
数值计算:为什么你不该再在代码中使用链表
4.86/5 (73投票s)
在比较链表和 vector 时,大多数编程资源都搞错了。在这里,你可以读懂它们错在哪里,以及为什么(大多数情况下)应该避免使用链表。

我的过失 —— 请在继续阅读前阅读
让我们再看一下标题。它包含一个非常重要的前缀。标题是:
数值计算:为什么你绝对、绝对、绝对不该再在代码中使用链表.
数值计算这个前缀是整篇文章的关键。如果忽略标题中的“数值计算:”部分,可能会被理解为一条普遍建议,即永远不要使用链表,但这不是本文的目的。
本文的重点是解释为什么链表如此不适合数值计算任务。“数值计算”的含义很快就会解释。即便如此,规则总有例外,所以标题不可能百分之百正确。
上面的标题是一种夸张手法。它强烈地强调了一个观点,但又故意说得过头。由于我对此有复杂的感受,显然一些读者也是如此,因此一个可能的标题修改是:
为什么你绝对、绝对、绝对不该用链表进行数值计算
然而,我决定保留原标题,因为修改它可能会更令人困惑。一些读者也评论说他们认为这个标题恰到好处。所以就让它保持原样吧。
那么,我到底为什么要做出这种在 CodeProject 上不寻常的举动,给文章起一个夸张的标题呢?老实说,因为这个信息需要被传播出去。我的印象是,使用链表进行数值计算的性能影响并不广为人知,这就是我决定写这篇文章的原因。
我希望通过这篇“我的过失”的说明 ,你能看透最初的困惑(这全是我的错),并看到核心问题:链表在一系列数值计算问题中的弊端。
目录
- 我的过失 —— 请在继续阅读前阅读
- 引言
- 在现实生活中
- 目录
- 免责声明
- 范围
- 在线资源
- 重要内容来了
- 引用局部性 I
- 代码
- 引用局部性 II
- 魔鬼代言人
- 魔鬼代言人 I - 复制的成本
- 魔鬼代言人 II:使用智能链表进行线性、有序插入
- 魔鬼代言人 III:内存碎片化让 vector 成为大忌
- 魔鬼代言人 IV:使用合并或排序的算法
- 魔鬼代言人 V:在首位插入
- 现在该怎么办?
Java和C#- 结论
- 参考文献
- 历史
引言
本文将解释为什么链表在处理数值计算时不是一个理想的选择。
数值计算 在这里是用来描述对原始数字或POD(Plain Old Data,普通旧数据)数据的处理、排序、插入、删除和简单操作的术语。本文旨在说明为什么链表不适合这些任务,实际上应该避免使用。本文带有鲜明的态度,但有事实和证据支持。欢迎你,甚至鼓励你,去验证这些说法,所有代码和证据都可以在线访问或下载。
本文的意图是通过一些明显的例子来证明一个观点,而不是涵盖其建议的每一个特例和例外。
这些明显的例子对一些读者来说是边缘情况,对另一些读者来说则是常见的编程任务。一些读者认为本文的观点是常识,另一些人则认为这是个笑话,当他们意识到这其实是现实时会感到震惊。我特别建议后者不要轻易否定这篇文章,而是花时间研究它。你可能会有新的见解。
在现实生活中
数值计算任务有时与我下面的例子相似,有时则不同。它们存在于各种领域,如航空电子技术、心脏手术设备、监控技术以及[...]你能想到的任何领域。在继续阅读时要记住的是,本文中使用的数值计算指的是对数字和 POD 数据的存储、检索、删除和排序。没什么奇怪的,非常常见,而且总是那些复制成本低廉的类型。
