
C# 的易于使用的 OpenCL 多设备负载均衡和流水线:Cekirdekler API
用几行代码为 C# 实现多设备 OpenCL 负载均衡器和流水线。
- 下载 cekirdekler_dll_v1_4_1_opencl_2_0_update2.zip - 400.4 KB
- 下载 cekirdekler_dll_v1_4_1_opencl_1_2_update2.zip - 430.2 KB
- 下载 cekirdekler_dll_v1_4_1_opencl_1_2_update2.rar - 373.7 KB
- 下载 cekirdekler_dll_v1_4_1_opencl_2_0_update2.rar - 347 KB
引言
Cekirdekler API 是一个开源的 C# OpenCL 包装器,它可以在多个支持 OpenCL 的设备之间进行负载均衡,并添加流水线功能以获得更高的性能,同时允许用户在他们的系统中的所有 GPU、CPU 甚至 FPGA 上运行他们原生的 C99 代码。
简而言之,它可以将程序中简单的热点瓶颈加速 10 倍、100 倍、1000 倍。
该项目已于几周前推送到 github:
https://github.com/tugrul512bit/Cekirdekler/wiki
以及它的 C++ 部分:
https://github.com/tugrul512bit/CekirdeklerCPP
(新信息会逐步添加到末尾,新的 dll 文件总是在“引言”之前,请参见末尾的更新日志部分)
(现在这里的 dll 文件是在 FX8150 上构建的,并修复了非控制台应用程序的控制台日志记录错误)
Unity 游戏引擎中的简单用例(在 R7-240 GPU 和 CPU 上计算 Vector3 数组和基本类型数组):
https://www.youtube.com/watch?v=XoAvnUhdu80
https://www.youtube.com/watch?v=-n_9DXnEjFw
https://www.youtube.com/watch?v=7ULlocNnKcY
背景
通常对于所有 OpenCL 的精简包装器,用户都需要自己实现所有缓冲区复制和事件处理。这个 API 会处理这些,而用户只需要用简单的 API 命令选择要做什么。一行代码声明一个设备、所有设备或一个子组设备,具体取决于它们的供应商、计算单元或内存大小。一行代码声明一个数字计算器,它保存用 C99 语言编写的 OpenCL 内核,并作为一个简单的多行字符串传递。一行代码声明一个由 C++ 中的缓冲区(可选)支持的数组,或者只是收集用户的 C# 数组并对其进行增强。一行代码执行计算。
使用代码
开头提供的压缩文件是为懒惰的开发者准备的。它们是在 Celeron N3060 上构建的,所以不要指望奇迹。我建议您访问我提供的 github 地址,下载整个项目并在您自己的计算机上构建,毕竟它是开源的。这是获得性能和安全性的最佳方式。
万一使用了压缩文件
- Cekirdekler.dll:在您的 C# 项目中将其添加为引用。然后添加诸如“using Cekirdekler;”以及它的一些子命名空间到您使用的代码文件中。
- Cekirdekler.XML:这有助于 IntelliSense 向您介绍方法和类。
- KutuphaneCL.dll:需要与 Cekirdekler.dll 放在同一个文件夹中,因为它使用 dllimport 属性来调用它。
- System.Threading.dll:您也可以从 Microsoft 的网站下载此文件。这使得它能够在 .Net 2.0 中运行。也请将其添加为引用。
- System.Threading.XML
主要命名空间是
- Cekirdekler:包含 ClNumberCruncher 和 Tester 类
- Cekirdekler.Hardware:显式设备选择,而不是选择所有设备
- Cekirdekler.Arrays:包含数组包装器,如 ClArray{generic} 和 ClFloatArray 等。
假设开发人员需要将 PI 的值加到数组的所有元素中
//
// float [] arrayOfPIs = new float[1024];
//
那么他/她需要这样写
ClNumberCruncher gpu = new ClNumberCruncher(AcceleratorType.GPU | AcceleratorType.CPU, @"
__kernel void test0(__global float * a)
{
int i=get_global_id(0);
a[i]+=3.1415f;
}
");
ClArray<float> f = arrayOfPIs;
f.compute(gpu, 1, "test0", 1024);
这使得加法运算可以通过系统中的所有 GPU 和所有 CPU 来完成。通过在数组元素上运行字符串中的 C99 代码。
compute 方法中的参数“1”是计算 ID,这意味着下次达到具有相同计算 ID 的 compute 方法时,负载均衡器将在所有设备之间进行工作项交换,以最小化 compute 方法的开销。
compute 方法中的参数“1024”是分配给设备的的总工作项数。如果系统中存在两个 GPU,两个设备都从 512 个工作项开始,然后通过更多的 compute 重复次数收敛到一个时间最小化的点。
工作组(OpenCL 对运行在同一计算单元中的最小线程共享内存的定义)大小的默认值为 256。如果需要将其设置为 64,
f.compute(gpu, 1, "test0", 1024,64);
当内核代码中需要多个缓冲区时
__kernel void test0(__global float * a,__global float * b,__global float * c){...}
可以这样从主机端添加它们
f.nextParam(g,h).compute(gpu, 1, "test0", 1024,64);
这样,数组 f、g 和 h 必须与内核参数中的顺序相同,并带有 __global 内存说明符。然后 f 链接到 a,g 链接到 b,h 链接到 c。
如果开发人员需要更高的性能,可以启用流水线
f.compute(gpu, 1, "test0", 1024,64,0,true);
值为零的参数是计算开始的偏移量,因此每个线程的全局 ID 都将根据此偏移量进行偏移。设置为 true 会启用流水线。默认值为 false。启用后,API 将每个设备的负载划分为 4 个较小的部分,并以事件驱动的流水线方式推送它们,这样这些部分就可以隐藏彼此的延迟。默认情况下,流水线类型是事件驱动的。还有一种驱动程序控制版本,它使用 16 个命令队列而无需事件同步,但具有完整的 blob(具有自己的读+计算+写组合)来隐藏命令队列之间的高得多延迟。通过添加另一个 true 值来启用驱动程序控制的流水线。
f.compute(gpu, 1, "test0", 1024,64,0,true,true);
这需要更多的 CPU 线程来控制所有 blob 的上传和下载数据。有些系统使用事件驱动的流水线效果更好,其中独立的读操作可以隐藏独立的计算,或者独立的写操作;而有些系统使用驱动程序控制的版本效果更好。
流水线的 blob 数量必须至少为 4 且必须是 4 的倍数,默认为 4。此值可以通过在流水线类型之后添加它来更改。
f.compute(gpu, 1, "test0", 1024*1024,64,0,true,true,128); // 128 blobs per device
有时即使是流水线也不够,因为 C# 数组和 C++ OpenCL 缓冲区之间存在不必要的复制,此时可以调整数组包装器的某个字段以实现零复制访问。
f.fastArr = true;
这会立即创建一个 C++ 数组,将 C# 数组的值复制到此 C++ 数组中,并将其用于它调用的所有计算方法。如果它将被使用多次,它将大大减少 GPU 到主机的访问时间。如果开发人员需要立即开始使用 C++,
ClArray<float> f = new ClArray<float>(1024);
这会默认创建并使用 C++ 数组。还有一个 ClFloatArray 可以作为初始化传递给它。API 提供了这些用于数组的类型:float、double、int、uint、char、byte、long。
ClNumberCruncher 类会自动处理 CPU、iGPU 和任何其他共享内存的设备作为流式处理器,以利用内核内的零复制读/写。这在计算数据比的场景较低时特别有用,例如开头提到的“加 PI”示例。
流式处理选项也对所有设备默认启用,因此设备可能不会使用专用内存。
当开发人员需要禁用此功能以供独立 GPU 使用时,需要将一个参数设置为 false。
ClNumberCruncher gpu = new ClNumberCruncher(AcceleratorType.GPU | AcceleratorType.CPU, @"
