
VexCL: 用于 OpenCL 的向量表达式模板库
4.77/5 (18投票s)
本文档是对VexCL的介绍。VexCL是一个为简化C++ OpenCL开发而创建的向量表达式模板库。
引言
VexCL是OpenCL的向量表达式模板库。它旨在简化基于C++的OpenCL开发。它支持多设备(及多平台)计算。库的源代码可在MIT许可证下公开获取。请参阅Doxygen生成的文档:http://ddemidov.github.com/vexcl。
这是两篇介绍VexCL库的文章中的第一篇。第一部分是对VexCL接口的介绍。而第二部分将VexCL的性能与现有的GPGPU实现进行了比较。比较基于odeint——一个用于常微分方程数值解的现代C++库。
引用OpenCL标准背后组织Khronos group的话来说,“OpenCL是第一个开放的、免版税的跨平台并行编程标准,用于个人电脑、服务器以及手持/嵌入式设备中发现的现代处理器。OpenCL(Open Computing Language)极大地提高了各种应用程序在众多市场类别中的速度和响应能力,从游戏和娱乐到科学和医疗软件。”
OpenCL最薄弱的方面可能是围绕它的工具和库的缺乏,以及开发OpenCL应用程序所需的样板代码量。VexCL库试图解决后者的问题。以一个简单的例子来说明,考虑OpenCL的“hello world”问题:两个向量的相加。下面的代码块包含使用纯OpenCL实现该任务的程序。请注意,这里使用的是官方的C++绑定;C语言版本会更冗长。
#include <iostream>
#include <vector>
#include <string>
#define __CL_ENABLE_EXCEPTIONS
#include <CL/cl.hpp>
// Compute c = a + b.
static const char source[] =
"#if defined(cl_khr_fp64)\n"
"# pragma OPENCL EXTENSION cl_khr_fp64: enable\n"
"#elif defined(cl_amd_fp64)\n"
"# pragma OPENCL EXTENSION cl_amd_fp64: enable\n"
"#else\n"
"# error double precision is not supported\n"
"#endif\n"
"kernel void add(\n"
" uint n,\n"
" global const double *a,\n"
" global const double *b,\n"
" global double *c\n"
" )\n"
"{\n"
" uint i = get_global_id(0);\n"
" if (i < n) {\n"
" c[i] = a[i] + b[i];\n"
" }\n"
"}\n";
int main() {
const unsigned int N = 1 << 20;
try {
// Get list of OpenCL platforms.
std::vector<cl::Platform> platform;
cl::Platform::get(&platform);
if (platform.empty()) {
std::cerr << "OpenCL platforms not found." << std::endl;
return 1;
}
// Get first available GPU device which supports double precision.
cl::Context context;
std::vector<cl::Device> device;
for(auto p = platform.begin(); device.empty() && p != platform.end(); p++) {
std::vector<cl::Device> pldev;
try {
p->getDevices(CL_DEVICE_TYPE_GPU, &pldev);
for(auto d = pldev.begin(); device.empty() && d != pldev.end(); d++) {
if (!d->getInfo<CL_DEVICE_AVAILABLE>()) continue;
std::string ext = d->getInfo<CL_DEVICE_EXTENSIONS>();
if (
ext.find("cl_khr_fp64") == std::string::npos &&
ext.find("cl_amd_fp64") == std::string::npos
) continue;
device.push_back(*d);
context = cl::Context(device);
}
} catch(...) {
device.clear();
}
}
if (device.empty()) {
std::cerr << "GPUs with double precision not found." << std::endl;
return 1;
}
std::cout << device[0].getInfo<CL_DEVICE_NAME>() << std::endl;
// Create command queue.
cl::CommandQueue queue(context, device[0]);
// Compile OpenCL program for found device.
