
一个可扩展的数学表达式解析器(带插件)
4.92/5 (141投票s)
为可扩展、可维护、健壮且易于使用的数学解析器设计和编码。
- 下载演示应用程序 - 1.05 MB
- 下载源代码 - 413.2 KB
- 下载 MTParserLib 的 Doxygen 文档 - 652.89 KB
- 下载 MTParserCOM DLL 文件 - 908.04 KB

引言
几乎所有应用程序都使用数学表达式。事实上,它们是编程语言的基础。当你输入一个程序时,你实际上是在编写大量的数学公式。程序本质上是静态的,也就是说,它在执行时不能被更改。例如,用 C++ 编写的程序在每次更改一行代码时都必须重新编译。因此,想象一下,如果一个数学公式需要修改以适应用户环境的变化。你喜欢为了一个小的公式更改而重新编译所有代码的想法吗?这就是数学表达式求值器的用武之地,因为它允许在运行时进行公式的求值和修改,而无需更改一行代码。诀窍是将数学公式视为数据而不是程序指令。求值器将公式作为字符串,在运行时进行编译,并计算可以被应用程序透明使用的结果。
数学软件是一个成熟的领域,并且有许多优秀的库以很小的费用提供。因此,提供增强的数学函数和算法不是这个解析器的主要任务。相反,重点在于允许在运行时公式求值的上下文中重用现有代码。为此,解析器的设计定义了一个框架,可以在其中优雅地集成现有函数。插件是扩展解析器的首选方式,如果您开发了一个插件,我邀请您将组件发送给我。
有两种解析器版本:一个原生的 C++ 库和一个 COM 组件。C++ 库具有高度可扩展性和速度,但其使用仅限于 C++ 语言。相比之下,COM 组件更容易集成到项目中,并且许多编程语言都可以使用它。COM 插件可用于扩展 C++ 库和 COM 组件。
本文结构如下
特点
以下是主要功能
- 用户定义的函数和运算符
可以定义 C++ 函数和运算符类来扩展解析器语言。通常,这些类将被打包成插件以允许运行时扩展。
- 用户定义的变量和常量
变量是一个特殊的符号,在求值时会被替换为值,但与常量不同,它的值可以被更改。它可以用于创建参数化公式,例如“3t+10”,其中 *t* 是时间变量。运行时可以定义无限数量的变量。
常量是一个特殊的符号,在求值时会被替换为值。使用常量而不是值有助于使数学公式更清晰,特别是对于广为人知的数值。解析器也可以进行优化,因为它知道这些值是常量。常量的例子有 pi (3.14159…) 和 e (2.71…)。运行时可以定义无限数量的常量。
- 用户定义的宏
宏函数有助于简化常用表达式的书写。例如,如果您经常使用定义为 sqrt(x^2+y^2) 的欧几里得距离,那么定义一个名为“euc(x,y)”的宏可能是一个好主意。宏可以使用任何已定义的运算符、函数、常量和宏。运行时可以定义无限数量的宏。
- 批量求值
为了实现非常高的性能,您可以使用一套不同的值在一次函数调用中多次求值一个表达式。这样,您可以节省昂贵的函数调用时间,尤其是在使用 COM 库版本时。结果是,用 C# 开发的客户端在使用 COM 库版本时,其性能几乎是未托管 C++ 应用程序的 70%!
- 插件扩展
插件允许通过添加函数、运算符和常量来在运行时扩展解析器语言。可以根据您的用户需求加载多个插件,从而允许应用程序的运行时自定义,并实现基于组件的发布策略(用户只需为他们使用的功能付费)。插件架构的另一个好处是第三方组件可以轻松地与您的应用程序集成。值得注意的是,插件的速度与原生 C++ 函数和运算符一样快。
- 国际化考虑
当今的国际软件市场需要本地化的应用程序。该组件自始至终都考虑到了这一点,因此本地化任务得到了简化。
- 本地化错误消息
参数化错误消息存储在每个语言的 XML 文件中。所有错误都带有附加字段,可以生成非常信息丰富的消息。没有内部消息:所有消息都可以本地化。
- 本地化文档
可以为函数、运算符、常量和变量提供文档,以帮助用户了解如何使用它们。文档文本存储在 XML 文件中。
- 可配置的语法
小数点和函数参数分隔符字符可以在运行时修改,以根据您的用户偏好自定义语法。
- Unicode 就绪
所有字符串都作为 Unicode 处理。这包括变量、常量、运算符和函数名。但是,通过一个简单的编译选项,您仍然可以启用 ANSI 字符串。
- 本地化错误消息
- 许多预定义的运算符和函数
超过 16 个运算符和 30 个函数。包括布尔、三角和数值近似函数。这仅仅是开始,因为可以加载插件来扩展解析器语言。
运算符
+
-
*
/
^
%
&
|
!
>, >=
<, <=
!=
==加法
减法和一元负号
乘法
除法
幂
模
逻辑与
逻辑或
逻辑非
大于或等于
小于或等于
不等于
等于通用函数
abs
acos
asin
atan
avg(x,y,z,…)
bin
ceil
cos
coshfact
floor
hex
if
isNaN
log
log10
max(x,y,z,…)
min(x,y,z,…)rand()
rand(min, max)
round
sin
sinh
sqrt
sum(x,y,z,…)
tan
tanh数值近似函数(使用数值近似插件)
derivate(expr, var, point)
trapezoid(expr, var, a, b, [step=0.1])
solve(expr, var, result, [vo=0], [tol=0.01], [maxIter=100])计算表达式相对于一个变量在指定点的数值导数近似值
使用梯形法则计算 a 和 b 之间的积分数值近似值
使用牛顿数值近似方法找到产生所需结果的变量值日期/时间函数(使用日期插件)
date
datevalue
day
hour
minute
monthnowdate
nowtime
second
时间
weekday
year - 用户自定义函数编译器
为了允许使用特殊语法,函数可以按照它们想要的方式编译它们的参数。大多数函数只接受数字,但一些复杂的函数需要更多的灵活性。例如,`solve` 函数将其第一个参数作为数学表达式,可选参数甚至可以提供。
- 信息丰富的错误消息
错误通过异常结构报告,其中包含详细字段,可以生成非常信息丰富的错误消息。异常结构的字段包含有关每个错误的“什么”和“在哪里”的信息。
- 速度非常快
使用快速算法来确保出色的性能。使用的一些技术包括表达式编译、常量表达式折叠和二分查找。
庞大的功能列表不一定造就一个好的解析器。质量也很重要。那么,一个一流的数学解析器应该具备哪些品质?如果您想在实时应用程序中使用它,那么性能是必须的。而且,由于实时应用程序通常不使用 Windows,因此解析器必须可移植到其他平台。如果您的场景是这样,那么不要在这个解析器上浪费时间,因为它既不是“西方最快的解析器”,也不是可移植的。
然而,这个解析器有一些非常有趣的品质!为了可扩展性、代码可维护性、易用性和健壮性,牺牲了一点性能。这些品质中的每一个都会对性能产生负面影响,但会在其他方面带来回报。
- 可扩展性允许您通过干净的面向对象代码轻松添加运算符和函数,而无需修改现有代码。这将避免引入细微的错误并浪费您调试损坏的解析器的时间。另一个好处是您不需要理解内部解析器逻辑就可以添加运算符和函数。
- 可维护性对于开源库来说绝对是可取的!为了性能,没有晦涩的代码。黑暗代码的特点是没有人想修改它,即使是做最简单的更改。可维护性定义为易于理解、易于修改、易于测试以及易于预测修改的副作用。
- 易用性确保将解析器集成到您的项目中不会成为一件麻烦事。这将允许您专注于您的应用程序,而不会浪费时间理解复杂的解析器接口。另一个方面是国际化:国际化一个从一开始就没有考虑过的库可能会非常耗时。
- 健壮性意味着您的应用程序不会因为缺少验证代码而崩溃。而且,如您所知,用户很擅长发现这些小漏洞……!这也意味着解析器将给出正确的结果,并进行必要的验证以确保结果的有效性。例如,解析器不应接受可能产生副作用的语法,例如:“5.2.3 + 3.2.3”。这两者截然不同:工作,以及按预期工作。
- 当然,解析器速度相当快!但正如我所说,这不是首要任务,因此,有时会做出影响性能的选择(并非没有一丝遗憾……!)。
请不要误会我:这个解析器在上述所有品质方面都不是完美的。但这些品质是我关心的,并将继续指导解析器朝着这个方向发展。
许可证
非商业用途免费使用。如果您想在商业产品中使用此解析器,请联系我并提供以下信息:
- 您的编程语言
- 对您有用的功能(请参阅功能列表)
- 关于解析器如何帮助您的简短描述
事实上,即使您在个人项目中使用此库,我也非常感谢能听到您的声音!所以,请随时分享您的经验。
设计讨论
本节介绍整体设计和权衡。
设计模式
使用了以下设计模式:外观、原型、抽象工厂和状态。
外观
描述
- 解析器由多个类和接口组成,它们协同工作以提供数学求值服务。这种分工是获得清晰设计所必需的。然而,解析器用户并不关心内部设计,因此需要一个以用户为中心的界面。外观提供了这个视角。
后果
- 通过隐藏实现细节来提高解析器的易用性。
- 通过最小化可见类的数量来减少客户端与库之间的耦合。
协作者

- 客户端
客户端是库的用户。例如,您的应用程序代码。您需要了解的唯一类是 `MTParser`。
MTParser这是外观类。它在一个接口中提供注册器和编译器的服务。此外,它定义了辅助方法来简化常见任务的执行。
- `MTParserRegistrar` 和 `MTParserCompiler`
解析器由多个对象(例如,编译器和注册器)组成,以避免将所有负担放在同一个对象上,那样会太庞大。`MTParserRegistrar` 和 `MTParserCompiler` 对象各自处理数学求值任务的一部分。
原型
描述
- 自定义函数和运算符可以在运行时定义,因此解析器不知道这些对象。在这种情况下,解析器如何在需要克隆自身时复制这些对象?原型是支持克隆的对象。因此,所有函数和运算符对象都是可以克隆自己的原型。`spawn` 方法用于请求对象复制自己。
后果
- 允许运行时项定义和创建(函数、运算符…)。
- 项与解析器之间没有耦合,尽管解析器需要创建项实例。这与基于工厂的创建模式非常不同,后者需要了解具体类。
- 项类处理创建任务的复杂性。事实上,一项需要知道如何复制自己。这在创建新的项类时是一个小的开销,但可以避免修改解析器代码。
协作者

MTParser当从现有的解析器对象初始化解析器时(使用 C++ 的 `=` 运算符或 COM 版本的 `Copy` 方法),所有已定义的项都需要复制。然后,解析器要求每个项构建一个新的项实例。新实例完全独立,但具有与原始项相同的状态。
- `MTFunctionI` 和 `MTOperatorI`
