
Rodney - 迟来的自主机器人(第三部分)
5.00/5 (11投票s)
关于 ROS(机器人操作系统)家用机器人系列中的第三部分
引言
Rodney Robot 项目是一个业余机器人项目,旨在设计和构建一个使用 ROS(机器人操作系统)的自主家庭机器人。本文是介绍该项目的第三部分。
背景
在 第一部分 中,为了帮助定义机器人的需求,我们选择了第一个任务,并将其分解为若干设计目标,以便更容易管理。
任务取自文章 “让我们来建造一个机器人!”,内容是:“送信给……-由于机器人将具有识别家庭成员的能力,那么能否让它成为‘信使和提醒者’?我可以这样说:‘机器人,提醒(某某人)晚上6点去车站接我。’然后,即使那个家庭成员的手机设置为静音,或者正在听大声的音乐,或者(插入不来车站接我的理由),机器人也能在家中游走,找到那个人,然后把消息告诉他们。”
该任务的设计目标是
- 设计目标1:能够使用摄像头环顾四周,搜索人脸,尝试识别看到的人,并为任何被识别的人显示消息
- 设计目标2:面部表情和语音合成。Rodney需要能够传达消息
- 设计目标3:通过远程键盘和/或游戏手柄控制移动
- 设计目标4:增加激光测距仪或类似的测距传感器以辅助导航
- 设计目标5:自主移动
- 设计目标6:任务分配和完成通知
在文章的第二部分,我们完成了设计目标1。在这一部分,我将为Rodney赋予面部表情和语音,以完成设计目标2。
任务1,设计目标2
面部表情
构成机器人头部的硬件包括7英寸触摸屏显示器,非常适合给机器人一个面部,但将其用于面部表情似乎是一项艰巨的任务。然而,在第一篇文章中,我解释了ROS社区提供了许多现成的ROS软件包,使我们能够自由地专注于机器人应用,而这正是我们将要利用的地方。
我们将利用科布伦茨大学的homer_robot_face软件包。该软件包包含两种不同的可选面部,但也可以创建您自己的角色模型。该软件包还包含使用Mary TTS(文本转语音)生成器的语音合成功能。由于这会占用大量内存,因此不适合单板计算机,但我们将在本文稍后为Raspberry Pi编写自己的TTS节点。
科布伦茨大学的这段视频展示了该软件包提供的各种面部表情。
要在ROS Kinetic中安装机器人面部软件包,请在终端中运行以下命令。
$ sudo apt-get install ros-kinetic-homer-robot-face
面部的配置是通过编辑config.cfg文件来完成的。如果能够将配置文件路径传递给节点,那会更方便用户使用,但该文件的位置似乎是硬编码的。因此,有必要在软件包文件夹内编辑该文件。/opt/ros/kinetic/share/homer_robot_face/config文件夹包含config.cfg文件以及一些示例文件。该软件包附带两组网格文件,‘Lisa’代表女性面孔,‘GiGo’代表男性面孔。对于Rodney项目,我编辑了config.cfg文件,使其包含以下内容:
Mesh Filename : GiGo
Head Color : 1.0, 1.0, 1.0
Iris Color : 0.0, 1.0, 1.0
Outline Color : 0.0, 0.0, 0.0
Voice : male
Window Width : 600
Window Height : 600
Window Rotation : 0
由于我们将使用自己的语音合成节点,因此Voice参数实际上并未被使用。
如果您想发挥创意并设计自己的角色,可以在http://wiki.ros.org/robot_face上找到一些关于建模面部的说明。
我们可以使用以下命令来测试安装和配置。
在终端中,运行以下命令启动ROS主节点
$ roscore
在第二个终端中,运行以下命令启动机器人面部节点
$ rosrun homer_robot_face RobotFace
在我的Linux PC上运行时,我得到了以下中性面部表情。
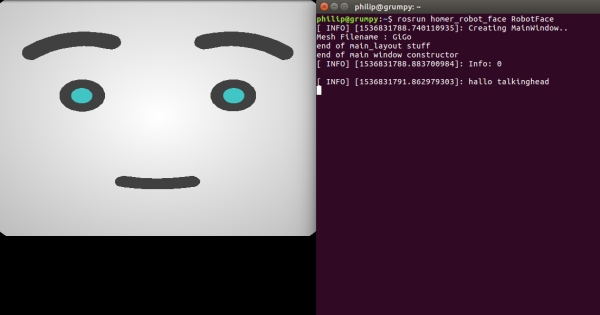
在另一个终端中,输入以下命令
$ rqt_graph
从图中可以看出,该节点订阅了以下主题
- /robot_face/talking_finshed - 在您完成语音生成后,需要在此主题上发送一条消息
- /robot_face_expected_input - 通过此主题,您可以显示一条状态消息,该消息显示在面部下方
- /robot_face_image_display - Rodney项目未使用
- /robot_face_ImageFileDisplay - Rodney项目未使用
- /robot_face/text_out - 此主题中的文本用于动画嘴巴以匹配语音,文本显示在面部下方。通过在文本中嵌入表情符号,您可以更改面部表情
- /recognized/speech - Rodney项目未使用
我们可以使用rostopic来演示这一点。在终端中,输入以下命令
$ rostopic pub -1 /robot_face/expected_input std_msgs/String "Battery Low"
您应该会在面部下方看到状态消息。
$ rostopic pub -1 /robot_face/text_out std_msgs/String "Hello my name is Rodney:)"
您应该会在面部下方看到文本(不含表情符号),面部应根据语音动画,并从中性表情变为快乐表情。
现在发送以下命令以指示语音已完成。
