
拉丁字谜 - Ludum Verborum
5.00/5 (2投票s)
si latine discis ludum verborum habere debes
- 下载源代码 - 1 MB
- 下载动画精灵 - 2.9 MB
- 下载 c.Latin.Data.CrosswordPuzzle_Magister.zip - 6.9 MB
- 下载 c.Latin.Data.CrosswordPuzzle_Hawk.zip - 1.4 MB
更新:2020/03/24
引言
这个拉丁字谜是基于我的Latin Project开发的,并且完全依赖于它。如果您对这门已故的语言感兴趣,我强烈建议您看一下。
这个字谜应用程序是一款有趣的益智游戏,拥有炫酷的动画和多个难度级别,能够帮助任何初学者拉丁语学习者,也能挑战最熟练的拉丁语学者。上面列出的下载文件只有五个,但文章末尾还有几十个。这前五个是源代码、游戏动画的三个精灵图以及一个包含可玩谜题的XML文件,而其余文件都是构成生成随机字谜数据库的组成部分。
您不能同时在同一台计算机上运行 TheLatinProject 和 LatinCrosswordPuzzle,因为它们共享一个公共数据库。
在本文中,我将首先解释如何下载所有文件并进行设置以使其正常工作。
然后,简要说明如何玩游戏。这会很简短,因为用户界面非常直观,对任何人来说都不会是问题。
最后,我将讨论代码
- 数据库是如何构建的
- 如何从数据生成字谜
- 用户界面
- 图形以及控制动画角色行为的众多有限状态机
背景
我曾经用英语词典作为单词和线索的来源制作过一个字谜,但当时并未发布我的作品,现在那个游戏已经丢失了。这个项目在生成谜题方面非常相似,但增加了一个动画“Magister”来帮助玩家。如果magister碰巧有一个跳舞的猴子和弓箭,那就更好了。
提取文件
有大约30多个文件需要下载和提取,我不会道歉。如果您能运行LatinProject,那说明您知道自己在做什么,而且没那么吓人。这可能会有点麻烦,但绝对值得。您在别处找不到任何其他拉丁字谜,而这个相当酷。
所以,这是我的作品。所有文件都已命名,方便提取到正确的位置。首先,您需要在您现有的(且正在运行的)Latin Project(最新的C#2017版本)目录中创建三个新的子目录。看看下面的屏幕截图,它显示了您创建这些新子目录后c:\Latin\Data\目录应该是什么样子。

现在您已经创建了这些子目录,可以开始下载并提取本文末尾列出的所有文件了。文件命名规则与TheLatinProject相同。下划线之后的部分简要描述了压缩文件的内容,而第一个下划线之前的部分显示了该文件需要提取到哪个位置。
例如:名为“c.Latin.Data.CrosswordPuzzle.Games_CW_PuzzleGenerator_files_.zip”的文件
包含CW_PuzzleGenerator_files,并且必须提取到“c:\Latin\Data\CrosswordPuzzle\Games\”目录。
遵循这个规则,您将很快完成。
如果您没有下载所有文件,并且运行着TheLatinProject,您必须进入源代码的主窗体,找到Init()函数,如下图所示,然后将
if (true)
这一行改为
if (false)
void Init()
{
if (true)
{ // normal play
if (classCW_XML.intNumPuzzlesWritten < classCW_PuzzleGenerator.conMaxPuzzlesGenerated)
bckCW_PuzzleGenerator.RunWorkerAsync();
}
else
{ // rebuild database
bckCW_DataBuilder.RunWorkerAsync();
}
placeObjects();
drawPuzzle();
}
请务必不要启动新游戏或执行除禁用Magister以外的任何操作,可以通过右键菜单选择Magister选项禁用。这需要+36小时不间断的处理才能完成!所以,您最好还是下载并提取这些文件。

让我向您介绍您的新拉丁语老师。他非常聪明。他会耍杂技,会跳舞,还会帮助您学习拉丁语。我们稍后会更详细地介绍他。
一旦您准备好运行源代码,您必须确保精灵文件(magister.sp3、hawk.sp3 和 monkey.sp3)已下载并提取到c:\Latin\Data\CrosswordPuzzle目录中。
此时,您应该已经准备好
- c:\Latin\Data\CrosswordPuzzle\目录下的3个精灵(.sp3)文件
- c:\Latin\Data\CrosswordPuzzle\Data目录下的Latin_CW_0000.bin
- c:\Latin\Data\CrosswordPuzzle\Data目录下的Latin_CW_0000.LL 到 Latin_CW_0140.LL
- c:\Latin\Data\CrosswordPuzzle\Games目录下的CrossWordPuzzles.xml
