
Android 上的 Neon Intrinsics:如何截断 1D 信号的阈值处理和卷积
0/5 (0投票)
在本文中,我将向您展示一种易于使用的方法,可用于编写高效代码,这些代码可用于信号和图像处理、神经网络或游戏应用程序。
单指令多数据 (SIMD) 架构允许您并行执行代码。SIMD 允许您在一条指令的过程中对整个数据序列或矢量执行相同的操作。因此,您可以使用 SIMD 显著提高 Android 移动或物联网应用程序的性能。
为了使开发人员能够轻松访问 SIMD 优化,处理器制造商提供了专用的开发人员工具。例如,Arm Neon 内联函数是内置函数,您可以从高级代码中访问它们。编译器将这些函数替换为几乎 1 对 1 映射的汇编指令。因此,正如我将在本文中演示的那样,只需稍作修改,您就可以轻松地将代码矢量化。
入门
在我最近的文章中,我展示了如何设置 Android Studio 以将 Arm Neon 内联函数用于 Android 应用程序。您从需要 Android 本机开发工具包 (NDK) 的本机 C++ 项目模板开始。该项目模板创建了一个引用本机 C++ 库的 Java 活动。该库必须包含 arm_neon.h 头文件,其中包含 Arm Neon 内联函数的声明。此外,您需要为 Arm Neon 内联函数启用构建支持。
在这里,我将这些步骤作为起点,向您展示这种方法可以轻松地用于编写高效代码,这些代码可用于信号和图像处理、神经网络或游戏应用程序。
具体来说,我将创建一个 Android 应用程序,该应用程序将使用 Neon 内联函数处理一维信号。该信号将是带有随机噪声的正弦波。我将展示如何实现该信号的截断阈值和卷积。阈值处理通常是各种图像处理算法的第一步,而卷积是主要的信号和图像处理工具。
和以前一样,我使用 Android Studio 并使用 Samsung SM-J710F 手机测试代码。完整的源代码可从 GitHub 存储库获取。


应用程序结构
我通过修改位于 app/src/main/res/layout 下的 activity_main.xml 来声明应用程序的 UI。如下所示,我使用一个线性布局来垂直对齐控件。这里使用额外的线性布局是为了将截断和卷积按钮彼此相邻放置。ScrollView 包装了所有控件,因此如果屏幕太小无法一次显示所有内容,用户可以向下滚动。
<?xml version="1.0" encoding="utf-8"?>
<ScrollView xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="match_parent"
android:layout_height="wrap_content">
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical"
tools:context=".MainActivity">
<Button
android:id="@+id/buttonGenerateSignal"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_gravity="center_horizontal"
android:onClick="buttonGenerateSignalClicked"
android:text="Generate Signal"
android:layout_margin="5dp"/>
<CheckBox
android:id="@+id/checkboxUseNeon"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_gravity="center_horizontal"
android:text="Use Neon?" />
<LinearLayout
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_gravity="center_horizontal">
<Button
android:id="@+id/buttonTruncate"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_gravity="center_horizontal"
android:onClick="buttonTruncateClicked"
android:text="Truncate"
android:layout_margin="5dp"/>
<Button
android:id="@+id/buttonConvolution"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_gravity="center_horizontal"
android:onClick="buttonConvolutionClicked"
android:text="Convolution"
android:layout_margin="5dp"/>
</LinearLayout>
<com.jjoe64.graphview.GraphView
android:id="@+id/graph"
android:layout_width="match_parent"
android:layout_height="350dp"
android:layout_margin="10dp"/>
<TextView
android:id="@+id/textViewProcessingTime"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_gravity="center_horizontal"
android:textSize="18sp" />
</LinearLayout>
</ScrollView>
为了在处理前后绘制信号,我使用了 GraphView 库。通过在 build.gradle 的依赖项节点下包含以下行来安装此库
implementation 'com.jjoe64:graphview:4.2.2'
然后,通过使用 <com.jjoe64.graphview.GraphView> 属性将 GraphView 包含在 UI 中。完成此操作后,您将获得对 GraphView 实例的引用,就像使用任何其他 Android 控件一样。
