
ArrayFire 与 oneAPI、库和 OpenCL 的互操作性
5.00/5 (1投票)
在本文中,我们将探讨如何将 oneAPI 深度神经网络 (oneDNN) 库和基于 SYCL 的数据并行 C++ (DPC++) 编程语言集成到现有代码库中。
oneAPI 极大地简化了异构加速器上的开发。通过一次编写、随处运行的方法,API 提供了一种强大的代码开发方式。ArrayFire 是一个 GPU 库,它已经为许多计算领域提供了大量有用的功能。它与 oneAPI 带给软件开发世界的理念相同。在本文中,我们将探讨如何将 oneAPI 深度神经网络 (oneDNN) 库和基于 SYCL 的数据并行 C++ (DPC++) 编程语言集成到现有代码库中。我们的目标是让程序员能够利用 oneAPI,避免在迁移到新编程模型时经常需要的代码重写。
与 SYCL 的互操作性
oneAPI 是 DPC++ 和库的组合,旨在简化跨架构并行编程。这些库与 DPC++ 语言紧密集成。它们都提供了多种方法来与底层的 OpenCL 实现进行互操作。基础语言提供了三种主要的 OpenCL 互操作方法,涵盖了大多数用例(图 1)。互操作函数的流程可以是从现有代码到 SYCL,反之亦然,具体来说:
- 通过从内核字符串创建内核对象,在 DPC++ 代码中使用现有 OpenCL 内核
- 从现有 SYCL 对象中提取 OpenCL 对象
- 从现有 OpenCL 对象中创建 SYCL 对象
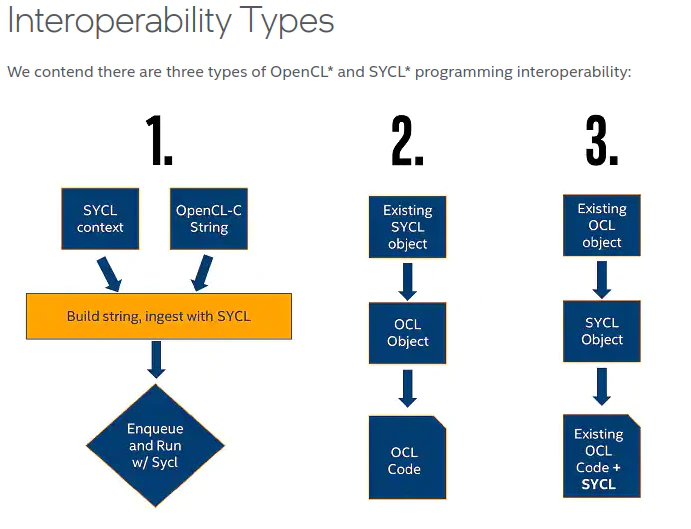
让我们考虑如何将现有 ArrayFire 代码库与这些互操作选项集成。在第一种情况下,我们可以直接重用原始 ArrayFire 内核(图 1,左)
queue q{gpu_selector()}; // Create command queue targeting GPU
program p(q.get_context()); // Create program from the same context as q
// Compile OpenCL vecAdd kernel, which is expressed as a C++ Raw String as indicated by R”
p.build_with_source(R"( __kernel void existingArrayFireVecAdd(__global int *a, __global int *b, __global int *c)
{
int i = get_global_id(0);
c[i] = a[i] + b[i];
} )");
// buffers here ...
q.submit([&](handler& h) {
// accessors here...
