
神经网络的简单完整解释
4.99/5 (51投票s)
本文还提供了一个关于神经网络的实际示例。在这里,您可以了解人脑在审视人工神经网络时究竟发生了什么。
引言
如今,科学家们正试图找到人脑的力量。他们试图模仿它来寻找大数据解决方案。

我认为还没有一篇关于神经网络的全面、简单、清晰和实用的文章。我一直想知道人脑在生物学上是如何工作的。我有很多问题没有得到解答。神经网络的细节对我来说总是模糊不清。我想回答的最重要的问题是:
- 人脑究竟是如何工作的?
- 感知器作为人工神经元是如何工作的 - 前馈神经网络?
- 神经网络中的权重是什么?
- 生物神经元中的权重等效物是什么?
- 神经网络中的激活函数的作用是什么?
- 生物神经元中的激活函数等效物是什么?
- 反向传播是如何工作的?
- 反向传播神经网络的确切数学逻辑是什么?
- 如何实现反向传播神经网络?
1. 人脑究竟是如何工作的?
要理解神经网络是如何工作的,最好研究一下人脑的运作。大脑中大约有 1011 个神经元,它们之间高度连接。当你看到一只动物,比如猫,它的特征,如大小、颜色和形状,会通过你的眼睛输入到你的大脑。然后,这些输入信息会被一些称为神经元的小细胞计算,这些神经元负责处理你大脑中的输入数据。
首先,神经元会搜索你以前见过的其他猫的图像。它们会将你记忆中的猫的旧照片与新的猫进行比较。这种比较是监督学习过程的基础,使你的大脑成为一个比较工具。这就是为什么人类倾向于比较一切。最后,你会得到回应,因为你以前见过猫,所以你说你看到了猫。

仅凭视觉,您每秒就可以处理 20 MB 的信息,这非常棒,因为它与您学习某项事物的能力、检测某人的声音或您的听觉能力无关。因此,您的大脑是一个令人难以置信的巨大 CPU。
假设这个巨大系统的小规模版本能够解决当今不同领域和领域的问题。例如,大脑特征的一小部分可以解决语音和面部或图像识别、情感分析和意见或情绪阅读、自动驾驶汽车甚至疾病诊断方面的问题。
下图有一个神经元细胞,包括树突、轴突和细胞核。请从左到右观察它。树突负责接收信息,其细胞核是数据处理的地方,结果将通过轴突传输到神经元的尾部。人工智能中一个这样的神经元的整个结构称为感知器。
右边的另一个神经元细胞会接收左边神经元的响应,通过一些化学物质引发放电。它的放电会导致数据发送和传输到其他细胞。因此,左侧神经元的输出就像右侧神经元的输入一样。这个过程会发生在其他细胞上。因此,大脑中的 1010 个神经元协同工作以实现它们各自的目标。
假设每天有多少过程需要分析才能处理您的生活。大脑可以毫无疲倦地完成所有这些工作。一天结束时,您只需要 7 小时来冷却这些小细胞。神经科学家发现,更多的学习可以让您的树突更强壮,因为点燃神经元细胞之间的连接几乎就像锻炼肌肉一样。因此,使用大脑不太可能患上阿尔茨海默病。

2. 感知器作为人工神经元是如何工作的 - 前馈神经网络?
下图您可以看到一个简单的感知器及其计算输出的操作。首先,有两个输入 X1 和 X2,然后每个连接到节点的连接都有权重。在神经网络中,所有的处理单元都是节点,与拥有复杂处理单元的计算机系统不同,神经网络拥有简单的处理单元。我们将两个数字(X 和权重)相乘。
然后我们将所有 X*权重相加,并将激活函数应用于结果值,最终输出就是感知器的答案。

上面一段的整个过程称为神经网络中的前向传播。但实际上,我们使用更多的节点和多层来进行神经网络学习。我提到我们的大脑有数十亿层,这个巨大的系统造就了我们今天的人类。因此,为了获得更好的学习效果,我们使用更多的层。这几乎可以保证在神经网络的学习或训练中取得结果的改进。下图中有两个隐藏层(浅蓝色)。每个节点的计算将像一个简单的感知器一样进行。


