
Visual FA 第 1 部分:理解有限自动机
5.00/5 (8投票s)
在本文中,我们将使用我的 Visual FA 解决方案来探索用于在文本中查找模式的有限自动机概念。
引言
这是 Visual FA 的又一次尝试。我第一次尝试时遇到了性能问题,这些问题被基准测试代码中的缺陷所掩盖。要解决这个问题,需要进行彻底的重写,从运行时逻辑到生成器和编译器。让我们花点时间为我感到难过吧。=) 或者羞辱我,随你的便。怎么方便怎么来。
无论如何,有很多内容需要涵盖,所以我将把它分解成一个多部分系列,并从头开始,即使这意味着我们将涵盖之前文章中的内容。
我们将使用Visual FA来完成这里的一切,所以本文的所有内容都是为了这个引擎而写的。在比较其他引擎时,例如微软的引擎,届时会进行说明。
文章列表
必备组件
- 您需要一个最新版本的 Visual Studio。
- 您需要将 Graphviz 安装并在您的 PATH 中。
- 您需要接受这样一个事实:在此项目根文件夹中包含两个可执行文件,它们对于构建是必需的 - deslang.exe 和 csbrick.exe - 在 CodeProject 的搜索框中搜索 - 这里有关于它们的文章,并且在 github 上也有代码,两者都有 - 有关它们的链接请参阅此解决方案中的README.md。它们是无害且必需的。如果没有在构建过程中进行一些花哨的操作,此项目就无法实现它所做的许多出色功能。
什么是 Visual FA?
简而言之,Visual FA 本质上是一个正则表达式引擎。这大大简化了,而且可能会引发更多问题。长篇回答是:它是一个用于在 Unicode 流中匹配模式的有限自动机模拟器、代码生成器和编译器。
微软已经提供了正则表达式!这有什么用?
没错,微软提供了一个华丽的回溯引擎,可以编译和生成代码。它无法进行文本标记,至少在没有严重妥协、黑客手段和性能损失的情况下无法做到。它还以牺牲速度为代价来换取功能。Visual FA 的不同之处在于它是一个极简引擎,没有回溯、锚点或任何可能妨碍原始性能的其他花哨功能,此外它还具有词法分析/标记化能力。
所以,如果您需要进行词法分析/标记化,您需要使用除微软之外的引擎。Visual FA 符合要求。其次,如果您不需要花哨的功能,并且想要更高的性能,这个库也是一个可行的选择,在某些情况下速度可以提高 3 倍。
最后,微软的引擎无法展示其所有内部机制,也无法生成精美的图表。本文中的所有图像都是使用 Visual FA 和 Graphviz 生成的。
本文主要是一系列概念的探索,并辅以一个关于使用 Visual FA 执行基本操作的快速入门指南。
正则表达式速成班
您不需要成为正则表达式专家才能享受本文,但掌握一些基本知识会非常有帮助。Visual FA 的语法极简且相对简单。此外,我们不会在这里涵盖 Visual FA 支持的所有内容,因为这并非完全必要。
正则表达式运算符
- 连接(隐式):
ABC- 匹配 "ABC" - 选择
|:ABC|DEF- 匹配 "ABC" 或 "DEF" - 字符集:
[A-C]- 匹配 "A"、"B" 或 "C" - 非字符集:
[^A-C]- 匹配任何不是 "A"、"B" 或 "C" 的字符 - 可选
?:A?- 匹配 "A" 或 "" - 重复零次或多次
*:A*匹配 "A"、"" 或 "AAAAAAAA" - 重复一次或多次
+:A+匹配 "A" 或 "AAAAAAAA" - 重复([最小]、[最大])
