
如何设计实用的类型系统以最大化软件开发项目的可靠性、可维护性和生产力 / 第1部分:是什么,为什么,以及如何?
5.00/5 (6投票s)
这是关于设计实用类型系统的系列文章的第一部分。
目录

引言
类型系统是每种编程语言的基础和核心部分,深刻地决定了代码的编写和维护方式。
精心设计的类型系统使开发人员能够编写简洁、易懂、可靠、可维护和安全的代码。
这是系列文章的第一篇。整个系列旨在回答以下问题:
-
什么是实用类型系统?
-
我们需要哪些特性,为什么需要它们,以及它们有什么好处?
-
哪些特性不应该被支持(即使它们在现代编程语言中很受欢迎)?
-
实用类型系统如何影响源代码的外观和感觉?
-
我们是否已经拥有实用类型系统?
本系列文章的目标读者是那些对编写可靠、可维护和安全代码感兴趣的软件开发人员,以及编程语言工程师。
什么是实用类型系统?
我们将查看许多源代码示例,演示类型系统如何帮助编写更好的代码。但首先,我们需要定义本文中使用的以下术语:类型、基数、类型系统和实用类型系统。
类型
类型是一组值的名称。
例如,许多编程语言支持名为boolean的类型。此类型可以包含两个值:true和false。使用集合的数学符号,元素集合是:{true, false}。
基数
类型的基数是其值集合中不同值的数量。
例如,boolean类型的基数为2,因为它有两个值:true和false。
正如我们很快将看到的,基数在实用类型系统的设计中起着举足轻重的作用。
类型系统
类型系统的作用是:
-
提供始终可用的预定义原生类型(例如,
string、number、boolean等)。 -
提供一套机制和规则,使开发人员能够定义其软件开发项目所需的新特定类型。
例如,类型系统使我们能够创建名为
product的记录类型,包含字段id、description和price。 -
定义不同类型如何协同工作(类型兼容性、类型转换等)。
实用类型系统
这是我对实用类型系统的定义:
引用一个实用类型系统必须满足两个条件:
简单!条件
它很容易做到:
定义具有尽可能低基数的新类型。
通过查看源代码中的定义快速理解类型。
更改和维护类型。
快速失败!条件
尽可能在编译时立即检测到无效值、类型不兼容和其他与类型相关的错误。
如果无法在编译时检测到错误,则必须尽快在运行时检测到。
— PTS 设计规则
此后,我将上述定义称为PTS 设计规则,其中PTS代表实用类型系统。
乍一看,上述定义可能显得过于简单,因为我没有提到诸如静态类型、语义类型、空安全、错误处理、默认不可变性等重要特性。然而,正如我们稍后将看到的,上述定义确实是我们所需要的一切。在接下来的文章中,我们将一遍又一遍地应用PTS 设计规则,以发现实用类型系统所需的所有特性和规则。
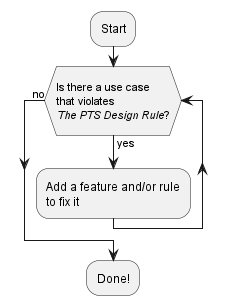
下面的流程图说明了该过程:
我们为什么需要它?
引用一个好的类型系统就像拥有编译时单元测试一样。
— 斯科特·弗拉辛
在本节中,我们将探讨良好类型系统的以下众所周知(和不那么众所周知)的优点:
-
增强表达能力
-
更可靠、可维护的代码
-
IDE 和工具的更好支持
-
更通用、可复用的代码
-
更高效的代码
-
支持“先数据,后代码!”方法
注意
熟悉这些优点的经验丰富的程序员可以跳到最后一项。
增强表达能力
考虑在具有使用动态类型(例如 JavaScript、Lisp、Lua、Python、Ruby)的类型系统的编程语言中的函数签名。这是一个 JavaScript 示例:
function makeCoffee ( milk, sugar, quantity ) {
// body
}
这段代码缺乏表达力!
