
基于熵差的关键词提取
在此,我们为长文本提供简单实用的关键词提取软件和dll。
- 下载 Keyword_Extraction_Based_On_Entropy_Difference-noexe.zip - 8.8 MB
- 下载 Keyword_Extraction_Based_On_Entropy_Difference.zip - 8.9 MB
请注意
如果您在您的程序或研究中使用关键词提取软件或动态链接库(dll),请注明论文和程序部分引用了以下论文。文章中的所有源代码都可以完全复制。
l 杨振、雷建军、范克峰、赖英旭。 基于内在和外在模式的熵差的关键词提取 ,Physica A: 统计力学及其应用,392 (2013), 4523-4531。 http://dx.doi.org/10.1016/j.physa.2013.05.052
引言
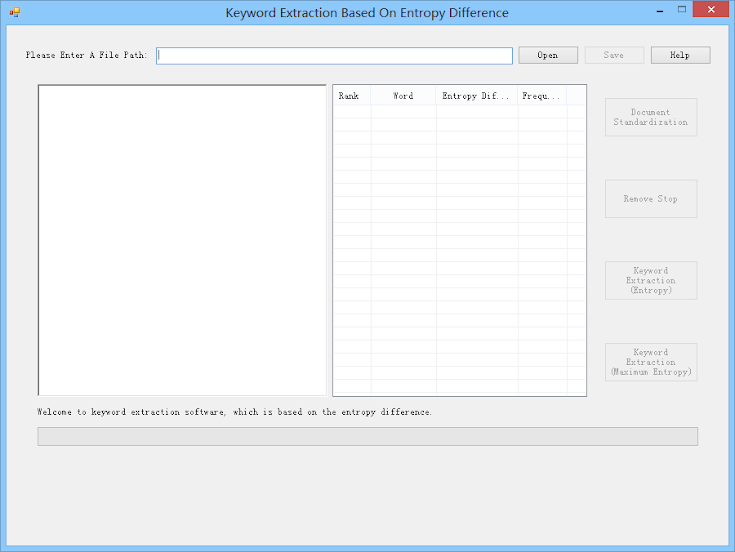
图1:软件界面
在此软件中,我们使用一种熵差度量来提取文本中的关键词。这是一种简单的度量,没有任何先验知识,并且可以有效地提取单个文本中的关键词。我们提供了由 C++ 和 C# 语言开发的 dll。我们还提供了关键词提取软件供您使用,该软件由 C# 开发。使用此软件,您只需要做一件事就是设置要处理的文件的路径,软件可以帮助您完成其余的工作。对于英文文本,您应该确保文本是标准格式,或者您可以使用软件中的“预处理”功能来格式化文本。然后,您可以选择一种方法——通用熵或最大熵来提取关键词。
对于中文文本,为了格式化文本,您应该按照以下步骤操作。首先,删除文本中的标点符号和图表。然后,将句子分成单词列表。两个连续的单词用空格隔开。我们提供了删除标点符号和图表的功能。您应该确保句子已经被分成单词列表。最后,您可以选择一种方法——通用熵或最大熵来提取关键词。
标准化文本将在使用部分给出。有了这些,您可以轻松完成文本关键词提取工作!