__kernel void test0(__global float * a)
{
int i=get_global_id(0);
a[i]+=3.14f;
}
",-1,-1,false);
开发人员还可以更显式地选择用于 GPGPU 的设备。
Hardware.ClPlatforms platforms = Hardware.ClPlatforms.all();
var selectedDevices = platforms.platformsIntel().devicesWithHostMemorySharing();
ClNumberCruncher gpu = new ClNumberCruncher(selectedDevices, @"
__kernel void test0(__global float * a)
{
int i=get_global_id(0);
a[i]+=3.14f;
}
");
上面的示例选择了所有 Intel 平台,然后选择了它们中所有共享系统 RAM 的设备,从而有效地选择了 CPU 及其 iGPU,这对于流式传输数据更好。有很多不同的方法可以根据设备的特定功能(如内存大小、计算单元数量和基准测试(未来版本))来选择设备。
当性能不令人满意时,需要仔细优化缓冲区复制。Cekirdekler API 的默认行为是将所有数组复制到所有设备缓冲区,进行计算,然后从所有设备读取部分结果。这会将一些未使用的相同数据复制到所有设备。当需要设备仅读取它们自己的部分数组时,需要设置一个字段。
array.partialRead=true;
然后,如果设备 1 计算数组的 50%,那么它只读取数组的 50%,设备 2 读取其余部分。然后,在计算完成后,两个设备都将结果写入数组。
有几个标志可以告知 API 如何处理缓冲区。
array.read
array.partialRead
array.write
"read" 指示 API 在计算之前将数组作为整体读取(除非设置了 partial)。
"write" 指示 API 将部分地写入数组,与 partialRead 相反。
如果只有一个设备,并且需要多次计算一个数组而无需与主机之间进行复制,那么所有三个字段都需要设置为 false。
缓冲区处理的另一个重要部分是“每个工作项的数组元素”值。API 将此值解释为对所有工作项都相同。例如,如果有 1024 个工作项,并且每个工作项只加载、计算、写入 float4 类型变量,那么开发人员负责在使用主机端的 float 数组时为 elementsPerWorkItem 值选择“4”。
f.numberOfElementsPerWorkItem = 4;
上面的示例启用了 4 倍的元素复制到设备。如果一个设备运行 400 个工作项,那么该设备现在从数组中获得 1600 个 float 元素。第一个工作项处理元素 0-3,第二个工作项处理元素 4-7,依此类推。
从控制台获取一些有用的信息(未来版本将是文件)也很容易。
已选平台
Cekirdekler.Hardware.ClPlatforms platforms = Cekirdekler.Hardware.ClPlatforms.all(); platforms.logInfo();
已选设备
Cekirdekler.Hardware.ClPlatforms platforms = Cekirdekler.Hardware.ClPlatforms.all(); var selectedDevices = platforms.platformsIntel().devicesWithHostMemorySharing(); selectedDevices.logInfo();
负载均衡器在每次 compute 方法调用时分配工作项
numberCruncher.performanceFeed = true; // set this before first compute
您可以在 github 存储库的 wiki 页面上找到更详细的信息。
引用重要信息:如果总工作量是盐或沙,那么负载均衡器会在设备之间交换颗粒。颗粒大小等于局部工作组大小乘以流水线 blob。如果禁用了流水线,那么颗粒大小就是局部工作组大小。如果颗粒大小相对于全局大小非常小,那么负载均衡就会变得更精细。
当系统中存在 M 个 GPU 时,全局大小必须至少是 M * Grain size。
每个设备必须至少有 1 个颗粒(例如,256 个线程)。设备不能完全卖掉所有颗粒。
增加流水线会增加颗粒大小,从而使负载均衡更困难。
与缓冲区类似,现在需要记住:将所有内容乘以数组的“numberOfElementsPerWorkItem”以了解它复制了多少数据。
示例:2k 个工作项分配给 2 个设备,分别为 1.5k 和 512。如果流水线已激活(4 个 blob)且工作组大小为 128,那么这两个设备只能交换 512 个工作项,并且最少有 512 个工作项。这是一个非常糟糕的负载均衡示例,颗粒不够细。现在假设内核使用 float16,但主机端提供了一个字节数组(就像它直接来自 TCP-IP 一样),那么开发人员需要将字节数组的“numberOfElementsPerWorkItem”值设置为 16*4,因为每个 float 是 4 个字节,每个工作项使用 16 个 float 结构。
未使用。
内核可以通过名称重复运行,或者不同的内核可以连续运行,它们之间用空格、逗号、分号、换行符“\n”或连字符分隔。(这些重复不会改变负载分区,会被视为一次操作)(似乎只适用于单设备使用)
f.compute(gpu, 1, "findParticles buildBoxes findNeighbors,calculateForces;moveParticles", 1024);
编辑-2:具有高数据重用率但数据计算比低 O(N²) 算法的示例
代码
Cekirdekler.Hardware.ClPlatforms platforms = Cekirdekler.Hardware.ClPlatforms.all();
var selectedDevices = platforms.platformsIntel().devicesWithHostMemorySharing(true);
selectedDevices.logInfo();
ClNumberCruncher gpu = new ClNumberCruncher(selectedDevices, @"
__kernel void algorithmTest(__global float4 * a,__global float4 * b)
{
int i=get_global_id(0);
float4 accumulator=(float4)(0.0f,0.0f,0.0f,0.0f);
for(int j=0;j<4096;j++)
{
float4 difference=a[i]-a[j];
accumulator+=(difference*difference);
}
b[i]=sqrt(accumulator);
}
");
ClArray<float> f = new ClArray<float>(4096*4);
f.numberOfElementsPerWorkItem = 4;
f.write = false;
f.partialRead = true;
ClArray<float> g = new ClArray<float>(4096*4);
g.numberOfElementsPerWorkItem = 4;
g.read = false;
gpu.performanceFeed = true;
for(int i=0;i<25;i++)
f.nextParam(g).compute(gpu, 1, "algorithmTest", 4096,64);
这个 opencl 内核每个工作项每个计算执行 4096*4*(1 次减法 + 1 次加法 + 1 次乘法) 次。主机端执行 4096 个工作项,因此每次 compute 方法执行 2.01 亿次浮点运算和 537MB 的内存访问。当负载均衡器收敛时,iGPU 以 5ms 的速度完成大部分工作,这意味着 40.2 GFLOPs(占理论最大值的 35%),因为最内层循环中的数据计算比很低。CPU 无法接近,因为 CPU 还充当 OpenCL 设备的调度器。
iGPU 有 12 个计算单元 = 96 个着色器
CPU 有 2 个核心但只选择 1 个核心 = 4 个算术逻辑单元
输出