现在您已经准备就绪。
请注意 - 2020/03/24,此处列出的所有.bin和.LL文件都已压缩成一个文件,可从我的Google Drive下载,具体说明请参见下文的遇到的问题部分。
玩游戏
字谜游戏自18世纪末以来就一直存在,快速查看维基百科会发现,其主题和设计模式的变体似乎与文化和语言有关。这款拉丁字谜自然依赖于拉丁语,但没有特定的主题或设计。它们是通过拉丁语词典中的单词随机生成的,您获得的线索取决于您当前玩的难度级别。所有谜题,无论难度如何,都以相同的方式生成,但较容易级别的线索提供了更多信息。
字谜的概念很简单:填空并用正确的字母来解决谜题。
上下文菜单
您可以通过右键单击屏幕并选择各种选项之一来使用上下文菜单
- 新建 - 开始新游戏
- 加载 - 从文件加载已保存的游戏
- 保存 - 将当前游戏保存到文件
- Magister - 开启/关闭Magister
- 难度 - 选择简单 - 普通 - 或困难
- 字体 - 选择用于在屏幕上显示线索的字体
- 退出 - 退出应用程序
谜题屏幕
屏幕分为两部分。左边是谜题及其所有空白格,您需要在其中填写正确的字母来完成答案。右边是提供每个单词线索的区域。要选择要填写的单词,只需单击该单词中的任何字符,它就会被高亮显示,以告诉您这是您正在处理的单词。如果选中的谜题方格同时属于水平单词和垂直单词,则水平单词会首先高亮显示,再次单击同一个方格,选中的单词将在该方格的水平和垂直单词之间交替。闪烁的方格是您的光标,显示您即将使用键盘填写的方格。下面的屏幕截图显示了(10, 6)方格在选定的黄色单词中“闪烁”黑色,该单词从V(10,0)开始,正如屏幕右侧的线索“cuneavisse”所描述的。
下面的两个屏幕截图都展示了为普通难度级别提供的线索。

您可以使用箭头键移动。当您结合使用箭头键和Control键时,您可以跳转到谜题中的下一个“交叉点”。End和Home键将使光标跳转到当前单词的任一端。您还可以通过按Delete键删除单词方格中的文本。
如果您选择了简单难度级别,游戏行为会略有不同——在简单级别,您输入的字母如果正确则显示为绿色,错误则显示为红色。此外,游戏界面不允许您覆盖简单级别中正确的谜题方格。
线索
当您选择一个单词时,您会在屏幕右侧看到该单词的线索。此信息左上角的数字是单词在谜题中的“地址”(以(X, Y)坐标表示),但您实际上不需要知道它,因为一旦您点击它,单词就会以黄色高亮显示。您获得的线索会因您选择的难度级别而异。
简单 - 最简单的游戏级别将为您提供最多的信息,以帮助您找出您正在寻找的单词。在此级别,线索将包括单词的词头(如词典中的显示)及其完整定义。利用此词头信息,您必须根据单词线索提供的具体形式来屈折或变位该单词。
普通 - 此难度级别比简单级别更难一些。屏幕上的字母不再是绿色/红色来告诉您它们是否正确,并且线索可能由单词的词头以及一段古拉丁文文本(其中该单词已被删除)组成。您不会被告知它是哪个词性,哪个变位或屈折,所以您必须阅读文本并尽力找出在处理非动词时态和人称时所需要的格、数和性。谜题中的所有单词都应该与其他单词交叉,所以如果您在一个单词上遇到困难,就转移到下一个单词,稍后回来处理,一旦您填写了与它交叉的一些其他单词,它可能会变得更容易。
困难 - 情况就变得复杂了。在这里,您可能会得到单词在词典中的定义,但不会提供该单词的词头或需要屈折/变位的词的格、数、性或人称。有时,您会收到一段文本,其中有一个红线标出了您正在寻找的单词被删除了,您必须凭记忆或对文本的理解来填空。
下图是为普通级别游戏提供的引文式线索的一个示例。您可以看到玩家获得了单词的词头,但没有获得格、数、时态或人称。

您可以使用上下文菜单,点击其中列出的难度选项来选择游戏难度级别。
如果您在理解屏幕上的某些拉丁语时遇到困难,可以单击线索中任何文本,如果该词有定义,您将获得所选单词的定义。您将无法让应用程序为您提供该单词的所有不同拼写,就像使用TheLatinProject一样,但某些古拉丁语引文中单词的定义可能有助于您找出所需单词的拼写。这可能也有助于您学习拉丁语。
Magister
Magister 对拉丁语非常热情,他能提供很多帮助。无论您玩哪个难度级别,他都会随时准备伸出援手来解决您的谜题,如果您是新手需要鼓励,他会稍微快一些。您可以通过右键单击鼠标并调出上下文菜单,然后选择其中的Magister选项来开启/关闭他。
您会通过Magister的表现来判断您在解决谜题方面是否做得好。如果屏幕上有任何错误,Magister会变得紧张,可能会来回踱步,直到您消除错误,或者他看到一个错误感到如此沮丧,以至于他会走遍您的谜题,并将错误的字母从屏幕上拽下来、扔掉、踢掉或喂给鸟。他只是想帮忙,所以不要生他的气,他只是对拉丁语非常热情。
您可能还会注意到他玩游戏时注意力集中在哪里。除非他被他最好的朋友Simius分心,否则他会跟着您的鼠标光标移动,或者,如果您在谜题中犯了错误,他可能会将他紧张的注意力完全集中在您犯的错误上,急于过去纠正它。所以,您可以根据他是否看着您的鼠标光标来判断您是否刚刚犯了错误。除非他忙于玩杂耍而无法看游戏板...