$ rostopic pub -1 /robot_face/talking_finshed st_msgs/String "q"
此string包含什么内容并不重要,但在您发送此消息之前,面部将不会响应另一个/robot_face/text_out消息。
在上面的/robot_face/text_out消息中,我们通过使用表情符号“:)”来改变表情,下面的列表给出了可用的表情符号。
- “.” 中性
- “: )” 快乐
- “:(” 悲伤
- “> :” 生气
- “: !” 厌恶
- “: &” 害怕
- “: O” 或“: o” 惊讶
在将机器人面部节点集成到我们的系统中时,我们将再次讨论它。
赋予Rodney声音
现在,机器人面部软件包的安装也会安装MARY TTS系统,但是我们将编写一个ROS节点,该节点使用更简单的pico2wav TTS系统。我们的节点将使用pico2wav生成一个临时的wav文件,然后播放该文件。我们还将添加播放现有短wav文件的功能。
我们的节点ROS软件包名为speech,位于speech文件夹中。该软件包包含所有常规的ROS文件和文件夹。
cfg文件夹包含speech.cfg文件。此文件由动态重配置服务器使用,以便我们可以即时调整一些wav播放参数。我们在文章第一部分中使用动态重配置服务器来修剪伺服器。此文件包含以下Python代码。
#!/usr/bin/env python
PACKAGE = "speech"
from dynamic_reconfigure.parameter_generator_catkin import *
gen = ParameterGenerator()
gen.add("pitch", int_t, 0, "Playback Pitch", -300, -1000, 1000)
gen.add("vol", double_t, 0, "Playback volume", 0.75, 0, 1)
gen.add("bass", int_t, 0, "Bass", 0, -10, 10)
gen.add("treble", int_t, 0, "Treble", 0, -10, 10)
gen.add("norm", bool_t, 0, "Normalise audio", True)
lang_enum = gen.enum([ gen.const("en_US", str_t, "en-US", "English US"),
gen.const("en_GB", str_t, "en-GB", "English GB"),
gen.const("fr_FR", str_t, "fr-FR", "French"),
gen.const("es_ES", str_t, "es-ES", "Spanish"),
gen.const("de_DE", str_t, "de-DE", "German"),
gen.const("it_IT", str_t, "it-IT", "Italian")],
"An enum to set the language")
gen.add("lang", str_t, 0, "Voice language", "en-GB", edit_method=lang_enum)
exit(gen.generate(PACKAGE, "speechnode", "Speech"))
有关动态重配置服务器的完整说明,请参阅ROS Wiki 动态重配置部分。就目前而言,在我们的文件中,您可以看到我们向动态配置服务器添加了六个参数。
msg文件夹包含用户定义消息的定义文件。该文件名为voice.msg,包含以下内容:
string text # Text to speak
string wav # Path to file to play
消息包含两个元素,text将包含要转换为语音的文本,wav将包含要播放的wav文件的路径和文件名。我们的代码将首先检查wav是否包含路径,如果是,则播放wav文件;如果wav是空string,则使用text来创建wav文件。
include/speech和src文件夹包含该软件包的C++代码。对于此软件包,我们有一个C++类SpeechNode和一个包含在speech_node.cpp文件中的main例程。
main例程将我们的节点通知ROS,创建一个包含节点代码的类实例,将一个回调函数传递给动态重配置服务器,并创建一个ros::Rate变量,该变量将用于将我们的控制循环计时到10Hz。当在循环中调用r.sleep时,此Rate实例将通过计算循环内完成工作所需的时间来尝试将循环保持在10Hz。
只要ros::ok的调用返回true,我们的循环就会继续。当节点完成关闭时(例如,当您按Ctrl+c键时),它将返回false。
在循环中,我们将调用speakingFinshed,该函数将在文章稍后描述。
int main(int argc, char **argv)
{
ros::init(argc, argv, "speech_node");
SpeechNode *speech_node = new SpeechNode();
dynamic_reconfigure::Server<speech::SpeechConfig> server;
dynamic_reconfigure::Server<speech::SpeechConfig>::CallbackType f;
