
2 代 Intel® Xeon® 可扩展处理器带来的领导力绩效
新功能和工具,最大限度地提升您的HPC、AI和分析应用
2019年4月,第二代英特尔®至强®可扩展处理器(代号为Cascade Lake)发布,这是一款服务器级处理器。这款新的处理器系列已经创下了95项性能世界纪录,赢得了性能领导地位1。新功能包括用于AI深度学习推理加速的英特尔®深度学习加速(Intel® DL Boost)以及对英特尔®傲腾™数据中心(DC)持久内存的支持。这些处理器将继续提供领先的性能,每个CPU插槽最多56个核心,每个插槽12个DDR4内存通道——使其成为各种高密度基础设施的HPC、AI和分析应用的理想选择。
英特尔至强可扩展处理器旨在满足一系列计算需求,包括50多种工作负载优化解决方案和各种定制处理器。8200系列最多提供28个核心(56个线程),而9200系列最多提供56个核心(112个线程)。每个处理器核心都有1MB专用的L2缓存和高达38.5 MB的非包含共享L3缓存。每个插槽最多有三个英特尔®超路径互连(Intel® UPI)链接,以10.4 GT/s的速度运行,用于跨芯片(多插槽)通信。处理器内存接口现在支持最多六个通道(8200系列)和12个通道(9200系列)的DDR4内存,以2,933 MT/s的速度运行。此外,处理器支持每个插槽最多4.5 TB的内存,使用英特尔傲腾数据中心持久内存模块。为了帮助提高DL应用的性能,英特尔至强可扩展处理器具有512位VNNI(矢量神经网络指令),有助于每个周期每个核心处理多达16个DP/32个SP/128个INT8 MAC(乘法累加)指令。为了解决一些侧信道安全问题,英特尔至强可扩展处理器实现了硬件缓解措施,与基于软件的方法相比,其开销更小2。这些处理器功能适用于多个计算领域,其中一些我们将在下面讨论。
我们还将讨论如何使用英特尔傲腾数据中心持久内存、英特尔®AVX-512矢量神经网络指令(VNNI)以实现更快的DL推理,以及英特尔至强可扩展处理器在HPC应用中实现的相对性能增益。
[编者注:我们将在本期使用最新性能分析工具为英特尔®傲腾™数据中心持久内存做准备中讨论如何确定应用程序如何最好地利用这种新内存。]
英特尔®傲腾™数据中心持久内存
英特尔傲腾数据中心持久内存是一种新型的非易失性、大容量内存,具有接近DRAM的延迟,提供经济实惠的大容量数据持久性。图1显示了不同类别内存和存储设备的延迟估算。请注意英特尔傲腾数据中心持久内存创建的介于SSD和传统DRAM之间的新层级。
英特尔傲腾数据中心持久内存采用与DRAM相同的封装形式,物理和电气上都与DDR4接口和插槽兼容。基于英特尔至强可扩展处理器的机器必须配置DRAM和英特尔傲腾数据中心持久内存的组合。(在基于英特尔至强可扩展处理器的机器上,无法只使用英特尔傲腾数据中心持久内存,因为DRAM对于系统活动是必需的。)

英特尔傲腾数据中心持久内存可以在两种不同模式下使用(图2)
- 内存模式
- 应用直接模式

内存模式
这是使用英特尔傲腾数据中心持久内存最简单的方式,因为现有应用程序无需更改源代码即可受益。在此模式下,新的易失性内存池对操作系统和用户应用程序可见。DRAM充当热(频繁访问)数据的缓存,而英特尔傲腾数据中心持久内存提供大容量易失性内存。内存管理由英特尔至强可扩展处理器内存控制器处理。当从内存请求数据时,内存控制器首先检查DRAM缓存。如果找到数据,响应延迟与DRAM延迟相同。如果DRAM缓存中未找到数据,则从英特尔傲腾数据中心持久内存中读取,其延迟更高。内存控制器预测机制通过提前获取所需数据来帮助提高缓存命中率。然而,对广泛地址范围进行随机访问的工作负载可能不会受益于预测机制,并且会经历比DRAM延迟稍高的延迟3。
应用直接模式