cl::Program program(context, cl::Program::Sources(
1, std::make_pair(source, strlen(source))
));
try {
program.build(device);
} catch (const cl::Error&) {
std::cerr
<< "OpenCL compilation error" << std::endl
<< program.getBuildInfo<CL_PROGRAM_BUILD_LOG>(device[0])
<< std::endl;
return 1;
}
cl::Kernel add = cl::Kernel(program, "add");
// Prepare input data.
std::vector<double> a(N, 1);
std::vector<double> b(N, 2);
std::vector<double> c(N);
// Allocate device buffers and transfer input data to device.
cl::Buffer A(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
a.size() * sizeof(double), a.data());
cl::Buffer B(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
b.size() * sizeof(double), b.data());
cl::Buffer C(context, CL_MEM_READ_WRITE,
c.size() * sizeof(double));
// Set kernel arguments.
add.setArg(0, N);
add.setArg(1, A);
add.setArg(2, B);
add.setArg(3, C);
// Launch kernel on the compute device.
queue.enqueueNDRangeKernel(add, cl::NullRange, N, cl::NullRange);
// Get result back to host.
queue.enqueueReadBuffer(C, CL_TRUE, 0, c.size() * sizeof(double), c.data());
// Should get '3' here.
std::cout << c[42] << std::endl;
} catch (const cl::Error &err) {
std::cerr
<< "OpenCL error: "
<< err.what() << "(" << err.err() << ")"
<< std::endl;
return 1;
}
}
抱歉浪费页面空间,但这正是这个例子的重点。请随意折叠掉这个丑陋的庞然大物,只要注意到它包含133行代码。正如你所看到的,OpenCL程序的基本步骤是选择计算设备、初始化OpenCL上下文、构建OpenCL程序、在选定的设备上分配和初始化内存,以及运行计算内核。VexCL致力于简化(并在可能的情况下消除)这些步骤。下面将介绍一个使用VexCL库解决相同问题的程序。
#include <iostream>
#include <vector>
#include <vexcl/vexcl.hpp>
int main() {
const unsigned int N = 1 << 20;
try {
// Init VexCL context: grab one GPU with double precision.
vex::Context ctx(
vex::Filter::Type(CL_DEVICE_TYPE_GPU) &&
vex::Filter::DoublePrecision &&
vex::Filter::Count(1)
);
if (ctx.queue().empty()) {
std::cerr << "GPUs with double precision not found." << std::endl;
return 1;
}
std::cout << ctx << std::endl;
// Prepare input data.
std::vector<double> a(N, 1);
std::vector<double> b(N, 2);
std::vector<double> c(N);
// Allocate device vectors and transfer input data to device.
vex::vector<double> A(ctx.queue(), a);
vex::vector<double> B(ctx.queue(), b);
vex::vector<double> C(ctx.queue(), N);
// Launch kernel on compute device.
C = A + B;
// Get result back to host.
vex::copy(C, c);
// Should get '3' here.
