
C# 搜索引擎:重构以支持 Word、PDF 等格式的搜索
重构 Searcharoo C# 搜索引擎代码,使其更易于扩展,并增加索引/搜索 Microsoft Office 文档、PDF 等文件的能力。

背景
本文是继前三篇 Searcharoo 示例之后的延续。
Searcharoo 版本 1 描述了如何构建一个简单的搜索引擎,该搜索引擎从指定文件夹爬取文件系统,并索引所有 HTML(或其他已知类型)文档。开发了一个基本的设计和对象模型,以支持简单的单字搜索,结果显示在一个基础的查询/结果页面中。
Searcharoo 版本 2 重点在于添加一个“爬虫”来查找要索引的数据,通过跟踪网页链接(而不是仅查看文件系统中的目录列表)。这意味着通过 HTTP 下载文件,解析 HTML 以查找更多链接,并确保我们不会陷入递归循环,因为许多网页会相互引用。本文还讨论了如何将多个搜索词的结果合并到一个“匹配”集合中。
Searcharoo 版本 3 为目录实现了“保存到磁盘”功能,以便在 IIS 应用程序重启后可以重新加载,而无需每次都重新生成。它还爬取了 FRAMESETs,并在索引器中添加了停用词、允许词和词干提取。还修复了 CodeProject 反馈的许多错误。
版本 4 简介
Searcharoo 版本 4 进行了以下更改(通常是受 CodeProject 成员的启发)
- 现在可以索引/搜索 **Word、Powerpoint、PDF** 以及许多其他文件类型,这要归功于 Eyal Post 在 CodeProject 上撰写的精彩文章《在 C# 中使用 IFilter》。这可能是整个项目中最好的一部分 - 但所有功劳都归功于 Eyal 写的精彩文章。
- 它会解析并遵守您的 **robots.txt** 文件(以及它已经支持的 robots META 标签)(cool263)。
- 您可以“标记” HTML 中的区域,以便在索引时忽略它们(xbit45)。
- 初步尝试跟踪隐藏在 Javascript 中的链接(ckohler)。
- 您可以通过命令行应用程序在本地运行爬虫,然后将目录文件上传到您的服务器(如果您服务器上没有安装所有 IFilter 来解析您想索引的文档,这很有用)。
- 代码已显著重构(感谢 mrhassell 和 j105 Rob 的鼓励)。我希望这能让人们更容易阅读/理解和编辑代码以添加他们需要的功能。
需要注意的一些事项:
- 您需要 Visual Studio 2005 来处理此代码。在之前的版本中,我试图将代码保存在少数几个文件中,并进行结构化,以便在 Visual WebDev Express 中轻松打开/运行(甚至第一个版本是在 WebMatrix 中编写的),但它已经变得太大了。据我所知,如果您想尝试一下,仍然可以将代码“塞进”VWD(使用 App_Code 目录和 ZIP 文件中的程序集)...
- 我包含了两位作者的两个项目:Eyal 的 IFilter 代码(来自 CodeProject 和他关于绕过 COM 使用 IFilter 的博客)以及 Mono.GetOptions 代码(处理命令行参数的好方法)。我并不为这些项目归功,而是感谢作者们的辛勤工作以及他们提供的源代码。
- UI(Search.aspx)实际上没有太大变化(除了因重构而导致的类名更改)- 我有一个改进它的想法和建议列表,但这些只能留待以后。
设计与重构
|
支持搜索目录的 Catalog-File-Word 设计(从版本 1!)基本保持不变,但是用于生成目录的类的组织结构进行了彻底的重新安排。 在版本 3 中,所有用于:下载文件、解析 HTML、提取链接、提取单词、添加到目录和保存目录的代码都被塞进了两个类( 请注意, |
|

这使得添加支持 IFilter(或我们可能希望添加的任何其他文档类型)所需的新功能变得困难,而这些文档类型与 HTML 页面不具有相同的属性。
为了“修复”这个设计缺陷,我将所有 HTML 特定代码从 Spider 中移出并放入 HtmlDocument。然后,我将所有“通用”文档属性(标题、长度、URI 等)推入一个超类 Document,HtmlDocument 继承自它。为了让 Spider 能够(多态地)处理任何类型的 Document,我将对象创建代码移到了静态的 DocumentFactory 中,这样就有一个单一的地方可以创建 Document 子类(因此将来容易扩展)。DocumentFactory 使用 HttpResponse 标头中的 MimeType 来决定实例化哪个类。

您可以看到 Spider 和 HtmlDocument 类变得多么整洁(好吧,那是因为我隐藏了 Fields compartment)。为了让您了解代码是如何“移动”的:Spider 从 680 行减少到 420 行,HtmlDocument 从 165 行增加到 450 行,而 Document 基类变成了 135 行 - 总行数增加了(功能也增加了),但重要的是相关函数是如何封装在每个类中的。
