使用 Direct3D12 实现动态资源
本文介绍了如何使用环形缓冲区和 Direct3D12 API 实现动态资源。
引言
动态资源是一种方便的编程范例,用于处理 Direct3D11 API 中频繁更改的资源。例如,使用动态常量缓冲区渲染多个具有不同变换矩阵的模型的一种方法是以下场景:
- 绑定着色器、纹理、常量缓冲区和其他资源
- 对于每个模型
- 使用 WRITE_DISCARD 标志映射常量缓冲区,这告诉系统缓冲区中的先前内容不再需要,可以丢弃
- 将新矩阵写入缓冲区
- 发出绘图命令
从应用程序的角度来看,缓冲区似乎是相同的,只是在每次绘图调用之前更新了缓冲区的内容。但在底层,Direct3D11 每次映射缓冲区时都会分配新的内存块。Direct3D12 没有动态资源的概念。程序员有责任分配内存并同步对其的访问。本文描述了 Diligent Engine 2.0 中采用的一种动态资源的可能实现。
朴素实现
在我们深入了解实现细节之前,让我们看看一个直接的实现。既然我们想要在每次绘图调用之前在缓冲区中拥有新数据,那么让我们尝试这样做。但是,我们不能仅仅将数据复制到缓冲区,因为当 CPU 想要更新缓冲区时,GPU 可能同时正在使用它。此外,缓冲区内存可能无法被 CPU 访问。因此,我们必须为每次更新分配新的 CPU 可访问内存块,将新数据写入此内存,并将复制命令记录到命令列表中。这将确保缓冲区更新和绘图命令将在 GPU 时间轴中以正确的顺序执行。主机必须确保所有分配都有效,直到所有引用它们的 GPU 命令完成,然后才能回收内存。Direct3D12 程序员还需要做的另一件重要事情是通知系统资源状态转换。在每个复制命令之前,资源必须转换到 D3D12_RESOURCE_STATE_COPY_DEST 状态,并且在绑定为常量缓冲区之前,它必须转换到 D3D12_RESOURCE_STATE_VERTEX_AND_CONSTANT_BUFFER。
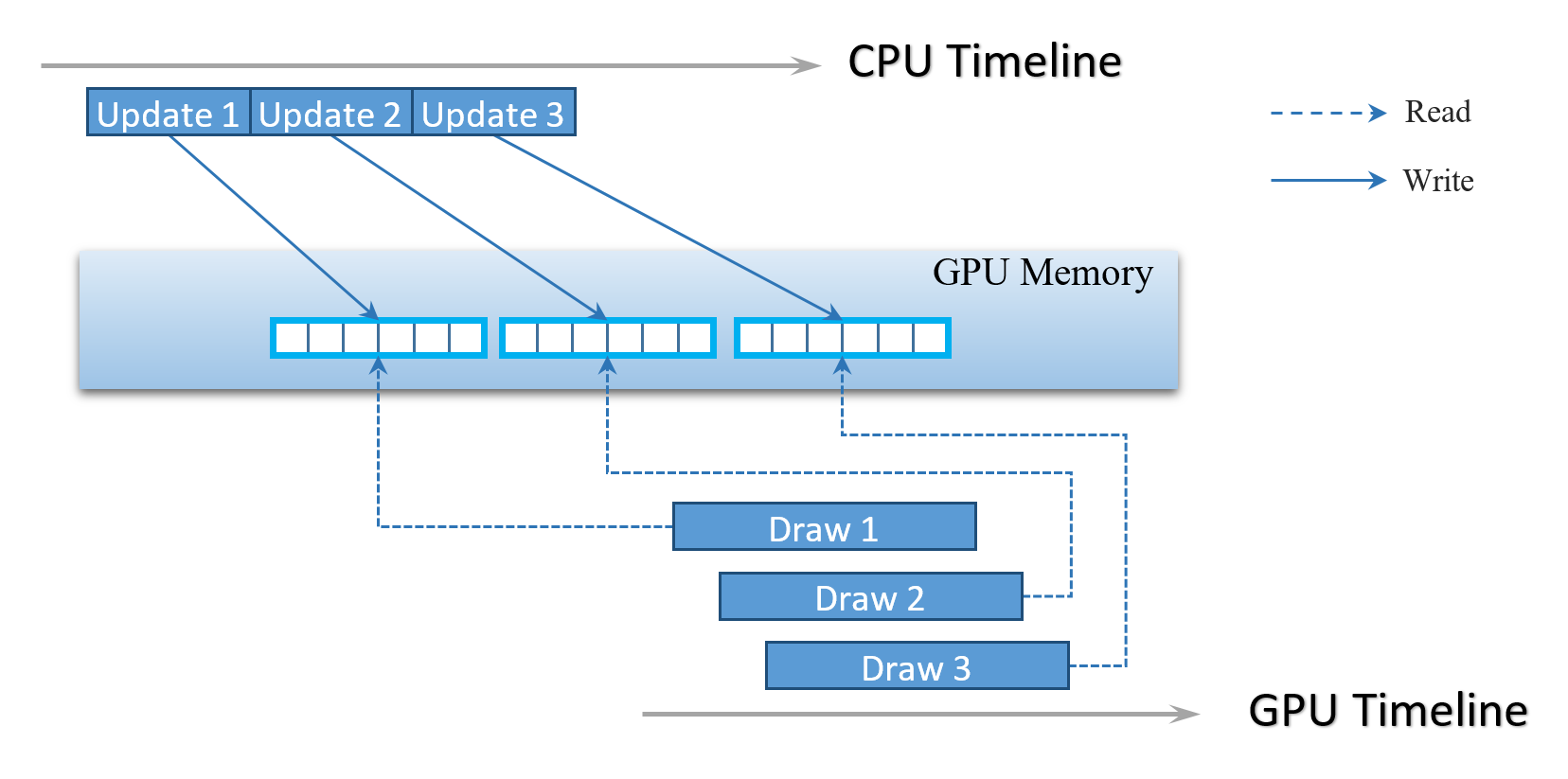
现在,如果我们查看我们的实现,最大的问题可能在于每次更新缓冲区时,我们都会复制数据两次(第一次复制到 CPU 可访问内存,第二次复制到常量缓冲区)。但真正的问题是我们必须在每次绘图调用之前在读写状态之间转换常量缓冲区。每次转换到 D3D12_RESOURCE_STATE_COPY_DEST 都要求 GPU 刷新管线,因为它必须确保所有可能的读取操作都在新数据写入之前完成。这有效地导致所有绘图命令的串行化。下图说明了 CPU 和 GPU 时间线中发生的情况

现代 GPU 拥有深度管线,能够并行处理多个命令。串行化 GPU 执行会对性能产生巨大影响。在我们包含 50,000 个单独绘图命令的测试场景中,总帧时间超过 300 毫秒。
高效实现
Diligent Engine 2.0 采用环形缓冲区策略来实现动态资源并避免 GPU 命令串行化。每次映射动态缓冲区时,都会在环形缓冲区中分配新的内存。在每一帧中,缓冲区都会增长并保存该帧的所有动态分配。当 GPU 完成一帧时,系统会回收该帧动态资源占用的内存。动态缓冲区的操作如下图所示

上图描述了以下场景
- 初始状态:缓冲区为空,头尾指针都指向分配内存的起始位置
- 帧 0、1 和 2:通过移动尾指针保留所需空间;当完成帧的命令记录时,帧尾的位置被推入队列
- 帧 3:GPU 完成帧 0 的渲染,通过将头指针移动到帧 0 尾部的记录位置来回收所有内存
- 帧 4:GPU 完成帧 1,可以回收内存。尾指针到达缓冲区末尾,分配从缓冲区起始位置继续
基本环形缓冲区
实现动态资源所需的第一个组件是实现上述内存管理策略的环形缓冲区类。
class RingBuffer
{
public:
typedef size_t OffsetType;
struct FrameTailAttribs
{
FrameTailAttribs(Uint64 fv, OffsetType off, OffsetType sz) :
FenceValue(fv),
Offset(off),
Size(sz)
{}
// Fence value associated with the command list in which
// the allocation could have been referenced last time
Uint64 FenceValue;
OffsetType Offset;
OffsetType Size;
};
static const OffsetType InvalidOffset = static_cast<OffsetType>(-1);
RingBuffer(OffsetType MaxSize)noexcept;
RingBuffer(RingBuffer&& rhs)noexcept;
RingBuffer& operator = (RingBuffer&& rhs)noexcept;
