
使用并行 HDF5 进行并行 I/O
4.67/5 (7投票s)
CFD 代码并行 I/O 的设计与实现
引言
原始的 FDomain 和 FGrid 类已不再可用。FDomain 和 FGrid 在此源代码中是虚拟数据结构。因此,在计算阶段写入虚拟数据以说明并行 I/O 的概念。由于所选数据大小和数据结构,此源代码中并行 I/O 的性能可能不是最佳的。一般来说,并行 I/O 读写操作可以应用于许多并行应用程序。
运行代码的先决条件:已安装 MPI 和并行 HDF5 库。phdf5.h5(仿真初始化文件)位于与其他源代码相同的目录中。运行代码不需要 HDFView,但它将有助于 *.h5 文件的可视化和修改。
在 Linux 中运行代码的命令:mpiexec -n 5 ./phdf5
注意:代码需要使用 5 个进程运行,因为 phdf5.h5 中有一个检查。如果运行代码的进程数不是 5,则需要相应地更改 phdf5.h5 中的 offset_array。
引言
本项目探讨了使用 http://www.hdfgroup.org/HDF5/ 提供的并行 HDF5 库进行高效并行 I/O 访问。代码将并行读写仿真数据。并行 I/O 功能在 FHDF 类中实现。FHDF 类的两个主要功能是
- 并行读取存储在 HDF5 文件中的初始仿真数据以重新启动仿真
- 在计算阶段将仿真数据并行写入 HDF5 文件
使用并行 HDF5 库设计的并行 I/O 文件结构如下所示

注意:HDF5(串行版本)是许多串行应用程序的优秀数据存储和管理工具。根据应用程序数据结构,除了强大的可视化功能外,I/O 性能可能优于典型的文件指针读写。
背景
执行仿真的目的之一是分析某些物理属性(例如随时间和空间变化的速率)的演变。因此,通常在仿真过程中将这些物理属性的数值写入文件以进行进一步的后处理和分析。适当的数据存储和管理正成为一个关键问题,尤其是对于生成大量数据的仿真。随着超级计算机设施的发展以适应计算密集型仿真,不幸的是生成了更多数据文件,并且这些文件需要更多的内存和磁盘进行存储和管理。
在顺序方法中(左图),所有进程将数据发送到一个进程,例如进程 0,然后进程 0 将数据写入文件。在读取阶段,进程 0 从存储硬件中的文件读取数据,然后将数据分发给所有其他进程。从文件 I/O 访问的角度来看,当进程数量较少时,此方法效率更高。随着进程数量的增加,进程 0 在从存储硬件读取或写入时会存在瓶颈。文件 I/O 中缺乏并行性限制了可伸缩性性能。此外,需要良好的通信方案以确保进程 0 正确接收或分发数据到其他进程。间接地,这会在进程 0 处创建对存储所有数据的高内存需求。如果内存需求高于某些超级计算机中心单个进程的可用内存,则此方法将不起作用。
 |  |
为了克服通信和内存需求的限制,一些并行应用程序读写单独的数据文件(右图)。这种方法的主要缺点是随着用于计算的进程数量的增加,需要/创建大量文件。此外,在后处理阶段对信息的需求很高,因为需要从每个单独的文件中收集信息并组装成最终的数据文件。在某些超级计算机中心的文件系统中,例如 LRZ 的 supermuc,这种方法容易因超时错误或崩溃而导致 I/O 错误,因为 supermuc 的并行文件系统针对高带宽进行了调整,但对于处理位于单个目录中的大量小文件(例如,每个目录生成约 1000 个文件的并行程序或同时运行的作业)并不理想。
随着 MPI-2 中并行 I/O 的引入,这为所有参与的并行进程写入单个文件提供了可能性。这是通过 MPI_File_set_view 设置文件视图来实现的,其中为每个进程定义了文件中的一个区域以进行读取或写入。数据将以二进制格式(机器可读格式)写入。因此,如果需要分析数据(例如,用于调试),则始终需要一个后处理步骤来将二进制格式转换为 ASCII 格式。此外,由于不同的字节序,二进制文件可能无法移植到其他超级计算机。

高级 I/O 库(例如 HDF5 库)提供应用程序程序和并行 MPI-IO 操作之间的接口。库专家封装 MPI-IO 库,优化并添加其他有用功能以构建高级并行 I/O 库。库用户只需要在他们的并行程序中应用此知识。这通常会节省应用程序程序中并行 I/O 的开发和优化时间。
Using the Code
并行读写操作在 FHDF 类中实现。它使用了因法律原因而无法获得的 FDomain 和 FGrid 类。FDomain 和 FGrid 类都定义了 CFD 代码的数据结构,该结构因 CFD 代码而异。但是,FHDF 的设计和实现概念可以应用于许多仿真。
//
// object initialization
//
MPI_Comm_size(MPI_COMM_WORLD, &comp_size);
int rank;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
bool success;
fd = new FDomain(); // contains the data structure of the simulation domain
FHDF *fhdf = new FHDF(MPI_COMM_WORLD, comp_size, rank, fd, success);
//
// parallel write
//
fhdf->writeDomainData(offset_array); // write FDomain and FGrid data (first time write)
fhdf->writeGridData(offset_array); // write FGrid data only (inside computational loop)
// offset_array:
// Its size equals to the comp_size + 2
// Its denotes the offset in row where each process begins writing
// (similar concept to MPI_File_set_view).