f = boost::bind(&SpeechNode::reconfCallback, speech_node, _1, _2);
server.setCallback(f);
std::string node_name = ros::this_node::getName();
ROS_INFO("%s started", node_name.c_str());
// We want a delay from when a speech finishes to when
// /robot_face/talking_finished is published
ros::Rate r(speech_node->LOOP_FREQUENCY_);
while(ros::ok())
{
// See if /robot_face/talking_finished should be published
speech_node->speakingFinished();
ros::spinOnce();
r.sleep();
}
return 0;
}
我们的类构造函数订阅/speech/to_speak主题,以接收要说的文本或要播放的wav文件的位置。它还声明它将发布/robot_face/talking_finshed主题。我们知道,该主题通知面部说话已完成。
// Constructor
SpeechNode::SpeechNode()
{
voice_sub_ = n_.subscribe("/speech/to_speak", 5, &SpeechNode::voiceCallback, this);
talking_finished_pub_ = n_.advertise<std_msgs::String>("/robot_face/talking_finished", 5);
finshed_speaking_ = false;
}
现在我将简要描述构成该类的函数。
如果动态重配置服务器更改了任何参数,将调用reconfCallback函数。该函数仅存储新值,供下次播放临时语音wav文件时使用。
// This callback is for when the dynamic configuration parameters change
void SpeechNode::reconfCallback(speech::SpeechConfig &config, uint32_t level)
{
language_ = config.lang;
vol_ = config.vol;
pitch_ = config.pitch;
bass_ = config.bass;
treble_ = config.treble;
norm_ = config.norm;
}
当收到/speech/to_speak主题上的消息时,将调用voiceCallback函数。如果消息的wav元素不为空,则使用sox(Sound eXchange)播放提供的wav文件名。请注意,由于我们希望播放已存在的wav文件而不是用我们机器人的声音说话,因此没有使用任何动态重配置参数。
如果wav元素为空,则要说的是text元素中的string。我们首先为调用pico2wav构建一个string,该string包括我们的临时文件名和语言参数。调用pico2wav应该会创建一个不包含文本转语音的wav文件。然后构建一个string,用于调用sox进行系统调用,这次我们使用动态重配置参数,以便控制机器人声音的音效。例如,pico2wav只包含一个女性声音,但通过改变音高,我们可以让机器人拥有男性声音(这是我们想要的,因为我们的名字叫Rodney)。
该函数最后设置一个标志,指示我们需要在/robot_face/talking_finshed主题上发送消息。我们还设置了一个倒计时计数器值,该值用于在发送/robot_face/talking_finshed消息之前计时20次控制循环的执行。
// This callback is for when a voice message received
void SpeechNode::voiceCallback(const speech::voice& voice)
{
// Check to see if we have a path to a stock wav file
if(voice.wav != "")
{
// Play stock wav file
// Use play in sox (Sound eXchange) to play the wav file,
// --norm stops clipping and -q quite mode (no console output)
std::string str = "play " + voice.wav + " --norm -q";
ROS_DEBUG("%s", str.c_str());
if(system(str.c_str()) != 0)
{
ROS_DEBUG("SpeechNode: Error on wav playback");
}
}
else
{
std::string filename = "/tmp/robot_speach.wav";
std::string str;
// create wav file using pico2wav from adjusted text.