RingBuffer(const RingBuffer&) = delete;
RingBuffer& operator = (const RingBuffer&) = delete;
~RingBuffer();
OffsetType Allocate(OffsetType Size);
void FinishCurrentFrame(Uint64 FenceValue)
void ReleaseCompletedFrames(Uint64 CompletedFenceValue);
OffsetType GetMaxSize()const{return m_MaxSize;}
bool IsFull()const{ return m_UsedSize==m_MaxSize; };
bool IsEmpty()const{ return m_UsedSize==0; };
OffsetType GetUsedSize()const{return m_UsedSize;}
private:
std::deque< FrameTailAttribs > m_CompletedFrameTails;
OffsetType m_Head = 0;
OffsetType m_Tail = 0;
OffsetType m_MaxSize = 0;
OffsetType m_UsedSize = 0;
OffsetType m_CurrFrameSize = 0;
};
在缓冲区中分配新空间时有两种可能的情况:尾指针在头指针之后或在头指针之前。在这两种情况下,我们首先检查尾指针是否可以在不越过缓冲区末尾或头指针的情况下移动。如果缓冲区末尾没有足够的空间,我们尝试从头开始分配数据。该函数跟踪总已用空间,如果缓冲区已满,则立即退出。这很重要,因为如果不跟踪大小,就无法区分缓冲区是空的还是完全满的,因为在这两种情况下 m_Tail==m_Head。由于同样的原因,该函数还跟踪当前帧大小,这是区分空帧和缓冲区大小帧所必需的。以下清单显示了 Allocate() 函数的实现
OffsetType Allocate(OffsetType Size)
{
if(IsFull())
{
return InvalidOffset;
}
if (m_Tail >= m_Head )
{
// Head Tail MaxSize
// | | |
// [ xxxxxxxxxxxxxxxxx ]
//
//
if (m_Tail + Size <= m_MaxSize)
{
auto Offset = m_Tail;
m_Tail += Size;
m_UsedSize += Size;
m_CurrFrameSize += Size;
return Offset;
}
else if(Size <= m_Head)
{
// Allocate from the beginning of the buffer
OffsetType AddSize = (m_MaxSize - m_Tail) + Size;
m_UsedSize += AddSize;
m_CurrFrameSize += AddSize;
m_Tail = Size;
return 0;
}
}
else if (m_Tail + Size <= m_Head )
{
//
// Tail Head
// | |
// [xxxx xxxxxxxxxxxxxxxxxxxxxxxxxx]
//
auto Offset = m_Tail;
m_Tail += Size;
m_UsedSize += Size;
m_CurrFrameSize += Size;
return Offset;
}
return InvalidOffset;
}
当一帧完成时,我们记录当前的尾部位置、帧大小和关联的栅栏值
void RingBuffer::FinishCurrentFrame(Uint64 FrameNum)
{
m_CompletedFrameTails.emplace_back(FenceValue, m_Tail, m_CurrFrameSize);
m_CurrFrameSize = 0;
}
当 GPU 完成渲染帧时,可以回收内存。这通过移动头部指针来执行
void ReleaseCompletedFrames(Uint64 CompletedFenceValue)
{
// We can release all tails whose associated fence value is less
// than or equal to CompletedFenceValue
while(!m_CompletedFrameTails.empty() &&
m_CompletedFrameTails.front().FenceValue <= CompletedFenceValue)
{
const auto &OldestFrameTail = m_CompletedFrameTails.front();
