
AI 增强的数据科学:Azure Synapse Analytics(第二部分:设置工作区和链接服务)
5.00/5 (2投票s)
在本文中,我们将直接设置 Azure Synapse 工作区和 Azure Synapse Studio,为本系列下一篇文章中的机器学习分析做准备。
在本系列第一篇文章中,我们了解了 Azure Synapse Analytics 和 Azure 机器学习如何帮助分析数据,而无需 extensive 编码和机器学习经验。我们还创建了本系列其余部分的路线图
- 创建 Azure Synapse Analytics 工作区
- 创建 Azure 机器学习工作区
- 创建和配置 Azure 机器学习链接服务
- 导入数据
- 使用 AutoML 训练预测模型
- 使用预训练的 Azure ML 模型丰富数据
- 使用 Azure 认知服务丰富数据
让我们开始创建工作区和链接服务,为本系列文章后面的数据分析做准备。
创建和配置 Synapse 工作区
我们将使用 Azure 门户创建 Azure Synapse 工作区。我们需要有一个活动的 Azure 帐户,所以如果您还没有,请注册。注册后,您可以享受 12 个月的免费热门服务和 200 美元的信用额度,用于在 30 天内充分探索 Azure。
在 Azure 门户中,我们点击创建资源并搜索“Azure Synapse Analytics”。

在 Azure Synapse Analytics 页面上,我们点击创建,然后开始输入我们的基本项目详细信息。接下来,我们选择要用于创建工作区的订阅。我们可以创建新的资源组(如上图所示)或管理以前创建的资源组。在这里,我们创建一个新的。
我们为工作区输入一个名称,从订阅中选择Data Lake Gen2,选择或创建一个新的存储帐户和文件系统,然后点击下一步:安全。

在下一页,安全,我们输入 SQL 管理员凭据。

接下来,我们查看我们的网络设置。

我们确保选中允许来自所有 IP 地址的连接。这是将 Azure Synapse Studio 或任何其他客户端工具连接到工作区终结点所必需的。成功预配工作区后,我们可以在以后限制和允许或禁止特定 IP 地址。
接下来,我们可以选择创建标签,尽管我们在此处跳过此步骤。然后,我们点击查看 + 创建以创建工作区。

工作区部署可能需要几分钟。我们可以监视顶部进度条中的部署状态——或者只是给自己冲一杯咖啡。
部署完成后,我们打开资源组并点击我们刚刚创建的工作区。在这里,我们可以看到工作区 Web URL、主要的 ADLS Gen2 存储帐户 URL 和文件系统、专用和无服务器 SQL 终结点以及开发终结点。

在我们的 Azure Synapse Analytics 工作区就位后,让我们继续创建 Azure 机器学习工作区。
创建和配置 Azure 机器学习工作区
我们可以使用 Azure 门户以与创建 Synapse 工作区相同的方式创建 Azure 机器学习工作区。
在 Azure 门户中,我们点击创建资源并搜索“机器学习”。当我们进入 Azure 机器学习页面时,我们点击创建以开始创建工作区。

我们将在本页输入基本的项目详细信息,例如订阅、资源组、工作区名称等。我们不创建新的资源组,而是选择我们之前创建的资源组。接下来,我们命名我们的工作区,其余字段将自动填充。

然后,我们点击下一步:网络。在这里,我们将遵循默认设置,并选择公共终结点作为连接方法。

然后我们点击下一步:高级,并再次保留默认设置。

我们将保留其余的默认设置,并继续创建工作区。部署完成后,我们将在已部署的资源下看到 Azure 机器学习工作区。

在我们的两个工作区都就位后,让我们继续创建链接服务。
创建和配置 Azure 机器学习链接服务
为了在 Azure Synapse Analytics 中利用 Azure 机器学习,我们需要链接我们的两个工作区。有两种身份验证类型:Synapse 工作区托管标识和服务主体。在这里,我们将使用服务主体创建链接服务。
创建服务主体
在创建链接服务之前,我们需要在 Azure 门户中创建一个新的服务主体。因此,我们首先打开 Azure 门户并导航到 Azure Active Directory。在这里,我们转到管理下的应用注册选项卡。

