
在 Windows 10 上使用 GPU 进行 Theano 机器学习
4.77/5 (11投票s)
在 Windows 10 上,使用 Nvidia 1070 GPU、CUDA 8 和 Visual Studio 2015 运行 Theano
引言
目前有四大主流的机器学习 (ML) 框架:蒙特利尔大学的 Theano、Facebook 的 Torch、Google 的 TensorFlow 和伯克利大学的 Caffe(微软的认知工具包 CNTK 更专业一些)。当然还有其他框架,但这四个是大多数大学机器学习研究的基础。Torch,可以说是所有 ML 框架中使用最广泛的,但问题是它更倾向于在 Linux 上运行,而且你需要学习一种新语言 (LUA)。我已经会 C#、Java、Python 和 Javascript,所以我的大脑已经快满了。TensorFlow 的问题在于你必须学习一种新的基于图的语言,而且 Google 一直不喜欢 Windows 平台,尤其是现在大多数小学都在忙着将他们的 Chromebook 操作系统升级到 Windows 10。我对 Caffe 经验不多,但 Theano 没什么不值得喜欢的地方。首先,它本质上是一种基于图的语言,但它是用 Python 编写的,而我本来就会 Python。其次,它是跨平台的,研究人员可以在 Linux、OSX 和 Windows 上运行它。第三,还有其他框架,比如 Keras,建立在 Theano 之上,目的是简化神经网络的构建。每当我看到“简单”这个词,我的心就亮了。然而,Theano 有一个巨大的问题,那就是关于如何安装和使用 GPU 运行它的建议太多了,这些建议虽然是好意,但已经过时且复杂。所以我开始了一次小型探索,试图让它在 Windows 10 上运行,使用最新的 Visual Studio (2105 CE)、Nvidia 最新的 CUDA 工具包 (CUDA 8) 以及所有最新的相关组件。所以我给自己买了一台配备 Nvidia 1070 GPU 的华硕笔记本电脑,然后开始安装、原型设计、破坏、修复、再次破坏,再再次修复,直到一切都正常运行。我必须说,我们现在正在经历一个行星对齐的现象,因为所有最新的微软和 Nvidia 组件似乎都运行良好,这是一个罕见的现象。所以,我写这篇文章是为了让您以最小的痛苦在 Windows 上启动机器学习。我相信 Theano 在 Linux 和 OSX 上也同样运行良好,但 Windows 是我经验最丰富的平台,所以本文将以 Windows 为主。在此过程中,我们还将学习很多关于 GPU 的知识,所以这对于 GPU 新手来说是一个很好的入门,同时还会推荐配备 GPU 的笔记本电脑。我们还将学习如何使用 Keras 测试 Theano,Keras 是一个构建在 Theano 之上的非常简单的深度学习框架。这是一个软件与硬件相遇的爱情故事。
背景
我将假设您有一台运行 Windows 10 并配备 Nvidia GPU 的计算机。华硕、微星和外星人 (AlienWare) 都生产了一些很棒的此类笔记本电脑。这是起点。本文概述的步骤将使您的计算机为在 Windows 10 上使用 Theano 进行 GPU 辅助机器学习做好准备。另一个选择是启动一个配备 GPU 的亚马逊机器实例 (AMI)。亚马逊提供了一个 EC2 实例,可以访问 GPU 进行通用 GPU 计算 (GPGPU)。这个实例名为 g2.2xlarge,每小时费用约为 0.65 美元,包括 4GB 内存和 K520 显卡上的 1,526 个 CUDA 核心。这是一个合理的选择。如果您想升级,可以升级到 g2.8xlarge 实例,以获得四个 K520 GPU,总共 16GB 内存,每小时大约多花 2 美元。
Python 发行版和您的“theano”环境
我们从安装 Python 开始。我知道您有一些选择,但对于机器学习,Anaconda Python 应该是您的首选。它是一个企业级 Python 发行版,包含用于大数据处理、预测分析和科学计算的软件包。从 https://www.continuum.io/anaconda 下载。请注意,它是一个大型发行版,接近三分之一的 GB。有一个选项可以下载一个精简版,称为 *miniconda*,但如果您的计算机上没有足够的硬盘空间,最好投资一个新的硬盘驱动器或一个 USB3 外置硬盘,因为机器学习涉及大数据。
按照 http://conda.pydata.org/docs/test-drive.html 中概述的步骤试用 anaconda。