// The last two members store the total number of rows in a dataset and the
// maximum rows written by a process.
// Example : 0 23 46 23
// Two processes in the computational phase.
// Process 0 and 1 begin writing at row 0 and 23 respectively.
// Total number of rows in the dataset is 46.
// The maximum number of rows written by a process is 23.
//
// parallel read
//
// fhdf->readHDF5(); // read the FDomain and FGrid data
//
// define H5T_COMPOUND datatype for class object with C data type
//
hid_t grid_tid = H5Tcreate(H5T_COMPOUND, sizeof(FGrid);
H5Tinsert(grid_tid, "mytag", HOFFSET(FGrid, mytag), H5T_NATIVE_INT);
H5Tinsert(grid_tid, "depth", HOFFSET(FGrid, depth), H5T_NATIVE_SHORT);
hsize_t vector_dim[] = {3};
hid_t vector_DT_INDEX_tid = H5Tarray_create(H5T_NATIVE_UINT, 1, vector_dim);
H5Tinsert(grid_tid, "n", HOFFSET(FGrid, n), vector_DT_INDEX_tid);
H5Tclose(vector_DT_INDEX_tid);
// Advantages of using H5T_COMPOUND:
// - used for mixed datatype in structure in C or class in C++ (only the primitive C data type)
// - avoid copying data from the structure or class to a temporary buffer
//
// syntax for parallel HDF5 write/read
//
H5Dwrite(dataset, datatype, dataspace(memory space), dataspace(file space), transfer property, buffer); ;
H5Dread(dataset, datatype, dataspace(memory space), dataspace(file space), transfer property, buffer); ;
// segregation of dataspace into memory space and file space allows a subset
// of the data to be written/read
可用的报告解释了本项目期间遇到的设计和实现、优点和问题。最重要的是,它为您提供了高效并行 I/O 设计和实现的主要概念。阅读报告将帮助您理解代码。
通过用其他仿真的相应数据结构替换此代码中的数据结构,可以轻松地将代码应用于其他仿真。
关注点
随着多核处理器的广泛可用,并行编程在塑造当今和未来高效应用程序的编程趋势中发挥着重要作用。根据摩尔定律,我们观察到在过去两到三十年间计算能力呈指数级增长。高效并行编程的关键部分是输入和输出。然而,I/O 访问的性能,即使在并行 I/O 访问中,也滞后。日益增长的不平衡促使对高效和可扩展 I/O 进行更多研究,尤其是在并行编程中。
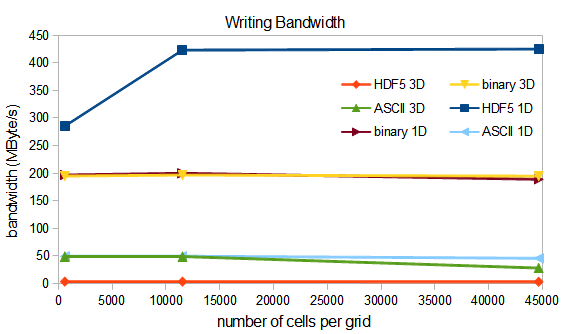
众所周知,就内存布局、内存访问和计算中的缓存效率而言,三维 (3D) 数组的性能通常不如一维 (1D) 数组。然而,3D 数组和 1D 数组数据结构在文件 I/O 访问中的性能比较鲜为人知。report.pdf 中的结果表明,使用 HDF5 库的并行 I/O 性能可能优于使用典型 C/C++ 文件指针的二进制写入。
当前并行计算中的一种通用方法是将计算域/数据大小分配给进程,使其可以适应缓存。这种策略可能会观察到超线性缩放。这是从计算角度来看的最佳解决方案。
不幸的是,正如我们之前观察到的,将小数据数组写入文件 I/O 会导致糟糕的 I/O 性能。因此,我们有两个独立的最佳解决方案,但它们相互矛盾。因此,需要在它们之间保持平衡,或者需要发现一种新方法来克服这一限制。
并行编程的新趋势是结合分布式和共享内存访问的新编程模型。再加上先进的互连技术,例如 Intel Quick Path Interconnect 技术,可以观察到改进的 I/O 可伸缩性性能,而无需严重依赖通信效率和单个进程的 I/O 性能。
历史
- 2013 年 4 月 23 日:首次提交