在我的职业生涯中,我曾几次遇到性能问题,其中一些时间关键区域仅仅因为使用链表进行数值计算而性能不佳。我曾在从实时、嵌入式、内存受限的小型 PowerPC 系统到 x86 PC 应用程序等一系列领域见证过这些与链表相关的性能问题。
这些时候,对于相关人员来说,这完全是个意外。之所以是意外,是因为对他们来说,数学复杂度模型已经证明了链表对于某种用途是一种非常高效的数据结构。它速度慢被认为是不好的,但也可以接受,因为根据同样的数学推理,其他数据结构会更慢。
不幸的是,对于特定的问题集,这些数学模型很可能会误导你。盲目地遵循数据结构和算法的大O 复杂度,可能会让你得出一个完全错误的结论。
大O表示法并不能说明一种(数据结构与算法的组合)与另一种相比表现如何。大O只会告诉你随着 n 的增加,性能会如何下降。因此,从抽象的大O角度来看,比较一个内存密集型的数据结构和另一个缓存友好的数据结构是毫无意义的。 这并不是什么新鲜事,但由于书籍和在线资源很少或从未提及这一点,所以没有多少人知道,或者至少容易忘记。
免责声明
以防我的“我的过失”和“引言”没有涵盖到。让我明确一点:本文并非要否定链表在其他类型用途中的价值,比如当它包含指向其他类型的指针,或者包含大型且复制成本高昂的类型时(是的,POD也可能太大)。
本文并非关于链表特别适用的特定使用模式——因为确实存在几种这样的情况。稍后可以看看评论区,你会发现更多或好或坏的此类案例。本文是一篇观点鲜明的文章,但有确凿的事实支持。它并未全盘否定链表,只在一个特定领域:数值计算。
文中使用了其他类型的容器与链表进行比较。目的不是为了吹捧这些容器,而是为了展示链表的不足之处。甚至会以明显 suboptimal (次优)的方式使用这些容器,但它们的表现仍然远超链表。
本文中的代码示例和容器名称来自C++。std::vector 在Java中被称为 ArrayList,C++中的链表叫做 std::list,在Java中则被称为 LinkedList。
好了,免责声明就到这里,我们开始吧。
范围
你应该使用哪种数据结构?你应该避免哪种数据结构?
想象一下,你必须使用一种数据结构。它没什么特别的,只是一个用来存储原始数字或 POD 数据载体的容器,你会不时地使用它们,有些则稍后使用。
这些项会被间歇性地插入和删除。它们内部会有某种顺序或重要性,并据此排列。有时插入和删除会在开头或结尾,但大多数时候,你需要在中间找到位置然后进行插入或删除。一个绝对的要求是,元素的插入和删除必须高效,最好是 O(1)。
那么,你应该使用哪种数据结构?
在线资源
在这种时候,一个好的建议是查阅书籍和/或在线资源,以确认你最初的直觉是否正确。在这种情况下,你可能记得 vector 通常访问元素很快,但在修改操作上可能较慢,因为插入/删除不在末尾的元素会导致数组中的部分内容移动。当然,你也知道当 vector 满了再插入时会触发重新调整大小。一个新的数组存储将被创建,vector 中的所有项将被复制或移动到新的存储中。这似乎 直观上很慢。
另一方面,链表访问元素可能是缓慢的 O(n),但插入/删除基本上只是交换指针,所以这种 O(1) 操作非常有吸引力。我查阅了几个不同的在线资源,然后做出了决定。就用链表了……
哔哔哔哔哔。错误。一个红色的小矮人跳到我面前,拦住了我。他用不容置疑的语气告诉我,我错了。大错特错。.