这些是项接口。`spawn` 方法用于请求一个复制的对象。
- `SinFct` 和任何其他具体项类
这些类知道如何克隆自己。创建可能仅包括类实例化,或许多操作来复制对象状态。好处是这种逻辑被封装在具体项类中,没有其他类知道它。
抽象工厂
描述
- 抽象工厂模式是关于定义一个工厂接口并使用它来获取对象。与工厂方法模式的区别在于具体工厂类直到运行时才知道。这可以转移到插件的上下文中。我们希望能够从未知 DLL 加载未知的项(即函数、运算符和常量)。抽象工厂接口对应于 COM 插件 IDL,它具有返回新项对象的各种方法。项类可以使用原生 C++ 类来实现。一旦解析器拥有每个项的对象,就不再需要插件了,因为原型模式用于复制现有项。这大大简化了插件的开发。
后果
- 调用插件中定义的项时没有性能损失,因为它是原生 C++ 类(即,这里没有 COM 调用,直接访问对象)。COM 调用仅在初始化阶段进行,当定义插件项时。
- 由于它们是 C++ 类,项可以使用 C++ 解析器服务,例如自定义编译。不需要特殊的互操作性考虑,如果混合使用 C++ 和 COM 对象,可能会发生这种情况。
- 插件易于创建,因为它们的 COM 接口很小。只需要几个与工厂相关的函数。函数和运算符不需要 COM 接口。
- 插件的维护因工厂接口相当稳定而得到简化。然而,项接口经常改变,但改变 C++ 类的接口比改变 COM 接口更容易。
协作者

IMTPlugin这是抽象工厂接口。它具有创建新函数和运算符对象的函数。一旦所有项都创建完成,就可以卸载插件。
- 插件实现
这是具体的插件类。它知道插件的所有函数和运算符类,因此可以创建新对象并返回给解析器。
MTParser解析器通过 `MTFunctionI` 和 `MTOperatorI` 接口使用函数和运算符对象。它使用 `IMTPlugin` 接口与插件通信。当加载插件时,解析器会向工厂请求每个项的一个对象。之后,解析器直接使用项对象。
- `MTFunctionI` 和 `MTOperatorI`
定义函数和运算符提供的服务的 C++ 接口。
- `Func1` 和 `Op1`
这些是插件中定义的函数和运算符。项代码由操作系统使用 DLL 机制动态加载到内存中。创建后,解析器对象只需要通过插件接口获得的内存指针。
状态
描述
- 编译器根据其当前状态以不同的方式解释字符。例如,在解析转换函数参数时,运算符字符没有任何意义。状态模式通过避免重复和处理带有多个复杂“
if”语句的特殊情况,极大地简化了编译器代码。一种解决方案是将与每个状态相关的代码放入一个单独的类中。这样,编译器可以分为一个通用解析器和多个状态。
后果
- 可以轻松添加新状态,而不会影响编译器代码。这意味着可以相对容易地添加新编译器功能。新功能是通过创建新的状态类来实现的,而不是向已经庞大的解析方法添加代码。
- 解析和编译任务可以分开。这允许通用解析器识别标记,并将解释任务委托给当前编译器状态。
- 没有庞大的单体编译器类。相反,有几个小类和一个通用编译器类,它为状态类提供通用服务。
协作者

MTParserCompiler这是表达式编译器。它提供解析(分词器)和通用堆栈管理服务。当识别出标记(例如,运算符名称)时,它会调用当前的编译器状态对象。
MTCompilerState这是一个所有状态都必须遵循的接口。每个方法对应一个已识别的标记事件。例如,当检测到运算符名称时,会调用 `onOp` 方法。状态可以决定如何处理每个事件。它还决定何时更改当前状态。
- 具体状态
目前有三种状态。以下转换图显示了触发每种状态的因素。
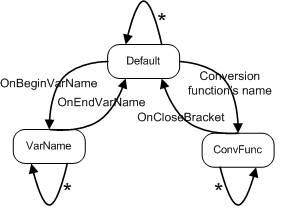
解析器设计
第一张图展示了数学表达式的组成。`MTParser` 类是一个外观,它隐藏了两个更复杂的类:注册器和编译器。注册器的职责是:
- 注册有效的表达式项。
- 确保没有冲突的项。
- 确保整个“语言”是一致的。
- 提供对已注册项的访问。
编译器的职责是:
- 将中缀表示法的表达式转换为堆栈,堆栈中的项可以按顺序求值。
- 验证表达式语法。
将解析器分成三个对象实际上降低了每个对象的复杂性,并有助于处理特殊注册器或编译器。例如,我们可以自然地想象一个编译器可以执行某些用户可以选择使用或不使用的优化。
本可以有一个名为求值器的另一个对象。该对象将负责使用编译器生成的堆栈来计算表达式结果。问题是这会在外观到求值器之间引入一次调用间接。遗憾的是,这种间接成本太高,因为求值方法被重复调用,因此每次间接调用的次数都会乘以一千倍。

以下类图显示了运算符、函数和变量是如何被抽象的。底部可以看到具体的运算符和函数类。通过实现 `MTOperatorI` 和 `MTFunctionI` 接口,可以简单地添加新的运算符和函数。运算符和函数之间的区别在于,函数可以有任意数量的参数,而运算符具有可变优先级(为了使解析算法正常工作,函数必须比运算符具有更高的优先级)。
另一种设计可以将这两个接口合并,但这可能会导致糟糕的函数和运算符实现,因为运算符限于两个参数,而函数的优先级是固定的。因此,在这种情况下,我宁愿增加设计复杂性以避免编码错误,方法是添加一个接口。`MTExprItemEvaluatorI` 接口定义了求值表达式所需的通用方法。它是保护数学表达式求值器免受更改并保持代码清洁的关键。

下一个类图展示了数学解析器的依赖关系(`MTParser` 类)。我们看到它必须知道表达式项是函数、运算符还是变量,以便分别处理每种类型。这意味着如果添加新的项类型,解析器将需要修改。这当然有改进的空间,但这种类型的更改可能不够频繁,不足以抵消潜在的解析速度损失。

最后,下一个类图展示了表达式求值期间的类关系。没有特定的项接口(即 `MTOperatorI`、`MTFunctionI`…),这意味着求值逻辑不需要更改,除非最通用的接口(即 `MTExprItemEvaluatorI`)发生更改。

算法
解析算法
基本上,这个数学解析器允许您在定义数学表达式时使用以下项:数值、常量、变量、运算符和函数。基础。然后对数学表达式进行预处理,并构建一个堆栈(请注意,这是一个堆栈而不是一个树)以加快求值速度。这样,大的处理只在解析时进行一次。这是一种非常常见且高效的解析数学表达式的算法,因此我将不详细介绍。
主要思想是这样的。首先,您有两个堆栈:一个临时堆栈将用于存储运算符(即运算符堆栈),另一个堆栈将包含预处理的表达式,稍后将用于求值(称之为第二个堆栈)。解析是从左到右进行的。所以,如果您得到一个数字,您会立即将其放入第二个堆栈。您对所有后续数字都这样做。现在,如果您得到一个运算符(称之为 `curOp`),您会执行以下操作:
If precedence(curOp) > precedence(lastOp) then
push curOp on the operator stack
Else
While precedence(curOp) <= precedence(lastOp)
pop lastOp
push lastOp on the second stack
push curOp on the operator stack
EndIf
最后,弹出所有剩余的运算符并将它们推到第二个堆栈上。
所有这一切的目标是将高优先级运算符放在堆栈的底部,以便它们首先被求值。这里的优先级是指数学运算符的优先级。所以,+ 和 - 具有相同的优先级,而 * 的优先级高于 +… 此外,`lastOp` 是运算符堆栈的顶层元素(换句话说,它是最后推入堆栈的运算符)。在求值时,您逐个弹出项并计算结果。实际实现是递归地完成的(更多细节请参见代码)。就这样!当然,还需要一些代码来处理函数和括号,但一旦您掌握了基本思想,这就会非常直接。
从技术上讲,这种算法通常称为“移位-约简”算法或简单的运算符优先级解析算法。它的目的是将使用中缀表示法的表达式字符串转换为逆波兰表示法。中缀表示法是我们人类常用的书写数学表达式的方式(例如,x+2*2),而逆波兰表示法是计算机更能理解的,因为无需担心运算符优先级和括号。后一种形式的一个例子在以下部分中给出。
求值算法
给定表达式 2^3+4*5,应用解析算法会得到以下堆栈(第一列)

(弹出项已高亮显示)
求值算法弹出第一项并对其进行求值。在这种情况下,选择 `+` 运算符(#1)。加法运算符需要两个参数,因此它弹出第一个参数,即 `*` 运算符(#2)。同样,乘法运算符需要两个参数,并弹出第一个参数 5 和第二个参数 4(#3)。现在可以对 `*` 运算符进行求值,并返回 20,这成为 `+` 运算符的第一个参数。接下来,加法运算符弹出第二个参数,即 `^`(#4)。然后 `^` 运算符弹出两个参数,3 和 2(#5),并返回 8。最后,`+` 运算符返回 28,即 8 和 20 的和。
伪代码是
double Evaluate()
item = first item on the stack
if item is a value
return the value
else
return item->Evaluate()
endif
double ItemXYZ::Evaluate(stack)
return fctXYZ(stack->pop(),stack->pop(), …)
double Pop()
if the next item on the stack is a value
return the value
else
return next item->Evaluate()
endif
同样,这是基本算法。实际上,它仅用于解析步骤,在求值步骤中使用更快的迭代算法。
使用 C++ 库和 COM 组件
本节介绍了如何使用 MTParser C++ 库和 COM 组件完成最常见的任务。C++ 代码将用于展示如何使用 C++ 库,而为了多样性,VB6 和 C# 代码将用于 COM 组件。
将解析器包含到您的项目中
在您开始求值数学公式之前,您必须将解析器集成到您的应用程序中。
[C++]
选择 Unicode 或 ANSI 字符串格式
您必须做出选择!如果您想遵循国际化准则,则应使用 Unicode。您可以在“UnicodeANSIDefs.h”文件中指明您的选择。该文件根据您选择的字符串格式定义正确的字符串操作函数。例如,在库代码中,不是直接使用 `std:string`,而是使用 `MTSTRING`。然后,如果使用 Unicode 版本,`MTSTRING` 将被定义为 `std::wstring`。这是库可以同时使用 Unicode 或 ANSI 字符串(但不能同时使用!)的技巧。
其他编译标志