{,}:A{2,}匹配 "AA"、"AAA" 或 "AAAAAAA" ()- 优先级覆盖(又称(?:)):(ABC)?- 匹配 "ABC"。请注意,Visual FA 不进行子捕获。
使用 Visual FA,您可以将表达式解析为抽象语法树 (AST) 或直接解析为状态机。
using VisualFA;
// parse into a state machine directly
FA fa = FA.Parse("foo|bar");
// parse into an AST for visitation
// and later transformation into a state
// machine using .ToFA()
RegexExpression exp = RegexExpression.Parse("foo|bar");
fa = exp.ToFA();
理解有限自动机
实际上,这有点夸大其词 - 我们将研究两种特定类型的有限自动机,用于匹配扁平流(一系列元素,但没有元素层级)中的模式:NFA 和 DFA。
它们分别代表非确定性有限自动机和确定性有限自动机,它们是两种类型的有限状态机。
令人困惑的术语迷宫
这里的术语有点模糊,因为这两种类型比它们的名称所暗示的更具体的状态机类型。所有有限自动机 - 也就是说,所有状态机,包括我们在这里不探讨的下推自动机和其他类型,都是确定性或非确定性的。话虽如此,当您在数学意义上看到 NFA 和 DFA 时,通常可以假定我们指的是我们将在这里介绍的两种类型的机器。
如果相反,您看到 NFA 和 DFA 被用来描述一类正则表达式引擎,那情况就有点不同了,尽管为了增加难度,它们源于同一种起源。Visual FA 可以轻松处理 NFA 状态机,但其正则表达式引擎严格来说是 DFA 类型。相比之下,微软的 Regex 引擎是 NFA 类型。DFA 正则表达式引擎通常根据表达式构建 NFA 机器,然后将其转换为 DFA 机器来进行实际匹配。Visual FA 也不例外。然而,这会使事情变得复杂,因为它可以在不先将其转换为 DFA 的情况下使用 NFA 机器运行匹配。即使在这种情况下,它也基本上是按照将要转换为 DFA 的方式来操作该机器的。相比之下,微软的引擎在其 NFA 状态上具有无法转换为 DFA 的东西。Visual FA 没有。实际上,Visual FA 的 NFA 只是等待变成 DFA。如果您现在还不理解这一切,那也没关系,但如果您在阅读过程中开始质疑所使用的术语,可以稍后重温一下。
一些基础知识 - 了解如何定位
从一个状态直接或间接通过转换可达的所有状态的集合 - 包括自身,被称为状态的闭包。
这很重要,因为在 Visual FA 中,您对整个状态机的“句柄”始终是根状态(通常称为q0,但您可以随意称呼它)。q0 的闭包始终是整个机器。在查看下一节(有漂亮的图片,它们在这里很有帮助)之后,请回顾这些材料。
本质上,您可以构建或解析一个状态机,而从这些构建器或解析函数中获得的就是它所构建的根。
FA myMachine = FA.Parse("foo|bar");
在这里,myMachine 实际上是q0,我们将在下一节下面的内容中看到。
myMachine 总共有 6 个状态,包括自身。
List<FA> closure = new List<FA>();
// fill the above list with 6 states
// first will be q0.
myMachine.FillClosure(closure);
// prints "myMachine has 6 states."