1 cores are chosen for compute(equals to device partition cores). --------- Selected devices: #0: Intel(R) Celeron(R) CPU N3060 @ 1.60GHz(Intel(R) Corporation) number of compute units: 1 type:CPU memory: 3.83GB #1: Intel(R) HD Graphics 400(Intel(R) Corporation) number of compute units: 12 type:GPU memory: 1.52GB --------- Compute-ID: 1 ----- Load Distributions: [50.0%] - [50.0%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 1,278.48ms, workitems: 2,048 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 21.15ms, workitems: 2,048 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [35.9%] - [64.1%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 742.94ms, workitems: 1,472 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 21.16ms, workitems: 2,624 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [25.0%] - [75.0%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 532.38ms, workitems: 1,024 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 16.43ms, workitems: 3,072 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [17.2%] - [82.8%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 361.98ms, workitems: 704 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 22.07ms, workitems: 3,392 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [12.5%] - [87.5%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 271.71ms, workitems: 512 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 10.75ms, workitems: 3,584 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [9.4%] - [90.6%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 185.23ms, workitems: 384 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 5.56ms, workitems: 3,712 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [6.3%] - [93.8%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 131.08ms, workitems: 256 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 15.73ms, workitems: 3,840 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [4.7%] - [95.3%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 90.93ms, workitems: 192 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 5.82ms, workitems: 3,904 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 75.73ms, workitems: 128 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 13.49ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [4.7%] - [95.3%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 101.55ms, workitems: 192 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 6.33ms, workitems: 3,904 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 100.61ms, workitems: 128 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 35.24ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 80.28ms, workitems: 128 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 6.82ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 86.85ms, workitems: 128 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 18.15ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 99.78ms, workitems: 128 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 12.82ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 86.12ms, workitems: 128 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 23.98ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 76.66ms, workitems: 128 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 5.47ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 81.75ms, workitems: 128 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 19.97ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 66.52ms, workitems: 128 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 6.36ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 78.79ms, workitems: 128 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 7.36ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 80.02ms, workitems: 128 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 15.07ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 69.05ms, workitems: 128 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 5.79ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 81.47ms, workitems: 128 