
制作简单数据管道 第4部分:使用GitHub Actions进行CI/CD
5.00/5 (3投票s)
使用Github Actions自动集成ETL变更并重新发布您的数据集
通过GitHub Actions和CI/CD原则,我们可以为我们简单管道的持续开发、测试和部署构建一个高效可靠的工作流程。
想自己试试吗?首先, 注册bit.io 以即时访问免费的Postgres数据库。然后克隆 GitHub仓库 并尝试一下!
可操作的工作流程
管道维护充其量可能很乏味,最坏的情况下容易出错。一旦管道投入使用,它就需要持续的更改来修复错误、添加新的必需功能,并跟上不断变化的外部数据源。
每次更改,我们都需要完成一系列任务,包括编写代码、运行测试和更新输出数据库,同时管理软件版本和任务顺序依赖。将这些因素混合在一起,很容易测试错误的软件版本或将错误的更改部署到生产环境。
幸运的是,我们可以构建一个变更管理工作流程并添加自动化,以减少持续管道更改的乏味性和出错倾向。
在本文中,我们将构建一个工作流程,它结合了持续集成/持续部署(CI/CD)原则和GitHub Actions自动化,以管理我们从第 一、二 和 三 部分开始的简单管道的持续更改。我们将从简要介绍GitHub Actions开始。

通过将CI/CD原则和自动化与GitHub Actions相结合,我们可以实现更快的迭代和更少的错误,同时进行持续开发。我们将解释并为维护简单管道构建此工作流程。
什么是GitHub Actions?
GitHub Actions是用于软件开发工作流的事件驱动的任务自动化器。例如,当打开一个将开发分支合并到另一个分支的拉取请求时(*驱动事件*),GitHub Actions可以用来执行一个单元测试脚本(*自动化任务*)。
GitHub Actions由事件触发。常见事件包括推送提交、打开拉取请求或定期cron计划。
一个事件会触发一个GitHub Actions工作流。工作流可以包含一个或多个作业,每个作业是一系列步骤。作业可以按顺序或并行运行,但作业内的步骤始终按顺序运行。在本文中,每个工作流只有一个作业。

Actions包含在步骤中,这些步骤按顺序在作业中运行,作业包含在由事件触发的工作流中。
每个作业都由指定的运行器执行,运行器是您自己的机器上的计算环境,或者是由GitHub托管的机器。我们在实现中将使用GitHub托管的运行器(在发布时,在使用限制内免费)。
每个步骤都包含一个Action,它可以是命令的已发布单元,例如“checkout a repo”或适合配置运行器的自定义命令。例如,如果运行器已安装Python并且有一个名为hello_world.py的脚本,我们的步骤可以运行自定义命令python hello_world.py。
每个GitHub Actions工作流都在相关仓库中的YAML文件中配置。下面的示例在每次将新提交推送到GitHub上的主分支时运行简单管道的一部分。
一个示例工作流,它检出仓库,安装依赖项,并仅在新泽西时报病例和死亡率数据集(来自第1部分)上运行简单管道。
在工作流级别,我们在第1行指定一个名称**ETL Example**,在第2-5行指定驱动事件on push to branch main,并在第7-28行指定一个作业。
在作业级别,我们在第8行指定最新的GitHub托管的Ubuntu运行器。我们还在第10-12行为主运行器设置了一些环境变量,包括存储在GitHub作为Secret的bit.io连接凭据。
在作业内部,我们指定步骤来
- 检出仓库。
- 设置Python。
- 安装Python依赖项。
- 运行简单管道的一部分,将COVID病例和死亡率加载到bit.io。
前两个步骤使用GitHub Actions 市场上的Action,这是一个由其他开发人员发布的用于通用操作(如将仓库检出到运行器)的Action仓库。后两个步骤使用直接在工作流文件中指定的自定义命令。
将工作流文件提交到我们仓库的主分支并推送到GitHub后,工作流按预期运行,并将新泽西时报数据集重新加载到bit.io。下面的屏幕截图显示了GitHub控制台中的工作流执行摘要和日志。