VERIFY_EXPR(OldestFrameTail.Size <= m_UsedSize);
m_UsedSize -= OldestFrameTail.Size;
m_Head = OldestFrameTail.Offset;
m_CompletedFrameTails.pop_front();
}
}
GPU 环形缓冲区
现在我们有了环形缓冲区管理的基本实现,我们可以实现基于 GPU 的环形缓冲区。
struct DynamicAllocation
{
DynamicAllocation(ID3D12Resource *pBuff, size_t ThisOffset, size_t ThisSize) :
pBuffer(pBuff), Offset(ThisOffset), Size(ThisSize) {}
ID3D12Resource *pBuffer = nullptr;
size_t Offset = 0;
size_t Size = 0;
void* CPUAddress = 0;
D3D12_GPU_VIRTUAL_ADDRESS GPUAddress = 0;
};
class GPURingBuffer : public RingBuffer
{
public:
GPURingBuffer(size_t MaxSize, ID3D12Device *pd3d12Device, bool AllowCPUAccess);
GPURingBuffer(GPURingBuffer&& rhs);
GPURingBuffer& operator =(GPURingBuffer&& rhs);
GPURingBuffer(const GPURingBuffer&) = delete;
GPURingBuffer& operator =(GPURingBuffer&) = delete;
~GPURingBuffer();
DynamicAllocation Allocate(size_t SizeInBytes);
private:
void Destroy();
void* m_CpuVirtualAddress;
D3D12_GPU_VIRTUAL_ADDRESS m_GpuVirtualAddress;
CComPtr<ID3D12Resource> m_pBuffer;
};
GPU 环形缓冲区类的构造函数在 GPU 内存中创建缓冲区并持久映射它。请注意,与 D3D11 不同,在 D3D12 中,只要 GPU 不访问 CPU 正在写入的相同内存,就可以将缓冲区映射并用于绘图操作,这是完全合法的。
GPURingBuffer::GPURingBuffer(size_t MaxSize, ID3D12Device *pd3d12Device, bool AllowCPUAccess) :
RingBuffer(MaxSize),
m_CpuVirtualAddress(nullptr),
m_GpuVirtualAddress(0)
{
D3D12_HEAP_PROPERTIES HeapProps;
HeapProps.CPUPageProperty = D3D12_CPU_PAGE_PROPERTY_UNKNOWN;
HeapProps.MemoryPoolPreference = D3D12_MEMORY_POOL_UNKNOWN;
HeapProps.CreationNodeMask = 1;
HeapProps.VisibleNodeMask = 1;
D3D12_RESOURCE_DESC ResourceDesc;
ResourceDesc.Dimension = D3D12_RESOURCE_DIMENSION_BUFFER;
ResourceDesc.Alignment = 0;
ResourceDesc.Height = 1;
ResourceDesc.DepthOrArraySize = 1;
ResourceDesc.MipLevels = 1;
ResourceDesc.Format = DXGI_FORMAT_UNKNOWN;
ResourceDesc.SampleDesc.Count = 1;
ResourceDesc.SampleDesc.Quality = 0;
ResourceDesc.Layout = D3D12_TEXTURE_LAYOUT_ROW_MAJOR;
D3D12_RESOURCE_STATES DefaultUsage;
if (AllowCPUAccess)
{
HeapProps.Type = D3D12_HEAP_TYPE_UPLOAD;
ResourceDesc.Flags = D3D12_RESOURCE_FLAG_NONE;
DefaultUsage = D3D12_RESOURCE_STATE_GENERIC_READ;
}
else
{
HeapProps.Type = D3D12_HEAP_TYPE_DEFAULT;
