
"志同道合" 产生 JavaScript 中的用户-物品推荐
4.95/5 (11投票s)
在本文中,我们将讨论如何使用 SVD++、皮尔逊相关系数和基于概率的相似度计算来生成用户-物品推荐。
引言
在本文中,我们将介绍并演示一种方法,该方法可以根据近期用户网站活动日志数据生成用户-物品推荐。本文讨论的方法解决了“机器学习与人工智能挑战”提出的一些问题。
具体来说,在本文中,我们将讨论如何使用各种数据挖掘算法来解决一个问题:计算某个用户将他们在社交媒体网站上查看过的文章推荐给该网站上其他用户的概率。为了构建推荐模型,我们将使用 SVD++、皮尔逊相关系数、基于概率的相似度计算算法等著名算法。
背景
在本节中,我们将找出如何利用各种数据挖掘和人工智能机器学习算法的基础,通过执行基于模型的协同过滤 (CF) 来生成高效的用户-物品推荐。具体来说,根据给定的任务,我们的目标是构建一个适当的模型,该模型可以确定用户对他们查看过的某篇文章是正面评价还是负面评价的概率,以及根据收集和表示的每个用户活动日志的“不完整”数据,将文章推荐给其他用户。
用户-物品推荐数据模型
根据挑战任务,我们主要处理了三个数据集,其中包含有关文章、用户或描述每个用户特定活动的日志条目的特定数据。文章数据集包含一组标签,这些标签充当描述每篇文章的属性。显然,多篇文章可以具有相同的属性值,这使得可以将具有相似描述、属于同一类的最相似文章组合起来。
反过来,用户的数据集包含的关于每个用户个人偏好的信息非常少且不一致。事实上,这就是为什么我们在生成推荐时主要依赖于收集并存储在日志条目第三个数据集中的每个用户活动因素。
为了为每个用户或一组用户生成有效的推荐,我们需要
- 确定特定文章与文章之间的基于概率的相关性值,并构建相似度矩阵;
- 分析日志条目,并收集关于每篇文章的统计数据(例如,浏览次数、点赞数和点踩数等);
- 根据分析的特定日志条目,将每篇文章与一个或多个用户关联起来;
- 编码和标准化收集到的统计数据,并为每个文章条目生成因子分解向量;
- 使用 SVD++ 算法 [2] 来训练数据模型,以预测一对给定文章基于先前收集和分析的数据的相似度;
由于特定用户和文章数据实际上没有相互关联,我们将基于假设来确定用户和文章特定元组之间的相似度:文章 A 可以推荐给对文章 B 感兴趣的特定用户,当且仅当这两篇文章最相似。因此,通过确定特定文章的相似度,我们实际上是根据用户对阅读相同文章的偏好和兴趣来寻找特定用户之间的可能性。用户或文章数据已组织的模型如图 1 所示。

相似度计算
正如我们上面已经提到的,每篇文章都关联有一组描述该文章的标签。不幸的是,这些标签是字符串值,无法表示为数值。因此,为了计算一对文章的相似度,我们使用基于概率的方法,根据该方法,我们的目标是找到第一篇文章和第二篇文章的属性集中存在的不同标签的数量。然后,使用概率公理的一个简单公式,我们将该数字除以两组标签的总数。

其中
- Ns – 描述文章 i 和文章 j 的相似标签的数量;
- N – 文章 i 和文章 j 的不同标签的总数;
- S – 文章 i 和文章 j 之间的相似度度量;
具体来说,为了构建相似度矩阵,我们使用一个可以表述如下的算法。通常,根据该算法,我们需要遍历文章数据集,对于每篇文章,执行搜索以找到当前文章 i 与同一数据集中每篇文章 j 的相似度。由于相似度已被计算,我们将以下值分配给相似度矩阵的元素 R[i][j]。
收集统计数据
为了将每篇文章与对其有积极或消极活动的一个或多个用户关联起来,并计算部分概率值和构建特定的因子分解向量,我们将使用一个算法来解析活动日志数据集。根据该算法,我们将遍历文章集,对于每篇文章 i,我们将在活动日志数据集中执行搜索,以查找最近对当前文章 i 有活动的那些用户。然后,我们将匹配这些标准的每个用户映射到文章数据集中当前的文章。
此外,在此过程中,我们还将获得诸如点赞/点踩次数、下载次数或当前文章 i 的浏览次数等统计数据。这些数据用于计算部分概率值,用于预测给定文章的兴趣和受欢迎程度。
同时,我们将使用收集到的统计数据为模型学习过程构建因子分解向量。
编码数据
为了构建将在模型学习过程中使用的因子分解向量,我们将使用浏览次数、点赞数、点踩数和下载次数等统计值作为每个因子分解向量的组成部分。

在使用这些值之前,我们需要将每个值归一化,使其属于区间 [0;1],使用以下公式:
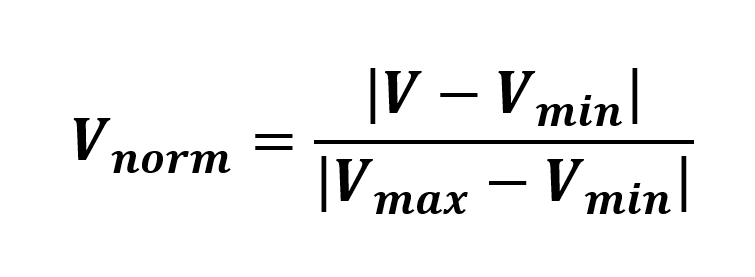
使用 SVD++ 算法训练预测模型
为了训练正在讨论的预测模型,我们将使用 [1] 中介绍和表述的 SVD++ 算法。根据以下算法,我们将需要调整每对相似文章 i 和 j 的基线预测器 Bi 和 Bj,这些调整基于随机梯度下降 (SGD) 和普通最小二乘法 (OLS) 方法。
SVD++ 算法包含以下步骤,其表述如下:
- 使用公式 (2) 计算“迄今为止”的估计评分值 \(\stackrel{\frown}{r}_{i,j} \):\(\stackrel{\frown}{r}_{i,j} =\mu +b_{i}^{U} +b_{j}^{I} +\overline{u_{i} v_{j}^{T} }\);
- 通过从上一步获得的估计评分值 \(\stackrel{\frown}{r}_{i,j}\) 中减去现有评分值,找到误差值,如下所示:\(\varepsilon _{i,j} =r_{i,j} -\hat{r}_{i,j} \);
- 计算上一步获得的误差值 \(\varepsilon _{i,j}^{2} \) 的平方,并将其添加到误差平方和中;
- 更新平均评分的当前值:\(\mu =\mu +\eta(\varepsilon _{i,j} -\lambda \mu)\)
