
C# 中的多线程 Web 抓取
4.92/5 (110投票s)
从初级到高级 - 多线程网络抓取,包含 WebBrowser、WebClient、HttpWebRequest/HttpWebResponse、Regex、BackgroundWorker 示例。
建议已采纳。请提出建议、投票、评论以改进本文。

简介
*所有代码示例仅供学习目的。不鼓励任何滥用行为。
* 大部分示例的源代码项目已添加。
网络抓取涉及从网页获取感兴趣的信息。我尝试制作一个分步指南,从使用 WebBrowser 进行网络抓取的基础知识,到一些高级主题,例如通过 HTTPWebRequest 执行登录和维护会话。这是本文的第一个版本,可能存在错误/疏漏。我欢迎所有建议,并会尽快采纳。
我采用了基于教程的循序渐进方法,网络抓取工作从教程的第一行开始。我采用了示例/任务导向的方法来保持趣味性,2-3 个示例后会跟着 2-3 个任务,以保持学习者的积极性。我假设用户对 C# 和 Visual Studio 编程环境有基本的了解。
目录
我涵盖的内容包括:
- WebBrowser
- WebBrowser 下载事件
- 导航到 Olx 的第一页
- 访问所有显示的广告在 ...
- Yahoo 登录表单填充与提交
- 修改 WebBrowser 头部
- 保存网页所有图片
- 使用 API 解决验证码 ...
- 为 WebBrowser 设置代理
- 正则表达式
- 在文本中查找数字
- 正则表达式运算符
- 在句子中查找单词
- 格式为 ddd-ddddd 的数字
- 在文本中查找电子邮件地址
- 在文本中查找 IP 地址
- 正则表达式实用程序
- WebClient
- 以字符串形式下载 HTML
- 下载并保存图片
- WebClient 的阻塞模式
- WebClient 的非阻塞模式
- 读/写流
- WebClient 的查询字符串
- 上传文件到 URL
- 关于 WebClient 的更多信息 ...
- BackgroundWorker
- 运行耗时函数
- 工作完成报告
- 更新进度
- 停止工作器
- 多线程应用程序下载图片 ...
- HttpWebRequest/HttpWebResponse
- HTTP 请求头
- 会话如何工作
- HTTP 响应头
- Mozilla Live HTTP Headers
- 用户代理字符串
- 获取 Facebook 登录页面 HTML ...
- 通过 HTTP 请求执行登录
- 自定义 HTTPWebRequest 进行登录...
- 理解 HTML 表单的 GET/POST
- 获取表单隐藏字段
- 准备 HTTP POST 数据
- 通过 HTTP 上传图片到 Facebook ...
以及许多相关的任务,以保持学习者探索创新的积极性。
WebBrowser 控件
顶部此控件提供一个内置的全功能浏览器作为控件。它使用户能够在您的表单内导航网页。
示例:WebBrowser 下载事件
将 WebBrowser 控件添加到表单。将其停靠在父容器中。
双击 WebBrowser 控件以添加 WebDocumentCompleted 事件。
Navigate 函数用于导航到给定地址。
文档加载完成后会触发 Document completed 事件。
现在运行程序。
有许多解决方案可以解决上述问题,例如计算 i-frame,然后计算 Document Completed 事件触发的次数。这非常复杂,最简单的方法是维护历史记录。
-
向程序添加一个
List<string>hist,并修改 Document Completed 事件如下:



示例:导航到 OLX 的第一个广告页面
在制作任何网络抓取工具、点击机器人等之前,了解该网站的布局是必要的。之后,以下内容很重要:
查找感兴趣的字段
-
缩小感兴趣的文本范围
查找感兴趣标签附近的带 ID 的标签
首先安装 Mozilla Firefox 15。导航到 http://www.olx.com/cars-cat-378
右键单击第一个广告链接,然后单击“检查元素”。
您将看到如下图所示的内容:
要访问第一个广告,我们需要其链接地址。
上图中突出显示的锚标签没有 id,因此如果我们使用
GetElementByTag(“a”)函数,我们将获得所有锚标签的列表,其中包括 olx 其他页面、帮助、联系我们等的链接。(所以这不是一个好的选择)因此,尝试找到最近的带有 ID 的标签。
在标签栏上,不断向左选择标签,直到找到带有 ID 的标签。
一旦您到达 id 为 "the-list" 的 div 标签,您将看到它是所有广告链接的容器。
因此,div#the-list 中的所有锚标签都是指向各个广告页面的链接。
以下是程序化获取它的代码。
我们想导航到第一个广告页面。



