
语义数据库:概念、架构与实现
4.99/5 (38投票s)
没有一个词的含义可以独立于它周围的其他词语而被识别。
语义数据库
概念
架构
实现

引言
本文将在几个部分讨论语义数据库的概念
- 讨论语义数据库的概念和必要性
- 架构影响
- 在关系型数据库管理系统 (RDBMS) 之上实现
- 单元测试以验证基本的插入和查询操作(更新和删除留待以后进行)
第二部分将在Higher Order Programming Environment中演示语义数据库的实际应用,并带有一个有用的应用程序。如果您不熟悉HOPE,此页面将引导您阅读Code Project上的其他文章。因为我将语义数据库设计为一个持久化组件,所以您会注意到单元测试正在与“载体”(用于在“接收器”——独立组件——之间发送消息的载体)进行交互。此外,因为我讨论的是语义数据库,所以我正在利用HOPE中管理语义结构的类,包括语义结构实例的动态运行时编译和实例化。因此,这里使用了大量的先前工作作为脚手架,但我认为这不会妨碍对概念和代码的理解。
正如许多读者现在已经习惯的那样,这绝对会是一次“狂野之旅”。概念、架构和实现将有望挑战您对数据是什么以及由此推断出的语义数据库是什么的固有观念。
希望读者也能原谅对非技术性语义讨论的深入探讨,因为它对于传达必要的基础信息至关重要。
最后,即使您不特别对语义数据库架构感兴趣,用于生成SQL查询语句的代码在任何需要根据模式信息自动连接多个表而无需手动编写复杂连接或依赖ORM的应用程序中都很有用。
代码在哪里?
一如既往,代码可以从GitHub克隆或fork。在第二部分中,我将有一个专门针对与该文章配套的代码的分支。
什么是语义学?
语义学是信息科学中一个新兴的研究和发展领域,然而,这个概念在计算机出现之前就已经存在很长时间了!首先,语义学是语言学和逻辑学中关注意义的分支。这可以分为三个主要类别:
- 形式语义学
- 意义的逻辑方面
- 词义
- 参考
- 蕴含
- 逻辑形式
- 意义的逻辑方面
- 词汇语义学
- 词语意义
- 词语关系
- 概念语义学
- 意义的认知结构
或者,更具体地说:
- 语义学是意义的研究
- 它关注之间的关系
- 指符:词语、短语、符号和标志
-
指示:它们代表什么
![]()
“没有一个词的含义可以独立于它周围的其他词语而被识别。”
-- (de Saussure, Ferdinand, 1916, 《普通语言学教程》)
什么是语义数据库的典型概念?
首先,“语义数据库”一词通常与“语义数据模型¹”这个短语一起使用。当你看到“语义数据”这个短语时,这通常意味着与语义网²、网络本体语言(OWL)³和资源描述框架(RDF)⁴有关。
语义网
“语义网是信息的愿景,信息可以被机器轻易地解释,从而机器可以承担更多在查找、组合和处理网络信息方面繁重的工作。正如最初设想的那样,语义网是一个系统,它使机器能够根据其含义‘理解’并响应复杂的人类请求。这种‘理解’要求相关信息源在语义上是结构化的。”²
OWL和RDF
不幸的是,这个词组最初的概念和短语,由Tim Berners-Lee(万维网的发明者)提出,已经被OWL和RDF在一定程度上“劫持”了。OWL和RDF主要关注“三元组”——主语-谓语-宾语表达式,其中“[主语]指示资源,谓语指示资源的特征或方面,并表达主语和宾语之间的关系。”⁴。这可以追溯到20世纪60年代,“Richard Montague提出了一种使用lambda演算定义词汇表中语义条目的系统。在这种术语中,句子“John ate every bagel”的句法解析将包括一个主语(John)和一个谓语(ate every bagel);Montague证明了整个句子的意义可以分解为其各个部分的意义以及相对较少的组合规则。”⁸
然而,这与纯粹的语义概念,特别是关于关系和结构的语义概念,非常不符。虽然主语-谓语-宾语表达式定义了主语和宾语之间的关系,但它丝毫没有定义主语之间以及宾语之间的关系。此外,S-P-O也未能表达宾语或主语的组合或结构,而从语义学角度来看,这至关重要。
显然,只需稍加思考,就可以创建一个主语-谓语-宾语三元组数据库。然后,甚至可以通过谓语(即关系类型)来查询数据库,询问主语与领域内所有宾语(或宾语及其主语)的关系。问题是,这种方法会让人们面临语义网的挑战:“广阔性、模糊性、不确定性、不一致性和欺骗性。”² 为什么?因为三元组实际上并没有提供太多机器可用的意义,因此容易出现上述问题。讽刺的是,虽然三元组包含主语和宾语之间的关系,但它并没有说明主语或宾语(甚至谓语,它也可能具有自己的结构)的结构。例如,考虑不确定性问题
“…意义不完整,缺少一些上下文元素。以单词‘red’为例,它在短语‘red book’中的含义与其他许多用法相似,可以看作是组合的。[6]然而,短语‘red wine’(深红色)、‘red hair’(铜红色)或‘red soil’(红土)、‘red skin’(红皮肤)中暗示的颜色却非常不同。事实上,这些颜色本身母语者可能不会称之为‘red’。这些实例是对比性的,所以‘red wine’之所以如此称呼,仅仅是因为与其他类型的葡萄酒相比(后者也是因为相同的原因,也不是白色的)。”⁶
如果完整的结构与数据(“red”)一起持久化

并且在查询“红色事物”时检索该结构,那么它的含义就不会含糊不清。
![]() 我们注意到父元素是没有值的——它们只是引用子元素“Color”的占位符。
我们注意到父元素是没有值的——它们只是引用子元素“Color”的占位符。
什么是“正确”的语义数据库概念?
就像爱丽丝梦游仙境一样,我们需要深入几个兔子洞来弄清楚这个问题。
![]()
“许多网站是由结构化数据生成的,而这些数据通常存储在数据库中。当这些数据被格式化为HTML时,恢复原始结构化数据变得非常困难。许多应用程序,尤其是搜索引擎,将从直接访问这些结构化数据中受益匪浅。”⁵
换句话说,通过暴露数据的语义,机器就可以比仅仅存储或显示数据更有趣地利用这些信息。一个经典的例子是包含电话号码的网站。如果电话号码带有语义标签,那么您的智能手机就可以轻松地将其提供为可拨打的号码。这与应用程序必须经历的繁琐过程形成对比,后者需要扫描页面并查找与各种电话号码表示样式匹配的文本,验证它实际上是一个数字而不是看起来像“619-555-1212”之类的数学表达式,等等。
结构化数据
在上面的引用中,您会注意到“恢复原始结构化数据”这句话。这暗示数据具有结构——它不仅仅是一个字段,而是字段有意义并且可以有子结构——换句话说,结构化数据是一个树。
这里有几个例子


接下来,我们需要理解“本体”的概念,这个词经常出现在关于语义的讨论中。
本体
![]()
“本体是对概念化的明确规范。”
-- Gruber, Tom (1993); “A Translation Approach to Portable Ontology Specifications”, in Knowledge Acquisition, 5: 199-199
前面我指出S-P-O三元组没有定义之间主语和之间宾语的关系。这正是本体发挥作用的地方。虽然在抽象意义上,“本体”的意思是“处理存在性质的形而上学分支”,但在信息科学中,“本体被定义为共享概念化的形式化、显式规范。它提供了一个通用的词汇表来表示领域中概念的类型、属性和相互关系。”⁹ 而且请注意:“本体是组织信息的结构化框架,并用于…语义网…”
语义学有助于理解“事物”的结构,但我们需要本体来将事物与其他事物联系起来。因此,人们可以预期语义数据库应该是关系型的——它应该能够将结构化数据关联到本体中。
这是Friend of a Friend¹⁰本体的一个实例示例(来自W3C SKOS Core Guide¹¹)

SKOS Core词汇表定义了语义关系的两个属性
- 两个结构之间的关系定义了一个相对于另一个是“更广泛”或“更狭窄”
- 一种关联关系,其中两个结构是“相关的”
在语义网和RDF Schema (RDFS)¹²的世界中,RDFS被用来描述本体“…也称为RDF词汇表,用于组织RDF资源。这些资源可以保存在三元组存储中,以便用SPARQL查询语言访问它们。”¹² 例如:“一个典型的rdfs:Class例子是FOAF词汇表中的foaf:Person。foaf:Person的一个实例是一个资源,它使用rdf:type属性链接到foaf:Person类,例如在下面的自然语言句子“John is a Person”的正式表达中。”¹²
![]()
我们看到两个概念正在出现
- 数据结构之间的关系本身就是一种分层结构
- 语义结构可以与其他结构关联以创建本体
这有助于我们理解语义数据库应该提供什么。
语义数据库
在语义数据库中(回到语义学的非常早期的定义),模式
- 描述指示
- 描述指示之间的关系
因此,数据库的工作就是将指符(值)与这些指示关联起来。因此:
- 结构解析为具体的属性,可以为其关联实例值
![]()
重要的是,结构与每个实例一起实例化。这允许结构与值一起检索。我们稍后会看到这意味着什么(以及为什么我将要实现的东西看起来如此有争议)。
为什么不使用关系型数据库?
在本文的实现部分,我将大量处理RSS Feed,所以让我们来看看在RDBMS中持久化RSS Feed及其条目的典型实现。首先,模式可能看起来是这样的:
|
|

(此处RSS_UI旨在持久化某个Feed项是否先前在列表中显示过,或者它是否是一个新Feed,以及用户是否实际访问了与Feed项关联的URL。)
请注意字段名称是如何成为高级抽象的。给定字段名称,人们无从得知“Title”是指RSS Feed的标题、书的标题还是赋予个人的头衔。添加“RSS_Feed_”到字段名称是繁琐且不传统的。此外,当我们执行“select * from RSS_Feed_Item”查询时,我们得到的是一行行数据,顺序与模式中字段的描述顺序相同。然而,这些仅仅是值——我们太常忘记返回的数据实际上没有语义含义,是UI为列标记了标签,我们才得以知道数据的含义。
![]()
更重要的是,在RDBMS中,关系是由以下因素驱动的:
- 基数
- 规范化规则
- 字段的“逻辑”分组
当我们创建模式时,这个过程可以如此自动化,以至于我们几乎没有意识到我们正在这样做。结果是那些不具有语义性而是被抽象化、不自然的结构化关系,(理想情况下)被限制在已建立的外键声明中。
然而,正如我们将看到的,我们可以在RDBMS之上实现语义数据库。
为什么不使用NoSQL数据库?
NoSQL数据库是面向文档的,它们不支持文档之间的关系,以至于用户可以构建一个由数据库引擎处理的连接查询。相反,在NoSQL数据库中,连接由客户端解决,这可能需要多次往返数据库才能获取所有信息,然后将其构建成一个连贯的结构。这使得NoSQL数据库完全不适合当前的任务。
为什么不使用图数据库?