仅仅通过函数签名,我们不知道如何使用这个函数。有很多相关的问题,例如:
-
这个函数是做什么的?“冲咖啡”是什么意思?函数返回什么?它只是产生副作用并且不返回任何东西吗?
-
我们应该如何使用输入参数
milk?它是一个布尔值,还是我们想添加的牛奶量,或者可能是一个描述牛奶种类和数量的对象? -
等等。
更好的命名会有所帮助,但让我们看看使用静态类型语言(例如 C、C++、C#、Go、Haskell、Java、Kotlin、Rust)的相同函数签名。下面的代码是用 Java 编写的:
CupOfCoffee makeCoffee ( boolean milk, boolean sugar, int quantity ) {
// body
}
好多了!
我们可以清楚地看到函数(或 Java 术语中的方法)返回一个CupOfCoffee对象。如果我们需要更多信息,我们可以查看CupOfCoffee的定义。如果我们使用现代 IDE,我们可以从上下文菜单中选择跳转到定义,IDE 会立即打开源代码文件(无需我们指定文件位置)。
我们还可以看到milk和sugar是boolean输入参数,因此我们可以推断它们表示我们是否想添加牛奶和糖。
然而,我们不知道如何使用quantity。
这是我们想要的咖啡杯数吗?可能不是,因为函数返回一个单独的CupOfCoffee,而不是一个List<CupOfCoffee>
它是一个枚举值吗(例如 1 = 小号,2 = 中号,3 = 大号)?可能不是,因为那样的话应该使用 Java 的enum类型。
那么quantity的单位是什么?是毫升、厘升,还是盎司?
quantity的有效范围是多少?如果quantity为零,函数会返回null吗?如果为quantity提供负值会发生什么?
注意
上面的例子并非旨在暗示“静态类型语言优于动态类型语言”。两种方法都有其优缺点,取决于具体情况。例如,动态类型在某些情况下可能更灵活。然而,经验证据表明,静态类型明显提高了可靠性和可维护性,尤其是在大型项目中。
在一个表达力更强的类型系统中,如果我们能这样编写代码,所有歧义都会消失:
fn make_coffee -> cup_of_coffee
in milk boolean
in sugar boolean
in quantity milliliters ( range = 50 .. 300 ) default: 200 !milliliters
// body
.
注意
以上示例采用了一种新的语法编写,将在后续文章中解释。
更可靠、可维护的代码
我们假设makeCoffee实际上是按最后一个示例所示的方式工作的:它接受boolean值作为输入milk和sugar,以及一个范围从50到300毫升的integer值作为输入quantity。
现在假设 Bob(团队中的新程序员)不知道这一点。为了得到一杯不加牛奶和糖的咖啡,他这样调用函数:
makeCoffee ( "no", "no", 1 )
问题:编译时会发生什么?运行时会发生什么?
这些都是关键问题!
这两个问题的答案都是:这取决于类型系统!
我们先来看看 JavaScript 中发生了什么。
JavaScript 主要由解释器实现,因此没有编译时(尽管运行时可能会使用 JIT 编译器来提高性能)。
运行时会发生什么?
函数期望milk是一个boolean值。然而,Bob 提供了一个string值。JavaScript 应用了一种容易出错的技术,称为隐式类型转换,并使用所谓的真值和假值。例如,任何非空字符串都被认为是真值。因此,如果函数包含一个if ( milk ) { ... } else { ... }语句,那么如果milk包含字符串"no",then分支就会执行。所以 Bob 会得到一杯加了牛奶的咖啡,这与他想要的完全相反!
这一切的最终结果是,Bob 点了一杯黑咖啡(不加牛奶和糖),结果却得到了一杯牛奶、糖和1毫升咖啡的混合物!
Java(和其他静态类型语言)呢?
