
AI 增强的数据科学与 Azure Synapse Analytics 第三部分:训练和使用模型以及丰富数据
5.00/5 (2投票s)
在本文中,我们将探讨如何使用预训练模型丰富数据,并从 Spark 表触发 Auto ML 实验。
在此三部分系列文章中,我们讨论了 Azure Synapse Analytics 和 Azure Machine Learning (ML) 如何结合使用,帮助数据科学家及其他人员在没有机器学习和编码经验的情况下探索他们的数据。首先,我们设置了 Azure Synapse Analytics 工作区、Azure Machine Learning 工作区和 Azure Machine Learning 链接服务,然后将我们的房屋销售数据导入 Spark 表以为机器学习做好准备。
本文将承接上一部分的内容,重点介绍 Azure Machine Learning。我们将探讨如何使用预训练模型丰富数据,并从 Spark 表触发 Auto ML 实验。这些操作将帮助我们分析美国国王县的房屋销售数据,从而更好地了解西雅图地区的房价。
让我们直接开始。
训练无代码 Auto ML 模型
Azure Machine Learning 与 Azure Synapse Analytics 的集成使我们能够直接在 Synapse Studio 中使用 Spark 表中的数据无缝训练模型。我们可以使用完整的数据块,也可以在训练模型之前对数据进行预处理。由于我们在上一篇文章中加载了大量数据集,为了节省时间和资源,我们将减小其维度后再将其输入 ML 模型。
假设我们只对数据中的少数几列感兴趣,例如卧室数、浴室数、楼层数、临水、景观、状况和建造年份(yr_built)来预测房屋价格。我们使用以下代码仅选择这些列,并将它们的数据类型从字符串更改为适当的类型。
from pyspark.sql.functions import *
df_reduced=df.select(col("price").cast("double"),col("bedrooms").cast("int"),col("bathrooms").cast("int"),col("floors").cast("int"), col("waterfront").cast("int"), col("view").cast("int"), col("condition").cast("int"))
同样,我们可以使用 `display` 函数查看将要输入模型的数据。

让我们检查一下架构,以确认我们的数据集现在已处于正确的形状。
df_reduced.printSchema()

最后,但同样重要的是,我们将上述缩减后的数据集保存到 Spark 表中。
df_reduced.write.mode("overwrite").saveAsTable("default.kchousereduce")
使用 Spark 表中的数据训练 AutoML 模型
要触发 AutoML 模型训练,我们首先选择 Spark 表,然后点击 **…** 激活菜单。

接下来,我们导航到 **Machine Learning**,然后选择 **Enrich with new model**(使用新模型丰富)。

**Enrich with new model** 使我们能够配置 Azure Machine Learning 实验。几乎所有字段都已预先填充。我们将其保持不变,并使用默认设置。但是,我们需要指定 Target column(目标列)。我们选择我们要预测的特征,例如 price(价格)。
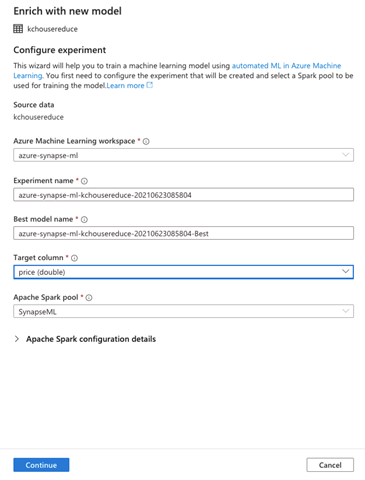
我们还可以配置 Apache Spark 的详细信息。我们展开 **Apache Spark configuration details**(Apache Spark 配置详细信息),然后选择 Executors(执行器)(2)和 Executor size(执行器大小)(Small,小型)。

设置好这些详细信息后,我们点击 **Continue**(继续)。
接下来,我们需要 **Choose a model type**(选择模型类型)。由于我们正在尝试预测一个连续的数值,我们将选择 Regression(回归),然后点击 **Continue**(继续)。