为了使数据在内存中持久化,英特尔傲腾数据中心持久内存应配置为应用程序直接模式。在此模式下,操作系统和用户应用程序将DRAM和英特尔傲腾数据中心持久内存视为离散的内存池。程序员可以在任一内存池中分配对象。需要以最低延迟获取的数据必须分配在DRAM中(这些数据本质上是易失性的)。大容量数据,可能不适合DRAM,或者需要持久化的数据,必须分配在英特尔傲腾数据中心持久内存中。这些新的内存分配可能性是应用程序直接模式需要更改源代码的原因。有趣的是,在应用程序直接模式下,还可以将英特尔傲腾数据中心持久内存用作比传统HDD/NVMe存储设备更快的存储替代方案。
配置
在内存模式和应用直接模式之间切换需要更改BIOS设置。ipmctl是一个开源实用程序,可用于配置和管理傲腾持久内存模块(PMM)4。以下是一些有用的管理命令
$ ipmctl show -topology $ ipmctl show -memoryresources
配置PMM是一个两步过程。首先,您指定一个目标并将其存储在PMM上。然后BIOS会在下次重新启动时读取它。
Memory mode $ ipmctl create -goal MemoryMode=100 App Direct mode $ ipmctl create -goal PersistentMemoryType=AppDirect Mixed mode $ ipmctl create -goal MemoryMode=60
在混合模式下,指定百分比的英特尔傲腾数据中心持久内存可以在内存模式下使用,剩余内存可以在应用程序直接模式下使用。上述命令将60%的可用持久内存分配给内存模式,40%分配给应用程序直接模式。(有关详细信息,请参阅参考文献4和5。)
持久内存开发套件(PMDK)
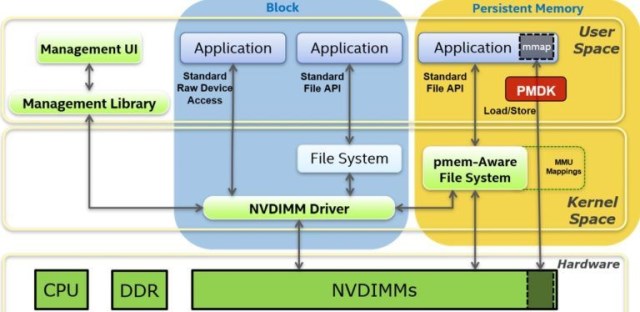
应用程序可以像使用传统内存一样,直接访问内存中的持久数据结构,从而无需在内存和存储之间来回分页数据块。要实现这种低延迟的直接访问,需要一种新的软件架构,允许应用程序访问持久内存的范围6。存储网络行业协会(SNIA)编程模型在这里为我们提供了帮助,如图3所示。
PMDK是一系列库和工具,系统管理员和应用程序开发人员可以使用它们来简化持久内存设备的管理和访问。这些库允许应用程序将持久内存作为内存映射文件进行访问。图3显示了SNIA模型,它描述了应用程序如何使用传统的POSIX标准API(如read、write、pread和pwrite)或加载/存储操作(如memcpy,当数据被内存映射到应用程序时)来访问持久内存设备。持久内存区域表示最快的访问速度,因为应用程序I/O绕过了现有文件系统页面缓存,直接访问或从持久内存介质访问6。
PMDK包含以下库和实用程序,以解决持久内存系统的常见编程需求
PMDK libraries Libpmem Libpmemobj Libpmemblk Libpmemlog Libvmem Libvmmalloc Libpmempool Librmem Libvmemcache PMDK libraries pmempool pmemcheck
PMDK示例
本节通过libpmemobj库演示了PMDK的使用,该库提供了一个事务性对象存储,提供内存分配、事务和持久内存编程的通用设施。本例演示了两个应用程序
- writer.c,它将一个字符串写入持久内存
- reader.c,它从持久内存中读取该字符串
带有注释的代码片段如表1所示。本例的完整源代码可在参考文献7中找到。
表1. 代码版本和优化摘要
| writer.c | reader.c | |||
int main(int argc, char *argv[1]
{
PMEMobjpoo] *pop = pmemobj_create(argv[1],
LAYOUT_NAME,
PMEMOB]_MIN_POOL, 0666),
if (pop == NULL) {
Perror("pmemobj_create");
return 1;
}
...
