
深度学习
4.88/5 (48投票s)
使用 TensorFlow Python 实现的深度学习卷积神经网络,完全易于理解
什么是深度学习?
实际上,深度学习是机器学习的一个分支。机器学习包含几种不同类型的算法,它们接收数千份数据并尝试从中学习,以便预测未来的新事件。但深度学习应用了具有扩展或变体形状的神经网络。深度学习能够处理数百万份数据。

深度学习最基本的结构可能是:它能够提取最佳特征。事实上,深度学习对数据进行总结,并基于压缩数据计算结果。这正是人工智能所需,尤其是在我们拥有庞大的数据库和巨大的计算量时。
深度学习具有受神经网络启发的序列层。这些层具有非线性函数,负责特征选择。每一层都有一个输出,该输出将作为下一层的输入。深度学习应用包括计算机视觉(如人脸或物体识别)、语音识别、自然语言处理 (NLP) 和网络威胁检测。
深度学习与机器学习对比
机器学习和深度学习之间的主要区别在于;在机器学习中,我们需要**人工干预来选择特征提取**,而在深度学习中,它将通过其**内置的直观知识**来完成。这些差异对其性能产生了巨大影响,无论是在精度还是速度方面。因为**手动特征检测总是存在人为错误**,所以深度学习可能是处理海量数据的最佳选择。
深度学习和机器学习的共同点是它们都可以在监督和无监督的情况下工作。深度学习只是基于神经网络,但它改变了在 CNN - RNN 等中的形状和操作。而机器学习则有基于统计学和数学科学的不同算法。尽管这并不意味着深度学习仅仅是神经网络,深度学习也可以使用各种机器学习算法,通过构建混合函数来提高性能。例如,深度学习可以将支持向量机 (SVM) 用作其激活函数,而不是 softmax。[1]

特征工程的重要性
我们试图使机器成为人工智能中一个独立的思考工具,需要最少的程序员干预。自动化机器最显著的特点是:它的思考方式,如果它的思考方式与人类大脑最相似,那么它将在最佳机器的竞争中获胜。所以,让我们来看看做出准确决策的关键属性。回想我们的童年,当我们看到物体但我们不知道它们的属性,如名称、确切大小、重量等。但我们可以通过注意到一件重要的事情来快速地对它们进行分类。例如,看着一只动物,一旦我们听到它的声音“汪汪叫”,我们就知道它是“狗”,或者当我们听到“喵喵叫”时,我们就知道它是“猫”。因此,在这里,动物的声音比大小具有更有效的影响,因为根据经验,当我们看到与其它动物大小相似的动物时,我们的大脑就会开始关注最独特的特征,即声音。另一方面,当我们看到动物园里最高的动物时,我们会忽略所有其他特征,并说“是的,它是长颈鹿”。

这是大脑的一个奇迹,因为它能够推断情况,并根据同一问题(如“动物检测”)中的不同条件,将一个特征作为最终的关键来做出决定,这种态度的结果将是准确且快速的。另一个故事来阐明特征工程的重要性是“二十个问题游戏”,如果你还没有玩过,请看这里。
如果玩家能够问出正确的问题,并且根据最近的答案,他应该制定和改进下一个问题,那么他就会赢。问题是按顺序进行的,下一个问题 100% 取决于前一个答案。前一个答案有过滤的作用,为玩家澄清问题,以达到目标。每个问题都有神经网络中的一个隐藏层,连接到下一层,它们的输出将作为下一层的输入。我们的第一个问题总是从“它活着吗?”开始,通过这个问题,我们消除了可能性的一半。这种省略和丢弃让我们能够提出更好类别的新问题,显然,在没有前一个答案进行澄清和过滤的情况下,我们无法问出下一个问题。这个故事在深度学习卷积神经网络中以某种方式发生。
深度学习与人脑
深度学习几乎在精确度和速度方面都模仿了人脑。卷积神经网络 (CNN) 的灵感来自大脑皮层。正如你在下面的图片中看到的,视觉皮层覆盖了整个视觉场。这些敏感细胞扮演着核或滤波器矩阵的角色,我们将在本文后面讨论。上帝创造了这些细胞来提取来自眼睛的重要数据。

假设学生有考试,他们正在准备,他们开始阅读书籍,同时他们会挑出书中的重要部分并写在笔记上或用荧光笔标记。在这两种情况下,他们都倾向于减少书的体积,并将 100 页总结为两页,这样便于作为参考和回顾。深度学习 CNN 中也发生了类似的情况,这次我们需要一个更小的矩阵来过滤和去除数据。

