
将智能应用提升到新水平:使用 Azure 机器学习实现高级功能(第 1 部分)
在这个由四部分组成的系列中,您将学习如何使用 Azure 容器应用创建智能应用。在第三部分中,您将探索如何通过使用自己的数据集训练自定义模型来提升您的智能应用。

在本系列文章的第一和第二部分中,我们探讨了如何使用Azure 容器应用构建智能应用,该应用集成了Azure AI 来对用户反馈进行情感分析。
在本第三个教程中,我们将准备通过使用目标数据训练自定义 AI 模型来增强我们创建的智能应用。此方法可帮助您根据应用程序的独特需求定制 AI,从而为您的用户提供更准确的情感分析。
解决方案架构
下图展示了我们在这两篇文章中旨在实现解决方案的架构。

使用 Azure 机器学习实现高级功能
Azure 机器学习是一个强大的基于云的平台,它使开发人员和数据科学家能够高效地构建、部署和管理机器学习模型。它提供了一套全面的工具和服务,以简化端到端的机器学习生命周期。
借助 Azure ML,我们可以准备、探索、清理和转换数据集以进行模型训练。该平台还提供了一系列内置算法和框架用于构建模型,例如 TensorFlow、PyTorch 和 scikit-learn,以及一个图形用户界面 (GUI) 来简化模型的创建和实验测试。
可扩展的计算资源,例如服务器和 GPU 集群,为这一过程提供动力,帮助在大型数据集上训练模型。Azure ML 协助将模型部署为 Web 服务或容器,使它们能够轻松集成到生产环境中。
与其他 Azure 服务的集成,例如 Azure Databricks 和 Azure Data Lake Storage,确保了数据摄取和集成到 ML 工作流的顺畅。
虽然像我们在本系列第一部分中使用的 Azure AI 模型这样的现成模型很方便,但它们可能无法捕捉到每个应用程序的复杂性,从而导致次优结果。开发自定义模型允许针对特定问题或数据集定制解决方案,从而提高准确性和相关性。
训练自定义模型还可以让我们更好地控制数据、特征和架构。这有助于性能优化、偏差缓解和模型微调,以满足不断变化的应用程序需求。
在本文中,我们将探讨如何通过以下方式从 Azure AI 情感分析 API 获得更好的结果:
- 使用 Azure ML Studio 和大量特定用户评论数据集训练我们自己的 AI 模型
- 创建支持模型开发的基础设施
- 加载我们的数据集并执行数据清理
- 构建和测试我们的模型训练管道
必备组件
要遵循本教程,我们需要:
- 下载第一部分创建的项目
- 一个Azure 帐户
- Docker Desktop 3.5.1 或更高版本
- 安装Visual Studio。此演示使用 Community Edition 2022。
要查看最终应用程序,请查看完整项目代码。
我们开始吧。
设置机器学习环境
在使用我们的数据构建训练管道之前,我们需要配置一个 ML 环境。导航到机器学习页面并使用您的 Azure 用户名和密码登录。
打开 Azure ML 会提示您创建一个工作区,其中包含工作区名称、关联的 Azure 订阅、资源组和区域。