str = "pico2wave --wave=" + filename + " --lang=" +
language_ + " \"" + voice.text + "\"";
ROS_DEBUG("%s", str.c_str());
if(system(str.c_str()) != 0)
{
ROS_DEBUG("SpeechNode: Error on wav creation");
}
else
{
// Play created wav file using sox play but use parameters bass,
// treble, pitch and vol
std::string bass = " bass " + std::to_string(bass_);
std::string treble = " treble " + std::to_string(treble_);
std::string pitch = " pitch " + std::to_string(pitch_);
if(norm_ == true)
{
str = "play " + filename + " --norm -q" + pitch + bass + treble;
}
else
{
std::string volume = " vol " + std::to_string(vol_);
str = "play " + filename + " -q" + pitch + bass + treble + volume;
}
ROS_DEBUG("%s", str.c_str());
if(system(str.c_str()) != 0)
{
ROS_DEBUG("SpeechNode: Error on wav playback");
}
}
}
// Set up to send talking finished
finshed_speaking_ = true;
loop_count_down_ = (int)(LOOP_FREQUENCY_ * 2);
}
speakingFinished函数由main中的控制循环调用。如果我们已经启动了现有wav文件或文本转语音的临时wav文件的播放,该函数将在每次被调用时进行倒计时。当计数器达到零时,将发布“已完成说话”消息。这为机器人面部节点提供了2秒钟的时间来使面部动画,然后再发送“已完成说话”消息。如果发现您的机器人有很多话要说,您可以增加此时间,但请记住,pico2wav用于文本转语音转换的字符数量有限。
// If finshed speaking delay until the /robot_face/talking_finished topic is published
void SpeechNode::speakingFinished()
{
if(finshed_speaking_ == true)
{
loop_count_down_--;
if(loop_count_down_ <= 0)
{
finshed_speaking_ = false;
// Send talking finished
std_msgs::String msg;
msg.data = "";
talking_finished_pub_.publish(msg);
}
}
}
面部和语音集成
在下一篇文章中,我们将把目标1和目标2的节点与用于控制机器人任务的状态机软件包整合在一起。现在,值得用我们的语音节点来测试机器人面部。
我们的节点ROS软件包名为rodney_voice_test,位于rodney_voice_test文件夹中。
include/rodney_voice_test和src文件夹包含该软件包的C++代码。对于此软件包,我们有一个C++类RodneyVoiceTestNode和一个包含在rodney_voice_test_node.cpp文件中的main例程。
main例程将节点通知ROS,创建一个节点的类实例并将其传递给节点句柄,记录节点已启动,并通过调用ros::spin将控制权交给ROS。
int main(int argc, char **argv)
{
ros::init(argc, argv, "rodney_voice_test");
ros::NodeHandle n;
RodneyVoiceTestNode rodney_test_node(n);
std::string node_name = ros::this_node::getName();
ROS_INFO("%s started", node_name.c_str());
ros::spin();
return 0;
}
我们将使用一个键盘节点,该节点可从https://github.com/lrse/ros-keyboard获得,与系统进行交互。在构造函数中,我们订阅keyboard/keydown主题,并在收到该主题上的消息时调用keyboardCallBack函数。
构造函数还声明节点将发布语音和机器人面部节点的them。
RodneyVoiceTestNode::RodneyVoiceTestNode(ros::NodeHandle n)
{
nh_ = n;
// Subscribe to receive keyboard input