3. 神经网络中的权重是什么?
权重是指节点之间连接的强度。权重的无符号值(没有 +、-)取决于节点之间连接的强度。
它可以是正的,也可以是负的。正值意味着更有可能传输数据,并在神经元之间建立强连接,而负值则相反。在初始化时,我们随机选择权重,但为了获得合理的结果,最好对输入数据进行归一化,如下所示,X 是输入数据。

因为本文中的激活函数是 sigmoid。随机选择权重的快捷解决方案是确定权重值的特定范围,如下面的公式所示,该公式取决于均匀分布,我在此省略了其逻辑,将在下一篇文章中进行扩展。

以上公式的参考资料是:深度学习教程;Glorot 和 Bengio (2010)
我提到神经网络是高度互联的,权重是使这种连接最有价值的元素。我们在初始阶段随机选择权重值。首先,前向传播从左到右进行。
然后,比较输出值与真实值之间的差异。真实值是训练数据集中标记为“Y”的值。然后进行反向传播计算,该计算以反向路径执行。
前向传播是从左到右,而反向传播是从右到左,以优化并获得新的权重以增强下一个输出。如果下一个输出值与“Y”的差异小于前一个输出值,那么它表明我们走在正确的方向上。
因此,权重是连接节点的一种工具,也是训练神经网络以减少错误的一个因素。BP、FP 和权重校准将反复进行测量,以获得新的权重值和准确的输出,从而降低错误。
为了更好地理解权重在神经网络中的作用,我邀请您阅读我关于“机器学习与梯度下降”的文章。神经网络中的权重几乎与 Yprediction 线 Y = aX + b 中的斜率“a”非常相似。精确的“a”值可以帮助我们找到更好的预测线来对数据进行分类。在神经网络中,权重也像“a”这样的一个因素,我们努力准确地找到它的值以获得更精确的分类。
4. 生物神经元中的权重等效物是什么?
神经网络结构中的一切都受到人脑的启发。因此,权重的无符号值意味着:神经元之间的树突连接 + 树突之间的突触数量 + 突触前后端 + 神经元之间的间隙形状 + 融合强度;最后但同样重要的是髓鞘形成。
髓鞘是神经元细胞轴突周围白色脂肪状物质,它就像它们的鞘或保护层。下图右侧有髓鞘的神经元上传播速度远快于左侧没有鞘的神经元。这种现象是由于跳跃式传导引起的。
传播次数及其速度可以产生更多、更强的突触。这些因素在我们大脑中获得更好的学习方面起着重要作用。对一个人大脑功能更好的人进行功能性磁共振成像 (FMRI) 活动显示,有更多的突触和更多的红点。
因此,神经网络中的权重在生物学上与上述因素的组合相同。
https://en.wikipedia.org/wiki/Myelin

5. 神经网络中激活函数的作用是什么?
激活函数(尽管有点)等同于极化和稳定。我想举一个例子来介绍极化和数学中的稳定。为了便于计算,我们需要对值进行一些极化,特别是小数。例如,我们有 1.298456,我们只需要一位小数来四舍五入和极化,以便进行简单快速的计算。我们将 1.298456 转换为 1.3,因为十进制数 2 后面的数字是 9,大于 5,所以我们将 2 转换为 3。在这些情况下,四舍五入可以帮助获得更优雅的值和结果。
在神经网络中,我们希望更好地区分和预测。因此,非线性函数有更多的四舍五入和弯曲。请看下图。与线性和非线性函数相比,显然非线性函数在预测方面更准确,并且具有更好的边界决策线来区分两个不同的类别。

我在梯度下降中使用了“均方误差 SSE”。神经网络的激活函数应该是非线性函数,如指数或正切,并且必须是可微的,因为在反向传播中,我们需要找到全局最小值。事实上,反向传播执行梯度下降。请通过此链接阅读有关梯度下降的文章。
均方误差 (SSE) = ½ Sum (Yactual– Ypredicted)2