图数据库似乎是一个可能的选择,并且将进一步进行研究。如果我们阅读Neo4j的介绍
来自Neo4j网站
“…图只是顶点和边的集合——或者,用不太令人望而生畏的语言来说,是一组节点以及连接它们的边的集合。图将实体表示为节点,并将这些实体与世界相关联的方式表示为边。” - Robinson, Ian, & Webber, Jim, & Eifrem, Emil (2013). Graph Databases. O'Reilly, pg 1 (免费下载此处。)
重要的是,关于传统的数据库,
“…关系数据库最初被设计用来编码纸质表格和表格结构——它们在这方面做得非常出色——但在尝试建模现实世界中出现的临时、异常关系时会遇到困难。讽刺的是,关系数据库在处理关系方面表现不佳。关系确实存在于关系数据库的语言中,但只是作为连接表的手段。在我们上一章关于连接数据的讨论中,我们提到我们经常需要消除连接实体的关系的语义歧义,以及限定其权重或强度。关系关系不做任何此类事情。” - (同上,pg 11)
并且
“与其他数据库管理系统不同,关系数据库需要我们使用诸如外键之类的 것입니다,或者进行诸如map-reduce之类的带外处理来推断实体之间的连接。通过将节点和边的简单抽象组合成连接的结构,图数据库使我们能够构建任意复杂的模型,这些模型与我们的问题域紧密映射。由此产生的模型比使用传统关系数据库和其他NOSQL存储产生的模型更简单,同时更具表现力。” - (同上,pg 6)
然而,看起来典型的图数据库侧重于信息的本体——它没有实际定义节点属性的结构的概念。这是“事实”概念的结果:“当两个或多个领域实体在一段时间内交互时,就会出现一个事实。我们将这些事实表示为单独的节点,并连接到参与该事实的每个实体。” - (同上,pg 66)
我们可以在创建图数据库的示例中看到这一点。来自pg 41

我们有“事实”节点
- William Shakespeare
- The Tempest
- Juilias Ceasar
这些信息缺乏语义上下文,例如表明“William Shakespeare”是一位剧作家,或者“The Tempest”是一部戏剧。有趣的是,这些语义信息在Cypher¹⁴查询片段bard=node:author(lastname='Shakespeare')中变成了任意标签。从查询中我们可以确定William Shakespeare是一位诗人,但是,这些信息在图数据库中完全丢失了!
换句话说,如果我们遵循“事实”的最佳实践,那么通过指定语义上下文就无法查询图数据库。我不能问图数据库“显示所有是诗人的名字”,除非我显式创建一个名为“bard”的节点,并与William Shakespeare建立关系。这个问题部分源于图数据库代表了一个特定的领域:“通过将节点和边的简单抽象组合成连接的结构,图数据库使我们能够构建任意复杂的模型,这些模型与我们的问题域紧密映射。” - (同上,pg 6)。最多,我们可以说一个具有“firstname”和“lastname”属性的节点代表一个“person”,但我们无法说出关于这个人的其他任何信息,例如区分这个人与剧作家、制片人或演员,除了通过与另一个具体节点的关系,其中关系提供了进一步的语义意义,例如“wrote_play”或“produced_play”或“acted_in”。
因此,关于语义结构,图数据库虽然是创建具体实体本体的优秀工具,但并不适用于具有语义意义但没有值的抽象结构元素(这些元素必须表示为没有属性的节点),图数据库也不能正确地语义化属性值,除了作为“字段名”,与传统数据库一样,语义信息不能作为数据的一部分被访问。
尽管如此,图数据库的文献中有许多有价值的指导,在设计语义数据库时很有用,那就是:
![]()
组成本体的语义结构之间的连接具有相关意义。
语义数据库架构
在上述讨论中,我们得出几个重要观察:
- 本体强调实体之间的关系,而不是定义实体结构。
- 语义学强调结构,但不强调结构之间的关系(本体)。
此外,关于当前的数据库选项:
- 图数据库通常捕获事实的本体,而不是语义和它们的结构。
- 关系型数据库捕获“逻辑”关系,而不是“自然”语义结构和本体。
- NoSQL数据库要求客户端提供支持关系的实现,NoSQL唯一支持的是非常有限的“文档ID”脚手架。
对于语义数据库,需要的是:
- 能够从语义学创建本体
- 能够定义语义元素的自然结构
使用我们的RSS_Feed_Item示例,我们可以组合一个“RSS_Feed_Item”概念的自然结构模型:
- RSS_Feed_Item
- RSS_Feed_Name
- 名称
- 文本
- Value : text
- 文本
- 名称
- RSS_Feed_Title
- 标题
- 文本
- Value : text
- 文本
- 标题
- RSS_Feed_Description
- 描述
- 文本
- Value : text
- 文本
- 描述
- RSS_Feed_PubDate
- Publication_Date
- 日期
- Value : date
- 日期
- Publication_Date
- RSS_Feed_Url
- URL
- Text (参见下文注释)
- Value : text
- Text (参见下文注释)
- URL
- RSS_Feed_Name
(当然,也可以争辩说“URL”应该细分为方案名称、域名和资源路径,但目前我们保持简单。)
![]()
这个结构需要注意的第一点是,查询可以在结构的任何级别进行,并且语义损失程度不同。例如,“select URL from RSS_Feed_Url”这个查询有一些上下文损失,因为我们仍然知道这些值与URL结构相关,但URL不再被标识为RSS Feed URL。像“select Value from URL”这样的查询则完全丢失了上下文——我们只得到一堆字符串。顺便说一下,这相当于在RDBMS中查询“select URL from RSS_Feed_Item”。在我提出的语义数据库实现中,“select Value from URL”这个查询实际上是不可能的,因为Value是一个原生类型,而不是语义类型。
使用RDBMS托管语义数据库
然而,语义数据库可以构建在RDBMS之上。我们可以利用RDBMS的有用功能:
-
外键约束
-
服务器端连接
-
唯一键约束
-
唯一键索引
当由RDBMS托管时,我们看到以下工件:
-
表代表结构
-
外键描述子结构
-
连接用于连接结构
-
在左连接中,所有为null的原生类型对于语义类型具有特定含义,即不存在结构实例。
-
主键几乎完全被限定在通过外键解决连接的角色上。
-
在对原生类型执行插入、更新和删除事务时,对唯一键(单个字段或复合键)的重视程度要高得多。
![]()
与RDBMS不同,RDBMS的关系是由基数、规范化和字段的逻辑结构驱动的,而在语义数据库中,关系由语义结构本身驱动。这本身就允许语义数据库更能适应封装新意义的新结构。
展开语义数据库结构
使用RSS Feed示例,数据库表中展开的结构将如下所示:

请注意,只有两张表包含实际值(Text和URL)。其他所有内容都是“底层”——它们只存在于其结构相关性中,并且只包含指向下一层通用概念的外键。虽然大多数结构与其泛化都有1:1的关系,但我们看到RSS_Feed_Item是四个不同结构的组合(这是它的特定本体)。
![]()
用面向对象的术语来说,我们可以清楚地看到“is a kind of”(是一种)和“has a”(拥有一个)关系,但是,应该注意的是,语义数据库绝不是OODBMS的实现,原因同样是——对象往往是逻辑构建块,为了程序员的方便而不是自然的语义构建块。然而,语义结构非常自然地契合OO范式。
折叠语义数据库结构
典型的结构然而更清晰地显示为一棵树
在RDBMS中的实现
这就是RDBMS中的模式(也是我真正开始收到“你疯了”的眼神的地方):

![]() 两个问题非常突出:
两个问题非常突出:
 |
“最深层”的语义类型几乎总是仅由外键组成。 |
 |
具有原生类型的表非常“精简”,只有很少的字段。 |
![]()
这个实现有趣之处在于,我们可以问一些可能有用的问题:
-
数据库中有哪些URL?
-
我们访问过的URL有哪些?
-
哪些URL与Feed相关?
-
所有“Title”的值有哪些?
-
所有Feed名称有哪些?
这些并不是我们一定能从RDBMS问出的问题,尤其是当一个更通用的概念如“URL”嵌入在多个表(RSS Feed URL、浏览器书签URL、文档嵌入URL等)的字段中时。即使是设计良好的数据库也有其局限性。
此外,由于更通用的语义类型与上下文类型的连接方式,我们可以问:
- 哪些Feed项是我访问过的?
- 哪些Feed项是书签?(我在图表中没有显示书签语义类型)
更重要的是(举例来说),当我们在浏览器中访问一个页面时,我们可以使用相同的更通用的URL类型和一个专门的“浏览器访问”类型,从而可以具体地询问:
- 我访问过的所有Feed项是什么?
- 我直接在浏览器中访问过的所有网页是什么?
- 我访问过的所有URL总数是多少?
希望这能展示语义数据库如何适应新结构,这些新结构又会创建新的上下文,然后可以用新的方式进行查询。
语义数据库的一些好处
- 通过保留语义结构,我们可以从非常具体到非常一般的不同语义含义级别查询数据库。
- 例如,语义类型“Title”非常通用,但它允许我们问“具有‘Title’含义的所有事物的值是什么?”
- 通过检查关系,我们可以问“具有‘Title’作为其含义的事物是什么?”
- 当我们查询数据库时,我们不仅仅得到一个记录列表——我们得到完全“重构”的语义类型。
- 在实际实现中,消除了对ORM层的需求
- 我们传入作为实际C#对象的语义结构
- 我们取回作为实际C#对象的语义结构
语义数据库的一些缺点
- 表及其字段按层次结构而非逻辑结构组织
- 我们通常习惯于将信息组织成逻辑关联和关系
- 层次结构组织创建了更多的表
- 查询中的连接数量会降低性能。
- 需要多次插入操作来创建语义类型的层次结构。
- 设计层次结构并非易事
- 我们需要学习如何思考多个抽象级别。
- 我们需要仔细考虑唯一原生类型和唯一语义类型。
- 手动编写SQL查询很痛苦
- 大量的连接,通常需要多次引用原生类型表,使得很难跟踪哪个FK连接与什么含义值相关联。
- 手动编写插入语句更痛苦
- 需要从下往上多次插入,需要子表的ID来填充父表的外键。
解决一些缺点
语义数据库引擎可以解决其中一些缺点:
- 自动生成SQL查询
- 隐藏了层次结构和表连接
- 自动生成SQL插入
- 管理所有必要的外键ID
- 提高性能
- 缓存查询,这样引擎就不必每次都重新创建SQL语句。
- 使用预编译语句,这样服务器每次使用查询语句时就不必解析和分析它。
原型设计与实现
语义数据库自然地处理语义结构。由于我已经在Higher Order Programming Environment (HOPE)项目中实现了大部分基础设施(最新文章列表可以在此处找到),我将利用该代码库。
![]()
强烈建议回顾入门文章,以帮助理解以下代码。在接下来的实际演示中,我将利用语义编辑器和各种“接收器”组件,语义数据库作为其中一个接收器实现。
单元测试
单元测试对于验证用户期望信任我们正确持久化和检索数据的行为至关重要(这也是我将其构建在RDBMS之上而不是编写一个全新的语义数据库实现的原因之一)。单元测试也是介绍语义数据库概念和实现的良好方式。
您会注意到单元测试结构基本上是这样的:
- 为每次测试清理数据库——这包括删除表
- 创建语义结构及其配置,以测试所需行为
- 将这些结构注册到语义数据库——这会创建后端表
- 执行所需的事务
- 验证结果。
在使用任何RDBMS时,以及就语义数据库而言,一个重要的考虑因素是唯一键的概念,无论是单个字段还是复合字段。然而,语义数据库还实现了唯一键“类型”的概念,其中类型是语义元素。这会产生一些有趣的需要测试的行为,而测试将有助于记录如何使用唯一键字段/类型配置。
数据库配置
如果您使用SQLite数据库运行测试,则无需任何配置——数据库文件会自动创建,并且没有权限问题。语义数据库也支持Postgres,这需要:
- 在“HOPE\UnitTests\SemanticDatabaseTests\bin\Debug”文件夹中放置一个“postgres.config”文件。该文件应包含两行:
- 用户名
- 密码
- 您还需要手动创建一个名为“test_semantic_database”的空数据库(无表)。
从语义结构创建表
这段代码
InitializeSDRTests(() => InitLatLonNonUnique()); sdr.Protocols = "LatLon"; sdr.ProtocolsUpdated();
初始化语义数据库接收器并定义“LatLon”的语义结构。当调用ProtocolsUpdated时,语义数据库将创建名为“LatLon”的表,包含两个字段:“latitude”和“longitude”。当遇到新的语义类型时,表会自动创建。在这种特定情况下,语义结构实例化如下:
protected void InitLatLonNonUnique()
{
SemanticTypeStruct sts = Helpers.CreateSemanticType("LatLon", false, decls, structs);
Helpers.CreateNativeType(sts, "latitude", "double", false);
Helpers.CreateNativeType(sts, "longitude", "double", false);
}
为了我们的目的,我们不会担心decls或structs是什么,如果您想知道,可以详细检查代码。关键在于,创建了一个名为“LatLon”的结构,其中包含两个原生类型,都是double类型,名为“latitude”和“longitude”。结构和原生类型均未定义为唯一。
![]() 尽管看起来奇怪,使用字符串作为类型名称——而不是,例如,
尽管看起来奇怪,使用字符串作为类型名称——而不是,例如,typeof(double)——是因为我们实际上是在模拟通常在语义编辑器中所做的事情,语义编辑器是一个用户界面组件,主要处理事物的名称字符串。
![]() 从语义结构创建表的数据库实现是:
从语义结构创建表的数据库实现是:
/// <summary>
/// Create the table for the specified semantic structure, adding any SQL statements for making foreign key associations.