要求
我强烈推荐并请求您仔细阅读下面列出的第一篇和第二篇文章,因为它们的概念是需要的,并且我假设您已经了解了线性回归和神经网络的所有知识。
- 机器学习 - 线性回归梯度下降
- 机器学习 - 神经网络
- 机器学习 - 朴素贝叶斯分类器
- 机器学习 - 随机森林 - 决策树
- 机器学习 - 马尔可夫链 - 蒙特卡洛
- 使用 Maven IntelliJ IDEA 在 Ubuntu Linux 上进行大数据 MapReduce Hadoop Scala
深度学习 - 卷积神经网络如何工作?
深度学习是具有两个以上隐藏层的神经网络。如果您是神经网络新手,请学习此链接。由于层数过多,数据量也越多,这会导致过拟合。过拟合发生在当我们用训练数据集构建了一个模型,使其非常完整并匹配测试集时,模型中总会有一个答案。模型的一个好特点是具有泛化性,而不是完全巧合。

我们不能,或者即使可以,构建一个完全匹配的模型也是错误的。让我们看看当我们想在模型中分配一个“Y”时会发生什么。在构建模型时,我们必须避免过于理想化,并倾向于使其具有通用性而不是特殊性,为了达到这一点,我们可以应用交叉验证。交叉验证是模型评估方法。最好的方法是使用 K 折交叉验证,它试图将训练集分成 k 部分,在每次迭代中,k 被用作测试集,其余 k-1 部分作为训练集,因此匹配的可能性会降低。在卷积神经网络中,有一些特定的解决方案可以替代 K 折交叉验证,以避免过拟合,例如**dropout**和**regularization**。
在深度学习中,全连接意味着一个隐藏层中的每个神经元都连接到下一层的神经元。在使用 dropout 进行训练时,一些神经元将被关闭,在训练完成后进行预测时,所有神经元都将开启。因此,深度学习试图省略和去除冗余数据,模糊它们的作用,并增强和突出重要特征的作用。例如,在下面的图片中,左边的图片具有高分辨率,但在随着时间的推移,深度学习 CNN 试图保留重要像素并使其变小。
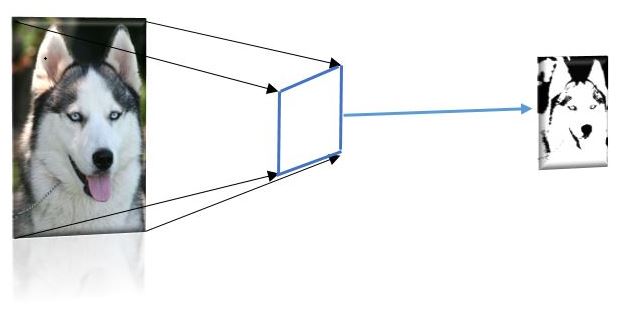
假设学生有考试,他们正在准备,他们开始阅读书籍,同时他们会挑出书中的重要部分并写在笔记上或用荧光笔标记。在这两种情况下,他们都倾向于减少书的体积,并将 100 页总结为两页,这样便于作为参考和回顾。深度学习 CNN 中也发生了类似的情况,这次我们需要一个更小的矩阵来过滤和去除数据。
我们可以将数据转换为更小的数据——更容易依靠其做出决策——借助更小的矩阵,并将原始矩阵旋转几次。我们通过移动滤波器矩阵围绕原始矩阵进行一些数学计算。例如,在下面的图片中,通过将一个矩阵旋转 3 次在原始矩阵上,12 个数据点将减少到 3 个数据点。这些计算可以最大化或取数据的平均值。

一个 CNN 维度
在现实世界中不存在一维矩阵,但为了展示它的方式,我更喜欢从一维矩阵开始。我想借助红色矩阵对蓝色矩阵进行降维。所以蓝色矩阵是真实数据集,红色矩阵是滤波器矩阵。我想将 5 个元素的蓝色矩阵转换为 3 个元素。我从左到右移动红色矩阵(每步只移动一个元素)。每当有重叠时,我就将两个相关的元素相乘,如果有多个匹配的元素,我就将它们相加。请注意,红色矩阵是 [2 -1 1],翻转后(核)变成 [1 -1 2]。
为了减少矩阵,我正在寻找有效的结果,当红色或滤波器元素全部被蓝色矩阵覆盖时,就会发生这种情况。我只选择了 [3 5]。









