
C# 中的拉丁文课本和查找表
4.83/5 (26投票s)
使用 C# 编写的 Wheelock's Latin 课本和 Cassell's Latin 词典。
为什么学拉丁文?
(本文曾发表过,现已更新为 2019 年代码重构,新增功能)
多年来,我一直在努力学习一点拉丁文。尽管学习进程相当缓慢,但它给了我编写一个对学习过程很有帮助的拉丁文项目的机会。在之前的一篇文章《拼写检查器,但语法由你决定》中,我曾提到过这个拉丁文项目但没有提供任何代码,这让我一直有些不安。所以,我决定专门写一篇文章来介绍这个项目,并重新整理数据,以便能够将其上传到此平台并公之于众。
我当初决定尝试学习拉丁文的原因,可能源于我小的时候受到天主教的熏陶,但那与我天生的无神论倾向毫无关系;或者,也可能源于我曾在一个晚上,因为看《巨蟒与圣杯》电影中的“生命之饼”而摔断了肋骨。

无论如何,你会发现这个应用程序比你在任何地方找到的其他拉丁文项目都更出色。一个与之媲美的程序是《Whittaker's Words》,它在 DOS 窗口界面中实现了这个应用程序查找表的大部分功能。虽然它不像其他程序那样用户友好,但考虑到其下载文件大小和安装的便捷性,它已经非常出色了!这个最新(2019年)版本包含了一些新功能,例如:
- 工具提示 - 有用的提示,在用户界面中引导您
- 词典内容搜索 - essentially an English-to-Latin dictionary(基本上是一个英拉词典)
- 拼写检查器
- 古代拉丁手稿库,涵盖罗马时期到中世纪和文艺复兴时期
- 库内容搜索 - 帮助您找到所需的文本
- 易于使用的词典编辑器界面 - 用于创建新词条或编辑现有词条
- 管理员登录 - 防止不负责任的用户篡改您的拉丁文!!!
一开始,我花了大量时间,在三年前开始使用《Wheelock's Latin》课本学习拉丁文时,亲自输入了《Cassell's Latin/English-English/Latin Dictionary》(24000个词条!)的前半部分(拉丁文到英文,A-Z)。在两年时间里,我用 VB 以零散的方式编写了程序的第一个版本,将从纸质拉丁文课本中学到的任何新屈折或变格添加到项目中,以便我的电脑能减轻学习过程的负担。
大约一年前(2009年),我用 C# 花了一个月的时间重写了整个程序。这个(首次发布的)新版本要好得多。由于最初的 VB 版本规划得很糟糕(根本没有规划!),因此 C# 重写要快得多,效率也高得多。之后,我还输入了 Wheelock's Latin 课本,并对最初以文本文件格式编写的文件进行了一些修改,现在它们是 XML 格式,格式信息是通过 RTF 文件中的代码从 CodeProject 文章《编写自己的 RTF 转换器》中提取的,这极大地简化了任务。我曾因案在监狱里待了七年,我出来后迫不及待地想回到这个和其他项目中。虽然旧版本的搜索引擎在下载后需要用户重新构建,但此版本的搜索引擎数据文件被分解以适应 Code-Project 允许的 10MB 文件上传大小。过渡到新系统带来了一些我未曾预料到的文件检索加速,这总是一件好事。
编写原始 VB 版本最困难的部分是让代码弄清楚 Cassell's 词典中的每个词条是什么类型的词。它是名词?形容词?属于哪种变格?动词?副词、不变格词、代词等等,因为那本词典没有包含一个拉丁文学者仅凭查看词条就能知道的所有信息。以“to”开头的定义,如“to run”或“to write”,被假定为动词。大多数名词只有两个主要形式,但有些形容词也是如此。总之,让整个过程正常工作花了近两年令人沮丧的时间,我无意再经历一次 C# 重写,所以我使用了 VB 代码来复制手工输入的第一版中的每个词条,弄清楚每个词是什么,然后将词类型信息存储在词的定义中,并保存在一个单独的目录中。完成这些后,我就准备好进行 C# 重写了,这就是你现在看到的作品。
最近,我又用一些代码检查了相同的词典文件,以查找我手工忽略修复和标记的所有“不变格词”。有数千个。幸运的是,我能够通过更精确的代码行自动重做其中许多,以处理特定情况,其中许多需要重写标题,经过大约一周的努力,它们似乎都改进了很多。现在有一个词典条目编辑器界面,比之前那个晦涩难懂、不太友好且有时会出错的版本要好得多,那个版本容易将有效条目覆盖为新的、不太有效的词条。……但我稍后会解释这一点。
您必须了解,我发布此文章、软件以及受版权保护的 Cassell's Dictionary 和 Wheelock's Latin 课本,冒着收到一位先生的愤怒邮件的风险

他为本程序录制了音频文件。
稍后会详细介绍,但首先,让我们在您的计算机上运行这个拉丁文项目。
安装
如果您已经在计算机上安装了 C#2019,您可能知道如何运行该应用程序,但仍然需要下载数据文件。但是,如果您是计算机编程经验很少或没有的拉丁语爱好者,您仍然可以通过下载预编译版本来使用此应用程序,该版本适用于 Windows 10。
Windows 10 电脑新手:在此处下载预编译版本。下载此文件后,在硬盘上的任何位置解压缩它,然后找到可执行文件。
C:\ ... 无论您在哪里解压缩它 ... \Latin Project 2_2\Latin Project 2_2\bin\Debug\Latin 2_2.exe
您可能想创建一个 Windows“快捷方式”,方法是选择文件,右键单击以显示菜单,然后单击“发送到”菜单选项中的“桌面”。否则,您每次都必须找到文件并双击它来启动它。(您仍然需要安装数据文件……请参阅下面的说明)
如果您**不**在运行 Windosw 10,您首先需要的是一个可用的 C#2019(目前是预览版)。您可以通过 Microsoft 的 Visual Studio 免费下载。它是一个大型产品,安装可能需要几分钟(安装 Visual Studio 时,请确保选择所有包含“C#”的选项)。一旦您运行了它,请下载上面的第一个压缩文件,并将其内容解压缩到硬盘上的任何位置。启动 C#2019,使用文件菜单选项 **加载解决方案**,然后在您解压缩源代码文件内容的目录中找到 LatinProject_2_2.sln 文件。按照下面的说明处理所有数据,准备好后,回到 C#2019 并按 F5。**id agere potestis!**
数据文件
使用 7-zip
如果您有 7-Zip,您可以通过此链接到我的 GoogleDrive 下载所有 数据文件。 。将此文件解压缩到您的硬盘上。应用程序希望在 c:\ 驱动器的根目录找到它们,所以只需使用 7-Zip
注意:拉丁文项目源代码(应用程序本身)期望在 c:\ 驱动器的根目录找到这些文件。将此文件解压缩到硬盘后,所有内容应如下面图片所示,还有一个新目录
C:\Latin\
如果您没有 7-zip,您可以访问此链接获取副本,否则您必须下载下面列出的所有文件,并按照下面的说明操作。
没有 7-zip
如果您没有 7-zip(或者只是想手动处理),您可以这样做:您需要在您的 C: 硬盘上创建一个名为 'Latin' 的子目录。这在应用程序中是硬编码的,所以除非付出一些代价,否则无法绕过。您可以查看代码并更改所有文件引用,但由于它们分散在许多地方,我强烈建议您坚持这样做。
注意:由于自 2018 年(或左右?)以来我对这些文件所做的任何更正都没有更新,因此如果您有可能,使用最新的 7-zip 文件会更好,因为没有它下载和安装对大多数人来说都会是一个很大的麻烦。
下载 c_Latin_Cassells_Dictionary_.zip - 7.3 MB
- 下载 c_Latin_Data_LUT_LUT_LL_000_.zip - 6.1 MB
- 下载 c_Latin_Data_LUT_LUT_LL_002-003_.zip - 8.7 MB
- 下载 c_Latin_Data_LUT_LUT_Bin_000-001_.zip - 8.4 MB
- 下载 c_Latin_Data_LUT_LUT_LL_001.zip - 6.2 MB
- 下载 c.latin.data_CS_Dictionary_.zip - 5.5 MB
- 下载 Changes_To_LatinProject_20190411.zip - 574 B
- 下载 VerbsMissingParts.zip - 1.4 KB
- 下载 c.latin.data_Dictionary_.zip - 1.1 MB
- 下载 c.latin.library_Subdir_A_C_.zip - 7.3 MB
- 下载 c.latin.library_Subdir_D_K_.zip - 8.1 MB
- 下载 c.latin.library_Subdir_L_R_.zip - 8.5 MB
- 下载 c.latin.library_Subdir_S_Z_.zip - 7 MB
- 下载 c.latin_wheelock_.zip - 7.6 MB
- 下载 c.latin.data.cs_library_Latin_Library_CS_000_003.fBin_.zip - 6.8 MB
- 下载 c.latin.data.cs_library_Latin_Library_CS_000_001.bin_.zip - 7.8 MB
- 下载 c.latin.data.cs_library_Latin_Library_CS_000_005.LL_.zip - 9.4 MB
- 下载 c.latin.data.cs_library_Latin_Library_CS_006_011.LL_.zip - 9.7 MB
- 下载 c.latin.data.cs_library_Latin_Library_CS_012_016.LL_.zip - 7 MB
下面的图片是关于如何在笔记本电脑上设置和运行拉丁文项目的有用指南。
文件很多。所有文件都需要解压缩到其相应的目录中。因此,您需要做的第一件事是创建必要的目录。您应该足够熟练使用 Windows 资源管理器来完成此操作。大多数人都可以,只需转到您的 C: 驱动器,右键单击以弹出上下文菜单,选择新建,然后选择文件夹并键入名称。您需要创建的目录如下面图片所示。
- C:\Latin\
- c:\Latin\Audio\
- c:\Latin\Data\
- c:\Latin\Data\CS_Library
- c:\Latin\Data\LUT
- c:\Latin\Library\
您想要下载的压缩音频文件位于 章节音频文件。只需将该文件的内容解压缩到 c:\Latin\Audio\ 目录中,下次启动应用程序时,拉丁文项目将对其进行处理。(**编辑** 2019/04/02 - 所有新上传的文件大多**名称不显示在下面的图片中**,但遵循相同的命名规则。.zip 文件内容的简短描述在第一个下划线**之后**;第一个下划线**之前**的文本是该文件需要解压缩的位置)
编辑 - 2019/04/11 - 图像中的文件名是在我将它们上传到 CodeProject 之前在我 PC 上显示的样子,并且带有圆括号 - 注意:您下载的文件将圆括号替换为下划线,并且可能与下面显示的文件相同,也可能不同。请记住,它们的目标路径在它们的文件名中,在第一个下划线**之前**进行描述。

