
CUDA 和 Thrust 的代码效率简要测试
4.88/5 (20投票s)
使用 Thrust 库验证短 CUDA 程序的执行效率。
引言
我正在进行数值模拟,这类工作通常非常耗时。即使广泛使用多核 CPU,其中许多工作也需要花费数小时才能完成。在能够负担得起集群之前,如何大幅提高台式计算机的计算效率以节省计算资源,成为了我面临的一个关键问题,也是我一直梦想实现的。
NVIDIA CUDA 似乎越来越受欢迎,并且有潜力通过释放 GPU 的强大能力来解决当前的问题。CUDA 框架提供了一种修改过的 C 语言,借助它,我可以用 C 编程经验来实现数值算法,并利用 GPU。而 thrust 是一个用于 CUDA 的 C++ 模板库,thrust 旨在提高开发者的开发效率;然而,对于数值工作来说,代码执行效率同样至关重要。有人认为,由于使用 thrust 库的额外开销,代码执行效率可能会在一定程度上有所损失。为了精确地判断这一点,我进行了一系列基本测试,以探索真相。基本上,这就是本文的目的。
我的测试计算机是一台 Intel Q6600 四核 CPU,配有 3G DDR2 800M 内存。虽然我的硬盘性能不佳,在 Windows 7 32 位系统下评分仅为 5.1,但我认为在这个平方和计算测试中,硬盘的访问可能并不显著。使用的显卡是 GeForce 9800 GTX+,配备 512M GDDR3 内存。显卡显示如下

[本文也可在 我的博客(Free your CFD) 中查阅,标题为“CUDA 和 Thrust 的代码效率简测”。]
原始 CUDA 中的算法
我使用的测试案例是计算整数数组(0到9范围内的随机数)的平方和。正如我提到的,测试中使用了在 Windows 7 32 位系统下运行的 GeForce 9800 GTX+ 显卡。如果用纯 C 语言实现,这个求和可以通过以下循环代码来完成,然后在 CPU 核心上执行。
int final_sum = 0;
for (int i = 0; i < DATA_SIZE; i++) {
final_sum += data[i] * data[i];
}
显然,这是一个串行计算。代码以串行指令流的形式执行。为了利用 CUDA 的强大功能,必须对算法进行并行化,并且并行化程度越高,能够发掘的潜在能力就越大。在我对 CUDA 的基本理解的帮助下,我将数据分成不同的组,然后使用 GPU 上等效数量的线程来计算每个组的平方和。最终,将所有组的结果加在一起得到最终结果。
设计的算法简要显示在图中
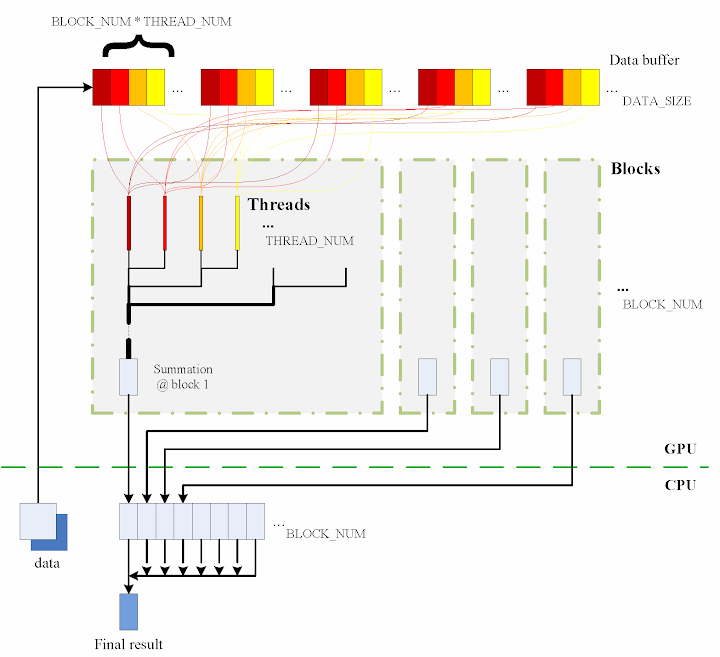
连续的步骤如下
- 将数据从 CPU 内存复制到 GPU 内存。
cudaMemcpy(gpudata, data, sizeof(int) * DATA_SIZE, cudaMemcpyHostToDevice);
- 总共使用了
BLOCK_NUM个块,每个块生成THREAD_NUM个线程来执行计算。实际上,我使用了THREAD_NUM = 512,这是 CUDA 块中允许的最大线程数。因此,原始数据被分成DATA_SIZE / (BLOCK_NUM * THREAD_NUM)组。 - 数据缓冲区的访问设计为连续的,否则效率会降低。
- 每个线程执行其相应的计算。
shared[tid] = 0; for (int i = bid * THREAD_NUM + tid; i < DATA_SIZE; i += BLOCK_NUM * THREAD_NUM) { shared[tid] += num[i] * num[i]; } - 通过使用块中的共享内存,可以在每个块中完成子求和。此外,子求和也进行了并行化,以实现尽可能高的执行速度。请参考源代码了解这部分的详细信息。