幸运的是,上述结果在 Java 中不会发生,因为类型系统不允许它发生。语句
makeCoffee ( "no", "no", 1 )
...将立即导致编译时错误,因为string不能赋值给boolean输入参数。
这正是我们想要的!我们希望类型系统帮助我们,并尽快报告错误。
有人可能会说上面的示例代码只是一个有趣的玩具示例,只对娱乐读者有用,没有人会写出如此愚蠢的代码。然而,事实是,愚蠢的错误在现实世界中确实会发生。实践表明,它们一直都在发生。它们的可能性随着项目的规模和复杂性而显著增加,并且可能受到各种因素的影响,例如领域复杂性、经理和开发人员的专业知识、需要编写和维护的代码量、用于检测和解决错误的工具和流程等等。
为了练习起见,只需想象一下在管理药品制造过程的复杂软件应用程序中出现上述错误。用错误的成分生产药品就不再有趣了。这个错误可能导致死亡,而这本可以通过使用具有更好类型系统的编程语言来编写可靠的代码来预防。
这是我的个人经验:尽管我编程已经几十年了(而且仍然热爱它),但我仍然会犯一些愚蠢的错误。我犯的错误比我开始写代码时要少,但我仍然无法编写无错误的代码。我的一些编码错误不仅仅是“愚蠢”——它们是“非常愚蠢”。我需要一个类型系统来保护我(尽可能地)避免自找麻烦。
我想我不是一个人。
也许有一些天才能够编写完全没有 bug 的代码,但我不是这样精英群体中的一员。我怀疑这样的人会是非常罕见的异类。
例如,考虑一位参与太空任务项目的高度合格的软件开发人员。他或她绝不会在不首先检查值是否过高的情况下,将一个64位浮点数强制转换为一个16位有符号整数值,因为那会很愚蠢,对吧?对,但这正是导致阿丽亚娜5号火箭在1996年爆炸的原因。这只是维基百科条目软件错误列表中一个后果极其严重的例子。
我们都会犯错,这没关系。这正是我们为什么需要能够自动检测不可避免的人为错误(包括愚蠢错误)的类型系统的原因。
IDE 和工具的更好支持
一个好的类型系统使 IDE 能够提供更好的编辑支持。一些例子是:
-
在编辑时自动报告 bug
-
更好的代码补全
-
安全自动重构,例如重命名类型
-
跳转到类型定义
-
显示类型的所有用法
我们都喜欢这些功能,因为它们极大地提高了我们的生产力,并使编写和维护代码的过程变得更加愉快。
其他工具(例如,静态代码分析器)也可以利用源代码或二进制代码中可用的类型信息,并提供更复杂的功能,例如检测额外的 bug 和安全问题,报告和/或纠正编码风格违规,或创建特定于项目的报告和统计信息。
更通用、可复用的代码
在运行时读取类型信息的能力(称为内省/反射)使我们能够编写更通用、可重用的代码。
例如,如果可以在运行时检查集合的元素类型,则可以编写通用实用函数:
注意
这个主题本身就值得一篇专门的文章,我计划在未来某个日期发表。
更高效的代码
一个好的类型系统使得编译器能够优化生成的二进制文件,从而实现:
-
更小的目标代码大小
-
更快的执行时间
1. 数据;2. 代码
还有一个不那么为人所知的支持实用类型系统的论据。
聪明的程序员告诉我们,我们应该始终先定义数据结构及其关系,然后再编写代码。我们应该先定义数据,然后编写代码。
- Data
- 代码
以下是一些知名人士的引言,他们深知自己在说什么:
引用我强烈主张围绕数据设计代码,而不是反过来,我认为这是 Git 相当成功的原因之一。
糟糕的程序员担心代码。好的程序员担心数据结构及其关系。
— Linus Torvalds,Linux 和 Git 的创建者;Git 邮件列表,2006-07-27
注意
有关 Git 中使用的数据结构的更多详细信息,请参阅:Hacker News 上的评论(尤其是 cmarschner 的第一条),以及 Linus 的第一个README 文件,其中描述了数据结构(以典型的 Linus 风格)。
引用表征规则:将知识折叠成数据,这样程序逻辑就可以是愚蠢而健壮的。
数据主导一切。如果你选择了正确的数据结构并组织得当,算法几乎总是显而易见的。数据结构,而不是算法,是编程的核心。
— 《Unix 编程艺术》,作者 Eric Steven Raymond
《Unix 哲学基础》部分中的表示规则:基本原则
注意
您可以在我2018年4月发表的文章成功软件开发人员的基本实用主义的“数据设计”部分中找到更多引述。
精心设计的数据结构可带来更简单、更易维护的代码、更少的 bug、更好的性能和更少的内存消耗。
这种差异可能非常显著,以至于它可能决定项目的成败。
注意
数据驱动编程的概念与上述1. 数据;2. 代码规则相关,但并不相同。
认识到定义数据是第一步,我们需要问:
我们用什么来定义数据?
