
使用正则表达式生成类似 Facebook 的预览
4.83/5 (7投票s)
将页面下载为 HTML 字符串。使用正则表达式解析它并提取所需的内容以生成 Facebook 点赞预览。
引言
本文将向您展示,当用户插入任何 URL 时,如何生成 Facebook 点赞链接预览?
背景
要理解这一点,了解 WebRequest 和正则表达式是必要的。
使用代码
首先,我们需要理解 什么是 WebRequest?
WebRequest 是通过 Internet 访问数据的请求/响应模型。请求从客户端发送到服务器。服务器将根据请求返回响应给客户端。如果访问 Internet 上的资源时出现任何错误,WebRequest 会抛出 WebException。
有关更多信息,请参阅 [https://msdn.microsoft.com/en-us/library/system.net.webrequest(v=vs.110).aspx]。
什么是正则表达式?
正则表达式由特殊字符和字母数字字符组成,用于描述特定场景的搜索模式。
例如
如果我们想检查输入的任何值是否为有效的金额格式。
我们知道有效的金额格式是任何数字后跟两位小数。即 99.99。
为此,下面的正则表达式可能很有用。[这只是一个示例,并非精确的正则表达式]
([0-9]{7}\.[0-9]{2})

图片来源:https://regexper.com/(许可 - 未修改)
现在,我们对 WebRequest 和 Regex(正则表达式)有了基本的了解。
如果我们还记得,当我们把任何链接粘贴到 Facebook 的状态块中时,它会做什么?它会创建一个预览,其中包含图像、网站标题、有效 URL 和描述。
有时我们可能找不到任何描述或图像。那么,问题是为什么有时它不显示任何图像?
要理解这一点,我们需要了解 Facebook 可能使用的是什么场景。根据我的研究,我知道它使用网站的元标记来获取生成预览所需的详细信息。如果任何网站没有包含图像和描述的元标记,那么它们就不会在预览中显示。
我们将使用相同的场景。但是,在这里,我们为用户提供了输入任何不带 HTTP 和/或 HTTPS 的 URL 的功能。
第一步,我们将获取用户的输入。当用户输入任何 URL 时,我们首先需要格式化 URL 以进行 WebRequest。
假设用户输入了“google.com”。那么,我们将有四个 URL,我们将从这些 URL 中至少一个 URL 中获取 WebResponse。
可能的 URL 列表
1) http://google.com
2) https://google.com
3) http://www.google.com
4) https://www.google.com
如何进行 WebRequest?以及如何检查其响应?请参阅下面的代码。
// making a webrequest
HttpWebRequest request = HttpWebRequest.Create(Url) as HttpWebRequest;
// webresponse
response = request.GetResponse() as HttpWebResponse;
if (response.StatusCode.ToString().ToLower() == "ok")
{
//valid url
}
一旦我们获得了一个有效的 URL,我们就需要将渲染的 HTML 页面作为字符串下载,然后我们可以应用正则表达式并提取生成预览所需的信息。
要将渲染的 HTML 页面下载为字符串,请参阅下面的代码。摘自 [ http://www.mikesdotnetting.com/article/49/how-to-read-a-remote-web-page-with-asp-net-2-0 ]
public static string GetHtmlPage(string strURL)
{
string strResult;
HttpWebRequest objRequest = (HttpWebRequest)WebRequest.Create(strURL);
objRequest.UserAgent = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.121 Safari/535.2";
WebResponse objResponse = objRequest.GetResponse();
using (var sr = new StreamReader(objResponse.GetResponseStream()))
{
strResult = sr.ReadToEnd();
sr.Close();
}
return strResult;
}
一旦我们将 HTML 页面下载为字符串,我们就需要提取所需的信息。
首先,我们将提取元标记。要提取元标记,我们需要构建一个正则表达式,以帮助提取页面中的所有元标记。
正则表达式:<meta[\\s]+[^>]*?content[\\s]?=[\\s\"\']+(.*?)[\"\']+.*?>