您会注意到屏幕右下角有一个计时器。别担心,这也不是末日钟,这里没有炸弹,也没有人在记分。不,计时器告诉您的是,在您可以请求Magister填写空白格之前需要等待多长时间,而不是删除错误。当计时器结束时,会出现一个“帮助”按钮,然后您可以选择您遇到困难的单词并按“帮助”按钮。计时器将重新启动,然后您会看到Magister停止他正在做的事情,去拿一支笔,然后回来填写您选择的单词中的一个空白格。如果您需要帮助,不要感到尴尬,拉丁字谜可能很难,他也很乐意这样做。
代码
现在让我们深入了解
数据库是如何构建的
谜题生成器建立在一个专门用于构建字谜的数据库之上。如果您对TheLatinProject的查找表(Look-Up Table)的工作原理有一个大致的了解,那么您会知道它包含一个二叉树,其中存储了Cassell's Dictionary中24,000个单词的772,000种不同拼写。字谜的数据来源于这772,000种不同的单词拼写。构建此数据库的代码首先按进入LUT二叉树的顺序(从记录号零开始,递增到最后一个772,000个)遍历这些记录,但并非每种拼写都能产生可行的单词供LatinCrosswordPuzzle游戏使用,因为其中许多单词有多个源文件,这会在以古拉丁语引文形式出现的线索中产生误导。例如,任何从形容词派生的名词或从名词派生的形容词,例如clausum, -i(中性名词)是源自动词claudo, claudere, clausi, clausum的过去分词。由于单词clausum可能是形容词clausus, -a, -um、名词或过去分词,应用程序无法区分这三者,并在显示线索和引文时随机选择一个。在这种差异很微妙的情况下例子不多,但在不微妙的情况下,我发现这是完全不可接受的。因此,为避免此问题,所有具有多个源单词的单词拼写都被视为无效,不会包含在字谜生成器数据库中。在772,000个候选单词中,我认为这是一个合理的解决方案。从最终版本生成的134个链表文件与之前生成的141个LL文件相比,这意味着当前数据库中有大约734,000个不同的单词(拼写),占原始数据的95%。
如何实现这一点的源代码相当直观,并显示在下方
bool bolValidWord = true;
try
{
cLUT_BinRec = classLatin_LUT.LUT_BinRec_Load(intCW_Build_Index++);
// test for and reject any word spelling that has more than one source filename
List<string> lstFilenames = new List<string>();
classLatin_LUT_LL_Record cLatin_LL = classLatin_LUT.LUT_LL_Record_Load(cLUT_BinRec.LL);
while (cLatin_LL != null && bolValidWord)
{
if (!lstFilenames.Contains(cLatin_LL.filename))
lstFilenames.Add(cLatin_LL.filename);
if (lstFilenames.Count<2 && cLatin_LL.next >= 0)
cLatin_LL = classLatin_LUT.LUT_LL_Record_Load(cLatin_LL.next);
else
cLatin_LL = null;
bolValidWord = lstFilenames.Count <= 1;
}
}
catch (Exception)
{
goto endPosition;
}
一旦一个单词被认为有效并可以插入数据库,它就会从左到右扫描,使用两个嵌套的for循环根据字母及其相对位置对单词进行排序。每个单词的每种可能的两位字母组合都用作排序设备,以生成这些组合的唯一代码,例如,单词necabo在位置2的首字母“C”,位置4的第二个字母“B”将产生一个唯一的代码,将C2B4组合成4个字符,无论位置的阿拉伯十进制数字是否需要两个字符而不是一个(如第12位或任何大于9的数字)。这个四字符代码然后用作二叉树的搜索键,其叶子指向一个循环链表。这些链表项的数据字段包含要包含在树中的单词。
这并非完全简单。实际上,循环链表按单词长度排序到第二个二叉树(单词长度),该二叉树从第一个树的叶子(定义两位字母组合的四字符代码)分支出来,然后这些二次二叉树的每个叶子指向一个循环链表,该链表保存长度相同且具有匹配两位字母组合(相同四字符代码)的单词。
我使用循环链表的原因是为了让应用程序能够“随机抽奖”,而不是在每个谜题中使用相同的单词。使用单向链表需要从头到尾读取才能进行真正的随机选择,这对于实时生成谜题来说太慢了。循环遍历所有选项的替代设计选择似乎更合理,因为原始LUT二叉树是随机生成的,它们都是随机输入的,并以该随机顺序出现在LatinProject LUT文件中,从而获得772,000个单词条目。此外,谜题生成器会跟踪在最近25场已生成游戏中使用的单词,以确保在25场游戏内不重复使用相同的单词,稍后将详细介绍。
生成主二叉树四字符代码的源代码如下所示
public static string getKey(char chr1, int int1, char chr2, int int2)
{
return ((chr1.ToString()
+ chr2.ToString()
+ Convert.ToChar('A' + int1)).ToString()
+ (Convert.ToChar('A' + int2))).ToString();
}
您可以在
public class classCW_BinTree_Record
我几年前写的第一个字谜使用了类似的系统,但将四字符代码转换为整数值,使用复杂的基于多值的计数系统,其中第一和第三个“小数”位是基数为26,另外两个是基数为40(最大单词长度),它们的总和产生一个唯一的整数,然后用作随机访问文件中的索引。这个系统速度快得多,因为它绕过了这个最新版本目前使用的二叉树,但需要一个更大的文件来容纳所有无效的两位字母组合。
由于字谜不尝试生成紧邻的单词运行在同一行上的谜题,因此数据库中不会输入任何相邻的字母组合。见下文