Console.WriteLine("myMachine has {0} states.",myMachine.Count);
Debug.Assert(myMachine==closure[0]); // always true
这是一种执行闭包的比较冗长的方式。有一个更短的调用方式。
IList<FA> closure = myMachine.FillClosure();
第一种形式允许您回收列表实例,这对于执行大量集合操作很重要。这就是为什么 Visual FA 使用 FillXXXX() 方法而不是总是返回新列表。FillClosure() 预计会被频繁调用,因此经过了相应的协调。
理解 DFA 如何工作
我们将从 DFA 开始,因为它们是最简单的机器类型。所有有限状态机都是状态的定向图,在特定输入上具有到其他状态的转换。

这是一个匹配文本 "foo" 或文本 "bar"(foo|bar)的 DFA 状态机。
- 我们总是从q0开始。
- 我们只能沿箭头指示的方向移动。
- 在每个状态 q 上,我们检查光标下的当前码点*以及出栈箭头的列表。如果有一个带有输入码点的箭头,我们必须沿着该箭头移动,并通过移动到下一个码点来前进光标。
- 如果从 3 没有匹配的出栈转换,那么我们必须评估我们当前所在的状态。如果它是双圈状态,这意味着我们可以返回迄今为止收集到的输入作为匹配。如果它不是双圈状态,则没有匹配。
* 码点表示我们正在检查的光标下的 UTF-32 Unicode 码点。在大多数情况下,这实际上就是您当前的字符。例外情况是 UTF-16 代理字符,它们将被解析为单个 UTF-32 码点以在机器中进行评估。我们在此级别不处理代理字符,因此没有什么可以使之复杂化。
您可以使用此解决方案附带的 FSM Explorer 应用程序来生成正则表达式并用输入文本对其进行可视化逐步跟踪。
输入 NFA
通常,每个 DFA 都以 NFA* 的形式诞生。原因是 NFA 在编程上更容易通过解析或组合几个机器(我们将介绍)来构建。我们不将其保留为 NFA,因为 NFA 图比 DFA 图更复杂,计算机难以遍历。
* GitHub 上的最新代码会直接从解析生成 DFA。并非总是如此,但当它不需要对状态机进行任何转换时会这样。您可以使用 IsDfa() 方法来确定整个机器是否是确定性的。
NFA 和 DFA 的主要区别在于,NFA 增加了同时处于多个状态的能力。
这可以通过两种方式发生
- 一个状态有多个出栈箭头,带有相同的码点但分支到不同的目标状态。这是“紧凑”NFA 的情况,我们将对此进行介绍。
- 存在 epsilon 转换。这些是未标记的箭头,可以在不前进输入的情况下移动。每个 epsilon 转换必须在遇到时立即遵循,但它不会将您带离当前状态,导致您可以同时处于多个状态的情况。这是“展开”NFA 机器的情况。
这里是与上面机器基本相同的机器,但表示为展开的 NFA。

灰色虚线箭头是 epsilon 转换,如上面列表中的 #2 所解释的。请注意,您总是立即遵循遇到的每个 epsilon 转换。这意味着一旦您进入q0,您也同时进入q1和q6。
这里是遍历 NFA 的规则。它们与 DFA 规则几乎相同,只是考虑了 epsilon 转换和多个状态。
- 我们总是从q0开始。
- 对于我们所处的每个状态,我们总是立即遵循每个 epsilon 并将其目标添加到我们当前所在状态的列表中。换句话说,我们取当前状态的 epsilon 闭包。(可以通过 epsilon 转换从某些状态到达的所有状态的集合称为epsilon 闭包。)
- 我们只能沿箭头指示的方向移动。
- 对于我们当前状态集合中的每个状态,我们检查光标下的当前码点*以及出栈箭头的列表。如果有一个带有输入码点的箭头,我们必须沿着每个匹配的箭头(可能不止一个)移动,并通过移动到下一个码点来前进光标。
- 如果从 3 没有匹配的出栈转换,那么我们必须从下一个状态列表中删除该状态。
- 如果我们当前状态没有可能的下一个状态,那么我们评估我们目前所在的状态。如果其中任何一个是双圈状态,这意味着我们可以返回迄今为止收集到的输入作为匹配。如果都不是双圈状态,则没有匹配。
状态机中的状态由 VisualFA.FA 实例表示,无论机器是 DFA 还是 NFA。
让我们在代码中重新审视一下这个机器。
using VisualFA;
// some of this is recap from above
// we called this myMachine above:
// difference now is we're parsing it
// into expanded form so we can have epsilon transitions
FA q0 = FA.Parse("foo|bar",0,false);
// collect all states reachable from q0
// on any transition including itself.
// q0 will be the first entry in the list
IList<FA> closure = q0.FillClosure();
// closure.Count is 10
// get the epsilon closure. Note that we typically
// do this on a set of states, except in the case of q0
// on our initial navigation. For q0 we need to make an
// array out of it.