我在 configureGraph 方法中执行了此操作,我在 onCreate 活动方法下调用了该方法(见下文)。然后,您可以使用对 GraphView 的引用来格式化绘图并添加数据系列。在本文中,我使用了三行系列(来自 GraphView 库的 LineGraphSeries 实例):一个用于显示输入信号,一个用于截断信号,最后一个用于卷积。
GraphView graph;
private LineGraphSeries<DataPoint> signalSeries = new LineGraphSeries<>();
private void configureGraph(){
// Initialize graph
graph = (GraphView) findViewById(R.id.graph);
// Set bounds
graph.getViewport().setXAxisBoundsManual(true);
graph.getViewport().setMaxX(getSignalLength());
graph.getViewport().setYAxisBoundsManual(true);
graph.getViewport().setMinY(-150);
graph.getViewport().setMaxY(150);
// Configure series
int thickness = 4;
signalSeries.setTitle("Signal");
signalSeries.setThickness(thickness);
signalSeries.setColor(Color.BLUE);
// Truncate, and convolution series are configured in the same way
// Add series
graph.addSeries(signalSeries);
// Add legend
graph.getLegendRenderer().setVisible(true);
graph.getLegendRenderer().setAlign(LegendRenderer.LegendAlign.TOP);
}
设置图形后,我为按钮实现了事件处理程序。每个事件处理程序的结构都相似。它们使用适当的 LineGraphSeries 实例的 resetData 方法在图表中显示数据。例如,以下代码显示了输入信号和卷积后的数据
private LineGraphSeries<DataPoint> signalSeries = new LineGraphSeries<>();
private LineGraphSeries<DataPoint> signalAfterConvolutionSeries =
new LineGraphSeries<>();
public void buttonGenerateSignalClicked(View v) {
signalSeries.resetData(getDataPoints(generateSignal()));
}
public void buttonConvolutionClicked(View v) {
signalAfterConvolutionSeries.resetData(getDataPoints(convolution(useNeon())));
displayProcessingTime();
}
请注意,与截断和卷积相关的事件处理程序还会获取信息,即处理是否应使用 Neon 内联函数或本机 C++ 完成。为此,我检查了应用程序界面中提供的“使用 Neon”复选框的状态
private boolean useNeon() {
return checkBoxUseNeon.isChecked();
}
getDataPoints 是一个辅助函数,用于将字节数组(来自 native-lib)转换为 GraphView 绘制所需的 DataPoints 集合(详情请参阅代码仓库)。
另一个辅助函数 displayProcessingTime 用于显示图表下方标签中的代码执行时间。我用它来比较 Neon 和非 Neon 代码之间的处理性能。
调用本地库
信号、截断数据和卷积数据都来自本机 C++ 库。要从 C++ 库获取数据,您需要创建 Java 方法和本机库函数之间的绑定。我将向您展示如何使用 generateSignal 方法来实现这一点。
首先,在 Java 类中声明该方法并带有一个额外的 native 修饰符
public native byte[] generateSignal();
然后,要自动生成绑定,将光标放在方法名称中(这里是 generateSignal)。按 Alt+Enter 显示上下文帮助,并如下所示选择“创建 JNI 函数…”选项。

Android Studio 将使用空声明补充 native-lib.cpp,该声明看起来像这样
extern "C"
JNIEXPORT jbyteArray JNICALL
Java_com_example_neonintrinsicssamples_MainActivity_generateSignal(
JNIEnv *env, jobject /* this */) {
}
输入信号
设置 UI 和 Java 到本地绑定后,使用 generateSignal 方法扩展 native-lib
#define SIGNAL_LENGTH 1024
#define SIGNAL_AMPLITUDE 100
#define NOISE_AMPLITUDE 25
int8_t inputSignal[SIGNAL_LENGTH];
void generateSignal() {
auto phaseStep = 2 * M_PI / SIGNAL_LENGTH;
for (int i = 0; i < SIGNAL_LENGTH; i++) {
auto phase = i * phaseStep;
auto noise = rand() % NOISE_AMPLITUDE;
inputSignal[i] = static_cast<int8_t>(SIGNAL_AMPLITUDE * sin(phase) + noise);
}
}
此方法生成一个有噪声的正弦波(请参阅前面所示的应用程序 UI 图像中的蓝色曲线),并将结果存储在 inputSignal 全局变量中。
您可以使用 SIGNAL_LENGTH、SIGNAL_AMPLITUDE 和 NOISE_AMPLITUDE 宏控制信号长度、其幅度和噪声贡献。但是请注意,inputSignal 的类型为 int8_t。设置过大的幅度会导致整数溢出。