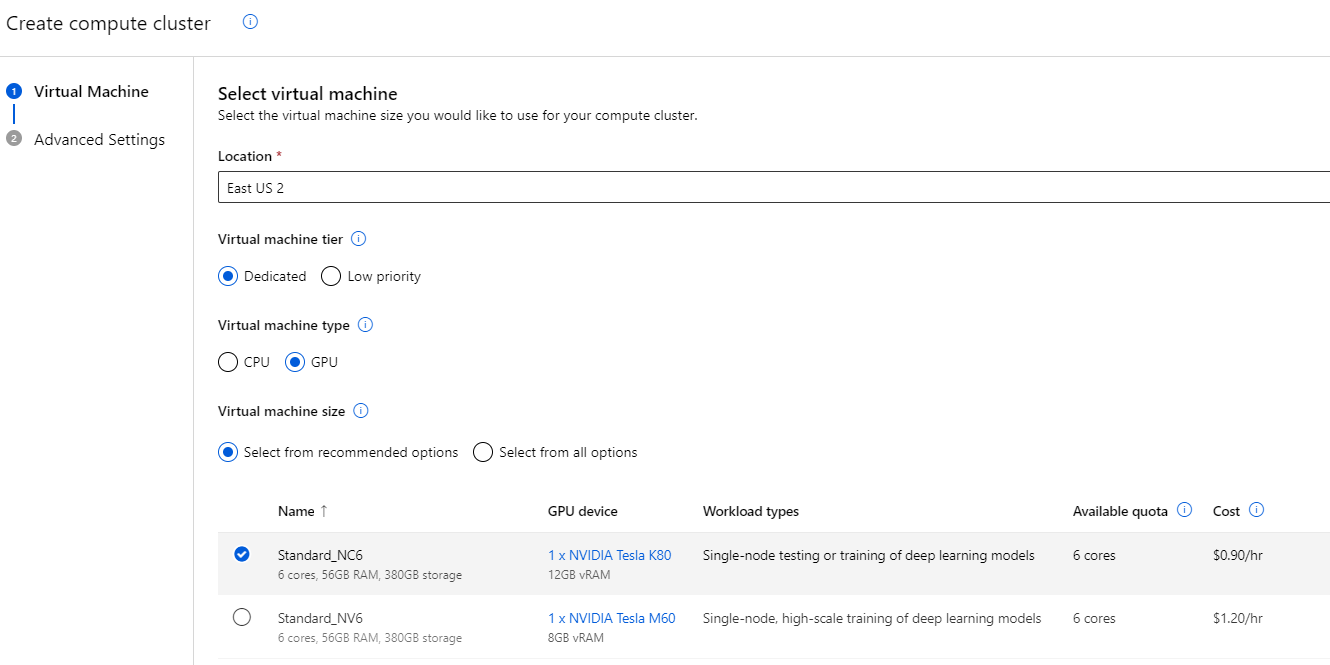
接下来,我们必须创建一些计算资源来训练我们的模型。Azure ML 提供两种选择:
- 单个计算实例 — 或虚拟机 (VM)
- 一个集群或可扩展虚拟机集
集群提供最大的灵活性,因此选择该选项。
建议为 VM 选择 GPU 类型,因为我们将使用自动化过程训练模型。由于 VM 选项总是在不断变化和更新,因此在您工作时可用选项列表可能有所不同。但关键是选择配备 GPU 的选项。这显著提高了性能,因为这些 AI 模型使用 GPU 指令更有效率。
如果基于 GPU 的 VM 不可用,您可以选择内存优化范围内的内存较大的实例,例如 Standard_E4ds_v4。但是,在这种情况下,请做好处理时间较长的准备。
使用 Azure 机器学习构建和训练模型
现在我们的基础设施已经到位,让我们开始构建和训练我们的模型。通常,在训练 AI 模型时,您拥有的数据越多,它的决策就越好。理想情况下,您还会使用应用程序生成的数据来构建此模型,以确保其根据您的用例量身定制。
因为我们没有特定的内部评论数据集,所以我们将使用 Kaggle 中的样本数据。具体来说,我们将使用亚马逊评论数据集的精简版来训练情感分析模型。这既能减少时间,又能提供有价值的见解。在实际场景中,您的数据集可能更大、更不完善,因此我们稍后将在 Azure ML 中回顾一些数据清理选项。
准备训练自定义 Azure 机器学习模型
首先,让我们将要使用的数据集添加到 Azure ML 中。创建一个名为“ReviewTrainingData”的新数据资产。

选择“从本地文件使用”,然后将 train.txt 文件上传到您的 Blob 存储桶中。接下来,单击“自定义分隔符”,选择“|”字符,并确保没有标题,因为我们的数据文件遵循此格式。
点击“下一步”查看 schema。第一列应设置为 Boolean,第二列应为评论文本。保存此数据集,并对 test.txt 文件重复此过程,将其命名为“ReviewValidationData”。

现在我们有了数据,让我们构建模型训练管道。从左侧菜单栏访问“管道”选项,然后选择“使用自定义组件创建新管道”。管道视图是我们配置数据操作、数据集清理、模型训练、验证和发布到终结点的地方。
我们可以向管道添加三个关键元素:
- 数据 — 这包含用于训练、验证和测试 AI 模型的数据资产。
- 模型 — 这包含预训练的 AI 模型,您可以将其集成到管道中以进行数据转换、操作或其他任务。
- 组件 — 这些是您用于帮助训练正在构建的模型的代码块。
我们的数据集已经干净,因此我们可以跳过转换和数据清理。如果需要,请查看 Azure 机器学习文档,以备将来使用。
接下来,我们将添加组件算法来训练我们的模型。Azure ML Studio 提供预构建的组件或自定义开发的组件选项。这些组件是 Azure ML 用于数据训练的构建块——代码或现有模型。它们可以是 Jupyter Notebooks 中创建的自定义代码、您以前训练过的现有 AI 模型,或来自 HuggingFace 等平台的开源模型。
对于情感分析,我们将使用 Azure ML 的预构建 AutoML 文本分类组件。AutoML 通过允许我们使用现有算法执行分类、回归、预测、视觉或自然语言处理 (NLP) 等任务来简化 ML。
在本教程中,我们将 training_data 和 validation_data 输入到 AutoML 组件中。这将根据主要指标生成最佳模型,该主要指标是指定数据结果的列。对于我们的数据集,它是将评论标记为正面或负面的列。但是,如果需要,信息可以更细粒度,例如正面/负面百分比。
将 AutoML 文本分类组件拖到画布上。将训练和验证数据连接到 AutoML 文本框上的相应点,如下所示。