www.cplusplus.com/reference/stl/list 关于 std::list[...] 与其他基础标准序列容器(vector 和 deque)相比,list 在容器内任何位置插入、提取和移动元素时通常表现更好,因此在大量使用这些操作的算法(如排序算法)中也表现更佳。
www.cplusplus.com/reference/stl/vector 关于 std::vector[...] vector 在访问元素以及在序列末尾添加或删除元素方面通常是时间效率最高的。[...] 对于涉及在末尾以外的位置插入或删除元素的操作,它们的表现比 deques 和 lists 差。
http://en.wikipedia.org/wiki/Sequence_container_(C%2B%2B)#List Vector 在删除或插入非末尾元素时效率低下。这类操作的复杂度为 O(n)(见大O表示法),而链表为 O(1)。但这被访问速度所抵消——访问 vector 中的随机元素复杂度为 O(1),而普通链表为 O(n),链接树为 O(log n)。
在这个例子中,大多数插入/删除肯定不会在末尾,这一点已经确定。所以这应该意味着链表会比 vector 更有效,对吗? 我决定再查一下 Wikipedia、 Wiki.Answers 和 Wikibooks on Algorithms。它们似乎都同意这个观点,我不明白那个红色小矮人在抱怨什么。
我休息了一下,观看了 Bjarne Stroustrup 的 Going Native 2012 主题演讲。在视频的 01:44 和幻灯片 43 页,发生了一些有趣的事情。我明白了那个红色小矮人试图告诉我的东西。一切都豁然开朗了。当然。我早该知道的。唉。引用局部性。
重要内容来了
链表在插入/删除单个元素时比 vector 快,这并不重要。在稍微大一点的范围内,这完全无关紧要。在元素可以被插入/删除之前,必须找到正确的位置。而找到那个位置与 vector 相比,速度极慢。事实上,如果对 vector 和链表都进行线性搜索,那么 vector 的线性搜索会完完全全、毫无悬念地击败 list。
- vector 上额外的移动和复制开销,在时间上是廉价的。它非常便宜,与遍历链表的巨大开销相比,完全可以忽略不计。
为什么?你可能会问。为什么 vector 的线性搜索效率如此之高,而所谓的哦-那么-慢的链表线性搜索却不行?链表的 O(n) 和 vector 的 O(n) 不是相当吗?
在完美世界里或许是,但在现实中并非如此! 这就是 Wiki.Answers 和其他在线资源出错的地方!因为它们的建议似乎是只要非末端插入/删除很常见,就使用链表。这是糟糕的建议,因为它们似乎完全忽视了 引用局部性的影响。
引用局部性 I
链表的元素位于不连续的内存区域。为了遍历列表,缓存行无法被有效利用。可以说,链表对缓存行不友好,或者说链表最大化了缓存行未命中。不连续的内存会使链表的遍历变慢,因为会大量使用内存读取。
另一方面,vector 的核心在于将数据存储在连续的内存中。插入或删除一个元素可能意味着数据必须移动,但这对于 vector 来说是廉价的。极其廉价 (是的,我喜欢这个词)。vector,凭借其连续的内存布局,最大化了缓存利用率并最小化了缓存行未命中。这造成了天壤之别,而且这个差别是巨大的,我很快就会向你展示。
让我们通过插入随机值来测试这一点。我们将保持数据结构有序,为了找到正确的位置,我们将对 vector 和链表都使用线性搜索。当然,这对 vector 来说是一种愚蠢的使用方式,但我想展示的是,与内存不连续的链表相比,内存连续的 vector 效率有多高。
代码
/* NumbersInVector &randoms is pre created random values that are stored in a
std::vector. This way the same random values can be used for testing and comparing the
vector to the linked-list.
Example:
0, 1, 8, 4, 1 will get sorted to:
0, 1, 1, 4, 8 */
template <typename Container>
void linearInsertion(const NumbersInVector &randoms, Container &container)
{
std::for_each(randoms.begin(), randoms.end(),
[&](const Number &n)
{
auto itr = container.begin();
for (; itr!= container.end(); ++itr)
{
if ((*itr) >= n) { break; }
}
container.insert(itr, n); // sorted insert
});
}
/* Measure time in milliseconds for linear insert in a std container */