图片来源:https://regexper.com/(许可 - 未修改)
我们如何使用上面的正则表达式提取元标记?请参阅下面的代码。匹配集合逻辑摘自 [ http://www.dotnetperls.com/scraping-html ]
public static MatchCollection GetWebPageMetaData(string s)
{
Regex m3 = new Regex("<meta[\\s]+[^>]*?content[\\s]?=[\\s\"\']+(.*?)[\"\']+.*?>");
MatchCollection mc = m3.Matches(s);
return mc;
}
提取元标记后,我们需要从中提取 og:image、og:description 和 og:title。请参阅下面的代码
var metadata = GetWebPageMetaData(s);
if (metadata != null)
{
foreach (Match item in metadata)
{
for (int i = 0; i <= item.Groups.Count; i++)
{
if (item.Groups[i].Value.ToString().ToLower().Contains("description"))
{
scrap.desc = item.Groups[i + 1].Value;
break;
}
if (item.Groups[i].Value.ToString().ToLower().Contains("og:title"))
{
scrap.title = item.Groups[i + 1].Value;
break;
}
if (item.Groups[i].Value.ToString().ToLower().Contains("og:image"))
{
if (string.IsNullOrEmpty(scrap.image))
{
scrap.image = item.Groups[i + 1].Value;
}
break;
}
else if (item.Groups[i].Value.ToString().ToLower().Contains("image") && item.Groups[i].Value.ToString().ToLower().Contains("itemprop"))
{
scrap.image = item.Groups[i + 1].Value;
if (scrap.image.Length < 5)
{
scrap.image = null;
}
break;
}
}
}
}
如果我们获得了所有必需的内容,那么我们就完成了。我们有一个有效的 URL、图像、网站描述和网站标题。只需将内容返回到视图即可。
如果没有获得任何描述怎么办?
如果我们没有在页面中找到任何描述,我们不会去寻找它,因为它在元标记中找不到。我们可以从 body 标签中获取任何一行或段落,但我们跳过了它,因为谁知道网站的第一个段落是该网站的内容?它可能是任何广告!!
如果没有获得任何图像怎么办?
在这种情况下,我们将使用正则表达式解析 HTML 字符串以获取 HTML 页面中的所有 img 标签。解析 [通过] 后,我们将查找名称中包含“logo”的图像。80% 到 90% 的几率可以获得网站的 logo。10% 到 20% 的几率我们可以获得 logo,但它可能不是同一网站的。
请参阅下面的代码来提取图像。摘自 [ http://stackoverflow.com/questions/20184532/c-sharp-regex-img-src ]
public static List<string> GetRegImages(string str)
{
List<string> newimg = new List<string>();
const string pattern = @"<img\b[^\<\>]+?\bsrc\s*=\s*[""'](?<L>.+?)[""'][^\<\>]*?\>";
foreach (Match match in Regex.Matches(str, pattern, RegexOptions.IgnoreCase))
{
var imageLink = match.Groups["L"].Value;
newimg.Add(imageLink);
}
return newimg;
}
现在我们有了页面上所有图像的列表。我们可能会以以下方式获得图像 URL。
/images/someimage.jpg
嗯,如果我们有像上面这样的图像 URL,我们就无法在我们的页面上渲染图像,因为它位于某个网站的内部文件夹中。要访问它,我们需要它的完整图像路径,即 http://SomeSiteUrl/images/someimage.jpg
我们将像之前查找有效网站 URL 一样格式化图像 URL。格式化图像 URL 后,我们将通过创建 WebRequest 来检查有效的可用图像 URL。
我们将重复此步骤,直到我们在列表中获得四个图像。
如果没有从元标记获得 og:title 怎么办?
在这种情况下,我们将使用正则表达式查找 title 标签。
这样我们就完成了。我们已经获得了创建 Facebook 点赞预览所需的所有内容。将内容返回到页面。应用有效的 CSS 以获得与 Facebook 链接预览完全相同的视图。
实施步骤
1) 打开 Visual Studio 并创建一个新项目。