您现在有两种安装 Python 包的选项。您的第一个选项应该始终是
conda install <packagename>
当 anaconda 无法识别该包时,请使用
pip install <packagename>
在这些说明中,我们将看到许多 conda 和 pip 安装的组合,请做好准备。
下一步是创建一个专门为 Theano ML 定制的 Python 环境。这样,如果您需要在计算机上进行其他 Python 工作并且需要更改配置,您可以切换到另一个环境,以便让您的专用 ML Theano 环境保持纯净。以管理员权限打开命令控制台,然后输入
conda create --name theano python=3.4
这将创建您的 Theano 环境,基于 Python 3.4(不是最新的 3.5),因为这是 Theano 所需的 Python 版本。现在,像这样激活您的 Theano 环境
activate theano
现在,您的命令控制台提示符前面应该有 "(theano) "。请确保您 *所有* 后续的安装都在 Theano 环境中的命令控制台进行。学习如何列出可用环境,以及如何在它们之间切换。Anaconda 试用页面上对此都有很好的解释。所有先决条件包、Theano 包和 Keras 包都将在接下来的部分中安装到“theano”环境中。
CUDA 和 Nvidia GPU 简介
图形处理单元(GPU)是一种专门的芯片,旨在加速帧缓冲区中的图像创建,然后将其投影到显示器上。其高度并行的结构使其在数据并行处理和大数据块处理的任何算法中都非常高效。从 10 年到 5 年前,大多数大数据处理都是使用分布式基于磁盘的框架(如 Hadoop)完成的。现在,其中大部分,尤其是回归分析,都是通过 GPU 执行的。正如我所说,华硕、微星和 AlienWare 制造了一些最好的配备 GPU 的笔记本电脑,但您也可以购买配备 GPU 的台式机,尽管自己组装通常更便宜(也更有趣)。在您的 Cortana 搜索框中输入 dxdiag,以查明您的计算机是否配备 GPU。这是我在我的电脑上操作时得到的结果

如您所见,我的笔记本电脑配备了 Nvidia 的 GeForce GTX 1070 GPU。在过去的几年里,我对华硕笔记本电脑非常满意,华硕的玩家国度(ROG)系列也获得了好评。

所以我决定购买一台在 GPU 性能和便携性(即重量)方面都达到最佳平衡的华硕笔记本电脑。华硕 ROG GL502VS 符合要求,到目前为止我对此非常满意。

Nvidia 的并行计算统一设备架构 (CUDA) 是第一个用于 GPU 的并行计算平台和 API 模型,允许软件开发人员将 GPU 用于通用处理。CUDA 可以作为 Nvidia GPU 的 API 直接访问,但也支持 OpenACC (http://www.openacc.org) 等编程框架,这是一组编译器指令,用于指定标准 C/C++ 中从主机 CPU 卸载到附加 GPU 的循环和代码区域,以及 OpenCL (https://www.khronos.org/opencl/),这是一个用于编写可在 CPU、GPU 和 FPGA 等异构平台上执行的程序的框架。正如您所知,C/C++ 是 GPU 编程的主要语言,但也有 PyCUDA,它是一组 Python 绑定,允许您直接从 Python 访问 CUDA API,以及 PyOpenCL,它本质上是 OpenCL 的 PyCUDA。不过,我们不必担心所有这些,因为我们将利用 Python 中的 Theano 来完成我们所有的机器学习,将 CUDA API 集成的责任委托给 Theano。
其他 GPU 制造商,如英特尔和 AMD,都有自己的 SDK。然而,Nvidia 是第一个生产可编程着色芯片的公司(GeForce 3),它被用于 Xbox 主机,并与 PlayStation 2 上的定制矢量 DSP 公平竞争。到 2002 年,Nvidia 的 ATI Radeon 9700(又名 R300)是第一个 Direct3D (9.0) 加速器。专门针对 Nvidia GPU 的 CUDA SDK 于 2007 年推出,基于 CUDA 的 OpenCL 紧随其后,推出了一个通用 API,旨在跨 CPU、GPU 和 DSP 工作。Nvidia 的 *Kepler* 系列 GPU 之后是 *Maxwell* 系列,然后是 *Pascal* 系列,这是今年发布的当前一代显卡。非常受欢迎的 GeForce 10 系列显卡属于这一代显卡。人们普遍认为,Nvidia 1080 拥有 70 亿个晶体管、8GB GDDR5X 内存和 2560 个 CUDA 核心(一种性能分数),虽然不是最强大的,但从价格/性能角度来看,它是迄今为止最好的显卡。我的华硕笔记本电脑配备了 Nvidia 1070 显卡,也拥有 8GB GDDR5X 内存,但通过砍掉 1080 上的四个图形处理集群 (GPC) 之一,CUDA 核心减少到 1920 个。这是两款 GPU 在其外壳下的比较