**Configure regression model**(配置回归模型)页面使我们能够提供和配置最适合我们用例的模型参数。在这里,我们将 Primary metric(主要指标)选择为 Spearman correlation(斯皮尔曼相关系数)、Normalized root mean squared error(标准化均方根误差)、R2 score(R2 分数)或 Normalized mean absolute error(标准化平均绝对误差)。在此,我们选择 Spearman correlation(斯皮尔曼相关系数)。
我们还可以指定 Maximum training job time(最大训练作业时间)、Max concurrent iterations(最大并发迭代次数)和 ONNX model compatibility(ONNX 模型兼容性)。为了演示,我们将 Maximum training job time(最大训练作业时间)减少到 0.5 小时,并启用 ONNX model compatibility(ONNX 模型兼容性),因为 Synapse Studio 目前仅支持 ONNX 模型。

在开始训练之前,请注意,Synapse Studio 还允许您在笔记本中打开 Auto ML 集成实验。因此,例如,如果您点击上图中可见的 **Open in notebook**(在笔记本中打开),Synapse Studio 将在笔记本中打开具有我们指定详细信息的实验。
供参考,我们的实验在笔记本中的外观如下。
automl_config = AutoMLConfig(spark_context = sc,
task = "regression",
training_data = dataset,
label_column_name = "price",
primary_metric = "spearman_correlation",
experiment_timeout_hours = 0.5,
max_concurrent_iterations = 2,
enable_onnx_compatible_models = True)
我们可以选择运行笔记本,或者直接点击 **Create run**(创建运行)。Azure Synapse Studio 现在将提交 AutoML 运行。

运行成功提交时,Synapse Studio 会通知您。您也可以在 Azure Machine Learning 门户中查看它。

由于我们在 Azure Synapse Analytics 中运行 AutoML 实验,在 Azure Machine Learning 门户中查看时,**Compute target**(计算目标)将显示为 **local**(本地)。我们还可以查看单个运行的详细信息。我们转到 **Models**(模型)选项卡,查看 AutoML 在运行期间构建的模型列表。模型列表按降序排列,最好的模型列在最前面。

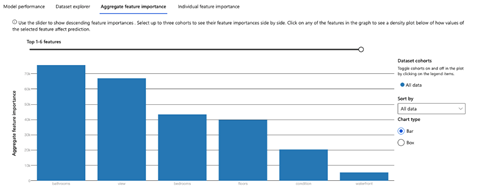
您可以选择任何模型,然后点击 **View Explanations**(查看解释)以打开一个包含模型解释的选项卡。您还可以选择 **Aggregate feature importance**(聚合特征重要性)以查看数据集中最重要的特征。
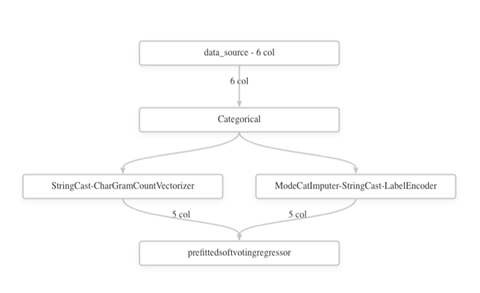
此外,您还可以查看 AutoML 应用的数据转换。我们转到 **Data transformation (preview)**(数据转换(预览))来查看图像。
使用预训练模型丰富数据
一旦我们的 AutoML 模型准备就绪,我们就可以使用它执行预测,例如预测房屋价格。让我们开始将测试数据导入 SQL 池。
将数据导入专用 SQL 池
我们需要以与之前上传数据集相同的方式将另一个数据集上传到 Azure Data Lake Storage。您可以使用任何您喜欢的数据集,但我们建议您使用本教程中创建的测试数据集。
让我们转到 Synapse Studio 中的 **Data**(数据)中心,然后选择 **Linked**(链接)选项卡。在那里,我们选择主存储帐户,然后点击 **Upload**(上传)以上传数据集。