背景
人工撰写的文本与猴子打字最显著的区别之一是,人工撰写的文本普遍存在有意义的主题。关键词/相关词提取和排名是诸如文本主题检测和跟踪等关键任务的起点,并且广泛应用于信息提取、选择和检索。
算法特点
作为关键词提取领域的新方法,该方法具有以下亮点:
• 它是一种评估和排序文本中词语相关性的新指标。
• 该指标使用香农熵在内在模式和外在模式之间的差值。
• 这项工作是关键词提取和排序的新成果。
• 该方法特别适用于没有先验信息的单个文档。
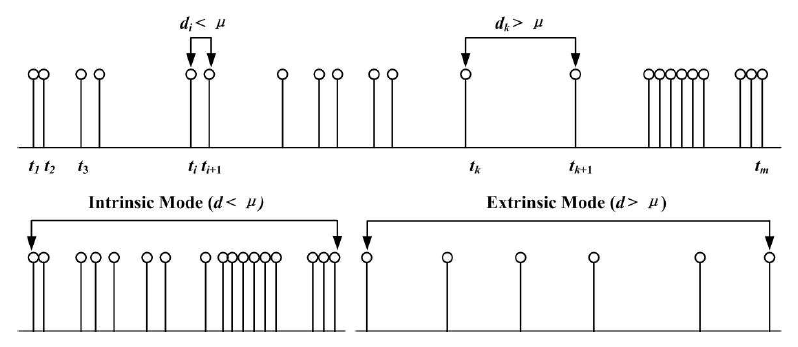
图2:文本中词语类型出现位置的内在模式和外在模式。
这里简要介绍一下算法的原理,它可以帮助您更好地理解和使用dll和软件。内在-外在模式的思想基于这样一个普遍观点:高度显著的词语往往受到作者意图的调节,而常用词语则基本均匀地分布在文本中。因此,内在模式表示相关词语在某个主题中出现的统计特性,即每个主题内部的聚类统计特性。同时,外在模式捕捉了一个词语在整个文本中消失聚类的统计特性,它表征了主题内词语聚类发生与作者书写风格之间的关系。如图2所示,两个连续出现的词语之间的距离定义为 di = ti+1 − ti。 Ti 是词语在文本中的位置。当di 属于内在模式,如果 di <μ。换句话说,词语的给定出现是内在模式的一部分,如果其局部间隔小于其平均等待时间。令 dI = {di|di <μ} 为所有 di <μ的并集,如图2左下角所示。通过实验发现,文章中出现的关键词呈现聚集性特征,因此其内在模式熵较大而外在模式熵较小;一般词语在文章中分布均匀,任意两个连续词语间隔变化不大,因此内在模式与外在模式的熵差较小。这样,您就可以利用熵差值E来提取关键词。实际应用中,为了消除随机分布的词语和边界条件的影响,我们采用 Cc 边界条件和归一化熵差 Enor 作为最终指标。如果您想了解更多关于此算法的细节,请点击此处 (http://dx.doi.org/10.1016/j.physa.2013.05.052) 查看完整论文。
使用方法
现在我们将详细介绍关键词提取软件和dll的使用。这里有两个样本,我们将用它们作为许多例子的来说明Enor度量的性能,一个是英文科学书籍,另一个是中国新闻报道。
请注意:在开始文本评估之前,所有标点符号都已从文本中删除,所有单词都已转换为小写,然后应用了基于空格的简单分词方法。对于中文文本,首先会进行额外的中文分词。
在关键词提取软件中,我们还为您提供文本预处理功能。预处理后,文本的标准化格式如下:
标准化文本输入:can any body hear me oh am I talking to myself my mind is running empty In the search for someone else cause tonight I'm feeling like an astronaut……
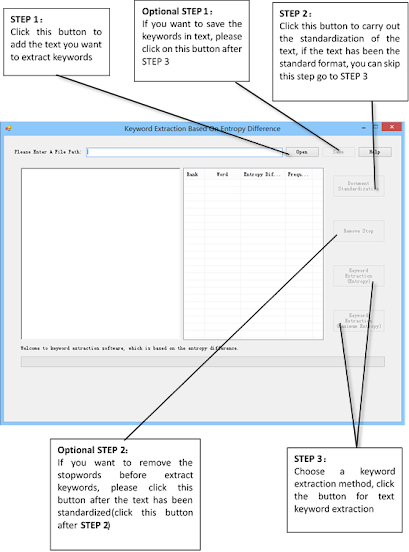
使用软件:首先,请单击图标启动关键词提取软件。按照下图所示的流程,您可以进行关键词提取过程。
使用DLL:
使用我们提供的dll非常简单,只要您熟悉C++或C#的dll调用,就可以轻松使用它。
使用C++ DLL:
请注意:在使用C++版本的dll之前,请按照如下方式设置您的Visual Studio (VS2010)
打开您的Visual Studio,点击菜单项目 -> 属性 -> 配置属性 -> C/C++ -> 代码生成 -> 运行时库,选择多线程(/MD)。
这里提供了C++ DLL的两个版本:发布版本DLL和调试版本DLL,请选择相应的DLL使用。例如,如果您想在“发布”方法下编译代码,请使用“release”文件夹中的DLL。我们推荐使用发布版本,因为它比调试版本速度更快。
步骤1:
在解压后的文件夹中找到DLL(在c++文件夹中)并点击release文件夹。文件夹中会有三个文件,如下图所示。然后,将这三个文件复制到您的项目中,并将“Node.h”文件导入到您的项目目录中。

步骤2:
在代码中添加头文件“Node.h”,如下所示:,#include"Node.h"
请注意:“Node.h”中结构体的变量顺序不可更改!现在,我们介绍结构体NODE,如下所示::
#include<vector>
using namespace std;
typedef struct
{
string word; //word
double EDnor; //Entropy difference, the greater the value is, the more critical the word
int frequency; //Frequency of the word
vector<int> t_loc; //the position of the word appeared in the text
vector<int> d_list; //the distance between two consecutive words