- 更新用户 \(i\) 的基线预测器的当前值:\(b_{i}^{U} =b_{i}^{U} +\eta (\varepsilon _{i,j} -\lambda b_{i}^{U})\);
- 更新物品 \(j\) 的基线预测器的当前值:\(b_{j}^{I} =b_{j}^{I} +\eta (\varepsilon _{i,j} -\lambda b_{j}^{I})\);
- 更新用户 \(i\) 的因子分解向量中每个潜在因子的值:\(u_{i} =u_{i} +\eta(\varepsilon _{i,j} v_{j}^{T} -\lambda u_{i})\);
- 更新物品 \(j\) 的因子分解向量中每个潜在因子的值:\(v_{j}^{T} =v_{j}^{T} +\eta (\varepsilon _{i,j} u_{i} -\lambda v_{j}^{T})\)
预测模型训练过程在多个“周期”内进行。在每个周期中,我们的目标是调整所有这些系数以最小化均方误差值。我们将继续执行此过程,直到它收敛到所需的误差精度值。
皮尔逊相关系数公式
为了计算最合适的相似度值并加速预测模型学习过程,我们还将使用著名的皮尔逊相关系数公式,该公式与计算 n 维空间中两个向量之间夹角的公式密切相关。

在模型训练过程中,我们将两个因子分解向量的数量积除以皮尔逊相关系数的值。
预测
既然我们已经训练了预测模型,现在我们可以预测用户对特定文章的兴趣。要预测用户将文章推荐给一个或多个其他用户的概率,我们需要遍历文章数据集,并为每篇文章验证给定用户是否最近查看、点赞或点踩了该文章。如果是,我们将使用以下公式计算概率值:
\(\stackrel{\frown}{r}_{i,j} =\mu +b_{i}^{U} +b_{j}^{I} +\overline{u_{i} v_{j}^{T} }\);
Using the Code
<!DOCTYPE html>
<html>
<head>
<title>User-To-Item Recommender Engine v.1.0a</title>
</head>
<body>
<table border="1" style="width: 1200px;">
<tr>
<td align="center"><p style="font-size:30px;">
<b>User-To-Item Recommender Engine v.1.0a<b></p></td>
</tr>
<tr>
<td>
<form>
<div>
<label for="datafile_upload">
<strong>Upload Data File (*.txt):</strong>
</label>
<input type="file" id="datafile_upload"
accept=".txt" onchange="loadData();">
</div>
</form>
</td>
</tr>
<tr>
<td>
<table border="1">
<tr>
<td>
<table>
<tr>
<td><button onclick="renderArticles();">Articles</button></td>
<td><button onclick="renderUsers();">Users</button></td>
<td><button onclick="renderFactors();">Logs</button></td>
<td><button onclick="renderStats();">Statistics</button></td>
<td><button onclick="renderResults();">Results</button></td>
</tr>
</table>
</td>
</tr>
<tr>
<td>
<div id="train_set" style="width: 1200px;
height: 500px; overflow-y: scroll;"></div>
</td>
</tr>
</table>
</td>
</tr>
<tr><td><span id="status"></span></td></tr>
<tr>
<td>
<table>
<tr>
<td>
User: <input type="text" id="user" value="" size=200><br>
Article: <input type="text" id="article" value="" size=200><br>
<button onclick="predict();">Predict</button>
</td>
</tr>
<tr>
<td>
<table>
<tr><td><b>Recommended:</b>
<span id="rc_p"></span>%</td></tr>
<tr><td><b>Viewed:</b>
<span id="view_p"></span>%</td></tr>
<tr><td><b>Upvoted:</b>
<span id="upvote_p"></span>%</td></tr>
<tr><td><b>Downvoted:</b>
<span id="downvote_p"></span>%</td></tr>
<tr><td><b>Downloaded:</b>
<span id="download_p"></span>%</td></tr>
</table>
</td>
</tr>
</table>
</td>
</tr>
<tr>
<td>
</td>
</tr>