我们选择数据集并完成上传。

我们的下一步是将此数据复制到我们的专用 SQL 池。首先,让我们在 SQL 池中创建一个相应的表,用于加载我们的数据。
在 Synapse Studio 中,我们导航到 **Data**(数据)中心,在 **Databases**(数据库)下展开 **SynapseML (SQL)**。要创建新表,我们从 **Tables**(表)操作菜单 (**…**) 中选择 **New SQL script**(新 SQL 脚本),然后点击 **New table**(新表)。

Synapse Studio 现在将启动一个新脚本文件。我们用以下代码替换文件内容。
CREATE TABLE [dbo].[PricePrediction]
(
[bedrooms] [int] ,
[bathrooms] [int] ,
[floors] [int] ,
[waterfront] [int] ,
[view] [int] ,
[condition] [int] ,
[price] [bigint]
)
当查询成功后,我们将继续将数据从 Azure Data Lake 复制到 SQL 表。为此,我们导航到 **Integrate**(集成)中心,点击 **+**,然后点击 **Copy Data tool**(复制数据工具)来启动复制管道向导。

接下来,我们遵循用户界面 (UI) 指南,为复制管道提供配置。
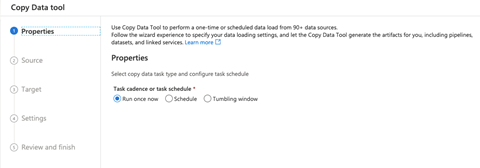
我们将底层存储选择为源 **Connection**(连接),并选择我们之前上传的 **test_pricing** 文件。

现在我们来审查源数据集的配置。您还可以点击 **Preview data**(预览数据)来验证您是否拥有正确的数据。

接下来,我们选择 Target(目标)。我们将把数据复制到我们之前创建的 SQL 表。

我们仔细审查列映射,因为这是一个关键步骤。如果我们的列映射不正确,则复制数据管道将失败。验证一切正常后,我们点击 **Next**(下一步)。

在 **Settings**(设置)页面上,我们只需要为我们的任务提供一个名称。例如,“CopyDataToSQLTable”。

最后,我们审查并完成复制数据管道的配置。

现在我们部署管道。部署成功后,我们就可以完成并运行管道了。为此,我们点击 **Finish**(完成)。

当管道成功运行时,数据将加载到相应的表中。

我们可以通过运行以下查询来验证数据是否已成功复制。

使用预训练模型丰富 SQL 池中的数据
接下来,我们将使用我们训练的预测模型来丰富刚刚创建的 SQL 表中的数据。
首先,我们移至 **Data**(数据)中心,并展开 SQL 表的操作菜单 (**…**)。

我们从菜单中选择 **Machine Learning**,然后选择 **Enrich with existing model**(使用现有模型丰富)。

**Enrich with existing model** 对话框显示我们在 Azure Machine Learning 中训练过的模型。但是,它仅列出了与 ONNX 兼容的模型。
我们从列表中选择所需的模型,然后点击 **Continue**(继续)。

在下一页中,我们将看到列映射。列已映射,因此我们进行验证并点击 **Continue**(继续)。

在下一页上,我们需要为过程命名。Synapse Studio 在我们运行脚本时创建该过程。
我们还需要选择丰富数据的 **Target table**(目标表)。我们可以选择一个现有表,或者 **Create new**(创建新表)。在这里,我们选择一个新表,因此我们也要指定表的名称。

该过程的最后一步是点击 **Deploy model + open script**(部署模型 + 打开脚本)。Azure Synapse Analytics 在我们点击该按钮时发送有关进度的更新,例如“正在上传您的模型”。

部署完成后,Synapse Studio 会打开脚本供我们审查和运行。我们将以下内容替换脚本的内容。
CREATE PROCEDURE [dbo].[housepricprediction]
AS
BEGIN
SELECT
CAST([bedrooms] AS [bigint]) AS [bedrooms],
CAST([bathrooms] AS [bigint]) AS [bathrooms],
CAST([floors] AS [bigint]) AS [floors],
CAST([waterfront] AS [bigint]) AS [waterfront],
CAST([view] AS [bigint]) AS [view],
CAST([condition] AS [bigint]) AS [condition]
INTO [dbo].[#PricePrediction]
FROM [dbo].[PricePrediction];
SELECT *
FROM PREDICT (MODEL = (SELECT [model] FROM [dbo].[testpredictions] WHERE [ID] = 'azure-synapse-ml-kchousereduce-20210623051203-Best:1'),
DATA = [dbo].[#PricePrediction],
RUNTIME = ONNX) WITH ([variable_out1] [real])
END
GO
EXEC [dbo].[housepricprediction]
现在我们运行脚本,以在测试数据上获得预测值。