if (validEntry(strWord))
{
for (int int_1 = 0; int_1 < strWord.Length - 2; int_1++)
{
for (int int_2 = int_1 + 2; int_2 < strWord.Length; int_2++)
{
classCW_BinaryTree.classCW_BinTree_Record cBinRec
= new classCW_BinaryTree.classCW_BinTree_Record(strWord, int_1, int_2);
classLatin_LUT_LL_Record cLUT_LL
= classLatin_LUT.LUT_LL_Record_Load(cLUT_BinRec.LL);
classCW_BinaryTree.classCW_LL_Record cLL
= new classCW_BinaryTree.classCW_LL_Record(strWord, cLUT_LL.filename);
classCW_BinaryTree.CW_BinTree_Insert(ref cBinRec, ref cLL);
}
}
}
下面是数据库的图示
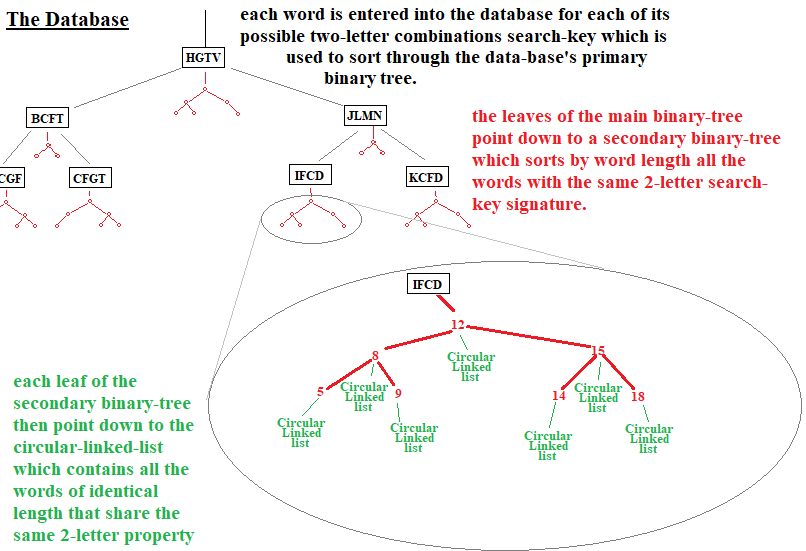
尽管负责重建字谜数据库的代码在
class classCW_BuildDataTree
插入和检索数据库数据的大部分工作在
classCW_BinaryTree
如何从数据生成字谜
要开始使用此数据生成谜题,应用程序首先随机选择两个两位字母组合,并在数据库中搜索有效条目。暂时不考虑生成线索,它会维护一个运行列表,其中包含:
- 屏幕上所有字母(位置和值)
- 水平单词列表(拼写和起始位置)
- 垂直单词列表(拼写和起始位置)
添加了这两个单词并将它们放置在谜题的左上角和右下角后,它开始了一个简单的算法:
- 随机选择一个谜题方格并将其从运行列表中移除(1 above)
- 测试是否可以水平添加单词
尝试水平输入单词,如果可以则输入
如果无法水平输入单词
则尝试垂直输入 - 输入单词时
- 使用它随机选择的(已在棋盘上的)字母/位置
- 测量该字母前后距离
- 决定是使用随机选择的字母作为两位组合的第1位还是第2位
- 使用棋盘上的另一个现有字母作为两位组合的另一个字母
- 或者,如果找不到或无法使用已有的字母,则随机选择第二个字母及其位置
- 测量单词在当前谜题配置中可以容纳的最大长度
- 将这些参数以四字符搜索键和最大单词大小的形式输入数据库搜索引擎
- 由于循环链表中的每个元素都包含生成该特定拼写的单词的文件名,并且谜题生成器会跟踪在前25个已生成谜题中使用的所有单词的文件名,因此派生自同一词典源文件的单词将被拒绝。
- 当选定一个适合现有谜题的新单词时
- 它被添加到相应的单词列表(水平/垂直)中
- 此新单词中的每个字母位置都会添加到现有的谜题方格列表中
- 最终,它无法轻易找到要添加到谜题中的单词,并且耗尽了尝试的谜题方格,然后退出并将谜题保存在CrossWordPuzzles.xml文件中。
在此应用程序的开发过程中,我花了一个半月(还是两个月?)的时间测试(玩)并发现了LatinProject的LUT中越来越多不令人满意的拉丁语单词错误。有时,拉丁语 so off,我不得不保存游戏并加载XML文件来查看谜题单词是什么……太经常拼写错误。在至少进行了十几场LUT重建并重建了PuzzleGenerator数据库后,现在它看起来有望减少令人尴尬的错误。所以,既然这个项目的开发阶段已经完成,我已将加密功能添加到谜题文件存储中,因此不再可能简单地保存游戏并从XML文件中读取答案。如果您想实现作弊模式,欢迎您修改classCW_XML文件。
所有谜题生成都由classCW_PuzzleGenerator类完成。
public const int conMaxPuzzlesGenerated = 100;
const int conCW_WordsUsedRecently_MaxPuzzlesInList = 25;
上面显示的两个常量位于classCW_PuzzleGenerator类中,它们控制着CrossWordPuzzles.xml文件中维护的最大谜题数量以及任何给定单词来源在多少场游戏内不允许重复使用的数量。将conMaxPuzzlesGenerated值设置得太高只会减慢新游戏的启动速度。限制同一单词在过多连续游戏中使用会给谜题生成器带来麻烦,并可能导致谜题只包含少量单词,而棋盘上有太多空白格。
当我开始这个项目并开始生成谜题时,我还没有优化数据库,使其更方便谜题生成器工作,因此生成谜题缓慢且费力。更重要的是,即使谜题生成器在玩家忙于解决谜题时在后台工作,它也可能需要十分钟才能生成一个谜题,并且当用户退出应用程序时,它可能会被迫停止工作。为了防止丢失这些辛勤获得的局部谜题数据,我实现了一个局部工作保存选项,谜题生成器使用它来保存部分生成的谜题,并在下次启动应用程序时从上次中断的地方继续。所以现在一个新的谜题可以在几秒钟内生成,局部工作保存功能似乎有点多余,但它仍然在使用并且运行良好。
一旦应用程序启动,谜题生成器后台工作者就开始生成新的谜题,直到达到最大谜题数量,或者它被中断并在用户启动新谜题并需要其他后台工作者在运行时生成线索时保存其工作。
生成线索
因为用户可能在请求新线索时反应迟缓,但又期望计算机在请求后迅速提供线索,所以有两个后台工作者分担生成谜题线索的职责。这两个后台工作者使用相同的工具,并根据用户的需求进行交替。它们的名字很长而且难以发音,
public BackgroundWorker bckCW_ClueWriter_OnDemand = new BackgroundWorker();
public BackgroundWorker bckCW_ClueWriter_All = new BackgroundWorker();
所以,我们称它们为按需(OnDemand)和全部(All)。全部在显示新谜题后立即开始工作。它首先按顺序处理谜题中的所有水平单词,然后在完成后开始处理垂直单词。每当用户选择一个新单词并期望在该单词的线索出现在屏幕上时,该单词就会被测试以查看是否已生成线索,如果尚未生成,则阴沉的全部会停止工作,让按需谄媚地努力工作,及时地为用户提供用户想要的东西。当按需完成工作后,全部就会回来生成剩余的线索。