<tr><td align="center">
<b>CPOL (C) 2018 by Arthur V. Ratz</b></td></tr>
</table>
</body>
<script>
var users_ents = new Array();
var factors_ents = new Array();
var articles_ents = new Array();
var rel_table = new Array();
var trained = 0;
var p_avg = 0, rel_table = new Array();
var alias = [ "# Articles", "# Users", "# User actions" ];
var max_views = 0, max_upvotes = 0, max_downvotes = 0, max_downloads = 0, max_logs = 0;
function loadData()
{
var file_reader = new FileReader();
var fp = document.getElementById("datafile_upload");
file_reader.onload = function() {
var contents = file_reader.result;
var lines_array = contents.split("\r");
var is_article = 0, is_user = 0, is_factor = 0;
for (var r = 0; r < lines_array.length; r++)
{
if (lines_array[r] == "\n" + alias[0])
{ is_article = 1; is_user = 0; is_factor = 0; }
if (lines_array[r] == "\n" + alias[1])
{ is_article = 0; is_user = 1; is_factor = 0; }
if (lines_array[r] == "\n" + alias[2])
{ is_article = 0; is_user = 0; is_factor = 1; }
if (lines_array[r][0] == '\n' && !isNaN(parseInt(lines_array[r][1], 10)))
{
var dataset_raw = lines_array[r].split(",");
if (is_article == 1) {
var attr_array = dataset_raw.slice(2, dataset_raw.length);
articles_ents.push({ "id" : dataset_raw[0], "name" : dataset_raw[1],
"attrs" : attr_array, "stats" : { "views" : 0,
"upvoted" : 0, "downvoted" : 0,
"downloads" : 0, "logs" : 0, "users1" : null,
"users2" : null, "bias" : 0.01, "vf" : null } });
}
else if (is_user == 1) {
users_ents.push({ "id" : dataset_raw[0], "name" : dataset_raw[1] });
}
else if (is_factor == 1) {
factors_ents.push({ "day" : dataset_raw[0],
"action" : dataset_raw[1], "user_id" : dataset_raw[2],
"user_name" : dataset_raw[3], "article_id" :
dataset_raw[4], "article_name" : dataset_raw[5]});
}
}
}
document.getElementById("status").innerHTML = "Processing...";
update_stats(articles_ents, factors_ents);
}
file_reader.readAsText(fp.files[0], "UTF-8");
}
function printOut()
{
var ds = null, index = -1;
var chunks = -1, tsID = -1;
self.onmessage = function(e) {
if (e.data["msg"] == "data_set") {
ds = e.data["value"];
}
else if (e.data["msg"] == "index") {
index = e.data["value"];
}
else if (e.data["msg"] == "chunks") {
chunks = e.data["value"];
}
else if (e.data["msg"] == "tsID") {
tsID = e.data["value"];
}
else if (e.data["msg"] == "invoke") {
console.log(ds.length);
var chunk_size = Math.ceil(ds.length / chunks);
var start = (index * chunk_size) < ds.length ?