使用 Azure Cognitive Services 丰富数据
Azure Synapse Analytics 还与其他 Azure 和第三方服务集成,包括 Azure Cognitive Services。目前,我们可以选择在 Synapse Studio 中进行情绪分析或异常检测。在我们开始之前,我们首先需要配置 Azure Cognitive Services 以便与 Azure Synapse Analytics 协同工作。
创建认知服务资源
Azure Cognitive Services 提供多种机器学习解决方案。在这里,我们将使用异常检测。
首先,我们转到 Azure 门户,在 Marketplace 中搜索 Anomaly Detector 资源。然后,我们点击 **Create**(创建)以开始创建 Anomaly Detector 服务。

在 **Create Anomaly Detector**(创建 Anomaly Detector)对话框中,我们选择 Subscription(订阅)、Resource group(资源组)、Pricing tier(定价层)和 Name(名称)。然后,我们点击 **Next: Virtual Network**(下一步:虚拟网络)。

为了简单起见,我们将允许所有网络访问此资源。

我们将保留其余选项卡的默认设置,然后转到 **Review + create**(审核 + 创建)以部署资源。

我们的下一步是配置访问和密钥。我们点击 **Go to resource**(转到资源),然后导航到 **Keys and Endpoint**(密钥和终结点)。此选项卡包含我们将用于访问 Cognitive Service API 的密钥。最佳做法是将它们存储在 Azure Key Vault 中以确保安全。

接下来,我们将创建一个 Azure Key Vault 来存储访问密钥。
创建 Key Vault 以配置密钥和访问
由于我们目前没有预配 Azure Key Vault 服务,我们将简单地在 Azure 门户中创建一个 Key Vault。
**Create key vault**(创建 Key Vault)对话框使我们能够配置项目和实例详细信息。请确保选择包含您的 Cognitive Service 的订阅和资源组。
我们为 Key Vault 输入名称,并选择适当的区域和定价层。我们保留其余字段的默认设置,然后点击 **Next: Access policy**(下一步:访问策略)。

**Access policy**(访问策略)选项卡允许我们添加和配置所有访问策略。确保为您的 Azure Synapse 工作区添加访问策略(如果还没有),并允许它从 Azure Key Vault 读取密钥。

这是 **Add Access Policy**(添加访问策略)页面的外观。

在我们的访问策略就绪后,我们转到 **Networking**(网络)。

在这里,我们为我们的用例选择适当的终结点设置。我们将保留其余字段的默认设置,然后转到 **Review + create**(审核 + 创建)。
创建 Key Vault 后,我们转到我们的资源,然后在 **Secrets**(密钥)下点击 **Generate/Import**(生成/导入)。
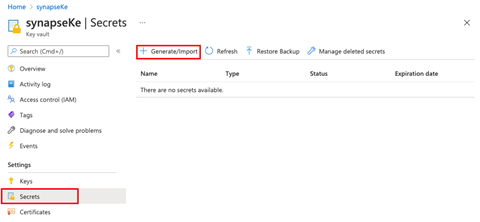
在这里,我们为我们的密钥输入一个名称。此名称很重要,因为稍后我们将使用它来连接到我们的 Azure Synapse 工作区。
**Value**(值)字段包含我们要保存的密钥值。首先,复制 Anomaly Detector 服务中的任意一个密钥值,并将其粘贴到 **Value**(值)中。接下来,将密钥切换为 **Enabled**(启用),然后点击 **Create**(创建)以在您的 Key Vault 中保存密钥值。