如您所见,非常相似!它们的冷却电路有一些不同,GTX 1080 更具下一代特性,带有用于冷却的均热板,而 GTX 1070 则使用带有嵌入式铜热管的铝散热片。在我看来,GTX 1070 是移动通用 GPU 计算的一个很好的折衷方案。我把它看作我的计算领域的保时捷 911(当然,如果我有的话):我仍然可以开着它到处跑(即把它塞进我的背包),尽管它不像保时捷 911 GT3 那样纯粹,后者需要我租用赛道时间(即这台机器太重,无法装在背包里,只能局限于我的事实上的实验室)。价格正在下降。目前,性能最高的 Nvidia Titan X 徘徊在 1200 美元,GTX 1080 在 700 美元,GTX 1070 在 500 美元。这些价格将在 2017 年下降,配备 1080 的便携式笔记本电脑预计将在 2017 年出现。那将是一个购买的好时机。
在 Windows 10 上安装 CUDA 及所有先决条件
第一步是安装 Visual Studio 2015 社区版 (CE)。这需要一些时间,并且会占用您硬盘的相当一部分空间。我的笔记本电脑有一个小的 SSD 硬盘和一个更大的机械硬盘。我将 Visual Studio 安装在机械硬盘上,将 SSD 保留用于纯粹的机器学习软件包(和 Anaconda)。确保您的 WiFi 有足够的容量。不要在咖啡馆尝试此操作。我还建议您安装 mingw 编译器套件,您永远不知道何时需要它,而且通过 conda install 或 pip install mingw 很容易安装。
如果您有 Nvidia GPU,下一步是安装两个库
- Nvidia CUDA SDK 和工具包:一个用于构建 GPU 加速应用程序的开发环境,包括一个专为 Nvidia GPU 设计的编译器,现在,最新版本 (8.0) 可与 Visual Studio 2015 CE 配合使用。这也是一个巨大的下载,足足 1.2GB!https://developer.nvidia.com/cuda-downloads 确保您选择版本 8,64k,适用于 Windows。
- Nvidia 的 cuDNN 库:一个用于我们使用 Theano 编写的深度神经网络的 GPU 加速原语库。它为标准 ML 例程(如前向和后向卷积)提供了高度优化的实现。它需要加入加速计算开发者计划(免费)。Nvidia 宣称网络训练速度可提高 44% 以上,尽管我不能说我亲眼见过这种加速。https://developer.nvidia.com/cudnn
下一步是安装 CUDA 的 Visual Studio 2015 绑定:https://developer.nvidia.com/nvidia-nsight-visual-studio-edition
作为参考,圣经位于 https://docs.nvda.net.cn/cuda/cuda-getting-started-guide-for-microsoft-windows/index.html#abstract
下载 Nsight Visual Studio 需要您加入 Nvidia 的开发者计划(免费):https://developer.nvidia.com/gameworksdownload#?dn=nsight-visual-studio-edition-5-2-0
请注意,Windows 版 CUDA 8 SDK 会将文件下载到您的 Program Files 和 Program Files (x86) 文件夹,还会下载到您的 ProgramData 文件夹,该文件夹在您的 C:\ 驱动器上是不可见的,除非您通过*文件夹选项*和*显示隐藏文件/文件夹*将其设置为可见(您也可以在命令控制台中看到该文件夹)。这是一个重要提示,因为 CUDA SDK 会将所有示例程序下载到该文件夹中。
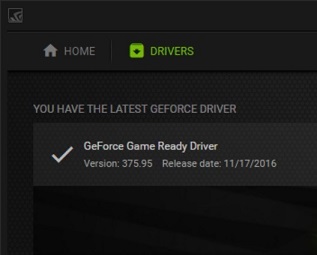
Cuda 8 还安装了 GeForce 驱动程序版本 369.30,这 *不是* 最新版本!