/// </summary>
protected void CreateTable(string st, List<string> fkSql)
{
// Fields and their types:
List<Tuple<string, Type>> fieldTypes = new List<Tuple<string, Type>>();
// Get the structure object backing the structure name.
ISemanticTypeStruct sts = rsys.SemanticTypeSystem.GetSemanticTypeStruct(st);
CreateFkSql(sts, fieldTypes, fkSql);
CreateNativeTypes(sts, fieldTypes);
dbio.CreateTable(this, st, fieldTypes);
}
/// <summary>
/// Any reference to a child semantic element is implemented as a foreign key.
/// Returns any foreign key creation sql statements in fkSql.
/// </summary>
protected void CreateFkSql(ISemanticTypeStruct sts, List<Tuple<string, Type>> fieldTypes, List<string> fkSql)
{
// Create FK's for child SE's.
sts.SemanticElements.ForEach(child =>
{
string fkFieldName = "FK_" + child.Name + "ID";
fieldTypes.Add(new Tuple<string, Type>(fkFieldName, typeof(long)));
fkSql.Add(dbio.GetForeignKeySql(sts.DeclTypeName, fkFieldName, child.Name, "ID"));
});
}
/// <summary>
/// The supported native types are simple field name - Type tuples.
/// </summary>
protected void CreateNativeTypes(ISemanticTypeStruct sts, List<Tuple<string, Type>> fieldTypes)
{
// Create fields for NT's.
sts.NativeTypes.ForEach(child =>
{
Type t = child.GetImplementingType(rsys.SemanticTypeSystem);
if (t != null)
{
fieldTypes.Add(new Tuple<string, Type>(child.Name, t));
}
else
{
// TODO: The reason for the try-catch is to deal with implementing types we don't support yet, like List<SomeType>
// For now, we create a stub type.
fieldTypes.Add(new Tuple<string, Type>(child.Name, typeof(string)));
}
});
}
![]()
dbio对象是一个接口,支持不同物理数据库(如SQLite、Postgres、SQL Server等)的连接和语法细节。
创建后,我们可以检查数据库,例如,一个非常简单的实现。以下是Postgres对上述代码创建的表所说的:
CREATE TABLE latlon ( id serial NOT NULL, latitude double precision, longitude double precision, CONSTRAINT latlon_pkey PRIMARY KEY (id) )
我们的每个单元测试都会删除表并重新创建它们,以清除之前测试的数据。
简单的非唯一键插入测试
![]() 此测试验证,当我们插入相同的信息时,我们得到两个记录。
此测试验证,当我们插入相同的信息时,我们得到两个记录。
/// <summary>
/// Verifies that a non-unique ST with 2 NT's generates multiple records for the same data.
/// </summary>
[TestMethod]
public void SimpleNonUniqueInsert()
{
InitializeSDRTests(() => InitLatLonNonUnique());
// Initialize the Semantic Data Receptor with the signal it should be listening to.
DropTable("Restaurant");
DropTable("LatLon");
sdr.Protocols = "LatLon";
sdr.ProtocolsUpdated();
// Create the signal.
ICarrier carrier = Helpers.CreateCarrier(rsys, "LatLon", signal =>
{
signal.latitude = 1.0;
signal.longitude = 2.0;
});
// Let's see what the SDR does.
sdr.ProcessCarrier(carrier);
IDbConnection conn = sdr.Connection;
int count;
IDbCommand cmd = conn.CreateCommand();
cmd.CommandText = "SELECT count(*) from LatLon";
count = Convert.ToInt32(cmd.ExecuteScalar());
Assert.AreEqual(1, count, "Expected 1 LatLon record.");
// Insert another, identical record. We should now have two records.
sdr.ProcessCarrier(carrier);
cmd.CommandText = "SELECT count(*) from LatLon";
count = Convert.ToInt32(cmd.ExecuteScalar());
Assert.AreEqual(2, count, "Expected 2 LatLon records.");
sdr.Terminate();
}
![]() 在上面的代码中,创建了一个“载体”。载体就像小信使鸽,用于在接收器之间通信。由于语义数据库实现在接收器内部,我们必须假装向其发送消息。您可以回顾关于HOPE的先前文章以了解更多关于载体、协议和信号的信息,但基本思想是,我们正在为“LatLon”协议(我们之前已定义了其语义结构)创建一个载体,并为原生类型字段分配值。语义引擎为每个语义结构生成C#代码并为我们实例化它。利用
在上面的代码中,创建了一个“载体”。载体就像小信使鸽,用于在接收器之间通信。由于语义数据库实现在接收器内部,我们必须假装向其发送消息。您可以回顾关于HOPE的先前文章以了解更多关于载体、协议和信号的信息,但基本思想是,我们正在为“LatLon”协议(我们之前已定义了其语义结构)创建一个载体,并为原生类型字段分配值。语义引擎为每个语义结构生成C#代码并为我们实例化它。利用dynamic关键字,我们可以分配属性值,而无需C# interface声明。
![]() 我们不明确说明“insert”是因为,在宏观层面,我们只想监听特定的语义实例(协议-信号),如果我们看到一个,我们就持久化它。前端UI允许我们选择要持久化的语义类型,但优点是任何发出特定协议的“接收器”都不关心它是否被持久化——基本上,我们将持久化变成了一个可选组件,完全将其与任何其他计算单元解耦。这意味着我们也可以实现不同的持久化机制,传统的RDBMS、图数据库,甚至NoSQL、Excel导出等。
我们不明确说明“insert”是因为,在宏观层面,我们只想监听特定的语义实例(协议-信号),如果我们看到一个,我们就持久化它。前端UI允许我们选择要持久化的语义类型,但优点是任何发出特定协议的“接收器”都不关心它是否被持久化——基本上,我们将持久化变成了一个可选组件,完全将其与任何其他计算单元解耦。这意味着我们也可以实现不同的持久化机制,传统的RDBMS、图数据库,甚至NoSQL、Excel导出等。
![]() 当我们传入一个语义结构时会发生什么?这会触发插入/更新算法,尽管我们在本文中只关注插入。暴露的“API”函数设置了一些初始状态变量并调用一个递归方法。
当我们传入一个语义结构时会发生什么?这会触发插入/更新算法,尽管我们在本文中只关注插入。暴露的“API”函数设置了一些初始状态变量并调用一个递归方法。
string st = carrier.Protocol.DeclTypeName; // Get the STS for the carrier's protocol: ISemanticTypeStruct sts = rsys.SemanticTypeSystem.GetSemanticTypeStruct(st); Dictionary<ISemanticTypeStruct, List<FKValue>> stfkMap = new Dictionary<ISemanticTypeStruct, List<FKValue>>(); ProcessSTS(stfkMap, sts, carrier.Signal);
为了保证外键的完整性,结构需要从下往上插入到数据库中。ProcessSTS方法通过深入到最低的结构元素——只实现原生类型的元素——来做到这一点。顶级函数很简单,递归到子语义元素,直到语义元素“触底”到只包含原生类型。
/// <summary>
/// Drills into any child semantic elements, accumulating foreign keys for each level in the semantic hierarchy.
/// When all children are inserted/updated, the parent can be inserted.
/// </summary>
protected int ProcessSTS(Dictionary<ISemanticTypeStruct, List<FKValue>> stfkMap, ISemanticTypeStruct sts, object signal, bool childAsUnique = false)
{
// Drill into each child ST and assign the return ID to this ST's FK for the child table name.
ProcessChildren(stfkMap, sts, signal, childAsUnique);
// Having processed all child ST's, We can now make the same determination of
// whether the record needs to check for uniqueness, however at this level,
// we need to write out both ST and any NT values in the current ST structure.
// This is very similar to an ST without child ST's, but here we also use ST's that are designated as unique to build the composite key.
int id = ArbitrateUniqueness(stfkMap, sts, signal, childAsUnique);
return id;
}
当算法触底时,会检查数据是否是唯一的语义元素和原生类型,这决定了是否允许插入重复项以及是否执行更新或插入。
当算法从语义树向上工作时,子ID会被累积,以便填充父节点的外键字段。
/// <summary>
/// For each child that has a non-null signal, process its children.
/// </summary>
protected void ProcessChildren(Dictionary<ISemanticTypeStruct, List<FKValue>> stfkMap, ISemanticTypeStruct sts, object signal, bool childAsUnique)
{
sts.SemanticElements.ForEach(child =>
{
// Get the child signal and STS and check it, returning a new or existing ID for the entry.
ISemanticTypeStruct childsts = child.Element.Struct; // rsys.SemanticTypeSystem.GetSemanticTypeStruct(child.Name);
object childSignal = GetChildSignal(signal, child);
// We don't insert null child signals.
if (childSignal != null)
{
int id = ProcessSTS(stfkMap, childsts, childSignal, (sts.Unique || childAsUnique));
RegisterForeignKeyID(stfkMap, sts, child, id);
}
});
}
每个子ID都与其名称(由语义数据库引擎自动生成)及其父语义元素相关联,这样每个语义元素都有0个或多个外键关系列表,当所有子元素都处理完毕后。
/// <summary>
/// Registers a foreign key name and value to be associated with the specified semantic structure, which is used when the ST is inserted
/// after all child elements have been resolved.
/// </summary>
protected void RegisterForeignKeyID(Dictionary<ISemanticTypeStruct, List<FKValue>> stfkMap, ISemanticTypeStruct sts, ISemanticElement child, int id)
{
// Associate the ID to this ST's FK for that child table.
string fieldName = "FK_" + child.Name + "ID";
CreateKeyIfMissing(stfkMap, sts);
stfkMap[sts].Add(new FKValue(fieldName, id, child.UniqueField));
}
唯一原生类型、语义元素(外键和所有子、孙等元素及原生类型)和语义结构(所有子、孙等元素及原生类型)由检查特定语义结构或其父节点设置的各种标志来仲裁。我知道这很冗长,所以让我们看看代码:
/// <summary>
/// Based on whether a semantic element is unique or whether the foreign key fields or native types are unique, we determine how to determine uniqueness.