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 6.99ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 70.18ms, workitems: 128 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 4.88ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [1.6%] - [98.4%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 34.74ms, workitems: 64 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 8.58ms, workitems: 4,032 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [1.6%] - [98.4%] ------------------------------------------------------ Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 42.93ms, workitems: 64 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 10.67ms, workitems: 4,032 -----------------------------------------------------------------------------------------------------------------
现在是同一个程序在一个 FX8150 + R7-240(强大得多)系统上运行
Compute-ID: 1 ----- Load Distributions: [50.0%] - [50.0%] ----------------------------------------------------- Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 197.44ms, workitems: 2,048 Device 1(gddr): Oland ||| time: 95.84ms, workitems: 2,048 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [45.3%] - [54.7%] ----------------------------------------------------- Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 136.6ms, workitems: 1,856 Device 1(gddr): Oland ||| time: 80.23ms, workitems: 2,240 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [42.2%] - [57.8%] ----------------------------------------------------- Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 117.06ms, workitems: 1,728 Device 1(gddr): Oland ||| time: 5.86ms, workitems: 2,368 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [31.3%] - [68.8%] ----------------------------------------------------- Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 82.22ms, workitems: 1,280 Device 1(gddr): Oland ||| time: 2.12ms, workitems: 2,816 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [21.9%] - [78.1%] ----------------------------------------------------- Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 55.55ms, workitems: 896 Device 1(gddr): Oland ||| time: 2.06ms, workitems: 3,200 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [15.6%] - [84.4%] ----------------------------------------------------- Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 51.72ms, workitems: 640 Device 1(gddr): Oland ||| time: 2.22ms, workitems: 3,456 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [10.9%] - [89.1%] ----------------------------------------------------- Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 76.16ms, workitems: 448 Device 1(gddr): Oland ||| time: 65.09ms, workitems: 3,648 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [10.9%] - [89.1%] ----------------------------------------------------- Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 51.23ms, workitems: 448 Device 1(gddr): Oland ||| time: 27.52ms, workitems: 3,648 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [9.4%] - [90.6%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 57.61ms, workitems: 384 Device 1(gddr): Oland ||| time: 18.26ms, workitems: 3,712 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [10.9%] - [89.1%] ----------------------------------------------------- Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 29.48ms, workitems: 448 Device 1(gddr): Oland ||| time: 2.06ms, workitems: 3,648 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [10.9%] - [89.1%] ----------------------------------------------------- Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 28.99ms, workitems: 448 Device 1(gddr): Oland ||| time: 29.28ms, workitems: 3,648 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [9.4%] - [90.6%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 29.65ms, workitems: 384 Device 1(gddr): Oland ||| time: 3.96ms, workitems: 3,712 