在所有线索都生成完毕后,如果需要,后台谜题生成器会启动并开始生成更多的谜题。
每个单词都需要一个线索,对应每个难度级别:简单、普通和困难。在我写这篇文章时,我正在考虑改变全部的工作方式和顺序,因为在写作时,全部会逐一生成所有三个难度级别的线索,然后再处理下一个单词。这可以优化……我希望我写这篇文章时没有让您等太久。讨厌那样让您等待。因此,从现在起,全部会按选定的玩家难度级别遍历每个单词,测试每个单词是否需要生成线索,然后遍历每个难度级别并重复。如果用户更改难度级别,则全部将继续生成错误的难度级别,直到它开始生成所需的难度级别,或者在用户选择一个尚未生成线索的新单词时被中断,并且按需向用户提供该线索,然后全部重新开始,就像从未做过其他事情一样。
线索生成过程最初非常缓慢,尤其是在遇到非常常见的单词并且它正在尝试从库中查找合适的引文时。正如我在上面提到的《拉丁语项目》最新更新中所述,库ContentSearch最初是为了提供包含用户搜索单词的文件详尽列表而构建和设计的。这对于LatinProject来说都很好,但对于字谜和线索生成来说,加载包含该单词的库中的每个文件的单独记录会不必要地减慢速度。因此,整个TheLatinProject ContentSearch被重建以适应此需求。它类似于上面描述的字谜数据库,它有一些类似于循环链表的东西来存储搜索单词的文件名,但它们不是按单词长度排序,而是按单词频率排序,即该单词在每个文件中出现的次数。更重要的是,它们是循环链表似的。而不是有一个头部和尾部相互指向的连接双向链表,ContentSearch使用两个指针指向一个单向链表:头部和尾部。生成引文的过程涉及找到指向次级树的二叉树,该次级树按单词长度排序文件名,然后遍历该次级二叉树。利用指向每个链表头部和尾部的指针列表,它然后随机选择一个,并从这些列表中最多取10个文件名。如果第一个列表短于最多10个文件名,则不对这些列表进行修改,但如果这最多10个文件名在一个链表的中间结束(很可能会发生),则通过取该列表的前几个元素并将其移动到列表的后部来修改最后一个列表,从而改变该链表中的头部和尾部指针,以及该二次二叉树叶子中的所有内容,这样字谜的世界就一切正常了。
在此更改之前,包含给定单词的所有文件名都位于单个链表中。需要完全加载此列表才能让线索生成器随机选择数千个可用文件之一,这会大大减慢速度。进行此更改后,线索生成过程只需要选择最少数量的文件(实际上是1个),随机选择一个并生成引文。快速而简单。相信我,这要好得多。
将合适的信息显示在屏幕上非常简单,我不会深入探讨,但如果您有兴趣,classGraphicText(实际在位图上绘制文本的类)在我大约十年前写的GCIDE文章中有解释。
用户界面
这个用户界面没什么特别之处。现在该写它了,我意识到没什么好写的。这里唯一的秘诀是
public TextBox txtUserInput = new TextBox();
此文本框在应用程序的整个生命周期中都处于聚焦状态。每当焦点转移到唯一另一个文本框时,它都会被强制回txtUserInput。只有两个函数处理此文本框,这两个函数是
private void TxtUserInput_KeyDown(object sender, KeyEventArgs e)
private void TxtUserInput_KeyPress(object sender, KeyPressEventArgs e)
您可以查看这些函数,了解如何使用e.suppress文本框属性拒绝所有无效的按键输入。这也是通过Control/箭头键组合来移动光标的地方。
除了键盘界面,您还有鼠标。由于屏幕完全由一个图片框组成,该图片框会根据需要刷新,鼠标界面仅包含该PictureBox的MouseMove和MouseClick事件处理程序。这个图片框只有三个区域,它们是:
- 谜题显示区域
- 线索显示区域
- 帮助按钮
由于classGraphicText用于显示线索文本,因此它也用于确定鼠标下方的单词,以便在用户请求时提供拉丁语词典词条。映射谜题区域很简单,只需知道每个谜题方格的大小,然后根据鼠标位置相对于谜题区域左上角进行计算,即可解析出鼠标光标下方的谜题方格的x-y坐标。线索区域内只有一个帮助按钮的子区域,并且仅在绘制按钮时需要。
这些事件处理程序很容易在主窗体中找到,不应给您带来太多麻烦。
图形和众多有限状态机
如果您还没有看过,我建议您阅读我的Sprite-Editor 2017文章。这是我几个月前编写并用于生成所有图形的应用程序。它相当酷。在此应用程序中,Magister、Monkey和Hawk角色都是精灵。每个精灵都有一个不同的精灵文件,如您在下载文件列表中所见。同样,如果您想了解更多关于如何制作精灵和生成快速简单的动画,请参阅我之前在这段话开头提到的文章。
屏幕上移动的其他对象是导弹或字母,这两种类型都有自己的类,用于跟踪它们的位置和速度。例如,每当Magister在玩杂耍时。Magister当时只是屏幕上的一个精灵,他正在耍的字母是独立的实体,称为Letters。Magister精灵的Juggle动画只显示Magister在没有东西的情况下摆动手臂进行杂耍。耍杂耍是通过测量当另一只手将要扔球时,该手的位置来完成的。然后它计算字母的轨迹,向上飞行到某个预定的中点,然后再次向下飞行,及时到达另一只手将要接住它的时候。左、右、左、右,三个字母同时飞舞,他就在那里不停地转。您可以在classMagister的Juggle()函数中看到这一点。下面是部分执行此操作的代码。您可以下载源代码查看其工作原理,但为了简洁起见,我删除了此Switch-Case语句中的大部分不同情况,只保留了LeftThrow来演示其工作原理。
enuJugglingFrames eJugglingFrame = (enuJugglingFrames)cData.cAnimationData.intFrameIndex;
switch (eJugglingFrame)
{
case enuJugglingFrames.LeftCatch:
{
...