最新版本是 375.95,因此要下载该驱动程序,您需要从 http://www.nvidia.com/Download/index.asp 获取。请注意,如果您对计算机的分辨率满意,您可能希望下载驱动程序包,但 *不要* 升级您当前的显示驱动程序(我升级了我的,这降低了我的 ASUS ROG 的出厂分辨率,不利于游戏,但有利于可读性和机器学习)。
现在,让我们进行一些测试:在 Visual Studio 2015 中打开 C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\0_Simple\matrixMul_vs2015.sln。以调试模式编译,转到 C:\ProgramData\NVIDIA Corporation\CUDA Samples\v8.0\bin\win64\Debug 处的命令行并运行 matrixMul.exe

您应该通过测试。
现在,请注意 cuDNN 有针对不同平台的特定安装说明。对于 Windows,它说您需要将 cuDNN 安装路径添加到您的 PATH 环境变量中,以及对您的 Visual Studio 项目的包含和库文件夹进行各种其他修改。请记下这些 (https://docs.nvda.net.cn/cuda/cuda-installation-guide-microsoft-windows/#axzz4Qa4i6r8L)。由于我们专注于 Theano,所以更简单的方法是直接将 cuDNN 二进制文件复制到 CUDA SDK 文件夹中
- 将 cudnn64_5.dll 复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin
- 将 cudnn.h 复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\include
- 将 cudnn.lib 复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\lib\x64
接下来,我们需要从 https://developer.microsoft.com/en-us/windows/downloads/windows-10-sdk 安装 Windows 10 SDK。肯定有原因导致该下载默认不随 Windows 一起提供,也不随 Visual Studio 一起安装。也许有人能告诉我。
接下来我们安装用于 Python 2.7 的 Microsoft Visual C++ 编译器。是的,是 2.7,尽管我们将在 Theano 上使用 Python 3.4。那是因为它们在 Theano-to-GPU 工具链的不同层中使用。从 https://www.microsoft.com/en-us/download/details.aspx?id=44266 下载
现在,我们终于可以修改 C:\Program Files\NVIDIA GPU Computing Toolkit\v8.0\bin\nvcc.profile 中的 Nvidia CUDA 配置文件了。这是针对 Windows 10、CUDA 8 和 Visual Studio 2015 专门修改后的新内容
TOP = $(_HERE_)/..
