
视频分析的内部
4.89/5 (7投票s)
视频分析原理。
引言

很多人都知道 OpenCV——一个强大的计算机视觉库。这个广泛的跨平台项目包含许多不同的算法,并且要理解它是如何工作的并不容易。你可以找到各种出版物和例子,介绍如何以及在哪里使用机器视觉,但关于它如何工作的内容却不多。而这对于理解过程非常重要,尤其当你刚开始学习计算机视觉时。
视频分析的总体流程图如下所示。
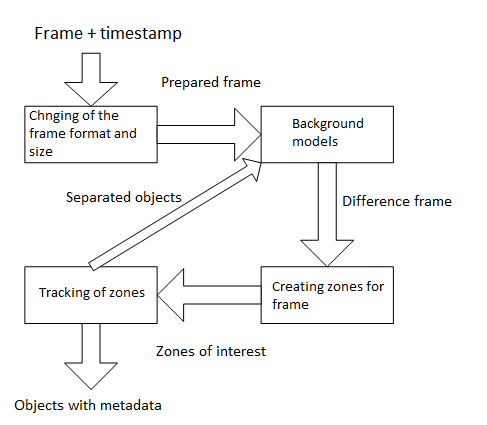
该过程分为几个阶段。关于画面中发生的事情的信息在每个阶段都会得到补充。不同阶段之间也可能存在反向引用,以便更好地响应场景变化。我们来详细看看这个流程图。
什么是视频流
首先,我们需要理解什么是视频流。视频数据有很多格式,但它们的本质是相同的:以每秒一定的帧率组成的连续帧。帧由分辨率和格式(每像素的位数及其解释:哪些位负责不同的颜色)决定。可以使用帧压缩来减少传输的数据量,但在屏幕上显示时,它们总是会解压缩回原始状态。分析算法总是处理未压缩的帧。
因此,视频流的特征是帧率、分辨率和比特格式。
值得注意的是,计算机视觉算法一次只分析一帧。也就是说,帧是按顺序处理的。此外,了解自上一帧以来经过了多长时间也很重要。这个值可以从帧率计算得出,但更实用的方法是为每一帧附加一个时间戳。
改变帧格式和尺寸
第一步是准备帧。通常,在这一步会大大减小帧的尺寸。原因是图像的每个像素都将参与后续处理。相应地,帧尺寸越小,处理速度越快。当然,在缩小尺寸时会丢失一些信息。但这并非关键,甚至是有益的。分析算法主要处理的对象足够大,不会在帧压缩过程中丢失。但一些与相机质量、光照、自然因素等相关的“噪声”会减少。
分辨率的改变是通过将原始图像的多个像素组合成一个来实现的。信息损失量取决于像素组合的类型。
例如,原始图像的 3x3 像素正方形将被转换为一个像素。你可以对所有 9 个像素求和,也可以对 4 个角像素求和,还可以只取中心的一个像素。
四个角像素的和

所有 9 个像素的和

只取中心的一个像素

结果在速度和质量上总会有细微差别。但有时,信息丢失较多的方式比使用所有像素的方式能得到更平滑的图像。
此阶段的另一个操作是更改帧格式。彩色图像通常不使用,因为这也会增加处理时间。例如,RGB24 每个像素包含 3 个字节。而 Y8 只包含一个字节,并且不会丢失太多信息。
Y8=(R+G+B)/3。
结果将是相同的图像,但为灰度。


背景模型
这是处理最重要的阶段。此步骤的目的是创建场景背景并获得背景与新帧之间的差异。处理结果很大程度上取决于此阶段算法的质量。纠正将对象误认为是背景或将部分背景识别为对象的情况在后续阶段将非常困难。
最简单的情况下,你可以将一个没有物体的空场景帧作为背景。

例如,取一个带有物体的帧

如果我们把这些帧转换为 Y8 并用带有物体的帧减去背景帧,我们会得到如下结果:

为了方便起见,可以进行二值化:将所有大于 0 的像素值替换为 255。结果我们将从灰度图像转换为黑白图像。

看起来一切都很好:物体与背景很好地分离,边界清晰。但是,首先,阴影会被当作物体的一部分。其次,你可能会在画面顶部看到图像噪声产生的伪影。
这种方法不适合实际应用。任何阴影、光线反射、相机亮度变化都会破坏整个结果。这就是问题的全部复杂性所在。对象应与背景分离,同时必须忽略自然因素和图像噪声:光线反射、建筑物和云的阴影、植物枝叶摇曳、帧压缩伪影等。此外,如果你要寻找的物体离开了,它不应该成为背景的一部分。
有许多 算法 可以解决这些问题,效率各不相同。从简单的平均背景到使用概率模型和机器学习。许多算法都包含在 OpenCV 中。而且可以组合使用几种算法,效果会更好。但是算法越复杂,下一帧的处理时间就越长。如果实时视频的帧率为 12.5 帧/秒,那么系统只有 80 毫秒的处理时间。因此,选择最优解决方案将取决于目标和为此实施分配的资源。
区域创建
形成了一个差分帧。我们看到黑色背景上的白色物体。


现在我们需要将物体从区域中分离出来,将物体像素组合成区域。

例如,可以通过 连通组件标记 来实现。
此时,你可以看到背景模型的所有问题。顶部的这个人被分成了几部分,有很多伪影、人的阴影。然而,其中一些问题可以在这个阶段得到纠正。了解物体的面积、宽度和高度、像素密度,可以过滤掉不必要的物体。
蓝色矩形表示参与进一步处理的对象,绿色表示被过滤掉的对象。这里也可能出错。如你所见,顶部的这个人被分成了几部分,由于尺寸过小而被过滤掉了。这个问题可以通过使用透视等方法来解决。
还可能出现其他错误。例如,一些物体可能会被合并成一个。因此,这个阶段有很大的实验空间。
区域跟踪
最后阶段,区域被转化为对象。这里使用了前几帧的处理结果。主要任务是确定两帧中的区域是否是同一个对象。特征可能不同:大小、像素密度、颜色特征、运动方向预测等。时间戳在这个阶段非常重要。它们允许计算对象的速度和行进距离。
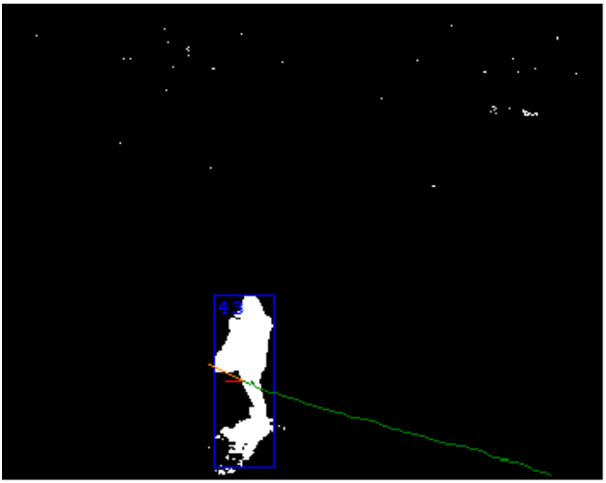
在这个阶段,可以纠正前一阶段的问题。例如,可以通过它们的运动历史来区分连接的对象。另一方面,也可能出现问题。其中最重要的是两个对象的交叉。一个特殊情况是,一个较大的对象长时间遮挡了较小的对象。
用于背景模型的对象
分析算法的架构可以包含反向引用,以改进前一阶段的工作。最容易想到的就是利用场景中对象的信息来形成背景。
例如,可以找到丢失的对象,不将其视为背景的一部分。或者对抗“幽灵”:如果你在一个有人的场景中创建背景,当人离开时,会出现一个“幽灵”对象。了解此处是对象的轨迹起点可以帮助你快速从背景中移除“幽灵”。
结果
所有阶段的结果是场景中对象的列表。其中每个对象都具有大小、密度、速度、轨迹、方向和其他参数。
此列表用于场景分析。你可以确定对象是否越界或是否朝错误方向移动。或者你可以计算给定区域内的对象数量、怠速、摔倒以及许多其他事件。
摘要
现代视频分析系统已取得非常好的成果,但它们仍然是一个复杂的多步骤过程。理论知识并不总能带来好的实际结果。
在我看来,创建良好的机器视觉系统非常复杂。设置算法是一个非常困难且耗时的过程。它需要大量的实验。尽管在这种情况下 OpenCV 非常好用,但这并不能保证结果,因为你需要知道如何正确使用它所包含的工具。