/// We always perform an insert if there is no way to determine whether the record is unique.
/// If it is unique, the ID of the existing record is returned.
/// </summary>
/// <param name="stfkMap"></param>
protected int ArbitrateUniqueness(Dictionary<ISemanticTypeStruct, List<FKValue>> stfkMap, ISemanticTypeStruct sts, object signal, bool childAsUnique)
{
int id = -1;
if (sts.Unique || childAsUnique)
{
// All FK's and NT's of this ST are considered part of the composite key.
// Get all NT's specifically for this ST (no recursive drilldown)
List<IFullyQualifiedNativeType> fieldValues = rsys.SemanticTypeSystem.GetFullyQualifiedNativeTypeValues(signal, sts.DeclTypeName, false);
id = InsertIfRecordDoesntExist(stfkMap, sts, signal, fieldValues, true);
}
else if (sts.SemanticElements.Any(se => se.UniqueField) || sts.NativeTypes.Any(nt => nt.UniqueField))
{
// Get only unique NT's specifically for this ST (no recursive drilldown)
// Note that a unique semantic element will automatically set the unique field for its native type children, subchildren, etc.
List<IFullyQualifiedNativeType> fieldValues = rsys.SemanticTypeSystem.GetFullyQualifiedNativeTypeValues(signal, sts.DeclTypeName, false).Where(fqnt => fqnt.NativeType.UniqueField).ToList();
id = InsertIfRecordDoesntExist(stfkMap, sts, signal, fieldValues, true);
}
else
{
// No SE's or NT's are unique, so just insert the ST, as we cannot make a determination regarding uniqueness.
id = Insert(stfkMap, sts, signal);
}
return id;
}
![]() 不明显的是,GetFullyQualifiedNativeTypeValues返回的结构会携带父元素的唯一性标志。
不明显的是,GetFullyQualifiedNativeTypeValues返回的结构会携带父元素的唯一性标志。
我们有三种状态:
- 结构或父结构被标记为唯一。这将所有外键和原生类型字段视为复合唯一键。
- 一个或多个子元素(实现为外键)是唯一的,或者一个或多个原生类型元素是唯一的。唯一的复合键仅由唯一的外键和原生类型字段组成。
- 没有唯一键。在这种情况下,结构总是被插入。
一旦我们有了一些唯一字段,我们就会测试它是否唯一,如果是,则插入它。
/// <summary>
/// Insert the record if it doesn't exist.
/// </summary>
protected int InsertIfRecordDoesntExist(Dictionary<ISemanticTypeStruct, List<FKValue>> stfkMap, ISemanticTypeStruct sts, object signal, List<IFullyQualifiedNativeType> fieldValues, bool childAsUnique)
{
int id = -1;
bool exists = QueryUniqueness(stfkMap, sts, signal, fieldValues, out id, true);
if (!exists)
{
id = Insert(stfkMap, sts, signal);
}
return id;
}
返回新记录的主键ID或现有ID。
/// <summary>
/// Build and execute a select statement that determines if the record, based on a composite key, already exists.
/// If so, return the ID of the record.
/// </summary>
protected bool QueryUniqueness(Dictionary<ISemanticTypeStruct, List<FKValue>> stfkMap, ISemanticTypeStruct sts, object signal, List<IFullyQualifiedNativeType> uniqueFieldValues, out int id, bool allFKs = false)
{
id = -1;
bool ret = false;
List<FKValue> fkValues;
bool hasFKValues = stfkMap.TryGetValue(sts, out fkValues);
StringBuilder sb = BuildUniqueQueryStatement(hasFKValues, fkValues, sts, uniqueFieldValues, allFKs);
IDbCommand cmd = AddParametersToCommand(uniqueFieldValues, hasFKValues, fkValues, allFKs);
cmd.CommandText = sb.ToString();
LogSqlStatement(cmd.CommandText);
object oid = cmd.ExecuteScalar();
ret = (oid != null);
if (ret)
{
id = Convert.ToInt32(oid);
}
return ret;
}
最后,如果需要插入,我们就有这段相当笨拙的代码来实际执行插入。
protected int Insert(Dictionary<ISemanticTypeStruct, List<FKValue>> stfkMap, ISemanticTypeStruct sts, object signal)
{
// Get native types to insert:
List<IFullyQualifiedNativeType> ntFieldValues = rsys.SemanticTypeSystem.GetFullyQualifiedNativeTypeValues(signal, sts.DeclTypeName, false);
StringBuilder sb = new StringBuilder("insert into " + sts.DeclTypeName + " (");
sb.Append(String.Join(", ", ntFieldValues.Select(f => f.Name)));
// Get ST's to insert as FK_ID's:
List<FKValue> fkValues;
bool hasFKValues = stfkMap.TryGetValue(sts, out fkValues);
if (hasFKValues && fkValues.Count > 0)
{
// Join in the FK_ID field names.
if (ntFieldValues.Count > 0) sb.Append(", ");
sb.Append(string.Join(", ", fkValues.Select(fkv => fkv.FieldName)));
}
// Setup NT field values:
sb.Append(") values (");
sb.Append(String.Join(", ", ntFieldValues.Select(f => "@" + f.Name)));
// Setup ST FK parameters:
if (hasFKValues && fkValues.Count > 0)
{
if (ntFieldValues.Count > 0) sb.Append(", ");
sb.Append(string.Join(", ", fkValues.Select(fkv => "@" + fkv.FieldName)));
}
sb.Append(")");
IDbCommand cmd = dbio.CreateCommand();
// Assign NT values:
ntFieldValues.ForEach(fv => cmd.Parameters.Add(dbio.CreateParameter(fv.Name, fv.Value)));
// Assign FK values:
if (hasFKValues && fkValues.Count > 0)
{
fkValues.ForEach(fkv => cmd.Parameters.Add(dbio.CreateParameter(fkv.FieldName, fkv.ID)));
}
cmd.CommandText = sb.ToString();
LogSqlStatement(cmd.CommandText);
cmd.ExecuteNonQuery();
int id = dbio.GetLastID(sts.DeclTypeName);
return id;
}
简单的唯一键插入测试
![]() 此测试验证,当我们尝试插入两条相同的记录时,语义数据库会根据我们的语义结构配置检测到这一点,并忽略第二次插入,因为它是一条重复记录。
此测试验证,当我们尝试插入两条相同的记录时,语义数据库会根据我们的语义结构配置检测到这一点,并忽略第二次插入,因为它是一条重复记录。
回想一下非唯一的LatLon语义结构是如何初始化的:
protected void InitLatLonNonUnique()
{
SemanticTypeStruct sts = Helpers.CreateSemanticType("LatLon", false, decls, structs);
Helpers.CreateNativeType(sts, "latitude", "double", false);
Helpers.CreateNativeType(sts, "longitude", "double", false);
}
在此单元测试中,我们以稍有不同的方式初始化结构:
protected void InitLatLonUniqueFields()
{
SemanticTypeStruct sts = Helpers.CreateSemanticType("LatLon", false, decls, structs);
Helpers.CreateNativeType(sts, "latitude", "double", true);
Helpers.CreateNativeType(sts, "longitude", "double", true);
}
);
Helpers.CreateNativeType(sts, "longitude", "double", true);
}
在此结构中,我们声明了原生类型字段都是唯一的。这个复合键构成了唯一的字段,我们看到语义数据库最终只插入了一条记录。
简单的唯一结构插入测试
![]() 同样,此测试验证,当我们尝试插入两条相同的记录时,语义数据库会根据我们的语义结构配置检测到这一点,并忽略第二次插入,因为它是一条重复记录。在这种情况下,是语义结构本身被标记为唯一的。
同样,此测试验证,当我们尝试插入两条相同的记录时,语义数据库会根据我们的语义结构配置检测到这一点,并忽略第二次插入,因为它是一条重复记录。在这种情况下,是语义结构本身被标记为唯一的。
protected void InitLatLonUniqueST()
{
SemanticTypeStruct sts = Helpers.CreateSemanticType("LatLon", true, decls, structs);
Helpers.CreateNativeType(sts, "latitude", "double", false);
Helpers.CreateNativeType(sts, "longitude", "double", false);
}
我们在这里(以简单的方式)测试,如果一个结构被声明为唯一的,那么我们就无需设置此处及以下所有原生类型字段为唯一的。
两级非唯一插入测试
![]() 这里我们做一些更有趣的事情——我们将创建一个简单的两级结构:父级“Restaurant”和子级“LatLon”,并验证我们在Restaurant和LatLon表中都得到两条记录。
这里我们做一些更有趣的事情——我们将创建一个简单的两级结构:父级“Restaurant”和子级“LatLon”,并验证我们在Restaurant和LatLon表中都得到两条记录。
首先,让我们看看语义结构的初始化:
protected void InitRestaurantLatLonNonUnique()
{
SemanticTypeStruct stsRest = Helpers.CreateSemanticType("Restaurant", false, decls, structs);
SemanticTypeStruct stsLatLon = Helpers.CreateSemanticType("LatLon", false, decls, structs);
Helpers.CreateNativeType(stsLatLon, "latitude", "double", false);
Helpers.CreateNativeType(stsLatLon, "longitude", "double", false);
Helpers.CreateSemanticElement(stsRest, "LatLon", false);
}
我们看到“Restaurant”有一个“LatLon”元素,它由两个原生类型“latitude”和“longitude”组成。请注意,“Restaurant”本身没有原生类型——我们实际上并不需要或想要任何原生类型——我们想从简单的开始。
![]() 在数据库端,语义数据库创建以下表(由Postgres描述):
在数据库端,语义数据库创建以下表(由Postgres描述):
CREATE TABLE restaurant ( id serial NOT NULL, fk_latlonid bigint, CONSTRAINT restaurant_pkey PRIMARY KEY (id), CONSTRAINT restaurant_fk_latlonid_fkey FOREIGN KEY (fk_latlonid) REFERENCES latlon (id) MATCH SIMPLE ON UPDATE NO ACTION ON DELETE NO ACTION )
注意对LatLon表的(令人恼火的)外键,Postgres将所有表和字段都转为小写。
LatLon表没有改变。
CREATE TABLE latlon ( id serial NOT NULL, latitude double precision, longitude double precision, CONSTRAINT latlon_pkey PRIMARY KEY (id) )
这个单元测试现在稍微不同地初始化语义结构,因为LatLon是Restaurant的一个元素:
[TestMethod]
public void TwoLevelNonUniqueSTInsert()
{
InitializeSDRTests(() => InitRestaurantLatLonNonUnique());
// Initialize the Semantic Data Receptor with the signal it should be listening to.
DropTable("Restaurant");
DropTable("LatLon");
sdr.Protocols = "LatLon; Restaurant";
sdr.ProtocolsUpdated();
// Create the signal.