(index * chunk_size) : ds.length;
var end = ((index + 1) * chunk_size) < ds.length ?
((index + 1) * chunk_size) : ds.length;
var ts_s = "";
for (var s = start; s < end; s++)
{
if(tsID == 0) {
ts_s += "<tr><td>" + ds[s]["name"] +
"</td><td>" + ds[s]["attrs"].toString() +
"</td></tr>\n";
}
else if(tsID == 1) {
ts_s += "<tr><td>" + ds[s]["name"] +
"</td></tr>\n";
}
else if(tsID == 2) {
ts_s += "<tr><td>" + ds[s]["day"] + "</td>" +
"<td>" + ds[s]["action"] + "</td>" +
"<td>" + ds[s]["user_id"] + "</td>" +
"<td>" + ds[s]["user_name"] + "</td>" +
"<td>" + ds[s]["article_id"] + "</td>" +
"<td>" + ds[s]["article_name"] + "</td></tr>\n";
}
else if(tsID == 3) {
ts_s += "<tr><td><center>" + ds[s]["name"] +
"</center></td><td><center>" + ds[s]["stats"]
["upvoted"].toString() + "</center></td>" +
"<td><center>" + ds[s]["stats"]
["downvoted"].toString() + "</center></td>" +
"<td><center>" + ds[s]["stats"]
["downloads"].toString() + "</center></td>" +
"<td><center>" + ds[s]["stats"]
["logs"].toString() + "</center></td></tr>\n";
}
else if(tsID == 4) {
ts_s += "<tr><td><center>" + ds[s]["name"] +
"</center></td><td><center>" + ds[s]["stats"]
["users1"].toString() + "</center></td>" +
"<td><center>" + ds[s]["stats"]
["users2"].toString() + "</center></td>" +
"<td><center>" + ds[s]["stats"]
["bias"].toString() + "</center></td>" +
"<td><center>" + ds[s]["stats"]
["vf"].toString() + "</center></td></tr>\n";
}
}
self.postMessage(JSON.stringify
({ "ts_buf" : ts_s, "index" : index }, null, 3));
}
}
}
function renderData(tsID, ds)
{
var thw_count = 0;
var ts = new Array();
var ts_buf = "";
if (tsID == 0)
{
ts_buf = "<table border=\"1\"
style=\"table-layout: fixed; overflow-x:auto; width: 100%;" +
"word-wrap: break-word;\"><thead>
<th width=\"25%\">Article</th>
<th width=\"25%\">Tags</th>";
ts_buf += "</thead><tbody>\n";
}
else if (tsID == 1)
{
ts_buf = "<table border=\"1\"
style=\"table-layout: fixed; overflow-x:auto; width: 100%;" +
"word-wrap: break-word;\"><thead>
<th width=\"25%\">User</th>";
ts_buf += "</thead><tbody>\n";
}
else if (tsID == 2)
{
ts_buf = "<table border=\"1\"
style=\"table-layout: fixed; overflow-x:auto; width: 100%;" +
"word-wrap: break-word;\">
<thead><th width=\"25%\">Day</th>";
ts_buf += "<th width=\"25%\">Action</th>";
ts_buf += "<th width=\"25%\">UserID</th>";
ts_buf += "<th width=\"25%\">UserName</th>";
ts_buf += "<th width=\"25%\">ArticleID</th>";
ts_buf += "<th width=\"25%\">ArticleName</th>";
ts_buf += "</thead><tbody>\n";
}
else if (tsID == 3)
{
ts_buf = "<table border=\"1\"
style=\"table-layout: fixed; overflow-x:auto; width: 100%;" +
"word-wrap: break-word;\"><thead>
<th width=\"25%\">Article</th>";