import numpy as np
x = np.array([0,1,2,3])
w = np.array([2,-1,1])
result = np.convolve(x,w)
result_Valid = np.convolve(x,w, "valid")
print(result)
print(result_Valid)
两个 CNN 维度
二维矩阵也有类似的故事。核矩阵 [[-1, 0], [2, 1]] 翻转后将变成 [[1, 2], [0, -1]]。因为在下面图片的每一步中,滤波器矩阵都在原始训练矩阵内部,所以所有计算出的元素都是有效的。






from scipy import signal as sg
print(sg.convolve([[2, 1, 3],
[5, -2, 1],
[0, 2, -4]], [[-1, 0],[2, 1]]))
print(sg.convolve([[2, 1, 3],
[5, -2, 1],
[0, 2, -4]], [[-1, 0],[2, 1]], "valid"))
深度学习数字识别代码示例
我想向您介绍最好的竞赛社区KAGGLE ,它在数据科学家中非常有名。有许多竞赛值得您练习机器学习和深度学习方面的能力。此外,对于能够为近期挑战编写代码的人,也有奖励。这里有作者编写的内核(kernels),您也可以为它们做出贡献,它们是学习 R 和 Python 中人工智能的好资源。此外,您还可以使用其数据集作为参考,并使用准备好的数据测试您的代码。
我想练习卷积,请点击这里。
下载训练和测试数据集
请访问此链接获取训练和测试数据集。显然,您必须在 Kaggle 网站上注册,然后尝试加入此竞赛。
# -*- coding: utf-8 -*-
"""
Created on Sun Nov 19 05:59:50 2017
@author: Mahsa
"""
import numpy as np
from numpy.random import permutation
import pandas as pd
import tflearn
from tflearn.layers.core import input_data,dropout,fully_connected,flatten
from tflearn.layers.conv import conv_2d,max_pool_2d
from tflearn.layers.normalization import local_response_normalization
from tflearn.layers.estimator import regression
from sklearn.cross_validation import train_test_split
train_Path = r'D:\digit\train.csv'
test_Path = r'D:\digit\test.csv'
#Split arrays or matrices into random train and test subsets
#https://scikit-learn.cn/stable/modules/generated/sklearn.model_selection.train_test_split.html
def split_matrices_into_random_train_test_subsets(train_Path):
train = pd.read_csv(train_Path)
train = np.array(train)
train = permutation(train)
X = train[:,1:785].astype(np.float32) #feature
y = train[:,0].astype(np.float32) #label
return train_test_split(X, y, test_size=0.33, random_state=42)
def reshape_data(Data,Labels):
Data = Data.reshape(-1,28,28,1).astype(np.float32)
Labels = (np.arange(10) == Labels[:,None]).astype(np.float32)
return Data,Labels
X_train, X_test, y_train, y_test = split_matrices_into_random_train_test_subsets(train_Path)
X_train,y_train = reshape_data(X_train,y_train)
X_test,y_test = reshape_data(X_test,y_test)
test_x = np.array(pd.read_csv(test_Path))
test_x = test_x.reshape(-1,28,28,1)
def Convolutional_neural_network():
network = input_data(shape=[None,28,28,1],name='input_layer')
network = conv_2d(network, nb_filter=6, filter_size=6,
strides=1, activation='relu', regularizer='L2')
network = local_response_normalization(network)
network = conv_2d(network, nb_filter=12, filter_size=5,
strides=2, activation='relu', regularizer='L2')
network = local_response_normalization(network)
network = conv_2d(network, nb_filter=24, filter_size=4,
strides=2, activation='relu', regularizer='L2')
network = local_response_normalization(network)
network = fully_connected(network, 128, activation='tanh')
network = dropout(network, 0.8)
network = fully_connected(network, 256, activation='tanh')
network = dropout(network, 0.8)
network = fully_connected(network, 10, activation='softmax')
sgd = tflearn.SGD(learning_rate=0.1,lr_decay=0.096,decay_step=100)
top_k = tflearn.metrics.top_k(3) #Top-k mean accuracy ,
Number of top elements to look at for computing precision
network = regression(network, optimizer=sgd,
metric=top_k, loss='categorical_crossentropy')
return tflearn.DNN(network, tensorboard_dir='tf_CNN_board', tensorboard_verbose=3)
model = Convolutional_neural_network()
model.fit(X_train, y_train, batch_size=128,
validation_set=(X_test,y_test), n_epoch=1, show_metric=True)
P = model.predict(test_x)
index = [i for i in range(1,len(P)+1)]
result = []
for i in range(len(P)):
result.append(np.argmax(P[i]).astype(np.int))
res = pd.DataFrame({'ImageId':index,'Label':result})
res.to_csv("sample_submission.csv", index=False)
通过 GPU 提高深度学习性能
游戏开发者、平面设计师和数据科学家之间的一个共同重要因素是矩阵。图像、视频或复杂数据中的每个数据点都在矩阵元素中有一个值。我们所做的一切都包含一些数学运算来转换矩阵。
对于常规处理,中央处理器 (CPU) 是一个不错的选择,但在对海量数据进行高级数学和统计运算时,CPU 无法承受,我们必须使用图形处理器 (GPU),它被设计用于复杂的数学函数。因为深度学习包含需要复杂计算的函数,如卷积神经网络、激活函数、sigmoid softmax 和傅里叶变换将在 GPU 上处理,而其余的 95% 将转移到 CPU 上,或者主要是 I/O 操作。
GPU 激活
- 打开开始菜单,输入“Windows 命令提示符 cmd”。
- 输入“
dxdiag” - 在打开的窗口中,查看“显示选项卡”。
- 如果名称等于“NVIDIA”或(NVIDIA GPU - AMD GPU - Intel Xeon Phi)等公司,则表示主板上有 GPU 卡。
- 让我们尝试配置 `\.theanorc` 文件,位于“C:\users\"yourname"\"\.theanorc”
- 在 `[global]` 部分设置 `\{ device = gpu 或 cuda0 , floatX = float32 \}`,并在 `[gpuarray]` 中设置 `preallocate = 1`。
- 如果您想了解更多信息,请看这里。