ICarrier carrier = Helpers.CreateCarrier(rsys, "Restaurant", signal =>
{
signal.LatLon.latitude = 1.0;
signal.LatLon.longitude = 2.0;
});
// Let's see what the SDR does.
sdr.ProcessCarrier(carrier);
IDbConnection conn = sdr.Connection;
int count;
IDbCommand cmd = conn.CreateCommand();
cmd.CommandText = "SELECT count(*) from LatLon";
count = Convert.ToInt32(cmd.ExecuteScalar());
Assert.AreEqual(1, count, "Expected 1 LatLon record.");
cmd.CommandText = "SELECT count(*) from Restaurant";
count = Convert.ToInt32(cmd.ExecuteScalar());
Assert.AreEqual(1, count, "Expected 1 Restaurant record.");
// Insert another, identical record. We should still have one record.
sdr.ProcessCarrier(carrier);
cmd.CommandText = "SELECT count(*) from LatLon";
count = Convert.ToInt32(cmd.ExecuteScalar());
Assert.AreEqual(2, count, "Expected 2 LatLon record.");
cmd.CommandText = "SELECT count(*) from Restaurant";
count = Convert.ToInt32(cmd.ExecuteScalar());
Assert.AreEqual(2, count, "Expected 2 Restaurant records.");
sdr.Terminate();
}
两级唯一结构插入测试
![]() 接下来,我们想看看当创建LatLon结构,并指示它是唯一时会发生什么:
接下来,我们想看看当创建LatLon结构,并指示它是唯一时会发生什么:
protected void InitRestaurantLatLonUniqueChildST()
{
SemanticTypeStruct stsRest = Helpers.CreateSemanticType("Restaurant", false, decls, structs);
SemanticTypeStruct stsLatLon = Helpers.CreateSemanticType("LatLon", true, decls, structs); // child ST LatLon is declared to be unique.
Helpers.CreateNativeType(stsLatLon, "latitude", "double", false);
Helpers.CreateNativeType(stsLatLon, "longitude", "double", false);
Helpers.CreateSemanticElement(stsRest, "LatLon", false); // The element LatLon in Restaurant is NOT unique.
}
正如预期的那样,当我们尝试插入两条重复记录时,LatLon结构只被插入一次,我们得到两条Restaurant记录指向同一个LatLon记录。
int count; IDbCommand cmd = conn.CreateCommand(); cmd.CommandText = "SELECT count(*) from LatLon"; count = Convert.ToInt32(cmd.ExecuteScalar()); Assert.AreEqual(1, count, "Expected 1 LatLon record."); cmd.CommandText = "SELECT count(*) from Restaurant"; count = Convert.ToInt32(cmd.ExecuteScalar()); Assert.AreEqual(1, count, "Expected 1 Restaurant record."); // Insert another, identical record. We should still have one record. sdr.ProcessCarrier(carrier); cmd.CommandText = "SELECT count(*) from LatLon"; count = Convert.ToInt32(cmd.ExecuteScalar()); Assert.AreEqual(1, count, "Expected 1 LatLon record."); cmd.CommandText = "SELECT count(*) from Restaurant"; count = Convert.ToInt32(cmd.ExecuteScalar()); Assert.AreEqual(2, count, "Expected 2 Restaurant records.");
两级唯一元素插入测试
![]() 这个主题的一个变体是创建Restaurant-LatLon结构,使得Restaurant结构中的LatLon元素被声明为唯一。具体来说,这意味着告诉语义数据库外键字段“fk_latlonid”是一个唯一字段。我们在代码中像这样初始化结构:
这个主题的一个变体是创建Restaurant-LatLon结构,使得Restaurant结构中的LatLon元素被声明为唯一。具体来说,这意味着告诉语义数据库外键字段“fk_latlonid”是一个唯一字段。我们在代码中像这样初始化结构:
protected void InitRestaurantLatLonUniqueParentSTElement()
{
SemanticTypeStruct stsRest = Helpers.CreateSemanticType("Restaurant", false, decls, structs);
SemanticTypeStruct stsLatLon = Helpers.CreateSemanticType("LatLon", false, decls, structs); // child ST LatLon is declared to NOT be unique.
Helpers.CreateNativeType(stsLatLon, "latitude", "double", false);
Helpers.CreateNativeType(stsLatLon, "longitude", "double", false);
Helpers.CreateSemanticElement(stsRest, "LatLon", true); // The element LatLon in Restaurant is unique.
}
这是我们的测试(测试代码的较早部分与前几种情况相同):
int count; IDbCommand cmd = conn.CreateCommand(); cmd.CommandText = "SELECT count(*) from LatLon"; count = Convert.ToInt32(cmd.ExecuteScalar()); Assert.AreEqual(1, count, "Expected 1 LatLon record."); cmd.CommandText = "SELECT count(*) from Restaurant"; count = Convert.ToInt32(cmd.ExecuteScalar()); Assert.AreEqual(1, count, "Expected 1 Restaurant record."); // Insert another, identical record. We should have two records. sdr.ProcessCarrier(carrier); cmd.CommandText = "SELECT count(*) from LatLon"; count = Convert.ToInt32(cmd.ExecuteScalar()); Assert.AreEqual(2, count, "Expected 2 LatLon records."); cmd.CommandText = "SELECT count(*) from Restaurant"; count = Convert.ToInt32(cmd.ExecuteScalar()); Assert.AreEqual(2, count, "Expected 2 Restaurant records.");
由于只有外键是唯一的,我们将插入两条LatLon记录,因为LatLon中没有声明唯一字段。由于这返回一个新的ID,外键字段不是唯一的,导致在Restaurant表中出现第二个条目。
两级唯一元素和结构插入测试
![]() 最后,我们测试一种组合,其中Restaurant的元素LatLon(即其外键)和LatLon结构本身都是唯一的。这是我们配置语义结构的方式:
最后,我们测试一种组合,其中Restaurant的元素LatLon(即其外键)和LatLon结构本身都是唯一的。这是我们配置语义结构的方式:
protected void InitRestaurantUniqueLatLonAndParentSTElement()
{
SemanticTypeStruct stsRest = Helpers.CreateSemanticType("Restaurant", false, decls, structs);
SemanticTypeStruct stsLatLon = Helpers.CreateSemanticType("LatLon", true, decls, structs);
Helpers.CreateNativeType(stsLatLon, "latitude", "double", false);
Helpers.CreateNativeType(stsLatLon, "longitude", "double", false);
Helpers.CreateSemanticElement(stsRest, "LatLon", true); // The element LatLon in Restaurant is unique.
}
现在我们看到,因为LatLon结构是唯一的并且Restaurant中的LatLon元素也是唯一的(实现为外键),所以当我们尝试插入两条相同的记录时,我们会得到一条Restaurant记录和一条LatLon记录。
int count; IDbCommand cmd = conn.CreateCommand(); cmd.CommandText = "SELECT count(*) from LatLon"; count = Convert.ToInt32(cmd.ExecuteScalar()); Assert.AreEqual(1, count, "Expected 1 LatLon record."); cmd.CommandText = "SELECT count(*) from Restaurant"; count = Convert.ToInt32(cmd.ExecuteScalar()); Assert.AreEqual(1, count, "Expected 1 Restaurant record."); // Insert another, identical record. We should still have one record. sdr.ProcessCarrier(carrier); cmd.CommandText = "SELECT count(*) from LatLon"; count = Convert.ToInt32(cmd.ExecuteScalar()); Assert.AreEqual(1, count, "Expected 1 LatLon record."); cmd.CommandText = "SELECT count(*) from Restaurant"; count = Convert.ToInt32(cmd.ExecuteScalar()); Assert.AreEqual(1, count, "Expected 1 Restaurant record.");
![]() 因为这一切都非常复杂,让我们来测试你的理解。当语义结构声明如下时会发生什么:
因为这一切都非常复杂,让我们来测试你的理解。当语义结构声明如下时会发生什么:
protected void InitRestaurantUniqueLatLonAndParentSTElement()
{
SemanticTypeStruct stsRest = Helpers.CreateSemanticType("Restaurant", true, decls, structs);
SemanticTypeStruct stsLatLon = Helpers.CreateSemanticType("LatLon", false, decls, structs);
Helpers.CreateNativeType(stsLatLon, "latitude", "double", false);
Helpers.CreateNativeType(stsLatLon, "longitude", "double", false);
Helpers.CreateSemanticElement(stsRest, "LatLon", true); // The element LatLon in Restaurant is unique.
}
是的,确实如此,因为Restaurant结构本身被声明为唯一的,每个子元素都继承了其父级的唯一性,所以当尝试重复插入相同的语义结构值时,我们只会插入一个实际记录。
简单的查询测试
![]() 如果你觉得插入数据很复杂,那么从数据库中检索数据更复杂,因为语义数据库会推断如何连接不同的语义结构。查询包括:
如果你觉得插入数据很复杂,那么从数据库中检索数据更复杂,因为语义数据库会推断如何连接不同的语义结构。查询包括:
- 确定原生类型字段
- 构建深入子元素的连接列表
- 按排序子句解析物理表和字段名称
- 按where子句解析物理表和字段名称(目前未实现)
- 添加数据库特定的行返回限制实现
- 在多结构连接中,推断结构之间的链接并将它们实现为额外的表连接
- 执行查询
- 使用每个返回行的数据填充语义实例
让我们从一个基本的单结构查询开始:
[TestMethod]
public void SimpleQuery()
{
InitializeSDRTests(() => InitLatLonNonUnique());
// Initialize the Semantic Data Receptor with the signal it should be listening to.
DropTable("Restaurant"); // Dependent table we have to remove first.
DropTable("LatLon");
sdr.Protocols = "LatLon";
sdr.ProtocolsUpdated();
sdr.UnitTesting = true;
// Create the signal.
ICarrier latLonCarrier = Helpers.CreateCarrier(rsys, "LatLon", signal =>
{
signal.latitude = 1.0;
signal.longitude = 2.0;
});
sdr.ProcessCarrier(latLonCarrier);
// Create the query
ICarrier queryCarrier = Helpers.CreateCarrier(rsys, "Query", signal =>
{
signal.QueryText = "LatLon";
});
sdr.ProcessCarrier(queryCarrier);
List<QueuedCarrierAction> queuedCarriers = rsys.QueuedCarriers;
Assert.AreEqual(1, queuedCarriers.Count, "Expected one signal to be returned.");
dynamic retSignal = queuedCarriers[0].Carrier.Signal;
Assert.AreEqual(1.0, retSignal.latitude, "Wrong data for latitude.");
Assert.AreEqual(2.0, retSignal.longitude, "Wrong data for longitude.");
}
![]() 因为我们使用的是HOPE架构,所以实际上没有接收结果记录的载体,所以我们检查队列,这比在我们的单元测试中添加接收载体所需的脚手架更简单。
因为我们使用的是HOPE架构,所以实际上没有接收结果记录的载体,所以我们检查队列,这比在我们的单元测试中添加接收载体所需的脚手架更简单。
![]() 单结构查询实现基本上就是你所期望的:
单结构查询实现基本上就是你所期望的:
protected void QueryDatabase(string query)
{
string maxRecords = null;
List<string> types;
List<string> orderBy;
Preprocess(query, out maxRecords, out types, out orderBy);
// We only have one protocol to query, so we can create the protocol directly since it's already defined.
if (types.Count() == 1)
{
string protocol = types[0];
AddEmitProtocol(protocol); // identical protocols are ignored.
ISemanticTypeStruct sts = rsys.SemanticTypeSystem.GetSemanticTypeStruct(protocol);
List<object> signals = QueryType(protocol, String.Empty, orderBy, maxRecords);
EmitSignals(signals, sts);
}
else ...
![]() 再次,因为语义数据库实际上是一个接收器,任何新遇到的协议都会被添加到数据库发出的协议列表中。因此,
再次,因为语义数据库实际上是一个接收器,任何新遇到的协议都会被添加到数据库发出的协议列表中。因此,AddEmitProtocol行。
QueryType方法将所有组件组合在一起以执行查询。
/// <summary>
/// Return a list of objects that represents the semantic element instances (signals) in the resulting query set.