答案当然取决于软件架构和开发环境,但通常情况下,我们使用编程语言的类型系统来定义数据结构及其关系。因此,一个合适的类型系统是必不可少的工具,它使我们能够以简洁、富有表现力、精确、可靠和可维护的方式定义数据。因此,类型系统通常在新软件项目开始时扮演重要角色,尤其是当涉及许多不同的数据结构时。
更重要的是,精心设计和可维护的数据在软件开发和维护周期中扮演着重要角色。例如,后期加入团队的新软件开发人员,如果能看到简洁、富有表现力、精确的类型定义,就能更快地理解应用程序的内部工作原理,从而快速理解允许哪些值。
弗雷德·布鲁克斯这样说(括号内的文字是为了澄清):
引用给我看你的流程图[代码],藏起你的表格[数据结构],我仍会感到困惑。给我看你的表格[数据结构],我通常就不需要你的流程图[代码]了;它们将不言自明。
— Brooks, F. P. (1995). The Mythical Man-month: Essays on Software Engineering. Pearson Professional.
它是如何工作的?
为了理解 PTS 的要旨,我们首先看一个真实的例子,以清晰地展示我们想要实现的目标。
然后我们将更仔细地研究PTS 设计规则中至关重要的“快速失败!”条件。
示例
假设我们要为产品分配质量等级。有五个等级:
worst, bad, medium, good, and best。
在 Java 中,我们可以定义一个enum类型Quality,如下所示:
public enum Quality {
WORST, BAD, MEDIUM, GOOD, BEST // Note: In idiomatic Java,
// enum values are defined in uppercase letters.
}
我们可以立即同意,定义Quality类型是容易的。我们能够用最简洁的代码表达我们想要的东西。
因此,PTS 设计规则的第一个条件(简单!条件)得到了满足:定义、理解和维护我们的类型是容易的。
现在我们验证第二个条件(“快速失败!”条件):“无效值、类型不兼容和其他与类型相关的错误应尽可能在编译时立即检测到。”
有效值可以赋值给Quality类型的变量,如下所示:
Quality productQuality = Quality.GOOD;
让我们尝试分配一个无效值:
Quality productQuality = Quality.QUITE_GOOD;
Java 编译器立即报告错误,因为QUITE_GOOD是一个无效值:
Tests.java:15: error: cannot find symbol
Quality productQuality = Quality.QUITE_GOOD;
^
symbol: variable QUITE_GOOD
location: class Quality
更好的是,如果使用智能 IDE,我们会在编辑时收到错误,这很棒。在 IntelliJ™ IDEA(一款出色的 Java 项目 IDE)中,屏幕如下所示(请注意修复 bug 的建议):

这正是我们想要的!
让我们尝试另一种错误:
Quality productQuality = "GOOD";
同样,编译器立即报告错误,因为我们试图将String类型的值赋给Quality类型的变量。
“快速失败!”条件也显然得到了满足。
我们可以得出结论,类型Quality是一个很好的例子,可以演示实用类型系统应该如何工作。该类型易于定义、理解和维护(条件1),并且编译器捕获所有类型错误(条件2)。此外,如果使用智能IDE,所有错误都会在编辑时立即报告,并且IDE会显示有用的消息来修复错误。太棒了!