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [7.8%] - [92.2%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 27.39ms, workitems: 320 Device 1(gddr): Oland ||| time: 2.13ms, workitems: 3,776 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [6.3%] - [93.8%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 30.99ms, workitems: 256 Device 1(gddr): Oland ||| time: 15.85ms, workitems: 3,840 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [6.3%] - [93.8%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 29.29ms, workitems: 256 Device 1(gddr): Oland ||| time: 2.59ms, workitems: 3,840 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [6.3%] - [93.8%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 28.12ms, workitems: 256 Device 1(gddr): Oland ||| time: 3.13ms, workitems: 3,840 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [6.3%] - [93.8%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 29.39ms, workitems: 256 Device 1(gddr): Oland ||| time: 2.21ms, workitems: 3,840 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [4.7%] - [95.3%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 24.06ms, workitems: 192 Device 1(gddr): Oland ||| time: 2.65ms, workitems: 3,904 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [4.7%] - [95.3%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 43ms, workitems: 192 Device 1(gddr): Oland ||| time: 3.3ms, workitems: 3,904 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 24.02ms, workitems: 128 Device 1(gddr): Oland ||| time: 2.49ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 24.75ms, workitems: 128 Device 1(gddr): Oland ||| time: 2.9ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 34.34ms, workitems: 128 Device 1(gddr): Oland ||| time: 2.71ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 26.74ms, workitems: 128 Device 1(gddr): Oland ||| time: 2.54ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 23.89ms, workitems: 128 Device 1(gddr): Oland ||| time: 2.66ms, workitems: 3,968 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [3.1%] - [96.9%] ------------------------------------------------------ Device 0(stream): AMD FX(tm)-8150 Eight-Core Proce ||| time: 23.71ms, workitems: 128 Device 1(gddr): Oland ||| time: 2.61ms, workitems: 3,968 -----------------------------------------------------------------------------------------------------------------
更强的 GPU 会胜过更强的 CPU。这可能是因为 CPU 实现没有足够的寄存器来处理所有线程,并且正在进行的线程更少,内存也更慢(API 缓冲区复制也使用相同的内存)。
使用相同的宿主代码但使用不同的内核和 400 万个工作项和 1600 万个数组元素的流式传输数据的示例
__kernel void algorithmTest(__global float4 * a,__global float4 * b)
{
int i=get_global_id(0);
b[i]=2.0f+a[i];
}
即使是单个 CPU 核心也具有与其 iGPU 相当的流式传输性能
输出
Compute-ID: 1 ----- Load Distributions: [50.0%] - [50.0%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 274.97ms, workitems: 2,097,152 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 109.74ms, workitems: 2,097,152 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [43.6%] - [56.4%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 44.11ms, workitems: 1,826,944 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 59.08ms, workitems: 2,367,360 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [45.7%] - [54.3%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 62.52ms, workitems: 1,918,400 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 16.6ms, workitems: 2,275,904 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [37.5%] - [62.5%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 86.73ms, workitems: 1,573,056 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 46.12ms, workitems: 2,621,248 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [33.5%] - [66.5%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 42.76ms, workitems: 1,405,568 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 59.51ms, workitems: 2,788,736 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [35.8%] - [64.2%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 