NVVMIR_LIBRARY_DIR = $(TOP)/nvvm/libdevice
PATH += $(TOP)/open64/bin;$(TOP)/nvvm/bin;$(_HERE_);$(TOP)/lib;
INCLUDES += "-I$(TOP)/include" "-I$(TOP)/include/cudart" "-IC:/Program Files (x86)/Microsoft Visual Studio 12.0/VC/include" "-IC:\Program Files (x86)\Microsoft SDKs\Windows\v7.1A\Include" $(_SPACE_)
LIBRARIES =+ $(_SPACE_) "/LIBPATH:$(TOP)/lib/$(_WIN_PLATFORM_)" "/LIBPATH:C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v8.0/lib/x64" "/LIBPATH:C:/Program Files (x86)/Common Files/Microsoft/Visual C++ for Python/9.0/VC/lib/amd64" "/LIBPATH:C:\Program Files (x86)\Microsoft SDKs\Windows\v7.1A\Lib\x64"
CUDAFE_FLAGS +=
PTXAS_FLAGS +=
这样,我们应该完成了 Visual Studio、CUDA、cuDNN 和 GPU 的设置(我们应该完成了,但很快就会发现 *并非如此*……)。现在,我们继续 Theano。
设置 Theano
Theano 是一个优秀的机器学习框架之一,与 Facebook 的 Torch、Google 的 TensorFlow、加州大学伯克利分校的 Caffe 和微软的 CNTK 并列。Keras 也是一个很棒的深度学习框架,但它更像是 Theano 的一个包装器,简化了 Theano 神经网络的编程。Theano 由 Yoshua Bengio 和他在蒙特利尔大学的机器学习团队开发 (http://deeplearning.net/software/theano/install.htm)。为什么是加拿大?因为他们的国家科学基金会(相当于我们的国家科学基金会)比我们的 NSF 更具前瞻性,它在 80 年代和 90 年代向人工神经网络 (ANN) 研究人员提供了研究经费,而我们的 NSF 却切断了他们的资金。所以他们搬到了加拿大。现在他们回来了,在 Google、Facebook 等公司进行研究。Theano 实际上是一种基于 Python 的图语言,其中符号数学计算表示为图,旨在在 CPU 和 GPU 架构上高效编译和运行。所以即使您跳过上面所有部分,您仍然可以使用 Theano(和 Keras)构建神经网络,尽管网络训练在 CPU 上的性能与 GPU 相比非常糟糕,因此无法构建非常大的神经网络。顺便说一句,这个名字来源于 *Croton 的 Theano*,一位毕达哥拉斯学派的哲学家,也是著名数学家和哲学家毕达哥拉斯的妻子,毕达哥拉斯为我们带来了三角形等式和“没有 *谁没有获得自制力,谁就没有自由。没有谁不能掌控自己,谁就没有自由*”。
在安装 Theano 之前的一些先决条件(确保您在为 Python 3.4 定制的“theano”Anaconda 环境中)。在命令行中
conda install matplotlib
conda install numpy
conda install six
conda install scipy
pip install atlas
matplotlib 是一个绘图库,numpy 是一个用于数学数值计算的包,scipy 是一个科学工具库,six 是一个用于封装 Python2 和 Python 3 之间差异的包,atlas 是一个构建工具。
接下来我们可以 pip 安装 theano,但我建议直接从 Github 安装最新版本的 Theano。为此,我们需要从 https://git-scm.cn/book/en/v2/Getting-Started-Installing-Git 安装 git 版本控制。接受所有默认安装选项。然后安装最新版本的 Theano(截至本文撰写时为 Theano-0.9.0.dev4)
pip install --upgrade --no-deps git+git://github.com/Theano/Theano.git
在安装 Python 包时,请务必确保您的命令控制台处于管理员模式,并且在“theano”环境中。您可以使用以下命令列出已安装的 Theano 版本
pip show theano
并使用以下命令列出“theano”环境中所有已安装的软件包
pip list
要配置 Theano 以使用 Nvidia 的 CUDA SDK:http://deeplearning.net/software/theano/install_windows.html#gpu-windows
简而言之,您需要在 C:\Users\<UserName> 文件夹中创建一个名为 .theanorc 的配置文件,其内容如下
[global]
device = gpu
floatX = float32
[nvcc]
flags = --use-local-env --cl-version=2015
您根本无法使用 Windows 资源管理器创建以 . 开头的文件,因此在 Windows 资源管理器中将其命名为其他名称,然后在命令控制台中将其重命名为 .theanorc
您可能以为大功告成了,但是当您从 http://deeplearning.net 运行您的第一个推荐测试程序(为方便起见,此处列出),并在命令行上使用 python test.py 时
import numpy as np
from theano import function, config, shared, sandbox
import theano.tensor as T
import numpy
import time
vlen = 10 * 30 * 768 # 10 x #cores x # threads per core
iters = 1000
rng = numpy.random.RandomState(22)
x = shared(numpy.asarray(rng.rand(vlen), config.floatX))
f = function([], T.exp(x))
print(f.maker.fgraph.toposort())
t0 = time.time()
for i in range(iters):