/// </summary>
protected List<object> QueryType(string protocol, string where, List<string> orderBy, string maxRecords)
{
// We build the query by recursing through the semantic structure.
ISemanticTypeStruct sts = rsys.SemanticTypeSystem.GetSemanticTypeStruct(protocol);
List<string> fields = new List<string>();
List<string> joins = new List<string>();
Dictionary<ISemanticTypeStruct, int> structureUseCounts = new Dictionary<ISemanticTypeStruct, int>();
List<Tuple<string, string>> fqntAliases = new List<Tuple<string, string>>();
BuildQuery(sts, fields, joins, structureUseCounts, sts.DeclTypeName, fqntAliases);
string sqlQuery = CreateSqlStatement(sts, fields, joins, fqntAliases, where, orderBy, maxRecords);
List<object> ret = PopulateSignals(sqlQuery, sts);
return ret;
}
在这个过程中非常重要的是递归的BuildQuery,它遍历语义结构,跟随子元素并创建必要的连接,同时收集任何原生类型。
/// <summary>
/// Recurses the semantic structure to generate the native type fields and the semantic element joins.
/// fqntAliases -- fully qualified native type and it's actual alias in the field list.
/// </summary>
protected void BuildQuery(ISemanticTypeStruct sts, List<string> fields, List<string> joins, Dictionary<ISemanticTypeStruct, int> structureUseCounts, string fqn, List<Tuple<string, string>> fqntAliases)
{
// Add native type fields.
string parentName = GetUseName(sts, structureUseCounts);
sts.NativeTypes.ForEach(nt =>
{
string qualifiedFieldName = fqn + "." + nt.Name;
string qualifiedAliasFieldName = parentName + "." + nt.Name;
fields.Add(qualifiedAliasFieldName);
fqntAliases.Add(new Tuple<string, string>(qualifiedFieldName, qualifiedAliasFieldName));
});
sts.SemanticElements.ForEach(child =>
{
ISemanticTypeStruct childsts = child.Element.Struct; // rsys.SemanticTypeSystem.GetSemanticTypeStruct(child.Name);
IncrementUseCount(childsts, structureUseCounts);
string asChildName = GetUseName(childsts, structureUseCounts);
joins.Add("left join " + childsts.DeclTypeName + " as " + asChildName + " on " + asChildName + ".ID = " + parentName + ".FK_" + childsts.DeclTypeName + "ID");
BuildQuery(childsts, fields, joins, structureUseCounts, fqn+"."+childsts.DeclTypeName, fqntAliases);
});
}
完成之后,就可以创建实际的SQL select语句了。
protected string CreateSqlStatement(ISemanticTypeStruct sts, List<string> fields, List<string> joins, List<Tuple<string, string>> fqntAliases, string where, List<string> orderBy, string maxRecords)
{
// CRLF for pretty inspection.
string sqlQuery = "select " + String.Join(", ", fields) + " \r\nfrom " + sts.DeclTypeName + " \r\n" + String.Join(" \r\n", joins);
sqlQuery = sqlQuery + " " + ParseOrderBy(orderBy, fqntAliases);
sqlQuery = dbio.AddLimitClause(sqlQuery, maxRecords);
return sqlQuery;
}
一旦我们获取了读取器,我们就可以遍历记录并创建要发出的信号。
protected List<object> PopulateSignals(string sqlQuery, ISemanticTypeStruct sts)
{
List<object> ret = new List<object>();
IDataReader reader = AcquireReader(sqlQuery);
while (reader.Read())
{
object outsignal = rsys.SemanticTypeSystem.Create(sts.DeclTypeName);
int counter = 0; // For a single table join, counter is always 0.
// Populate the signal with the columns in each record read.
Populate(sts, outsignal, reader, ref counter);
ret.Add(outsignal);
}
reader.Close();
return ret;
}
信号字段的实际填充再次是递归的,并依赖于生成查询语句字段的相同顺序。这里我们使用反射来设置值,同时深入语义结构。
/// <summary>
/// Recursively populates the values into the signal. The recursion algorithm here must match exactly the same
/// form as the recursion algorithm in BuildQuery, as the correlation between field names and their occurrance
/// in the semantic structure is relied upon. For now at least.
/// Returns true if there are any non-null NT valus.
/// </summary>
protected bool Populate(ISemanticTypeStruct sts, object signal, IDataReader reader, ref int parmNumber)
{
List<object> vals = new List<object>();
bool anyNonNull = false;
for (int i = 0; i < sts.NativeTypes.Count; i++)
{
vals.Add(reader[parmNumber++]);
}
// Add native type fields. Use a foreach loop because ref types can't be used in lambda expressions.
sts.NativeTypes.ForEachWithIndex((nt, idx) =>
{
object val = vals[idx];
if (val != DBNull.Value)
{
Assert.TryCatch(() => nt.SetValue(rsys.SemanticTypeSystem, signal, val), (ex) => EmitException(ex));
anyNonNull = true;
}
});
foreach (ISemanticElement child in sts.SemanticElements)
{
ISemanticTypeStruct childsts = child.Element.Struct;
PropertyInfo piSub = signal.GetType().GetProperty(child.Name);
object childSignal = piSub.GetValue(signal);
anyNonNull |= Populate(childsts, childSignal, reader, ref parmNumber);
}
return anyNonNull;
}
![]() 在单结构查询中,我们实际上并不关心是否有任何非空字段。然而,Populate方法的返回值在处理多结构查询时很有用,因为结构的所有空字段会将结构设置为null。此外,
在单结构查询中,我们实际上并不关心是否有任何非空字段。然而,Populate方法的返回值在处理多结构查询时很有用,因为结构的所有空字段会将结构设置为null。此外,parmNumber再次是多结构查询中的一个因素。
别名查询测试
![]() 此测试简单地检查表和字段名别名是否被使用。语义结构设置如下:
此测试简单地检查表和字段名别名是否被使用。语义结构设置如下:
protected void InitPersonStruct()
{
SemanticTypeStruct stsText = Helpers.CreateSemanticType("Text", false, decls, structs);
Helpers.CreateNativeType(stsText, "Value", "string", false);
SemanticTypeStruct stsFirstName = Helpers.CreateSemanticType("FirstName", false, decls, structs);
Helpers.CreateSemanticElement(stsFirstName, "Text", false);
SemanticTypeStruct stsLastName = Helpers.CreateSemanticType("LastName", false, decls, structs);
Helpers.CreateSemanticElement(stsLastName, "Text", false);
SemanticTypeStruct stsPerson = Helpers.CreateSemanticType("Person", false, decls, structs);
Helpers.CreateSemanticElement(stsPerson, "LastName", false);
Helpers.CreateSemanticElement(stsPerson, "FirstName", false);
}
这里,Person包含FirstName和LastName,两者都引用Text结构。这需要两次连接到Text表,这意味着表必须被别名。字段名称相同,也必须被别名。
![]() 在语义数据库中,通过跟踪表的使用并为每次使用增加计数器来实现这一点。
在语义数据库中,通过跟踪表的使用并为每次使用增加计数器来实现这一点。
/// <summary>
/// Append the use counter if it exists.
/// </summary>
protected string GetUseName(ISemanticTypeStruct sts, Dictionary<ISemanticTypeStruct, int> structureUseCounts)
{
int count;
string ret = sts.DeclTypeName;
if (structureUseCounts.TryGetValue(sts, out count))
{
ret = ret + count;
}
return ret;
}
生成的查询如下所示:
select Text1.Value, Text2.Value from Person left join LastName as LastName1 on LastName1.ID = Person.FK_LastNameID left join Text as Text1 on Text1.ID = LastName1.FK_TextID left join FirstName as FirstName1 on FirstName1.ID = Person.FK_FirstNameID left join Text as Text2 on Text2.ID = FirstName1.FK_TextID
请注意“as”语句。为了方便起见,每个表都有别名。这对于多结构连接是必不可少的。
唯一键连接
![]() 有三种连接结构的方式:通过其唯一键字段、声明为唯一的结构,或通过结构的唯一元素。后两种都解析为唯一键字段,但仍需要测试(下一个测试)。这里,我们测试一个共享结构,该结构被声明为唯一的,允许语义数据库推断两个父结构可以连接。结构定义如下:
有三种连接结构的方式:通过其唯一键字段、声明为唯一的结构,或通过结构的唯一元素。后两种都解析为唯一键字段,但仍需要测试(下一个测试)。这里,我们测试一个共享结构,该结构被声明为唯一的,允许语义数据库推断两个父结构可以连接。结构定义如下:
protected void InitFeedUrlWithUniqueStruct()
{
SemanticTypeStruct stsUrl = Helpers.CreateSemanticType("Url", true, decls, structs);
Helpers.CreateNativeType(stsUrl, "Value", "string", false);
SemanticTypeStruct stsVisited = Helpers.CreateSemanticType("Visited", false, decls, structs);
Helpers.CreateSemanticElement(stsVisited, "Url", false);
Helpers.CreateNativeType(stsVisited, "Count", "int", false);
SemanticTypeStruct stsFeedUrl = Helpers.CreateSemanticType("RSSFeedUrl", false, decls, structs);
Helpers.CreateSemanticElement(stsFeedUrl, "Url", false);
}
创建了一个通用的结构Url,并将其声明为唯一的。Visited和RSSFeedURl结构都引用Url。
单元测试设置了两个“feed”条目:
然而,visited仅引用 https://(抱歉Code Project!)。
protected void TwoStructureJoinTest()
{
DropTable("Url");
DropTable("Visited");
DropTable("RSSFeedUrl");
sdr.Protocols = "RSSFeedUrl; Visited";
sdr.ProtocolsUpdated();
sdr.UnitTesting = true;
// The schema defines that:
// URL is a unique structure
// RSSFeedUrl.Url is unique (no duplicates pointing to the same Url)
// Visited.Url is unique (no duplicates pointing to the same Url)
ICarrier feedUrlCarrier1 = Helpers.CreateCarrier(rsys, "RSSFeedUrl", signal =>
{
signal.Url.Value = "https://";
});
// A URL we will not be joining on because we don't have a Visited record.
ICarrier feedUrlCarrier2 = Helpers.CreateCarrier(rsys, "RSSFeedUrl", signal =>
{
signal.Url.Value = "https://codeproject.org.cn";
});
ICarrier visitedCarrier = Helpers.CreateCarrier(rsys, "Visited", signal =>
{
signal.Url.Value = "https://";
signal.Count = 1; // non-zero value to make sure that we're not getting a default value back.
});
sdr.ProcessCarrier(feedUrlCarrier1);
sdr.ProcessCarrier(feedUrlCarrier2);
sdr.ProcessCarrier(visitedCarrier);
// Create the query
ICarrier queryCarrier = Helpers.CreateCarrier(rsys, "Query", signal =>
{
// *** The order here is important, because the second join will be a left join ***
// TODO: This needs to be exposed to the user somehow.
signal.QueryText = "RSSFeedUrl, Visited";
});
sdr.ProcessCarrier(queryCarrier);
List<QueuedCarrierAction> queuedCarriers = rsys.QueuedCarriers;
Assert.AreEqual(2, queuedCarriers.Count, "Expected two signals to be returned.");
// The result, using a left join, is:
// "https://"; 1; "https://"
// "https://codeproject.org.cn"; ; "" <-- notice the Visited portion is null!