36.81ms, workitems: 1,502,656 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 37.58ms, workitems: 2,691,648 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [36.0%] - [64.0%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 42.64ms, workitems: 1,508,672 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 41.78ms, workitems: 2,685,632 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [35.8%] - [64.2%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 35.24ms, workitems: 1,502,720 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 43.96ms, workitems: 2,691,584 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [37.4%] - [62.6%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 47.63ms, workitems: 1,568,512 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 47.72ms, workitems: 2,625,792 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [37.1%] - [62.9%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 40.25ms, workitems: 1,555,200 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 26.12ms, workitems: 2,639,104 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [36.2%] - [63.8%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 43.01ms, workitems: 1,517,760 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 39.6ms, workitems: 2,676,544 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [35.7%] - [64.3%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 51.87ms, workitems: 1,498,816 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 31.02ms, workitems: 2,695,488 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [34.6%] - [65.4%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 43.02ms, workitems: 1,452,992 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 33.43ms, workitems: 2,741,312 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [34.2%] - [65.8%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 49.68ms, workitems: 1,434,624 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 22.51ms, workitems: 2,759,680 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [33.7%] - [66.3%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 46.59ms, workitems: 1,415,296 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 41.88ms, workitems: 2,779,008 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [33.1%] - [66.9%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 26.05ms, workitems: 1,389,440 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 39.56ms, workitems: 2,804,864 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [32.9%] - [67.1%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 39.74ms, workitems: 1,379,648 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 34.79ms, workitems: 2,814,656 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [32.6%] - [67.4%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 39.8ms, workitems: 1,365,888 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 33.18ms, workitems: 2,828,416 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [32.0%] - [68.0%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 49.77ms, workitems: 1,340,736 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 31.22ms, workitems: 2,853,568 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [31.1%] - [68.9%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 41.33ms, workitems: 1,304,640 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 40.6ms, workitems: 2,889,664 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [30.6%] - [69.4%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 49.4ms, workitems: 1,283,264 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 38.03ms, workitems: 2,911,040 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [30.0%] - [70.0%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 42.96ms, workitems: 1,257,024 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 