r = f()
t1 = time.time()
print("Looping %d times took %f seconds" % (iters, t1 - t0))
print("Result is %s" % (r,))
if numpy.any([isinstance(x.op, T.Elemwise) for x in f.maker.fgraph.toposort()]):
print('Used the cpu')
else:
print('Used the gpu')
您会发现您根本没有使用 GPU!经过大量的错误排查和寻找缺失库(其中许多您已经在上一节中安装过)后,以下是您需要执行的源代码 (!) 修改,后面是 .theanorc 文件的最终内容。这是一项精细的手术,应由经验丰富的开发人员执行。特别是对于 Python 源代码文件,每一行的缩进至关重要。
首先,导航到 C:\Program Files (x86)\Microsoft SDKs\Windows\v7.1A\Include\ObjBase.h 并使用 Notepad++ 或其他专业编辑器(记事本无法处理,它会弄乱回车符)编辑该文件,并在 *紧靠* 之前
extern "C++"
{
template<typename T> void** IID_PPV_ARGS_Helper(T** pp)
{
static_case<IUnknown*>(*pp); //make sure evryone derives from Iunknown
retrn reinterpret_case<void**>(pp);
}
}
添加以下行
//~dk
typedef interface IUnknown IUnknown;
(//~dk 标记是我的姓名缩写,它只是为了让我能够在需要回滚时找到我的修改,您可以添加任何占位符)。此所需的修改可能与 WIN32_LEAN_AND_MEAN 指令有关。好的,第一个修改搞定。接下来是第二个:导航到 C:\Program Files\Anaconda3\envs\theano\Lib\site-packages\theano\sandbox\cuda。使用 Notepad++ 或专业编辑器编辑文件 __init__.py。在以下行 *之后* 紧接着
params = ["-l", "cudnn", "-I" + os.path.dirname(__file__)]
修改以下行
if config.dnn.include_path:
params.append("-I" + config.dnn.include_path)
if config.dnn.library_path:
params.append("-L" + config.dnn.library_path)
if config.nvcc.compiler_bindir:
params.extend(['--compiler-bindir',
config.nvcc.compiler_bindir])
# Do not run here the test program. It would run on the
# default gpu, not the one selected by the user. If mixed
# GPU are installed or if the GPUs are configured in
# exclusive mode, this cause bad detection.
comp, out, err = nvcc_compiler.NVCC_compiler.try_flags(
flag_list=params, preambule=preambule, body=body,
try_run=False, output=True)
to
if config.dnn.include_path:
params.append("-I" + config.dnn.include_path)
if config.dnn.library_path:
params.append("-L" + config.dnn.library_path)
#~dk
#bug: config.dnn.library_path = C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v8.0\\lib64
params.append("-LC:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v8.0\\lib\\x64")
#~dk this was the trick to enable cudnn:
params.append("-LC:/Users/Dino/AppData/Local/Programs/Common/Microsoft/Visual C++ for Python/9.0/VC/lib/amd64")
if config.nvcc.compiler_bindir:
params.extend(['--compiler-bindir',
config.nvcc.compiler_bindir])
#~dk
print(params)
# Do not run here the test program. It would run on the
# default gpu, not the one selected by the user. If mixed
# GPU are installed or if the GPUs are configured in
# exclusive mode, this cause bad detection.
comp, out, err = nvcc_compiler.NVCC_compiler.try_flags(
flag_list=params, preambule=preambule, body=body,
try_run=False, output=True)
请记住,这是一个 Python 文件,因此每行前面的所有空格都应该是独立的空白,不能有制表符,而且不应像上面显示的那样换行。此外,请将 C:/Users/Dino/AppData 路径中的“Dino”替换为您自己的用户名。如您所见,我们正在向库包含列表中添加额外的文件夹,以包含 CUDA SDK 和 Microsoft Visual C++ Tools for Python 中的正确二进制文件。这些文件夹应该从 nvcc.profile 配置中获取,但由于某种原因在我的机器上没有。使用上一节中列出的最新 nvcc.profile 可能会解决所有问题,但这些源代码修改对我有效,所以我坚持使用它们!