std::cout << c[42] << std::endl;
} catch (const cl::Error &err) {
std::cerr << "OpenCL error: " << err << std::endl;
return 1;
}
}
这个程序更加简洁(精确地说,是45行),而且几乎和之前一样有效。VexCL使用模板元编程技术,所以大部分工作在编译时完成。VexCL示例唯一可观的开销是内核源的动态构造。但这是一个相对轻量级的操作,并且只在程序中首次遇到一个表达式时执行一次。
VexCL大量使用了C++11特性,因此你的编译器需要足够现代。GCC 4.6及以上版本完全支持。Microsoft Visual C++ 2010在禁用某些功能的情况下也能编译该项目:由于它不支持可变参数模板,所以只启用了单参数内置函数;用户自定义函数则完全不可用。
VexCL接口描述
计算设备选择
VexCL支持多设备计算。您使用的计算设备甚至可以属于不同的OpenCL平台。例如,一个VexCL上下文可以包含AMD和NVIDIA显卡以及Intel CPU。初始化VexCL最简单的方法是使用vex::Context类。它的构造函数接受一个设备过滤器或一个作用于cl::Device的函数对象。定义了几个标准过滤器。计算设备可以按名称、供应商、平台、类型(CPU或GPU)等进行过滤。设备过滤器可以与逻辑运算符组合。例如,以下代码段列出了所有支持双精度计算的可用GPU。
vex::Context ctx(
vex::Filter::Type(CL_DEVICE_TYPE_GPU) && vex::Filter::DoublePrecision
);
std::cout << ctx << std::endl;
如果内置功能不足,用户可以提供自己的过滤器。
VexCL中的几乎任何类都接受cl::CommandQueue的std::vector作为构造函数参数。每个命令队列假定位于一个独立的计算设备上。可以通过调用已初始化的vex::Context类的queue()方法获得此队列列表,或者由用户提供。这使得VexCL可以轻松地集成到已经有自己OpenCL初始化方式的现有项目中。
向量算术
一旦初始化了VexCL上下文,就可以在关联的设备上分配设备向量。VexCL上下文中的每个设备都有自己的向量内存份额和计算工作。VexCL中的向量在构建时给定的所有设备之间进行分区。所有向量使用相同的分区方案。这保证了两个等大小向量的对应元素位于相同的计算设备上,并且计算不需要设备间的数据传输。
在下面的示例中,设备向量x被分配到所有支持双精度计算的设备上。
vex::Context ctx(vex::Filter::DoublePrecision);
const size_t N = 1024 * 1024;
vex::vector<double> x(ctx.queue(), N);
默认分区方案基于在上下文中每个设备上衡量代码a = b + c;的性能,其中a、b和c是驻留在被基准测试设备上的向量。这个测试在第一次分配任何多设备向量时执行。每个设备获得与其性能成比例的向量部分。这是在使用VexCL库的多设备上下文时引入的另一个开销。但这个开销可以通过提供设备权重函数轻松消除。例如,如果你有一个同构的计算设备集合,那么平均分配是最好的选择。为了跳过带宽测试,为每个设备分配相同的权重。
vex::partitioning_scheme<>::set(
[](const cl::Context&, const cl::Device&) { return 1.0; }
);
请注意,你必须在分配任何向量之前设置分区方案。否则,将使用默认分区方案。分区行为只能修改一次。这保证了所有向量都能被一致地分区。
一旦设备向量被分配,就可以使用简单直观的算术表达式来改变它们的状态。对于你使用的每个表达式,都会生成相应的内核,并在第一次在你的程序中遇到时进行编译和自动调用。如果你想将生成的内核的源输出到标准流,请在包含VexCL头文件之前定义VEXCL_SHOW_KERNELS宏。
const size_t n = 1 << 20;
std::vector<float> x(n);
std::generate(x.begin(), x.end(), [](){ return (float)rand() / RAND_MAX; });
vex::vector<float> X(ctx.queue(), x);
vex::vector<float> Y(ctx.queue(), n);
vex::vector<float> Z(ctx.queue(), n);
Y = 42;
Z = sqrt(2 * X) + pow(cos(Y), 2.0);
计算工作在设备之间分配。VexCL支持的向量表达式是天生并行的,所以如果你有两个或更多的计算设备,你应该会为你的代码获得线性加速。你可以将结果复制回主机,或者使用vex::vector::operator[]直接读写向量元素。尽管后一种技术非常低效,只能用于调试目的。
copy(Z, x);
assert(x[42] == Z[42]);
规约
将向量规约到单个值是一个常用的操作。你使用规约来获得向量元素的总和,或者找到向量中的最大/最小值。类模板vex::Reductor允许对任意表达式进行规约。支持的规约类型为SUM、MIN和MAX。以下是如何获得表达式中所有元素的总和。
vex::vector<double> x(ctx.queue(), 4096);
vex::vector<double> y(ctx.queue(), 4096);
// ...