SSE 测量 Yactual 和 Ypredicted 之间的误差值。因此,为了获得比上图蓝色线条更好的预测线,我们对 SSE 求导并计算这条线的新的斜率。
您可以选择以下函数之一作为您的激活函数。供参考,请查看此链接。
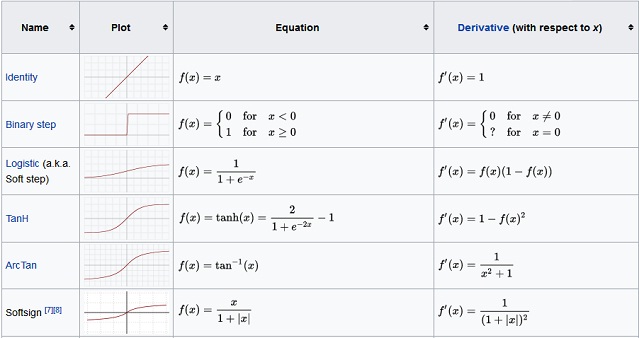
6. 生物神经元中激活函数的等效物是什么?
神经网络中的激活函数称为传递函数。神经网络中的传递函数根据节点的输入为其生成输出。激活函数在生物学中称为动作电位,它与信号如何在轴突中传输有关。
化学物质产生电脉冲,刺激神经元及其轴突,以便在神经元的单一方向上传输信号。它有助于为当前神经元产生结果。供参考,请查看此链接。

7. 反向传播是如何工作的?
为了总结以上所有概念,我想将反向传播分为以下几个步骤:
- 初始步骤是训练数据集,其中有一个或多个列用于 X 作为输入,一个标签用于 Y,应读取并考虑。因此,定义了输入层和输出层的数量。
- 我们需要选择隐藏层的数量;隐藏层的数量决定了学习的深度。更多的隐藏层可以更好地模仿人脑并提高其准确性。但最重要的问题是,更多的隐藏层需要更多的计算,尤其是在反向传播中,并且会消耗更多的内存。
- 在定义隐藏层后,我们需要权重值,这些值是随机选择的(高斯分布),并且有一个公式,我在本文的第三部分已经解释过3. 神经网络中的权重是什么?
*前向传播以达到输出值:
每一层都有一个节点,我为它们假设了两个值,第一个是没有应用 sigmoid 函数的,称为“Input_sigma”或“hidden_sigma”,下一个是应用了 sigmoid 函数的,称为“hidden_node”、“output_node”。然后我们从左到右开始计算前向传播。
Input_sigma = input_node * weight_1hidden_node = Sigmoid (input_sigma)hidden_sigma = hidden_node * weight_2Sigmoid (hidden_sigma) = output_nodemargin_error = expected – output_node*反向传播以获得更好的权重:
在反向传播中,因为我们需要最优值,所以我们从 sigmoid 函数求导,并从右到左反向计算,以找到新的权重值。
output_node′ = Sigmoid′ (hidden_sigma) * marginweight_2 ′ = (output_node′ / hidden_node) + weight_2hidden_node ′ = (output_node′ / weight_2) * Sigmoid′ (input_sigma)weight_1 ′ = (hidden_node′ / input_node) + weight_1- 再次,我们使用新的权重和当前边际误差与先前边际误差的比较值重复步骤 1 到 5,如果当前误差小于先前误差,则表明我们走在正确的方向上。
- 我们迭代步骤 1 到 10,直到边际误差接近我们的“
Y”。
8. 反向传播神经网络的确切数学逻辑是什么?
反向传播与梯度下降执行方式相同,我们需要激活函数的导数。我将其计算描述如下:
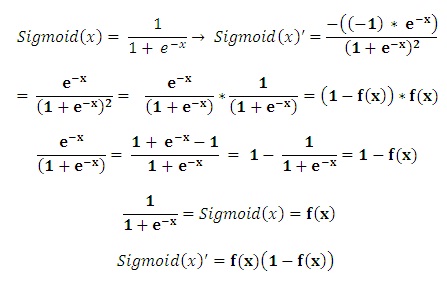
XOR 是测试我们第一个神经网络的最简单样本之一。XOR 表有两个输入和一个输出。