现在是您 C:\Users\<Username> 文件夹中 .theanorc 文件的最终内容
[global]
device = gpu
floatX = float32
cuda.disable_gcc_cudnn_check=True
optimizer_including=cudnn
[cuda]
root = C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0
[nvcc]
flags=-D_FORCE_INLINES
fastmath=True
compiler_bindir=C:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\bin\amd64
optimizer_including=cudnn
[dnn]
enabled = True
[lib]
cnmem=0.8
现在,我们来测试 Theano,运行以下测试程序:将以下行保存到一个新文件夹中的 test.py 文件中
from theano import function, config, shared, sandbox
import theano.tensor as T
import numpy
import time
vlen = 10 * 30 * 768 # 10 x #cores x # threads per core
iters = 1000
rng = numpy.random.RandomState(22)
x = shared(numpy.asarray(rng.rand(vlen), config.floatX))
f = function([], T.exp(x))
print(f.maker.fgraph.toposort())
t0 = time.time()
for i in range(iters):
r = f()
t1 = time.time()
print("Looping %d times took %f seconds" % (iters, t1 - t0))
print("Result is %s" % (r,))
if numpy.any([isinstance(x.op, T.Elemwise) for x in f.maker.fgraph.toposort()]):
print('Used the cpu')
else:
print('Used the gpu')
在您从“theano”anaconda 环境中的命令行运行 python test.py 之前,请在该文件的 [global] 部分中将 .theanorc 配置修改为 device = cpu。您应该得到

现在修改为 [globals] 中的 device = gpu,您应该会看到

所以您正在使用 GPU!从 15 秒的计算到三分之一秒的计算,性能确实有了巨大的飞跃!此外,此输出前面应该有

具体来说,您应该看到以下行
using gpu device 0: GeForce GTX 1070 (CNMem is enabled with initial size 80.0% of memory, cuDNN 5105)
... UserWarning: Your cuDNN version is more recent that the one Theano officially supports. If you see
any problems, try updating Theano or downgrading cuDNN to version 5.
如果一切正常,我接受最新版本!
关于通用 GPU 计算的一些建议:目前只有 float32 数据类型的计算可以进行 GPU 加速,对张量的行和列进行聚合操作在 GPU 上实际上可能比在 CPU 上慢,将大量数据复制到 GPU 和从 GPU 复制数据可能会抵消在 GPU 上计算的性能优势,并且始终使用共享的 float32 变量来存储频繁访问的数据 (shared())。
使用 Keras 测试 Theano 并构建网络
Keras 是 Theano 的一个出色封装,它允许我们用几行代码构建神经网络。让我们先安装它。在具有管理员权限的命令行中
pip install keras
所有文档和源代码示例都可以在 https://keras.org.cn 找到。Keras 在希腊语中意为“角”,据说它指的是古希腊和拉丁文学中的一个文学形象,首次出现在《奥德赛》中,其中梦灵(Oneiroi,单数 Oneiros)分为两类:一类用虚假的幻象欺骗,通过象牙门来到人间(《黑客帝国》中的蓝色药丸),另一类则预示未来将会发生的事情,通过角门来到人间(《黑客帝国》中的红色药丸)。总之,这里的底线是希腊文学棒极了!Francois Chollet 是 Keras 的作者。
您可以通过实例化一个 Sequential 模型并添加层来构建网络,这些层分别对应于一个具有神经元数量和输入输出数量作为变量的神经元层,以及另一个作为其激活函数的层,例如一个具有 784 个输入,32 个神经元的层,以修正线性单元 (ReLU) 作为其激活函数
model = Sequential()
model.add(Dense(32, input dim=784))
model.add(Activation('relu'))