vex::Reductor<double,vex::SUM> sum(ctx.queue());
// Sum:
std::cout << sum(x) << std::endl;
// Inner product:
std::cout << sum(x * y) << std::endl;
// How many elements in x are greater than 1?
std::cout << sum(x > 1) << std::endl;
另一个例子是找到一组二维点到原点的最大距离。点坐标存储在x和y向量中。
vex::Reductor<double, vex::MAX> max(ctx.queue());
std::cout << max(sqrt(pow(x, 2.0) + pow(y, 2.0))) << std::endl;
请注意,vex::Reductor实例在构造时会在其队列列表中的每个设备上分配一个小的临时缓冲区,因此出于性能考虑,它应该只被分配一次并在整个应用程序生命周期中使用。
用户自定义函数
在VexCL中可以轻松定义要在内核中使用的简单函数。你只需要定义函数体、返回类型和参数类型。之后,该函数就可以在向量表达式中使用,就像内置函数一样。请注意,函数体必须定义在全局作用域,并且属于extern const char[]类型。这些要求是为了能够将函数体字符串用作模板参数。以下示例计算位于第一象限的二维点的数量。
extern const char between_body[] = "return prm1 <= prm2 && prm2 <= prm3;";
UserFunction<between_body, bool(double, double, double)> between;
// Number of points in first quadrant
size_t points_in_1q(
const vex::Reductor<size_t, vex::SUM> &sum,
const vex::vector<double> &x,
const vex::vector<double> &y
)
{
return sum(between(0.0, atan2(y, x), M_PI/2));
}
任何有效的向量表达式都可以用作函数参数。请注意,函数体中的参数名称始终是prm1、prm2等。函数体不必是一行代码:任何有效的OpenCL运算符序列都可以。由于OpenCL内核是在运行时编译的,所以直到程序中第一次遇到使用该函数的表达式,你才会得到关于该函数的编译错误。
自定义函数不仅可以引入新功能,还可以提高性能。有关更多解释,请参阅内核生成部分。
稀疏矩阵-向量乘法和卷积
线性代数中最常见的运算之一是矩阵-向量乘法。类vex::SpMat保存稀疏矩阵的表示,该矩阵跨越多个设备。其构造函数接受以CRS格式存储的稀疏矩阵。在计算设备上,矩阵以混合ELL-CRS格式存储。在下面的示例中,设备矩阵从主机向量构建,并用于计算最大残差值。
// Construct the matrix.
vex::SpMat<double> A(ctx.queue(), n, row.data(), col.data(), val.data());
// Compute residual. r, f, and u are device vectors.
r = f - A * u;
double res = max(fabs(r));
有关实现共轭梯度法求解线性方程组的示例,请参阅文件examples/cg.cpp。
另一个常用的操作是向量与模板的卷积。VexCL支持三种模板:简单模板、广义模板和用户自定义模板运算符。简单模板基于一维数组,直接使用。广义模板基于二维密集矩阵,与一个参数的内置或用户自定义函数一起使用。要定义模板运算符,用户必须提供其维度(宽度和中心)以及主体字符串。
简单模板卷积在许多情况下非常有用。例如,它允许我们对设备向量应用移动平均滤波器。你只需要用std::vector、一对迭代器或初始化列表来构造一个vex::stencil对象。你还需要指定模板中心的职位。
// Moving average with 5-points window.
std::vector<double> sdata(5, 0.2);
vex::stencil<double> s(ctx.queue(), sdata, sdata.size() / 2);
// Convolve x with s. x and y are device vectors.
y = x * s;
广义模板基本上是一个小的密集系数矩阵。它与一个参数的内置或用户自定义函数结合使用。例如,下面的非线性向量算子
y[i] = sin(x[i-1] - x[i]) + sin(x[i] - x[i+1]);
可以实现为
const uint rows = 2;
const uint cols = 3;
const uint center = 1;
vex::gstencil<double> S(ctx.queue(), rows, cols, center, {
1, -1, 0, // stencil coefficients for first sin argument.
