
大数据
4.98/5 (24投票s)
这是关于大数据的几乎所有内容。

引言
如今,我们面临着数据量不断增长的现象。我们希望长期保存所有这些数据并以高速度处理和分析它们,这促使我们构建了一个良好的解决方案。寻找传统数据库的合适替代品,这些数据库可以存储任何类型的结构化和非结构化数据,这是数据科学家面临的最大挑战。
我选择了一个从第一步到结果的完整场景,这在互联网上很难找到。我选择了MapReduce(通过Hadoop处理数据)和Intellij idea中的Scala,而所有这一切都将在Ubuntu Linux操作系统下进行。
数据量有多大才算大数据?

什么是大数据?
大数据是指海量数据的巨大卷,这些数据是结构化、非结构化或半结构化的,并且难以用传统数据库存储和管理。其卷从太字节到拍字节不等。关系数据库(如SQL Server)不适合存储非结构化数据。正如您在下图中看到的,大数据是所有类型的结构化或非结构化数据的集合,它具有存储、管理、共享、分析等基本要求。

大数据需要将海量数据导入存储盒中进行处理和分析。
大数据面临两个重要挑战
- 收集大量数据(例如导入、传输和加载数据)
- 分析数据(例如处理、排序、计数、聚合数据)
要执行上述步骤,我们需要建立一个消息系统。消息系统是将数据从一个应用程序传输到另一个应用程序的解决方案。消息传递系统有两种类型:点对点和发布-订阅。在点对点中,发送的消息只能由一个消费者消耗,而在发布-订阅消息系统中,消费者可以从发布者那里使用多个主题。

处理类型
连续处理
在连续处理中,只有一个任务需要处理。这与批处理形成对比。
异步处理
在异步处理中,每个任务将在一个单独的线程中处理。它可以同时执行多个任务。同步和异步之间的主要区别是多任务的并行处理。假设有两种吃饭方式,一种是在街边排队买土耳其烤肉(同步过程),另一种是在餐厅坐着吃(异步过程)。
在土耳其烤肉店,我们必须等到每个人都拿到自己的三明治,而在餐厅里,服务员会记录所有人的订单,然后根据空闲的烹饪位置随机准备食物。
批处理 – 离线
在批处理中,首先将数据存储在磁盘上,其中可能包含数百万条记录,然后对所有这些海量数据进行处理和分析。Hadoop通过MapReduce是一个很好的例子。在批处理中,不需要实时了解即时结果。它适用于离线模式下分析大量数据。
流处理 - 实时
在流处理中,首先将数据注入Spark或Storm等分析工具,然后立即对数据进行分析。此解决方案适用于处理需要即时响应的少量最新记录,例如身份验证或授权系统。由于在内存中处理而不是在磁盘上处理,因此此过程很快。由于分析的记录较少且在内存中处理,因此延迟较高。
基本和相关概念
什么是数据管道?
数据管道是一系列相关且连接的元素,其中每个部分处理数据,使其对下一个元素可重用,并产生具有所需形状和格式的灵活输出。
为了看到实际示例,请参阅[借助管道读取CSV文件]。

延迟
数据包从一个点传输到另一个点的时间间隔。低延迟表示网络效率高。
吞吐量
从开始发送到过程结束为止,在特定时间内执行的总操作数。
可靠
可靠的系统保证所有数据都将得到妥善**处理**而不会失败,并在崩溃时会重新执行。
容错
容错系统保证所有数据都将得到妥善**保存**而不会失败,这意味着当集群崩溃时,特定任务将被定向到另一台机器。
持久性
当过程完成后,将向客户发送成功消息。尽管这会牺牲性能,但它是值得的。
可扩展性
可扩展性主要定义在分布式系统和并行编程上。它可以保证流量和数据**增长速度**。
性能
性能**系统可保证**吞吐量**,即使在**遇到**大数据时也是如此。
No SQL
MongoDB
Mongo用C++编写。它是**面向文档**的。它灵活,便于处理具有许多查询的数据。
Redis
Redis是开源的内存数据结构存储,具有缓存和消息代理功能。
大数据工具
Hadoop/Hbase
它是开源的,非关系型数据库,是分布式的。Apache HBase建立在Hadoop之上。
Cassandra
它具有良好的可扩展性,容错性和较低的延迟,同时具有出色的缓存。
数据流
Flink
它是批处理或实时处理。Flink具有流式处理和SQL查询的API。
Storm
Storm是实时系统,具有高吞吐量和可扩展性。它每秒可以处理每节点一百万条记录。
Kinesis
Kinesis具有实时处理能力。
Kafka
Kafka是一个发布-订阅消息系统,具有良好的性能、可靠性、可扩展性和持久性,并支持实时处理。
什么是Hadoop?
实际上,我们期望所有数据库都有两个问题。首先,我们需要存储数据,其次,我们希望以快速准确的方式妥善处理存储的数据。由于大数据的任意形状和庞大数量,无法将其存储在传统数据库中。我们需要考虑新的数据库,它可以处理大数据的存储和处理。
Hadoop作为大数据的革命性数据库,能够存储任何形状的数据并在节点集群中处理它们。它还极大地降低了数据维护成本。借助Hadoop,我们可以存储任何类型的数据,例如,长时间内的所有用户点击。因此,它便于进行历史分析。Hadoop具有分布式存储和分布式处理系统,如MapReduce。