template <typename Container>
TimeValue linearInsertPerformance(const NumbersInVector &randoms, Container &container)
{
g2::StopWatch watch;
linearInsertion(std::cref(randoms), container);
auto time = watch.elapsedMs().count();
return time;
}
时间跟踪(我在此处写过的StopWatch)在 C++11 中很简单... 现在只需要创建随机值并记录几组随机数所用的时间。我们从 10 个数字的小集合一直测量到 500,000 个。这将提供一个很好的视角。
void listVsVectorLinearPerformance(size_t nbr_of_randoms)
{
std::uniform_int_distribution distribution(0, nbr_of_randoms);
std::mt19937 engine((unsigned int)time(0)); // Mersenne twister MT19937
auto generator = std::bind(distribution, engine);
NumbersInVector values(nbr_of_randoms);
// Generate n random values and store them
std::for_each(values.begin(), values.end(), [&](Number &n)
{ n = generator();});
NumbersInList list;
TimeValue list_time = linearInsertPerformance(values, list);
NumbersInVector vector;
TimeValue vector_time = linearInsertPerformance(values, vector);
std::cout << list_time << ", " << vector_time << std::endl;
}
对多达 500,000 个值调用此函数,给了我们足够的数据来绘制图表,这恰好显示了 Bjarne Stroustrup 在 Going Native 2012 上告诉我们的内容。对于删除元素,我们得到了类似的曲线,但耗时没有那么密集。我用谷歌文档收集了一些我在 IdeOne.com、一台 x64 Windows7 和一台 Ubuntu Linux 笔记本电脑上做的时间测试结果,供你查看。

你看到底部那片红色的模糊区域了吗? 图表没有显示错误。那片红色模糊区域是 vector 的时间测量值。在链表中进行 500,000 次有序插入耗时约 1 小时 47 分钟。同样数量的元素,vector 耗时 1 分 18 秒。
你可以自己测试。代码已附在本篇文章中。如果想快速测试,可以试试在 pastebin 和在线编译器 IdeOne 上的较小规模(最多15秒)测试,最多40,000个元素:http://ideone.com/62Emz
引用局部性 II
处理器和缓存架构对结果显然有很大影响。在 Linux 操作系统上,可以通过以下命令获取缓存级别信息
grep . /sys/devices/system/cpu/cpu*/cache/index*/*
在我的 x64 四核笔记本电脑上,每个核心对共享 2 个 32KB 的 L1 缓存,缓存行大小为 64 字节。2 个 256KB 的 L2 缓存。所有核心共享一个 3MB 的 L3 缓存。

四核 Intel i5 概念图
我觉得将我的四核电脑与一台更简单、更旧的电脑进行比较会很有趣。使用CPU-Z 免费软件,我从我那台旧的双核 Windows 7 电脑上得知,它有 2 个 32KB 的 L1 缓存和 1 个 2048KB 的 L2 缓存。用较小的数据集进行测试,清楚地显示了缓存的重要性(忽略不同的总线带宽和 CPU 速度)

x86 旧双核 PC

x64 四核 Intel i5
魔鬼代言人
当然,总有例外、特殊情况和反对意见,无论是针对使用 vector 还是不使用链表的建议。如果我们能忽略那些明显不相关的情况,只关注 POD 或数值计算,那么仍然有一些合理的担忧需要解决。
魔鬼代言人 I - 复制的成本
对于 vector 来说,传统上被认为的开销,即复制、移动和调整大小(涉及内存分配和复制),对某些人来说(参考文献:[2]至[7]),是选择链表而非 vector 的充分理由。
上面已经展示了,相对于遍历链表的成本,vector 那些被认为低效的操作实际上是极其廉价的。链表的元素插入是廉价的,但要到达插入位置,必须在不连续的内存中进行一次非常昂贵的遍历。
上面的例子有些极端。整数的例子揭示了链表的另一个缺点。链表需要 3 倍于整数大小的空间来表示一个元素,而 vector 只需要 1 倍。所以对于小数据类型,使用链表就更没有意义了。
然而,如果复制的成本不那么低廉会怎样? 如果修改 vector 的成本增加会怎样?