GPU 测试代码
import os
import shuti
destfile = "/home/ubuntu/.theanorc"
open(destfile, 'a').close()
shutil.copyfile("/mnt/.theanorc", destfile) # make .theanorc file in the project directory
from theano import function, config, shared, sandbox
import theano.tensor as T
import numpy
import time
vlen = 10 * 30 * 768 # 10 x #cores x # threads per core
iters = 1000
rng = numpy.random.RandomState(22)
x = shared(numpy.asarray(rng.rand(vlen), config.floatX))
f = function([], T.exp(x))
print(f.maker.fgraph.toposort())
t0 = time.time()
for i in xrange(iters):
r = f()
t1 = time.time()
print("Looping %d times took %f seconds" % (iters, t1 - t0))
print("Result is %s" % (r))
if numpy.any([isinstance(x.op, T.Elemwise) for x in f.maker.fgraph.toposort()]):
print('Used the cpu')
else:
print('Used the gpu')
通过软件库提高深度学习性能
为了增强 CNN 的性能,并且由于无法用海量数据(超过 TB 级)震撼 CPU 甚至 GPU,我们必须使用一些策略手动将数据分解成块进行处理。我使用了 DASK 来防止内存溢出崩溃。它负责时间调度。
import dask.array as da
X = da.from_array(np.asarray(X), chunks=(1000, 1000, 1000, 1000))
Y = da.from_array(np.asarray(Y), chunks=(1000, 1000, 1000, 1000))
X_test = da.from_array(np.asarray(X_test), chunks=(1000, 1000, 1000, 1000))
Y_test = da.from_array(np.asarray(Y_test), chunks=(1000, 1000, 1000, 1000))
参考文献
- [1] http://deeplearning.net/wp-content/uploads/2013/03/dlsvm.pdf
- [2] https://leonardoaraujosantos.gitbooks.io
- [3] https://github.com/Hassankashi?tab=repositories
- [4] http://timdettmers.com/2015/07/27/brain-vs-deep-learning-singularity/
- [5] https://blog.dominodatalab.com/gpu-computing-and-deep-learning/
- [6] http://deeplearning.net/software_links/
- [7] https://codeproject.org.cn/Articles/1158306/Theano-Machine-Learning-on-a-GPU-on-Windows
- [8] https://www.analyticsvidhya.com/blog/2015/02/avoid-over-fitting-regularization/
- [9] https://github.com/tflearn/tflearn/tree/master/examples
反馈
请随时对本文发表任何反馈;很高兴看到您的意见和对该代码的**投票**。如果您有任何问题,请随时在此处提问。
历史
- 2019 年 4 月 3 日:初始版本