...
pmemobj_close(pop);
return 0;
}
| int main(int argc, char *argv[1]
{
PMEMobjpoo] *pop = pmemobj_open(argv[1],
LAYOUT_NAME,
if (pop == NULL)
{
perror("pmemobj_open");
return 1;
}
...
...
pmemobj_close(pop);
return 0;
}
| |||
pmemobj_create API 函数接受创建文件时通常会用到的参数,以及一个布局,这是一个由您选择的字符串,用于标识内存池。 | 在读取器中,我们没有创建新的内存池,而是使用与写入器代码中相同的布局打开了我们创建的内存池。 | |||
PMEMoid root = pmemobj_root(pop, sizeof (struct my_root)); struct my)root *rootp = pmemobj_ direct(root); | PMEMoid root = pmeobj_root(pop, sizeof (structr my_root)); struct my_root *rootp = pmeobj_direct(root); | |||
需要为应用程序在内存池中保留一个已知位置,称为根对象。它是所有内存结构都可以附加到的锚点。在上面的代码中,我们正在pop内存池中使用pmemobj_root创建一个根对象。我们还在使用pmemobj_direct将根对象转换为可用的直接指针。 | 由于我们已经在内存池中创建了根对象,所以pmeobj_root返回根对象而没有将其初始化为零。它将包含写入器负责存储的任何字符串。 | |||
char buf[MAX_BUT_LEN];
scanf("X9s", buf):
| if (rootp->len == strlen(rootp->buf))
printrf("%s\n", rootp->buf);
| |||
| 上述部分从持久内存中读取字符串。 |
英特尔傲腾数据中心持久内存的性能提升
本节介绍了使用英特尔傲腾数据中心持久内存(图4)在Aerospike*、Asiainfo的基准测试和SAS VIYA*等企业应用中实现的性能提升。Aerospike是一款NoSQL*键值数据库应用,在使用应用程序直接模式的英特尔傲腾数据中心持久内存后,重启时间减少了135倍。这有助于Aerospike在几秒钟内而不是几小时内重启,从而实现更频繁的软件和安全更新,同时显著减少中断。Asiainfo的一项基准测试显示,由于英特尔至强可扩展处理器和应用程序直接模式的英特尔傲腾数据中心持久内存的综合作用,延迟降低了68%。性能提升归因于能够将更多数据存储在内存中,从而减少了向较慢SSD的溢出。SAS VIYA*是一个统一的开放分析平台,具有在云端部署的AI功能。使用英特尔傲腾数据中心持久内存模式,梯度提升模型所需的大型数据集可以放置在内存中,性能几乎没有下降或没有下降,并且成本降低。性能提升高达18%。

借助英特尔®AVX-512 VNNI实现更快的AI推理
神经网络需要进行多次矩阵操作,这可以通过MAC指令实现。在上一代英特尔至强可扩展处理器中,将两个8位(INT8)值相乘并将结果累加到32位需要三条指令。在最新一代英特尔至强可扩展处理器中,这只需一条指令8即可完成。这种指令数量的减少代表了性能的提升,这是通过在执行管道的端口0和端口5上同时执行MAC指令来实现的(图5)。

目前,英特尔®编译器仅通过内在函数和内联汇编支持VNNI指令。对于打算在不使用内在函数或汇编的情况下利用VNNI功能的用户,用于深度神经网络的英特尔®数学核心函数库(Intel® MKL-DNN)9和BigDL10是推荐的替代方案。Intel MKL-DNN是为传统HPC环境高度优化的DL原语集合,而BigDL(由Intel MKL-DNN提供支持)为Apache Spark*中的大数据用户提供类似的优化DL功能。
与上一代英特尔至强可扩展处理器相比,使用英特尔MKL-DNN优化的Caffe* 1.1.3在双路英特尔®至强®铂金8280处理器上提供了14倍的推理吞吐量,在双路英特尔至强铂金9282处理器上提供了30倍的推理吞吐量11。对Caffe ResNet-50*使用英特尔至强铂金9282处理器进行的类似研究表明,其推理吞吐量优于英伟达*GPU(图6)12。其他流行的框架,如Chainer*、DeepBench*、PaddlePaddle*和PyTorch*,也使用英特尔MKL-DNN来获得更好的性能。

英特尔至强可扩展处理器上的HPC应用性能