在 Azure Synapse Analytics 中创建 Azure Key Vault 链接服务
我们的最后一步是在 Azure Synapse Studio 中创建 Azure Key Vault 链接服务。为此,我们在 Synapse Studio 中打开我们的工作区,转到 **Manage**(管理)选项卡,然后选择 **Linked services**(链接服务)。然后,我们点击 **New**(新建)以开始创建我们的新链接服务。
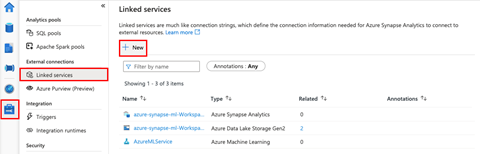
在下一页上,我们搜索“Azure Key Vault”。

我们选择 Azure Key Vault,然后点击 Continue(继续)。
接下来,我们需要将我们的新链接服务(Azure Key Vault)指向我们刚刚创建的 Key Vault。我们为链接服务命名,并选择我们的 Azure Subscription(Azure 订阅)和 Azure key vault name(Azure Key Vault 名称)。然后,我们点击 **Test Connection**(测试连接)以验证我们的链接是否成功。如果连接成功,我们点击 **Create**(创建)。

现在,我们准备在 Synapse Studio 中尝试 Azure Cognitive Services。
使用 Cognitive Services 设置异常检测
对于异常检测,我们将首先创建测试数据。从 Azure Synapse Studio,我们导航到 **Develop**(开发)部分,点击 **+**,然后创建一个新的 **Notebook**(笔记本)。

接下来,我们将以下代码输入笔记本单元格并运行它以创建测试异常数据。不要忘记将笔记本附加到 Spark 池。
from pyspark.sql.functions import *
df = spark.createDataFrame([
("2018-01-01T00:00:00Z", 500.0),
("2018-02-01T00:00:00Z", 200.0),
("2018-03-01T00:00:00Z", 800.0),
("2018-04-01T00:00:00Z", 900.0),
("2018-05-01T00:00:00Z", 766.0),
("2018-06-01T00:00:00Z", 805.0),
("2018-07-01T00:00:00Z", 800.0),
("2018-08-01T00:00:00Z", 20000.0),
("2018-09-01T00:00:00Z", 838.0),
("2018-10-01T00:00:00Z", 898.0),
("2018-11-01T00:00:00Z", 957.0),
("2018-12-01T00:00:00Z", 924.0),
("2019-01-01T00:00:00Z", 881.0),
("2019-02-01T00:00:00Z", 837.0),
("2019-03-01T00:00:00Z", 9000.0),
("2019-04-01T00:00:00Z", 850.0),
("2019-05-01T00:00:00Z", 821.0),
("2019-06-01T00:00:00Z", 2050.0),
("2019-07-01T00:00:00Z", 10.0),
("2019-08-01T00:00:00Z", 765.0),
("2019-09-01T00:00:00Z", 1100.0),
("2019-10-01T00:00:00Z", 942.0),
("2019-11-01T00:00:00Z", 789.0),
("2019-12-01T00:00:00Z", 865.0),
("2020-01-01T00:00:00Z", 460.0),
("2020-02-01T00:00:00Z", 780.0),
("2020-03-01T00:00:00Z", 680.0),
("2020-04-01T00:00:00Z", 970.0),
("2020-05-01T00:00:00Z", 726.0),
("2020-06-01T00:00:00Z", 859.0),
("2020-07-01T00:00:00Z", 854.0),
("2020-08-01T00:00:00Z", 6000.0),
("2020-09-01T00:00:00Z", 654.0),
("2020-10-01T00:00:00Z", 435.0),
("2020-11-01T00:00:00Z", 946.0),
("2020-12-01T00:00:00Z", 980.0),
], ["datetime", "value"]).withColumn("group", lit("group1"))
我们可以打印新创建数据的架构以进行验证。
df.printSchema()