编辑注意:2019/03/18 - 我发现了一个拉丁文错误,关于 **fero, ferre, tuli, latum**(整个动词都需要用户定义,而不仅仅是异常情况,因为应用程序没有识别出它的词根是 **fere-**),并且发现 `Rebuild_LUT()` 没有识别 Future_Active_Participle_Feminine 词性,它所有的 12 个条目都被声明为 Nominative Singular(例如 amaturarum => Nominative Singular,Amaturis => nominative singualr,Amaturae => Nominative singular……你懂的)。
因此,这些更改导致包含 **LUT** 字样的文件与上面图片中列出的文件不完全相同,但遵循了我前面解释的相同命名规则,所以这应该不难。只需将名为“c.latin.data.lut( --- ).zip”的文件解压缩到“c:\Latin\Data\LUT\”目录中。
编辑注意:2019/03/20 - 我一直在开发一个拉丁语填字游戏(生成器和游戏),它发现了许多我以前从未注意到的问题。最新的发现是那些词根异常的词。例如 **ex**eo, -ire, **af**fero, -ferre,它们的解决方案都被识别为——不定式——而不是相应的 Present Active whatever-it-was-supposed-to-be。这已经修复了。
此外,在 24000 条记录中有 8 条在这些 8 个词典单词文件的标题中,连字符和词尾之间有一个空格。这使得 opifex 无法正常工作,无法为这 8 个词进行正确的变位/屈折。
最后,有几种形式如果使用 OS 窗体控件(窗体顶部的 X,按下 Shift-Alt 时)处理,会导致问题。这些问题在再次调用时会出现。似乎已修复。我们拭目以待。
编辑注意:2019/04/02 - 我一直在研究我的填字游戏,并发现了词典中许多未正确工作的词,特别是动词。我后来写了几行代码来交叉引用词典中的所有动词。它生成 2 个列表:1) 具有所有四个主要部分的动词 2) 缺少一个或多个主要部分的动词(不包括不规则动词、半被动动词和被动动词)。然后,它将所有完整动词构建成一个 alpha 树,并将不完整动词逐个通过 alpha 树进行匹配。
为了测试一个“不完整”(缺少主要部分)的动词是否实际上是由前缀和另一个“完整”动词组成的,它搜索不完整动词的最后几个字母是否在完整动词列表中匹配。
例如:
dēmulceo, dēmulcēre, dēmulsi, -> dēmulceo, dēmulcēre, dēmulsi, dēmulsum
动词:“demulceo, demulcere, demulsi” 的标题是这样的。它缺少第四个主要部分。该程序会自动生成第四个主要部分(如果缺失)。在这种情况下,它认为:“demulcitum”,使用了拉丁文规则(据我理解)和“habeo, habere, habui, habitum”的例子。这是错误的。但 Cassell's 词典也没说得更好(或者我只是在输入时忽略了输入第四个主要部分),这个词导致了它所有的完成被动形式都错了。
我的“调试”代码所做的是找到这些“不完整”的动词,并将它们通过“完整动词”的 alpha 树进行匹配。我本可以列出所有合理的后缀并尝试移除它们,看看是否能在 alpha 树中找到匹配项,但它却取了第一个主要部分的最后 4 个字母,并在 alpha 树中搜索匹配项,每失败一次就增加一个字母。当它找到匹配项时(在此情况下,失败于 'lceo' 和 'ulceo',找到 'mulceo'),它将剩余未使用的字母“de-”作为前缀,将其添加到匹配的完整动词“mulceo, mulcere, mulsi, mulsum”的第四个主要部分,得出“demulsum”作为缺失的第四个主要部分。
我记录了在此文本文件中的所有更改: 动词缺失主要部分 (如果您有兴趣)。
您可以在注释掉的调试函数中看到执行此操作的代码
void findVerbsMissingPrincipalParts()
编辑注意:2019/04/11 - 代码没有重大更改,但我发现更多词典条目需要 rework。LUT 文件和 Cassells 词典文件已更新并在此处提供。以下链接将为您提供有关 Cassells 词典条目更改的信息 动词缺失主要部分 。
编辑注意:2019/06/05 - 我每天都在玩一两个填字游戏,并在源材料中积累了足够多的错误,足以进行更新 - 今天的更新包括新的源代码、查找表和 Cassell's 词典文件。有关最近更改的详细信息,请参阅 Changes_To_LatinProject_20190605.zip - 563
完成后,您的 c:\Latin 目录应如下所示。

您现在可以开始了!
如前所述,查找表和其他所有搜索引擎都已准备就绪。您无需自己生成它们,因为生成和使用它们的算法已将它们分成可以上传到 Code-Project 网站的文件大小。(您正在处理的所有这些文件)如果您觉得下载所有内容并将其解压缩到各自的目录中令人望而生畏,并且您认为自己做不到,我知道您可以。否则,下载 Cassell's 词典、库和音频文件,然后预计等待一周,应用程序将生成您运行它所需的所有搜索引擎。
一点代码
搜索引擎由二叉树组成,每个叶子指向一个链表,链表元素包含应用程序用来向用户提供所需信息的。与最初发布的应用程序相比,此版本不同之处在于它们被分解成更小的段。如何做到这一点相对简单。有一个类管理所有打开文件的文件流。
public class classFileStreamManager
{
Semaphore sem = new Semaphore(1, 1);
public FileStream fs;
public void WaitOne() { sem.WaitOne(); }
public void Release() { sem.Release(); }
}
该类是函数返回的值,该函数提供一个记录索引参数。该函数分配一个 FileStream 及其自己的 Semaphore,并将 FileStream 定位到调用函数读取或写入的正确位置。文件只打开一次(如果需要,则创建),直到应用程序关闭和释放。下面您可以看到它们在一个典型示例中是如何协同工作的。
public static string LUT_BinRec_FileName_Get(int intFileNumber){ return classXmlLatin.strWorkingDirectory + "Data\\LUT\\Latin_LUT_" + intFileNumber.ToString("000") + ".bin"; }
public static int intLUT_Bin_NumRecPerFile = (int)Math.Pow(2, 15);
public static classFileStreamManager LUT_BinRec_FileStream_Get(int index)
{
int intFileNumber = (int)Math.Floor((float)index / (float)intLUT_Bin_NumRecPerFile);
int intIndex_Revised = index - intFileNumber * intLUT_Bin_NumRecPerFile;
classFileStreamManager cFS = null;
if (lstSemFSLUT_Bin_FS.Count > intFileNumber)
cFS = lstSemFSLUT_Bin_FS[intFileNumber];
if (cFS == null)
{
string strFilename = LUT_BinRec_FileName_Get(intFileNumber);
cFS = new classFileStreamManager();
if (System.IO.File.Exists(strFilename))
cFS.fs = new FileStream(strFilename, FileMode.Open);
else
cFS.fs = new FileStream(strFilename, FileMode.Create);
if (lstSemFSLUT_Bin_FS.Count <= intFileNumber)
lstSemFSLUT_Bin_FS.AddRange(new classFileStreamManager[intFileNumber - lstSemFSLUT_Bin_FS.Count+1]);
lstSemFSLUT_Bin_FS[intFileNumber] = cFS;
}
cFS.fs.Position = intIndex_Revised * classLUT.lngLUT_Bin_RecordSize;
return cFS;
}
public static classLUT_BinTree_Record LUT_BinRec_Load(int index)
{
string strFilename = classLUT.strLUTBINFilenameAndDirectory;
classLUT_BinTree_Record cRetVal = new classLUT_BinTree_Record();
classFileStreamManager cFS = LUT_BinRec_FileStream_Get(index);
cFS.WaitOne();
BinaryFormatter formatter = new BinaryFormatter();
try
{
cRetVal.left = (int)formatter.Deserialize(cFS.fs);
cRetVal.right = (int)formatter.Deserialize(cFS.fs);
cRetVal.LL = (int)formatter.Deserialize(cFS.fs);
cRetVal.strWord = (string)formatter.Deserialize(cFS.fs);
}
catch (Exception e)
{
classDebug.instance.Print_Exception(e);
}
cFS.Release();
cRetVal.intMyIndex = index;
return cRetVal;
}
函数 `LUT_BinRec_Load(int index)` 需要来自 `LUT_BinRec_FileStream_Get()` 的 FileStream
- 文件名由索引除以每个文件记录数推导得出
- 然后,它打开一个新的 FileStream(如果尚未打开)
- 它计算记录的位置并将 FileStream 定位到需要的位置
- 将 FileStream 和其自己的 Semaphore 一起发送给调用函数
您会注意到每个文件记录数是 2 的幂 Math.Pow(2, 15)。即使结果可能只超过 5MB,将其加倍到 Math.Pow(2, 16) 也会超过本站 10MB 的阈值。2 的幂,在二进制中,当然是一个不错的整数,计算机可以使用它进行右移,而无需进行冗长、乏味且极其缓慢的长除法。
`LUT_BinRec_Load()`
- 函数接收其 FileStream,并相信它已位于需要的位置
- 等待信号量给出绿灯
- 从 FileStream 加载记录
- 释放信号量并退出
这样做的额外好处是,如果多个线程通过同一引擎进行搜索,它们很少会发生冲突,因为它们很可能在读取不同的文件,并且每当发生冲突时,信号量都会阻止任何重大碰撞或导致应用程序崩溃的碰撞。在应用程序的整个生命周期内保持 FileStreams 打开可以加快搜索速度,并且它们快速可靠。
Latina est Gaudium
是的,拉丁文是一门令人愉快的语言!但首先,您需要掌握这门语言,因为我们说的不是俚语!这门语言很古老,而且在所有意图和目的上,目前都被认为是**死**的,但这并不是因为它正在衰落就对其加以排斥。让我来告诉您一些关于拉丁语的事情,以及为什么这个程序不仅仅是一本电子教科书。名词都有性别,包括第三种性别叫做“中性”,在拉丁语中意思是“既不”(您可能不知道!)。然后,每个名词和形容词都有六个格和两个数(单数和复数)。更重要的是,形容词有三种不同的用法:原级、比较级和最高级;所有形容词都有三个性别,两个数,和六个格。