英特尔至强可扩展8200和9200处理器增加的内核数量和更高的带宽为HPC应用带来了显著的提升。图7显示了行业标准基准测试的性能提升,图8显示了实际应用的性能提升。LAMMPS*和GROMACS*受益于AVX-512、更高的内核数量和超线程。英特尔至强可扩展处理器上更高的可用带宽为OpenFOAM*、WRF*和NEMO*等受内存带宽限制的代码带来了积极的提升。


提高HPC、AI和分析应用性能
最新英特尔至强可扩展处理器中的新硬件功能使开发人员能够提高各种HPC、AI和分析应用的性能。英特尔在处理器技术方面不断创新。即将推出的Cooper Lake架构将引入bfloat16以增强AI训练支持。此外,英特尔最近发布了10nm的第10代英特尔®酷睿™处理器,提供了更好的性能和密度改进。
附录
配置:单节点英特尔®至强®代际HPC性能
英特尔®至强®6148处理器:英特尔参考平台,搭载2个6148英特尔处理器(2.4GHz,20核),12x16GB DDR4-2666,1个SSD,集群文件系统:Panasas(124 TB存储)固件v6.3.3.a和基于OPA的IEEL Lustre,BIOS:SE5C620.86B.00.01.0015.110720180833,微代码:0x200004d,Oracle Linux Server release 7.6(兼容RHEL 7.6)在7.5内核上使用ksplice进行安全修复,内核:3.10.0-862.14.4.el7.crt1.x86_64,OFED堆栈:OFED OPA 10.8在RH7.5上使用Lustre v2.10.4。
英特尔®至强®铂金8260处理器:英特尔参考平台,搭载2个8260英特尔处理器(2.4GHz,24核),12x16GB DDR4-2933,1个SSD,集群文件系统:Panasas(124 TB存储)固件v6.3.3.a和基于OPA的IEEL Lustre,BIOS:SE5C620.86B.0D.01.0286.011120190816,微代码:0x4000013,Oracle Linux Server release 7.6(兼容RHEL 7.6)在7.5内核上使用ksplice进行安全修复,内核:3.10.0-957.5.1.el7.crt1.x86_64,OFED堆栈:OFED OPA 10.9在Oracle Linux 7.6上(兼容RHEL 7.6)使用Lustre v2.10.6。
英特尔®至强®铂金9242处理器:英特尔参考平台,搭载2个英特尔至强9242处理器(2.2GHz,48核),24x16GB DDR4-2933,1个SSD,集群文件系统:2.12.0-1(服务器)2.11.0-14.1(客户端),BIOS:PLYXCRB1.86B.0572.D02.1901180818,微代码:0x4000017,CentOS 7.6,内核:3.10.0-957.5.1.el7.x86_64
英特尔®至强®6148/8260/9242处理器
| Application | 工作负载 | 英特尔®编译器 | 英特尔®软件有限公司软件 | BIOS设置 |
| STREAM OMP 5.10 | Triad | 2019u2 | HT=ON, Turbo=OFF, 每个核心1个线程 | |
| HPCG 2018u3 | 包含MKL的二进制文件 | 2019u1 | MPI 2019u1, MKL 2019u1 | HT=ON, Turbo=OFF, 每个核心1个线程 |
| SPECrate2017 _fp_base | 截至2019年6月20日发布的最佳结果 | |||
| HPL 2.1 | 包含MKL的二进制文件 | 2019u1 | MKL 2019, MPI 2019u1 | HT=ON, Turbo=OFF, 2个线程 每个核心 |
| WRF 3.9.1.1 | conus-2.5km | 2018u3 | MPI 2018u3 | HT=ON, HT=ON,1 每个核心的线程数 核心 |
| GROMACS 2018.2 | 所有工作负载 | 2019u2 | MKL 2019u2, MPI 2019u2 | HT=ON, Turbo=OFF, 2个线程 每个核心 |
| LAMMPS 12 2018年12月 | 所有工作负载 | 2019u2 | MPI 2019u2 | HT=ON, Turbo=ON, 2个线程 每个核心 |
| OpenFOAM 6.0 | 42M_cell_motorbike | 2019u1 | MPI 2018u3 | HT=ON, Turbo=OFF, 每个线程1个 核心 |
| NEMO v4.0 | ORCA2_ICE_PISCES | 2018u3 | MPI 2018u3 | HT=关闭, TURBO=开启, 纯MPI run |