目前我们没有任何已注册的应用程序,因此我们将通过点击新注册来注册一个。

我们为应用程序输入一个名称,并选择支持的帐户类型。在这里,我们保留默认的帐户类型。我们保留重定向 URI 为空,然后点击注册以注册我们的应用程序。

当应用程序成功注册后,我们需要为应用程序生成一个秘密。因此,我们从应用程序导航到证书和秘密,然后点击客户端秘密下的新客户端秘密。

我们现在输入新秘密的描述,并选择最适合我们的有效期(在这里,我们的秘密将在六个月后过期),然后点击添加。

当 Azure Active Directory 生成秘密时,我们将其值安全保存,因为我们将在创建链接服务时需要它。
我们的下一步是为应用程序创建服务主体。为此,我们导航到应用程序的概览选项卡。在我们的案例中,Azure Synapse Analytics 已自动创建了我们的服务主体,如下图所示。

在创建链接服务之前,我们需要做的最后一件事是确保服务主体拥有与 Azure 机器学习工作区协同工作所需的权限。因此,我们首先导航到我们之前创建的 Azure 机器学习工作区,并选择访问控制 (IAM) 部分进行配置。接下来,我们点击+ 添加并选择添加角色分配以添加新角色。

接下来,我们从添加角色分配页面上的下拉菜单中选择参与者角色。我们还选择了我们刚刚创建的服务主体,在我们的案例中是 Azure Synapse Analytics。

现在我们点击保存以添加角色分配。当角色成功添加后,我们就可以创建 Azure 机器学习链接服务了。
创建 Azure ML 链接服务
从这里开始,我们将转到 Azure Synapse Studio 创建链接服务。我们在 Azure Synapse 工作区中的入门下找到启动 Azure Synapse Studio 的选项。我们点击打开。

出现提示时,点击验证以继续。确保您的浏览器允许弹出窗口。

进入 Studio 后,我们转到管理部分并选择链接服务。我们发现 Azure Synapse Analytics 和 Azure Data Lake Storage Gen2 链接服务已列出。我们将通过点击+ 新建为 Azure ML 创建一个新的链接服务。

在下一页,我们搜索“机器学习服务”。我们选择Azure 机器学习并继续。

接下来,我们需要在新的链接服务 (Azure Machine Learning) 对话框中提供 Azure ML 工作区的详细信息。我们输入这些详细信息
- 名称:我们为链接服务输入一个名称。
- 集成运行时:我们选择一个集成运行时选项。在这里,我们使用默认设置。
- 身份验证方法:如前所述,Azure Synapse Analytics 提供两种身份验证方法:Synapse 工作区托管标识和服务主体。我们在这里选择服务主体。
- Azure 订阅:此字段会自动填充,但我们确保选择了包含 Azure Synapse Analytics 资源组的订阅。
- Azure 机器学习工作区名称:我们选择之前创建的 Azure ML 工作区。
- 租户:此字段已预先填充。您也可以在应用程序的概览页面上找到此租户 ID。请参阅下图。

- 服务主体 ID:这是应用程序(客户端)ID。您可以在应用程序概览页面上的租户 ID 上方找到此 ID。请参阅下图。

- 服务主体密钥:这是我们在上一节中生成的秘密值。
当我们填写完所有必填字段后,点击测试连接以验证配置。如果测试通过,我们点击创建。这是我们创建服务之前的新链接服务对话框的样子

成功创建服务后,我们可以在链接服务下看到它。

导入数据
在将数据导入 Synapse 工作区之前,我们需要创建 Spark 和 SQL 池来存储数据。创建这些池非常简单,我们可以在 Azure Synapse Studio 中完成此操作。
在 Azure Synapse Studio 中创建专用 SQL 池
在 Azure Synapse Studio 中,我们点击管理并选择SQL 池。在这里,我们看到一个无服务器 SQL 池已经存在。不过,我们对专用 SQL 池感兴趣,因此我们点击新建。