}Node; //the structure which the dll returns contains key information
#pragma comment (lib,"Keyword_Extraction.lib")
//input: string text ,the text after pretreatment
//int &num ,return the size of the Node array
//return: Node* ,return the keyword array
extern Node* keyword_extra_entropy(string text,int&num); // return the keyword array with the //general entropy method
extern Node* keyword_extra_entropy_MAX(string text,int&num); // return the keyword array with //the Maximum entropy method DLL封装了两个函数: Node *keyword_extra_entropy (string text, int & num) 和 Node *keyword_extra_entropy_MAX (string text, int & num)。分别地,第一个函数使用通用熵方法,第二个函数使用最大熵方法计算最大熵。这两个函数都有两个输入:string类型——预处理后的文本;int类型——返回数组的大小。输出:Node*类型——类型为Node的数组,结构体Node包含上述介绍的内容。 步骤3
按照上述步骤,您可以调用函数来获取关键词,例如下面的代码展示了TOP-10关键词:
int i;
int num;
Node *result;
result=keyword_extra_entropy_MAX(text,num);
for(i=0;i<10;i++)
cout<<endl<<result[i].word<<"==="<<result[i].EDnor<<"==="<<result[i].frequency; 示例:
现在,我们选择书籍“物种起源”作为示例,并演示使用dll的整个过程:
代码:
#include<fstream>
#include<iostream>
#include<string>
#include"Node.h"
void main(){
//read the whole txt file in string type variable
filebuf *pbuf;
ifstream filestr;
long size;
char * buffer;
filestr.open ("D:\\test.txt",ios::binary); //please change the file
//path according to your actual situation
pbuf=filestr.rdbuf();
size=pbuf->pubseekoff
(0,ios::end,ios::in);
pbuf->pubseekpos (0,ios::in);
buffer=newchar[size+1];
pbuf->sgetn (buffer,size);
buffer[size]='\0';
filestr.close();
string text=buffer;
//Call the function to
//extract keywords in the dll
int num;
Node *result;
result=keyword_extra_entropy_MAX(text,num);
//output all keywords in the array,
//here “num” is the size of the array.
for(int i=0;i<num;i++)
cout<<endl<<result[i].word<<"==="<<result[i].EDnor<<"==="<<result[i].frequency;
system("pause");
} 使用C# DLL :
C#版本的dll将整个类封装起来,所以它包含比C++版本的dll更多的函数(包括预处理函数等)。请参阅文件“KEBOED接口文档”了解C# dll的用法。
实验结果 :
对于英文示例,我们选择“物种起源”,使用我们的关键词提取软件,并选择“最大熵”关键词提取方法,

对于中文样本,我们选择了一篇网络新闻报道,这篇报道的标题是《让雷锋精神代代相传》。我们使用关键词提取软件,并选择“最大熵”关键词提取方法,得到以下结果:

这两个样本文本也将包含在压缩包中。
结论
总结,理解人类书面文本的复杂性需要对文本中词语的统计分布进行适当的分析。我们发现,高度显著的词语往往受到写作意图的调节,而常用词语则基本均匀地分布在文本中。这项工作中的思想可以应用于任何具有清晰可识别词语的自然语言,而无需任何关于语义或语法的先前知识。