}
break;
case enuJugglingFrames.LeftThrow:
{
if (((classAnimationTag)cData
.cAnimationData
.cAnimation
.tag).intRepeatAnimation > 1)
{ // calculate starting position of thrown letter
classAnimation_Frame cFrame_start
= cData
.cAnimationData
.cAnimation.lstFrames[(int)enuJugglingFrames.LeftThrow];
classAnimation_Frame_LimbData cLeftHandData
= (classAnimation_Frame_LimbData)cFrame_start
.getData(enuMagister_Limbs.Hand_Left.ToString());
Point ptStart = cMath.AddTwoPoints(cData.pt, cLeftHandData.ptDrawCenter);
// calculate end position of thrown letter
classAnimation_Frame cFrame_End
= cData
.cAnimationData
.cAnimation
.lstFrames[(int)enuJugglingFrames.RightCatch];
classAnimation_Frame_LimbData cRightHandData
= (classAnimation_Frame_LimbData)cFrame_End
.getData(enuMagister_Limbs.Hand_Right.ToString());
Point ptEnd = cMath.AddTwoPoints(cData.pt, cRightHandData.ptDrawCenter);
// calculate Apex position of thrown letter
classAnimation_Frame_LimbData cHatData
= (classAnimation_Frame_LimbData)cFrame_start
.getData(enuMagister_Limbs.Hat.ToString());
Point ptApex = cMath.AddTwoPoints(cData.pt, cHatData.ptDrawCenter);
ptApex.X = cData.pt.X - (ptApex.X - ptEnd.X) / 2;
ptApex.Y -= 100;
classLetter cLetterLeft = lstJugglingLetters[0];
lstJugglingLetters.Remove(cLetterLeft);
lstJugglingLetters.Add(cLetterLeft);
// calculate positions of ThrownLetter as it climbs
double[] dblFraction_UpPath = { 0.4, 0.7, 0.9, 1.0 };
PointF ptfDelta_Up = new PointF(ptApex.X - ptStart.X, ptApex.Y - ptStart.Y);
cLetterLeft.lstPath.Clear();
for (int intStepUpCounter = 0;
intStepUpCounter < dblFraction_UpPath.Length;
intStepUpCounter++)
{
Point ptUp
= new Point(ptStart.X
+ (int)(ptfDelta_Up.X
* dblFraction_UpPath[intStepUpCounter]),
ptStart.Y
+ (int)(ptfDelta_Up.Y
* dblFraction_UpPath[intStepUpCounter]));
cLetterLeft.lstPath.Add(ptUp);
}
// calculate positions of ThrownLetter as it falls
double[] dblFraction_DownPath = { 0.1, 0.3, 0.6, 1.0 };
PointF ptfDelta_Down = new PointF(ptEnd.X - ptApex.X, ptEnd.Y - ptApex.Y);
for (int intStepDownCounter = 0;
intStepDownCounter < dblFraction_DownPath.Length;
intStepDownCounter++)
{
Point ptDown
= new Point(ptApex.X
+ (int)(ptfDelta_Down.X
* dblFraction_DownPath[intStepDownCounter]),
ptApex.Y
+ (int)(ptfDelta_Down.Y
* dblFraction_DownPath[intStepDownCounter]));
cLetterLeft.lstPath.Add(ptDown);
}
cLetterLeft.bolDraw
= ((classAnimationTag)cData
.cAnimationData
.cAnimation
.tag).intRepeatAnimation > 1;
}
}
break;
case enuJugglingFrames.RightCatch:
{
...
}
break;
case enuJugglingFrames.RightThrow:
{
...
}
}
break;
case enuJugglingFrames.LeftWait:
case enuJugglingFrames.RightWait:
break;
}
这比我预期的要容易得多。然而,Hawk的动画则有些困难,因为尽管Monkey会跳舞、翻滚并从藤蔓上荡秋千,但它从不会爬到Magister的手臂上,也从不会触碰游戏区域内的游戏方格。所以,猴子可能看起来很酷,而且知道只有在棋盘上没有错误时才能看到它的滑稽动作,这令人鼓舞,但Hawk的例行公事——飞越屏幕,落在Magister手臂上,等待Magister的指示,然后飞走并俯冲下来抓住那个不属于那里的错误字母,然后再次飞走——给了我相当大的麻烦。
每个精灵Magister、Monkey和Hawk都有自己的类以及独立的有限状态机。这些FSM是让角色按照您的意愿行事的相对简单的方法。它们是角色可以处于的“状态”列表,当处于给定状态时,角色就知道该做什么,因为您已将其隔离用于该特定目的。在Magister的情况下,他有以下一般状态:
嬉戏(Frolic)开始担心(beginToWorry)担心(Worry)纠正(makeACorrection)庆祝(Celebrate)- &
帮助(Help)
当棋盘上没有错误时,他会嬉戏。对他来说,这意味着:耍杂技、快乐地挥手、跳舞或弹手风琴。当棋盘上有错误时,他会“开始担心”,这时他还没有真正紧张地踱步,但不再耍杂技或弹手风琴,他只是有些心不在焉地挥手,同时看向谜题。当一段时间过去(动画周期)并且棋盘上的所有错误都未纠正时,他会“担心”。对于Magister来说,这意味着他会紧张地来回踱步,只停下来擦汗,焦急地跺脚,担心用户糟糕的拉丁语。在每个动画序列结束时,他有一定几率会改变状态并“MakeACorrection”。当他在纠正时,有一个独立的FSM指导他选择一种纠正方式(例如,大锤、弓箭、挥手或鹰,仅举几例)以及从棋盘上纠正哪个不正确的字母。当构成该特定FSM_MakeACorrection的有限状态序列完成后,他将再次进入“Worry”状态(如果棋盘上仍有错误),或者他可能会嬉戏。