- `_MTPARSER_USE_PLUGIN`:如果定义,将编译插件功能。
- `_MTPARSER_USE_LOCALIZATION`:如果定义,将编译本地化功能。
默认情况下,这些标志在 `MTParserPublic.h` 文件中定义。
编译库
如果您没有 `.lib` 文件,那么您必须自己编译库。您将能够使用 Visual Studio 6、.NET 2003 和 .NET 2005 编译库。
注意:请确保使用与您的项目相同的运行时库版本(例如,多线程 DLL)进行编译。
以下列表简要描述了每个项目
- MTParserLib:核心 C++ 解析器库。
- COM Library:COM 解析器库版本。允许多种语言使用解析器功能。COM 库版本只是核心库的包装器。
- MTParserInfoFile:用于读取本地化目的所需的 XML 信息文件的 COM 对象。它使用 .NET XML 服务,并且在核心库之外,因为 .NET 服务在 VC6 中不可用。
- Plugins/MTParserPlugin:用于生成 TLB 文件的插件 IDL 接口。
- Plugins/MTDatePlugin:日期和时间插件。
- Plugins/MTNumAlgoPlugin:数值算法插件。
- Code Samples/C++ Library/C++ Client:使用 C++ 解析器库版本的主要演示应用程序。
- Code Samples/COM Library/C++ Client:使用 COM 解析器库版本 C++ 演示应用程序。
- Code Samples/COM Library/C# Client:使用 COM 解析器库版本 C# 演示应用程序。
- Code Samples/COM Library/VB Client:使用 COM 解析器库版本 VB6 演示应用程序。
如果您只使用基本功能,则只需编译 MTParserLib 项目。
Visual Studio 6
转到“项目设置”|“C/C++”|“代码生成”,然后选择“使用运行时库”。如果您用与项目不同的运行时库编译库,则会出现链接错误,指出存在多个符号定义。
使用 Visual Studio 6,您将能够编译以下项目:
- MTParserLib/MTParserLib.dsw
- Code Samples/C++ Library/C++ Client/MathExpr.dsw
Visual Studio .NET 2003, 2005
转到项目属性页,然后到 C/C++|代码生成,然后选择“运行时库”。通常,您将在调试模式下使用多线程调试 DLL,在发布模式下使用多线程 DLL。
使用 Visual Studio .NET,您将能够编译所有项目,除了 VB6 示例。
在项目中包含正确的头文件
您需要包含的唯一头文件是 `MTParser.h` 和 `MTParserLocalizer.h`(如果您使用本地化功能)。数学解析器类是 `MTParser`。
#include "../MTParserLib/MTParser.h" #include "../MTParserLib/MTParserLocalizer.h"
注意:我假设库位于项目旁边的一个目录中。例如,如果您的项目在 `c:\project\MyProject\` 中,那么数学解析器库在 `c:\project\MTParserLib\` 中。
将库链接到您的项目
有四种库版本,分别对应 Debug/Release 和 ANSI/Unicode 的每种组合。您会在 `MTParserLib` 下的 `lib` 目录中找到 `.lib` 文件。您可以将正确的库添加到项目链接设置中,或使用以下预编译器命令:
#ifdef _DEBUG
#ifdef _UNICODE
#pragma comment(lib, "../MTParserLib/lib/MTParserUd.lib")
#else
#pragma comment(lib, "../MTParserLib/lib/MTParserd.lib")
#endif
#else
#ifdef _UNICODE
#pragma comment(lib, "../MTParserLib/lib/MTParserU.lib")
#else
#pragma comment(lib, "../MTParserLib/lib/MTParser.lib")
#endif
#endif
上面的代码根据您的项目设置自动链接到正确的库版本。
我强烈建议您在进行项目基准测试时使用发布版本,因为它确实更快。
[VB6]
您需要做的就是将 MTParser 组件添加到您的项目引用中。要做到这一点,在 Visual Basic 6.0 中,转到“项目”|“引用”|“浏览”,然后浏览 `MTParserCOM.dll` 文件。最常见的问题是忘记在系统中注册 COM 文件。要手动执行此操作,请使用位于 `Windows\System32` 目录中的 `regsvr32.exe` 应用程序。运行“regsvr32 MTParserCOM.dll”。
[C#]
您需要做的就是将 MTParser 组件添加到您的项目引用中。要做到这一点,在 Visual Studio .NET 2003 中,转到“项目”|“添加引用”|“浏览”,然后浏览 `MTParserCOM.dll` 文件。如 VB6 部分所述,请确保注册 COM 文件。要使用解析器命名空间,请添加以下行:
using MTPARSERCOMLib;
创建解析器对象
您可以创建一个新对象并从头开始配置它,也可以复制现有的对象配置。
使用默认配置初始化对象
这是创建新解析器对象的基本方法。默认配置包括默认的运算符和函数,并将点(.)作为小数点,将逗号(,)作为函数参数分隔符。
[C++]
调用空构造函数
MTParser parser; // default configuration
[VB6]
像往常一样创建一个新对象
Dim parser As New MTParser
[C#]
像往常一样创建一个新对象
MTParser parser = new MTParser();
使用另一个对象配置初始化对象
当您想要使用多个解析器对象时,配置一个对象然后复制它比配置所有对象更方便。所有对象状态都会被复制,包括:当前数学公式、变量、常量、自定义函数、自定义运算符和语法。这种复制对于确保新对象能够继续正常运行至关重要,即使原始对象已被销毁。
[C++]
有两种方法可以使用另一个对象配置来配置新对象。第一种方法是使用复制构造函数,第二种方法是调用赋值运算符。
MTParser parserTemplate;
// Configure the template object…
parserTemplate.enableAutoVarDefinition(true);
// Using the copy-constructor to configure a new object
MTParser parser2(parserTemplate);
// Using the assignment operator to configure an object
MTParser parser3;
parser3 = parser2;
[VB6]
Dim parserTemplate As New MTParser
Dim parser As New MTParser
'Configure the template object…
parserTemplate.autoVarDefinitionEnabled = True
' Using the copy method to re-configure an object
parser.Copy parserTemplate
[C#]
MTParser parserTemplate = new MTParser();
MTParser parser = new MTParser();
// Configure the exprTemplate object…
parserTemplate.autoVarDefinitionEnabled = 1;
// Using the copy method to re-configure an object
parser.Copy(exprTemplate);
求值数学表达式
这是这个库的主要目的!如果您想计算简单表达式(如“2+2”)或任意复杂度和长度的表达式(如“pi*min(x+y+sin(z)/2^3-40.9988*2, avg(y,x*10,3,5))”)的结果,那么本节将向您展示它是如何工作的。
求值表达式并立即获取结果
这是求值表达式最简单、最直接的方法。
[C++]
MTParser parser;
MTDOUBLE result = parser.evaluate(_T("2+10*2"));
[VB6]
Dim parser As New MTParser
Result = parser.Evaluate("2+10*2")
您通过使用“On Error GoTo”语句以标准方式处理错误。
[C#]
MTParser parser = new MTParser();
double result = parser.evaluate("2+10*2");
多次求值表达式
如果您想多次求值表达式,并使用不同的变量值,那么先编译表达式然后求值表达式将提高性能。以下代码对同一个表达式求值 1000 次:
[C++]
有两种方法:一种使用循环,第二种使用批量求值。在 C++ 中,两种方法具有相同的性能,但第二种方法在您已经有一堆变量值需要处理时更好。原因是变量值将自动从向量中提取。
以下代码在循环中多次求值表达式:
MTDOUBLE x;
MTParser parser;
parser.defineVar(_T("x"), &x);
parser.compile(_T("x+2*sin(x)"));
for( int t=0; t < 1000; t++ )
{
x = t; // new variable value
MTDOUBLE result = parser.evaluate();
}
以下代码一次解析调用中多次求值表达式:
unsigned int nbEvals = 1000;
// Create variable object
MTDoubleVector *pX = new MTDoubleVector(_T("x"));
// Defines variables in the parser. pX is now owned by the parser.