什么是Hadoop生态系统?
如上所述,Hadoop适合存储非结构化数据库或处理它们。Hadoop生态系统有一个抽象定义。数据存储在左侧,具有HDFS和HBase两种存储可能性。HBase建立在HDFS之上,两者都是用Java编写的。

HDFS
- Hadoop分布式文件系统允许将大数据存储在分布式平面文件中。
- HDFS适用于顺序访问数据。
- 没有随机实时读/写访问数据。它更适合离线批处理。
HBase
- 以列式存储键/值对数据。
HBase可以进行实时读/写。
Hadoop是用Java编写的,但您也可以用R、Python、Ruby实现。
Spark是一个开源的集群计算系统,用Scala实现,适合支持分布式计算上的作业迭代。Spark具有高性能。
Hive、Pig、Sqoop和Mahout是数据访问工具,它们使查询数据库成为可能。Hive和Pig是类SQL的;Mahout用于机器学习。
MapReduce和Yarn都用于处理数据。MapReduce被构建用于在分布式系统中处理数据。MapReduce可以处理所有任务,如作业和任务跟踪器、监控和并行执行。Yarn,Yet Another Resource Negotiator,是MapReduce 2.0,它具有更好的资源管理和调度。
Sqoop是一个连接器,用于从/向外部数据库导入和导出数据。它以并行方式轻松快速地传输数据。
Hadoop如何工作?
Hadoop遵循主/从架构模型。对于HDFS,主节点中的NameNode监控并跟踪所有从节点,这些从节点是一组存储集群。

MapReduce处理过程中有两种不同类型的工作。Map作业发送查询以处理集群中的各种节点。此作业将被分解为更小的任务。然后Reduce作业收集每个节点生成的输出,并将它们合并为一个单一值作为最终结果。

这种架构使Hadoop成为一种便宜、快速且可靠的解决方案。将大作业分解成小作业,并将每个任务放在不同的节点上。这个故事可能会让您想起多线程处理。在多线程中,所有并发进程都通过锁和信号量共享,但MapReduce中的数据访问由HDFS控制。
实际示例
下图中有三个文本文件用于练习单词计数。MapReduce开始将每个文件分割到节点集群中,正如我在本文开头所解释的那样。在映射阶段,每个节点负责计数单词。在每个节点中的中间分割只是同质单词,以及该特定单词在前一个节点中的数量。然后在归约阶段,每个节点将被汇总并收集其自己的结果以产生一个单一值。

Tensorflow在Windows上 - Python - CPU

下载Anaconda Python 3.6
如果您想使用舒适的IDE和专业的编辑器,而无需安装库,可以使用Anaconda & Spider。

然后从启动器打开Anaconda Navigator,选择并启动“Spider”。

有一些要点
- Python是面向对象的
- 动态类型
- 丰富的库
- 易于阅读
- Python区分大小写
- 缩进对Python很重要
安装Tensorflow
- 从“开始菜单”打开Anaconda Navigator -> 从“左侧面板”选择“环境” -> 进入“根” -> 选择“所有频道” -> 搜索“tensor”。
- 选择“tensorflow”,但如果您认为您需要使用R进行统计计算,或者使用GPU获得快速结果,那么请选择“r-tensorflow”和“tensorflow-gpu”。
- 然后,按绿色“应用”。

- 然后在下一个窗口中,再次接受其余的作为依赖项的包。

什么是深度学习?
实际上,深度学习是机器学习的一个分支。机器学习包含一些不同的算法,它们获取数千条数据并尝试从中学习,以便预测未来的新事件。但是,深度学习应用神经网络作为扩展或变体。深度学习能够处理数百万条数据。
深度学习最基础的基础设施可能是其提取最佳特征的能力。实际上,深度学习对数据进行摘要,并基于压缩数据计算结果。这正是人工智能所需,尤其是在我们拥有大量数据库和大量计算的情况下。
深度学习具有由神经网络启发的顺序层。这些层具有非线性函数,负责特征选择。每一层都有一个输出,将用作下一层的输入。深度学习应用程序包括计算机视觉(如面部或物体识别)、语音识别、自然语言处理(NLP)和网络威胁检测。
我强烈建议您访问并阅读[本文]。
Hadoop安装和实现步骤
1.下载并安装Java
在此处下载此版本jdk1.8.0_144。
选择驱动器(C:\Java)作为安装路径。
2.下载并安装Hadoop
在此[处]下载Hadoop,并将其放在驱动器(D:\)上。您应该看到类似下图的内容。