//Getting AddsBlock HtmlElement
HtmlElement he = webBrowser1.Document.GetElementById("the-list");
//Getting Collection of all the Anchor Tags in AddsBlock
HtmlElementCollection hec = he.GetElementsByTagName("a");
//Naviagting to 1st Add Page
//obtainign href value to get the page address
webBrowser1.Navigate(hec[0].GetAttribute("href"));
示例:导航到所有显示的广告
http://www.olx.com/cars-cat-378
您已经了解了如何导航到第一个广告。
要导航到所有页面,我们需要将所有广告链接存储在一个列表中,以便稍后可以访问这些广告。
为此,请创建一个列表来存储所有广告链接的 href 值。
修改 Document Completed 事件,将所有链接添加到 URL。
我们为什么要检查 href != "http://www.olx.com/cars-cat-378"?因为每个单独的广告块都包含指向显示它的页面的链接(这意味着要制作准确的抓取工具,您需要很好地理解所有内容以及它在哪里)。
所有链接都存储在 urls 列表中,现在我们需要让浏览器自动导航到所有这些链接。
List<string>
urls = new List<string>();
HtmlElement he = webBrowser1.Document.GetElementById("the-list");
HtmlElementCollection hec = he.GetElementsByTagName("a");
foreach(HtmlElement a in hec)
{
string href = a.GetAttribute("href");
if(href != "http://www.olx.com/cars-cat-378")
{
if(!urls.Contains(href))
urls.Add(href);
}
}
if(urls.Count > 0)
{
string u = urls[0];
urls.RemoveAt(0);
webBrowser1.Navigate(u);
this.Text = "Links Remaining" + urls.Count.ToString();
}
else
{ MessageBox.Show("Complete"); }
任务 1:修改上述代码,使其浏览下一页。
例如:http://www.olx.com/cars-cat-378-p-2
http://www.olx.com/cars-cat-378-p-3
http://www.olx.com/cars-cat-378-p-4 等
任务 2:在每个广告页面上,抓取所有者姓名和电话号码(如果提供)。
任务 3:制作应用程序,从给定的 olx 类别 URL 抓取指定数量的单个广告。
示例:Yahoo 登录表单填充与提交
检查用户名和密码文本框的 ID(使用“检查元素”)。
在应用程序中创建一个按钮点击事件。
对于登录按钮点击(实际上我们需要提交表单,所以找到登录表单 ID。获取其元素,并调用其提交函数)。
htmlElement hu = webBrowser1.Document.GetElementById("username");
hu.Focus();
hu.SetAttribute("Value","userName");
HtmlElement hp = webBrowser1.Document.GetElementById("passwd");
hp.Focus();
hp.SetAttribute("Value", "password");
HtmlElement hf = webBrowser1.Document.GetElementById("login_form");
hf.InvokeMember("submit");
任务 1:找出如何选择下拉列表、复选框、单选按钮的值。您可以尝试填写 Yahoo 注册页面。
任务 2:点击超链接。
示例:在 WebBrowser 控件中,我们可以添加/更改标头。最重要的标头是 Referrer 和 User-Agent。
User Agent 标头告诉 Web 服务器发送请求的浏览器。
Referrer 告诉 Web 服务器,用户是从哪个网页发送到当前网页的。
更改 User-Agent 标头
webBrowser1.Navigate("url", "_blank", null, "Referrer: sample user agent");
任务 1:浏览到 webBrowser1.Navigate("logme.mobi");
查看 HTTP 标头,然后尝试修改您的 User-Agent 和 Referrer。
您可以在 http://www.useragentstring.com/pages/useragentstring.php 获取完整的用户代理字符串列表。任务 2:在 C# 应用程序中访问 www.google.com,使用一些 Apple、Linux 浏览器用户代理。获取 Google 搜索结果的非 JavaScript 页面。
示例:保存网页的所有图片
添加对 using mshtml; 的引用;
您可以将 Yahoo 注册页面用于练习
IHTMLDocument2 doc = (IHTMLDocument2)webBrowser1.Document.DomDocument;
IHTMLControlRange imgRange = (IHTMLControlRange)((HTMLBody)doc.body).createControlRange();
foreach (IHTMLImgElement img in doc.images) {
imgRange.add((IHTMLControlElement)img);
imgRange.execCommand("Copy", false, null);
try{
using(Bitmap bmp = (Bitmap)Clipboard.GetDataObject().GetData(DataFormats.Bitmap))
bmp.Save(img.nameProp + ".jpg");
}
catch (System.Exception ex)
{
MessageBox.Show(ex.Message);
}
}
上述代码将把网页的所有图片保存在当前目录中。
任务:在验证码名称中查找模式,修改代码以仅保存验证码。
示例:使用 DeathByCaptcha API 解决验证码。
添加对 using DeathByCaptcha; 的引用;
以下代码解决了验证码。
研究如何报告 Captcha.Text 错误。
Client client = (Client)new SocketClient(capUser, capPwd);
try
{
Captcha captcha = client.Decode(path + capName, 50);
if (null != captcha)
{
//Captcha Solved
MessageBox.Show(captcha.Text);
}
else
{
//Captcha Not Solved Show Error Message
}
}
catch(DeathByCaptcha.Exception ex) {
MessageBox.Show(ex.Message);
}
示例:为 WebBrowser 设置代理。
using Microsoft.Win32;
RegistryKey reg = Registry.CurrentUser.OpenSubKey(
"Software\\Microsoft\\Windows\\CurrentVersion\\InternetSettings", true);
registry.SetValue("ProxyEnable", 1);
registry.SetValue("ProxyServer", "192.168.1.1:9876");
正则表达式
顶部一种简洁灵活的文本字符串匹配方式。
在 C# 中,Regex、Match、MatchCollection 类用于查找字符串模式。这些类位于以下命名空间中。
using System.Text.RegularExpressions;
示例 1:在文本中查找数字。

以下是正则表达式运算符:
|
[xyz] |
字符集。匹配所包含的任何一个字符。例如,"[abc]" 匹配 "plain" 中的 "a"。 |
|
[^xyz] |
负字符集。匹配未包含的任何字符。例如,"[^abc]" 匹配 "plain" 中的 "p"。 |
|
[a-z] |
字符范围。匹配指定范围内的任何字符。例如,"[a-z]" 匹配 "a" 到 "z" 范围内的任何小写字母字符。 |
|
[^m-z] |
负范围字符。匹配指定范围之外的任何字符。例如,"[m-z]" 匹配不在 "m" 到 "z" 范围内的任何字符。 |
|
* |
匹配前面一个字符零次或多次。例如,"zo*" 匹配 "z" 或 "zoo"。 |
|
+ |
匹配前面一个字符一次或多次。例如,"zo+" 匹配 "zoo" 但不匹配 "z"。 |
|
? |
匹配前面一个字符零次或一次。例如,"a?ve?" 匹配 "never" 中的 "ve"。 |
|
. |
匹配除换行符以外的任何单个字符。 |
示例 2:在句子中查找单词。

句子的最后一个词不在匹配列表中,因为它后面没有空格。
|
{n} |
n 是一个非负整数。精确匹配 n 次。例如,"o{2}" 不匹配 "Bob" 中的 "o",但匹配 "foooood" 中的前两个 "o"。 |
|
{n,} |
n 是一个非负整数。匹配至少 n 次。例如,"o{2,}" 不匹配 "Bob" 中的 "o",但匹配 "foooood" 中的所有 "o"。"o{1,}" 等价于 "o+"。"o{0,}" 等价于 "o*"。 |
|
{n,m} |
m 和 n 是非负整数。匹配至少 n 次且最多 m 次。例如,"o{1,3}" 匹配 "fooooood" 中的前三个 "o"。"o{0,1}" 等价于 "o?"。 |
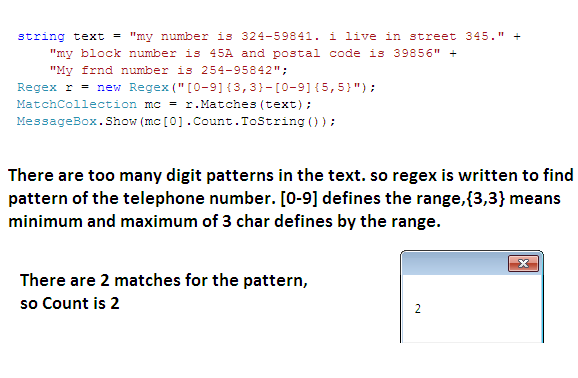
示例:匹配格式为 ddd-ddddd 的电话号码。其中 d 表示数字。
示例:在文本中查找电子邮件。
一个普通电子邮件的正则表达式可以是:
"\b[A-Za-z0-9_]+@[A-Za-z0-9_]+\.[A-Za-z0-9]{2,4}\b"
其中 \b 定义一个空格;[A-Za-z0-9_]+ 定义用户名,其中可能包含 A-Z、0-9、a-z 和 _(下划线)的重复;@[A-Za-z0-9_]+ 定义托管公司名称,例如 yahoo;\. 定义点(.);[A-Za-z0-9]{2,4} 匹配顶级域名,如 com、net、edu 等。
示例:在文本中查找 IP 地址的正则表达式。
查找 IP 地址的一个基本正则表达式可以是 "\b[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+\b";但这也会匹配 1925.68541.268.1 这样的内容(这意味着任意数量的数字带三个点——这不是有效的 IP 地址)。
另一个可以是:
"\b[0-9]{1-3}\.[0-9]{1-3}\.[0-9]{1-3}\.[0-9]{1-3}\b"
现在这不会匹配带有超过 3 个数字和点的字符串。但它可能会匹配 999.999.999.999,这又是一个无效地址。
所以正则表达式可以像下面这样复杂:
"b(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\."+ "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\."+"(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\."+"(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b"
复杂度和准确性之间总是存在权衡。因此,根据您的输入文本,您可以赋予其中一个维度比另一个维度更重要的地位。
任务 1:HTML 的锚标签在抓取中至关重要。链接的值放在 href 属性中,如下所示。编写正则表达式来查找 href 值。