帮助状态仅在用户按下帮助按钮时才能达到。在他把一个字母写在棋盘上帮助玩家之后,他可能会庆祝(如果游戏完成),如果棋盘上仍有错误则担心,如果没有错误则嬉戏。
唯一与其他大多数动画不同的动画是弹手风琴。看看它,如果您使用过SpriteEditor或阅读过那篇文章,您可能会觉得这个动画有点奇怪,因为他的手在手风琴的侧面转动曲柄。我所做的是在Magister精灵中添加了accordionBox、HandleShaft和Handle。然后,我在该动画的第一帧中将手柄定位在其旋转的顶部。第二帧显示手柄接近底部。我使用SpriteEditor的AutoInsertIntermediateFrames功能生成了这两个帧之间的中间帧,并完成了手柄的旋转。请注意,Magister的手在任何时候都没有够到手柄,这时手柄是自己转动的。所以,我逐帧浏览动画,并将手放在每个帧的手柄上,工作就完成了,Magister为他的宠物猴子弹奏着卡西姆的 acordeon(我知道猴子有尾巴,但我还没有费心将Simius精灵的名字改为反映他实际上是黑猩猩的事实,并且在他引起简·古道尔的官方投诉之前,我将继续称他为“猴子”。顺便说一句,我喜欢她)。
这就是我关于这个主题想说的全部了。
各种FSM包含在各自的角色类中。我应该指出,我在实现这些FSM的方式上并不一致。Magister通用FSM的第一个实现有两个变量用于当前状态和下一状态,而我后来实现的多数只有一个当前状态,Switch-Case代码指的是在标记的case结束时发生的事情,而不是开始时。这不是最好的代码。但它很稳定,而且我厌倦了这个项目,所以我不会修复没坏的东西。
动画标签
如果您查看classMagister,您可能会注意到Magister的所有精灵动画标签都在那里定义。动画标签未包含在我的Sprite Editor文章中,我只在处理LatinCrossWordPuzzle项目时才添加它们,所以我在这里提及它们。许多Visual Studio对象,如TextBoxes和Panels等,都有一个Tag属性,允许您通过先将其转换为称为object的通用类型来将任何内容附加到该对象。事实证明,这些额外的数据位非常有用,所以我像吃蛋糕一样简单地将它们添加到了classSpriteAnimation中。本质上,Tag只不过是指向保存通用类型Object的地址的指针。在这里,Magister的精灵有一个classAnimationTag,如下所示:
public class classAnimationTag
{
public int intRepeatAnimation = 1;
public int intActionFrame = 0;
public Point[] ptSteps;
public enum enuPathType {
independent,
X_only,
Y_only,
Y_tracks_X,
X_tracks_Y,
_numPathType};
public classAnimationTag(ref classAnimation cAnimation,
int TimesRepeat,
int ActionFrame,
Point[] steps,
enuPathType pathType)
{
intRepeatAnimation = TimesRepeat;
intActionFrame = ActionFrame;
ptSteps = steps;
PathType = pathType;
}
enuPathType _pathtype = enuPathType.Y_tracks_X;
public enuPathType PathType
{
get { return _pathtype; }
set { _pathtype = value; }
}
}
当Magister的精灵初始化时,它所有的动画都必须有一个标签。这些标签由上面显示的数据组成,然后转换为对象并分配给各自的动画。classAnimationTag实例化的某些参数可能不明显,让我们看一下:
-
第一个是对其所关联的动画的引用(可能冗余但方便)。
-
TimesRepeat - 告诉处理Magister动画的函数特定动画要重复多少次,然后Magister才会继续做其他事情。有些动画只执行一次,而有些则设置为随机值(如跳舞或嬉戏动画),而另一些(如
walk_left、walk_right)则设置为1或2(可能3)以衡量Magister的步伐,具体取决于他朝哪个方向行走。关于这一点,稍后在谈论classPath时会进一步介绍。 -
ActionFrame - 有些动画需要在动画进行中执行一个动作(例如,
SledgeHammer动画必须导致Magister击打掉棋盘上的字母,当锤子到达那里时)。这些是在classMagister's nextFrame()函数开头处理的,该函数使用Switch/Case来确定正在运行的动画应该发生什么。 -
steps - 步骤是一个笛卡尔坐标点数组,告诉动画处理函数在动画的任何一帧中Magister(或其他精灵)应该放置的位置。大多数动画不会导致Magister的位置发生变化,并为步骤提供一个空列表,但Magister的行走动画、Monkey的翻滚和Hawk的飞行都会。点的数量必须与动画的帧数完全相同,稍后在谈论
classPath时我会详细解释。 -
pathType -
classPath有几种不同的计算方法,用于确定给定精灵在指定动画的每一帧将移动多少像素,这就是初始化该信息的地方。
classPath
classPath的实现是为了方便将精灵从屏幕的一个点移动到另一个点。由于CrosswordPuzzle不执行任何碰撞检测测试,并且精灵会不受阻碍地到达目的地,因此classPath可以轻松计算出要让精灵到达目的地需要多少次给定动画的迭代,以及该精灵在X、Y方向上需要移动多少像素才能平滑过渡。它的工作原理并不复杂。如上所述,每个动画都有自己的动画标签,其中包含使用steps和pathType计算精灵运动所需的参数。由于steps列表中的每个点都详细说明了精灵在x-y轴上需要移动的距离,因此这些点的总和等于该精灵在一个完整动画周期中移动的距离。精灵很少会精确地移动到动画最初绘制的单个周期所能达到的距离,因此classPath会完成剩余的工作,以实现角色打算进行的特定起始位置到结束位置的过渡,同时绘制指定的动画以到达那里。
精灵需要移动的总距离除以在理想情况下通过动画的一个周期可以移动的总距离。将此数字四舍五入到最接近的整数,然后将该整数用作动画标签的TimesRepeat字段。然后,在精灵从A点到B点的过渡完成时,像任何常规整数变量一样测试这个TimesRepeat字段,跟踪动画已迭代了多少次,然后停止,可能恰好停在精灵需要到达的位置。
现在classPath知道动画需要重复多少次,如上所述,这个值很少会精确地等于动画的steps点列表的总和。因此,动画的理想行进距离(由steps总和给出)与它实际到达屏幕上需要到达的位置的距离之间的分数被用来修改steps数组点的运行总和。
例如,如果动画完成3个周期,移动精灵的距离等于steps列表中的精确值(在应用程序的整个生命周期中这些值never change),大于总行进距离,那么每个步骤都会被修改以反映该差异,以便最终总和正好是您需要的。
它不会修改steps数组中的单个Point值,而是对这些点进行累加,将此值除以总距离,然后取该分数并乘以它需要行进的总距离,以获得更准确的结果。这类似于使用卷尺计算他在第n帧需要去的位置,而不是使用8英尺的办公尺,并在每一帧中累积误差。
三个精灵角色(Magister、Hawk和Monkey)各自拥有自己的class,并且每个类都有一个classPath的实例。每当角色需要移动时,就会识别出它的动画,然后classPath的实例才会被告知目的地。由于classPath已经知道要使用哪个动画,它会执行上述计算,并创建一个列表,其中包含该角色在动画的每个迭代的每一帧中将要到达的点。然后,当精灵需要被绘制到屏幕上时,classPath会提供路径上的下一个点,并将其从列表中移除,直到点用完,就像动画的最后一次迭代完成其完整周期一样,Magister正好在那里,准备将错误的条目踢出谜题棋盘,微笑着慢悠悠地回到屏幕右侧的固定位置。