MTParser parser;
parser.defineVar(pX);
// Allocate memory for variable values and results
MTDOUBLE *pXVector = new MTDOUBLE[nbEvals];
MTDOUBLE *pResults = new MTDOUBLE[nbEvals];
// Add your code to fill the value vector…
// Assign variable values
pX->setValues(pXVector, nbEvals);
// Compile the expression only once
parser.compile(_T("x+2*sin(x)"));
// Evaluate the expression for all variable value in one function call
parser.evaluateBatch(nbEvals, pResults);
[VB6]
以下代码在循环中多次求值表达式:
Dim x As New MTDouble
Dim parser As New MTParser
x.Create "x", 1
parser.DefineVar x
parser.Compile "x+y*sin(z)"
For i = 1 To 1000
x.Value = i ' new variable value
result = parser.EvaluateCompiled()
Next i
以下代码多次求值表达式,但只进行一次函数调用。请注意特殊的 VB6 函数 **setValueVectorVB6** 和 **evaluateCompiledBatchVB6**。需要这两种方法来适应 VB6 和 .Net。
Dim parser As New MTParser
Dim x As New MTDoubleVector
Dim y As New MTDoubleVector
Dim z As New MTDoubleVector
x.Create ("x")
y.Create ("y")
z.Create ("z")
parser.defineVar x
parser.defineVar y
parser.defineVar z
' Compile the expression only once
parser.compile "x+2*sin(x)"
' Generate random variable values...
Dim nbEvals As Long
nbEvals = 800000
Dim xval() As Double
ReDim xval(nbEvals) As Double
' Add your code to fill the value vector…
' Set values...
x.setValueVectorVB6 xval
' this will contain all the results after evaluations
Dim results() As Double
ReDim results(nbEvals) As Double
' Evaluate the expression for all
' variable value in one function call
parser.evaluateCompiledBatchVB6 nbEvals, results
[C#]
与 C++ 一样,有两种方法:一种是使用循环,第二种是使用批量求值。但与 C++ 不同的是,第二种方法确实更快(快了多达 40 倍!),因为 COM 调用非常慢。
以下代码在循环中多次求值表达式:
int nbEvals = 1000;
MTDouble x = new MTDouble();
x.create("x", 0.0);
MTParser parser = new MTParser();
parser.defineVar(x as IMTVariable);
parser.compile("x+2*sin(x)");
for( int t=0; t < 1000; t++ )
{
x.value = t; // new variable value
double result = parser.evaluateCompiled();
}
以下代码多次求值表达式,但只进行一次函数调用:
MTDoubleVector x = new MTDoubleVector();
x.create("x");
MTParser parser = new MTParser();
parser.defineVar(x as IMTVariable);
// Allocate memory for variable values and results
double[] xval = new double[nbEvals];
double[] results = new double[nbEvals];
// Add your code to fill the value vector…
// Assign variable values
x.setValueVector(xval);
// Compile the expression only once
parser.compile("x+2*sin(x)");
// Evaluate the expression for all
// variable value in one function call
parser.evaluateCompiledBatch(nbEvals, results);
管理变量
变量是一个特殊的符号,在求值时会被替换为值,但与常量不同,它的值可以被更改。它可以用于创建参数化公式,例如“3t+10”,其中 *t* 是时间变量。
定义变量
在您可以在表达式中使用变量之前,除非您使用自动变量定义功能,否则必须先定义它。否则,解析器将无法识别该变量,并会抛出异常。
[C++]
原则是将解析器中的变量名链接到您的程序中的实际变量值。在 C++ 中,这种链接是通过使用变量指针建立的。
以下代码示例定义了一个名为“x”的变量,并将其值链接到您的程序中的变量“myVar”:
MTDOUBLE myVar;
MTParser parser;
parser.defineVar(_T("x"), &myVar);
求值包含这样定义的变量的表达式时,值将通过变量指针自动获得。这种方法避免了您必须通过调用 `setVarValue` 等方法手动设置变量值。相反,要更改变量值,只需为 C++ 变量赋一个新值,例如:
myVar = 10;
[VB6]
以下代码定义了一个名为“x”的变量。
Dim x As New MTDouble
Dim parser As New MTParser
x.Create "x", 1
parser.defineVar x
`Create` 方法使用名称和默认值初始化变量对象。要更改或获取变量值,请使用 `Value` 属性,如下所示:
x.Value = 10 ' set the variable value
val = x.Value ' get the variable value
[C#]
以下代码定义了一个名为“x”的变量。
MTDouble x = new MTDouble();
MTParser parser = new MTParser();
x.create("x", 0);
parser.defineVar(x as IMTVariable);
`create` 方法使用名称和默认值初始化变量对象。要更改或获取变量值,请使用 `value` 属性,如下所示:
x.value = 10 // set the variable value
double val = x.value // get the variable value
仅定义已使用的变量
当可能的变量数量非常多时,预先全部定义它们,仅仅因为其中一些可能在一个表达式中使用,这不是很优化。相反,您可以询问解析器使用了哪些变量并且尚未定义。这允许您仅定义必要的变量。默认情况下,如果解析器遇到未定义的变量,它会抛出异常。要更改此行为,您必须启用自动变量定义功能。
[C++]
最简单的方法是让解析器使用默认值定义变量,然后您用所需的变量重新定义它们。以下代码展示了其工作原理:
MTParser parser;
parser.enableAutoVarDefinition(true);
parser.compile(_T("x+y+z"));
double *pVars = new double[parser.getNbUsedVars()];
for( unsigned int t=0; t < parser.getNbUsedVars(); t++ )
{
parser.redefineVar(parser.getUsedVar(t).c_str(), &pVars[t]);
}
首先,您通过调用 `enableAutoVarDefinition` 方法启用自动变量定义功能,然后编译表达式。其次,您遍历每个使用的变量,并重新定义它们以指向有效的内存位置。您也可以使用新的 `MTVariableI` 对象重新定义变量。
工厂设计模式非常适合这里。它可以用于获取与每个变量关联的变量对象或内存指针。事实上,这种设计模式已经实现了,下一节将对此进行描述。
如果您提供一个变量工厂,当需要定义一个变量时,它将被调用。要创建变量工厂,您必须实现 `MTVariableFactoryI` 接口。它唯一的职责是创建新的变量对象。
以下代码展示了如何启用自动变量定义功能并设置变量工厂:
class MyVariable : public MTVariableI { public: virtual const MTCHAR* getSymbol(){ return _T("symbol"); } virtual MTDOUBLE evaluate(unsigned int nbArgs, const MTDOUBLE *pArg){ return 1.32213; } virtual MTVariableI* spawn() throw(MTParserException){ return new MyVariable(); } }; class MyVarFactory : public MTVariableFactoryI { public: virtual MTVariableI* create(const MTCHAR *symbol) { return new MyVariable(); } virtual MTVariableFactoryI* spawn(){ return new MyVarFactory (); } }; parser.enableAutoVarDefinition(true, new MyVarFactory());
“true”参数用于启用该功能,第二个参数是变量工厂对象。当解析器遇到未定义的变量时,它将使用变量符号调用工厂的 `create` 方法。
[VB6]
以下代码在不预先定义变量的情况下编译表达式,然后重新定义每个使用的变量:
Dim parser As New MTParser
parser.autoVarDefinitionEnabled = 1
parser.compile "x+y+z"
Dim vars() As MTDouble
ReDim vars(0 To parser.getNbUsedVars() - 1) As MTDouble
For t = 0 To parser.getNbUsedVars - 1
Dim symbol As String
symbol = parser.getUsedVar(t)
Set vars(t) = New MTDouble
vars(t).Create symbol, 0
parser.redefineVar vars(t)
Next t
[C#]
以下代码在不预先定义变量的情况下编译表达式,然后重新定义每个使用的变量:
MTParser parser = new MTParser();
parser.autoVarDefinitionEnabled = 1;
parser.compile("x+y+z");
MTDouble[] vars = new MTDouble[parser.getNbUsedVars()];
for(int t=0; t<parser.getNbUsedVars(); t++)
{
vars[t] = new MTDouble();
vars[t].create(parser.getUsedVar(t), t);
parser.redefineVar(vars[t] as IMTVariable);
}
扩展解析器
可以通过定义自定义常量、函数和运算符来扩展解析器语言。
定义常量
常量是一个特殊的符号,在求值时会被替换为值。使用常量而不是值有助于使数学公式更清晰,特别是对于广为人知的数值。解析器也可以进行优化,因为它知道这些值是常量。常量的例子有 pi (3.14159…) 和 e (2.71…)。
要定义常量,请使用 `defineConst` 方法。第一个参数是常量名称,第二个参数是常量值。
[C++]
MTParser parser; parser.defineConst(_T("pi"), 3.14159265359);
[VB6]
Dim parser As New MTParser
parser.defineConst "pi", 3.14159265359
[C#]
MTParser parser = new MTParser();
parser.defineConst("pi", 3.14159265359);
定义自定义函数或运算符
仅限 C++ 库和 .Net COM