首先,创建一个新文件夹并命名为“data”,如果不存在的话。
格式
以管理员身份运行**“Windows命令提示符”**。
D:\hadoop\bin>hadoop-data-dfs - remove all
D:\hadoop\bin>hadoop namenode -format
Start
- D:\hadoop\sbin>start-dfs.cmd
(等待一分钟) - D:\hadoop\sbin>yarn-dfs.cmd

您将看到四个窗口
yarn-resourcemanager
yarn-nodemanager
namenodedatanode
所以,如果您看到了这4个窗口,意味着一切顺利。
调整环境


测试并运行简单著名的Python代码,如wordcount
在D:\hdp中创建一个新文件夹,然后在其中创建并保存以下python和文本文件。
wordcount-mapper.py
import sys
for line in sys.stdin: # Input is read from STDIN and the output of this file
# is written into STDOUT
line = line.strip() # remove leading and trailing whitespace
words = line.split() # split the line into words
for word in words:
print( '%s\t%s' % (word, 1)) #Print all words (key) individually with the value 1
wordcount-reducer.py
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin: # input comes from STDIN
line = line.strip() # remove leading and trailing whitespace
word, count = line.split('\t', 1) # parse the input we got from mapper.py
# by a tab (space)
try:
count = int(count) # convert count from string to int
except ValueError:
continue #If the count is not a number,
#then discard the line by doing nothing
if current_word == word: #comparing the current word with the previous word
#(since they are ordered by key (word))
current_count += count
else:
if current_word:
# write result to STDOUT
print( '%s\t%s' % (current_word, current_count))
current_count = count
current_word = word
if current_word == word: # do not forget to output the last word if needed!
print( '%s\t%s' % (current_word, current_count))
创建一个名为“mahsa.txt”的文本文件。
Hello
Hello
Hello
Hello
Hello
Good
Good
让我们在Hadoop上运行它。
D:\hadoop\sbin>hadoop fs -mkdir -p /hdp

D:\hadoop\sbin>hadoop fs -copyFromLocal D:\hdp\wordcount-mapper.py /hdp
D:\hadoop\sbin>hadoop fs -copyFromLocal D:\hdp\wordcount-reducer.py /hdp
D:\hadoop\sbin>hadoop fs -copyFromLocal D:\hdp\mahsa.txt /hdp

D:\hadoop\sbin>hadoop fs -ls /hdp
D:\hadoop\sbin>D:\hadoop\bin\hadoop jar D:\hadoop\share\hadoop\tools\lib\
hadoop-streaming-2.3.0.jar -file /hdp/wordcount-mapper.py -mapper
"python wordcount-mapper.py" -file /hdp/wordcount-reducer.py -reducer
"python wordcount-reducer.py" -input /hdp/mahsa.txt -output /outputpython