ts_buf += "<th>Upvoted</th>";
ts_buf += "<th>Downvoted</th>";
ts_buf += "<th>Downloads</th>";
ts_buf += "<th>Logs</th>";
ts_buf += "</thead><tbody>\n";
}
else if (tsID == 4)
{
ts_buf = "<table border=\"1\"
style=\"table-layout: fixed; overflow-x:auto; width: 100%;" +
"word-wrap: break-word;\"><thead>
<th width=\"25%\">Article</th>";
ts_buf += "<th>Positive</th>";
ts_buf += "<th>Negative</th>";
ts_buf += "<th>Bias</th>";
ts_buf += "<th>Factorization Vector</th>";
ts_buf += "</thead><tbody>\n";
}
var chunks = 50;
if (ds.length / chunks < 1)
chunks = 1;
document.getElementById("train_set").innerHTML = "";
for (var i = 0; i < chunks; i++)
{
var code = printOut.toString();
code = code.substring(code.indexOf("{")+1, code.lastIndexOf("}"));
var blob = new Blob([code], {type: "application/javascript"});
var w = new Worker(URL.createObjectURL(blob));
w.onmessage = function(e) {
var json_obj = JSON.parse(e.data);
if (thw_count == chunks - 1) {
for (var t = 0; t < ts.length; t++) {
ts_buf += ts[t];
}
document.getElementById("train_set").innerHTML = ts_buf +
"</tbody></table>";
}
if (e.data != null) {
ts[json_obj["index"]] = json_obj["ts_buf"];
}
thw_count++;
}
w.postMessage({ "msg" : "data_set", "value" : ds });
w.postMessage({ "msg" : "index", "value" : i });
w.postMessage({ "msg" : "chunks", "value" : chunks });
w.postMessage({ "msg" : "tsID", "value" : tsID });
w.postMessage({ "msg" : "invoke" });
}
}
function renderArticles()
{
if (trained == 0) {
alert('Train the model first...');
return;
}
renderData(0, articles_ents);
}
function renderUsers()
{
if (trained == 0) {
alert('Train the model first...');
return;
}
renderData(1, users_ents);
}
function renderFactors()
{
if (trained == 0) {
alert('Train the model first...');
return;
}
renderData(2, factors_ents);
}
function renderStats()
{
if (trained == 0) {
alert('Train the model first...');
return;
}
renderData(3, articles_ents);
}
function renderResults()
{
if (trained == 0) {
alert('Train the model first...');
return;
}
renderData(4, articles_ents);
}
function update_worker()
{
var chunks = -1;
var articles = null, factors = null, index = -1;
self.onmessage = function(e) {
if (e.data["msg"] == "articles") {
articles = e.data["value"];
}
if (e.data["msg"] == "factors") {
factors = e.data["value"];
}
else if (e.data["msg"] == "index") {
index = e.data["value"];
}
else if (e.data["msg"] == "chunks") {
chunks = e.data["value"];
}
else if (e.data["msg"] == "invoke") {
var chunk_size = Math.ceil(articles.length / chunks);
var start = (index * chunk_size) < articles.length ?
(index * chunk_size) : articles.length;
var end = ((index + 1) * chunk_size) < articles.length ?