运算符和函数已被完全抽象,因此您可以运行时添加自己的运算符和函数,而无需修改数学解析器代码。这种通用化通过消除所有 `switch case` 来选择运算符和函数,大大简化了数学解析器。因此,代码非常美观。
[C++]
以下代码是定义求和函数所需的所有内容:
class SumFct : public MTFunctionI
{
virtual MTSTRING getSymbol(){return _T("sum"); }
virtual MTSTRING getHelpString(){ return _T("sum(v1,v2,v3,...)"); }
virtual MTSTRING getDescription()
{ return _T("Return the sum of a set of values"); }
virtual int getNbArgs(){ return c_NbArgUndefined; }
virtual MTDOUBLE evaluate(unsigned int nbArgs, const MTDOUBLE *pArg)
{
MTDOUBLE val = 0;
for( unsigned int t=0; t < nbArgs; t++ )
{
val += pArg[t];
}
return val;
}
virtual MTFunctionI* spawn(){ return new SumFct(); }
};
`getSymbol` 方法返回在数学表达式中找到的函数名称。`getHelpString` 方法提供正确的语法,`getDescription` 方法提供函数的简短描述。`getNbArgs` 方法返回此函数所需的参数数量。`c_NbArgUndefined` 常量表示此函数接受不确定数量的参数。最后,`Evaluate` 方法计算求和并返回结果。还有一个特殊的 `spawn` 方法,它返回一个新的 `SumFct` 对象。此方法的作用是允许复制解析器配置。
创建自定义运算符和函数类后,可以使用以下代码告知解析器使用它们:
try
{
parser.defineOp(new MyOp());
…
parser.defineFunc(new MyFct());
…
}
catch( MTParserException &e ){}
要定义运算符,请调用 `defineOp` 方法并传入自定义运算符对象。`defineFunc` 方法对自定义函数执行相同的操作。在上面的示例中,解析器将在其销毁时自动释放对象内存,因此您无需保留每个创建对象的指针并自行删除。
运算符和函数重载
此功能允许您定义多个同名但参数数量不同的函数。例如,Random 函数可以接受零个或两个参数:
// Random with zero argument
class RandFct : public MTFunctionI
{
virtual MTSTRING getSymbol(){return _T("rand"); }
virtual MTSTRING getHelpString(){ return _T("rand()"); }
virtual MTSTRING getDescription()
{ return _T("Random value between 0 and 1"); }
virtual int getNbArgs(){ return 0; }
virtual bool isConstant(){ return false; }
virtual MTDOUBLE evaluate(unsigned int nbArgs, const MTDOUBLE *pArg)
{
return rand()/(double)RAND_MAX;
}
virtual MTFunctionI* spawn(){ return new RandFct(); }
};
// Random with two arguments
class RandMinMaxFct : public MTFunctionI
{
virtual MTSTRING getSymbol(){return _T("rand"); }
virtual MTSTRING getHelpString(){ return _T("rand(min, max)"); }
virtual MTSTRING getDescription()
{ return _T("Random value between min and max"); }
virtual int getNbArgs(){ return 2; }
virtual bool isConstant(){ return false; }
virtual MTDOUBLE evaluate(unsigned int nbArgs, const MTDOUBLE *pArg)
{
return pArg[0]+(rand()/(double)RAND_MAX)*(pArg[1]-pArg[0]);
}
virtual MTFunctionI* spawn(){ return new RandMinMaxFct(); }
};
第一个 Random 函数返回 0 到 1 之间的值。第二个更专业的函数允许用户指定随机值的范围。
另一个函数重载用途是性能优化。例如 `min` 和 `max` 函数。这些函数可以接受不确定数量的参数,但大多数情况下,只使用两个或三个参数。因此,定义了三个函数原型:两个参数、三个参数和不确定数量的参数。具有确定数量参数的函数通常更快,因为它们只处理一个预定义的情况;因此,代码可以针对这种情况进行优化(即,没有循环)。
[C#]
当您无法(或没有勇气)在 C++ 或插件中开发您的函数时,您的另一个选择是实现 IMTFunction COM 接口。性能平均会降低约 30%。但我和您一样同意,这确实容易得多!
以下是接受不确定数量参数的求和函数的代码。如您所见,可以实现多个 `evaluateX` 方法以提供更好的性能。如果您的函数总是接受 2 个参数,您只需要实现 `evaluate2` 方法。`getNbArgs` 方法返回的特殊 -1 值表示不确定数量的参数。
public class MySumFunction : IMTFunction
{
public double evaluate0()
{
throw new Exception("The method or operation is not implemented.");
}
public double evaluate1(double arg)
{
return arg;
}
public double evaluate2(double arg, double arg2)
{
return arg + arg2;
}
public double evaluate3(double arg, double arg2, double arg3)
{
return arg + arg2 + arg3;
}
public double evaluate(Array pArgs)
{
double sum = 0;
for (int t = 0; t < pArgs.Length; t++)
{
sum += (double)pArgs.GetValue(t);
}
return sum;
}
public string getDescription()
{
return "Computes the sum of many values";
}
public string getHelpString()
{
return "slowsum(x,y,z,...)";
}
public int getNbArgs()
{
return -1;
}
public string getSymbol()
{
return "slowsum";
}
}
以下代码定义您的函数:
MTParser parser = new MTParser(); parser.defineFunc(new MySumFunction());
定义宏函数
宏函数有助于简化常用表达式的书写。例如,如果您经常使用定义为 `sqrt(x^2+y^2)` 的欧几里得距离,那么定义一个名为“euc(x,y)”的宏可能是一个好主意。
要定义宏,请使用 `defineMacro` 方法。第一个参数是宏原型,第二个是宏函数,第三个是简短描述。
[C++]
MTParser parser;
parser.defineMacro(_T("euc(x,y)"), _T("sqrt(x^2+y^2)") ,
_T("Euclidean distance"));
[VB6]
Dim parser As New MTParser
parser.defineMacro "euc(x,y) ", "sqrt(x^2+y^2)" , "Euclidean distance"
[C#]
MTParser parser = new MTParser();
parser.defineMacro( "euc(x,y)", "sqrt(x^2+y^2)"), "Euclidean distance");
加载插件
在运行时加载函数、运算符和常量。`loadPlugin` 方法接受一个类标识符(CLSID)字符串。此字符串标识一个 COM 对象,应由插件开发者提供给您。CLSID(可以存储为字符串)应从文件或注册表中检索。这允许您在应用程序发布后添加和修改类标识符,从而实现插件的目标。
[C++]
MTParser parser;
parser.loadPlugin(_T("{4C639DCD-2043-42DC-9132-4B5C730855D6}"));
[VB6]
Dim parser As New MTParser
parser.loadPlugin "{4C639DCD-2043-42DC-9132-4B5C730855D6}"
[C#]
MTParser parser = new MTParser();
parser.loadPlugin("{4C639DCD-2043-42DC-9132-4B5C730855D6}");
加载所有可用插件
每个插件关联的 XML 信息文件包含插件的 CLSID。因此,解析器可以自动查找信息文件并发现它们的 CLSID。这是处理插件的一种非常灵活的方式,因为您可以添加和删除插件而不修改您的程序。以下代码示例加载当前目录中的所有插件:
[C++]
MTParser parser;
MTSTRING directory = _T("./");
MTSTRING pluginFileSearchPattern = _T("*.xml");
parser.loadAllPlugins(directory.c_str(), pluginFileSearchPattern.c_str());
[VB6]
Dim parser As New MTParser
parser.loadAllPlugins App.Path, "*.xml"
[C#]
MTParser parser = new MTParser();
string directory = System.AppDomain.CurrentDomain.BaseDirectory;
parser.loadAllPlugins( directory, "*.xml");
本地化解析器
许多内容需要本地化:错误消息、项文档(例如,函数描述)和表达式语法(例如,小数点和参数分隔符字符)。
初始化本地化器
本地化器是一个单例(唯一实例)对象,有助于本地化的各种任务。总的来说,它包含错误消息和项文档的本地化字符串。因此,当您需要本地化字符串时,只需向本地化器询问。
在使用本地化器之前,您必须告诉它要使用哪个区域设置以及在哪里查找本地化信息。区域设置字符串遵循标准,如 ISO 两字母语言标识符。例如,英语是“en”,法语是“fr”。本地化信息存储在 XML 文件中(与插件附带的文件相同)。XML 文件为每个区域设置包含一个部分。接下来是一个 XML 文件示例:
<?xml version="1.0" encoding="utf-8" ?>
<LibraryInfo schema="2" type="static" data1="" data2="" version="3">
<Resource LCID="en">
<function id="sin" symbol="sin" args="x" argDescs="" description="Sine" />
<function id="asin" symbol="asin" args="x"
argDescs="" description="Arcsine" />
<function id="sinh" symbol="sinh" args="x"
argDescs="" description="Hyperbolic sine" />
…
<operator id="+" symbol="+" args="x,y"
description="Add two numbers" />
<operator id="minus" symbol="-" args="x,y"
description="Substract two numbers" />
<operator id="unaryMinus" symbol="-" args="x"
description="Unary minus" />
…
<exception id="MTDEFEXCEP_SyntaxArgDecConflict"
description="The argument separator character
and the decimal point character
are the same"/>
<exception id="MTDEFEXCEP_SyntaxArgVarConflict"
description="The argument separator character and one of