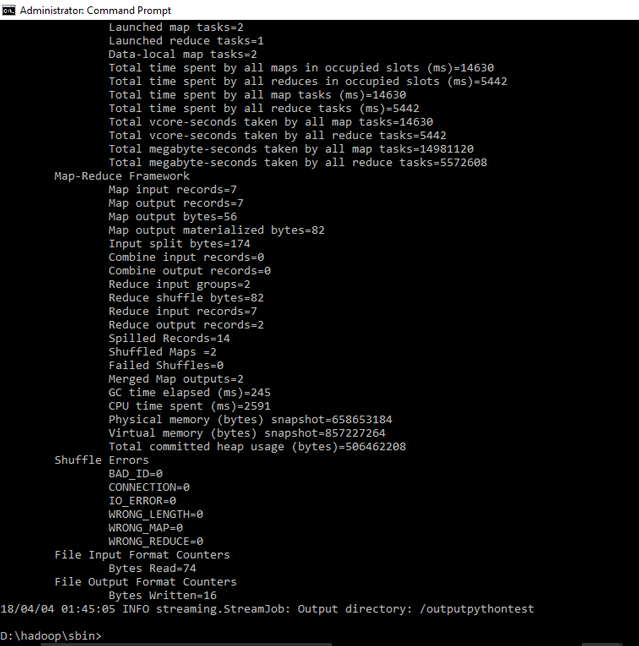


测试并运行简单的“Hello”Tensorflow Python代码
在D:\hdp中创建代码。
# -*- coding: utf-8 -*- """ Created on Sun Apr 1 15:42:59 2018
@author: Mahsa """ import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!') sess = tf.Session() print(sess.run(hello))
D:\hadoop\sbin>hadoop fs -copyFromLocal D:\hdp\tensortest.py /hdp
D:\hadoop\sbin>D:\hadoop\bin\hadoop jar D:\hadoop\share\hadoop\tools\lib\
hadoop-streaming-2.3.0.jar -D mapreduce.job.reduce=0 -file /hdp/tensortest.py
-mapper "python tensortest.py" -input /hdp/mahsa.txt -output /outputtensortest


D:\hadoop\sbin>hadoop fs -ls /outputtensortest
D:\hadoop\sbin>hadoop fs -cat /outputtensortest/part-00000

测试并运行简单的“Digit-Recognition”Tensorflow Python代码
在D:\hdp中创建代码。
# -*- coding: utf-8 -*-
"""
Created on Sun Apr 1 15:42:59 2018
@author: Mahsa
"""
from tensorflow.examples.tutorials.mnist import input_data
# Downloading MNIS dataset
mnist_train = input_data.read_data_sets("data/", one_hot=True)
import tensorflow as tf
batch = 100
learning_rate = 0.01
training_epochs = 10
# matrix
x = tf.placeholder(tf.float32, shape=[None, 784])
yt = tf.placeholder(tf.float32, shape=[None, 10])
# Weight
Weight = tf.Variable(tf.zeros([784, 10]))
bias = tf.Variable(tf.zeros([10]))
# model
y = tf.nn.softmax(tf.matmul(x,Weight) + bias)
# entropy
cross_ent = tf.reduce_mean(-tf.reduce_sum(yt * tf.log(y), reduction_indices=[1]))
# Prediction
correct_pred = tf.equal(tf.argmax(y,1), tf.argmax(yt,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Gradient Descent
train_optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_ent)
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
# Batch Processing
for epoch in range(training_epochs):
batch_num = int(mnist_train.train.num_examples / batch)
for i in range(batch_num):
batch_x, batch_y = mnist_train.train.next_batch(batch)
sess.run([train_optimizer], result={x: batch_x, yt: batch_y})
if epoch % 2 == 0:
print( "Epoch: ", epoch)
print ("Accuracy: ", accuracy.eval
(result={x: mnist_train.test.images, yt: mnist_train.test.labels}))
print( "Complete")
D:\hadoop\sbin>D:\hadoop\bin\hadoop jar D:\hadoop\share\hadoop\tools\lib\hadoop-streaming-2.3.0.jar -D mapreduce.job.reduce=0 -file /hdp/tensordigit.py -mapper "python tensordigit.py" -input /hdp/mahsa.txt -output /outputtensordigitt
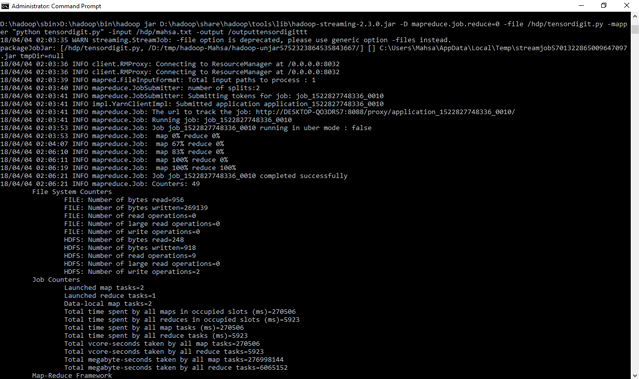
D:\hadoop\sbin>hadoop fs -ls /outputtensordigittt


反馈
欢迎您随时对本文发表任何反馈;很高兴看到您的意见和对本代码的投票。如果您有任何问题,请随时在此处向我提问。
参考文献
- https://databricks.com/blog/2016/01/25/deep-learning-with-apache-spark-and-tensorflow.html
- http://highscalability.com/blog/2012/9/11/how-big-is-a-petabyte-exabyte-zettabyte-or-a-yottabyte.html
- http://bigdata-madesimple.com/a-deep-dive-into-nosql-a-complete-list-of-nosql-databases/
- https://northconcepts.com/docs/what-is-data-pipeline/
- http://dataaspirant.com/2017/05/03/handwritten-digits-recognition-tensorflow-python/
- http://www.algoworks.com/blog/real-time-data-streaming-tools-and-technologies/
历史
- 2018年4月25日:初始版本
- 2019年4月3日:文章更新