((index + 1) * chunk_size) : articles.length;
max_views = 0; max_upvotes = 0;
max_downvotes = 0; max_downloads = 0; max_logs = 0;
for (var i = start; i < end; i++)
{
var logs_count = 0;
var users1 = new Array();
var users2 = new Array();
var views = 0, upvotes = 0;
var downvotes = 0, downloads = 0;
for (var j = 0; j < factors.length; j++) {
if (factors[j]["article_name"] == articles[i]["name"])
{
views = (factors[j]["action"] ==
"View") ? views + 1 : views;
upvotes = (factors[j]["action"] ==
"UpVote") ? upvotes + 1 : upvotes;
downvotes = (factors[j]["action"] ==
"DownVote") ? downvotes + 1 : downvotes;
downloads = (factors[j]["action"] ==
"Download") ? downloads + 1 : downloads;
if (factors[j]["action"] == "View" ||
factors[j]["action"] == "UpVote" ||
factors[j]["action"] == "Download") {
users1.push(factors[j]["user_name"]);
}
else {
users2.push(factors[j]["user_name"]);
}
if (views > max_views || max_views == 0)
max_views = views;
if (upvotes > max_upvotes || max_upvotes == 0)
max_upvotes = upvotes;
if (downvotes > max_downvotes || max_downvotes == 0)
max_downvotes = downvotes;
if (downloads > max_downloads || max_downloads == 0)
max_downloads = downloads;
if (logs_count > max_logs || max_logs == 0)
max_logs = logs_count;
logs_count++;
}
}
articles[i]["stats"]["logs"] = logs_count;
articles[i]["stats"]["views"] = views;
articles[i]["stats"]["users1"] = users1;
articles[i]["stats"]["users2"] = users2;
articles[i]["stats"]["upvoted"] = upvotes;
articles[i]["stats"]["downvoted"] = downvotes;
articles[i]["stats"]["downloads"] = downloads;
var views_norm = Math.abs(0.01 - articles[i]["stats"]
["views"]) / Math.abs(0.01 - max_views) / 10;
var upvotes_norm = Math.abs(0.01 - articles[i]["stats"]
["upvoted"]) / Math.abs(0.01 - max_upvotes) / 10;
var downvotes_norm = Math.abs(0.01 - articles[i]["stats"]
["downvoted"]) / Math.abs(0.01 - max_downvotes) / 10;
var download_norm = Math.abs(0.01 - articles[i]["stats"]
["downloads"]) / Math.abs(0.01 - max_downloads) / 10;
var logs_count_norm = Math.abs(0.01 - articles[i]["stats"]
["logs"]) / Math.abs(0.01 - max_logs) / 10;
articles[i]["stats"]["vf"] = [ views_norm, upvotes_norm,
downvotes_norm, download_norm, logs_count_norm ];
}
self.postMessage(JSON.stringify({ "result" : articles,
"start" : start, "end" : end }, null, 3));
}
}
}
function update_stats(articles, factors)
{
var chunks = 10;
if (articles.length / chunks < 1)
chunks = 1;
var thw_count = 0; var workers = [];
for (var i = 0; i < chunks; i++)
{
var code = update_worker.toString();
code = code.substring(code.indexOf("{")+1, code.lastIndexOf("}"));
var blob = new Blob([code], {type: "application/javascript"});
workers.push(new Worker(URL.createObjectURL(blob)));
workers[i].onmessage = function(e) {
if (thw_count == chunks - 1) {
a2a_table();
for (var q = 0; q < workers.length; q++) {
workers[q].terminate();
}
}
//else {
var json_obj = JSON.parse(e.data);
for (var t = json_obj["start"]; t < json_obj["end"]; t++) {
articles_ents[t] = json_obj["result"][t];
}
thw_count++;
//}
}
workers[i].postMessage({ "msg" : "articles", "value" : articles_ents });
workers[i].postMessage({ "msg" : "factors", "value" : factors });
workers[i].postMessage({ "msg" : "index", "value" : i });
workers[i].postMessage({ "msg" : "chunks", "value" : chunks });
workers[i].postMessage({ "msg" : "invoke", "value" : null });
}
}
function count_if(attrs_s, tag_name)
{
attrs_s = attrs_s + ''; tag_name = tag_name + '';
tag_name = tag_name.replace(/[.*+?^${}()|[\]\\]/g, '\\$&');
return (attrs_s.match(new RegExp(tag_name, 'gi')) || []).length;
}
function count_unique(attributes)
{
var count = 0, tags = new Array();
var attrs_text = attributes.toString();
for (var i = 0; i < attributes.length; i++) {
if (count_if(attrs_text, attributes[i]) == 1) {
tags.push(attributes[i]); count++;
}
}
return new Object({ "tags" : tags, "count_unique" : count });
}
function normalize(value, min, max)
{
return Math.abs(min - value) / Math.abs(min - max);
}
function a2a_worker()
{
function similarity(article_p1, article_p2)
{
var unique_attrs1 = article_p1["attrs"];
var unique_attrs2 = article_p2["attrs"];
unique_attrs1 = unique_attrs1.filter(function(tag_name, pos, tags)
{ return tags.indexOf(tag_name) == pos; });
unique_attrs2 = unique_attrs2.filter(function(tag_name, pos, tags)
{ return tags.indexOf(tag_name) == pos; });
var count_unique = 0;
for (var i = 0; i < unique_attrs1.length; i++) {
count_unique += (unique_attrs2.indexOf(unique_attrs1[i]) >= 0) ? 1 : 0;
}
return count_unique / (unique_attrs1.length + unique_attrs2.length);
}
var sum = 0, count = 0;
var rl_value = 0, r = new Array();
self.onmessage = function(e) {
if (e.data["msg"] == "articles") {
articles = e.data["value"];
}
else if (e.data["msg"] == "rel_table") {
rel_table = e.data["value"];
}
else if (e.data["msg"] == "index") {
index = e.data["value"];
}
else if (e.data["msg"] == "chunks") {
chunks = e.data["value"];
}
else if (e.data["msg"] == "invoke") {
var chunk_size = Math.ceil(articles.length / chunks);
var start = (index * chunk_size) < articles.length ?