GitHub控制台中“Actions”选项卡中“ETL example”工作流的屏幕截图。在这里,我们可以看到所有步骤都已成功完成。我们还展开了简单管道步骤的日志。
这个简单的例子说明了GitHub Actions自动化的核心概念,但还没有帮助我们的开发工作流。然而,在我们构建自动化工作流之前,我们还需要介绍一些持续集成/持续部署(CI/CD)概念。
什么是CI/CD?
CI/CD是持续集成/持续部署(或持续交付)的缩写。关于定义这些术语范围的论述不计其数。我们将优先考虑基本概念而非全面覆盖,并展示如何将这些基本概念应用于我们简单的管道。
持续集成(CI)是指使用自动化频繁构建、测试和合并代码更改到共享存储库中的分支。CI的基本动机是追求比大型、不频繁的集成事件(同时解决许多开发者的多项更改)更快的开发人员迭代和变更部署。
持续部署(CD)是指使用自动化频繁地重新部署软件项目。CD的基本动机是让运维团队摆脱耗时且易出错的手动部署过程,同时快速将变更推送到用户。对于我们的批量处理管道,部署仅仅意味着在主分支上推送更改后重新运行管道以更新数据库。这确保了数据库始终反映推送到主分支的最新管道版本的输出。
CI/CD可以通过具体的例子更容易解释。让我们看看如何使用GitHub Actions将CI/CD集成到我们简单的管道中。
用于CI的拉取请求操作
持续集成涉及自动化代码的构建和测试,以便能够频繁地从开发分支合并到共享存储库。
开发人员使用拉取请求提交更改以合并到共享分支,拉取请求可用作事件来触发GitHub Actions的自动化CI测试。如果自动化测试通过,审阅者可以批准拉取请求以进行合并。如果自动化测试失败,提交的开发人员可以向开发分支推送修复,从而触发测试自动重新运行(下面的步骤3-5)。
我们通过在打开一个提交更改到主分支的拉取请求(3)后,使用GitHub Actions(4)自动测试我们的开发分支管道来演示CI实践。除了运行单元测试和数据测试外,自动化测试还会执行整个开发分支管道,并将输出加载到bit.io上的开发存储库中,这实际上是一个端到端的集成测试。测试满意后,审阅者可以批准拉取请求(5)进行合并。
我们可以修改示例工作流文件来实现此自动化、由拉取请求驱动的测试。文件越来越长,但只引入了几个新想法。
- 第3行 — 驱动事件现在是提交到main的拉取请求,而不是推送。
- 第12行 — 我们现在正在加载到bit.io上的开发存储库,名为“
simple_pipeline_dev”。我们可以端到端地运行管道的开发版本,而不会影响“simple_pipeline”主存储库中的已发布数据集。 - 第24-25行 — 我们的单元测试套件在开发分支的代码上运行。
- 第25-45行 — 我们现在正在加载第1部分中的所有三个数据源 ,而不仅仅是一个示例。
- 第47-51行 — 我们添加了在bit.io上运行的加载后SQL作业,以更新一个报告表,显示加利福尼亚州的COVID病例和死亡率、疫苗接种以及按县划分的人口。
此工作流现在由拉取请求驱动,而不是推送到main,并添加了所有三个表加载以及加载后的SQL作业。第24-25行显示了运行开发分支代码单元测试的关键附加步骤,而数据测试则集成在第27-45行的简单管道步骤中。最后,请注意,加载和SQL作业都应用于一个单独的开发存储库“simple_pipeline_dev”,以便测试不会干扰已发布的生产环境。
现在,当我们打开一个提交到主分支的拉取请求时,工作流会自动运行,并显示“检查”的结果,如下图所示的成功结果屏幕截图。
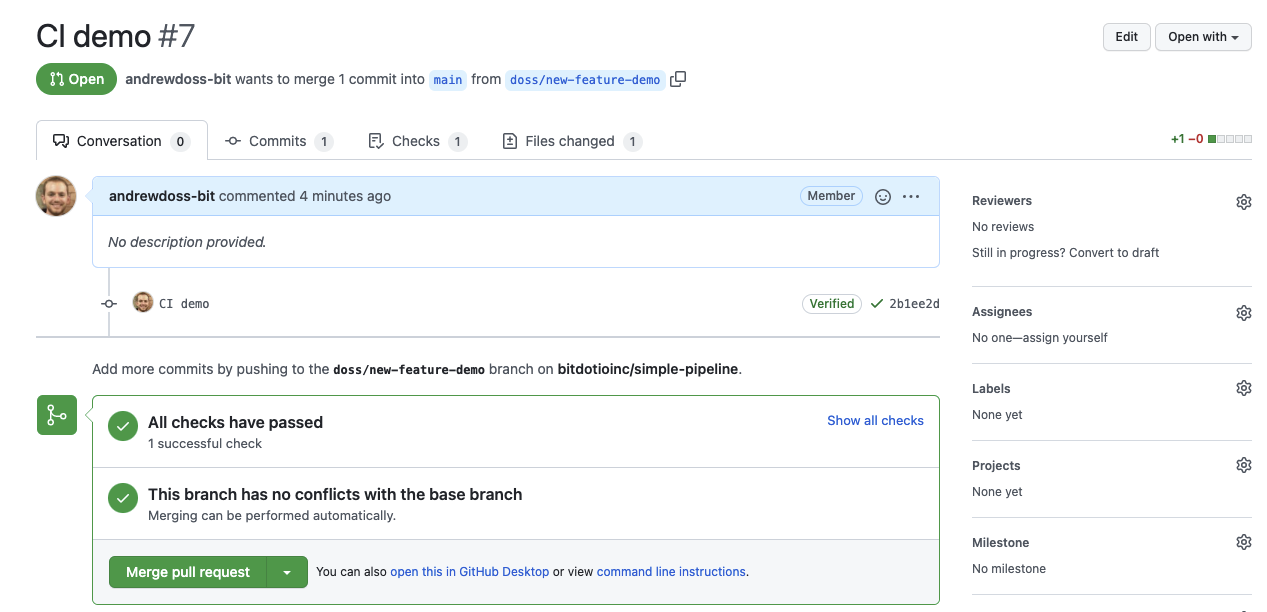
下面,我们显示了上面拉取请求驱动的成功自动化测试工作流的摘要。您可以看到来自第3部分 的7个单元测试用例的日志,并且所有单元测试在管道运行前都已通过。