我想实现 XOR 的第四行,即 (1, 1) = 0。
Y 是 0,输出是 0.68。因此,边际误差是 -0.68。下一个输出是 0.57,小于 0.68。


9. 如何实现反向传播神经网络?
执行文件
根据以上所有解释,我将在 Matlab 上实现它。首先,我创建了“execution.m”文件来调用预测函数。
%% Machine Learning - Neural Networks - Simple Example
%% Initialization
clear ; close all; clc
input_node = [1 1]; %1*2
% Generate Weight By Gausian Distribution
Weight_1 = [ -0.5 1.01 0.23 ; -0.32 -0.24 -0.12 ]; %2*3
Weight_2 = [ 0.15 1.32 -0.37 ]; %1*3
pred = mypredict(Weight_1, Weight_2, input_node);
fprintf('\Final Output Backward Propagation: %f\n', perd);
预测文件
然后我编写了“myprerdict.m”,其中大部分代码将在这里完成。
function p = mypredict(Weight_1, Weight_2, input_node)
%Forward Propagation
input_sigma = input_node*Weight_1;
hidden_node = sigmoid(input_sigma); % 1*3
hidden_sigma = hidden_node*Weight_2';
output_node = sigmoid(hidden_sigma);
for jj=1:1000
%sigmoid' = f(x)(1-f(x))
%output_node_prime = s'(inner_sigma)*margin
if jj>1
Weight_2 = Weight_2_prime;
Weight_1 = Weight_1_prime;
end
margin = 0 - output_node;
sigmoid_prime_hidden_sigma = sigmoid(hidden_sigma);
output_node_prime =
(sigmoid_prime_hidden_sigma *(1-sigmoid_prime_hidden_sigma))*margin;
delta_weight = (output_node_prime)./hidden_node; % 1*3
Weight_2_prime = Weight_2 + delta_weight;
sigmoid__prime_input_sigma = sigmoid_derivative(input_sigma);
mydivide = output_node_prime./Weight_2;
hidden_node_prime = zeros(1,3);
hidden_node_prime(1,1) = mydivide(1,1) * sigmoid__prime_input_sigma(1,1);
hidden_node_prime(1,2) = mydivide(1,2) * sigmoid__prime_input_sigma(1,2);
hidden_node_prime(1,3) = mydivide(1,3) * sigmoid__prime_input_sigma(1,3);
delta_weight_2 = hidden_node_prime'*input_node;
Weight_1_prime = Weight_1 + delta_weight_2';
input_sigma = input_node*Weight_1_prime;
hidden_node = sigmoid(input_sigma); % 1*3
hidden_sigma = hidden_node*Weight_2_prime';
output_node = sigmoid(hidden_sigma);
end
p = output_node;
end
Sigmoid 函数
function y = sigmoid(x)
y = 1.0 ./ (1.0 + exp(-x));
end
sigmoid_derivative
function y = sigmoid_derivative(x)
%sigmoid' = f(x)*(1-f(x))
sigmoid_helper_2 = zeros(1,3);
for i=1:3
a= x(1,i);
sigmoid_helper_2(1,i)= sigmoid(a)*(1-sigmoid(a));
end
y = sigmoid_helper_2;
end
关注点
我发现神经网络非常令人兴奋,我认为我们可以称之为人工智能之母。
神经网络的最大优点和缺点是:
- 对数据集进行归一化并进行最佳特征选择可以使我们在海量训练数据集中获得更准确的输出。
- 性能和准确性取决于权重,但如果您将其选择在正确的范围内,则可以提高性能和准确性。
- 反向传播比其他方式消耗更多的内存。
最后,我强烈建议您在 coursera.org 上注册机器学习课程:https://www.coursera.org/learn/machine-learning & 使用我的 github 作为作业指南。
https://github.com/Hassankashi?tab=repositories
反馈
欢迎您随时对本文发表任何反馈;很高兴看到您的意见和对本代码的投票。如果您有任何问题,请随时在此处向我提问。
历史
- 2019 年 4 月 3 日:初始版本