the variable name delimiter
characters are the same"/>
<exception id="MTDEFEXCEP_SyntaxDecVarConflict"
description="The decimal point character and one of the
variable name delimiter
characters are the same"/>
…
</Resource>
<Resource LCID="fr">
<function id="sin" symbol="sin" args="x"
argDescs="" description="Sinus" />
<function id="asin" symbol="asin" args="x"
argDescs="" description="Arc sinus" />
<function id="sinh" symbol="sinh" args="x"
argDescs="" description="Hyperbolique sinus" />
…
<operator id="+" symbol="+" args="x,y"
description="Additionne deux nombres" />
<operator id="minus" symbol="-" args="x,y"
description="Soustrait deux nombres" />
<operator id="unaryMinus" symbol="-" args="x"
description="Soustraction unaire" />
…
<exception id="MTDEFEXCEP_SyntaxArgDecConflict"
description="Les caractères de séparation d'arguments
et de point décimal sont les mêmes"/>
<exception id="MTDEFEXCEP_SyntaxArgVarConflict"
description="Les caractères de séparation d'arguments
et de délimiteurs de noms de variables sont les mêmes"/>
<exception id="MTDEFEXCEP_SyntaxDecVarConflict"
description="Les caractères de point décimal et de
délimiteurs de noms de variables sont les mêmes"/>
…
</Resource>
</LibraryInfo>
`LibraryInfo` 节点有四个属性。`schema` 属性是用于验证 XML 文件格式或模式的版本号。例如,在将来的版本中,可能会添加或删除部分,并且模式编号将相应地递增。`type` 属性表示信息文件是否与插件相关联。在这种情况下,`data1` 属性设置为插件文件名,`data2` 属性设置为插件 CLSID。这允许通过枚举信息文件并检索 CLSID 来自动加载插件。
以下是资源部分。`LCID` 属性是区域设置字符串标识符。因此,当您请求某个区域设置时,本地化器会尝试查找具有相应 LCID 的资源部分。在资源部分中,定义了函数、运算符、常量、变量和异常。
以下代码将区域设置设置为法语 (fr) 并加载当前目录中存在的所有信息文件:
[C++]
MTParserLocalizer::getInstance()->setLocale(_T("fr"));
MTParserLocalizer::getInstance()->registerAllLibraries(_T("./"), _T("*.xml"));
[VB6]
Dim localizer As New MTParserLocalizer
localizer.setLocale "fr"
localizer.registerAllLibraries App.Path, "*.xml"
[C#]
string dir = System.AppDomain.CurrentDomain.BaseDirectory;
MTParserLocalizer localizer = new MTParserLocalizer();
localizer.setLocale("fr");
localizer.registerAllLibraries( dir, "*.xml");
本地化错误消息
错误消息在 XML 文件中声明,从而允许您轻松添加支持的语言并修复翻译错误。这些信息文件在运行时加载。以下行是 XML 文件英文部分的一部分,声明了一个异常:
<exception id="MTDEFEXCEP_OpAlreadyDefined"
description="Operator already defined: '%itemName'"/>
- `id`: 唯一的异常字符串标识符。使用字符串而不是数字允许定义新异常(例如,通过插件)而不必担心已使用的 ID。
- `description`: 带有参数的异常消息。参数将在运行时替换为实际的异常值。
以下代码使用本地化器获取本地化错误消息:
[C++]
MTSTRING getAllExceptionLocalizedString(const MTParserException &e)
{
MTSTRING msg;
for( unsigned int t=0; t<e.getNbDescs(); t++ )
{
MTSTRING desc;
// Take the localized exception description if available
try
{
desc =
MTParserLocalizer::getInstance()->getExcep(
e.getException(t)->getData());
}
catch( MTParserException )
{
// description not available...so take the default english message
desc = e.getDesc(t).c_str();
}
msg += desc;
if( t != e.getNbDescs()-1 )
{
msg += _T("\r\n");
}
}
return msg;
}
[VB6]
Private Function getLastExcepText(parser As MTParser) As String
Dim Msg As String
Dim e As New MTExcepData
Dim localizer As New MTParserLocalizer
Dim desc As String
Do
parser.getLastExcep e
If e.getID() <> "ok" Then
desc = getLocalizedExcepText(e, localizer)
If desc = "" Then
' Take the default description
desc = e.getDescription()
End If
Msg = Msg + desc
Msg = Msg + vbCrLf
End If
Loop Until e.getID() = "ok"
getLastExcepText = Msg
End Function
' Get the localized exception text. Return an empty string if not available
Private Function getLocalizedExcepText(data As MTExcepData, _
localizer As MTParserLocalizer) As String
On Error GoTo unavailableDesc
getLocalizedExcepText = localizer.getExcep(data)
Exit Function
unavailableDesc:
getLocalizedExcepText = ""
End Function
[C#]
string getLastExcepText(MTParser parser)
{
string msg = "";
MTExcepData e = new MTExcepData();
MTParserLocalizer loc = new MTParserLocalizer();
do
{
parser.getLastExcep(e);
if (e.getID() != "ok")
{
string desc = "";
try
{
desc = loc.getExcep(e);
}
catch( Exception )
{
// No localized description available,
// so take the default text
desc = e.getDescription();
}
msg = msg + desc;
msg = msg + Environment.NewLine ;
}
} while(e.getID() != "ok");
return msg;
}
本地化项文档
函数、运算符、常量和变量都附带用户文档。这使用户能够学习和记住每个项的作用以及如何使用它。
以下行是 XML 文件英文部分的一部分,提供了函数的文档:
<function id="randminmax" symbol="rand" args="min,max"
argDescs="lower bound,upper bound"
description="Random value between min and max" />
- `id`: 唯一的标识符,因为允许函数重载。例如,有两个随机函数:一个不接受参数并返回 0 到 1 之间的数字,另一个接受最小值和最大值并返回这两个值之间的数字。
- `symbol`: 函数符号。目前无法翻译。因此,符号在所有语言中必须相同。
- `args`: 由逗号分隔的函数参数名称列表。
- `argDescs`: 由逗号分隔的函数参数描述列表。
- `description`: 函数描述。
本地化解析器语法
为了适应国际用户,您可以根据用户偏好配置语法。
以下代码自动使用 Windows 系统中注册的用户语法偏好设置:
[C++]
MTParser parser;
parser.useLocaleSettings();
[VB6]
Dim parser As New MTParser
parser.useLocaleSettings
[C#]
MTParser parser = new MTParser();
parser.useLocaleSettings();
您还可以手动指定以下项的语法设置:
- 小数点:x.yyyyy
- 函数参数分隔符:f(x,y)
- 变量名起始-结束分隔符:[myVariable]
[C++]
以下代码读取区域设置的小数点字符,并相应地设置解析器语法:
MTParser parser;
LCID lcid = GetThreadLocale(); // get the current locale id
MTCHAR buf[4];
if( GetLocaleInfo(lcid, LOCALE_SDECIMAL, buf, 4) )
// get the decimal point character
{
MTSYNTAX syntax;
syntax = parser.getSyntax();
// make sure that the argument separator character is different
// from the decimal point character
syntax.argumentSeparator = ',';
if( buf[0] == ',' )
{
syntax.argumentSeparator = ';';
}
syntax.decimalPoint = buf[0];
parser.setSyntax(syntax);
}
`getSyntax()` 方法检索当前语法。这允许您仅设置对您有意义的语法元素,并为剩余的元素使用默认元素。接下来,函数参数分隔符设置为逗号字符,小数点设置为点字符。在法语中,函数参数分隔符可以设置为“;”,小数点字符设置为“,”。`setSyntax()` 方法实际上注册了语法。
[VB6]
Dim parser As New MTParser
Dim syntax As sMTSyntax
syntax = parser.getSyntax
syntax.decimalPoint = ASC(",")
syntax.argumentSeparator = ASC(";")
parser.setSyntax syntax
[C#]
MTParser parser = new MTParser();
sMTSyntax syntax = parser.getSyntax();
syntax.decimalPoint = ',';
syntax.argumentSeparator = ';';
parser.setSyntax(ref syntax);
一点本地化说明
字符串中的冗余比拆分句子为小“可重用”词更好。例如,如果您有以下两条错误消息:“Operator name cannot be null”(运算符名称不能为空)和“Function name cannot be null”(函数名称不能为空),您可以写成:
//(IDS_xxx could be strings in your application resources)
std::wstring FormatNullError(int itemType)