IList<FA> epsilonClosure = FA.FillEpsilonClosure(new FA[] { q0 });
// epsilonClosure is { q0, q1, q6 }
// There is no instance overload for a single state
// for this operation because it makes conflicts
// in terms of determining whether to call the instance
// or static methods
使用 Thompson 构建算法组合 NFA 机器
Thompson 构建算法是一个众所周知的(在 FA 极客中)将正则表达式运算符转换为 NFA 的算法。其思想是,每个操作都有一个众所周知的构建方法,然后您可以像乐高积木一样将它们组合起来,构建您的最终表达式。
让我们从可以说是最简单的开始 - 一个字面量 - ABC:(在正则表达式的说法中,这实际上是 3 个字面量连接,但出于某些原因,将字面量字符串视为一流实体很有用。)

FA ABC = FA.Literal("ABC");
作为我们第二个或多或少“原子”的构造,一个集合 [ABC]。
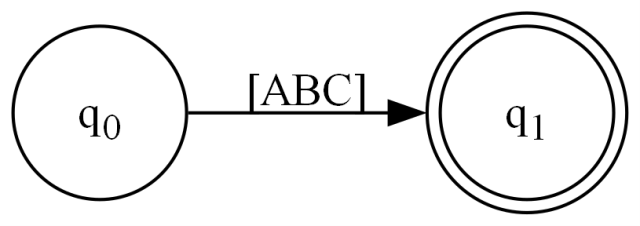
FA AthroughC = FA.Set(new FARange[] {new FARange('A','C')});
现在进行简单的连接,ABC(DEF)。

FA ABC = FA.Literal("ABC");
FA DEF = FA.Literal("DEF");
FA ABC_DEF = FA.Concat(new FA[] { ABC, DEF });
接下来,一个小的选择 ABC|DEF。

FA ABC = FA.Literal("ABC");
FA DEF = FA.Literal("DEF");
FA ABCorDEF = FA.Or(new FA[] { ABC, DEF });
接下来,一个可选匹配 (ABC)?。

FA ABC = FA.Literal("ABC");
FA ABCopt = FA.Optional(ABC);
最后是一些重复/循环:(ABC)+。

FA ABC = FA.Literal("ABC");
FA ABCloop = FA.Repeat(ABC,1,0);
我们可以通过将每个表达式视为自己的机器,然后将这些机器组合起来,来组合所有内容。上面的图是所有其他机器都可以构建出来的基本机器。这就是在这一阶段使用 NFA 的优势。DFA 不能轻易地组合。
说到这里
从 NFA 到 DFA - 幂集构造的力量
幂集构造,或者根据询问对象称为子集构造,基本上是创建一个新的 DFA 来匹配给定 NFA 的相同输入的过程。数学上已经证明,对于遵循本文规则的任何 NFA 来说,这是可能的。诀窍在于找到它。主要思想是,您可能处于的 NFA 中的每一个组合状态都代表了新 DFA 中的一个状态,其转换合并到该单一状态中。
这并不总是有效,因为在 NFA 中,您可以在任何给定输入上转换到多个状态。幂集构造对此的应对方法是进一步向下游冒泡冲突 - 这样它会尝试在更远的路径上进行消歧。
这里有一对我们将要介绍的图。这是一个判断输入是行注释还是块注释开头的机器。

上面的机器是紧凑形式的 NFA。下面的机器是等效的 DFA(未最小化 - q4 可能会被消除并合并到 q3)。
下面的图在每个状态标签下方都有 {} 集合。这些集合是导致 DFA 中状态的 NFA 状态的集合。例如,DFA 中的 q0 只是 NFA 中的 q0。然而,在 NFA 中从 q0 沿着 / 转换会让我们进入两个不同的状态,q1 和 q3。我们 DFA 中的 q1 反映了这一点。
注意 DFA 转换如何将 / 上的分歧/发散冒泡到更远的路径,从 q0 到 DFA 中的 q1,并在 * 或 / 上。这就是我之前提到的关于处理歧义的内容。构造算法假设如果足够深入地遍历,最终会找到某种区分性输入。当不是这样时,一个表达式会盲目地推开另一个表达式,并有效地将其隐藏。
// machines start out in compact NFA form by default
// either through parsing or thompson construction
FA nfa = FA.Parse(@"(\/\/[^\r\n]*)|(\/\*)");
// convert to a DFA (no minimization)
FA dfa = nfa.ToDfa();
// or (slower, makes more efficient machines)
FA min_dfa = nfa.ToMinimizedDfa();
// minimization removes duplicate states
// in the above machine q4 would be removed.