0, 1, -1 // stencil coefficients for second sin argument.
});
y = sin(x * S);
可以与用户自定义函数结合使用。为了实现以下算子
y[i] = x[i] + pow(x[i-1] + x[i+1], 3);
你会写
extern const char pow3_body[] = "return pow(prm1, 3);";
UserFunction<pow3_body, double(double)> pow3;
void pow3_oper(const vex::vector<double> &x, vex::vector<double> &y) {
gstencil<double> S(ctx.queue(), 1, 3, 1, {1, 0, 1});
y = x + pow3(x * S);
}
用户自定义模板运算符允许定义高效的任意模板。你需要指定模板维度,并为返回模板局部值的函数提供主体。让我们用模板运算符来实现上一个例子。请注意,在主体中,模板所应用于向量的字符串元素用X[i]表示,其中i是相对于模板中心的。
// Defined at global scope:
extern const char pow3_op_body[] =
"double t = X[-1] + X[1];\n"
"return X[0] + t * t * t;"
// Define stencil operator:
const uint width = 3;
const uint center = 1;
vex::StencilOperator<double, width, center, pow3_op_body> pow3_op(ctx.queue());
// Apply stencil operator to device vector x:
y = pow3_op(x);
后一种实现更有效,因为它使用了单一内核启动。你看,模板卷积和稀疏矩阵-向量乘法一样,都是一个两步操作。首先,必须在相邻的计算设备之间交换卤素点。其次,必须启动OpenCL内核。因此,模板卷积只允许在加法表达式中使用。内部,这些表达式是分开计算的。首先,计算除模板卷积外的所有项,并将结果存储到结果向量中。其次,计算模板卷积并将其添加到结果中。所以表达式y = x + pow3(x * S);在功能上等同于
y = x; // First kernel launch.
y += pow3(x * S); // Second kernel launch.
内核生成
你在代码中使用的每个表达式都会生成一个OpenCL内核。例如,以下表达式
x = 2 * y - sin(z);
会触发此内核的生成、编译和启动。
#if defined(cl_khr_fp64)
# pragma OPENCL EXTENSION cl_khr_fp64: enable
#elif defined(cl_amd_fp64)
# pragma OPENCL EXTENSION cl_amd_fp64: enable
#endif
kernel void Sub_Mul_cvsinv(
ulong n,
global double *res,
int prmll,
global double *prmlr,
global double *prmr1
)
{
size_t i = get_global_id(0);
size_t grid_size = get_num_groups(0) * get_local_size(0);
while (i < n) {
res[i] = ((prmll * prmlr[i]) - sin(prmr1[i]));
i += grid_size;
}
}
每个内核只生成和编译一次(每个OpenCL上下文),在程序中第一次遇到它时。上面示例中的表达式对应于下图中的表达式树。

如你所见,表达式树的类型取决于其操作和操作数的类型。所以表达式2.0 * y - sin(z)会产生一个相似但不同的树,因为常量类型在这里是double而不是int。如果你想限制生成的内核数量,应该牢记这一点。另一件需要记住的事情是,无法判断树的几个叶子节点是否引用了相同的数据。考虑《用户自定义函数》部分中的示例,我们不得不计算第一象限中的点。我们可以不使用自定义函数来实现这个示例。
return sum(atan2(y, x) >= 0.0 && atan2(y, x) <= M_PI/2);
生成的内核将读取x和y向量中的数据两次,从性能角度来看这不是很好。引入between函数可以使全局内存读取次数减半!