Quality类型完全符合PTS 设计规则。
我们的目标是为所有类型实现这种卓越水平。然而,正如我们将在本系列接下来的文章中看到的,这相当具有挑战性。
快速失败!
注意
熟悉重要“快速失败!”原则的读者可以跳过本节。
尽管简单!条件(PTS 设计规则的第一个条件)很容易理解,但让我们看一个简单的例子,说明快速失败!条件(PTS 设计规则的第二个条件)的完整含义:
引用尽可能在编译时立即检测到无效值、类型不兼容和其他与类型相关的错误。
如果无法在编译时检测到错误,则必须尽快在运行时检测到。
— PTS 快速失败!条件
假设在一个便携式应用程序(运行在 Linux、MacOS 和 Windows 上)中,需要删除临时文件 temp/secret/passwords.txt(其中包含纯文本密码!),但源代码意外地在文件路径中使用了无效字符 ::
fileToDelete = "temp/secret:passwords.txt"
^
这显然是无效数据的情况。
注意
字符:在 Windows 中是无效字符,但在 Linux 中不是无效字符,即使此字符在 Linux 上用作路径分隔符。为了本示例的缘故,我们假设在文件路径中:是无效的,即使应用程序运行在 Linux 上也是如此。
一个有趣的问题出现了:会发生什么?
答案:这取决于类型系统!
在一个原始的类型系统中,IO 错误可以被忽略。如果源代码没有明确地测试 IO 错误,那么既不会在编译时,也不会在运行时生成错误。文件 temp/secret/passwords.txt 将简单地不会被删除,应用程序将愉快地继续执行,就好像在纯文本文件中暴露密码不是什么大问题,一切都很好一样。
在许多编程语言中,这个 bug 会导致应用程序稍后尝试访问文件时出现“文件未找到”运行时错误。然而,这里的“稍后”可能意味着“很久以后”。因此,如果应用程序在执行应该删除文件的指令之前崩溃或中断,那么文件将不会被删除,也不会生成错误。
在一个更好的类型系统中,当赋值fileToDelete = "temp/secret:passwords.txt"执行后(即,在访问操作系统上的文件之前),就会发生“无效文件路径”运行时错误。
一个理想的类型系统会在编译时报告 bug。
更好的是,如果使用现代 IDE 编写代码,bug 会在编辑时报告,并能立即在几秒钟内修复!
在一个完美的世界里,所有错误都能立即得到反馈。
但我们尚未达到那一步。实用类型系统能做到的最好情况是自动检测尽可能多的技术性错误。
以下是检测 bug 的时间,按从最好到最差的顺序列出:
-
编辑时
-
编译时
-
运行时立即
-
运行时稍后
-
Never
至此,应该很清楚 PTS 的目标是在编译时(如果使用智能 IDE,则在编辑时)捕获尽可能多的 bug。
如果无法在编译时检测到错误,则应尽快在运行时检测到。
现在假设这个有bug的文件路径(temp/secret:passwords.txt)不是硬编码的,而是从配置文件中读取的。在这种情况下,编译器无法报告bug。因此,配置文件中的错误应该在从文件中读取路径时立即捕获(而不是仅仅在删除文件时才捕获)。后续文章将展示类型系统如何促进数据输入验证。
请注意,在运行时检测到的 bug 可以通过单元测试捕获。这有助于在应用程序投入生产之前消除 bug。因此,即使语言具有高级类型系统,对单元测试的良好支持(超出本文范围)也是任何编程语言中必不可少的功能。一个好的类型系统并不能使单元测试变得可有可无。“如果它编译通过,它就能工作!”这只是痴心妄想。世界上没有哪个编译器能检测出诸如使用错误公式计算圆形面积之类的 bug。我们需要单元测试来检测这类 bug。
注意
您可以在我的文章软件开发中“快速失败!”原则介绍中阅读更多关于“快速失败!”原则的重要信息。
PTS 编码规则
几乎所有编程语言都允许我们编写可靠的代码。
但实践表明,在许多编程语言中编写可靠的代码具有挑战性,并且通常需要样板代码(如后续文章将展示)。这在很大程度上取决于类型系统。