3(性别)x 3(类型)x 2(数)x 6(格)= 108 种拼写同一个形容词的方式。
每个形容词。
动词呢?!在被动和主动、复数和单数之间,您有第一、第二和第三人称。现在时、过去时和将来时、虚拟式、分词、不定式……太多了!而且它们非常相似,但又各不相同。而且这还是在您弄清楚动词是第一变位、第二还是第三变位!或者,它是一个第三变位 IO 动词。然后,有一个叫做“被动周边式”的可怕的东西。
总之,我想说的是,如果您只靠一本课本学习拉丁文,您会遇到一些麻烦。而这正是这个程序的作用。它将能够变位和屈折词典中的每一个词,并为您提供每一个词的所有替代拼写。
例如,动词“**fero, ferre, tuli, latum”。这些是动词“承受”的四个主要部分。所以,如果您正在阅读一些内容,但不知道 **tulissent** 是什么意思,您会翻阅书架上的词典,在字母 'T' 下查找,但永远找不到动词 fero, ferre 的过去完成时虚拟式第三人称复数拼写。……除非,当然,您已经运行了这个程序。那样您就知晓了。
Opifex: 技术工人
当您首次启动程序时,您将看到 Wheelock's Latin 的封面。图像下方灰色下划线文字都是指向书中其他部分的链接。程序的课本部分的工作方式与 HTML 和互联网类似,只不过它是一个文件网络,所有文件都包含在硬盘上的单个目录中,您可以对其进行导航。这是通过一个名为 `xmlRecord` 的类与 `classGraphics` 结合实现的,我在《GCIDE:完整的英语词典》一文中曾讨论过。
`classXmlLatin` 类似,但它没有连接文件的链接,这些链接构成了文件网络,因为 `classXmlLatin` 处理的词典文件不需要任何网络,并且完全通过查找表的引用加载。还记得前面提到的 LUT 吗?这就是拉丁文实际发生的地方。`classLatin` 依赖 `classXmlLatin` 来检索其用于创建查找表的词典条目。
当您最终让程序为您构建 LUT 时,您会发现程序在构建此数据库的过程中将非常消耗 CPU。它将使您的计算机连续忙碌近 24 小时!您可以随时停止和重新启动,无需额外费用,您可以让它通宵运行。这似乎很长时间,但如果您下载此程序是因为您需要(或想要)学习拉丁文,那么您将不会想没有它。
`classLatin` 使用一个 *opifex*(技术工人)来完成所有工作。程序只需要实例化一个 `classLatin`;该类然后创建自己的资源处理器以及它所依赖的著名 *opifex*。资源处理器管理 `classWordInfo`。这些 *word-info* 对象包含 *opifex* 进行变位或屈折所需的所有词典条目信息,无论具体情况如何。`classWordInfo` 还有两个组合框,如果需要,可以放在屏幕上。您可以从资源管理器请求任意数量的这些组合框,每当用户在任一组合框上更改选择时,`classWordInfo` 就会将自身传递给 *opifex* 来提供拉丁文。
`classOpifex` 的实际代码并非非常复杂,因为所有工作都分为大量的函数,这些函数的命名都考虑了其特定任务。对于大多数变位/屈折函数,*opifex* 接收一个 `classWordInfo` 实例作为参数。由于每个函数都是为一种独占用途而编写的,所以这些函数只需要做它们该做的事情。在程序的原始 Visual Basic 版本中,我犯了一个错误,试图让一个函数完成所有工作,结果发现这会随着课本新章节的出现而带来新问题。这个 C# 版本没有一个函数有“我能搞定一切”的态度,而是依赖于一小群函数,每个函数处理不同的拉丁文变位或屈折。
这里有一个例子……
public classLatin_C.classSolution conjugate_Present_Indicative_Active(classWordInfo word)
{
if (verbIsDeponent(word))
return conjugate_Present_Indicative_Active_Deponent(word);
classLatin_C.classSolution cRetVal = new classLatin_C.classSolution();
string[,] strSolution = new string[2, 3];
cRetVal.strSolution = strSolution;
cRetVal.typeSolution = getTypeSolution(classEnum.enuVerbTenses.Present_Indicative_Active);
// 1st, 2nd, 3rd, 4th, 3rd-IO
string[,,] strEndings = {{{"ō", "ās","at"}, {"āmus","ātis","ant"}},
{{"eō", "ēs","et"}, {"ēmus","ētis","ent"}},
{{"ō", "is","it"}, {"imus","itis","unt"}},
{{"ō", "s","t"}, {"mus","tis","unt"}},
{{"iō", "is","it"}, {"imus","itis","iunt"}}};
string strBase = word.strWords[1];
if (word.eWordType == classEnum.enuWordType.verb_4th_conjugation)
strBase = word.strWords[0].Substring(0, word.strWords[0].Length - 2)
+ makeLongVowel(word.strWords[0][word.strWords[0].Length - 2]);
else
strBase = strBase.Substring(0, strBase.Length - "are".Length);
classEnum.enuVerbConjugations verbConjugation = getVerbConjugationFromeWordType(word.eWordType);
for (classEnum.enuNumber numberCounter = classEnum.enuNumber.Singular;
numberCounter <= classEnum.enuNumber.Plural;
numberCounter++)
for (classEnum.enuPerson personCounter = classEnum.enuPerson.First;
personCounter <= classEnum.enuPerson.Third;
personCounter++)
cRetVal.strSolution[(int)numberCounter, (int)personCounter]
= shortenLongVowels(strBase + strEndings[(int)verbConjugation,
(int)numberCounter,
(int)personCounter]);
cRetVal.strRowNames = getRowNamesOfConjugation();
cRetVal.strColumnNames = getColumnNamesOfDeclension();
return cRetVal;
}
在此示例中,*opifex* 被要求将提供的 `word` 进行现在时主动语态的变位。它会先问“这是一个被动动词吗?”,如果是,它会转向处理该情况的 *opifex* 函数。否则,它会创建一个名为 `udtSolution` 的结构实例,并将动词时态翻译成 `typeSolution`(两个枚举类型)。然后,因为这种情况下的拉丁文规则是在添加人称词尾之前去掉动词第二个分词的最后一个字母(`classWordInfo` 中的 `strWord[1]`),所以它会生成一个名为 `strBase` 的变量,并继续添加适当的词尾,获取此解决方案类型的行名和列名,并将其重新连接到调用函数。
如果您仔细查看这些函数,您会发现它们几乎都做同样的事情,只有细微的差异以适应其特定任务。由于拉丁文中名词、形容词和动词的变位和屈折方式非常多,所以这样做比节省代码空间将它们合并到一个或几个函数中要容易得多。这种设计使得调试更加容易。这样,如果明年我发现我一直在错误地屈折第三变位阴性最高级形容词,那么只需要修复一个函数,并在调试时不会影响任何其他内容。
Bada-bing, bada-boom。
在组合框二中
每当屏幕上出现一个词典条目时,您会发现它除了定义之外还有一些额外功能。查看词条上方的两个组合框,您会看到左边的组合框告诉您这是什么类型的词,例如,**magnus, -a, -um**:第一变位形容词。在此下方列出的是该形容词的三种斜体用法(原级、比较级和最高级)的每一种的三个性别:您可以选择其中任何一个条目并获得输出。选择任何特定的性别将为您提供该形容词在您所选性别/类型下的两个数和 6 个格的拼写。单击列表中间附近的**比较级**标题,将生成另一个包含所有 3 个性别 x 2 个数 x 6 个格(magnus 的所有比较级拼写!)的表单,如果您仍然不确定要查找什么,上面提到的第一个标题(带有词语类型信息)将一次性将这个特定形容词的 108 种拼写方式全部显示在屏幕上。