对于较大的类型,你可能会看到与上面所示相同的行为,但显然时间会有所不同。随着类型大小的增长和变得更加昂贵,最终链表的性能将超过需要大量移动和复制对象的 vector。使用 C++ 移动操作符或许能改变这一点。我没有用移动操作符测试过,所以这得由你自己去尝试了。
随着 POD(普通旧数据)的大小增加,复制成本也会增加。复制和移动的开销会逐渐显现。缓存架构和缓存行的大小也会产生影响。如果 POD 的大小超过缓存行的大小,那么缓存的使用效率将不如用于较小 POD 时那么理想。
在某个 POD 大小时,这种额外的开销甚至会比链表的慢速遍历更耗时。在这一点上,即使是对于本文前面使用的场景,选择 vector 也会比选择链表更差。
下面三张图表展示了这一点。测试分别针对 200、4000 和 10,000 个元素进行。每张图表代表固定数量的元素,其中 POD 的字节大小在增加。
观察链表和 vector 性能曲线的交点。在这个交点上,性能从有利于 vector 转向有利于链表,对于该数量的元素而言。

从图表中可以明显看出,对于相同数量的元素,POD 大小对链表的性能几乎没有影响。而对于 vector,POD 大小则至关重要。复制成本与大小成正比增加。

使用链表的效率受限于内存访问的成本,因此几乎不受 POD 大小的影响。然而,随着项目数量的增加,内存访问的总成本将变得更加昂贵,需要更大的 POD(以字节为单位),链表的性能才能超过 vector。

数据已收集在一个谷歌文档中,并在下载区以 Excel 格式提供。可以在 ideone.com/W9vpT 上快速查看,也可通过下载获取。
魔鬼代言人 II:使用智能链表进行线性、有序插入
对于上面展示的线性、有序插入比较,一个常见的反对意见是,既然链表的线性搜索已知很慢,那么应该保留指向最后插入位置的迭代器。这样,线性搜索平均可以从 O(n) 中获益,变为 O(n/2)。
测试结果显示了缓存架构对连续内存结构性能的巨大影响。第一次测试运行在 ideon.com/XprUU 上进行。ideone 在线编译器的缓存架构未知,并且由于它同时为多个运行提供服务,其缓存利用率很可能是不可预测的,且内存使用量很大。
在这种很可能缓存利用率不足的情况下,智能链表显然是赢家。至少在元素数量达到一定程度之前是这样。直到元素数量达到 6000 个,vector 才追上智能链表。这让我大吃一惊!但当我在一个已知的缓存架构上测试时,这就说得通了。

同样的测试在一台具有已知缓存架构的机器上运行,即我的 x64 笔记本电脑,它有 L1、L2 和 L3 缓存。结果立即显示了缓存利用对连续内存结构的好处。智能链表和 vector 在大约 100 个元素以内保持同步,到 500 个元素时,差异约为 20%,并稳步增加。

如果你看一下它的数据表,你可以看到在 ideone.com/XprUU 和 x64 笔记本电脑上运行时的性能数据。
在其他具有不同缓存架构的计算机上,以及使用其他语言(Java、C# 等)时,这会产生不同的结果。
魔鬼代言人 III:内存碎片化让 vector 成为大忌
对于内存碎片化,或者系统内存可能碎片化的系统,或者对于巨大的 vector,使用 vector 列表可能会更有利。有几种不同的类型可供选择:展开链表(unrolled linked-lists)[12] 或 std::deque 是两种选择。
我没有测试内存碎片化的场景,因为我实在想不出一种方法来轻易地强制内存碎片化。在 32 位双核 PC 和 64 位四核 PC 上,我一次也没有遇到过内存分配异常,即使是在进行 500,000 个项目比较测试的数倍情况下也是如此。
魔鬼代言人 IV:使用合并或排序的算法
是的,这又如何呢?前面指出的在线资源都声称,在合并或排序容器时,链表的性能会超过 vector。很抱歉,对于具有现代缓存架构的计算机来说,情况并非如此。至少在数值计算领域不是这样,而sort不正是最常用于这个领域的吗?