// This is a new ST that isn't defined in our schema.
dynamic retSignal = queuedCarriers[0].Carrier.Signal;
Assert.AreEqual("https://", retSignal.RSSFeedUrl.Url.Value, "Unexpected URL value.");
Assert.AreEqual(1, retSignal.Visited.Count);
retSignal = queuedCarriers[1].Carrier.Signal;
Assert.AreEqual("https://codeproject.org.cn", retSignal.RSSFeedUrl.Url.Value, "Unexpected URL value.");
Assert.AreEqual(null, retSignal.Visited);
}
![]() 从查询中我们可以看到它是如何连接两个表的:
从查询中我们可以看到它是如何连接两个表的:
select Url1.Value, Visited.Count, Url2.Value from RSSFeedUrl left join Url as Url1 on Url1.ID = RSSFeedUrl.FK_UrlID left join Visited on Visited.FK_UrlID = RSSFeedUrl.FK_UrlID left join Url as Url2 on Url2.ID = Visited.FK_UrlID
并注意数据是如何返回的:

![]() 第二行显示我们没有与https://codeproject.org.cn相关的Visited记录。由于Visited结构的所有字段都为null,语义数据库会将实例设置为null,这里会进行测试。
第二行显示我们没有与https://codeproject.org.cn相关的Visited记录。由于Visited结构的所有字段都为null,语义数据库会将实例设置为null,这里会进行测试。
retSignal = queuedCarriers[1].Carrier.Signal;
Assert.AreEqual("https://codeproject.org.cn", retSignal.RSSFeedUrl.Url.Value, "Unexpected URL value.");
Assert.AreEqual(null, retSignal.Visited);
![]() 另外请注意,返回的结构是由语义数据库在运行时创建的。返回的信号由一个根语义类型组成,其元素是连接的结构。因此,在上面的查询中,我们得到以下结构:
另外请注意,返回的结构是由语义数据库在运行时创建的。返回的信号由一个根语义类型组成,其元素是连接的结构。因此,在上面的查询中,我们得到以下结构:
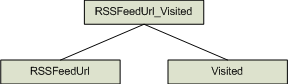
或者,我更喜欢这样为语义结构图示,以便所有原生类型都在顶部:

![]() 当我们尝试连接多个语义结构时会发生什么?
当我们尝试连接多个语义结构时会发生什么?
首先,我们需要发现正确的连接顺序,以便在SQL连接中先声明表,然后再引用它们。虽然这不是所有数据库引擎的要求,但我注意到SQLite如果看到尚未在连接中声明的表引用,肯定会不高兴。所以,现在我们可以开始逐步分析这段代码:
else if (types.Count() > 1)
{
// First we need to find common structures between each of the specified structures.
Dictionary<string, List<Tuple<ISemanticTypeStruct, ISemanticTypeStruct>>> stSemanticTypes = new Dictionary<string, List<Tuple<ISemanticTypeStruct, ISemanticTypeStruct>>>();
Dictionary<TypeIntersection, List<ISemanticTypeStruct>> typeIntersectionStructs = new Dictionary<TypeIntersection, List<ISemanticTypeStruct>>();
Dictionary<ISemanticTypeStruct, int> structureUseCounts = new Dictionary<ISemanticTypeStruct, int>();
List<TypeIntersection> joinOrder = DiscoverJoinOrder(types, stSemanticTypes, typeIntersectionStructs);
...
DiscoverJoinOrder看起来很简单……
protected List<TypeIntersection> DiscoverJoinOrder(List<string> types, Dictionary<string, List<Tuple<ISemanticTypeStruct, ISemanticTypeStruct>>> stSemanticTypes, Dictionary<TypeIntersection, List<ISemanticTypeStruct>> typeIntersectionStructs)
{
// For each root type, get all the sub-ST's.
foreach (string st in types)
{
stSemanticTypes[st] = rsys.SemanticTypeSystem.GetAllSemanticTypes(st);
}
List<TypeIntersection> joinOrder = GetJoinOrder(types, stSemanticTypes, typeIntersectionStructs);
return joinOrder;
}
……但这是欺骗性的,因为真正的工作在GetJoinOrder中。这个函数效率不高,但目前可以完成工作。概念是:
- 从第一个结构(根结构)开始,尝试将其与某个后续结构连接。
- 一旦找到共享结构,将其从列表中移除,然后重新开始,尝试解析连接列表中的下一个结构。
这个过程确保连接的创建顺序是先于其他连接引用。
/// <summary>
/// Iterate until all joins are resolved.
/// </summary>
protected List<TypeIntersection> GetJoinOrder(List<string> types, Dictionary<string, List<Tuple<ISemanticTypeStruct, ISemanticTypeStruct>>> stSemanticTypes, Dictionary<TypeIntersection, List<ISemanticTypeStruct>> typeIntersectionStructs)
{
// We assume that the first ST is always the "base" ST, and everything else is joined to it or to other ST's.
// This requires that we process joins 1..n in a specific order to ensure that joins to ST's are first defined, then referenced.
// TODO: We do not have a test for that.
List<TypeIntersection> joinOrder = new List<TypeIntersection>();
List<string> typesToJoin = new List<string>();
// We need to join all these types.
// These may become "base" types if we have a dependency like:
// 1 depends on 2, and 2 depends on 0.
// To resolve 1, we first discover that 2 depends on 0
// We then iterate again with 2 as the base type and discover that we can now join 1 as a dependency on 2.
// The resulting order is then 0, 2, 1.
typesToJoin.AddRange(types.Skip(1));
// Assume idx 0 is the base.
int baseIdx = 0;
// Do we have any types left to join?
while (typesToJoin.Count > 0)
{
int idx = 0;
bool found = false;
// Easier to debug if we don't use anonymous methods. Better for stack traces on exceptions too!
foreach (string typeToJoin in types)
{
// Skip any type that we already found a join for (it won't be in the list.)
if (!typesToJoin.Contains(typeToJoin))
{
++idx;
continue;
}
// Returns a list of intersecting ST's between the base ST and another ST.
List<ISemanticTypeStruct> sharedStructs = stSemanticTypes[types[baseIdx]].Select(t1 => t1.Item1).Intersect(stSemanticTypes[types[idx]].Select(t2 => t2.Item1)).ToList();
// If we have shared structure...
if (sharedStructs.Count > 0)
{
// TODO: We still need to verify that we have unique keys in which to accomplish a join.
// Write a test for this.
// (For now, we always assume that we do)
TypeIntersection typeIntersection = new TypeIntersection(types[baseIdx], types[idx]);
typeIntersectionStructs[typeIntersection] = sharedStructs;
joinOrder.Add(typeIntersection);
typesToJoin.Remove(types[idx]);
found = true;
// Try next type.
break;
}
++idx;
}
if (found)
{
// Start with the base again.
baseIdx = 0;
}
else
{
// TODO: Determine what type failed to join so we can put out a more intelligent exception.
throw new Exception("Cannot find a common type for the required join.");
}
}
return joinOrder;
}
我们继续设置各种结构,这些结构将用于构建完整的查询,并为第一个(根)语义结构构建各个部分。
// Since we always start with the first ST in the join list as the base type: List<ISemanticTypeStruct> sharedStructs = typeIntersectionStructs[joinOrder[0]]; ISemanticTypeStruct sharedStruct = sharedStructs[0]; string baseType = joinOrder[0].BaseType; ISemanticTypeStruct parent0 = stSemanticTypes[baseType].Single(t => t.Item1 == sharedStruct).Item2; bool parent0ElementUnique = parent0.SemanticElements.Any(se => se.Name == sharedStruct.DeclTypeName && se.UniqueField); // Build the query pieces for the first type: ISemanticTypeStruct sts0 = rsys.SemanticTypeSystem.GetSemanticTypeStruct(baseType); List<string> fields0 = new List<string>(); List<string> joins0 = new List<string>(); List<Tuple<string, string>> fqntAliases = new List<Tuple<string, string>>(); BuildQuery(sts0, fields0, joins0, structureUseCounts, sts0.DeclTypeName, fqntAliases);
现在我们有了用于第一个结构字段和所需连接的集合。
然后我们遍历剩余的结构,按照前面确定的顺序。
// Now we're ready to join the other ST's, which are always joinOrder[joinIdx].JoinType.
for (int joinIdx = 0; joinIdx < joinOrder.Count; joinIdx++)
{
string joinType = joinOrder[joinIdx].JoinType;
FixupBaseType(stSemanticTypes, sharedStruct, joinOrder, joinIdx, ref baseType, ref parent0, ref parent0ElementUnique);
始终跟踪我们正在连接到的结构是必要的。如果结构0与结构1连接,但结构2与结构1连接,那么我们就必须更新我们的“基础”类型,使其变为结构1。这正是FixupBaseType所做的。
protected void FixupBaseType(Dictionary<string, List<Tuple<ISemanticTypeStruct, ISemanticTypeStruct>>> stSemanticTypes, ISemanticTypeStruct sharedStruct, List<TypeIntersection> joinOrder, int joinIdx, ref string baseType, ref ISemanticTypeStruct parent0, ref bool parent0ElementUnique)
{
// If we've changed the "base" type, then update parent0 and parent0ElementUnique.
if (joinOrder[joinIdx].BaseType != baseType)
{
baseType = joinOrder[joinIdx].BaseType;
parent0 = stSemanticTypes[baseType].Single(t => t.Item1 == sharedStruct).Item2;
parent0ElementUnique = parent0.SemanticElements.Any(se => se.Name == sharedStruct.DeclTypeName && se.UniqueField);
}
}
它确保我们“连接”的表是连接声明的右侧。
接下来,我们获取“基础”结构和我们正在连接的结构之间的共享结构。这里的代码注释比代码多。
sharedStructs = typeIntersectionStructs[joinOrder[joinIdx]]; // If the shared structure is a unique field in both parent structures, then we can do then join with the FK_ID's rather than the underlying data. // So, for example, in the UniqueKeyJoinQuery unit test, we can join RSSFeedItem and Visited with: // "join [one of the tables] on RSSFeedItem.FK_UrlID = Visited.FK_UrlID" (ignoring aliased table names) // IMPORTANT: Where the parent tables in the "on" statement are the parents of the respective shared structure, not the root query structure name (which just so happens to be the same in this case.) // If there is NOT a unique key at either or both ends, then we have to drill into all native types at the joined structure level for both query paths, which would look like: // "join [one of the tables] on Url1.Value = Url2.Value [and...]" where the and aggregates all the NT values shared between the two query paths. // Notice that here it is VITAL that we figure out the aliases for each query path. // Interestingly, if both reference is unique structure, we get an intersection. // If both reference a non-unique structure, we get an intersection, but then we need to check the parent to see if the element is unique for both paths. // TODO: At the moment, we just pick the first shared structure. At some point we want to pick one that can work with FK's first, then NT unique key values if we can't find an FK join. // TODO: If there's more than one shared structure, try an pick the one that is unique or who's parent is a unique element. // TODO: Write a unit test for this. sharedStruct = sharedStructs[0];
共享结构要求我们获取具有与共享结构匹配的语义元素的父结构。
// Find the parent for each root query given the shared structure. ISemanticTypeStruct parent1 = stSemanticTypes[joinType].Single(t => t.Item1 == sharedStruct).Item2; bool parent1ElementUnique = parent1.SemanticElements.Any(se => se.Name == sharedStruct.DeclTypeName && se.UniqueField);
![]() 因为我们总是钻研一个特定结构的所有语义结构,所以这段代码做了一件非常具有欺骗性的事情——它允许我们找到任何结构树中的父节点。这非常重要,因为我们可以“并肩”连接语义结构,换句话说,在共享结构在两个语义树之间遇到的任何地方。
因为我们总是钻研一个特定结构的所有语义结构,所以这段代码做了一件非常具有欺骗性的事情——它允许我们找到任何结构树中的父节点。这非常重要,因为我们可以“并肩”连接语义结构,换句话说,在共享结构在两个语义树之间遇到的任何地方。
此时,我们还有两个重要的标志:
- parent0ElementUnique
- parent1ElementUnique
这很重要,因为它指示过程我们可以使用外键进行连接,而不是原生类型的唯一字段。我们将在下一个测试中看到这个测试。
// If the shared structure is unique, or the elements referencing the structure are unique in both parents, then we can use the FK ID between the two parent ST's to join the structures.