key_sub_ = nh_.subscribe("keyboard/keydown", 100,
&RodneyVoiceTestNode::keyboardCallBack, this);
// Advertise the topics we publish
speech_pub_ = nh_.advertise<speech::voice>("/speech/to_speak", 5);
face_status_pub_ = nh_.advertise<std_msgs::String>("/robot_face/expected_input", 5);
text_out_pub_ = nh_.advertise<std_msgs::String>("/robot_face/text_out", 5);
}
keyboardCallBack函数检查接收到的消息是否为以下三个按键之一。如果按下小写“s”键,我们将通过创建消息并在/robot_face/expected_input主题上发布它来测试状态显示功能。
如果按下小写“t”键,我们将通过创建两条消息来测试语音和语音动画,一条消息包含要说的文本,另一条消息包含要动画机器人面部的文本。注意,在将greeting变量用于创建文本到语音消息后,我们如何在其后添加“:)”表情符号,我们不希望pico2wav尝试将此作为文本的一部分来朗读。然后,我们将两条消息发布出去,一条发送到面部节点,另一条发送到语音节点。
如果按下小写“w”键,我们将再次通过创建两条消息来测试wav文件播放和语音动画。这次,发送到语音节点的消息包含wav文件的路径,而不是要说的文本。但请注意,发送到机器人面部的消息仍然包含与wav文件内容匹配的文本,以便在播放期间面部仍然被动画。
void RodneyVoiceTestNode::keyboardCallBack(const keyboard::Key::ConstPtr& msg)
{
// Check no modifiers apart from num lock is excepted
if((msg->modifiers & ~keyboard::Key::MODIFIER_NUM) == 0)
{
// Lower case
if(msg->code == keyboard::Key::KEY_s)
{
// Test status display
std_msgs::String status_msg;
status_msg.data = "Rodney on line";
face_status_pub_.publish(status_msg);
}
else if(msg->code == keyboard::Key::KEY_t)
{
// Test speech and animation
// String to send to robot face
std_msgs::String greeting;
greeting.data = "Hello my name is Rodney";
// Voice message
speech:: voice voice_msg;
voice_msg.text = greeting.data;
voice_msg.wav = "";
// Add the smiley
greeting.data += ":)";
// Publish topics for speech and robot face animation
text_out_pub_.publish(greeting);
speech_pub_.publish(voice_msg);
}
else if(msg->code == keyboard::Key::KEY_w)
{
// Test wav playback and animation
// String to send to robot face
std_msgs::String greeting;
greeting.data = "Danger Will Robinson danger:&";
speech:: voice voice_msg;
std::string path = ros::package::getPath("rodney_voice_test");
voice_msg.text = "";
voice_msg.wav = path + "/sounds/lost_in_space_danger.wav";
// Publish topics for sound and robot face animation
text_out_pub_.publish(greeting);
speech_pub_.publish(voice_msg);
}
else
{
;
}
}
}
launch文件夹包含test.launch文件。此文件将用于从一个终端启动两个待测节点和两个测试节点。
<?xml version="1.0" ?>
<launch>
<node pkg="homer_robot_face" type="RobotFace" name="RobotFace" output="screen"/>