{
std::wstring msg;
if itemType == Function then
msg = IDS_FUNCTION
else
msg = IDS_OPERATOR
msg += IDS_CANNOT_BE_NULL
return msg;
}
这太以英语为中心了!首先,在某些语言(如法语)中,您必须知道名词的性别才能正确地匹配动词。在上面的例子中,您没有这些信息,因此 `IDS_CANNOT_BE_NULL` 字符串无法准确翻译。其次,词序可能需要修改。在法语中,句子倒置为:“Le nom de la fonction ne peut être null”,相当于“The name of the function cannot be null”。对于函数是“La”,对于运算符是“ L’ ”。结论:您不想在运行时连接单词。这是翻译者的工作,他拥有高效且低成本地翻译冗余词的工具。您的工作是写完整且自包含的句子。
处理错误
付出了特殊的努力来简化错误处理任务。错误通过异常机制在整个 API 中统一报告。没有方法返回奇怪的错误代码。
[C++]
有两种异常类:`MTException` 和 `MTParserException`。前者是通用的异常,只包含异常描述。使用此异常,您不会获得任何异常参数。唯一的优点是默认错误描述易于访问。第二个异常类包含附加字段,可以生成本地化错误消息。
`throw(MTParserException)` 声明子句已用于可能抛出异常的所有方法。因此,当您在方法原型旁边看到此代码时,请务必在使用它时使用 `try`-`catch` 语句。
以下代码展示了如何捕获这两种异常:
try
{
…
}
catch( MTException &e )
{
// catch the simplified exception
Display(e.m_description);
}
或者
try
{
…
}
catch( MTParserException &e )
{
// catch the detailed exception
Display(e.getException(0)->getData().description);
}
实际上,异常机制支持链式异常。这用于报告通过多个调用层发生的复杂异常。在这种情况下,每一层都可以为异常添加上下文信息。结果是,如果需要,可以获得不同级别的详细信息。以下代码显示了如何显示对象中包含的所有异常:
try
{
…
}
catch( MTParserException &e )
{
for( int t=0; t < e.size(); t++ )
{
Display(e.getException(t)->getData().description;
}
}
索引为 0 的异常最后发生,因此是最一般的异常。
[VB6]
抛出异常的方法的描述已附加“THROWS EXCEPTION”语句。因此,当您看到这些词时,请务必在使用此方法时使用 `ON ERROR` 语句。以下代码展示了如何处理错误:
Private Sub MySub()
On Error GoTo errorHandling
…
Exit Sub
errorHandling:
MsgBox "Error: " & Err.Description
End Sub
与 C++ 版本一样,支持链式异常。以下函数检索所有可用的异常描述:
Private Function getLastExcepText(parser As MTParser) As String
Dim Msg As String
Dim e As New MTExcepData
Do
parser.getLastExcep e
If e.getID() <> "ok" Then
Msg = Msg + e.getDescription()
Msg = Msg + vbCrLf
End If
Loop Until e.getID() = "ok"
getLastExcepText = Msg
End Function
您只需轮询解析器对象,直到它返回 `"ok"` 异常。
[C#]
以下代码返回一个包含所有异常文本的消息:
string getLastExcepText(MTParser parser)
{
string getLastExcepText = "";
string Msg = "";
MTExcepData e = new MTExcepData();
do
{
parser.getLastExcep(e);
if (e.getID() != "ok")
{
Msg = Msg + e.getDescription();
Msg = Msg + Environment.NewLine;
}
} while(e.getID() != "ok");
getLastExcepText = Msg;
return getLastExcepText;
}
您只需轮询解析器对象,直到它返回 `"ok"` 异常。
使用 COM 插件
插件允许在运行时加载函数、运算符和常量。它们需要用 C++ 编写。
创建插件
以下是使用 Visual C++ 6.0 创建插件的步骤:
- 创建一个新的 ATL/COM 项目。
- 在“类视图”选项卡中,创建一个新的简单 ATL 对象。
- 我建议您使用以下 ATL 对象属性:
- 线程模型 = Free。这允许您的插件在任何线程中使用,而无需特殊的封送代码。
- 勾选“Free threaded marshaller”框。与前一个设置效果相同。
- 勾选“Support ISupportErrorInfo”框。这允许您的插件抛出带有文本和异常 ID 的“富”异常。
- 实现 `IMTPlugin` 接口。创建 ATL 对象后,转到“类视图”选项卡,右键单击对象类。然后,选择“实现接口”。接下来,单击“添加类型库”并浏览 MTPluginIDL 项目的“MTPluginIDL.tlb”文件。
实现插件
插件接口是一个简单的工厂。您必须做的唯一事情是创建对象并返回它们。您通过实现 `MTFunctionI` 和 `MTOperatorI` 接口以标准方式创建函数和运算符。
您可能想查看日期插件的实现以获取更多详细信息。使用此设计时,唯一需要更改的代码是填充常量、运算符和函数数组的初始化代码。此代码看起来像:
void CMTDatePlugin::initPlugin()
{
// constants...
addConst(_T("cname1", cval1);
addConst(_T("cname2", cval2);
…
// operators...
m_ops.push_back(new myOp1());
m_ops.push_back(new myOp2());
…
// functions...
m_funcs.push_back( new MyFct1() );
m_funcs.push_back( new MyFct2() );
…
}
插件代码的其余部分只是将调用委托给正确的运算符和函数。
注册插件
在使用插件(和任何 COM 对象)之前,您必须在 Windows 系统中注册它。有一个名为“regsvr32.exe”的小系统实用程序可以为您完成此操作。只需在命令提示符下使用以下语法运行它:“regsvr32 myPluginFile.dll”。
如果您想以编程方式注册 COM 对象,请使用以下 C++ 代码:
BOOL RegisterCOM(const std::wstring &filename){
HINSTANCE hLib = LoadLibrary(filename.c_str());
HRESULT (*lpDllEntryPoint)();
if (hLib < (HINSTANCE)HINSTANCE_ERROR)
{
return 0;
}
BOOL Success = 1;
lpDllEntryPoint = (HRESULT (*)())GetProcAddress(hLib,
"DllRegisterServer");
if (lpDllEntryPoint != NULL)
{
HRESULT hr;
hr = (*lpDllEntryPoint)();
if (FAILED(hr))
{
Success = 0;
}
}
else
{
Success = 0;
}
FreeLibrary(hLib);
return Success;
}
主要思想是调用所有 COM 对象都具有的 `DllRegisterServer` 函数。此函数将执行所有剩余的注册操作,例如向 Windows 注册表添加键。
需要分发的文件
根据您使用的功能,并非所有文件都是必需的。以下是文件列表以及何时需要将它们分发给您的应用程序的说明:
- `MTParserCOM.dll`:使用 COM 库版本时需要。
- `_MTParserPlugin.tlb`:使用插件时需要。这是定义插件接口的类型库文件。
- `MTDatePlugin.dll` 和 `MTDatePlugin.xml`:使用日期和时间函数时需要。
- `MTNumAlgoPlugin.dll` 和 `MTNumAlgoPlugin.xml`:使用数值算法函数(solve、derivate…)时需要。
- `MTParserGen.xml`:使用本地化解析器时需要。它包含不同语言的异常、函数和运算符的文本。
- `MTParserInfoFile.dll`:使用本地化功能时需要。此组件读取 XML 信息文件。
因此,如果您使用不带任何额外功能的 C++ 库版本,则无需分发任何文件,因为解析器已静态链接到您的应用程序。
部署 COM 对象时,必须分发 Visual Studio 运行时 DLL 文件。这些文件会根据您是否使用 Unicode 和您的 Visual Studio 版本而有所不同。例如,使用 Unicode 和 Visual Studio .NET 2003 编译时,您需要分发:`MFC71U.dll`、`MSVCP71.dll` 和 `MSVCR71.dll`。
像 Dependency Walker 这样的工具可能有助于您确定所需的 DLL 并排除有问题的安装。
演示应用程序

有四种代码示例:
- 使用 C++ 解析器库的 C++ 客户端。主要演示应用程序,具有本地化的用户界面(英语和法语)。
- 使用 COM 解析器库的 C++ 客户端。
- 使用 COM 解析器库的 VB 客户端。
- 使用 COM 解析器库的 C# 客户端。
所有示例都是等效的,并且演示了相同的功能。您可以在名为 `Code samples` 的目录中找到它们,该目录位于 `MTParser_src` 主目录下的。在 `C++ library` 子目录中,您会找到一个使用静态 MTParser C++ 库的 C++ 应用程序。在 `COM library` 子目录中,您会找到三个使用 MTParser COM 库的代码示例:一个 C++,一个 Visual Basic 6,还有一个 C#。
其他数学解析器
市面上有许多优秀的数学解析器。下表列出了八个数学解析器及其规格。当您想评估其他符合您配置需求的解析器时,此表可能会很有用。
| CioinaEval | EffOBJ | JFormula | JbcParser | JEP | MTParser | muParser | Ucalc | USPExpress | |
| 原生语言 | Delphi | C++ | Java | Java | Java | C++ | C++ | C++ | C++ |
| 分发格式 | DLL, So | DLL | JAR | JAR | JAR | .lib, COM | .lib, DLL | DLL | COM |
| 面向对象 | N | N | Y | Y | Y | Y | Y | N | Y |
| 跨平台 | Y | N | Y | Y | Y | N | Y | N | Y |
| 商业许可 | $ | $ | $ | $ | $ | 询问 | 询问 | $ | $ |
| 个人许可 | $ | $ | $ | $ | GPL/$ | 免费 | 免费 | $ | $ |
| 源代码 | $ | N/A | $ | $ | GPL/$ | 免费 | 免费 | N/A | N/A |
结论
我非常感谢您的评论,我将根据您的反馈继续定期改进此库。我添加功能的指导原则是:保持库足够通用,以便对尽可能多的人有用,并遵循“保持简单,愚蠢”(Keep It Simple Stupid)。不要犹豫给我建议并批评我的工作。只要您提出一些解决方案,我们都欢迎。
参考文献
- Grune, Dick. (1990). Parsing Techniques – A Practical Guide. Vrije Universiy, Amsterdam. 完整的免费在线编译器书籍。涵盖了各种算法。
- GSL: GNU Scientific Library. C 语言中一套非常完整且免费的数值算法集合。可以开发包装器将这些算法与 MTParser 集成。
- Niemann, Thomas. (2000). Operator-Precedence Parsing. ePaper Press。一篇简短而精炼的文章,解释了运算符优先级解析算法。这是此组件用于解析数学表达式的基本算法。
- Norvell, Theodore. (2001). Parsing Expressions by Recursive Descent. 一篇很好的文章,解释了移位-约简算法。这只是另一种命名运算符优先级算法的方式。
- Press, William H. (1992). Numerical Recipes in C: The Art of Scientific Computing. Cambridge University Press. 关于数值方法的经典书籍。在线版本可免费获取,应能为您提供一些插件思路……!