让我们将此数据保存到我们的 Spark 表。
df.write.mode("overwrite").saveAsTable("anomaly_detection_data")
在保存数据后,我们接下来进入有趣的部分。我们将使用 Anomaly Detector Cognitive Service 来丰富此表。
丰富表
要丰富我们的表,我们导航到 Synapse Studio 的 **Data**(数据)选项卡,然后选择我们刚刚创建的表。接下来,我们通过点击 **…** 激活操作菜单,然后从菜单中选择 **Machine Learning**,再选择 **Enrich with existing model**(使用现有模型丰富)。

**Enrich with existing model** 使我们可以在两个支持的 Cognitive Services 之间进行选择。在这里,我们选择 **Anomaly Detector**,然后点击 **Continue**(继续)。

在下一页上,我们需要指定模型的配置。**Granularity**(粒度)表示采样数据的速率。我们将选择 monthly(每月)。然后,我们选择 **Timestamp column**(时间戳列)、**Time series value column**(时间序列值列)和 **Grouping column**(分组列)的值,然后点击 **Open notebook**(打开笔记本)。
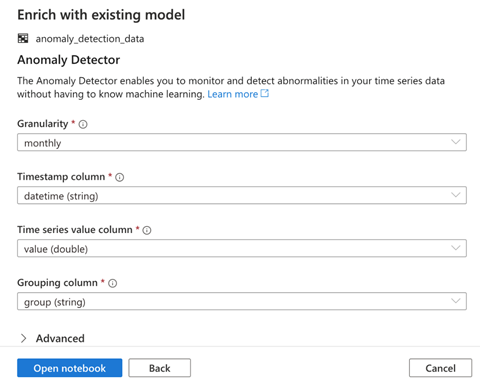
现在我们观察打开的笔记本。该笔记本使用 MMLSpark 连接到 Cognitive Services。
import mmlspark
if mmlspark.__spark_package_version__ < "1.0.0-rc3":
raise Exception("This notebook is not compatible with the current version of mmlspark: {}. Please upgrade to 1.0.0-rc3 or higher.".format(
mmlspark.__spark_package_version__))
另外,请注意,我们之前提供的 Azure Key Vault 详细信息将安全地访问 Cognitive Services 资源。该资源将加载指定 Spark 表中的数据,运行异常检测,然后显示结果。
from mmlspark.cognitive import *
from notebookutils import mssparkutils
# Fetch the subscription key (or a general Cognitive Service key) from Azure Key Vault
service_key = mssparkutils.credentials.getSecret("synapseKe", "synapse-cognitive-service", "AzureKeyVaultLinkedService")
# Load the data into a Spark DataFrame
df = spark.sql("SELECT * FROM default.anomaly_detection_data")
anomalyDetector = (SimpleDetectAnomalies()
.setLocation("northeurope")
.setSubscriptionKey(service_key)
.setOutputCol("output")
.setErrorCol("error")
.setGranularity("monthly")
.setTimestampCol("datetime")
.setValueCol("value")
.setGroupbyCol("group"))
results = anomalyDetector.transform(df)
# Show the results
display(results.select("datetime", "value", "group", "output.*", "error").limit(10))
我们点击 **Run all**(全部运行)以查看结果。


结论
这一系列文章向您介绍了 Azure Synapse Analytics 的机器学习功能。我们学习了如何集成 Azure Machine Learning 和 Azure Synapse Analytics。我们还探索了使用预训练模型以及 Azure Cognitive Services 来丰富数据集。最后但同样重要的是,我们使用 AutoML 训练了一个无代码预测机器学习模型。我们使用这些技术分析了房屋销售数据。
Azure Synapse Analytics 帮助数据科学家和机器学习工程师以最少的代码丰富数据集和训练机器学习模型。这项集成服务支持所有专业水平的用户,使他们能够执行复杂的数据科学和机器学习任务,而无需担心底层细节。
要了解有关 Azure Synapse Analytics 的更多信息,请注册观看 Azure Synapse Analytics 实操培训系列,然后应用这些机器学习技术来获取数据洞察。这个深入的网络研讨会系列将教您如何开始使用您的第一个 Synapse 工作区,构建无代码 ETL 管道,直接连接到 Power BI,连接和处理流数据,使用无服务器和专用查询选项,以及更多内容。