// Otherwise, we have to use the NT values in each structure.
if ((sharedStruct.Unique) || (parent0ElementUnique && parent1ElementUnique))
{
...
如果我们知道共享结构被声明为唯一的,或者我们同时拥有两个父节点的唯一元素,那么我们可以使用外键值来连接这两个表。首先,我们构建要连接的表的字段和连接。
// Build the query pieces for the second type, preserving counts so we don't accidentally re-use an alias. ISemanticTypeStruct sts1 = rsys.SemanticTypeSystem.GetSemanticTypeStruct(joinType); List<string> fields1 = new List<string>(); List<string> joins1 = new List<string>(); BuildQuery(sts1, fields1, joins1, structureUseCounts, sts1.DeclTypeName, fqntAliases); fields0.AddRange(fields1);
这些字段被添加到我们正在查询的“主”字段集中。
接下来,我们构建结构-结构连接。
// Note the root element of the second structure is always aliased as "1".
// TODO: This doesn't handle self joins. Scenario? Unit test? Test and throw exception?
// IMPORTANT: In Postgres, we note that the join that declares the table referenced in joins1 must be joined first.
// TODO: We use a left join here because we want to include records from the first table that may not match with the second table. This should be user definable, perhaps the way Oracle used to do it with the "+" to indicate a left join rather than an inner join.
// TODO: The root table name of the second table (parent1) doesn't need an "as" because it will only be referenced once (like in the "from" clause for parent0), however, this means
// that we can't join the same type twice. When will this be an issue?
// Except for types in the query itself, we need to aliased type.
string rightSideTableName = parent0.DeclTypeName;
if (!types.Contains(parent0.DeclTypeName))
{
rightSideTableName = parent0.DeclTypeName + "1"; // TODO: But do we need to know which alias, out of a possibility of aliases, to choose from???
}
if (sharedStruct.DeclTypeName == parent0.DeclTypeName)
{
// The right side should, in this case, be the ID, not an FK, as the left side is joining to the actual table rather than both referencing a common shared FK.
joins0.Add("left join " + parent1.DeclTypeName + " on " + parent1.DeclTypeName + ".FK_" + sharedStruct.DeclTypeName + "ID = " + rightSideTableName + ".ID");
}
else
{
joins0.Add("left join " + parent1.DeclTypeName + " on " + parent1.DeclTypeName + ".FK_" + sharedStruct.DeclTypeName + "ID = " + rightSideTableName + ".FK_" + sharedStruct.DeclTypeName + "ID");
}
joins0.AddRange(joins1);
最后,我们添加第二个结构特有的连接——这些连接用于钻入结构,而不是连接两个结构。
joins0.AddRange(joins1);
有趣的是,因为我还没有这样做,所以通过唯一原生类型连接尚未实现。
else
{
// TODO: Implement a join based on NT unique key values, as we're joining an ST with only NT's.
throw new Exception("Non-FK joins are currently not supported.");
}
最后,在所有表连接都创建完毕后,我们完成SQL语句并开始读取结果。
string sqlQuery = "select " + String.Join(", ", fields0) + " \r\nfrom " + sts0.DeclTypeName + " \r\n" + String.Join(" \r\n", joins0);
sqlQuery = sqlQuery + " " + ParseOrderBy(orderBy, fqntAliases);
sqlQuery = dbio.AddLimitClause(sqlQuery, maxRecords);
ReadResults(sqlQuery);
我们读取根结构和所有连接的结构,构建新的语义结构,最终(终于!)发出带有自定义协议和信号的载体。
while (reader.Read())
{
int counter = 0;
List<object> joinSignals = new List<object>();
// The resulting fields are in the order of how they're populated based on our join list.
object outsignal0 = PopulateStructure(types[0], reader, ref counter);
PopulateJoinStructures(joinSignals, joinOrder, reader, ref counter);
// Now create a custom type if it doesn't already exist. The custom type name is formed from the type names in the join.
ISemanticTypeStruct outprotocol;
object outsignal = CreateCustomType(types, out outprotocol);
// Assign our signals to the children of the custom type.
// TODO: Again, self-joins will fail here.
SetValue(outsignal, types[0], outsignal0);
SetJoinedSignals(outsignal, joinOrder, joinSignals);
// Finally! Create the carrier:
rsys.CreateCarrier(this, outprotocol, outsignal);
}
![]() 请注意,这会为每行创建一个载体。将协议信号集合放置在单个载体上的功能待办。
请注意,这会为每行创建一个载体。将协议信号集合放置在单个载体上的功能待办。
三结构连接测试
![]() 当测试例如如下设置的三结构连接时,这变得更有趣:
当测试例如如下设置的三结构连接时,这变得更有趣:
protected void InitFeedUrlWithUniqueElements()
{
SemanticTypeStruct stsUrl = Helpers.CreateSemanticType("Url", false, decls, structs);
Helpers.CreateNativeType(stsUrl, "Value", "string", true);
SemanticTypeStruct stsVisited = Helpers.CreateSemanticType("Visited", false, decls, structs);
Helpers.CreateSemanticElement(stsVisited, "Url", true);
Helpers.CreateNativeType(stsVisited, "Count", "int", false);
// For 3 ST join tests.
SemanticTypeStruct stsDisplayed = Helpers.CreateSemanticType("Displayed", false, decls, structs);
Helpers.CreateSemanticElement(stsDisplayed, "Url", true);
SemanticTypeStruct stsFeedUrl = Helpers.CreateSemanticType("RSSFeedUrl", false, decls, structs);
Helpers.CreateSemanticElement(stsFeedUrl, "Url", true);
}
此测试设置了四个结构:Url、Visited、Displayed和RSSFeedUrl。
protected void ThreeSemanticTypesJoinTest()
{
DropTable("Url");
DropTable("Visited");
DropTable("Displayed");
DropTable("RSSFeedUrl");
DropTable("RSSFeedItemDisplayed");
sdr.Protocols = "RSSFeedUrl; Visited; Displayed";
sdr.ProtocolsUpdated();
sdr.UnitTesting = true;
// The schema defines that:
// URL is a unique structure
// RSSFeedUrl.Url is unique (no duplicates pointing to the same Url)
// Visited.Url is unique (no duplicates pointing to the same Url)
ICarrier feedUrlCarrier1 = Helpers.CreateCarrier(rsys, "RSSFeedUrl", signal =>
{
signal.Url.Value = "https://";
});
// A URL we will not be joining on because we don't have a Visited record.
ICarrier feedUrlCarrier2 = Helpers.CreateCarrier(rsys, "RSSFeedUrl", signal =>
{
signal.Url.Value = "https://codeproject.org.cn";
});
ICarrier visitedCarrier = Helpers.CreateCarrier(rsys, "Visited", signal =>
{
signal.Url.Value = "https://";
signal.Count = 1; // non-zero value to make sure that we're not getting a default value back.
});
ICarrier displayedCarrier = Helpers.CreateCarrier(rsys, "Displayed", signal =>
{
signal.Url.Value = "https://codeproject.org.cn";
});
sdr.ProcessCarrier(feedUrlCarrier1);
sdr.ProcessCarrier(feedUrlCarrier2);
sdr.ProcessCarrier(visitedCarrier);
sdr.ProcessCarrier(displayedCarrier);
// Create the query
ICarrier queryCarrier = Helpers.CreateCarrier(rsys, "Query", signal =>
{
// *** The order here is important, because the second join will be a left join ***
// TODO: This needs to be exposed to the user somehow.
signal.QueryText = "RSSFeedUrl, Visited, Displayed";
});
sdr.ProcessCarrier(queryCarrier);
List<QueuedCarrierAction> queuedCarriers = rsys.QueuedCarriers;
Assert.AreEqual(2, queuedCarriers.Count, "Expected two signals to be returned.");
// The result, using a left join, is:
// "https://"; 1; "https://"
// "https://codeproject.org.cn"; ; "" <-- notice the Visited portion is null, however the "displayed" portion is NOT null.
// This is a new ST that isn't defined in our schema.
dynamic retSignal = queuedCarriers[0].Carrier.Signal;
Assert.AreEqual("https://", retSignal.RSSFeedUrl.Url.Value, "Unexpected URL value.");
Assert.AreEqual(1, retSignal.Visited.Count);
Assert.AreEqual(null, retSignal.Displayed);
retSignal = queuedCarriers[1].Carrier.Signal;
Assert.AreEqual("https://codeproject.org.cn", retSignal.RSSFeedUrl.Url.Value, "Unexpected URL value.");
Assert.AreEqual(null, retSignal.Visited);
Assert.AreNotEqual(null, retSignal.Displayed);
}
生成的查询如下所示:
select Url1.Value, Visited.Count, Url2.Value, Url3.Value from RSSFeedUrl left join Url as Url1 on Url1.ID = RSSFeedUrl.FK_UrlID left join Visited on Visited.FK_UrlID = RSSFeedUrl.FK_UrlID left join Url as Url2 on Url2.ID = Visited.FK_UrlID left join Displayed on Displayed.FK_UrlID = RSSFeedUrl.FK_UrlID left join Url as Url3 on Url3.ID = Displayed.FK_UrlID
返回的数据如下:

待续...
虽然代码中还有一些重要的待办事项,但我们已经有了足够多的实现来做一些有用的事情。在上一篇文章中,我探讨了RSS Feed与自然语言处理的关系。在下一篇文章中,我们将使用语义数据库来构建一个包含“已访问”和“已显示”状态持久化的Feed阅读器应用程序。我们将研究:
- 支持应用程序的语义结构
- 使用的接收器
- 如何在构建HOPE Applet时添加诊断
- 查看数据库引擎生成的SQL
- 了解在持久化是组件的环境中工作有多么神奇。
作为预告,这是Applet的屏幕截图,它正在处理五个不同的“科技”Feed,显示最近Feed、已访问Feed,并具备书签功能。


参考文献
1 - 语义数据 - http://en.wikipedia.org/wiki/Semantic_data_modell
2 - 语义网 - http://en.wikipedia.org/wiki/Semantic_Web
3 - 网络本体语言 - http://en.wikipedia.org/wiki/Web_Ontology_Language
4 - 资源描述格式 - http://en.wikipedia.org/wiki/Resource_Description_Framework
5 - schema.org - schema.org
6 - 语义学 - http://en.wikipedia.org/wiki/Semantics
7 - Tim Berners-Lee - http://en.wikipedia.org/wiki/Tim_Berners-Lee
8 - 语义学 - http://en.wikipedia.org/wiki/Semantics
9 - 本体 - 本体(信息科学)
10 - Friend of a Friend - Friend of a Friend
11 - W3C SKOS Core Guild - W3C SKOS Core Guide
12 - RDF Schema - http://en.wikipedia.org/wiki/RDF_Schema
13 - Neo4j - https://neo4j.ac.cn/
14 - Cypher - Cypher