(index * chunk_size) : articles.length;
var end = ((index + 1) * chunk_size) < articles.length ?
((index + 1) * chunk_size) : articles.length;
for (var i = start; i < end; i++) {
r[i] = new Array();
for (var j = i + 1; j < end; j++) {
r[i][j] = ((rl_value = similarity
(articles[i], articles[j])) > 0) ? rl_value : 0.01;
}
sum += r[i][j]; count++;
}
p_avg = sum / count;
self.postMessage(JSON.stringify({ "result" : r,
"start" : start, "end" : end, "p_avg" : p_avg }, null, 3));
}
}
}
function a2a_table()
{
var chunks = 10;
if (articles_ents.length / chunks < 1)
chunks = 1;
for (var i = 0; i < articles_ents.length; i++) {
rel_table[i] = new Array();
for (var j = 0; j < articles_ents.length; j++) {
rel_table[i][j] = 0;
}
}
var thw_count = 0; var workers = [];
for (var i = 0; i < chunks; i++)
{
var code = a2a_worker.toString();
code = code.substring(code.indexOf("{")+1, code.lastIndexOf("}"));
var blob = new Blob([code], {type: "application/javascript"});
workers.push(new Worker(URL.createObjectURL(blob)));
workers[i].onmessage = function(e) {
var json_obj = JSON.parse(e.data);
if (thw_count == chunks - 1) {
learn(rel_table); renderData(0, articles_ents);
for (var q = 0; q < workers.length; q++) {
workers[q].terminate();
}
}
//else {
for (var i1 = json_obj["start"]; i1 < json_obj["end"]; i1++) {
for (var i2 = i1 + 1; i2 < json_obj["end"]; i2++) {
rel_table[i1][i2] = json_obj["result"][i1][i2];
}
}
p_avg += json_obj["p_avg"] / chunks;
thw_count++;
//}
}
workers[i].postMessage({ "msg" : "articles", "value" : articles_ents });
workers[i].postMessage({ "msg" : "rel_table", "value" : rel_table });
workers[i].postMessage({ "msg" : "index", "value" : i });
workers[i].postMessage({ "msg" : "chunks", "value" : chunks });
workers[i].postMessage({ "msg" : "invoke", "value" : null });
}
}
function vf_product(article_p1, article_p2)
{
var vf1 = article_p1["vf"];
var vf2 = article_p2["vf"];
var product = 0;
for (var i = 0; i < vf1.length; i++) {
product += vf1[i] * vf2[i];
}
return product;
}
function vf_sum(vf)
{
var sum = 0;
for (var i = 0; i < vf.length; i++) {
sum += vf[i];
}
return sum;
}
function vf_average(vf)
{
return vf_sum(vf) / vf.length;
}
function correlation(article_p1, article_p2)
{
var vf1 = article_p1["vf"];
var vf2 = article_p2["vf"];
var vf_avg1 = vf_average(vf1);
var vf_avg2 = vf_average(vf2);
var vf_sum1 = 0, vf_sum2 = 0, vf_sum3 = 0;
for (var i = 0; i < vf1.length; i++) {
vf_sum1 += (vf1[i] - vf_avg1) * (vf2[i] - vf_avg2);
}
for (var i = 0; i < vf1.length; i++) {
vf_sum2 += Math.pow(vf1[i] - vf_avg1, 2);
}
for (var i = 0; i < vf2.length; i++) {
vf_sum3 += Math.pow(vf2[i] - vf_avg2, 2);
}
return vf_sum1 / (vf_sum2 * vf_sum3);
}
function compute_p(article_p1, article_p2)
{
var article1 = article_p1["stats"];
var article2 = article_p2["stats"];
return p_avg + article1["bias"] + article2["bias"] +
(vf_product(article1, article2) / correlation(article1, article2));
}
function learn(rl_table)
{
var ts = 0.5;//0.025; // The training speed
var rc1 = 0.0005; // Regularization coefficient lambda1
var rc2 = 0.0025; // Regularization coefficient lambda2