我们可以在GitHub控制台的Actions选项卡中监控自动化测试工作流的进度和结果。在这里,我们展示了在管道将数据加载到bit.io上的开发存储库之前运行的成功单元测试步骤的日志。
最后,我们可以检查bit.io上的开发存储库,并确认数据集已按预期更新。

通过检查开发存储库“simple_pipeline_dev”中的加载表和派生报告,我们可以确认我们的开发管道已成功端到端运行,而没有干扰主“simple_pipeline”存储库的状态。
如果此时我们感到满意,我们可以将更改合并到主分支,然后继续重新部署我们的主管道。
用于CD的推送操作
持续部署是指使用自动化频繁地重新部署软件项目。
在我们的例子中,我们可以添加第二个GitHub Actions工作流,它会在每次将新提交推送到主分支时重新运行我们的主管道并更新bit.io上的主存储库。这可以节省时间,更快地将我们的更改推送到已发布的数据库,并确保主分支上的最新提交与数据库状态一致。
此部署工作流仅需要对拉取请求测试工作流进行一些更改。
- 第5行 — 驱动事件现在是推送到主分支(包括合并拉取请求)。
- 第12行 — 数据现在加载到主“
simple_pipeline”存储库。 - 第22行 — 单元测试已被删除,因为它们已经在拉取请求集成测试期间运行。
我们的第二个部署工作流仅需要对拉取请求测试工作流进行一些更改。我们已将驱动事件更改为推送到主分支,将加载指向主“simple_pipeline”存储库,并删除了已在拉取请求集成工作流期间运行的单元测试。

在审查了更改并看到它们通过了自动化集成测试后,我们合并了拉取请求(通常,非作者的开发人员会批准拉取请求)。
下面,我们展示了GitHub Actions控制台中主管道成功重新运行的摘要。