要将生成的信号传递给 Java 代码进行绘图,您需要在可导出的 C 函数中调用 generateSignal 方法(该函数之前由 Android Studio 创建)
extern "C"
JNIEXPORT jbyteArray JNICALL
Java_com_example_neonintrinsicssamples_MainActivity_generateSignal(
JNIEnv *env, jobject /* this */) {
generateSignal();
return nativeBufferToByteArray(env, inputSignal, SIGNAL_LENGTH);
}
这里有一个新事物,nativeBufferToByteArray。此方法获取指向本机 C++ 数组的指针,并将数组元素复制到 Java 数组(有关更多信息,请参阅此链接)
jbyteArray nativeBufferToByteArray(JNIEnv *env, int8_t* buffer, int length) {
auto byteArray = env->NewByteArray(length);
env->SetByteArrayRegion(byteArray, 0, length, buffer);
return byteArray;
}
截断
现在让我们转到通过截断进行的阈值处理。
此算法的工作原理如下:给定一个输入数组,它将所有高于预定义阈值 T 的元素替换为 T 值。所有低于阈值的项保持不变。
要实现这样的算法,您只需使用一个 for 循环。然后,在每次迭代中,您可以调用 std::min 方法来检查当前数组值是否高于阈值
#define THRESHOLD 50
int8_t inputSignalTruncate[SIGNAL_LENGTH];
void truncate() {
for (int i = 0; i < SIGNAL_LENGTH; i++) {
inputSignalTruncate[i] = std::min(inputSignal[i], (int8_t)THRESHOLD);
}
}
在此示例中,阈值通过相应的宏设置为 50,截断信号存储在 inputSignalTruncate 全局变量中。
使用 Neon 进行截断
由于上述算法的每次迭代都是独立的,因此您可以直接应用 Neon 内联函数。为此,您只需将 for 循环分成几个段。每个段将并行处理几个输入元素。
您可以并行处理的项数取决于输入数据类型。这里,输入信号是 int8_t 元素的数组,因此每次迭代最多可以处理 16 个项(请参阅下面的 TRANSFER_SIZE 宏)。
使用 Neon 内联函数的一般模式是:首先将数据从内存加载到寄存器,使用 Neon SIMD 处理寄存器,然后将结果存储回内存。以下是在截断情况下遵循此方法的方法
#define TRANSFER_SIZE 16
void truncateNeon() {
// Duplicate threshValue
int8x16_t threshValueNeon = vdupq_n_s8(THRESHOLD);
for (int i = 0; i < SIGNAL_LENGTH; i += TRANSFER_SIZE) {
// Load signal to registers
int8x16_t inputNeon = vld1q_s8(inputSignal + i);
// Truncate
uint8x16_t partialResult = vmin_s8(inputNeon, threshValueNeon);
// Store result in the output buffer
vst1q_s8(inputSignalTruncate + i, partialResult);
}
}
您首先将循环分成 SIGNAL_LENGTH / TRANSFER_SIZE 段。然后,使用 vdupq_n_s8 Neon 函数将阈值复制到名为 threshValueNeon 的向量中(您可以在此处获取所有可用 Neon 函数的列表)。
之后,您使用 vld1q_s8 方法将输入信号块加载到寄存器中,计算阈值和输入信号片段之间的最小值,并将结果存储回 inputSignalTruncate 数组。
为了比较 Neon 和非 Neon 方法的性能,将 truncate 和 truncateNeon 方法放入 Java 绑定方法中
double processingTime;
extern "C"
JNIEXPORT jbyteArray JNICALL
Java_com_example_neonintrinsicssamples_MainActivity_truncate(JNIEnv *env, jobject thiz, jboolean useNeon) {
auto start = now();
#if HAVE_NEON
if(useNeon)
truncateNeon();
else
#endif
truncate();
processingTime = usElapsedTime(start);
return nativeBufferToByteArray(env, inputSignalTruncate, SIGNAL_LENGTH);
}
您可以使用 chrono 库测量处理时间(请参阅随附代码),并将测量的执行时间存储在 processingTime 全局变量中。它使用以下绑定传递给 Java 代码
extern "C"
JNIEXPORT jdouble JNICALL
Java_com_example_neonintrinsicssamples_MainActivity_getProcessingTime(
JNIEnv *env, jobject thiz) {
return processingTime;
结果如下所示。
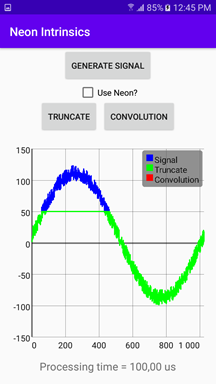

要获取它们,请在您的设备上运行应用程序并单击生成信号按钮。它绘制蓝色曲线。然后,点击截断按钮。会出现一条绿线。
最后,勾选“使用 Neon”复选框,然后再次点击截断按钮。如图所示,使用 Neon 内联函数,我将处理时间从 100 微秒缩短到 6 微秒,执行速度大约快 16 倍!我在没有任何重大代码更改的情况下实现了这一点——只是对单个循环进行了轻微修改,并使用了 Neon 内联函数。
卷积
最后,让我们看看如何使用 Neon 内联函数实现一维卷积。