自定义内核
正如Kozma Prutkov反复说的,“一个人不能拥抱无法拥抱的东西”。因此,为了可用,VexCL必须支持自定义内核。编写OpenCL内核时,你必须记住VexCL向量分布在上下文中所有可用的计算设备上。vex::vector::operator()返回一个cl::Buffer对象,该对象存储给定设备上的向量的一部分。对于内核作者有用的其他方法是vex::vector::part_size()和vex::vector::part_start()。前者返回给定设备上的向量分区大小;后者返回给定设备上的第一个向量元素的数量。因此,x.part_start(d+1) - x.part_start(d)始终等于x.part_size(d)。如果结果依赖于邻近点,你必须记住这些点可能位于不同的计算设备上。在这种情况下,必须手动安排这些卤素点的交换。
下面的例子为上下文中的每个设备构建并启动一个自定义内核。
// Use environment variables to control device selection.
vex::Context ctx( vex::Filter::Env );
const size_t n = 1 << 20;
vex::vector<float> x(ctx.queue(), n);
std::vector<cl::Kernel> kernel(ctx.size());
for(uint d = 0; d < ctx.size(); d++) {
cl::Program program = vex::build_sources(ctx.context(d), std::string(
"kernel void dummy(ulong size, global float *x)\n"
"{\n"
" size_t i = get_global_id(0);\n"
" if (i < size) x[i] = 4.2;\n"
"}\n"
));
kernel[d] = cl::Kernel(program, "dummy");
}
for(uint d = 0; d < ctx.size(); d++) {
kernel[d].setArg(0, static_cast<cl_ulong>(x.part_size());
kernel[d].setArg(1, x(d));
ctx.queue(d).enqueueNDRangeKernel(kernel[d], cl::NullRange, n, cl::NullRange);
}
在极少数情况下,如果你的内核包含语法错误,错误描述将输出到标准错误流,并抛出一个cl::Error异常。顺便说一句,VexCL重载了输出到流的运算符,以便为cl::Error对象提供更易读的错误消息。
可扩展性
本节展示了该库相对于计算设备数量的可扩展性。通过在多块Nvidia Tesla C2070卡上运行大量的测试内核,测量了有效性能(GFLOPS)和带宽(GB/sec)。还测试了添加第四块性能稍逊的设备(Intel Core i7)的效果。所示结果是20次运行的平均值。实验细节可在文件examples/benchmark.cpp中找到。基本上,测量了以下代码的性能。
// Vector arithmetic
a += b + c * d;
// Reduction
double s = sum(a * b);
// Stencil convolution
y = x * s;
// SpMV
y += A * x;

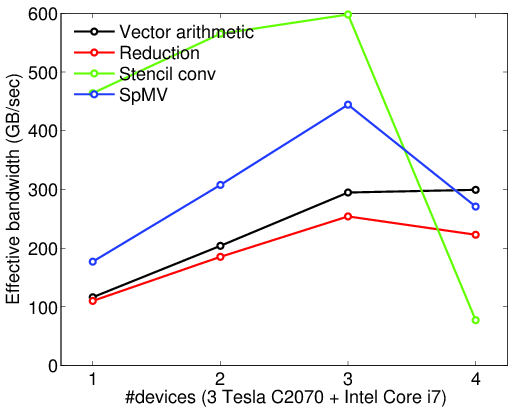
正如你所看到的,VexCL在添加计算设备时几乎呈线性扩展。请注意,模板卷积操作的性能和带宽远高于其他基元。这是因为该算法使用了速度快得多的本地(共享)内存,并且有效性能和带宽的公式没有考虑到这一点。另一件值得注意的事情是,在VexCL上下文中添加Intel CPU后,整体性能有所下降。唯一从这次添加中获得速度提升的原语是向量算术。这可能是因为向量算术的性能被用作问题分区的基础。
结论
VexCL允许编写简洁易读的代码,而不会牺牲太多性能。在下一篇文章中,headmyshoulder将讨论将VexCL集成到odeint中——一个用于常微分方程数值解的现代C++库。odeint现在支持GPU计算,通过使用Thrust库支持CUDA,通过使用VexCL支持OpenCL。这使得我们能够比较这两种解决方案的性能。
致谢
这项工作得到了俄罗斯基础科学基金会(RFBR)项目编号12-01-00033和12-07-0007的部分支持。