// Set buffers as arguments to the kernel
h.set_args(A, B, C);
// Launch vecAdd kernel from the p program object across N elements.
h.parallel_for(range<1> (N), p.get_kernel("vecAdd"));
});
实际上,ArrayFire 内核依赖于比简单缓冲区更复杂的数据结构,因此以这种方式重用内核并不像复制粘贴 CL 字符串那么简单。我们需要使用其他两种方法之一来处理数据交换。
第二种方法(图 1,中)是从 SYCL 对象中提取 OpenCL 组件,它基于在现有 SYCL 对象上使用 .get() 方法的简单约定。对 SYCL 对象的每次调用都将返回相应的底层 OpenCL 对象。例如,cl::sycl::queue::get() 将返回一个 OpenCL cl_command_queue。
第三种方法(图 1,右)接受现有 OpenCL 对象并使用它们创建 SYCL 对象。这可以通过 SYCL 对象的构造函数完成,例如 sycl::queue::queue(cl_command_queue,…)。在这些情况下,构造函数还将保留 OpenCL 实例,以在构造期间增加 OpenCL 资源的引用计数,并在销毁 SYCL 对象期间释放该实例。
与 oneAPI 库的互操作性
oneAPI 库中存在类似的互操作约定。某些库,例如 oneMKL,直接依赖于 DPC++ 互操作性。它们的函数可以接受统一共享内存 (USM) 指针。其他库,例如我们将在示例中使用的 oneDNN,提供类似的 .get() 和 constructor() 机制。
oneDNN 的数据结构与 DPC++ 相似但略有不同。sycl::device 和 sycl::context 组合成一个 dnnl::engine 对象,而 dnnl::stream 则取代了 sycl::queue。尽管存在这些差异,OpenCL 互操作性的机制保持不变。OpenCL 对象可以通过 getter 函数获取,而新的 oneDNN 对象可以通过其构造函数从现有 OpenCL 对象创建。oneDNN 还提供了具有相同功能的显式互操作头文件。
oneDNN 在其支持的运行时后端方面具有灵活性。它可以使用 OpenCL 运行时或 DPC++ 运行时来与 CPU 和 GPU 引擎交互。开发人员可能需要将 oneDNN 与使用 OpenCL 或 DPC++ 的其他代码一起使用。为此,该库提供了 API 扩展以与相应的底层对象进行互操作。根据目标,互操作性 API 在 dnnl_ocl.hpp 或 dnnl_sycl.hpp 头文件中定义。对于我们的用例,我们有兴趣用 ArrayFire 库提供的现有预处理功能补充 oneDNN 推理引擎的功能。目前,这将通过 OpenCL 互操作函数完成。
ArrayFire 和 oneDNN:详细信息
我们将用于探索 OpenCL 与 oneDNN 互操作细节的示例是基于 cnn_inference_f32.cpp 示例。此示例使用 oneDNN 设置 AlexNet 网络进行推理。我们的目标是利用 ArrayFire 的许多 OpenCL 图像处理函数来预处理用户输入图像,然后将数据提供给现有推理引擎。完整的工作流程包括以下步骤:
- 包含相关的互操作头文件
- 创建 GPU 引擎,同时与 ArrayFire 共享 cl_context
- 通过 OpenCL 互操作接口创建 GPU 命令队列
- 使用 ArrayFire 执行预处理和数据准备
- 创建 GPU 内存描述符/对象
- 通过 OpenCL 互操作接口访问 GPU 内存作为输入
- 创建 oneDNN 原语/描述符/内存以构建网络
- 像往常一样使用 oneDNN 执行网络
- 释放 GPU 内存
我们首先需要添加到文件中的是 ArrayFire 和 oneDNN 的互操作头文件。OpenCL 头文件也包含在内。
#include "oneapi/dnnl/dnnl.hpp" // oneDNN header
#include "oneapi/dnnl/dnnl_ocl.hpp" // oneDNN OpenCL interop header
#include <CL/cl.h> // OpenCL header
#include <arrayfire.h> // ArrayFire header
#include <af/opencl.h> // ArrayFire OpenCL interop header
接下来,我们将从 ArrayFire 获取 OpenCL 上下文和队列,以便与 oneDNN 共享
cl_device_id af_device_id = afcl::getDeviceId();
cl_context af_context = afcl::getContext();
cl_command_queue af_queue = afcl::getQueue();
OpenCL 对象将用于创建相应的 oneDNN 对象。这将使用 互操作头文件中定义的互操作函数。这些函数位于额外的 ocl_interop 命名空间中。请记住,这将使对象在 oneDNN 范围的整个生命周期中保持不变
dnnl::engine eng = dnnl::ocl_interop::make_engine(af_device_id, af_context);
dnnl::stream s = dnnl::ocl_interop::make_stream(eng, af_queue);