请注意上面图片与下面图片的区别。如果您没有立即注意到,下面图片比上面图片多了几个额外功能。这是因为下面图片是同一个词的词典定义表单的屏幕截图,是在用户以管理员身份登录时拍摄的。由于词典很容易编辑,为了防止任何人轻易篡改您的数据和您的拉丁语词典或其他文件(只有负责任的用户才应该这样做),您现在拥有了登录功能。稍后将详细介绍。

动词和名词类似,但有时态、被动和主动;或者对于名词,与形容词类似,但只有一种性别。随便玩玩,您就会明白我的意思了。
在右边!
另一个组合框是我称之为**拉丁逻辑**的东西。它加载了 Wheelock's Latin 课本中与您正在查看的特定词语相关的页面链接。当您弹出包含词语 **capio, -ere** 定义的词典条目时,您可能会好奇第三变位-IO 动词是什么,通过扫描列表中的条目,您会找到您要找的东西。然后,当您从拉丁逻辑组合框中选择一个条目时,您的拉丁语课本的一个全新实例将弹出,正好是正确的页面,第 10 章,子标题“IO verbs”,供您阅读。
还有个 LUT 要做
您真的应该让您的程序构建一个查找表,因为没有它,您就错过了 lut!(双关语)。 让我解释一下。如果您还没有实际看到一个*词典条目*并告诉*opifex*开始工作,那是因为您还没有将查找表上线。一旦您做到了,它就非常方便。查找表的作用与上面提到的 GCIDE 文章非常相似:它帮助您找到您要找的东西。它告诉您一个词是什么,该特定拼写有多少种来源,以及在哪里可以找到您正在查看的词的词根。为此,程序会遍历拉丁文/英文词典中的每个条目,一次加载一个词条,生成它所知道的所有可能拼写,然后将它们存储在数据库中,并附带获取每个拼写的方法。然后,当用户询问例如 **capiunt** 这个词时,它会扫描数据库并告诉您,如果您在随身携带的拉丁语词典中查找,您会在 **capio, -ere, cepi, captum** 下找到 **capiunt**;但是,LUT 还会告诉您它是现在时主动语态,第三人称,复数,这是您否则必须自己弄清楚的。
别以为您可以通过不背诵变位和屈折就能精通拉丁文。那是很不幸的。您仍然需要投入时间来真正掌握如何变位和屈折,而这个应用程序将帮助您确保您做得正确。只是不要让它让您变得懒惰。

上面的图片显示了顶部的课本页面“论一个情绪化的朋友”。单击第一句拉丁语中的单词 **difficilis** 会显示 **difficilis** 的形式,列出了该特定拼写的所有可能来源,然后选择第一个会弹出其前一个窗体(带有两个组合框的词典条目)或蓝色的窗体(原级阳性屈折)分别通过单击该拼写可能来源列表的左半部分或右半部分。单击左半部分会调用一个 DictionaryDefinitionForm,让您选择所需的 Latin_Solution,或者单击右半部分,您将获得您在列表中单击的解决方案项。
您会注意到这个词还显示了“音频”按钮,按下后会播放该词的发音(前提是您已下载音频文件)。注意到蓝色了吗?名词和形容词根据性别进行了颜色编码。蓝色代表阳性名词,粉色代表阴性名词。形容词也以相同的三种颜色显示,但名词只有一个特定性别,而形容词(根据它们所修饰的名词的数、格和性别进行匹配)则显示所有三种颜色。
拉丁语很特别,因为如果您在口袋词典中查找“**cep**erant”这个词,您可能不会想到去查“**cap**io”,也可能找不到。但有了这个 LUT,所有这些都为您完成了!不幸的是,大部分思考也替您完成了,这使得完全依赖程序而不学习任何实际的拉丁语变得很容易,正如我愉快地发现的那样。我花了多年时间才真正学会这些,我有点慢。如果你们认真对待任何语言,变位/屈折规则都是至关重要的。所以坐下来,锻炼你的大脑,学习它们。
LUT 首先会给您一个词源列表。在那里,您可以要求它为您提供所选条目的词典形式,或者直接将其解决方案显示在屏幕上。当列表中只有一个项目时,您可以通过按 F1 或 F3 来完成其中之一。或者,您可以单击窗体的左半部分或右半部分,一个弹出式的帮助文本会告诉您您将要选择什么。“在此处单击以获取完整推导”会在鼠标光标位于左半部分时显示在弹出式文本中,而“在此处单击以获取特定推导”则会在鼠标光标位于右半部分时显示。
程序的 `mode` 选择允许您在*练习册*、*课本*和*词汇*模式之间选择。*课本*是默认的启动值,在这里您可以单击单词、链接或图像。单击拉丁语单词会使程序在 LUT 中搜索您单击的单词,使阅读拉丁语对于任何新手来说都不那么令人生畏。如果您单击了一个在 LUT 中找不到的单词,程序不会生气或争辩,而是会停止并等待您的下一个请求。下面的 `classGraphicOutputPanel` 窗体中的 `PictureBox` 的鼠标单击事件显示了在哪里
void pic_MouseClick(object sender, MouseEventArgs e)
{
if (DisableNavigation
&& ((wordUnderMouse != null
&& wordUnderMouse.eWordImageType != classEnum.enuXmlRec_WordImageType.solution)
|| (wordUnderMouse == null)))
return;
if (wordUnderMouse != null)
{
switch (wordUnderMouse.eWordImageType)
{
case classEnum.enuXmlRec_WordImageType.link:
string strFilenameAndDirectory
= cLibXmlRecord.strWorkingDirectory
+ wordUnderMouse.strAddress + ".xml";
if (System.IO.File.Exists(strFilenameAndDirectory))
{
loadFile(wordUnderMouse.strAddress);
cutNavigation();
addNavigationPage();
}
else
{ // exit
if (DisableNavigation)
return;
}
break;
case classEnum.enuXmlRec_WordImageType.solution:
frmPopUp.rtx.Font = new Font("ms sans serif", 12, FontStyle.Regular);
frmPopUp.rtx.Text = wordUnderMouse.strAddress;
FormPopup_PlaceAndShow();
break;
case classEnum.enuXmlRec_WordImageType.image:
Form frmPic = new Form();
PictureBox pic = new PictureBox();
frmPic.Controls.Add(pic);
pic.SizeMode = PictureBoxSizeMode.AutoSize;
pic.Image = wordUnderMouse.bmp;
frmPic.Size = new Size(pic.Width + 15, pic.Height + 35);
frmPic.Text = wordUnderMouse.strText;
pic.Location = new Point(0, 0);
frmPic.KeyDown += new KeyEventHandler(cLibLatin.frm_KeyDown);
frmPic.Show();
break;
case classEnum.enuXmlRec_WordImageType.plain:
classLUT.LUT_Search(classStringLibrary.RemoveMacrons(wordUnderMouse.strText),
classEnum.enuLUT_Search_Output.frmResultShow,
classEnum.enuLUT_Search_CallingFunction.notRelevant);
break;
}
}
}
课本只不过是一个带有额外功能的文本框;您猜对了,它是一个与拉丁语 LUT 兼容的区域。只需单击您输入的单词,然后按 F1、F2、F3 或 F4。
- F1 - LUT - 查找表
- F2 - 词典 - 提供词典中的单词的字母列表
- F3 - 词典内容搜索 - 搜索词典的定义
- F4 - 库搜索 - 搜索存储在您的库子目录中的古代拉丁文文本
您可以右键单击以获取上下文菜单,并在其中查看这些选项。
介绍华丽的*查找表面板*
主窗体的左侧包含一个隐藏面板,用于您的 LUT 控件。

除了归功于本程序的素材来源外,它还通过启用一个定时器来测试 Microsoft 剪贴板中的文本,从而允许您在其他程序中使用拉丁语 LUT。当它发现文本与上次检查时不同时,它会剪掉第一个单词并将其插入查找表。这在您阅读《邪恶力量》的剧本,或者研究梵蒂冈的拉丁语文件以寻找驱魔仪式时非常方便,或者如果您只是好奇您多年来一直信任的那个熟悉的品牌名称实际上是否是一个伪装的拉丁语绰号。要使用它,当您选中 LUT 面板上的复选框时,您只需选择您想通过 LUT 运行的文本,例如,在您的网页浏览器上,并通过高亮显示然后按 Ctrl-C 组合键将其复制到操作系统的剪贴板。
搜索面板