41.33ms, workitems: 2,937,280 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [29.7%] - [70.3%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 42.62ms, workitems: 1,243,904 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 31.64ms, workitems: 2,950,400 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [29.3%] - [70.7%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 45.05ms, workitems: 1,228,032 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 32.9ms, workitems: 2,966,272 ----------------------------------------------------------------------------------------------------------------- Compute-ID: 1 ----- Load Distributions: [29.1%] - [70.9%] ----------------------------------------------------- Device 0(stream): Intel(R) Celeron(R) CPU N3060 ||| time: 41.57ms, workitems: 1,222,144 Device 1(stream): Intel(R) HD Graphics 400 ||| time: 39.57ms, workitems: 2,972,160 -----------------------------------------------------------------------------------------------------------------
更新日志(v1.1.5)
- 在 compute() 方法中
- 添加了全局工作项数量与局部工作项边界检查
- 添加了数组边界检查(不检查全局偏移值)(不检查内核参数类型)
- 如果越界,则在控制台消息之后立即返回,并在将来的 compute 方法中提前退出。
- 隐藏了无用的 ClDevices 构造函数,设备选择从 ClPlatforms.all() 开始,并以返回 ClDevices 的 devices____ 命名的方法结束。
- 其他
-
当内核参数解释不同类型的宿主数组时,必须满足元素对齐条件。
-
在显式选择设备时,无需在 ClNumberCruncher 构造函数的 number-of-cores 和 number-of-gpus 参数中都放入 -1(这些参数现在仅用于隐式设备选择)。
更新日志(v1.1.6)
- 集群计算相关类的英文翻译(预 Alpha 版)
- 重命名一些类文件以使用正确的名称
- 添加了少量文档
更新日志(v1.1.9)
- 现在用户定义的结构数组可以被 byte 类型的 ClArray 包裹,例如
xyzoGPU = ClArray<byte>.wrapArrayOfStructs(vertices);
在上面的示例中,vertices 是 Vector3 的数组(这是来自一个正在工作的 Unity 示例)。
这会自动设置“numberOfElementsPerWorkItem”属性,使其与每个结构对应的字节数一致,因此无需设置它,但可以获取它进行查看。
注意!OpenCL 对 float3(内核端结构)的解释因供应商而异。因此,请将 Vector3 和类似的 3D 元素视为纯浮点数,并将索引乘以 3,为 y 加 1,为 z 加 2(x 已经是 + 零)。
更新日志(v1.2.0)
- 添加了设备到设备流水线功能。这允许开发人员并发使用多个 GPU 处理要连续运行的不同内核。双缓冲会自动处理,以重叠所有流水线阶段的计算和数据移动操作,以隐藏它们的延迟。演示如下:https://www.youtube.com/watch?v=pNIBzQvc4F8,这里是关于它的 wiki 页面:https://github.com/tugrul512bit/Cekirdekler/wiki/Pipelining:-Device-to-Device
- 删除了“Copy Memory”依赖项,现在它更能适应 Unity 游戏引擎(仍然是 Windows)。
- 向 ClNumberCruncher 添加了 `normalizedGlobalRangesOfDevices(int id)` 和 `normalizedComputePowersOfDevices()`,以便直接从客户端代码查询一些性能信息(而无需设置 performanceReport 标志)。
这是一个展示流水线如何工作的 gif
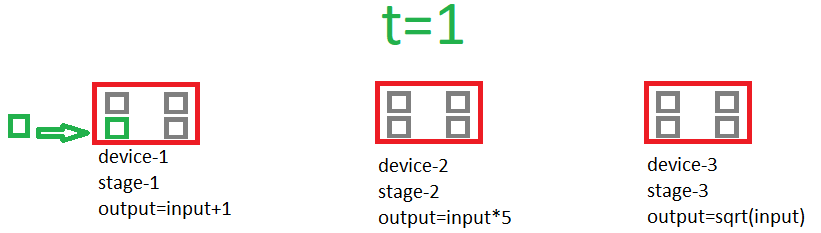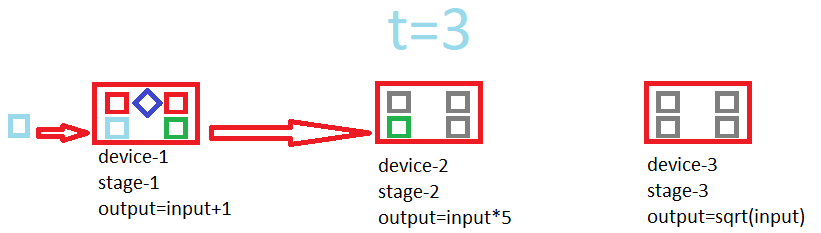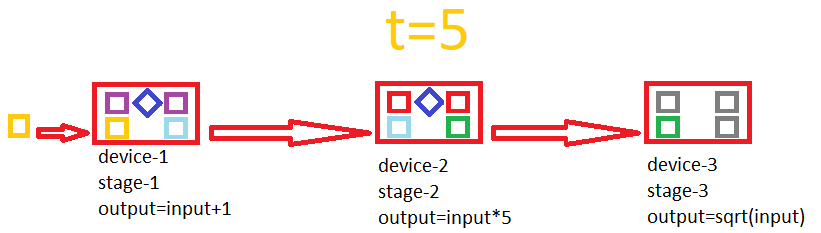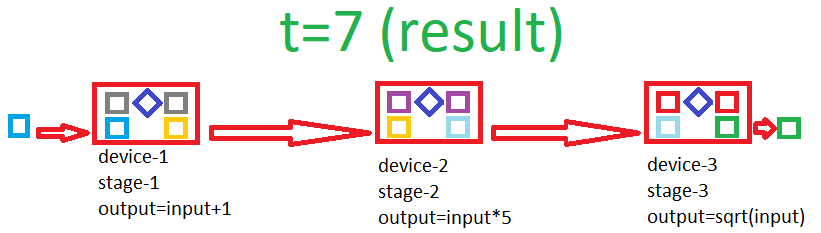
构建流水线的示例
计算 x+1 的单阶段
Hardware.ClDevices gpu1 = Hardware.ClPlatforms.all().devicesWithMostComputeUnits()[0];
Pipeline.ClPipelineStage add = new Pipeline.ClPipelineStage();
add.addDevices( gpu1);
ClArray<float> inputArrayGPU1 = new ClArray<float>(1024);
ClArray<float> outputArrayGPU1 = new ClArray<float>(1024);
add.addInputBuffers(inputArrayGPU1);
add.addOutputBuffers(outputArrayGPU1);
add.addKernels(@"
__kernel void vecAdd(__global float * input, __global float * output)
{
int id=get_global_id(0);
output[id]=input[id]+1.0f;
}", "vecAdd", new int[] { 1024/*global range*/ }, new int[] { 256/* local range*/ });
计算 x*5 的单阶段
Hardware.ClDevices gpu2 = Hardware.ClPlatforms.all().devicesWithMostComputeUnits()[1];
Pipeline.ClPipelineStage mul = new Pipeline.ClPipelineStage();
mul .addDevices( gpu2);
ClArray<float> inputArrayGPU2 = new ClArray<float>(1024);
ClArray<float> outputArrayGPU2 = new ClArray<float>(1024);
mul .addInputBuffers(inputArrayGPU2);
mul .addOutputBuffers(outputArrayGPU2);
mul .addKernels(@"
__kernel void vecMul(__global float * input, __global float * output)
{
int id=get_global_id(0);
output[id]=input[id]*5.0f;
}", "vecMul", new int[] { 1024/*global range*/ }, new int[] { 256/* local range*/ });
将两个阶段绑定在一起并创建流水线
add.prependToStage(mul); // prepends add stage to mul stage var pipeline = add.makePipeline(); // creates a 2-stage pipeline out of add and mul.
将数据推入流水线,将结果获取到数组中
if(pipeline.pushData(new object[] { arrayToGetData }, new object[] { arrayToReceiveResult }))