然后我们可以加载和预处理图像,重用 ArrayFire 库的加速 GPU 函数
// create empty array within same context as oneDNN
af::array images = af::constant(0.f, h, w, 3, batch);
images = read_images(directory);
images = af::resize(images, 227, 227) / 255.f; // resize to alexnet input size
// and normalize [0-1]
images = af::reorder(images, 3, 2, 0, 1); // hwcn -> nchw
... // additional preprocessing
oneDNN 最终需要 dnnl::memory 对象。这不是原始内存,而是具有额外元数据(例如 dnnl::descriptor)的内存。oneDNN 支持缓冲区和 USM 内存模型。缓冲是默认设置。要构造具有互操作支持的 oneDNN 内存对象,我们将使用以下 互操作函数
ocl::interop make_memory(
const memory::desc& memory_desc, // descriptor describing memory shape and layout
const engine& aengine, // our interop engine
memory_kind kind, // buffer or USM
void* handle = DNNL_MEMORY_ALLOCATE // handle to underlying storage
)
这里,描述符遵循示例中的描述符,我们期望 AlexNet 的输入是 227 x 227 的 NCHW 图像。引擎只是我们一直在 ArrayFire 和 oneDNN 之间共享的执行引擎。内存类型应该指定我们是使用 USM 还是缓冲区接口。如果选择传入句柄指针,它应该与我们传入的内存类型匹配。如果句柄是 USM 指针或 OpenCL 缓冲区,则 oneDNN 库不拥有缓冲区,用户负责管理内存。使用特殊的 DNNL_MEMORY_ALLOCATE 值,库将代表用户分配一个新的缓冲区。
oneDNN 同时支持缓冲区和 USM 内存模型,因此用与 ArrayFire 共享的对象替换引擎和队列将导致不兼容的内存创建模式。在创建 dnnl::memory 对象时,可能会发生以下错误
oneDNN error caught:
Status: invalid_arguments
Message: could not create a memory object
必须使用互操作函数,而不是默认的 dnnl::memory 创建方法,如下所示
cl_mem *src_mem = images.device<cl_mem>(); // get cl_mem from arrayfire
dnnl::memory user_src_memory = ocl_interop::make_memory( // interop mem function
{{conv1_src_tz}, dt::f32, tag::nchw}, // create descriptor
eng, // specify engine
ocl_interop::memory_kind::buffer, // specify memory type
*src_mem); // pass cl_mem handle
这适用于所有默认 dnnl::memory 分配实例。必须使用指定 ocl_interop::memory_kind::buffer 的互操作函数
ocl_interop::make_memory(descriptor, engine, ocl_interop::memory_kind::buffer);
最后,加载所有权重后,可以像往常一样创建和调用推理原语。网络运行后,我们应该释放我们负责的资源
// additional alexnet network setup
// loading of weights following cnn_inference_f32.cpp
...
// execute all primitive steps for full inference using our inputs
for (size_t i = 0; i < net.size(); ++i) {
net.at(i).execute(s, net_args.at(i));
}
s.wait(); // wait until stream finishes writing to memory
images.unlock(); // return memory ownership to arrayfire to free resources
我们希望确保 oneDNN 使用 OpenCL 运行时而不是 DPC++ 运行时。这可以通过指定 SYCL_DEVICE_FILTER=opencl 环境变量来实现。有关参考,可以在 此 gist 中找到修改后可用的 cnn_inference_f32.cpp。
结论
oneAPI 提供了将现有 OpenCL 代码库与新的异构编程方法集成所需的所有工具。底层的 OpenCL 对象可以在 DPC++ 之间双向共享。oneAPI 的库有自己的方法来处理互操作任务。通过细微的代码更改,可以重用整个 OpenCL 库,而不是重写。oneAPI 通过避免对已有有用代码的重复开发工作来节省未来的开发时间。