这些资源又一次给了你错误的建议。
从数学角度看,是的,在计算大O复杂度时,这确实有道理。问题在于这些数学模型(至少是我见过的那些)是有缺陷的。至少在根据大O复杂度值来决定使用何种数据结构方面是有缺陷的,因为这还不够好。
计算机缓存、RAM 和内存架构被完全忽略,只考虑了数学上的、简单的复杂度。
为了说明这一点,下面列出了一些简单的排序测试。
void listVsVectorSort(size_t nbr_of_randoms)
{
std::uniform_int_distribution<int> distribution(0, nbr_of_randoms);
std::mt19937 engine((unsigned int)time(0)); // Mersenne twister MT19937
auto generator = std::bind(distribution, engine);
NumbersInVector vector(nbr_of_randoms);
NumbersInList list;
std::for_each(vector.begin(), vector.end(), [&](Number& n)
{ n = generator(); list.push_back(n); } );
TimeValue list_time;
{ // list measure sort
g2::StopWatch watch;
list.sort();
list_time = watch.elapsedUs().count();
}
TimeValue vector_time;
{ // vector measure sort
g2::StopWatch watch;
std::sort(vector.begin(), vector.end());
vector_time = watch.elapsedUs().count();
}
std::cout << nbr_of_randoms << "\t\t, " << list_time << "\t\t, " << vector_time << std::endl;
}
我做的排序测试可以在谷歌电子表格的“sort comparison”标签页上找到。我使用了 std::sort (vector) 对比 std::list::sort。
当然,这是两种不同的算法,它们很可能使用了两种不同的算法,所以这个测试可能有点冒险。无论如何,这可能很有趣,因为两种算法都处于最佳状态,而这正是链表理应胜出的地方。毫不意外,它并没有。
std::sort (vector) 轻松击败了 std::list::sort。完整的代码已附上,可在此处获取:http://ideone.com/tLUeK。
下面的图表显示了从 10 到 1,000 个元素的排序性能。链表的成本总是更高。两者都显示出随着元素数量增加而成本成比例增加,但链表的斜率更陡。与 vector 相比,随着元素数量的增加,链表排序的每个元素的成本显然会更昂贵。
在一台拥有更好 CPU 缓存架构的现代 x64 计算机上进行此测试,会进一步拉大 std::list 和 vector 之间的差距。

随着元素数量的持续增长,这种初步的性能观点并未改变。下图显示了从 10 到 100,000 个元素的情况,但其比例特性与比较 10 到 1,000 个元素时几乎相同。

相应的合并排序测试没有进行。然而,对于合并两个已排序的结构,合并后仍需保持有序,这又涉及到遍历,因此链表再次表现不佳。
魔鬼代言人 V:在首位插入
一位读者在下面的评论中写道:
“[如果]你的插入总是在索引 0 或中间某个位置完成。无论列表变得多大,操作都以常数时间 O(1) 执行。而对于 vector,它是 O(log(n))。数组越大,插入越慢。”另一位读者在我的博客中写道:
“一个非常常见的例子是在列表的开头添加元素。使用 LinkedList 这会是一个相当简单的操作(只是交换一些指针),而 ArrayList [Java版的动态数组] 则需要费力地进行这样的插入(移动整个数组)”
从我自己的文章评论回复中复制粘贴给第一位读者:
“你上面写的内容完全准确。你不是第一个提到这一点的人,虽然这很对,但它也很错。让我解释一下。
你所描述的场景非常可信。事实上,将一个新数据放在旧数据前面,依此类推,也许是数据收集最常见的任务?
在这种情况下,对链表在“索引 0”处进行插入是合理的。但这对 vector 来说不合理。
vector 的默认插入应该通过
push_back来完成。即在增长的方向上插入。这是一个避免移动整个前面部分内容的明显选择。这在 C++ 中非常明确,std::vector[^] 有push_back和insert,但完全没有这个函数:.push_front所以,我们别傻了[天真],对吧?在 vector 上使用
push_back,然后将其与在链表的索引 0处插入进行比较,这可能是程序员会选择的有效选项。你同意吗?vector 上的
push_back不需要为每个新元素都移动所有东西。当 vector 满了需要重新调整大小时的开销仍然存在。“
这三种插入方式的代码和性能比较可以在 http://ideone.com/DDEJF 看到。它比较了常见的链表操作:在“索引 0”处插入,与 std::vector push_back,以及一种幼稚的 std::vector “ push_front
From: http://ideone.com/DDEJF. Times are given in microseconds [us]
elements, list, vector, vector (naive)
10, 3, 6, 1
100, 7, 3, 13
500, 43, 7, 83
1000, 70, 10, 285
2000, 149, 27, 986
10000, 928, 159, 22613
20000, 1578, 284, 97330
40000, 3138, 582, 553636
100000, 7802, 1179, 3555756
Exiting test,. the whole measuring took 4266 milliseconds (4seconds or 0 minutes)

现在该怎么办?
Donald Knuth 曾就优化发表过以下言论:
“我们应该忘记那些微小的效率提升,大约 97% 的时间里:过早优化是万恶之源”.