接下来,我们为专用 SQL 池(SynapseML)命名并选择其初始设置。默认情况下,性能级别为 DW1000c,这意味着 1,000 个数据仓库计算单元,每小时约 15.10 美元。在这里,我们必须在基于成本预算的容量与性能要求之间进行权衡。为了本文的目的,我们选择 DW100c。

在下一步,附加设置中,我们可以使用现有数据或创建一个空池。我们将通过选择“无”作为数据源来创建一个空池,然后继续查看 + 创建以创建该池。

当我们的专用 SQL 池创建成功后,我们将继续创建 Spark 池。
创建 Spark 池
创建 Spark 池与创建 SQL 池几乎相同。在 Azure Synapse Studio 中,我们导航到管理选项卡并选择Apache Spark 池。目前没有可用的池,因此我们通过点击新建来创建一个。

接下来,我们为 Spark 池(SynapseML)命名并选择基本设置。我们选择节点大小(小型、中型、大型、超大型或超超大型),启用或禁用自动伸缩,并选择节点数量。我们必须在预算和性能之间做出权衡。
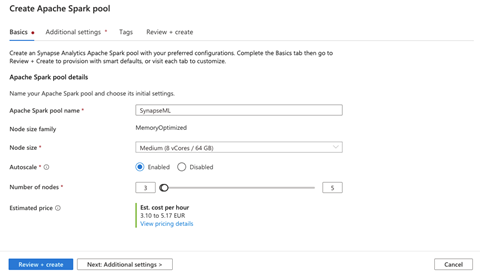
现在,我们点击下一步:其他设置。

在此页面上,我们可以进一步自定义 Spark 池。例如,我们可以启用或禁用自动暂停,并指定当没有活动作业时 Spark 在关闭集群之前应等待多长时间。
我们还可以选择要使用的 Apache Spark 版本。在撰写本文时,Apache Spark 3.0 仍在预览中。
我们还可以使用配置文件配置 Apache Spark 并指定任何其他池属性。
为简单起见,我们将对其余字段使用默认设置。审查设置后,我们点击创建。
Spark 池成功部署后,我们应该在Apache Spark 池下看到它。

我们的 Spark 池现在已经就绪,但我们的底层存储仍然为空。接下来,让我们将一些数据上传到 Azure Data Lake Storage,然后将其导入 Spark 池。
将数据上传到 Azure Data Lake Storage
Azure Synapse 提供了一个简单的界面,可以将数据文件上传到 Azure Data Lake Storage。
在 Synapse Studio 中,我们选择数据中心,然后选择“已链接”部分。在这里,我们找到了主要的 Azure Data Lake Storage Gen2 帐户。我们发现我们的存储是空的。要上传数据,我们点击上传。

在上传文件对话框中,我们选择要上传的数据文件。为了演示,我们将使用我们从 Kaggle 下载的开源金县房屋销售,美国数据集。

选择要上传的文件后,我们点击上传以将数据上传到 Azure Data Lake Storage。

将数据从 Azure Data Lake 导入 Spark 表
Azure Synapse Analytics 使用户只需点击几下即可轻松地将数据从 Azure Data Lake Storage 导入 Spark 表。首先,我们右键单击数据文件,然后从新建笔记本下选择新建 Spark 表。

然后我们将笔记本单元格的代码替换为以下代码并运行它
%%pyspark
df = spark.read.load('abfss://synapsedemoml@synapsedemoml.dfs.core.windows.net/kc_house_data.csv', format='csv'
, header=True
)
df.write.mode("overwrite").saveAsTable("default.kchouse")
我们将整个数据集加载到名为“kchouse”的 Spark 表中。我们可以使用以下代码查看表的内容
display(df.limit(10))
下一步是什么?
本文向我们展示了如何创建 Azure Synapse Analytics 工作区、Azure 机器学习工作区和 Azure 机器学习链接服务。然后,我们将数据从底层存储导入到 Spark 表中。
在所有配置和数据都就绪之后,我们将探讨如何使用训练好的模型丰富我们的房地产数据并围绕预测分析进行工作。继续阅读本系列最后一篇文章,以使用机器学习工具。
如需更深入的 Azure Synapse 培训,请注册观看 Azure Synapse Analytics 实践培训系列。