在拉丁语方面,有时您需要搜索课本中可能遗漏的内容。这就是您屏幕底部的面板所做的事情。选择*标题*复选框会在 Wheelock's 课本的每个章节标题和子章节标题中搜索您正在寻找的单词。*词汇表*仅搜索词汇表单词及其英文定义。这在您尝试从英语翻译成拉丁语时非常方便,它类似于词典内容搜索,但仅限于词汇表。如果您想知道“女孩”在拉丁语中的单词,您可以在词汇表或词典内容中搜索它,结果将是词汇条目 **puella, -ae**,其定义中包含单词*girl*。从那里,您可以单击单词 **puella**,让查找表输出漂亮的粉色 12 部分屈折!不选中任何一个复选框将搜索课本中的所有内容,但不包括词汇表条目。
在代码方面,您可能会觉得面板的按钮很有趣。背景图像存储在程序的资源中,然后在运行时复制到面板上。然后,每个按钮/复选框都会放置在面板上,对于每个按钮/复选框,都会从同一个源图像创建一个位图,并策略性地放置在该对象上,以完成图片。这创造了一个很好的图形效果。
至于实际执行搜索的代码,它在某些方面与 LUT 相似,因为它依赖于二进制流文件,其中包含大小相同的记录,这些记录可以以随机访问的方式检索和保存。这些记录包含一个可搜索的单词,以及它所在的文件的名称,以及三个整数变量,用于创建构成数据库的二叉树/链表。虽然 LUT 使用两种不同的文件类型(每种都有多个以适应 Code-Project 的 10MB 上传限制),一种用于二叉树,另一种用于保存二叉树的每个叶子指向的所有链表条目,但课本搜索引擎将所有信息都保存在单个文件中。或者说三个文件,因为有三种不同类型的搜索:普通搜索、词汇表搜索和标题搜索,每种都“需要”自己的文件。我在这里用引号括起来“需要”,但如果三个不同的树的根节点分别位于记录 1、2 和 3,那么所有三个搜索引擎都可以存储在同一个文件中。您只需要知道文件中您想要的树的数量,并为每个树的根节点预留这三个条目。撇开这个想法不谈,这个程序为三种不同的搜索模式使用了三个不同的文件。实际上只有一个搜索引擎,并且由于 `getRecord()` 和 `putRecord()` 函数接受一个 `Mode` 参数,它们可以在每次执行时打开和关闭相应的文件。`Mode` 是一个枚举类型,三个文件名存储在一个数组中,并考虑了枚举类型的整数值,因此通过模式类型索引即可轻松获得正确的文件。
classSearchRec_FileTreeElement getRecord(long index, enuTypesSearches Mode)
{
FileStream fs;
if (index < 0)
return null;
if (System.IO.File.Exists(strSearchBinFilenameAndDirectory[(int)Mode]))
{
fs = new FileStream(strSearchBinFilenameAndDirectory[(int)Mode], FileMode.Open);
fs.Position = getBinPosition(index);
BinaryFormatter formatter = new BinaryFormatter();
string strFilename = (string)formatter.Deserialize(fs);
string strWord = (string)formatter.Deserialize(fs);
classSearchRec_FileTreeElement cRetVal =
new classSearchRec_FileTreeElement(strWord, strFilename);
cRetVal.lngLeft = (long)formatter.Deserialize(fs);
cRetVal.lngRight = (long)formatter.Deserialize(fs);
cRetVal.lngNext = (long)formatter.Deserialize(fs);
cRetVal.intSizeLinkedList = (int)formatter.Deserialize(fs);
fs.Close();
return cRetVal;
}
return null;
}
您可以在上面的第二个 `if` 语句中看到 IO 系统如何测试搜索引擎文件的存在性,该文件存储在 `strSearchBinFilenameAndDirectory[]` 数组中,该数组由输入参数 `Mode` 的整数值索引。
public class classSearchRec_FileTreeElement
{
public long lngLeft;
public long lngRight;
public long lngNext;
public string strWord;
public string strFilename;
public int intSizeLinkedList;
public classSearchRec_FileTreeElement(string Word, string filename)
{
lngLeft = -1;
lngRight = -1;
lngNext = -1;
intSizeLinkedList = 1;
strWord = Word;
strFilename = filename;
}
}
搜索引擎中一个更有趣的部分可能是它执行布尔搜索的方式。每当用户在搜索引擎中输入多个单词时,程序就需要找到结果并将其显示在屏幕上。要理解这如何工作,您首先必须知道,当搜索引擎数据库创建时,每个文件都被扫描,每个文件中的每个单词都被输入到相应的数据库中,并且来自任何一个文件的*没有重复*的单词进入了数据库。因此,即使单词“the”在一个特定文件中出现十二次,它也被输入到数据库中,表示“至少出现一次”,不再多。此外,当多个文件具有相同的单词时,二叉树必须在该特定叶子处分支成一个链表(都在同一个文件中,使用相同的记录类型,该记录类型具有二叉树链接的所有三个整数索引 `intLeft` 和 `intRight` 以及链表 `intNext`)。在将新的查找结果插入二叉树叶子的链表时,树的叶子(而不是它指向的链表中的节点)会跟踪链表中的条目数。这相当于跟踪有多少文件包含这个特定的单词,而无需计算链表中的条目数。由于搜索引擎只需构建一次,然后只被引用而从不编辑,因此将此值存储在列表的第一个元素中使其易于获取。
因此,当搜索引擎发现需要交叉引用两个或多个文件名列表以查看它们是否包含您正在比较的两个单词时,它会首先在 RAM 中生成一个*最短*列表的二叉树,然后将下一个最短列表中的每个条目运行到这个二叉树中。包含在第二个列表中且在第一个列表的 bin 树中找到的filenames 将进入另一个 bin 树,然后该 bin 树用于第三个单词的文件列表。该代码保留了指向这些 RAM 树根的两个指针的数组,并在两者之间交替,通过越来越小的树扫描越来越大的列表,直到最终扫描所有结果列表的总和而未在之前的树中找到任何文件名,此时它退出,或者它已经扫描了所有列表,并且现在持有所需用户要查找的每个搜索词都包含在最后一个创建的 RAM bin 树中的所有文件名。
public class classSearchRec_RAMTReeElement
{
public classSearchRec_RAMTReeElement Left;
public classSearchRec_RAMTReeElement Right;
public classSearchRec_RAMTReeElement Next;
public string strWord;
public string strFilename;
public int intSizeLinkedList;
public classSearchRec_RAMTReeElement(string Word, string filename)
{
Left = null ;
Right = null ;
Next = null;
intSizeLinkedList = 1;
strWord = Word;
strFilename = filename;
}
}
所有这些都在 `classWheelockTextbook_Search` 的
public string[] searchWord(string strSearchWords, enuTypesSearches eMode)
弹出窗口中完成
图像下方右侧顶部的按钮,上面有一个**^**,会弹出一个新的弹出窗口,加载当前页面,并具有应用程序主窗体的所有功能。它的“主页”导航按钮会将您带回到加载它的文件,所以如果您迷路了,您可以随时找到路。
面板和模式

在上面的图片中,您可以看到一些导航控件自近十年前上次发布文章以来发生了变化。组合框仍然一样,它会跟踪您在 Wheelock's Latin 课本中的最近访问记录。右侧是**主页**图标,它将您带回到“主页”,该页面显示书的封面并列出所有章节。左右箭头(示例中仅可见左箭头)可以带您回到或前进到您最近的阅读内容,而双正方形图标是一个复制设备,它将弹出您正在查看的记录的精确副本,以防您想同时查看多个页面。

在上面的图片中,您可以看到屏幕上出现的四种不同的*侧面板*。我称它们为*侧面板*,因为可以单击位于窗体左边缘的标签将它们带到前面,这就是它们全部被带到前面时的样子。当您再次单击它们时,您只能看到左边缘的单词伸出来,因此得名。我已经讨论了搜索面板和 LUT*炫耀面板*,但您还没有听说过另外两个面板,标记为*模式*和*工具提示*。这没什么神秘的,可能也不用多说,模式面板是您选择应用程序模式的地方,而工具提示面板则用于切换工具提示。
词汇模式
在模式面板中,您可以选择三种模式之一:课本、练习册和词汇模式。单击*词汇*单选按钮将带您到这里

这是词汇模式。您可以使用计算机上的抽认卡来复习您的拉丁语词汇。`classVocabulary` 是上面图片中您看到的带有“Vocabulary”字样的分组框。右侧的组合框列出了 Wheelock 的所有词汇章节文件(共四十个章节),您可以选择或取消选择您希望在下次复习拉丁语词汇时随机选择的章节。每当您选择一个章节时,该章节中包含的所有单词都会添加到待复习的单词列表中。然后,当您单击组合框下方的“复习单词”按钮时,将从您选择的复习章节中随机挑选一些新单词添加到您当前的词汇单词列表中,然后会出现一个抽认卡,上面是第一个供您学习的单词。