等等,词法分析到底是什么?
我已经多次提到词法分析和标记化。标记化文档意味着将其中的文本分解成一系列标记,每个标记代表一个位置、匹配的值以及匹配的符号表达式(如果未匹配任何表达式,则为错误符号)。这通常被解析器用来解析结构化文本。
由于微软的解析器无法做到这一点,您可能不熟悉正则表达式的这种用法,但它对于正则表达式来说就像匹配字符串中的文本一样是基础。
为了工作,您的状态机需要由多个表达式组成。每个表达式都有一个与之关联的符号。Visual FA 称之为接受符号。当您检索输入上的匹配项时,会报告一个匹配项,其中包含与匹配文本的表达式关联的接受符号以及报告的位置。文档的每一部分都会被返回,包括未匹配的部分。它们将报告一个接受符号 -1。
本引擎的所有搜索功能都会返回所有文本 - 即使是未匹配的部分。这使其与微软的产品有显著不同,并且可用于更多场景。如果您希望它像微软的产品一样工作,您只需忽略 FAMatch 实例,其 IsSuccess 属性为 false 或其 SymbolId 属性小于零。
这是一个词法分析器可能的样子(以 DFA 形式呈现)

注意从 q10 出栈的特殊虚线转换。这不是 epsilon 转换 - 那些是灰色的并且没有标签 - 这是一个惰性匹配模拟转换到“块结束”。我们将在下文介绍块结束以及它们的必要性。
“块结束” - 解决棘手问题的一个相对简单的解决方案
DFA 机器无法惰性匹配。嗯,有一个人声称已经弄清楚了,并且提供了一个实现,但我担心如果我理解正确,它会使状态表大小爆炸,而且我不确定我是否理解正确。无论如何,DFA 机器总是会消耗输入直到它们无处可去,即使较短的字符串可能产生有效的匹配。这被称为贪婪匹配。
有时这不是您需要的。特别是,那些需要匹配多字符结束条件到任意文本的情况,例如查找 HTML/SGML/XML 注释和 CDATA 部分的结束,或查找 C 风格块 /* */ 注释的结束,正如我们已经完成的。为此需要惰性匹配。它要求引擎停止如此贪婪!然而,我们无法在不破坏 NFA 到 DFA 转换的数学原理的情况下将其传达给引擎。
我们现在这样做:如前所述,每个表达式都有一个非负整数接受符号与之关联。
每个接受符号可能还有一个与之关联的另一个表达式/状态机,称为“块结束”。如果存在,则当匹配初始表达式时,匹配器将继续消耗输入,直到并包括匹配块结束表达式的点。
尽管每个表达式只允许一个,并且只允许接受所有字符直到最终匹配,但这仍然涵盖了惰性匹配大约 80% 的用例,而无需对引擎的任何工作机制进行根本性更改。
在 Visual FA 中,您在运行时引擎执行时、使用编译后的匹配器进行编译时以及使用生成的匹配器进行生成时指定您的块结束。它们始终指定为一个数组,其中数组的索引对应于与该块结束关联的接受符号。数组可以为 null,并且不需要是容纳最大接受符号的整个大小 - 只需要容纳具有附加块结束的最大接受符号。
// accept sym zero is default but specified here for clarity
FA commentBlock = FA.Parse(@"\/\*", 0); // accept sym of zero
FA commentBlockEnd = FA.Parse(@"\*\/");
foreach(FAMatch match in commentBlock.Run("foo /*bar*/ baz",
new FA[] { commentBlockEnd}))
{
Console.WriteLine("{0}:{1} at {2}",
match.SymbolId,
match.Value,
match.Position);
}
这将打印以下内容到控制台。
-1:foo at 0
0:/*bar*/ at 4
-1: baz at 11
如前所述,运行器总是返回整个文本。如果您只想要匹配的部分,请检查每个 FAMatch 实例的 IsSuccess。
DFA 如何执行
让我们模拟一下 DFA 的执行,就像它是 C# 代码一样。
int cp; // the current codepoint under the cursor
int len; // the current match capture length
int p; // the current position
int l; // the current line
int c; // the current column
cp = -1;
len = 0;
if ((this.position == -1)) {
// first move
this.position = 0;
}
// mark the current location
