合中的所有记录,并使用唯一属性在 SSN 字段上创建了索引。因此,如果我尝试插入重复的 SSN 值,我将收到错误。让我们试试:
db.Users.insert({"Name":"Preeti","Age":20,
Interest : ["music","driving"],"SSN" : "54321"})
错误信息是:
insertDocument :: caused by :: 11000 E11000 duplicate key error index:
Test.Users.$SSN_1 dup key: { : "54321" }
因此,我们无法在具有 unique 属性的 index 的字段中插入重复值。
2. Sparse (稀疏)
我正在删除 Users 集合,并将插入一些文档,如下所示:
db.Users.drop()
db.Users.insert({"Name":"Ajay","Age":30,
Interest : ["cricket","music"] ,"SSN" : "12345"})
db.Users.insert({"Name":"Manoj","Age":60,
Interest : ["cricket","driving"],"SSN" : "54321"})
db.Users.insert({"Name":"Preeti","Age":20,
Interest : ["music","driving"]})
db.Users.insert({"Name":"Anuj","Age":70,
Interest : ["cooking","music"]})
那么,如果我尝试在 SSN 字段上创建具有 unique 属性的 Index,会发生什么?如果我尝试像下面这样使用 unique 属性创建 index,我将收到一个错误,因为 SSN 在最后两个文档中包含 null,因此 SSN 不是唯一的。
db.Users.createIndex({SSN:1},{unique:true})
错误是:
E11000 duplicate key error index: Test.Users.$SSN_1 dup key: { : null }
那么解决方案是什么?我不能为这些记录创建 unique 索引吗?
等等……我们有一个解决方案……我们有 sparse 属性来处理这种情况。
Sparse 会告诉数据库,对于 SSN 缺失的文档,不应将其包含在 index 中。
太棒了……是时候创建具有 sparse 和 unique 属性的 index 了。
db.Users.createIndex({SSN:1},{unique:true,sparse:true})
这次,创建具有 unique 属性的 index 时不会出现错误,因为有 sparse。
3. Partial Index (部分索引)
这是 MongoDB 3.2 带来的一项新概念。有时,我们希望在具有特定条件的 index。如果我们使用某个条件创建 index,那么它就是部分 Index。
假设我想仅当 Age 大于 30 时才在 Name 字段上创建 Index。我们需要在创建 Index 时指定一个条件,如下所示:
db.Users.createIndex(
{ Name: 1},
{ partialFilterExpression: { Age: { $gt: 30 } } }
)
要应用条件,我们使用 partialFilterExpression。
4. TTL Index (TTL 索引)
MongoDB 有一种特殊的单字段 Index,称为 TTL Index。MongoDB 使用此类型的 Index 在特定时间段后自动删除文档。我们使用 expireAfterSeconds 选项 来提供过期时间。
我正在 Age 上创建 TTL 索引,过期时间为 60 秒,如下所示:
db.Users.createIndex( { "Age": 1 }, { expireAfterSeconds: 60 } )
它将在 60 秒后自动删除该文档。一个后台任务每 60 秒运行一次,删除所有过期的文档。因此,删除该文档可能需要一些额外的时间。这也取决于 mongod 实例的工作负载,因此过期的文档可能会在集合中存在超过指定时间。
一些要点
1. getIndexes()
如果我们想查看集合上所有已创建的索引,我们使用 getIndexes() 方法。
语法:db.CollectionName.getIndexes()
2. dropIndex()
要删除 Index,我们使用 dropIndex() 方法。
语法:db.CollectionName.dropIndex({"Key":1 or -1})
传递在创建 index 时使用的 1 或 -1 键。
3. dropIndexes()
要从集合中删除所有 Indexes,我们使用 dropIndexes() 方法。
db.CollectionName.dropIndexes()
4. 获取集合中的所有索引
db.getCollectionNames().forEach(function(collection) {
index = db[collection].getIndexes();
print("Indexes for " + collection + ":");
printjson(index);
});
5. Rebuild an Index (重建索引)
要重建 Index,我们使用 reIndex() 方法,如下所示:
db.CollectioName.reIndex()
限制
- 单个集合最多不能拥有 64 个索引。
- 复合索引不能包含超过 31 个字段。
参考
历史
- 2016 年 4 月 19 日:初始版本
最后,如果这对您有帮助并且您喜欢它,请投票。