您可以在此处找到卷积的形式定义。但是,简单来说,要计算卷积,您需要有输入信号。此外,您还需要定义所谓的核。该核通常比输入信号短得多,并且因应用程序而异。人们使用不同的核来平滑或过滤噪声信号或检测边缘。
2D 卷积也用于卷积神经网络中以查找图像特征。
在这里,我有一个 16 元素的核,每个元素的值都为 1。我沿着我的输入信号滑动这个核,并在每个位置将输入元素乘以所有核值,然后对结果乘积求和。归一化后,我的核将作为移动平均值工作。
这是此算法的 C++ 实现
#define KERNEL_LENGTH 16
// Kernel
int8_t kernel[KERNEL_LENGTH] = {1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1};
void convolution() {
auto offset = -KERNEL_LENGTH / 2;
// Get kernel sum (for normalization)
auto kernelSum = getSum(kernel, KERNEL_LENGTH);
// Calculate convolution
for (int i = 0; i < SIGNAL_LENGTH; i++) {
int convSum = 0;
for (int j = 0; j < KERNEL_LENGTH; j++) {
convSum += kernel[j] * inputSignal[i + offset + j];
}
inputSignalConvolution[i] = (uint8_t)(convSum / kernelSum);
}
}
如您所见,此代码使用两个 for 循环——一个遍历输入信号元素,另一个遍历核。为了提高性能,我可以采用手动循环展开,并用硬编码索引替换嵌套的 for 循环,如下所示
convSum += kernel[0] * inputSignal[i + offset + 1]; convSum += kernel[1] * inputSignal[i + offset + 2]; … convSum += kernel[15] * inputSignal[i + offset + 15];
但是,由于内核长度与我可以传输到 CPU 寄存器的项数相同,因此我可以使用 Neon 内联函数并完全展开第二个循环
void convolutionNeon() {
auto offset = -KERNEL_LENGTH / 2;
// Get kernel sum (for normalization)
auto kernelSum = getSum(kernel, KERNEL_LENGTH);
// Load kernel
int8x16_t kernelNeon = vld1q_s8(kernel);
// Buffer for multiplication result
int8_t *mulResult = new int8_t[TRANSFER_SIZE];
// Calculate convolution
for (int i = 0; i < SIGNAL_LENGTH; i++) {
// Load input
int8x16_t inputNeon = vld1q_s8(inputSignal + i + offset);
// Multiply
int8x16_t mulResultNeon = vmulq_s8(inputNeon, kernelNeon);
// Store and accumulate
// On A64 the following lines of code can be replaced by a single instruction
// auto convSum = vaddvq_s8(mulResultNeon)
vst1q_s8(mulResult, mulResultNeon);
auto convSum = getSum(mulResult, TRANSFER_SIZE);
// Store result
inputSignalConvolution[i] = (uint8_t) (convSum / kernelSum);
}
delete mulResult;
}
同样,我首先将数据加载到 CPU 寄存器(从核和输入信号)。我使用 Neon SIMD 处理它,并将结果存储回内存(这里是 inputSignalConvolution 数组)。
上述代码与 ARM v7 及更高版本兼容。但是,在 AARCH64 上,可以通过利用 vaddvq_s8 函数来进一步改进它,该函数对向量中的元素求和。我可以用它来对核下的值求和(请参阅代码中的注释)。
为了测试代码,我使用了另一个 Java 到本地绑定
extern "C"
JNIEXPORT jbyteArray JNICALL
Java_com_example_neonintrinsicssamples_MainActivity_convolution(
JNIEnv *env, jobject thiz, jboolean useNeon) {
auto start = now();
#if HAVE_NEON
if(useNeon)
convolutionNeon();
else
#endif
convolution();
processingTime = usElapsedTime(start);
return nativeBufferToByteArray(env, inputSignalConvolution, SIGNAL_LENGTH);
}
然后,重新运行应用程序后,我获得了相同的结果,但使用 Neon 内联函数优化后处理时间仅为一半(请参见下图中的底部标签——处理时间在图表下方以蓝色突出显示)。


总结
在本文中,我开发了一个 Android 应用程序,该应用程序使用本机 C++ 代码执行信号处理。我展示了如何轻松地将 Java 与本机代码结合起来以执行计算密集型工作。本机部分的性能通过 Arm Neon 内联函数得到了进一步增强。您看到 Neon 内联函数可以显著缩短处理时间。特别是对于带截断的阈值处理,处理时间缩短到原始处理时间的约 6%。
当您的迭代代码独立时,即后续迭代不依赖于先前结果时,您会发现 Arm Neon 内联函数很有用。流行的开源库(如 OpenCV)已经使用 Neon 内联函数来提高性能。例如,Carotene 存储库包含基于 Neon 内联函数的代码,该代码实现了许多图像处理算法。您可以使用此存储库来深入了解 Neon 内联函数如何帮助您的项目。