ResourceDesc.Flags = D3D12_RESOURCE_FLAG_ALLOW_UNORDERED_ACCESS;
DefaultUsage = D3D12_RESOURCE_STATE_UNORDERED_ACCESS;
}
ResourceDesc.Width = MaxSize;
pd3d12Device->CreateCommittedResource(&HeapProps, D3D12_HEAP_FLAG_NONE, &ResourceDesc,
DefaultUsage, nullptr, __uuidof(m_pBuffer), &m_pBuffer) );
m_pBuffer->SetName(L"Upload Ring Buffer");
m_GpuVirtualAddress = m_pBuffer->GetGPUVirtualAddress();
if (AllowCPUAccess)
{
m_pBuffer->Map(0, nullptr, &m_CpuVirtualAddress);
}
}
请注意,缓冲区是在 D3D12_RESOURCE_STATE_GENERIC_READ 状态下创建的。此状态永远不会改变,这将消除所有状态转换。
Allocate() 方法只是调用 RingBuffer::Allocate() 并填充 DynamicAllocation struct 的成员
DynamicAllocation GPURingBuffer::Allocate(size_t SizeInBytes)
{
auto Offset = RingBuffer::Allocate(SizeInBytes);
if (Offset != RingBuffer::InvalidOffset)
{
DynamicAllocation DynAlloc(m_pBuffer, Offset, SizeInBytes);
DynAlloc.GPUAddress = m_GpuVirtualAddress + Offset;
DynAlloc.CPUAddress = m_CpuVirtualAddress;
if(DynAlloc.CPUAddress)
DynAlloc.CPUAddress = reinterpret_cast<char*>(DynAlloc.CPUAddress) + Offset;
return DynAlloc;
}
else
{
return DynamicAllocation(nullptr, 0, 0);
}
}
动态上传堆
最后,我们拥有实现基于环形缓冲区的动态上传堆所需的所有组件。该类维护一个 GPU 环形缓冲区列表。如果当前缓冲区中的分配失败,该类将创建一个新的 GPU 环形缓冲区,其大小加倍,并将其添加到列表中。只有最大的缓冲区用于分配,所有其他缓冲区在 GPU 完成相应帧后释放。
class DynamicUploadHeap
{
public:
DynamicUploadHeap(bool bIsCPUAccessible, class RenderDeviceD3D12Impl* pDevice, size_t InitialSize);
DynamicUploadHeap(const DynamicUploadHeap&)=delete;
DynamicUploadHeap(DynamicUploadHeap&&)=delete;
DynamicUploadHeap& operator=(const DynamicUploadHeap&)=delete;
DynamicUploadHeap& operator=(DynamicUploadHeap&&)=delete;
DynamicAllocation Allocate( size_t SizeInBytes, size_t Alignment = DEFAULT_ALIGN );
void FinishFrame(Uint64 FenceValue, Uint64 LastCompletedFenceValue);
private:
const bool m_bIsCPUAccessible;
std::vector<GPURingBuffer> m_RingBuffers;
RenderDeviceD3D12Impl* m_pDeviceD3D12 = nullptr;
};
当请求一块动态内存时,上传堆首先尝试在最大的 GPU 缓冲区中分配内存。如果分配失败,它会创建一个提供足够空间的新缓冲区并从该缓冲区请求内存
DynamicAllocation DynamicUploadHeap::Allocate(size_t SizeInBytes, size_t Alignment /*= DEFAULT_ALIGN*/)
{
const size_t AlignmentMask = Alignment - 1;
// Assert that it's a power of two.