遇到的问题
这款游戏在开发过程中遇到了一些问题。当我开始这个项目时,我认为我花了一个半月的时间来刷新和复活TheLatinProject已经够好了。相信我投入的所有工作已经使其近乎完美,我确信字谜将是一种快速酷炫的方式来改进(已经)非常好的东西。然而,早上随便使用TheLatinProject半小时而没注意到有什么严重问题是一回事,而玩一个有时变位动词像Ozzy Osbourne那样,以及屈折拉丁名词像塔利班那样,则是完全另一回事。在玩游戏时,我立即意识到TheLatinProject存在一些不容忽视的错误,这些错误在休闲使用时可能多年未被发现,但在字谜线索中却非常明显。因此,我一次又一次地发现并修复了TheLatinProject查找表中的拉丁语问题,重新编译LUT(延迟7小时),然后重建CrosswordPuzzle数据库(最初需要10天!!!现在需要36+小时),之后才过了几个小时的测试,当发现更多问题时,不得不重复这个过程。Needless to say, TheLatinProject得到了极大的改进。它现在比几个月前好多了,但在经历了十几场重建和这些重建带来的令人沮丧的延迟之后,我对这个项目彻底感到厌烦。现在它完成了,我很乐意享受它。
2020/03/024 以下zip文件仍然可用,但我做了很多更正。您不必下载和解压下面列出的每个(旧的、未更正的)文件,而是可以从我的Google Drive下载一个压缩文件。只需从那里下载CrosswordPuzzle.zip文件,并将其内容解压到您的C:\Latin\Data\目录中,而无需下载上面列出的旧.zip文件。这些更正已反映在zip文件中列出的拉丁项目定义中对拉丁词典的更改。您可以下载此文件,解压文本文件,并使用Latin Project的管理员编辑工具对词典进行更改。
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_130-133_.zip - 7.4 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_125-129_.zip - 9.2 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_120-124_.zip - 9.1 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_115-119_.zip - 9 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_110-114_.zip - 9.1 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_105-109_.zip - 9.1 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_100-104_.zip - 9 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_095-099_.zip - 9 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_090-094_.zip - 9 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_085-089_.zip - 9 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_080-084_.zip - 9.1 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_075-079_.zip - 9 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_070-074_.zip - 9.1 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_065-069_.zip - 9.2 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_060-064_.zip - 9.3 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_055-059_.zip - 9.4 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_050-054_.zip - 9.4 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_045-049_.zip - 9.4 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_040-044_.zip - 9.4 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_035-039_.zip - 9.4 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_030-034_.zip - 9.3 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_025-029_.zip - 9.3 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_020-024_.zip - 9.4 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_015-019_.zip - 9.4 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_010-014_.zip - 9.4 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_005-009_.zip - 9.4 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_LL_000-004_.zip - 7 MB
- 下载 c_Latin_Data_Crossword_Data_Latin_CW_Bin_000_.zip - 9.4 MB
- 下载 c_Latin_Data_CrosswordPuzzle_games_data_.zip - 40.7 KB
(近期将检查更新,但现在我需要制作一款街机风格的游戏,否则我会崩溃。)
更新
2019/06/05 - 自首次发布本文以来,我每天都在玩字谜游戏,并且继续发现LatinProject中的问题。现在肯定比以前少了,但可能还有一些遗留问题,所以时不时回来看看是否有新的数据供您改进您在家中运行的版本。由于Latin Project的查找表必须重建才能重新编译此项目的data,因此您需要下载该项目的最新文件以及这些文件。此项目的源代码或精灵没有新的更改,因此您只需要下载本文底部的文件(位于此文本正上方)。
注意:此处列出的文件名不能准确描述它们需要解压到哪个目录。LL和Bin文件的正确目录(不是底部的games_data.zip文件)应该是
c:\Latin\Data\CrosswordPuzzle\Data\
而不是
c:\Latin\Data\Crossword\Data\(如文件名所示)
刚才提到的games文件放在
c:\Latin\Data\CrosswordPuzzle\
并且会自动解压到c:\Latin\Data\CrosswordPuzzle\Games\
它自己。
请原谅这个错误,我相信您能够处理。我只是太懒了,不想全部更改并重新上传。
2020/03/24 - 每天玩一场游戏,我得以逐渐发现并修复数据中的问题。
享受这款游戏,causa Latinam est Gaudium!