意思是“过早优化”是指软件开发者在不确定是否需要或是否能显著提升性能的情况下,就对代码进行性能改进。这些改动导致设计不如以前清晰、不正确或难以阅读。代码变得过于复杂或晦涩难懂。这显然是一种反模式。
另一方面,我们有极端过早优化反模式的反面,这被称为过早劣化(Premature Pessimization)。过早劣化是指程序员选择了已知性能比其他技术差的技术。通常这是出于习惯或仅仅是随手而为。
示例 1:总是复制参数,而不是使用 const 引用。
示例 2:使用后置递增 ++ 操作符而不是前置递增 ++。即 value++ 而不是 ++value。
对于原生类型,使用前置或后置递增的成本可以忽略不计,但对于类类型,性能差异可能会产生影响。因此,总是使用 value++ 是一个坏习惯,当用于另一组类型时,实际上会降低性能。因此,总是最好使用前置递增。代码清晰度与后置递增一样,并且性能永远不会更差。
在一个性能优势不大的场景中(比如只有 10 个元素且很少被触及)使用链表,仍然比使用 vector 要差。这是一个你应该远离的坏习惯。
当有其他选择可用时,为什么要使用一个性能差的容器呢?那些选择同样简洁易用,并且对代码清晰度没有影响。
远离过早优化,但要确保不要掉入过早劣化的陷阱!你应该遵循最佳(最优)的解决方案,当然,还有常识,而不是试图优化和混淆代码和设计。像链表这样的次优技术应该避免,因为显然有更好的替代方案。
Java 和 C#
本文发表时收到的一个评论大致是这样的:
这对于 C++ 可能是对的,但对于 Java 或 C# 就没那么重要了。
选择这些语言不是为了速度,而是为了更快的开发时间 [等等,等等].
这或许是对的,但实际上,由于速度问题很可能像影响 C++ 代码一样迅速而猛烈地影响 Java 和 C#,所以这可能仍然很重要。
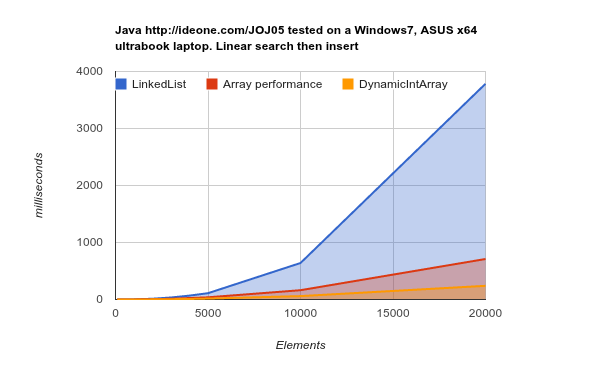
我得到了一位友好的读者的帮助,进行了一次 Java 尝试。在其他读者提出一些修改建议后(参考文献评论),我在 http://ideone.com/JOJ05 上有了一个类似的线性搜索,然后插入的例子。
在 Java 中,与 C++ std::list 等价的被称为 LinkedList。C++ 的动态数组 std::vector 在 Java 中被称为 ArrayList。这些库之间有一个很大的区别,Java 的 LinkedList 和 ArrayList 都只能包含对象。这意味着对于包含 Integer 对象的 ArrayList 来说,连续内存带来的提升会稍小一些。为了在搜索中访问和比较值,需要多一次间接引用,即从引用到值。
为了看看这对 ArrayList 造成了什么差异,我加入了一个 DynamicIntArray,以获得一个真正缓存友好的结构进行比较。DynamicIntArray 使用 int,而不是 Integer 对象。

对于 Java,LinkedList 立即显示出其性能比 ArrayList 差。在 ideone.com 上的测试(http://ideone.com/JOJ05)中,LinkedList 的性能比最好的数组容器慢 1.5 到 3 倍。
在我的 x64 超极本上,缓存架构不同,缓存友好的结构得到了很好的提升。在相同元素范围内,LinkedList 的速度比 DynamicIntArray 慢 1.5 到 15 倍。
Integer 对象导致 ArrayList 变慢
在 ideone.com 上,使用 Integer 对象而不是 int 带来的额外间接引用开销,导致 ArrayList 相对于更快的 DynamicIntArray 大约慢了 30%。 在我的 x64 笔记本上,ArrayList 完成任务的时间大约是 DynamicIntArray 的两倍(200%)(但仍然比在 ideone.com 上快)。
更多针对 Java 的测试已在我的博客上发布,但这里放不下。如果你想阅读更多相关内容(过滤、排序、大O讨论),你可以在这里阅读。