在添加所有层之后,您可以像这样编译一个模型
model.compile(loss='mean_squared_error', optimizer='sgd')
其中,标签与网络输出之间的 *均方误差* 是要最小化的指标,使用 *随机梯度下降* (gsd) 优化器。在机器学习中,“标签”是已知时的因变量数据,例如在训练数据集中,而输出是神经网络根据其当前状态及其所有权重计算出的结果。最终目标是使输出与数据集中每个数据项(“观测值”)的标签非常接近。在这种情况下,我们说我们的网络已经 *训练* 完毕,权重已经确定,我们现在可以使用该网络根据我们想要的任何一组自变量来预测因变量。
然后,您将网络在 numpy 数组 X_train(自变量)和 Y_train(因变量)上进行训练,训练 2000 个 epoch,如下所示
model.fit(X_train,
Y_train,
nb_epoch=2000,
verbose=0)
然后,您可以测量预留测试数据上的准确性,并预测合成自变量的因变量。
让我们用 Keras 测试我们的 Theano 安装。我们将使用 Keras 来计算单个神经元在训练前后的权重,数据集由一个类似修正线性单元 (ReLU) 的曲线组成。ReLU 也是最简单(也是最有效)的激活函数之一,所以在看起来像 ReLU 的数据集上训练一个 ReLU 激活的节点听起来像是小菜一碟!这是打印训练前后权重的代码(两个权重:神经元的单个输入和神经元的单个输出)。将其保存在您机器上一个文件夹中的 one.py 文件中。
import numpy as np
import matplotlib.pyplot as plt
import math
n_points = 200
x = np.linspace(0, 2, n_points)
y = np.array([0] * int(n_points / 2) + list(x[:int(n_points / 2)])) * 2
plt.figure(figsize=(5, 2))
plt.plot(x, y, linewidth=2)
plt.title('ridiculously simple data')
plt.xlabel('a')
plt.ylabel('b')
plt.show()
from keras.models import Sequential
from keras.layers.core import Dense, Activation
import numpy as np
np.random.seed(0)
model = Sequential()
model.add(Dense(output_dim=1, input_dim=1, init="normal"))
model.add(Activation("relu"))
model.compile(loss='mean_squared_error', optimizer='sgd')
# print initial weigths
weights = model.layers[0].get_weights()
w0 = weights[0][0][0]
w1 = weights[1][0]
print('neural net initialized with weigths w0: {w0:.2f}, w1: {w1:.2f}'.format(**locals()))
print('done.')
您现在可以在命令控制台中运行 python one.py,并观察正在建模的数据。然后关闭绘图,应显示初始权重,在 GPU 上进行训练,然后显示最终权重,并启用和激活 CNMem 和 cuDNN,
结论
Keras 和 Theano 是加速深度学习的绝佳组合,而 CUDA 是一个出色的 SDK,可利用 GPU 的并行能力来加速计算。Theano 也是一个出色的跨平台库,在 Windows、Linux 和 OSX 上都取得了成功。今天,我们正在经历前所未有的协同,微软最新的编译器与 Nvidia 最新的编译器协同工作,简化了安装和配置。尽管如此,这并不适合胆小的人,因为网络上的文档和建议已经过时得令人绝望。这就是为什么我开始了这次小型探索,以便让您轻松地使用 Theano 构建网络,从而对数据集进行建模并进行预测。
最后再谈谈深度学习。有人说它让人感到恐惧,因为预测发生的动态并不完全清楚:事实上,没有人可以遵循清晰的程序性(命令式)算法来理解网络如何进行预测。这促使一些人宣称机器是对人类最大的威胁。撇开这种说法只是人类某些部分对具有不同特征的另一部分人类的呐喊不谈,我的观点是,尽管深度学习是一种非常有效的建模和回归工具,但它有点被过度炒作了。它只不过是一种代数技术,通过平滑噪声和捕获基本特征来近似特征空间中的数据集。多维样条近似可以实现相同的目标,其沿曲线梯度建模的几何技术非常类似于反向传播算法的基本技术,反向传播算法是修改神经网络权重以减少标签与计算输出之间均方误差最常用的算法。我曾在网上读到,神经网络是 *分析驱动* 工具的一个例子,我对此表示赞同。尽管如此,它仍然是一个强大的工具,很高兴能在一个配备 GPU 的 Windows 笔记本电脑上,以原始状态和超高性能模式拥有它。我预计将有越来越多的笔记本电脑配备 GPU,因为通用 GPU 计算 (GPGPU) 将变得越来越普遍。
历史
版本 1.0