上图显示了抽认卡的正面。单词以拉丁语显示;在这种情况下,是拉丁语动词 **cogito** 及其四个主要部分。移动鼠标,您会发现顶部的三个单词,“Delete”、“Next”和“Quit”,是可点击的,并且像按钮一样工作。但是,您首先需要翻转卡片。为此,抓住卡片上不是*按钮*的任何地方,然后垂直移动鼠标,同时按住鼠标按钮。这将产生一个翻转动画,让您可以根据鼠标的位置显示抽认卡的任意一面。
卡片的*翻转*效果是一个简单的技巧。有两个图片框,填充并对接在窗体上,一个在另一个上面。程序使用一个变量来跟踪您正在查看的*那一面*,并使用另一个变量来记住您抓住了哪一面,所以当鼠标移动时,图像会根据其被抓取的位置(在屏幕中线上方或下方)以及此时鼠标光标的位置(也相对于屏幕中线)进行收缩和扩展,然后决定哪个图像在前。这一切都在 `classFlashCard`(在 `classVocabulary.cs` 文件中)的 `MouseMove` 事件中完成。
请注意布尔全局变量 `bolIgnoreMouseMove`。因为所有操作都发生在鼠标移动事件处理程序内部,它会移动窗体,影响鼠标下方的图像,并导致更多事件被处理,所以这些事件必须被忽略,直到它完成操作,否则它们会级联导致灾难。此布尔值在事件处理程序开始时进行测试,然后在其退出前重置,允许处理程序在更新窗体的过程中引起更多事件,确保这些事件在完成之前被忽略。
void pic_MouseMove(object sender, MouseEventArgs e)
{
if (bolIgnoreMouseMove)
return;
bolIgnoreMouseMove = true;
if (bolGrab)
{
Point ptMousePosition = new Point(MousePosition.X, MousePosition.Y);
if (distanceBetweenTwoPoints(ptMousePosition, ptOldMousePosition) > 5)
{
ptOldMousePosition = ptMousePosition;
int intNewHeight =
Latin_Project.Properties.Resources.flashcard_source_back.Height;
int intNewTop = intMidScreen;
int intGrabDist_Abs = Math.Abs(intGrabDistFromCenter);
int intMidHeight = Height / 2;
int intDistanceFromCenter = Math.Abs(e.Y - intMidHeight);
bool bolSetToNewValues = false;
if (intGrabDistFromCenter < 0)
{ // grabbed it above mid-point
if (e.Y > intMidHeight - intGrabDist_Abs)
{ // in the process of flipping or completed action
if (e.Y > intMidHeight)
{ // seeing the side not-grabbed
eVisibleSide = otherSide(eGrabSide);
if (e.Y < intMidHeight + intGrabDist_Abs)
{
// fraction of size (still flipping)
intNewHeight = (int)(((double)intDistanceFromCenter /
(double)intGrabDist_Abs) *
Latin_Project.Properties.Resources.flashcard_source_back.Height);
}
bolSetToNewValues = true;
}
else
{ // still seeing the grabbed-side
eVisibleSide = eGrabSide;
if (e.Y > intMidHeight - intGrabDist_Abs)
{
// fraction of size (still flipping)
intNewHeight = (int)(((double)intDistanceFromCenter /
(double)intGrabDist_Abs) *
Latin_Project.Properties.Resources.flashcard_source_back.Height);
}
bolSetToNewValues = true;
}
}
}
else
{
// grabbed below mid-point -> (intGrabDistFromCenter > 0)
if (e.Y < intMidHeight)
{ // seeing the side not-grabbed
eVisibleSide = otherSide(eGrabSide);
if (e.Y > intMidHeight - intGrabDist_Abs)
{
// fraction of size (still flipping)
intNewHeight = (int)(((double)intDistanceFromCenter /
(double)intGrabDist_Abs) *
Latin_Project.Properties.Resources.flashcard_source_back.Height);
}
bolSetToNewValues = true;
}
else
{
// still seeing the grabbed-side
eVisibleSide = eGrabSide;
if (e.Y < intMidHeight + intGrabDist_Abs)
{
// fraction of size (still flipping)
intNewHeight = (int)(((double)intDistanceFromCenter /
(double)intGrabDist_Abs) *
Latin_Project.Properties.Resources.flashcard_source_back.Height);
}
bolSetToNewValues = true;
}
}
if (bolSetToNewValues)
{
Height = intNewHeight;
Top = intMidScreen - intNewHeight / 2;
}
pic[(int)eVisibleSide].BringToFront();
}
}
else
{
cWordUnderMouse = mainForm.cLibGrText.getWordUnderMouse(
new Point(e.X, e.Y), uWords[(int)eVisibleSide].cWord);
if (cWordUnderMouse != null &&
cWordUnderMouse.eWordImageType == enuWordImageType.link)
Cursor = Cursors.Hand;
else
Cursor = curNormal;
}
bolIgnoreMouseMove = false;
}

cogito ergo sum...
左上角的数字告诉您在此复习会话中还剩下多少张抽认卡,以及下一轮还剩下多少张。单击“删除”选项将丢弃您正在查看的卡片,使其下次复习拉丁语词汇时不会自动包含在内。或者,单击“下一个”选项会将您手中的卡片放回复习堆中,然后会随机抽取另一张。
新东西
现在我们来看一些最初文章中未包含的新功能。
- 管理员登录
- 词典定义编辑器
- 词典内容搜索
- 词典列表
- 库与库搜索
- 工具提示
管理员登录
为了防止任何不负责任的用户(或学生)的脏手接触您的查找表和无数数据树,许多功能已对非管理员用户禁用。要以管理员身份登录,请进入**练习册模式**。然后单击**文件菜单**选项,然后选择**登录管理员**。您将看到下面的窗体:

默认密码为空字符串,所以第一次使用时只需按回车键即可登录管理员。然后它会提示您更改密码,如下所示

您就完成了。
代码:
一旦决定包含这些管理员/用户访问级别,通过隐藏或显示启用用户与受限功能交互的控件,就可以相对轻松地允许/阻止它们控制的许多功能。完成之后,我花了二十分钟编写了下面显示的加密/解密函数。
public static string Encrypt(string strText, string strKey)
{
string strRetVal = "";
if (strKey.Length == 0)
{
strRetVal = strText;
}
else
{
for (int intEscapeCounter = 0; intEscapeCounter < lstEscapeChar.Count; intEscapeCounter++)
{
classEscapeChar cEscape = lstEscapeChar[intEscapeCounter];
strText = strText.Replace(cEscape.strSource, cEscape.strTarget);
}
for (int intChar = 0; intChar < strText.Length; intChar++)
{
char chrSource = strText[intChar];
int intSource = conValidChar.IndexOf(chrSource);
char chrKey = strKey[intChar % strKey.Length];
int intKey = conValidChar.IndexOf(chrKey);
char chrTarget = conValidChar[ (intKey + intSource) % conValidChar.Length];
strRetVal += chrTarget.ToString();
}
}
return strRetVal;
}
public static string Decrypt(string strText, string strKey)
{
string strRetVal = "";
if (strKey.Length ==0)
{
strRetVal = strText;
}
else
{
for (int intChar = 0; intChar < strText.Length; intChar++)
{
char chrSource = strText[intChar];
int intSource = conValidChar.IndexOf(chrSource);
char chrKey = strKey[intChar % strKey.Length];
int intKey = conValidChar.IndexOf(chrKey);
char chrTarget
= conValidChar[(intSource - intKey + conValidChar.Length) % conValidChar.Length];
strRetVal += chrTarget.ToString();
}
for (int intEscapeCounter = 0; intEscapeCounter < lstEscapeChar.Count; intEscapeCounter++)
{
classEscapeChar cEscape = lstEscapeChar[intEscapeCounter];
strRetVal = strRetVal.Replace(cEscape.strTarget , cEscape.strSource);
}
}
return strRetVal;
}
这两个函数基本上所做的是,它们一次取源文本中的一个字符,并将每个字符与密钥文本(密码)中的一个字符进行匹配。允许字符列表被搜索,并且这两个字符的索引值相加,然后通过使用 '%' 模数学函数将它们的和减小以适应允许字符列表的长度(还记得四年级时 22 除以 3 不是 7.33333 而是 7 余 1 吗?模数就是“余 1”部分)。文本首先会被清理掉不好的控制函数,如 '\t' 和 '\r\n',这些字符会弄乱加密结果,所以它们被替换为替代字符串。经过处理的、已转义的文本被加密。要解密文本,反过来也是如此:加密字符串中的每个字符的索引减去相应密码字符的索引值,以获得转义文本中的原始字符。一旦整个文本被解密,文本将被搜寻,用原始的替代字符串替换控制字符,然后恢复原始文档。
然而,对于管理员密码,有一个“隐藏在显眼处”的文件,名为

没有人会多想它,直到您第一次单击“登录管理员”文件菜单选项后才会出现。第一次这样做时,在您更改密码之前,该文件将包含未加密的测试句子,您的密码将随后加密该句子,并且需要用相同的密码解密才能访问管理员功能。在更改密码之前查看它,之后再次查看,您会看到区别。如果您丢失或忘记了密码,只需删除该文件即可将其重置为空字符串。这听起来可能是一种无用的加密密码方式,因为任何人都可以阅读这篇文章并删除该文件以访问管理员功能,但如果您是自己计算机或计算机实验室的管理员,您可以设置此文件以及所有敏感目录及其文件的安全功能,使其对除您(管理员)之外的所有用户都设置为“只读”。所以,它不是万无一失的,任何密码学家只需要二十分钟就能破解您的密码。它不是万无一失的,但编写它也只花了二十分钟,所以应该够用了。
词典定义编辑器
如承诺的,有一种方法可以编辑和创建新的词典条目。如果您发现 LUT 不包含您正在查找的单词,您可以为其创建一个条目,应用程序将生成该单词的各种格/变位,并将其包含在 LUT 中。界面非常易于管理。请看下面的图片。它显示了管理员可用的新菜单选项。
有一点应该提到,另一个功能是,您可以非常容易地输入长音符号,只需在您想输入的带长音符号的元音前输入一个“前缀”字符。只需输入“**/e**”,然后“**/”就会消失,留下 **ē**。这同样适用于练习册,您可以在那里进行写作并使用拼写检查器。