双击 AutoML 文本分类组件以指定此组件的设置。关键设置包括:
- 训练模型的计算资源
- 验证模型的主要指标
- 目标列(AI 预测的内容)
- 数据集语言
这个特定的组件还允许您选择一个算法以获得更大的控制,例如 bert-base、roberta 或 xlnet 模型类型。例如,我们可以选择 bert-base 算法,因为它在此任务中具有更好的整体性能。每个组件的设置和详细信息各不相同,因此值得根据您的需求和预期结果尝试不同的算法。

对于此应用程序中相对简单的增强功能,我们只使用了一个训练组件。但请记住,根据您的 AI 训练目标,您可以根据需要连接不同的组件和模型。例如,您可能希望分解评论、分类主题、为短语分配情感,最后提供整体情感。
对于这个更复杂的过程,您的训练和测试数据需要包含这些分解和情感,然后才能训练模型。此外,请记住,模型训练过程中的每个步骤都可能需要时间,具体取决于您的数据大小和复杂性。然后,组件将生成一个名为“最佳模型”的对象,即经过训练的 ML 模型。
我们还可以添加一个额外的功能来注册和部署模型。但是,在本文中,我们将跳过这一点,因为我们需要自定义一些稍后托管模型的元素。
训练自定义 Azure 机器学习模型
现在,我们已准备好使用管道训练模型。点击右上角的“配置并提交”。在“设置管道作业”屏幕中,提供实验名称,如果需要,添加标签或详细信息,然后确认以启动作业。您可以将管道重命名为更易用的名称,例如“用户反馈情感”。在此阶段,您还可以更改其他设置,但现在,保存管道并点击“提交”以开始构建模型。

请注意,构建模型可能需要时间,尤其是对于大型数据集。我们在此处使用的简化数据集大约需要 8.5 小时进行训练。因此,请记住在此期间您将承担所选计算实例的成本。如果您不想等待,请下载模型并继续本教程。稍后,我们将回顾您可以上传预训练模型而不是使用管道生成的模型的位置。
现在,转到“作业”菜单查看正在运行的管道。在此阶段,您必须等待作业完成才能完全训练模型。这将需要大约 8.5 小时。请记住,Azure ML 将学习管道限制为 24 小时运行时。如果您有更大的管道,则需要调整作业设置以防止超时。

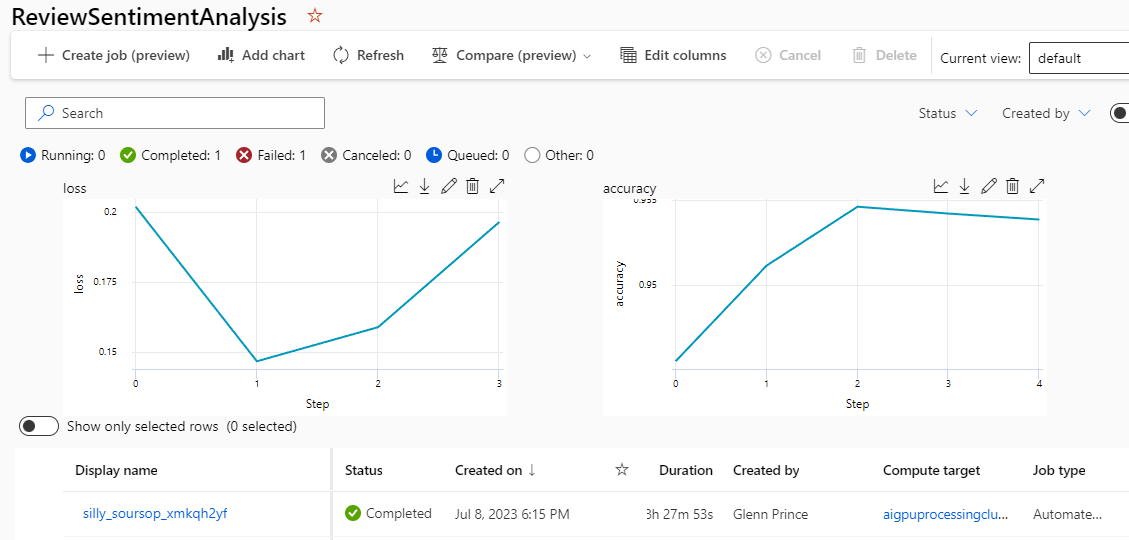
管道作业完成后,您可以通过单击作业来评估模型使用测试数据的性能,这将显示一个准确性图。
结论
在本文中,我们通过在 Azure 机器学习中训练自定义 AI 模型,为扩展我们的应用程序做好了准备。我们介绍了如何根据我们自己的应用程序数据训练情感分析模型,并将其集成到我们的应用程序中。
Azure ML 帮助您在 Azure AI 现有的 AI 功能基础上进行构建,使您能够在应用程序中训练、发布和无缝使用 AI 服务。凭借训练自定义模型的新能力,AI 功能的可能性是无限的。
在本系列的第四篇也是最后一篇文章中,我们将演示如何从我们的应用程序访问我们新创建的模型,以便应用程序用户受益于专门的 AI。