正如已经看到的,实用类型系统的一个重要作用是尽可能地促进编写和维护可靠代码的过程。
然而,类型系统并不能在所有情况下都强制我们编写可靠代码。它只能在一定程度上做到这一点。
例如,类型系统不能强迫我们创建一个专用类型ISBN,该类型仅允许符合 ISBN 标准的有效值。如果我们决定对 ISBN 使用简单的字符串,从而允许诸如@#$之类的无意义值、诸如<script>alert("Hi! You've been hacked")</script>之类的恶意值以及其他邪恶值,那么类型系统对此无能为力。
只有当程序员真正使用可用的类型系统机制来定义安全类型时,才能实现最大可靠性。因此,除了PTS 设计规则,我们还需要以下简单的PTS 编码规则:
引用软件项目中的所有数据类型都应具有尽可能低的基数。
— PTS 编码规则
上述规则对于库/框架开发者尤其重要,因为这些包通常被许多其他开发者像黑盒一样使用 API。应尽可能保护标准库和第三方库的用户免受意外误用。
如果一个包使用具有尽可能低基数的安全类型,可以很容易地防止整类错误。
除了不允许无效值之外,专用的安全类型还提供针对语义类型错误的保护。
考虑以下 Java 代码:
String s1 = "Hello" // declare 's1' of type 'String', with value "Hello"
String s2 = s1 // declare 's2' of type 'String', with same value as 's1'
这段代码有 bug 吗?
嗯,没有明显的 bug,而且这段代码对编译器来说肯定是正确的。
现在我们只需更改变量名:
String message = "Hello"
String book_ISBN = message
代码现在明显是错误的("Hello"是一个无效的 ISBN),但编译器无法检测到这个 bug。
然而,通过使用专用且安全的ISBN类型,而不是String,可以轻松预防此 bug:
String message = "Hello"
ISBN book_ISBN = message
^^^^
好多了!编译器可以立即报告此 bug,因为String类型与ISBN类型不兼容。此外,高级类型系统的编译器会对book_ISBN = "Hello"这样的赋值生成错误,因为“Hello”是一个无效的 ISBN。
注意
以后发表的一篇文章将解释如何在 PTS 中创建和处理像ISBN这样的安全类型。
我们可以得出结论,我们需要PTS 设计规则和PTS 编码规则。它们是相辅相成的。设计规则旨在由语言设计者/实现者应用,而编码规则则适用于软件开发人员。
结论(到目前为止)
一个实用的类型系统使代码:
更易读写
更具表达力,更易懂
更可靠、更易维护、更安全
更小、更快
结果是它:
提高了软件质量和可靠性
减少了开发时间和成本
让编程更有趣
实用类型系统至关重要
下一步?
在下一篇文章中,我们将探讨 PTS 的目标和非目标、PTS 的历史、核心类型以及在实用类型系统中不应支持的“特性”。
然后,我们将反复应用PTS 设计规则,以发现所有必要的 PTS 特性和规则,从而帮助我们在更短的时间内编写可靠、可维护和安全的代码。
我们还将查看许多源代码示例,以说明在实现 PTS 的语言中源代码可能是什么样子。
本系列所有文章链接
以下列表将在本系列每篇文章发布后更新。
致谢
非常感谢Tristano Ajmone提供的宝贵反馈,以改进本文。
历史
- 2023-10-02:初始版本
- 2023-10-03:更改了最后一个 Java 示例
- 2023-10-18:添加了“本系列所有文章链接”部分
- 2023-11-14:添加了第3部分(记录类型)的链接
- 2023-11-29:添加了第4部分(联合类型)的链接
- 2024-03-15:添加了第5部分(空安全)和第6部分(错误处理)的链接
- 2024-06-29:添加了第7部分(我们应该根除空字符串——原因在此)的链接