单击“条目编辑器”将调出下面显示的词典条目编辑器窗体。文件菜单选项是标准的,应该不会给您带来麻烦,但如果您想查看您写的内容的结果,您可以保存文件并单击“**选项-查看**”菜单选项。这将显示该单词的词典定义窗体,即您的最终输出,然后您可以对其进行试运行,看看它是否如您所愿地进行变位/屈折。如果不行,那可能是因为您误认了词性。您可以从“词性”组合框中选择任何可用的词性选项。文本文件和文件菜单选项一样直接,但您需要考虑到这是一个词典单词,并且输入的单词必须看起来像它所声称的那样。所以看看一些类似词的例子,这些词已在 LUT 及其词典中,以了解标题应该如何显示。如果不确定替代标题拼写(下面 fustis 有一个替代拼写“-is”作为其属格单数),只需输入完整的单词。如果您足够勇敢地编辑告诉代码如何添加这些词尾的文本文件,您可以尝试一下(LatinEndings.txt),但我不建议这样做,因为它制作得非常仔细且易出错,很容易弄得一团糟。
如果您确信您输入的单词将按预期工作,那么“自动附加 LUT”选项就可用了。我建议您在熟悉编辑器之前不要勾选此选项,以确保您不会因为误认输入的单词而产生错误的格。您始终可以通过按该单词的词典定义窗体上的“**附加 LUT**”按钮来附加 LUT。所以,请将“自动附加 LUT”选项保持未选中状态,查看结果,测试它,然后,如果您满意,将其附加到 LUT。您可以随意多次将同一个单词附加到 LUT,但这将意味着其搜索结果将显示您执行此操作的次数。这可能不算什么,但最终会成为一个问题,需要采取严厉措施。
在“标题”文本框中按下 ENTER 键将促使编辑器搜索 LUT 中具有类似标题的文件,以帮助您决定是否应该创建新的词条(如果已存在)。
如果您觉得需要重建 LUT,可以删除 c:\\Latin\\Data\\LUT\\ 目录中的所有文件,然后从本文中提取 LUT 文件,或者在没有这些文件的情况下再次启动 LatinProject。它会提示您重建 LUT,点击“是”并准备好耐心等待近 24 小时。您可以通过关闭那个倒计时剩余文件数的小窗体来停止此过程,但请不要在旋转的“忙碌”轮消失之前退出程序。下次启动应用程序时,它将继续重建。如果您只是让它在夜间或您不使用电脑时运行,那并不可怕,否则在重建 LUT 时您的电脑会很迟钝。

您会注意到窗体的下半部分是灰色区域。这是为您输入非标准解决方案保留的空间。看看下面的例子,它显示了前面提到的著名的动词 **fero, ferre**。这是一个特殊的动词,需要在此处输入其形式。选择一个词性后,可能的解决方案列表(拉丁文课本中的形式)取决于词的类型。动词有每个时态的变位,以及其分词的屈折。因此,本质上是第三变位动词的 fero,具有与例如动词 **dico, dicere**(说,或者讲)相同的列表。区别在于 dico, dicere 是规则的,除了标题和定义外不需要特别注意,而 fero, ferre 是特殊的,几乎所有形式都需要输入。要做到这一点,您需要转到下面的每个变位,并选择该时态名称左侧的中间单选按钮。列表顶部的(按字母顺序排列的)Future_Indicative_Active 被设置为“Regular”(左边的单选按钮),因为动词 **fero, ferre** 在除了**现在时主动语态**和**命令式**之外的所有形式上都是规则的。

向下滚动以显示字母顺序排列的现在时形式和现在时命令式。因为 **fero, ferre** 是一个特殊的动词,它的特殊形式必须手动输入。我已经像这样处理了其中大部分例外情况并自己输入了它们,所以您不必这样做,但有很多您在 Cassell's 词典中找不到的新词,您可能想包含它们。使用此编辑器这样做并不困难。如果您看下面的图片,您会看到其余的形式,并注意到 **Present_Active_Imperative**、**Present_Indicative_Active** 和 **Present_Indicative_Passive** 都设置为中间的单选按钮,这意味着它们是**用户定义的**。将鼠标移到这些单选按钮上会改变鼠标光标,以显示这些按钮的含义。它们告诉编辑器该特定形式是**规则**、**用户定义的**还是**无**(不存在)。当您选择“用户定义”时,下面将出现一个带有必需文本框的面板,告诉您在何处输入指定动词正确变位所需的信息。

正如您所见,**fero, ferre** 的三个特殊形式是根据该动词的使用传统输入的。保存文件,在选项菜单列表中选择“查看”,然后进行试运行。让它承受重担(ferat!)
编辑 2019/04/02 - 编辑器出现了一些问题 - 它添加了一个动词时态编辑面板的双重副本,导致其中一个可见而第二个不可见 - 但更不可接受的是,不可见的是被记录的那个,使得无法编辑该特定条目。我记不清几周前是在哪里注意到的,花了二十分钟就修好了。现在看起来好多了。
词典列表
当您寻找 LUT 中找不到的单词时,您可能想查看拼写相似的单词列表,看看能找到什么。或者您可能只是想浏览一下 Cassell's 词典,就像人们常做的那样。要做到这一点,您只需在**练习册**模式下按 F2 来调用“词典列表”窗体。
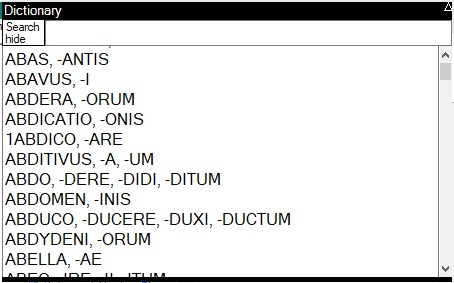
上面显示的表单是您的字典列表。您可以在顶部的文本框中输入您要查找的单词,也可以随时滚动。它非常直接,将鼠标悬停在任何单词上,都会出现一个弹出式定义。单击一个单词,您将召唤该单词的字典定义表单。按 ESC 或单击隐藏按钮,字典列表表单将消失。
一小段代码:
Cassell's 字典中有超过 24000 个单词条目,将它们全部包含在一个列表中将占用大量内存并且加载时间很长。因此,该表单的作用是它有三个简短的单词列表,它们在表单的框架内上下移动,当即将到达末尾时,它会发送到下一个显示相同列表单词的列表框后面,而该列表框仅处于其列表的开头,并且仍然可以向用户显示更多内容,无论他们滚动哪个方向。移动垂直滚动条,它将带您到您放置它的任何位置。所有这些都写在 formDictionaryList.cs 文件中(该文件不幸发生了一起事故,无法在图形编辑器中正确加载……哎呀,我的错)。它被分为三个部分:表单本身(formDictionaryList)、用于三个面板共享在表单内上下滑动以向您显示当前可见单词列表的职责的类(classDictionaryList_DisplayPanel)以及显示屏幕上一个单词的类(classDictionaryList_DisplayBox)。最后一个类包含单词的标题和文件名,因此当您的鼠标光标悬停在上面时,弹出文本可以快速出现,如果您单击它,将出现该单词的字典定义表单。
词典内容搜索
当您想从英语翻译成拉丁语时,字典内容搜索非常方便。最初,当我第一次将 Cassell's 字典的拉丁语/英语部分输入我的计算机时,我并没有 bother typing in the English/Latin half of that dictionary thinking I could just make a search engine that will provide me with just what I needed。搜索拉丁语单词定义的英文内容与拥有英/拉丁语字典不同,但仍然相当不错。在这篇文章的第一个版本中,我还没有来得及编写内容搜索,所以它没有包含在那个版本中。这一次,在容忍了我在使用拼写检查器时发现的 LUT 的所有问题和麻烦,并意识到 Cassell's 字典中的许多单词都找不到 LUT……我花了几个星期(现在已经超过一个月)努力让这个项目恢复健康,并朝着其恢复的良好健康和重大升级迈出了巨大的一步。
所以,我们有了内容搜索。它像所有其他搜索树一样是一个搜索树,但它搜索字典文件的内容,通过这样做,它允许您通过其定义的內容来查找单词。相当直接的概念。这是表单的样子

当您在工作簿模式下使用上下文菜单或在选定单词上按 F2 时,将启动字典内容搜索,并出现上面图像左侧的表单。您可以按字母顺序(如上所示)或按它们在每个文件中出现的次数(频率)重新排序搜索结果。当您将鼠标光标悬停在单词上时,会弹出一个窗口,显示该单词的定义,其中搜索到的单词以粗体突出显示。如果您想查看该单词的字典定义表单,只需单击该单词,其字典表单将出现,其中搜索词以红色突出显示。该搜索引擎与其他的相同,是一个带有链接叶子数据的二叉树。所以,如果您已经见过这些,您不会惊讶地发现它与其他搜索树非常相似。并且能给出不错的结果。不是谷歌……但仍然如此。
图书馆和图书馆搜索
图书馆是历史上各个时代的拉丁语文献的集合。它包括加图和卡图鲁斯等人的演说。尤利乌斯·凯撒的高卢战记、圣经、《君士坦丁献礼》、艾萨克·牛顿的《自然哲学的数学原理》(“Natura nihil agit frustra, & frustra sit per plura quod fieri potest per pauciora.”)以及《联合国人权宣言》。您可以通过在工作簿中使用“文件-加载”菜单选项来浏览图书馆的档案,或者输入一些您正在寻找的关键词,选择它们并按 F4 启动搜索。一旦出现结果列表,您可以选择您想要的条目,它将被加载到工作簿中供您阅读(如果您足够博学且大胆,也可以进行编辑)。请注意,艾萨克是一位天才,他的许多其他作者也是如此,他们的著作至今仍然存在。这些东西是历史,可能不应该被编辑,但如果您愿意,您可以随意编辑。所有这些文件都是通过我制作的网络爬虫从the Latin Library 下载的。我以前从未制作过网络爬虫,不得不慢慢地对其进行调整,但结果还算可以。如果您是历史爱好者,这里有很多东西可以阅读,或者只是看看。
编辑 - 2019/04/02 - 我添加了一个“追加”功能。您现在可以输入或复制文本到工作簿中,(在管理员访问权限下)通过搜索菜单下拉列表中的“追加”选项将库追加。您还可以通过从您指定的目录中选择文件来追加文件列表。当您以这种方式用目录中的新文件追加库时,这些文件将被移动到相应的 c:\\Latin\\Data\\Library\\子目录。如果,在完成将这些文件输入搜索引擎的过程(这可能很慢)后,仍然有文件存在,那是因为那些未被移除的文件已经存在于库中,因此没有被再次添加或覆盖。如果您从库中删除一个文件 - 搜索引擎将期望找到它,当它找不到时可能会导致问题。最好不要删除此项目中的任何文件。如果您想重建任何搜索引擎 - 删除您要重建的 Data 子目录中的所有文件,然后启动 TheLatinProject 再次 - 它会提示您是否应该重建这些文件。
另外 -(对 TheLatinProject 用户是透明的)- 我对库的内容搜索引擎进行了更改。它与其他搜索引擎有些不同,因为我的填字游戏使用它来生成线索,并且当我尝试为像 'ut' 或 'est' 这样的词或几乎出现在库中每个文件中的任何词获取引用时,生成线索的速度非常(痛苦地)慢。之所以花费这么长时间,是因为搜索引擎给了它每个文件的链接列表,有时一次有 1500 个……太多了,太慢了,当您只需要一个随机的并且没有时间在用户耐心等待鼠标点击响应时去挖掘所有文件时。因此,新的库搜索引擎类似于三元树,它有一个二叉树来查找您正在寻找的单词,然后该树中的每个叶子都有另一个二叉树,该二叉树根据该单词在每个文件中的出现频率对包含该单词的文件列表进行排序。然后,该二叉树的每个叶子(“频率树”有自己的记录类型和扩展名为 .fBin 的文件)有两个指向该频率/单词文件列表的链接列表的 Head 和 Tail 的指针。如果没有指向链接列表末尾的“Tail”指针,要从中获取 10 个“随机”文件,就需要加载给定列表中所有文件名,即使这些列表按频率排序,它们仍然可能很长 - 因此,它不是使用列表中顶部的相同 10 个文件名,而是可以将文件名移到列表的末尾并相应地更改 Head 和 Tail 指针。填字游戏很快就会准备好……我厌倦了在 LatinProject 的字典中发现问题,并且真的想继续开发一个街机游戏来分散我对所有这些拉丁语的注意力……以及构建所有这些搜索引擎需要时间……我已经有好几周了,我希望这一切都能结束……它必须结束。完美(可能不是),但仍然相当不错。