- 所有块的
BLOCK_NUM个子求和结果被复制回 CPU 端,然后将它们相加得到最终值。cudaMemcpy(&sum, result, sizeof(int) * BLOCK_NUM, cudaMemcpyDeviceToHost); int final_sum = 0; for (int i = 0; i < BLOCK_NUM; i++) { final_sum += sum[i]; }
关于这个过程,函数 QueryPerformanceCounter 记录代码的执行时长,然后用于比较不同实现的性能。在每次调用 QueryPerformanceCounter 之前,会调用 CUDA 函数 cudaThreadSynchronize() 来确保 GPU 上的所有计算都已真正完成。(*请参考 CUDA 最佳实践指南 §2.1*。)
有关原始 CUDA 代码的更多详细信息,可以直接参考附件的源代码。也欢迎提供评论。
Thrust 中的算法
使用 thrust 库可以使 CUDA 代码像纯 C++ 代码一样简单。该库的用法也与 C++ 的 STL(标准模板库)兼容。例如,利用 thrust 支持在 GPU 上进行计算的代码大致如下:
thrust::host_vector<int> data(DATA_SIZE);
srand(time(NULL));
thrust::generate(data.begin(), data.end(), random());
cudaThreadSynchronize();
QueryPerformanceCounter(&elapsed_time_start);
thrust::device_vector<int> gpudata = data;
int final_sum = thrust::transform_reduce(gpudata.begin(), gpudata.end(),
square<int>(), 0, thrust::plus<int>());
cudaThreadSynchronize();
QueryPerformanceCounter(&elapsed_time_end);
elapsed_time = (double)(elapsed_time_end.QuadPart - elapsed_time_start.QuadPart)
/ frequency.QuadPart;
printf("sum (on GPU): %d; time: %lf\n", final_sum, elapsed_time);
thrust::generate 用于生成随机数据,为此,预先定义了函数对象 random。random 被定制为生成一个 0 到 9 范围内的随机整数。
// define functor for
// random number ranged in [0, 9]
class random
{
public:
int operator() ()
{
return rand() % 10;
}
};
然而,与没有 thrust 的随机数生成相比,代码可能没有那么优雅。
// generate random number ranged in [0, 9]
void GenerateNumbers(int * number, int size)
{
srand(time(NULL));
for (int i = 0; i < size; i++) {
number[i] = rand() % 10;