2) 选择 Asp.net Web 应用程序,并将项目名称命名为 FacebookLikePreview。

03) 选择 MVC 模板,然后单击更改身份验证。

04) 勾选无身份验证,然后单击确定。

05) 转到解决方案资源管理器,右键单击 Models,然后单击新建文件夹,并将其命名为 VM (View Model)。

06) 右键单击 VM,然后添加一个类文件。将其命名为 Scrap.cs。


07) 现在转到 HomeController 并实现逻辑。在此,我没有显示所有代码片段,因为这会增加文章的长度。

08) 创建两个视图模型,如下面的图像所示。
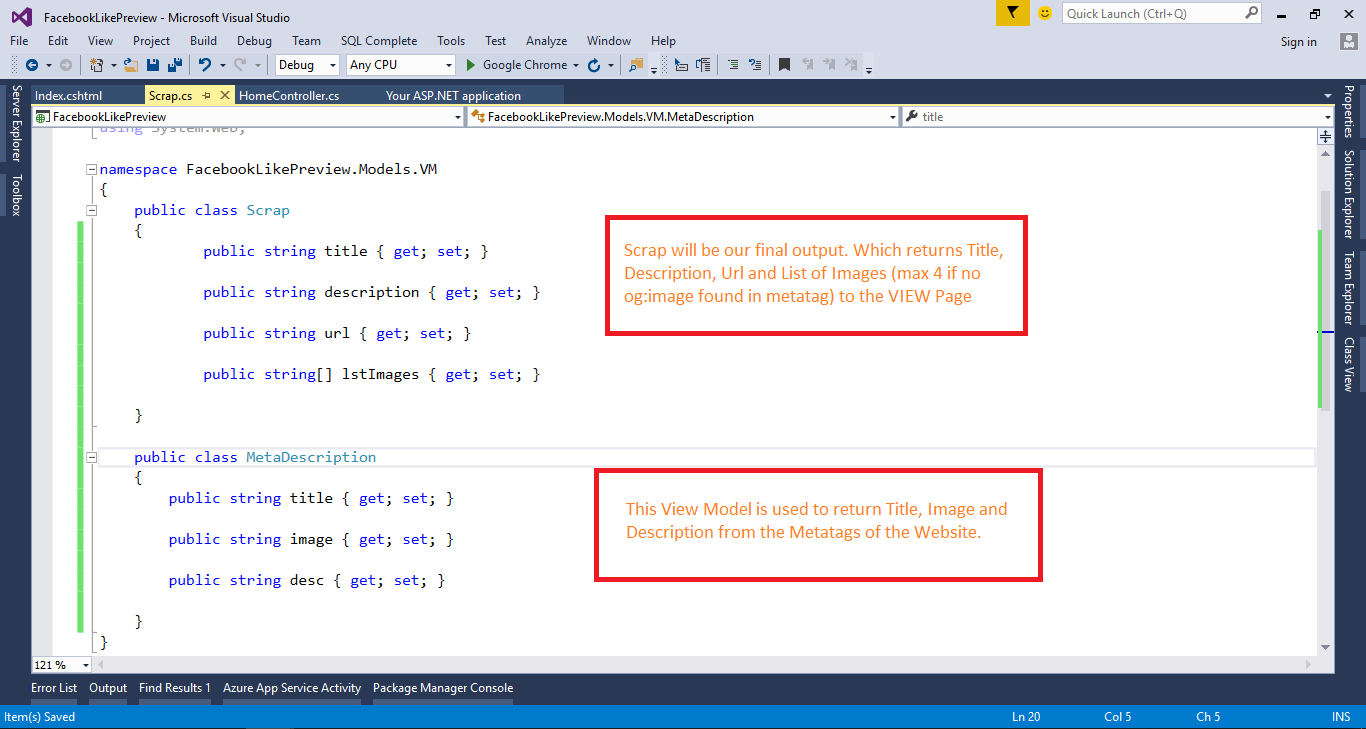
09) 转到 index.cshtml 页面并创建视图。当用户输入任何 URL 并单击“生成预览”按钮时,将向控制器发出 Ajax 调用,该控制器将返回所需的内容。所有必需的内容都将使用 jQuery 进行绑定。




注意:最初我尝试使用 HtmlAgility pack 来实现这个概念。但后来转向正则表达式,因为它对于解析 HTML 页面以获得期望的输出是准确的。
参考
1) https://code.msdn.microsoft.com/Exctract-from-web-address-c9895a2f
3) http://mantascode.com/c-programmatically-download-all-images-from-a-website-and-save-them-locally/
5) https://codeproject.org.cn/Articles/1041115/Webscraping-with-Csharp
6) http://stackoverflow.com/questions/6887910/regex-for-extracting-image-file-links