拼写检查器
用户和管理员都可以使用拼写检查器选项。它在较大的文件上有点慢,比如库中的文件,但在您自己输入的小文件中,当打印出来时,不超过一两页,它是相当足够的。它将整个文本解析为单词列表,一次处理一个单词(在列表中擦除同一个单词的所有副本),并搜索 LUT 以查找该单词的确切拼写。当它在查找表中找不到该单词时,它会保留一个“错误”列表及其在文本中的位置,然后继续处理下一个单词,直到处理完整个文件。之后,它会重新加载工作簿面板中的 RichTextBox,并突出显示所有找不到的单词。
要使用拼写检查器,您只需按“SpellChecker”菜单选项,它就会运行直到完成。
一小段代码
实现拼写检查器本身并不特别困难,一旦 LUT 运行起来,直到我决定它需要通过 BackgroundWorker 来完成,然后我就有点不知所措(仍然不太会使用线程),直到我真正开始做。LUT_Search() 是作为 BackgroundWorker 运行的。所以,拼写检查器最初只是问 LUT,“这个词在 LUT 中吗”当它调用 LUT_Search() 函数时,主线程在那里等待答案。但是,有了 BackgroundWorker,这就需要一些重新思考。所以 LUT_Search() backgroundworker 完成了它的工作,spellChecker 必须退出,然后在 LUT_Search() 完成时作出反应。要做到这一点,它会响应其全局属性的更改:cSpellChecker_LUTSearchResults,这是由 LUT_Search background worker 在其任务结束时设置的。见下文:
private void BckLUT_Search_RunWorkerCompleted(object sender, RunWorkerCompletedEventArgs e)
{
semLUT_Search.Release();
if (formLUT_Results.instance == null)
{
classLUT_LL_Record_output[] cRetVal = (classLUT_LL_Record_output[])e.Result;
formLUT_Results.instance
= new formLUT_Results((strCurrentPrefix.Length > 0
? strCurrentPrefix + "+"
: "")
+ strCleanWord
+ (strCurrentPostFix.Length > 0
? "+" + strCurrentPostFix
: ""),
cRetVal,
ref word,
ref cLibWordResourceHandler,
ref cOpifex,
ref classXmlLatin.instance);
formLUT_Results.instance.Hide();
}
switch (eCallingFunction)
{
case classEnum.enuLUT_Search_CallingFunction.SpellChecker:
classSpellchecker.instance.cSpellChecker_LUTSearchResults = (classLUT_LL_Record_output[])e.Result;
break;
case classEnum.enuLUT_Search_CallingFunction.DictionaryEditor:
formDictionary_Editor.instance.cHeadingSearchResults = (classLUT_LL_Record_output[])e.Result;
break;
如上所示,Switch(eCallingFunction) 决定了在 LUT-Search 结束时该做什么,这取决于哪个表单调用了它并让它工作。在拼写检查器的情况下,它设置了 cSpellChecker_LUTSearchResults 方法并退出。当您在 Heading 文本框中按 Enter 键时,它会对字典编辑器做类似的事情,以告知您该标题的单词是否已在 LUT 中,然后再创建另一个。
“我说完了,”福雷斯特·甘普说。
工具提示
一个很棒的新增功能是工具提示。这些有用的提示会在您学习如何使用此应用程序时为您提供指导。您只需将鼠标光标在屏幕上的对象上停留几秒钟,就会很快出现一个有用的提示。屏幕上的大多数对象都有多个提示,所以有时最好转到另一个对象然后再回到第一个对象,看看它第二次或第三次会说什么。
一小段代码:
您可能知道,如果您曾经编写过工具提示,它们本身并不允许每个负责的对象有多个提示。如果您还没有阅读我仅在一个月前发布的Sprite Editor 2017 文章,那么您可能会对该应用程序使用的 classToolTip 感兴趣。它利用 AlphaTree(一种搜索树)在 ToolTip 的 PopUp 事件发生时查找给定对象的名称。然后,它从 AlphaTree 的搜索结果中提取信息,并通过重置该对象在 ToolTip 中的提示来选择那里列出的其中一个提示,然后将其显示给用户。它非常简单,每个对象都有一个唯一的名称。许多对象,如字典定义表单上的对象,可以根据用户容忍的数量显示,它们都具有相同的名称。由于每个表单必须有一个与之关联的 ToolTip 对象(如果它有的话),因此每个表单的每个实例都告诉其自己的工具提示识别其自己的表单上的对象,然后该 ToolTip 对象被告知使用应用程序中所有表单通用的 PopUp Event,该事件位于 formLatinProject 中。所有表单上的所有工具提示只有一个 alphatree。alphatree 查看任何给定工具提示已触发弹出事件的对象名称,然后告诉该工具提示在显示到屏幕之前动态设置该对象的提示。
这是 classToolTip 中每个提示的设置函数:
public void Tip_set(string strComponentName, string strTip)
{
if (strComponentName.Length == 0) MessageBox.Show("Component name is blank");
classToolTip_Element cTT_Ele = (classToolTip_Element)cAT_Objects.Search(strComponentName);
if (cTT_Ele != null)
cTT_Ele.Tip = strTip;
else
{
cTT_Ele = new classToolTip_Element();
cTT_Ele.strName = strComponentName;
cTT_Ele.Tip = strTip;
object objTT_Ele = (object)cTT_Ele;
cAT_Objects.Insert(ref objTT_Ele, strComponentName);
}
}
如您所见,组件的名称与 AlphaTree 中的 Tip 字符串相关联。如果名称已经在树中有数据,则新提示将添加到 cTT_ELe.Tip 方法的 Set{} 中,否则将创建一个新元素,赋予新提示,然后通过树的 Insert() 函数运行。classToolTip 的 Get 函数搜索树,并通过相同的 cTT_Ele.Tip 方法返回一个新的提示字符串,该方法跟踪要报告的下一个提示。
您好!
拉丁语可能不是世界上最古老的语言,但它催生了今天所有的罗曼语。它可以在历史中找到,从“Iacta alea est”到“Sic semper Tyrannis”,以及文学中的伟大英雄,如“尼摩船长”、哈利·波特和可怕的贝拉特里克斯。拉丁语无处不在,如果您不想真正学习这门语言,或者您没有时间、精力或意愿,您仍然可以使用此程序进行简单的翻译。
谁知道下次您需要进行一次驱魔仪式时会发生什么!
未来的更新
我差不多已经完成了拉丁语填字游戏生成器,里面有一些有趣的动画。它进展顺利,应该很快会作为一个单独的项目发布。将来还会有更多的测验和游戏,但这将是遥远的未来。现在,exspecta et mox plus erit!
更新
- 2010 年 4 月 16 日:更新了源代码,修复了一些小错误,将侧面板移到底部,并添加了一个新的“弹出”按钮。
- 2010 年 4 月 20 日:移动了侧面板,并添加了“词汇单词”和抽认卡。
- 2019 年 3 月 14 日:对整个项目进行了改造,并添加了新功能
- 2019 年 4 月 2 日:更正了字典文件,添加了新的追加库搜索功能
- 2019 年 6 月 5 日:在玩拉丁语填字游戏时,在 Cassell's 字典和源代码中发现了一些拉丁语错误,并进行了必要的更改
- 2022 年 3 月 23 日:我终于发现了 7-zip 这个东西——将 DataFiles 上传到了 Google Drive——我发现了一些错误并进行了修复。字典 Data 文件(7-zip 文件是较新的,并包含这些更正……如果您还在使用旧文件,您需要升级才能看到这些更改)已在这个压缩文本文件“Changes to Latin Project”中记录了更改。