新的 Document 类可以构成任何可下载文件类型的基础:它是一个抽象类,因此任何子类必须至少实现 GetResponse() 和 Parse() 方法。
GetResponse()控制类如何从远程服务器的流中获取数据(例如,文本和 HTML 被读入内存,Word/PDF/等被写入临时磁盘位置)并提取文本。Parse()对文件内容执行任何所需的附加工作(例如,删除 HTML 标签、解析链接等)。
第一个“新”类是 TextDocument,它是 HtmlDocument 的一个简化版本:它不处理任何编码(假定为 ASCII),也不解析链接或 HTML,因此两个抽象方法非常简单!从那里开始,构建 FilterDocument 类来包装 IFilter 调用相对容易,IFilter 调用允许读取许多不同的文件类型。
为了展示支持 IFilter 的设计是多么容易扩展,FilterDocument 类继承了几乎所有来自 Document 的内容,并且只需要添加少量代码(如下所示;其中大部分是为了下载二进制数据,外加 Eyal 的 IFilter 示例提供的三行代码)。要点说明:
- BinaryReader 用于读取这些文件的 WebResponse(在 HtmlDocument 中我们使用 StreamReader,它用于文本/编码)。
- 流实际上被保存到磁盘(注意:您需要在 *.config 中指定临时文件夹,并确保您的进程在该位置有写入权限)。
- 保存的文件位置是传递给 IFilter 的参数。
- 保存的文件在方法结束时被删除。
public override void Parse()
{
// no parsing (for now).
}
public override bool GetResponse (System.Net.HttpWebResponse webresponse)
{
System.IO.Stream filestream = webresponse.GetResponseStream();
this.Uri = webresponse.ResponseUri;
string filename = System.IO.Path.Combine(Preferences.DownloadedTempFilePath
, (System.IO.Path.GetFileName(this.Uri.LocalPath)));
this.Title = System.IO.Path.GetFileNameWithoutExtension(filename);
using (System.IO.BinaryReader reader = new System.IO.BinaryReader(filestream))
{ // we must use BinaryReader to avoid corrupting the data
using (System.IO.FileStream iofilestream
= new System.IO.FileStream(filename, System.IO.FileMode.Create))
{ // we must save the stream to disk in order to use IFilter
int BUFFER_SIZE = 1024;
byte[] buf = new byte[BUFFER_SIZE];
int n = reader.Read(buf, 0, BUFFER_SIZE);
while (n > 0)
{
iofilestream.Write(buf, 0, n);
n = reader.Read(buf, 0, BUFFER_SIZE);
}
this.Uri = webresponse.ResponseUri;
this.Length = iofilestream.Length;
iofilestream.Close(); iofilestream.Dispose();
}
reader.Close();
}
try
{
EPocalipse.IFilter.FilterReader ifil
= new EPocalipse.IFilter.FilterReader(filename);
this.All = ifil.ReadToEnd();
ifil.Close();
System.IO.File.Delete(filename); // clean up
} catch {}
}
这样,您就可以在一个简单的类中实现 Word、Excel、Powerpoint、PDF 等的索引和搜索……所有索引和搜索结果显示工作都保持不变!