{
Console.WriteLine("Needs M*2+1 iterations");
Console.WriteLine("Extra client arrays for both inputs and outputs of pipeline");
Console.WriteLine("First result is ready!");
}
if(pipeline.pushData())
{
Console.WriteLine("Needs M*2-1 iterations");
Console.WriteLine("input of first stage and output of last stage are directly accessed");
}
现在它计算数组中每个元素的 (x+1)*5,并并发使用两个 GPU,每个 GPU 处理一个阶段,同时通过双缓冲移动数据。
更新日志(v1.2.1)
- 减少了每个“设备到设备流水线阶段”的命令队列消耗,以便为更多阶段腾出空间。
更新日志(v1.2.2)
-
现在可以在 buildPipeline() 方法中自动使用该方法中提供的参数来初始化设备到设备流水线阶段。
stage.initializerKernel("kernelName", new int[] { N }, new int[] { 256 });
更新日志(v1.2.3)
-
可以使用“@”分隔符将“设备到设备流水线阶段”中的多个内核名称分组,而不是使用“”,“”,“;”分隔符,这样它们只在第一个内核之前从主机读取一次输入,并在最后一个内核之后将输出写入主机。没有“@”,每个内核都会读写输入和输出,这使得“多内核阶段”变慢。
以“@”分隔的内核被视为一个内核,因此它们都使用单一的全局-局部范围值。
“a@b@c” N : 256 1 次读取 1 次写入
“a b@c” N,M : 256,128 2 次读取 2 次写入
更新日志(v1.2.4)
-
修复了与“performanceFeed”标志相关的控制台输出算法中的一个小错误。
更新日志(v1.2.5)
-
可以通过 loginfo 查询显式设备实例的设备名称(返回多行字符串,每行代表一个不同的设备,并带有供应商名称)。
更新日志(v1.2.6)
-
向 Number cruncher 添加了内核重复功能。减少了数百个内核上的 API 开销累积。
兼容 CekirdeklerCPP v1.2.6+
更新日志(v1.2.7)
-
为 numberCruncher 和设备到设备流水线阶段添加了 enqueueMode 标志,这样它们就可以通过单次主机和设备之间的同步执行数千次操作(对于轻负载工作量,速度提高高达 60 倍)。这只适用于单 GPU 非驱动程序流水线非事件流水线的 compute() 操作。但可用于设备到设备流水线。现在可以入队不同的全局范围和局部范围(每个内核)而无需回退到“设备到设备”或“重复”功能,轻负载工作量可获得 60 倍的性能(例如,仅 1024 个线程的向量加法)。
更新日志(v1.2.8)
-
减少了不必要的 clSetKernelArg 问题。
添加了 `ClArray.writeAll` 以将结果数组作为一个整体获取,而不是只获取一部分元素。类似于 `ClArray.read = true and ClArray.partialRead=false` 的非部分读取。如果使用了多个 GPU,每个 GPU 只写入 1 个结果数组(而不是写入相同的数组,这会导致未定义行为)。
修复了一个 C# char 数组错误(在传递给 C++ 时未获取其数据的真实指针)。
修复了 Enqueue 模式性能查询错误(未能提供准确的时间),现在可以通过 clNumberCruncher.lastComputePerformanceReport() 进行查询。
更新日志(v1.2.9)
-
为 ClArray 类添加了 readOnly 和 writeOnly 属性,以便当一个数组只被读取而另一个只被写入时,一些内核可以提高高达 10% 的性能。
例如,该内核通过为第一个参数设置 readOnly,为第二个参数设置 writeOnly,性能提高了 10%。
__kernel void test(const __global float * data,__global float * data2)
{
int id=get_global_id(0);
for(int i=0;i<50;i++)
data2[id]=sqrt(data[id]);
}
更新日志(v1.2.10)
- 向 Number cruncher 添加了异步入队模式。这允许一些操作在时间线上重叠以节省更多时间并将 GPU 推向极限。最多可以使用 16 个队列,并且仅适用于单设备(每个 ClNumberCruncher 实例)。可以使用此功能构建自定义“流水线”。
更新日志(v1.2.11 和 v1.2.12)
- 添加了单 GPU 流水线子功能。这会隐式使用异步入队模式,并允许用户使用所有阶段重叠在时间线上的“流水线”。例如,一个 5 阶段的流水线可以并发计算所有阶段,并节省大量时间以获得更高的计算吞吐量。
-
为“流水线”添加了并发级别选项,以将命令队列的数量限制在 1 到 16 之间。
矩阵乘法流水线示例
https://www.youtube.com/watch?v=Uuk-9El6K1U
图像处理(模糊、旋转、缩放、混合)流水线示例:
https://www.youtube.com/watch?v=tw3csfV57fc
更新日志(v1.3.2)
- 根据计算 ID + 内核名称生成多个内核实例(减少 clsetkernelarg() 调用次数,并实现使用相同内核名称和不同参数的异步队列计算)(用于任务池 + 设备池的平铺计算)。
- 添加了任务(稍后在 compute() 中执行)。
- 添加了任务池和设备池功能(不可分离的内核通过贪婪算法分配给设备)。
更新日志 v1.3.3 - v1.4.1
- 添加了任务的回调选项,这有助于早期、异步地与其他 C# 部分通信。
- 为性能优化了池。
- 一些 bug 修复。
- OpenCL 2.0 动态并行支持。现在父内核可以入队子内核。设备队列的初始化(队列大小 =(首选+最大)/ 2)是自动处理的。
平滑的 k-means 聚类示例视频,使用 OpenCL 2.0 动态并行功能。
https://youtu.be/tXy8SaRULJs?t=17s
比较“批量计算”功能与“流水线”和“负载均衡”的性能。
https://www.youtube.com/watch?v=Ep-36Lpqngc
重新审视 Grainsize。
- 每个设备至少需要 1 个颗粒。然后,如果有剩余的颗粒,则由负载均衡器放置。
- 启用 N-blob 流水线会将颗粒大小乘以 N(默认为 4)。
- 增加局部范围(工作组大小或局部内存共享组的工作项数量)也会增加颗粒大小。
- 设备之间的颗粒交换在前 10 次迭代中很快,然后启用平滑处理,因此单个设备的性能突然飙升不会损坏它。
- 全局偏移参数不影响工作项数量或任何基于工作项的边界检查,但它会影响数组越界,开发人员/用户需要在运行之前检查它(可能在集群中)。
注意:有些类名称中包含“cluster”,这些类处于预 Alpha 阶段,工作方式未经优化,尚未翻译成英文(截至目前)。全局偏移参数曾被这些类使用。
注意 2:Number cruncher 对象分配 16 个队列,这可能不适用于某些设备,并且可能导致 CL_OUT_OF_RESOURCES 或 CL_OUT_OF_HOST_MEMORY,即使 RAM 未满。适用于 AMD 和 INTEL,未尝试过 NVIDIA。我甚至没有接触过任何 FPGA,我很想。我听说它们的 OpenCL 编译时间是几个小时!
注意 3:ClNumberCruncher 不检查编译器是否可用,因此,将来会添加 ClNumberCruncher 来控制逻辑,这样它会更线程安全。目前,请将所有 ClNumberCruncher 实例串行构建,并使用锁。不同 ClNumberCruncher 实例的 Compute 方法也是线程安全的,但不能在不同的线程中使用同一个实例来调用 compute 方法。
注意 4:所有设备、平台,所有对象在销毁时都会释放它们的 C++(非托管)对象,因此用户可能永远不需要 dispose() 它们(除非需要严格的内存控制)。
有关最新版本,请访问 github 存储库,如果您在 Cekirdekler API 方面遇到问题,请随时添加“issue”。
感谢您的时间。
关注点
如果您用这个 API 编写了一个完整的图像缩放器,那么只要您在机箱中添加另一个 GPU,您就会获得即时加速,无论它是否是同一供应商、同一级别。即使对其中一张卡进行超频也会对性能产生积极影响,前提是图像足够大以实现更精细的负载均衡。
历史
将在 github 中添加新功能后在此处继续添加更多内容。