答案 1:正则表达式可以很简单:
Regex r = new Regex("href=\"[^\"]+\"");
\" 用于定义双引号("),因为双引号是特殊字符,所以需要用斜杠(\)来表示。之后,您可以从匹配值中删除 href=" 和 "。
任务 2:Pinterest.com 上的 Pin 的网址格式如下:
"/pin/125678645821924781/" "/pin/63894888434527857/"
"/pin/25825397833321410/"编写正则表达式从 www.pinterest.com 的 HTML 中查找 pin 地址。
任务 3:广告的缩略图显示在 http://www.olx.com/cars-cat-378

编写一个正则表达式来匹配图片链接。
任务 4:制作以下实用程序。

加载输入文本文件
按下加载按钮
编写正则表达式
按下执行
所有匹配项都显示在多行文本框中,每行一个匹配值。
WebClient
顶部 此类位于 using System.Net; 下。它提供了各种从互联网下载文件的函数。它可以用来下载网页的 HTML 源代码作为字符串,或者作为文件。它支持将文件下载为数据字节。
这个类在抓取时非常有用,因为它允许编码人员只下载 HTML 文件,而使用 WebBrowser 进行抓取虽然简单,但不是一种高效/快速的方式。
示例:将 Yahoo.com 的 HTML 源代码下载为字符串。
在表单上创建一个按钮和一个文本框。
在按钮点击事件中添加以下代码,并在运行时按下按钮。
这里我们正在创建一个 WebClient 变量,然后使用其 DownloadString 方法下载给定 URL 的 HTML。
下载的 HTML 将显示在 textbox1 中。
WebClient wc = new WebClient();
textBox1.Text = wc.DownloadString("http://www.yahoo.com");

使用 Webclient 的好处:
易于使用
支持各种文件和字符串下载方法
高效,与 WebBrowser 相比,使用的带宽少得多
一旦 HTML 源代码下载完成,您可以使用正则表达式或第三方 HTML 解析器从 HTML 源代码中获取所需信息。
示例 2:下载并保存图片。
将以下代码添加到按钮点击事件中,并在运行时按下按钮。
WebClient wc = new WebClient();
wc.DownloadFile("http://www.dotnetperls.com/one.png", "one.png");
图片 one.png 将被下载并存储在当前目录中。

第一个参数是图片的 URL,第二个参数是图片的名称。
同样地,WebClient 类提供了字符串和文件上传的方法,但我们将使用 HTTPWebRequest 类来实现。
wc.DownloadData() 方法提供将数据下载为字节。这在使用了不同编码(如 UTF8 等)的情况下非常有用。
示例:WebClient 的阻塞模式。
将以下代码添加到按钮点击事件中,并在运行时按下按钮。
WebClient wc = new WebClient();
wc.DownloadData("http://www.olx.com");
按下按钮后,尝试移动表单,表单将变为“无响应”状态。

为什么会这样?从互联网下载字符串、文件或数据是耗时的,而 WebClient 类在与 UI 相同的线程上执行下载操作。这会导致 UI 无响应。
这意味着,一旦 WebClient 正在下载,应用程序就无法执行其他任务。这就是阻塞模式。解决此问题的方法是在非阻塞模式下使用 WebClient。
示例:WebClient 的非阻塞模式
wc.DownloadStringAsync() 用于在单独的线程上执行下载操作。这使得 UI 保持响应,并且应用程序可以在下载进行时执行其他任务。
wc.DownloadStringAsync(new Uri("http://www.yahoo.com"));
这将从资源下载一个字符串,而不会阻塞调用线程。
要执行异步下载操作,用户需要定义 Download Completed 事件,以便在下载完成后通知调用线程。
在上述情况下,我们需要添加 DownloadStringCompleted 事件。
以下代码将使 WebClient 异步下载字符串,并在完成后触发 Download Completed 事件。
WebClient wc = new WebClient();
wc.DownloadStringCompleted+=new DownloadStringCompletedEventHandler(wc_DownloadStringCompleted);
wc.DownloadStringAsync(new Uri("http://www.yahoo.com"));
-
下载的字符串作为参数传递给 Download Complete 事件,可以通过以下方式访问:
void wc_DownloadStringCompleted(object sender, DownloadStringCompletedEventArgs e)
{
//Accessing the Downloaded String
string html = e.Result;
//Code to Use Downloaded String
textBox1.Text = html;
}
下载完成事件在调用线程上触发,因此您可以轻松访问 UI 元素。
示例:读/写流
WebClient 类提供了各种阻塞和非阻塞方法,用于直接读写操作的流访问。
以下代码片段以阻塞模式获取读取流:
WebClient wc = new WebClient();
StreamReader sr = new StreamReader(wc.OpenRead("http://www.yahoo.com"));
//Here You Can Perform IO
//Operations like, Read, ReadLine
//ReadBlock, ReadToEnd etc
//Supported by StreamReader Class
同样,写入流也可以用于与写入相关的 IO 操作。
示例:WebClient 的查询字符串。
获取或设置与请求关联的查询名称/值对的集合。
查询字符串有助于通过 URL 发布方法将参数发送到 URL。
谷歌的搜索结果页面地址格式如下:
https://www.google.com.pk/search?q=search+phrase
在上述 URL 中,1 是一个参数,search+phras 是它的值。
以下示例展示了如何使用查询字符串将参数及其值发送到 URL。
string uriString = "http://www.google.com/search";
//Create a new WebClient instance.
WebClient wc = new WebClient();
//Create a new NameValueCollection instance to hold the QueryString parameters and values.
NameValueCollection myQSC = new NameValueCollection();
//Add Parameters to the Collection
myQSC.Add("q", "Search Phrase");
// Attach QueryString to the WebClient.
wc.QueryString = myQSC;
//Download the search results Web page into 'searchresult.htm'
wc.DownloadFile(uriString, "searchresult.htm");
NameValueCollection 类位于 System.Collections.Specialized 下。
示例:将文件上传到 URL。
String uriString = "FileUploadPagePath";
// Create a new WebClient instance.
WebClient myWebClient = new WebClient();
//Path to The File to Upload
string fileName = "File Path";
// Upload the file to the URI.
//The 'UploadFile(uriString,fileName)' method
//implicitly uses HTTP POST method.
byte[] responseArray = myWebClient.UploadFile(uriString, fileName);
// Decode and display the response.
textBox1.Text = "Response Received. " + System.Text.Encoding.ASCII.GetString(responseArray);
示例:WebClient 的其他信息。
设置代理
wc.Proxy = new WebProxy("ip:port");
添加自定义标头
wc.Headers.Add(HttpRequestHeader.UserAgent, "user-agent");
获取响应标头
WebHeaderCollection whc = wc.ResponseHeaders;
任务 1:添加 Referrer 标头。
任务 2:从响应头中读取响应码和状态。
任务 3:WebClient 的 BaseAddress 是什么?
任务 4:使用 WebClient.QueryString 在 Google 上进行搜索。
任务 5:使用 WebClient.Upload 上传文件。
BackgroundWorker
顶部 此类提供了一种在后台线程上运行耗时操作的简便方法。BackgroundWorker 类允许您检查操作的状态,并允许您取消操作。
示例:在 BackgroundWorker 上运行耗时函数。
对于此示例,我们假设以下函数是一个耗时函数,用户需要多次运行此函数,导致 UI 无响应。
private void HeavyFunction()
{
System.Threading.Thread.Sleep(1000);
}
制作一个如下所示的表单,带有开始、停止按钮和状态文本。从组件中向表单添加一个 BackgroundWorker。