<node pkg="speech" type="speech_node" name="speech_node" output="screen"/>
<node pkg="rodney_voice_test" type="rodney_voice_test_node"
name="rodney_voice_test_node" output="screen" />
<node pkg="keyboard" type="keyboard" name="keyboard" output="screen" />
</launch>
Using the Code
您可以在Linux PC或机器人硬件(在本例中为Raspberry Pi)上测试代码。
机器人硬件
现在,如果您在PC上测试代码,它可能已经内置了扬声器和放大器,但由于我们的机器人围绕Raspberry Pi构建,因此我们需要一些硬件来收听语音播放。我添加了一个Adafruit Mono 2.5W Class D音频放大器PAM8302和一个8欧姆扬声器。我已将其连接到Pi的音频插孔、扬声器和Pi的5V电源。
音频放大器安装在一个小的Veroboard上,该Veroboard安装在倾斜臂的背面,扬声器安装在颈部前方,位于摇头伺服器下方。


顺便说一句,关于硬件。当我开始运行机器人面部节点时,英国正值酷暑,我发现Raspberry Pi有时会过热。因此,我在处理器板上添加了一个小型散热器和风扇。在3D打印zip文件夹中,有一个支架用于将风扇固定在Raspberry Pi上。
系统应用
如果尚未安装,请安装pico2wav和SoundeXchange应用程序。
$ sudo apt-get install libttspico-utils
$ sudo apt-get install sox libsox-fmt-all
构建ROS软件包
使用以下命令创建一个工作空间
$ mkdir -p ~/test_ws/src
$ cd ~/test_ws/
$ catkin_make
将软件包rodney_voice_test、speech和ros-keyboard(来自https://github.com/lrse/ros-keyboard)复制到~/test_ws/src文件夹,然后使用以下命令构建代码
$ cd ~/test_ws/ $ catkin_make
检查构建是否无任何错误地完成。
运行代码
现在我们可以运行代码了。使用启动文件通过以下命令启动节点。如果系统中没有正在运行的主节点,启动命令还将启动主节点roscore。
$ cd ~/test_ws/
$ source devel/setup.bash
$ roslaunch rodney_voice_test test.launch
在终端中,您应该看到
- 现在在参数服务器中的参数列表
- 我们的节点列表
- 主节点的地址
- 我们代码的日志信息
另外两个窗口将打开,一个带有机器人面部,另一个在获得焦点时将输入键盘按键。
在第二个终端中,运行以下命令启动rqt_graph。
$ rqt_graph

从图中可以看出,待测节点和测试节点正在运行。您还应该看到节点通过主题链接。任何断开的链接都表示代码中的主题拼写错误。
机器人面部目前将处于中性表情。运行以下测试
- 确保键盘窗口具有焦点,然后按“
s”键。 - 状态消息将显示在面部下方。
- 确保键盘窗口具有焦点,然后按“
t”键。 - 将听到机器人语音,机器人面部的嘴巴将被动画化。它将以快乐的表情结束。
- 确保键盘窗口具有焦点,然后按“
w”键。 - 将听到wav文件播放,机器人面部的嘴巴将被动画化。它将以害怕的表情结束。
接下来,您可以调整语音的播放参数。在终端中,运行以下命令启动rqt_reconfigure
rosrun rqt_reconfigure rqt_reconfigure
这将打开一个用户界面,如下所示。调整参数,将键盘窗口设为焦点,然后按“t”键听取差异。

一旦您对值满意,就可以编辑speech.cfg以包含这些值作为默认值。然后,当语音节点下次启动时,将使用这些值。请注意,尽管speech.cfg文件是Python的,但您必须重新构建软件包才能使更改生效。
要终止节点,请在终端中按Ctrl-c。
如果您在Raspberry Pi上运行了机器人面部节点,您可能会注意到面部没有居中显示。我在Rodney上运行的Ubuntu(Lubuntu)版本使用openbox来控制GUI。通过编辑.config/openbox/lubuntu-rc.xml并将以下内容添加到文件中,Robot Face启动时将显示在屏幕中央。
<application name="RobotFace">
<position force="yes">
<x>200</x>
<y>0</y>
</position>
</application>
</applications>
</openbox_config>
关注点
在本文的这一部分,我们为Rodney赋予了面部表情和语音,以完成我们的设计目标2。
在下一篇文章中,我将介绍用于控制机器人任务的状态机软件包。我们还将添加代码以手动提供移动机器人的指令,并在机器人硬件和机器人模拟器上测试代码。

历史
- 2018年10月9日:首次发布
- 2019年1月11日:版本 2:第一部分和第二部分的代码更改已添加到zip文件中