VERIFY_EXPR((AlignmentMask & Alignment) == 0);
// Align the allocation
const size_t AlignedSize = (SizeInBytes + AlignmentMask) & ~AlignmentMask;
auto DynAlloc = m_RingBuffers.back().Allocate(AlignedSize);
if (!DynAlloc.pBuffer)
{
// Create new buffer
auto NewMaxSize = m_RingBuffers.back().GetMaxSize() * 2;
// Make sure the buffer is large enough for the requested chunk
while(NewMaxSize < SizeInBytes)NewMaxSize*=2;
m_RingBuffers.emplace_back(NewMaxSize, m_pDeviceD3D12->GetD3D12Device(), m_bIsCPUAccessible);
DynAlloc = m_RingBuffers.back().Allocate(AlignedSize);
}
return DynAlloc;
}
当前帧完成后,堆通知所有环形缓冲区。它还让所有环形缓冲区回收所有已完成帧的内存。当 GPU 完成相应帧后,堆会销毁除最大缓冲区外的所有缓冲区。因此,在典型条件下,堆只包含一个环形缓冲区。
void DynamicUploadHeap::FinishFrame(Uint64 FenceValue, Uint64 LastCompletedFenceValue)
{
size_t NumBuffsToDelete = 0;
for(size_t Ind = 0; Ind < m_RingBuffers.size(); ++Ind)
{
auto &RingBuff = m_RingBuffers[Ind];
RingBuff.FinishCurrentFrame(FenceValue);
RingBuff.ReleaseCompletedFrames(LastCompletedFenceValue);
if ( NumBuffsToDelete == Ind && Ind < m_RingBuffers.size()-1 && RingBuff.IsEmpty())
{
++NumBuffsToDelete;
}
}
if(NumBuffsToDelete)
m_RingBuffers.erase(m_RingBuffers.begin(), m_RingBuffers.begin()+NumBuffsToDelete);
}
管理上传堆
渲染设备维护一个上传堆数组,每个设备上下文一个。这使得可以从不同的上下文自由线程分配动态资源。当一帧完成时,设备从栅栏读取最后完成的帧号,发出当前帧号信号,并通知所有上传堆。
void RenderDeviceD3D12Impl::FinishFrame()
{
auto CompletedFenceValue = GetCompletedFenceValue();
auto NextFenceValue = m_pCommandQueue->GetNextFenceValue();
for (auto &UploadHeap : m_UploadHeaps)
{
UploadHeap->FinishFrame(NextFenceValue, CompletedFenceValue);
}
// ...
}
资源绑定
在我们的动态常量缓冲区场景中,缓冲区在每次绘制调用之前分配新的内存。D3D12 API 允许 将频繁更改的常量缓冲区直接绑定到根参数 以绕过描述符堆
D3D12_GPU_VIRTUAL_ADDRESS CBVAddress = pDynamicBuff->GetGPUAddress();
pCmdList->SetComputeRootConstantBufferView(RootParam, CBVAddress);
动态顶点和索引缓冲区可以通过 IASetIndexBuffer() 和 IASetVertexBuffers() 方法设置。
性能
基于环形缓冲区的动态资源实现避免了冗余复制并消除了 GPU 命令串行化(参见下图)。在我们的 50,000 次绘制调用测试案例中,帧时间从 300 毫秒下降到 25 毫秒。性能仍然远非最佳,但更新动态资源已不再是问题。