为 BackgroundWorker 的 DoWork 事件创建一个事件处理程序。DoWork 事件处理程序是您在后台线程上运行耗时操作的地方。您可以通过双击 BackgroundWorker 的事件窗格来创建此事件。

传递给后台操作的任何值都通过传递给事件处理程序的 DoWorkEventArgs 对象的 Argument 属性传递。

让我们在 backgroundWorker1_DoWork 事件中调用 HeavyFunction 5 次。
private void backgroundWorker1_DoWork(object sender, DoWorkEventArgs e)
{
for(int i = 0; i < 5; i++)
HeavyFunction();
}要启动 BackgroundWorker 工作,我们需要调用 backgroundWorker1 的 RunWorkerAsync() 函数。在 Start 按钮点击事件中调用它。
private void Start_Click(object sender, EventArgs e)
{
backgroundWorker1.RunWorkerAsync();
}
一旦点击了“开始”按钮,BackgroundWorker 将开始工作,但 UI 将保持响应。
您已成功学习如何在易于管理的单独线程上放置耗时函数。
工作完成后会触发 RunWorkerCompleted 事件。
该事件在调用线程(调用 BackGroundWorker.RunWorkerAsync() 的线程)上调用。在我们的例子中,它是 UI 线程。
要收到 BackGroundWorker 完成的通知,请添加事件 RunWorkerCompleted。

RunWorkerCompleted 事件将在 UI 线程上触发,因此我们可以轻松访问所有 UI 元素。
private void backgroundWorker1_RunWorkerCompleted(object sender, RunWorkerCompletedEventArgs e)
{
Status.Text = "Work Complete";
}
现在,按下“开始”按钮 5 秒后,状态标签文本将设置为“工作完成”。

在 BackgroundWorker 上执行一些耗时函数时,我们可能希望向用户更新进度。例如,在下载多个文件的场景中,我们可能希望更新 UI 以显示已完成的文件数量。
要执行此类更新,将调用 ReportProgress 函数,该函数在调用线程上引发 ProgressChanged 事件。
-
要调用 Report Progress,首先需要添加 Progress Changed 事件并将 WorkReportProgress 属性设置为 True。


在 Report Progress 方法中,可以传递 2 个参数:int ProgressPercentage 和 object UserState。这两个参数都可以在 ProgressChangedEventArgs 的 ProgressPercentage 和 UserState 属性中访问。

要报告进度,请将 BackgroundWorker DoWork 事件更改为以下内容:
private void backgroundWorker1_DoWork(object sender, DoWorkEventArgs e)
{
for (int i = 0; i < 100; i++)
{
HeavyFunction();
backgroundWorker1.ReportProgress(i, " Heavy Function Done");
}
}
要在 ProgressChanged 事件中更新 UI,请将其修改如下:
private void backgroundWorker1_ProgressChanged(object sender, ProgressChangedEventArgs e)
{
Status.Text = e.ProgressPercentage.ToString() + (string)e.UserState;
}
现在,一旦您按下“开始”按钮,状态将更新为 ReportProgress 方法中传递的参数。

当 BackgroundWorker 完成工作时,RunWorkerCompleted 事件将被触发,因此状态将更新为“工作完成”。

要在工作期间停止 BackgroundWorker,我们需要将 WorkerSupportsCancellation 属性设置为 True。

在工作过程中的任何时候,我们都可以通过调用 CancelAsync() 函数来停止 BackgroundWorker。将停止按钮的点击事件修改如下:
private void Stop_Click(object sender, EventArgs e)
{
backgroundWorker1.CancelAsync();
}
将 DoWork 事件修改如下,以便在取消待定(Cancelling is Pending)时停止:
private void backgroundWorker1_DoWork(object sender, DoWorkEventArgs e)
{
for (int i = 0; i < 1; i++)
{
if (backgroundWorker1.CancellationPending)
{
e.Cancel = true;
break;
}
HeavyFunction();
backgroundWorker1.ReportProgress(i, "Heavy Function Done");
}
}
为了使用准确信息更新 UI,您可以修改 BackGroundWorkerCompleted 事件,如下所示,以显示 BackGroundWorker 是停止了还是完成了工作:
private void backgroundWorker1_RunWorkerCompleted(object sender, RunWorkerCompletedEventArgs e)
{
if(e.Cancelled)
Status.Text = "Work Stooped";
else
Status.Text = "Work Complete";
}
如果 BackgroundWorker 正忙于某个任务,而用户再次按下“开始”按钮,这将导致错误并抛出异常。IsBusy 属性告诉我们工作线程是否忙碌,因此在调用 RunWorkerAsync() 函数之前,必须检查 BackgroundWorker 是否忙碌。以下代码完成了这项工作:
private void Start_Click(object sender, EventArgs e)
{
if (!backgroundWorker1.IsBusy)
backgroundWorker1.RunWorkerAsync();
else
MessageBox.Show("Busy in Work - Press Stop");
}
您可以将非 UI 对象作为参数发送给 RunWorkerAsync 函数,然后在 DoWork 事件中访问它。
示例:制作多线程应用程序从 pinterest.com 下载图片。
按如下所示设计 UI:

添加一个 BackgroundWorker,命名为 backGroundWorker1,添加 DoWork、ProgressChange 和 RunWorkCompleted 事件。将 WorkerReportsProgress 和 WorkerSupportsCancellation 属性设置为 True。
程序逻辑:我们将使用 backGroundWorker1 使用 WebClient 下载 http://www.pinterest.com 的 HTML 源代码,然后我们将使用正则表达式查找所有图片的 URL 并将其添加到 List<string> urls 中。与用户设置的线程数相等的 BackgroundWorker 将在运行时创建,每个 BackgroundWorker 将从 List<string> urls 中获取一个 URL,并使用 WebClient 下载该图片。
为 backgroundworker1 事件添加以下代码:
private void backgroundWorker1_DoWork(object sender, DoWorkEventArgs e)
{
WebClient wc = new WebClient();
string html = wc.DownloadString("http://www.pinterest.com");
Regex reg = new Regex("src=\"http://[^/]+/upload/[^\"]+");
MatchCollection mc = reg.Matches(html);
backgroundWorker1.ReportProgress(0, mc.Count.ToString() + "Images Found");
System.Threading.Thread.Sleep(2000);
lock(urls)
{
foreach (Match m in mc)
{
urls.Add(m.Value.Replace("src=\"",""));
}
}
}
private void backgroundWorker1_ProgressChanged(object sender, ProgressChangedEventArgs e)
{
Status.Text = (string)e.UserState;
}
在 DoWork 中,我们刚刚下载了 HTML,使用正则表达式获取了图片链接,并将其添加到了 List<string> urls 中。
现在我们需要为下载图片创建工作线程。我们将在用户按下“开始”按钮时执行此操作。将以下代码添加到“开始”按钮点击事件中:
private void Start_Click(object sender, EventArgs e)
{
int maxThrds;
if(!int.TryParse(NoOfThreads.Text, out maxThrds))
{
MessageBox.Show("Enter Correct Number of Threads");
return;
}
if(maxThrds <= 0)
{
MessageBox.Show("Enter 1 or more Threads");
return;
}
if (!backgroundWorker1.IsBusy)
{
for(int i = 0; i < maxThrds; i++)
{
BackgroundWorker bgw = new BackgroundWorker();
bgw.WorkerReportsProgress = true;
bgw.WorkerSupportsCancellation = true;
bgw.DoWork += new DoWorkEventHandler(bgw_DoWork);
bgw.ProgressChanged += new ProgressChangedEventHandler(bgw_ProgressChanged);
bgw.RunWorkerCompleted += new RunWorkerCompletedEventHandler(bgw_RunWorkerCompleted);
//Start The Worker
bgw.RunWorkerAsync();
}
backgroundWorker1.RunWorkerAsync();
}
else
{
MessageBox.Show("Busy in Work");
}
}
首先我们检查输入是否正确,然后我们在运行时创建 backgroundworker。
一旦所有运行时线程的属性都设置完毕,我们就为每个工作线程调用 bgw.RunWorkerAsync。
- 以下是运行时创建的工作线程的 DoWork 事件代码。
private void bgw_DoWork(object sender, DoWorkEventArgs e)
{
BackgroundWorker bgw = (BackgroundWorker)sender;
while(true)
{
string imgLink = "";
lock(urls)
{
if(urls.Count > 0)
{
imgLink = urls[0];
urls.RemoveAt(0);
count++;
}
else
{
System.Threading.Thread.Sleep(500);
}
}
if (imgLink != "")
{
string filename = imgLink.Substring(imgLink.LastIndexOf("/") + 1);
WebClient wc = new WebClient();
wc.Headers.Add(HttpRequestHeader.Referer, "Mozilla/5.0 (Windows NT 6.1; rv:15.0) Gecko/20100101 firefox/15.0.1");
wc.DownloadFile(imgLink, filename);
bgw.ReportProgress(0, count.ToString() + "Images Downloaded");
}
}
}
在第一行中,我们将 sender 强制转换为 BackgroundWorker 对象,以便可以为其报告进度。然后我们将所有代码放入一个循环中,在每次迭代中,我们从列表中删除一个 URL,然后将其置于下载状态。
如果 List<string> urls 中没有链接,我们将线程置于睡眠状态 500 毫秒。
-
由于许多线程将访问 List<string> urls,因此已将其置于锁中。
任务 1:如何停止运行时创建的工作线程。
任务 2:修改 backgroundworker1 以收集用户定义的图片数量。例如 30、100、220(如果超过 50 张,您必须抓取第 2、3、4 等页面)。
任务 1 提示:可以使用以下选项:
选项 1:您可以维护一个运行时创建的工作线程列表,然后为列表中的每个工作线程调用
CancelAsync()。然后修改每个运行时工作线程的代码,如果 CancellationPending 为真,则中断循环。
选项 2:声明一个全局变量 int rnd,在开始按钮点击事件中为其分配一些随机值,并将其作为参数传递给 BackgroundWorker DoWork 事件。
//Start Button Click Event
if(!backgroundWorker1.IsBusy)
{
rnd = new Random().Next(0, 99999);
for (int i = 0; i < maxThrds; i++)
{
BackgroundWorker bgw = new BackgroundWorker();
bgw.WorkerReportsProgress = true;
bgw.WorkerSupportsCancellation = true;
bgw.DoWork += new DoWorkEventHandler(bgw_DoWork);
bgw.ProgressChanged += new ProgressChangedEventHandler(bgw_ProgressChanged);
bgw.RunWorkerCompleted += new RunWorkerCompletedEventHandler(bgw_RunWorkerCompleted);
//Start The Worker, Pass rnd as Argument
bgw.RunWorkerAsync(rnd);
}
backgroundWorker1.RunWorkerAsync();
}
将 rnd 值强制转换为局部 int 变量,修改 DoWork 事件使其工作直到 rnd 未更改。
void bgw_DoWork(object sender, DoWorkEventArgs e)
{
int chk = (int)e.Argument;
while (chk == rnd)
{
//Do the Task
}
}在停止按钮点击事件中,为 rnd 分配一些新值,这将导致所有运行时创建的工作线程从循环中中断。
private void Stop_Click(object sender, EventArgs e)
{
rnd = new Random().Next(0, 9999);
}
任务 3:思考更多选项。
HTTPWebRequest / HTTPWebResponse
在此之前,我们需要了解一些主要的 HTTP 头部信息,并安装一些有助于我们确定网站布局、数据包和修改数据包的附加组件。
在您的任何浏览器中,访问 http://logme.mobi 。您将看到类似以下内容:

这是您的 HTTP 头信息,您的浏览器发送给 http://logme.mobi 的 Web 服务器。其中,User-Agent(它定义了用于浏览的浏览器)和 Connection 头很重要。
现在只需刷新页面,您将看到类似以下内容:
![]()
此标头定义了 Cookie,Cookie 是什么?Cookie 是以文本文件形式存储在您计算机上的一小段信息,当您浏览某些网站时,Web 服务器会使用它。
为了维护会话,cookie 头部非常重要。
会话如何工作? 用户请求登录页面后,服务器会发出一些 cookie,然后用户提交登录信息和 cookie,如果登录成功,服务器会发出新的 cookie 集,该 cookie 集将用户标识为已通过身份验证的用户。然后,对于后续对服务器的请求,将使用这些新发出的 cookie 集。这样就维护了会话。在任何时候,如果您清除 cookie 头部,您都将被重定向到登录页面。

安装 Mozilla Firefox 15.0,然后安装 Live HTTP Headers 附加组件。您可以从 这里 获取。运行 LiveHTTPHeader,然后刷新 http://logme.mobi 页面。您将看到类似以下内容:
LiveHTTPHeader 附加组件在您使用 Mozilla Firefox 浏览时,显示所有请求和响应的 HTTP 标头。此工具在确定网站的 HTTP 数据包格式方面非常有用,尤其有助于了解执行某些 POST 操作时正在发布的所有数据。
现在从 这里 安装 Tamper Data 附加组件。此工具在浏览网页时修改 HTTP 头部内容非常有用,此工具在确定执行某些 HTTP POST 请求哪些字段和头部是强制性的,以及我们可以从特定 POST 请求中跳过哪些内容方面非常有用。一旦您运行它,它将看起来像这样:

点击“开始篡改”按钮。在地址栏中输入 useragentstring.com/,然后按 Enter 键。一旦按下 Enter 键,将打开以下窗口,询问您是篡改数据、提交请求还是中止请求。

点击“篡改数据”,然后将打开以下窗口:
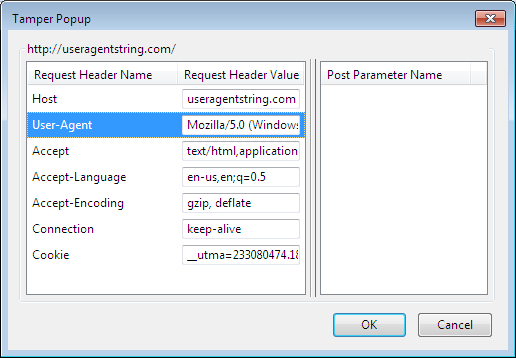
在用户代理字段中,输入以下内容并按确定:
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1
现在提交所有后续请求,一旦页面加载,您会看到网站显示您的浏览器是 Chrome,而您使用的是 FireFox。

同样,您可以更改 POST 方法参数。
.Net 中的 HTTPWebRequest 类:此类位于 System.Net 命名空间下,它提供方法和属性来向 Web 服务器发出 HTTP 请求。
属性,用于向 Web 服务器发出 HTTP 请求。
示例 1:下载 Facebook 登录页面的 HTML。
要创建此类的对象,可以使用 WebRequest.Create 函数:HttpWebRequest myReq = (HttpWebRequest)WebRequest.Create(url);
打开浏览器中的 LiveHTTPHeaders,并浏览到 https://#

上图显示了 HTTP 请求头,让我们在 C# 中实现它。
HttpWebRequest request = (HttpWebRequest)WebRequest.Create("https://#/");
request.UserAgent = "Mozilla/5.0 (Windows NT 6.1; rv:11.0) Gecko/20100101 Firefox/15.0";
request.Accept = "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8";
request.Headers.Add("Accept-Language: en-us,en;q=0.5");
request.Headers.Add("Accept-Encoding: gzip, deflate");
request.KeepAlive = true;
第一行创建了一个指向给定 URL 的 HTTPWebRequest 对象,然后我们通过属性将 User-Agent 和 Accept 标头添加到 HTTP 数据包中。并非所有标头都可以通过属性访问,因此用户可能需要通过将其添加到 Headers 集合来添加标头。然后我们通过将其添加到 Headers 集合来添加 Accept-Language 和 Accept-Encoding 标头。
接下来重要的任务是向 HTTPWebRequest 对象添加 Cookie 容器,因为我们希望记录服务器为响应请求而发送的 Cookie。如果未添加 Cookie 容器,则我们无法访问响应头中的 Cookie。
request.CookieContainer = new CookieContainer();
全局声明一个 CookieCollection 变量,所有收到的 Cookie 都将添加到此集合中,以便我们可以将收到的 Cookie 用于后续请求。如果您每次都使用新的 Cookie 容器,则无法维护会话。
现在我们已经完成了所需的 HTTPWebRequest 对象的创建。在创建 HTTPWebResponse 对象之前,让我们看看我们在 LiveHTTPHeader 中收到的浏览器发送的请求的响应。
第一行显示代码和状态。然后我们只关心 Cookies。我们收到了 4-5 个 Cookies,它们将存储在浏览器 Cookies 文件夹中,并随下一次请求发送。如果我们执行登录,这些 Cookies 将随为登录生成的 HTTP 请求一起发送,然后如果登录成功,服务器将发出一些额外的 Cookies(这些 Cookies 将包含使我们成为经过身份验证的用户的信息,用于后续请求)。
现在让我们创建 HTTPWebResponse 对象,这很简单。
一旦收到响应,下一步就是将收到的 Cookie 添加到全局定义的 CookieCollection 中。但在此之前,让我们看看我们收到了哪些 Cookie。在上述代码行之后添加以下代码以查看收到的 Cookie。
这将在 MessageBox 中显示您的 Cookie。
CookieCollectioncookies = new CookieCollection();

HttpWebResponse response = (HttpWebResponse)request.GetResponse();
string txt = "Cookies Count=" + response.Cookies.Count.ToString() + "\n";
foreach (Cookie c in response.Cookies)
{
txt += c.ToString() + "\n";
}
MessageBox.Show(txt);
//Adding Recevied Cookies To Collection
cookies.Add(response.Cookies);

现在响应已收到,下一步是从流中下载数据,可以是 HTML 源代码、其他文件,也可能什么都没有,具体取决于您发出请求的 URL。在我们的例子中,它是 Facebook 登录页面的 HTML 源代码。
StreamReader loginPage = new StreamReader(response.GetResponseStream()); string html = loginPage.ReadToEnd();
此 HTML 源代码可用于通过正则表达式或使用一些第三方 HTML 解析库获取一些信息,或作为离线页面存储在 HTML 文件中。
示例 2:登录 Facebook。
在用 C# 登录之前,我们先在 mozilla 浏览器中登录,并通过 LiveHTTPHeaders 分析 HTTP 头部。启动 LiveHTTPHeader,浏览到 https://#,输入用户名和密码,点击登录按钮。浏览器发送的 HTTP Web 请求将类似于以下内容:

第一行是发送您的用户名和密码的 URL(稍后在示例 3 中,我们将看到如何找到此 URL)。第二行告诉 HTTP 方法和版本,分别是 POST 和 1.1。
然后所有字段都像我们在示例 1 中看到的普通 HTTP 头部。重要部分从 Cookie 头部开始,在示例 1 中,一旦我们浏览到 https://#,就没有 Cookie 头部,而我们在响应头部中收到了一些 Cookie,现在当我们点击登录按钮时,之前收到的 Cookie 集正在此 Cookie 头部中发送。
下一个头部显示 Content Type,有两种主要的 Content Type 用于 POST 数据,application/x-www-form-urlencoded 和 multipart/form-data。您可以在 这里 找到更多关于它们的信息。
下一个头部显示 Content Length,最后一行显示 Content。您将在此行中看到您的电子邮件地址和密码。实际上,最后一行显示的是通过 HTTP Post 方法发送到服务器的数据。
还有其他几个值,稍后在示例中,我们将看到这些值是什么以及从何处获取这些值!!!
让我们检查上述请求的响应头。

响应头显示了许多 Cookie,这些是服务器在成功登录时发出的 Cookie,现在对于任何后续请求,浏览器都会将这些 Cookie 发送给服务器,并以此方式维护会话。
进入“工具”->“清除最近历史记录”并删除 Cookie,然后尝试浏览您的 Facebook 个人资料页面,您会发现您将被重定向到 Facebook 登录页面。
-
现在,让我们创建与上面屏幕截图中看到的相同登录请求头,并测试我们是否能够成功登录。
string getUrl = "https://#/login.php?login_attempt=1"; string postData = "lsd=AVo_jqIy&email=YourEmailAddress&pass=YourPassword&default_persistent=0& charset_test=%E2%82%AC%2C%C2%B4%2C%E2%82%AC%2C%C2%B4%2C%E6%B0%B4%2C%D0%94%2C%D0%84&timezone=-300&lgnrnd=072342_0iYK&lgnjs=1348842228&locale=en_US"; HttpWebRequest getRequest = (HttpWebRequest)WebRequest.Create(getUrl); getRequest.UserAgent = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.2 (KHTML, like Gecko) Firefox 15.0.0.1"; getRequest.CookieContainer = new CookieContainer(); //Adding Previously Received Cookies getRequest.CookieContainer.Add(cookies); getRequest.Method = WebRequestMethods.Http.Post; getRequest.ProtocolVersion = HttpVersion.Version11; getRequest.AllowAutoRedirect = false; getRequest.ContentType = "application/x-www-form-urlencoded"; getRequest.Referer = "https://#"; getRequest.KeepAlive = true;
getUrl 被分配给数据将发布到的地址,postData 变量是上面 HTTP 请求数据包中内容的副本。然后我们创建了一个 HTTPWebRequest 对象,并设置了其 User-Agent 头。
我们在响应 https://# 请求时收到的 Cookie 被添加到 HTTPWebRequest 对象中,如果我们不添加这些 Cookie,那么服务器将重定向我们到登录页面,而不是处理我们的登录请求。接下来,我们将 HTTP 方法设置为 Post,版本设置为 1.1(用于 HTTPS)。
对于我们尝试登录的请求,将 AllowAutoRedirect 属性设置为 false 非常重要,如果此属性设置为 true,则 HTTPWebRequest 对象将遵循重定向响应。
在重定向期间,您可能会失去对服务器在登录请求响应中发送的 Cookie 的访问权限。
现在让我们将登录信息发送到服务器。
//Converting postData to Array of Bytes byte[] byteArray = Encoding.ASCII.GetBytes(postData); //Setting Content-Length Header of the Request getRequest.ContentLength = byteArray.Length; //Obtaining the Stream To Write Data Stream newStream = getRequest.GetRequestStream(); //Writing Data To Stream newStream.Write(byteArray, 0, byteArray.Length); newStream.Close();
数据已写入流中,现在让我们获取响应并查看我们收到了哪些 Cookie。
HttpWebResponse getResponse = (HttpWebResponse)getRequest.GetResponse();
string txt = "Cookies Count=" + getResponse.Cookies.Count.ToString() + "\n";
foreach (Cookie c in getResponse.Cookies) {
txt += c.ToString() + "\n";
}
MessageBox.Show(txt);

我们成功登录到系统并收到了 9 个 Cookie,上面的快照显示了关于收到的 Cookie 的信息很少,您可以通过访问 Cookie 的属性获取更多信息。
将收到的 Cookie 添加到全局定义的 CookieCollection 中,以便可以在后续请求中使用。
如何检查登录是否成功?通常,Cookie 数量是判断登录是否成功的一种简单方法,为了更确定,您可以尝试获取主页的 HTML,如果您没有被重定向到登录页面,则表示您已成功登录。
示例 3:自定义 HTTPWebRequest 登录。
在最后一个示例中,我们只是重播了 mozilla 浏览器生成的 HTTP 数据包。现在让我们看看 POST Url 和 PostData 字段是从哪里获得的。从 Facebook 退出登录,并打开登录页面。右键单击电子邮件文本框,然后单击“检查元素”。

以下 HTML 窗格将出现在底部。单击 Form 元素。

在这里你可以看到高亮区域中的 action 字段,这个字段告诉数据要发布到的 url。
在突出显示区域下方,您可以看到几个输入字段,在示例 2 中,postData 您看到了除电子邮件和密码之外的许多字段,所以基本上这些字段与电子邮件和密码一起被发送到服务器。这些是登录表单的一部分,并且必须与登录信息一起发送到服务器。Facebook 经常更改这些字段的值,因此您无法在软件/应用程序中硬编码这些字段的值。
现在我们将了解如何从 Facebook 登录页面源代码中获取这些值。
您可以使用正则表达式、字符串操作或某些第三方 HTML 解析库来获取这些字段及其值。我正在使用 HTML Agility Pack 来获取登录表单标签及其所有子输入标签,并最终准备 postData。
现在,您可以像示例 2 中那样发布数据。一旦收到成功的登录 Cookie,将其添加到全局定义的 CookieCollection 中,然后对于任何后续请求,将这些 Cookie 与 HTTPWebRequest 一起发送。
string email="youremail";
string passwd="yourpassword"; string postData = ""; //Load FB login Page HTML
A.HtmlDocument doc = new A.HtmlDocument();
doc.LoadHtml(fb_html); //Get Login Form Tag A.HtmlNode
node = doc.GetElementbyId("login_form");
node = node.ParentNode; //Get All Hidden Input Fields //Prepare Post Data
int i = 0; foreach(A.HtmlNode h in node.Elements("input"); {
if(i>0)
{
postData += "&";
}
if(i == 1)
{
postData += "email=" + email + "&";
postData += "pass=" + passwd + "&";
}
postData += (h.GetAttributeValue("name", "") + "=" +
h.GetAttributeValue("value", ""));
i++;
}
示例 4:上传图片到个人资料。
我们将使用移动版 Facebook 上传图片到个人资料,而将上传到普通版 Facebook 作为用户的一项任务。
要上传图片/文件,Content Type 使用 multipart/form-data。
-
首先,让我们通过 LiveHTTPHeaders 检查上传图片的 HTTP 流量。
登录 http://m.facebook.com/,然后上传一张图片。
-
您将在 LiveHTTPHeaders 中看到如下 HTTP 请求:

现在您应该已经熟悉了上述 HTTP 请求头,唯一不同的是发布数据的方式,我们使用的是 multipart/form-data,而不是 application/x-www-form-urlencoded。您还可以观察 postData 的布局(就在 ContentType 下方)。
现在让我们研究一下这些字段(如 fb_dtsg、characterset 等)是从哪里来的。右键单击上传页面的上传照片表单,然后选择“检查元素”。

您可以看到所有字段都在图片上传的 form 标签下。同样,您可以使用正则表达式、字符串操作或 HTMLAgilityPack 来获取这些字段的名称和值。但首先您需要获取此页面的 HTML。
让我们获取所有这些字段并添加到字典集合中。此类位于
System.Collections中。创建一个字典变量 nvc。正如您所见,照片上传表单没有 ID,因此首先使用字符串操作获取表单标签的 HTML,然后使用 HTMLAgilityPack 轻松获取所有输入标签。
我们将使用以下函数上传照片:
传递的参数的详细信息如下:
HttpWebRequest req = (HttpWebRequest)WebRequest.Create("http://m.facebook.com/upload.php");
req.CookieContainer = new CookieContainer();
req.CookieContainer.Add(cookies);
req.AllowAutoRedirect=true;
req.UserAgent = "Mozilla/2.0 (Windows NT 6.1) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/5.0.874.121";
HttpWebResponse resp = (HttpWebResponse)req.GetResponse();
StreamReader sr = new StreamReader(resp.GetResponseStream());
string uploadHTML = sr.ReadToEnd();
Dictionary<string, string> nvc = new Dictionary<string, string>();
uploadHTML = uploadHTML.Substring(uploadHTML.IndexOf("<form"));
uploadHTML = uploadHTML.Replace("<form","<formid=\"myform\" ");
uploadHTML = uploadHTML.Remove(uploadHTML.IndexOf("/form>") + 6);
A.HtmlDocument doc = new A.HtmlDocument();
doc.LoadHtml(html);
A.HtmlNode node = doc.GetElementbyId("myform");
node = node.ParentNode;
foreach (A.HtmlNode h in node.Elements("input"))
{
string key = h.GetAttributeValue("name", "");
if (key != "")
nvc.Add(key, h.GetAttributeValue("value",""));
}
HttpUploadFile("http://upload.facebook.com/mobile_upload.php",
"file1", "filename", @"filePath", "image/jpeg", nvc);
上传表单的动作 URL
要上传的文件的 input 标签的名称
文件名称
您计算机上文件的路径
文件类型,在本例中是扩展名为 jpeg 的图像
包含所有输入标签名称和值的字典
以下是
HTTPUploadFile函数的完整代码段:
public void HttpUploadFile(string url,string paramName, string filename,
string filepath, string contentType, Dictionary<string,string> nvc)
{
//Prepairing PostData Format
string boundary = "---------------------------" + DateTime.Now.Ticks.ToString("x");
byte[] boundarybytes = System.Text.Encoding.ASCII.GetBytes("\r\n--" + boundary + "\r\n");
//Creating Request to Action URL
HttpWebRequest wr = (HttpWebRequest)WebRequest.Create(url);
wr.ContentType = "multipart/form-data; boundary=" + boundary;
wr.KeepAlive = true;
wr.CookieContainer = new CookieContainer();
//Adding Cookies Received at Login
wr.CookieContainer.Add(cookies);
wr.Method = WebRequestMethods.Http.Post;
wr.UserAgent = "Mozilla/2.0 (Windows NT 6.1) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/5.0.874.121";
wr.AllowWriteStreamBuffering = true;
wr.ProtocolVersion = HttpVersion.Version11;
wr.AllowAutoRedirect = true;
wr.Referer = "Referer: http://m.facebook.com/upload.php";
//Obtaining Stream to Write Data
Stream rs = wr.GetRequestStream();
string formdataTemplate = "Content-Disposition:
form-data; name=\"{0}\"\r\n\r\n{1}";
foreach (string key in nvc.Keys)
{
rs.Write(boundarybytes, 0, boundarybytes.Length);
string formitem = string.Format(formdataTemplate, key, nvc[key]);
byte[] formitembytes = System.Text.Encoding.UTF8.GetBytes(formitem);
//Writing all the input tags values
rs.Write(formitembytes, 0, formitembytes.Length);
}
rs.Write(boundarybytes,0, boundarybytes.Length);
//Writing File Contents
string headerTemplate = "Content-Disposition: form-data; " +
"name=\"{0}\"; filename=\"{1}\"\r\nContent-Type:{2}\r\n\r\n";
string header = string.Format(headerTemplate, paramName, filename, contentType);
byte[]headerbytes = System.Text.Encoding.UTF8.GetBytes(header);
rs.Write(headerbytes, 0, headerbytes.Length);
FileStream fileStream = new FileStream(filepath, FileMode.Open, FileAccess.Read);
byte[] buffer = new byte[4096];
int bytesRead = 0;
while((bytesRead = fileStream.Read(buffer, 0, buffer.Length)) != 0)
{
rs.Write(buffer, 0,bytesRead);
}
fileStream.Close();
//Completing the Data
byte[] trailer = System.Text.Encoding.ASCII.GetBytes("\r\n--" + boundary + "--\r\n");
rs.Write(trailer, 0, trailer.Length);
rs.Close();
//Receving Response
HttpWebResponse wresp = (HttpWebResponse)wr.GetResponse();
cookies.Add(wresp.Cookies);
StreamReader sr = new StreamReader(wresp.GetResponseStream());
string sourceCode = sr.ReadToEnd();
StreamWriter sw = new StreamWriter("upload.html");
sw.Write(sourceCode);
sw.Close();
任务 1:为 www.tagged.com 制作一个墙壁发布软件。
任务 2:调查一些使用 AJAX 的网站,看看如何使用 HTTPWebRequest、HTTPWebResponse 来实现。
任务 3:使用登录 Cookie 在某些网站上执行登录,查看受登录保护的页面。