结论
本文并非要否定链表在所有方面的用途。但它确实展示了链表在数值计算领域的缺点。
传统上,甚至在今天,书籍和在线资源 几乎总是完全忽视计算机架构以及这对引用局部性概念的影响。这些资源计算算法的大O效率,并提出一些完全错误的建议,因为内存密集型和缓存友好型结构之间存在巨大差异。 实际上,缓存架构有着巨大的影响。
在上面,我展示了一些对 C++ std::vector 的愚蠢用法。没有使用快速的 [] 操作符或某种树形结构,而是让场景公平进行,以免不必要地贬低 std::list,事实上,有些场景是为了偏袒链表而设计的。结果表明,对于小型的、复制成本低的数据、原始数字或 POD,连续内存结构优于不连续内存结构。与动态数组(如 Vector)相关的新分配、复制、移动等被认为的开销,与访问链表中元素时涉及的非常非常慢的内存读取相比,几乎可以忽略不计。
当涉及数值计算时,vector 或其他连续内存结构应该是默认选择,而不是链表。当然,每个新情况都需要进行分析,并适当地选择数据结构和算法。明智地运用你阅读本文所获得的知识,只有在链表能提供基于数组的结构不易获得的优势时才使用它。
请记住,链表的性能问题通常不是你软件的主要性能瓶颈。但当动态 vector 同样可以轻松使用时,为什么还要使用一个明显次优的数据结构呢?代码可读性相同,而对我来说,将链表用于数值计算是过早劣化的一个明显案例。
当我们从事数值计算时,为什么不利用你对链表缺点的理解,暂时远离链表呢?至少在你确定你需要它之前。你的代码会因此变得更好,性能将持平或更好,有时甚至好得多。
反馈
我建议查看下面的评论,或许可以自己留一条。有很多观点,甚至有一些对我建议的有趣例外,总的来说都是由同样聪明的程序员发表的非常明智的评论。感谢他们,这篇文章在我回应了他们的关切后得到了改版。
最后,一个小小的请求。在我因这篇固执的文章被炮轰之前,为什么不在 ideone.com 或类似网站上运行一些示例代码,证明我错了并教育我呢?我乐于学习 =)
哦,是的。我知道,谢谢你的指出。还有其他容器,但这次我专注于链表与 vector 的对比。
参考文献
- Bjarne Stroustrup 的主题演讲,GoingNative 2012
- cplusplus.com std::list 参考
- cplusplus.com std::vector 参考
- 维基百科关于序列容器
- Wiki.Answers: [链]表与 Vector 的区别
- WikiBooks: 优/缺点 [列表 vs 向量]
- 维基百科:链表 vs. 动态数组
- 维基百科:关于优化和 Donald Knuth
- CodeProject: 预分配数组列表, 作者 Vinod Vijayan
- George Aristy 的博客回应 性能比较:链表 vs. Vector [Java]
- Future Chips: 你是否应该使用链表?
- MSDN 博客:展开链表
- KjellKod.Wordpress 本文的初始博客版本: 现已镜像
- KjellKod.Wordpress 在读者提出改进建议后的 Java 后续文章
历史
- 2012年3月5日 从博客文章再版 http://kjellkod.wordpress.com/2012/02/25/why-you-should-never-ever-ever-use-linked-list-in-your-code-again/
- 2012年3月6日 标题更新 & 澄清初始问题场景... 正在进行“面部”和“迷雾”提升,以消除一些困惑并更好地证明观点。
- 2012年4月19日 迟来的大改版。我的过失、引言、免责声明、结论和总体的“迷雾清理”。这应该能消除许多早期的误解... 代码示例也已添加和更新。
- 2012年8月18-21日 “魔鬼代言人 V” + Java 部分更新以及布局和文本的微小改动。Java部分因改进建议和来自 KjellKod.WordPress 的“博客回复”而更新(Java 大乱斗)