p = this.position;
l = this.line;
c = this.column;
// load cp with the current available
// codepoint, but do not capture
this.Advance(s, ref cp, ref len, true);
q0:
// if it's a '/'
if ((cp == 47)) {
// move and capture
this.Advance(s, ref cp, ref len, false);
goto q1;
}
// not accepting
goto errorout;
q1:
// if it's a '*'
if ((cp == 42)) {
this.Advance(s, ref cp, ref len, false);
goto q2;
}
// not accepting
goto errorout;
q2:
// accepted /* - now process block end
// for symbol zero
return _BlockEnd0(s, cp, len, p, l, c);
errorout:
// error handling. keep capturing the bad data until
// it looks like we might get good data.
if (((cp == -1) // eof?
|| (cp == 47))) { // q0 transitions
if ((len == 0)) { // didn't capture, so end of input
return FAMatch.Create(-2, null, 0, 0, 0);
}
return FAMatch.Create(-1,
s.Slice(p, len).ToString(),
p,
l,
c);
}
this.Advance(s, ref cp, ref len, false);
goto errorout;
基本思想是始终有一个当前正在查看的输入。这可能需要在第一个输入时处理一个边缘情况,具体取决于您的源输入 API 的外观。一旦您做到了
- 存储当前位置
- 对于机器中的每个状态
- 检查转换以查找任何匹配。
- 匹配时,捕获当前输入并前进光标,加上跳转到下一个状态。
- 如果不接受,则出错。
- 如果接受,则返回当前匹配,或者转到关联的块结束函数(如果存在)。
- 检查转换以查找任何匹配。
- 出现错误时,我们查看当前输入是否与 q0 的任何内容匹配。如果不匹配,我们将其捕获。如果匹配,我们返回到目前为止所获得的内容作为错误“匹配”。如果我们没有匹配任何内容,并且我们还没有捕获任何内容,则报告实际的输入结束。
在块结束时,事情稍微简单一些。
q0:
if ((cp == 42)) { // is it a '*'?
// capture and then advance the input
this.Advance(s, ref cp, ref len, false);
goto q1;
}
// not accepting
goto errorout;
q1:
if ((cp == 47)) { // is it a '/'?
this.Advance(s, ref cp, ref len, false);
goto q2;
}
// not accepting
goto errorout;
q2:
// accepting
// since this is a block end, we return everything
// we captured since we were called.
return FAMatch.Create(0,
s.Slice(position, len).ToString(),
position,
line,
column);
errorout:
// if there's no more input, return what we have
// as an error
if ((cp == -1)) {
return FAMatch.Create(-1,
s.Slice(position, len).ToString(),
position,
line,
column);
}
this.Advance(s, ref cp, ref len, false);
goto q0;
下一步?
接下来,我们将更详细地介绍 API 机制及其工作原理,然后是编译和代码生成。您可以在此处找到它。
享受。
历史
- 2024 年 1 月 15 日 - 初次提交