var eps = 0.00001; // Error precision accuracy coefficient
var threshold = 0.01; // Threshold coefficient
var is_done = 0;
var RMSE = 0, RMSE_New = 0;
do
{
RMSE = RMSE_New, RMSE_New = 1;
for (var i = 0; i < rl_table.length; i++)
{
for (var j = i + 1; j < rl_table[0].length; j++)
{
if (rl_table[i][j] > 0 && rl_table[i][j] != 0.01)
{
var error = rl_table[i][j] -
compute_p(articles_ents[i], articles_ents[j]);
RMSE_New = RMSE_New + Math.pow(error, 2);
p_avg += ts * (error - rc1 * p_avg);
articles_ents[i]["stats"]["bias"] +=
ts * (error - rc1 * articles_ents[i]["stats"]["bias"]);
articles_ents[j]["stats"]["bias"] +=
ts * (error - rc1 * articles_ents[j]["stats"]["bias"]);
for (var t = 0;
t < articles_ents[i]["stats"]["vf"].length; t++) {
articles_ents[i]["stats"]["vf"][t] +=
ts * (error * articles_ents[i]["stats"]["vf"][t] +
rc2 * articles_ents[j]["stats"]["vf"][t]);
articles_ents[j]["stats"]["vf"][t] +=
ts * (error * articles_ents[j]["stats"]["vf"][t] +
rc2 * articles_ents[i]["stats"]["vf"][t]);
}
}
}
}
RMSE_New = Math.sqrt(RMSE_New / (rl_table.length * rl_table[0].length));
if (RMSE_New > RMSE - threshold) {
ts *= 0.66; threshold *= 0.5;
}
} while (Math.abs(RMSE - RMSE_New) > eps);
trained = 1;
document.getElementById("status").innerHTML = "Completed...";
}
function predict()
{
if (trained == 0) {
alert('Train the model first...');
return;
}
var user_name = document.getElementById("user").value;
var article_name = document.getElementById("article").value;
var article_index = -1;
for (var t = 0; t < articles_ents.length && article_index == -1; t++)
article_index = (articles_ents[t]["name"] == article_name) ? t : -1;
if (article_index != -1) {
var found = 0;
for (var i = 0; i < articles_ents.length && !found; i++)
{
var users = articles_ents[i]["stats"]["users1"];
if (users.find(function (user) { return user == user_name; }) != undefined) {
found = 1;
var total = articles_ents[i]["stats"]["views"] +
articles_ents[i]["stats"]["upvoted"] +
articles_ents[i]["stats"]["downvoted"] +
articles_ents[i]["stats"]["downloads"];
var probability = compute_p(articles_ents[article_index],
articles_ents[i]) * 100;
document.getElementById("rc_p").innerHTML =
Math.round(probability).toString();
document.getElementById("view_p").innerHTML =
Math.round(articles_ents[i]["stats"]["views"] / total * 100);
document.getElementById("upvote_p").innerHTML =
Math.round(articles_ents[i]["stats"]["upvoted"] / total * 100);
document.getElementById("downvote_p").innerHTML =
Math.round(articles_ents[i]["stats"]["downvoted"] / total * 100);
document.getElementById("download_p").innerHTML =
Math.round(articles_ents[i]["stats"]["downloads"] / total * 100);
}
}
}
}
</script>
</html>
参考文献
- "C#.NET: Implementing SVD++ AI Data Mining Algorithm To Produce Recommendations Based On Ratings Prediction" - https://codeproject.org.cn/Articles/1166739/Csharp-NET-Implementing-SVDplusplus-AI-Data-Mining
- "C#.NET Implementation of K-Means Clustering Algorithm to Produce Recommendations" - https://codeproject.org.cn/Articles/1123288/Csharp-NET-Implementation-of-K-Means-Clustering-Al
历史
- 2018年2月28日 - 本文最终修订版已发布