- Wikipedia. Reverse Polish Notation。对逆波兰表示法的非常易于理解的定义和示例。这种表示法用于以一种更容易被计算机处理的方式表示数学表达式。
历史
现在项目已经成熟,有一些有趣的指标可以展示。
下图显示了自第一个版本以来代码行数(LOC)的演变。LOC 的总数包括空行、注释行和可执行行。C++ 可执行行以分号(;)结尾。
当前版本大小(LOC)
- 总计:24896
- 可执行:6382
- 注释:3222

好奇我在这上面花了多少时间?下图告诉我们,我一半以上的时间都在打磨现有东西。

- 2008年3月10日
- 增强(感谢 Rohallah Tavakoli):修正了 throw 子句以方便移植。
- 增强:函数、常量、运算符和变量名可以包含小数点字符。由于此字符不用于分割公式部分,因此可以在标记名中使用。
- 新功能:用于批量求值的 VB6 方法。VB6 需要不同于 .net 的方法签名才能使用 safearray。
- 新功能:用户自定义函数!只需在您的 .net 应用程序中实现 IMTFunction 接口!
- 功能已移除:变量名分隔符。无用的功能,允许了奇怪的语法。最好避免变量名包含特殊字符,因为它会混淆用户。
- Bug 修复(感谢 Romy):非运算符现在具有一元运算符优先级。添加了测试用例。
- Bug 修复:在 redefineVar 中返回内部变量的副本,使用 spawn 方法,因为注册表拥有它们。
- 2006年9月20日
- 增强(感谢 udvranto):已准备好支持 VS.NET 2005。
- 增强(感谢 Jamie Riell):运算符优先级已重新审视。现在使用 C++ 运算符优先级值。
- 增强(感谢 ABuenger):现在可以在没有插件和本地化功能的情况下编译。
- 新功能(感谢 Bidoy):添加了一元加法运算符。语法如 +2 现在是有效的。
- 新功能(感谢 Eldon Zacek 和 bastet69):可以取消定义常量、函数和运算符。
- 新功能(感谢 claude_kouakou):可以枚举已定义的变量。添加了 getNbDefinedVars 和 getVar 方法。
- 功能已移除(感谢 iberg):不再检查内存不足异常。由应用程序负责处理系统异常。历史上,当 `
new` 运算符返回 `null` 而不是抛出异常时,此功能是必需的。 - Bug 修复:“2,2”之类的表达式导致解析器崩溃。已修复 Compiler 方法 `getCurItemType`。
- Bug 修复(感谢 tux512):`log10` 函数现在使用 log10 数学函数而不是 log 函数!
- Bug 修复(感谢 tux512):“1+()”之类的表达式导致解析器崩溃。现在 `()` 语法无效。已添加测试用例。
- 2005年9月20日
- 重构:数值算法已移入插件。这些是专用函数。
- 重构:变量键已移除。这是一个不必要的优化,而且有些丑陋。现在只使用变量名。
- 重构:异常框架已重构。异常标识符现在是字符串而不是数字,并且是运行时可配置的异常数据。这允许在没有冲突的情况下添加新异常。因此,插件可以定义自己的异常并在其 XML 文件中放入本地化文本。
- 增强 - 健壮性:现在可以捕获内存不足的情况。当内存不足时,会抛出异常。
- 新功能:异常消息格式化器,允许格式化参数化消息。
- 增强 - 性能:在注册表中:运算符的哈希表,函数的多重映射,常量的映射。现在,搜索函数非常高效。最终结果是更好的编译时间。
- 新功能:现在可以搜索所有插件并自动加载它们。`loadAllPlugins` 接受一个搜索模式来定位所有信息文件并提取 CLSID 字符串。
- 新功能:批量求值。允许在同一次调用中多次求值表达式,并在每次求值时自动提取变量值。
- 新功能:本地化器对象,允许本地化项信息。XML 文件用于存储本地化信息。使用 `MTParserLocalizer` 对象获取已定义项的本地化信息。使用 COM 对象解析 XML 文件并使用 .NET 框架 XML 函数。
- 新功能:重新定义变量。这简化了自动变量定义功能的使用,因为不再需要变量工厂。您可以编译表达式并使用正确的变量类型重新定义自动定义的变量。
- 新功能:C# 演示应用程序。感谢 Derek Price。
- 2005年6月20日
- 重构:`getSymbol` 方法现在位于 `MTExprItemEvaluatorI` 接口中。以前,具体类(函数、运算符和变量)的符号格式存在差异,但现在所有格式都相同。
- 增强 - 内存(感谢 Eamonn McGrath):宏现在使用更少的内存。使用延迟初始化技术,宏仅在表达式中实际使用时才创建。`MTFunctionI` 接口中添加了新方法以允许延迟初始化,并在函数未使用时避免资源浪费。
- 增强 - 错误:转换函数不再允许缺少闭合括号。
- 增强 - 验证:现在在调用 `getFunc`、`getOp` 和 `getConst` 方法时会验证函数、运算符和常量 ID。当 ID 超出范围时,会抛出错误而不是完全终止应用程序。
- 增强 - 性能:VS.NET 编译器提供了 15% 的速度提升。
- 新功能:添加了新函数“
isFinite”,以允许处理诸如除以零之类的求值错误。 - 新功能(受 Eamonn McGrath 启发):宏的参数现在可以排序,并且不必遵循宏函数出现的顺序。现在您提供宏原型,例如:macro(arg1, arg2, arg3...) 而不是仅提供其名称。
- Bug 修复:递归函数(如 `trapezoid(2*x,x,trapezoid(2*x,x,0,5),0, 0.001)`)的问题。现在参数按值传递而不是按引用传递。
- Bug 修复(感谢 Martin Gamperl):使用自动变量定义功能时,与起始-结束变量分隔符一起出现的问题。变量编译器状态未遵循已启用的自动变量功能状态。已添加测试用例。
- Bug 修复(感谢 Visual Studio .NET!):存在一个关于 void 表达式的问题(再次)。程序尝试读取无效内存空间。
- 2005年4月23日
- 重构:插件设计现在遵循抽象工厂模式。开发插件现在更容易了。
- 重构:两个异常类型 `MTDefException` 和 `MTParsingException` 已合并为 `MTParserException`。两种异常类型是不合理的。`MTException` 仍然存在。
- 增强 - 性能:插件项现在与原生 C++ 项一样快。插件不再通过调用 COM 方法来评估项,而是直接返回插件实例并使用。
- 增强 - 异常:与插件相关的两个新异常:
e_MTDefExcep_PluginVersion和e_MTDefExcep_PluginNotFound。e_MTDefExcep_ConvFuncSyntax异常已被更通用的e_MTParsingExcep_InvalidFuncSyntax取代。 - 增强 - 编译器性能:编译步骤现在更快。主要问题是使用了字符串而不是简单的字符指针。
- 新功能:函数可以拥有自己的编译器。这允许定义一系列广泛的新函数,使用特殊的语法。转换函数不再是特殊实体,现在拥有一个特殊的编译器。这种泛化简化了代码,并为各种新函数打开了大门。
- 新功能:数值近似函数。导数、积分和求解函数已使用新的自定义编译器功能实现。这些函数展示了可以完成的工作,并用于演示目的。
- 错误修复:内存泄漏。感谢 CodeProject 的 Dan Moulding 的 Visual Leak Detector!
- 错误修复(感谢 mgampi!):表达式 "(2,2)" 的问题。现在验证是否在函数内部使用了参数分隔符。
有关完整历史记录,请参阅库源文件。