合并拉取请求后,我们触发了主部署工作流,该工作流成功执行了更新的管道,并将数据重新加载到bit.io上的主“simple_pipeline”存储库。
最后,我们可以检查bit.io上的主存储库,并确认数据集已按预期更新。
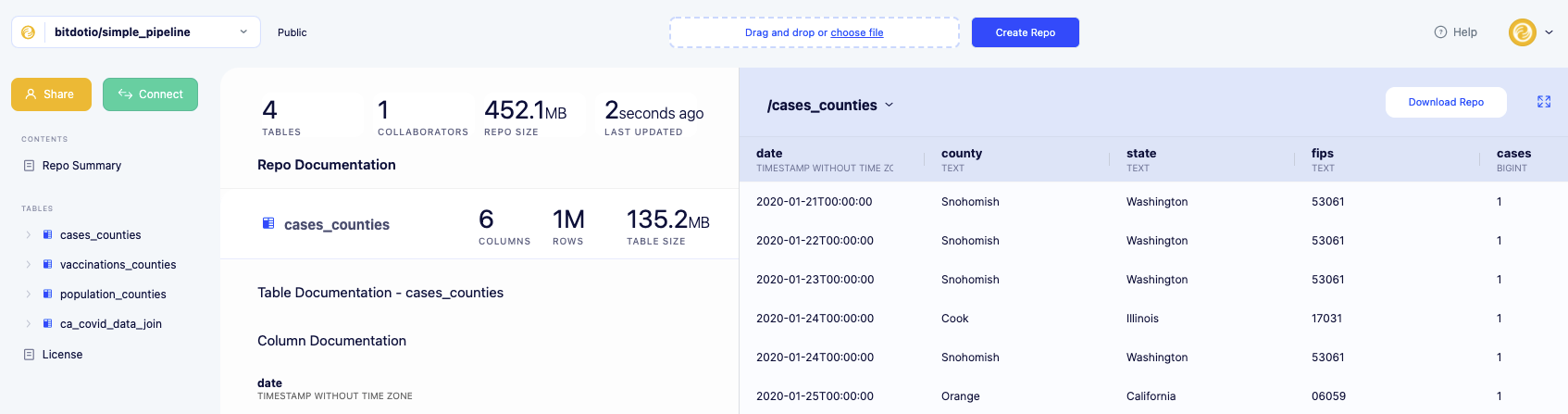
通过检查主存储库“simple_pipeline”中的加载表和派生报告,我们可以确认我们的开发管道已成功端到端运行,而没有干扰主“simple_pipeline”存储库的状态。
结论
好了!我们已经构建了一个具有CI/CD功能的自动化工作流,该工作流管理我们进行持续管道更改的步骤。您可能已经注意到一些我们尚未处理的细节,例如,管理多个开发人员的并行更改和强制执行审阅者。但是,我们这里使用的概念可以应用于构建更复杂的工作流,以处理这些和其他细节。
最后一个细节 — 您还可以使用主部署工作流来安排管道的每日重新运行,方法是在现有的推送事件驱动程序旁边添加一个cron计划事件。但是,GitHub托管的Actions并非用于通用的部署后计算服务,因此您可能需要考虑使用工作流来更新您自己机器上的计划作业,或者在您自己 的GitHub Actions主机上运行重复管道。
如果您还没有这样做,我们邀请您注册bit.io以即时访问免费的私有Postgres数据库,克隆GitHub仓库,并尝试处理您需要的数据集!
对未来的Inner Join出版物和相关的bit.io数据内容感兴趣?请考虑订阅我们的每周新闻通讯。
附录
系列概述
本文是关于构建一个简单而有效的ETL管道的四部分系列文章的一部分。我们尽量少使用ETL工具和框架,以保持实现简单并专注于基本概念。每一部分都引入了一个新的概念,以构建完整的管道,该管道位于这个仓库中。
其他注意事项
本系列旨在通过简单易用的实现来说明ETL模式。为了保持这种关注点,一些细节已留给本附录。
- 最佳实践 — 本系列文章省略了一些用于构建健壮的生产管道的重要实践:暂存表、增量加载、容器化/依赖项管理、事件消息/警报、错误处理、并行处理、配置文件、数据建模等。有很棒的资源可供学习如何将这些最佳实践添加到您的管道中。
- ETL vs. ELT vs. ETLT — ETL模式可能带有特定的ETL流程,为每个最终用例加载精确表的含义。在现代数据环境中,许多转换工作发生在数据仓库加载之后。这导致了“ELT”或冗长的“ETLT”一词。简单来说,您可能希望将加载前的转换保持轻量级(如果有的话),以便在数据仓库内迭代转换。
继续阅读
我们写了一整套关于ETL管道的文章!在这里查看