“其余代码”结构
重构远远超出了 HtmlDocument 类。大约 31 个文件现在被组织到解决方案中的五个(5!)项目中:
| EPocalipse.IFilter | 来自 CodeProject 文章《在 C# 中使用 IFilter》的未修改代码。 |
|---|---|
| Mono.GetOptions | 封装在 Visual Studio 项目文件中,但否则与 Mono 源代码库 相同。 |
| Searcharoo | 所有 Searcharoo 代码 现在都位于此项目中,分为三个文件夹:/Common//Engine//Indexer/ |
| Searcharoo.Indexer | 新的控制台应用程序,允许在本地 PC 上生成目录文件(很可能安装了各种 IFilter),然后将其复制到您的网站进行搜索。 您还可以创建一个计划任务来定期重新索引您的站点(这对于调试也很有用)。 |
| WebApplication | 用于运行 Searcharoo 的 ASPX 文件。 它们已被重命名为: Search.aspxSearchControl.ascxSearchSpider.aspx将这些文件添加到您的网站,合并 web.config 设置(根据需要更新),确保 Searcharoo.DLL 已添加到您的 /bin/ 文件夹,并确保您的网站“用户帐户(ASPNET)”对 Web 根目录有写入权限。 |
新功能和错误修复
I. robots.txt
Searcharoo 的早期版本只查看 HTML Meta 标签中的 robots 指令 - robots.txt 文件被忽略。现在我们可以索引非 HTML 文件了,我们还需要灵活地禁止在某些地方进行搜索。有关该方案如何工作的更多阅读,请参见 robotstxt.org。
Searcharoo.Indexer.RobotsTxt 类有两个主要功能:
- 检查(如果存在)并下载和解析站点上的 robots.txt 文件。
- 为 Spider 提供一个接口,以便根据 robots.txt 规则检查每个 URL。
第一个功能在 RobotsTxt 类的构造函数中实现 - 它会读取文件中的每一行(如果找到),丢弃注释(用井号“#”表示),并构建一个要禁止的“URL 片段”数组。
第二个功能由下面的 Allowed() 方法公开。
public bool Allowed (Uri uri)
{
if (_DenyUrls.Count == 0) return true;
string url = uri.AbsolutePath.ToLower();
foreach (string denyUrlFragment in _DenyUrls)
{
if (url.Length >= denyUrlFragment.Length)
{
if (url.Substring(0, denyUrlFragment.Length) == denyUrlFragment)
{
return false;
} // else not a match
} // else url is shorter than fragment, therefore cannot be a 'match'
}
if (url == "/robots.txt") return false;
// no disallows were found, so allow
return true;
}
robots.txt 文件中没有显式解析 Allowed: 指令 - 所以还有一些工作要做。
忽略 NOSEARCHREGION
在 HtmlDocument.StripHtml() 中,这个新的子句(以及 .config 中的相关设置)将导致索引器跳过 HTML 文件中被 HTML 注释包围的部分,这些注释的(默认)形式为 <!--SEARCHAROONOINDEX-->不索引的文本<!--/SEARCHAROONOINDEX-->。
if (Preferences.IgnoreRegions)
{
string noSearchStartTag = "<!--" + Preferences.IgnoreRegionTagNoIndex +
"-->";
string noSearchEndTag = "<!--/" + Preferences.IgnoreRegionTagNoIndex +
"-->";
string ignoreregex = noSearchStartTag + @"[\s\S]*?" + noSearchEndTag;
System.Text.RegularExpressions.Regex ignores =
new System.Text.RegularExpressions.Regex(ignoreregex
, RegexOptions.IgnoreCase | RegexOptions.Multiline |
RegexOptions.ExplicitCapture);
ignoreless = ignores.Replace(styleless, " ");
// replaces the whole commented region with a space
}
该区域内的链接仍然会被跟踪 - 要停止 Spider 搜索特定链接,请使用 robots.txt。
跟踪 Javascript “链接”
在 HtmlDocument.Parse() 中,以下代码被添加到匹配 anchor 标签的循环中。这是一段非常粗糙的代码,它查找 onclick="" 属性中第一个单引号括起来的字符串(例如,onclick="window.location='top.htm'"),并将其视为链接。
if ("onclick" == submatch.Groups[1].ToString().ToLower())
{ // maybe try to parse some javascript in here
string jscript = submatch.Groups[2].ToString();
// some code here to extract a filename/link to follow from the
// onclick="_____"
int firstApos = jscript.IndexOf("'");
int secondApos = jscript.IndexOf("'", firstApos + 1);
if (secondApos > firstApos)
{
link = jscript.Substring(firstApos + 1, secondApos - firstApos - 1);
}
}
几乎不可能预测 JavaScript 链接的无限组合,但这段代码应该可以为人们提供一个修改的基础,以适应他们自己的站点(最有可能是在复杂的菜单图像滚动或其他绕过常规 href 行为的情况下)。最坏的情况是会提取一个非真实页面的内容并得到 404 错误……
多语言“选项”
文化提示:在上一个版本中,我非常专注于减小索引大小(从而减小目录在磁盘和内存中的大小)。为此,我硬编码了以下 Regex.Replace(word, @"[^a-z0-9,.]", "") 语句,该语句积极地从单词中删除“不可索引”字符。不幸的是,如果您使用的 Searcharoo 语言不是英语,那么这个正则表达式会非常激进,它会删除您的大部分(甚至全部)内容,只留下数字和空格!
我尝试通过将其设置为 .config 中的一个选项来稍微改进其“可用性”
<add key="Searcharoo_AssumeAllWordsAreEnglish" value="true" />该选项控制 Spider 中的这个方法:private void RemovePunctuation(ref string word)
{ // this stuff is a bit 'English-language-centric'
if (Preferences.AssumeAllWordsAreEnglish)
{ // if all words are english, this strict parse to remove all
// punctuation ensures words are reduced to their least
// unique form before indexing
word = System.Text.RegularExpressions.Regex.Replace(word,
@"[^a-z0-9,.]", "",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
}
else
{ // by stripping out this specific list of punctuation only,
// there is potential to leave lots of cruft in the word
// before indexing BUT this will allow any language to be indexed
word = word.Trim
(' ','?','\"',',','\'',';',':','.','(',')','[',']','%','*','$','-');
}
}
将来我希望让 Searcharoo 更加支持语言,但目前至少希望这能使其有可能在非英语环境中运行。
Searcharoo.Indexer.EXE
该控制台应用程序是一个包装器,它执行与 SearchSpider.aspx 完全相同的功能(现在所有代码都已从 ASPX 重构到 Searcharoo 的“common”项目中)。实际的控制台程序代码非常简单:
clip = new CommandLinePreferences();
clip.ProcessArgs(args);
Spider spider = new Spider();
spider.SpiderProgressEvent += new SpiderProgressEventHandler(OnProgressEvent);
Catalog catalog = spider.BuildCatalog(new Uri(Preferences.StartPage));
这几乎与 SearchSpider.aspx 基于 Web 的索引器界面相同。
您将在 Searcharoo.Indexer 项目中找到的其他代码与使用 Mono.GetOptions 解析命令行参数相关,它将下面的带有属性修饰的类转换成下面的良好行为的控制台应用程序,几乎不需要额外的代码。


当它运行时,它实际做的事情是这样的:
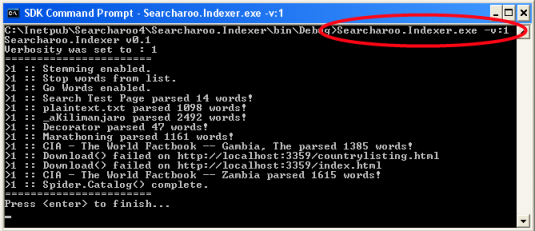
与 SearchSpider.aspx 一样,您将看到输出,因为它在跟踪链接并从您网站的每个页面中索引文本。verbosity 设置允许您控制显示多少“调试”信息:
| -v:0 | 无:完全静默(无控制台输出) |
| -v:1 | 最小:仅显示页面名称和单词计数。 |
| -v:2 | 信息:一些错误信息(例如,403、404)。 |
| -v:3 | 详细:更多异常和其他信息(例如,cookie 错误)。 |
| -v:4 | 非常详细:更多信息(例如,robots Meta 排除)。 |
| -v:5 | 详细:输出每个文档中提取的单词 - 非常详细。 |
注意: exe 有自己的 Searcharoo.Indexer.exe.config 文件,该文件通常包含与您的 web.config 完全相同的设置。如果您网站包含大量 IFilter 文档(Word、Powerpoint、PDF),并且在服务器上运行 SearchSpider.aspx 时遇到错误,因为服务器上未安装 IFilters,那么您可能需要考虑使用 Indexer。目录输出文件(searcharoo.dat 或 .config 文件中指定的任何名称)可以 FTP 到您的服务器,在那里将被加载和搜索!
参考文献
关于 IFilter 及其工作原理(或不工作原理)有很多可以阅读的内容。从《在 C# 中使用 IFilter》及其参考文献开始:通过绕过 COM 在 C# 中使用 IFilter,其中包含对 LoadIFilter、IFilter.org 和 IFilter Explorer 的引用。
dotlucerne 也有文件解析参考。).
Searcharoo 现在有了自己的网站 - searcharoo.net - 在那里您可以尝试一个可用的演示,并可能找到一些不够重大的修复和增强,不足以撰写新的 CodeProject 文章……
总结
希望您发现新功能很有用,本文也切合您的需求。再次感谢 Searcharoo 中使用的其他开源项目作者。