}
}
同样,square 是一个接受一个参数的转换函数对象。有关其定义的详细信息,请参考源代码。square 被定义为 __host__ __device__,因此它可以同时用于 CPU 和 GPU 端。
// define transformation f(x) -> x^2
template <typename T>
struct square
{
__host__ __device__
T operator() (T x)
{
return x * x;
}
};
以上就是基于 thrust 的代码。它足够简洁了吗?:) 这里,函数 QueryPerformanceCounter 也记录了代码的持续时间。另一方面,host_vector data 在 CPU 上进行操作以进行比较。使用以下代码,求和由 CPU 端执行:
QueryPerformanceCounter(&elapsed_time_start);
final_sum = thrust::transform_reduce(data.begin(), data.end(),
square<int>(), 0, thrust::plus<int>());
QueryPerformanceCounter(&elapsed_time_end);
elapsed_time = (double)(elapsed_time_end.QuadPart - elapsed_time_start.QuadPart)
/ frequency.QuadPart;
printf("sum (on CPU): %d; time: %lf\n", final_sum, elapsed_time);
我还测试了使用 thrust::host_vector<int> data 作为普通数组时的性能。我认为这会产生更多的开销,但我们可能想知道到底有多少。相应的代码如下:
final_sum = 0;
for (int i = 0; i < DATA_SIZE; i++)
{
final_sum += data[i] * data[i];
}
printf("sum (on CPU): %d; time: %lf\n", final_sum, elapsed_time);
同样记录了执行时间以进行比较。
GPU 和 CPU 的测试结果
以往的经验表明,当实现大规模并行计算时,GPU 优于 CPU。当 DATA_SIZE 增加时,GPU 的计算潜力将逐渐释放。这是可以预见的。此外,我们使用 thrust 时会损失效率吗?我猜会的,因为它会带来额外的开销,但我们会损失很多吗?我们必须从比较结果中判断。
当 DATA_SIZE 从 1M 增加到 32M(1M 等于 1 * 1024 * 1024)时,得到的结果如表所示:
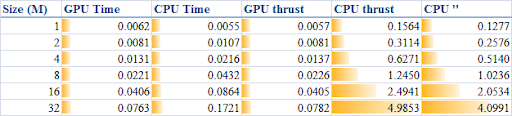
各项的描述如下:
- GPU 时间:原始 CUDA 代码的执行时间
- CPU 时间:在 CPU 上运行的纯循环代码的执行时间
- GPU thrust:使用 thrust 的 CUDA 代码的执行时间
- CPU thrust:使用 thrust 的 CPU 代码的执行时间
- CPU '':基于
thrust::host_vector的纯循环代码的执行时间
相应的趋势可以总结为:
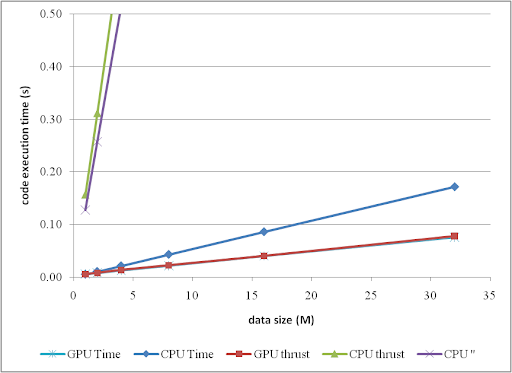
或者通过柱状图进行比较:
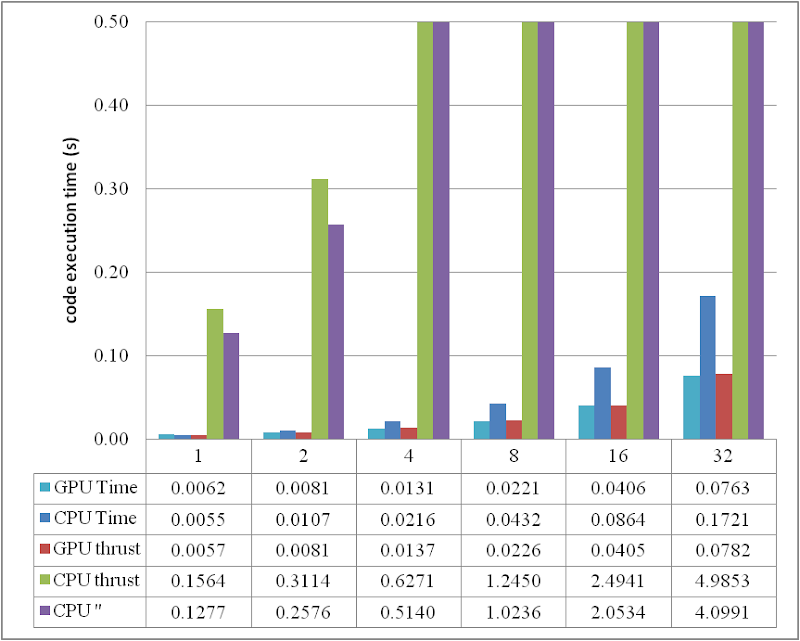
当 DATA_SIZE 大于 4M 时,GPU 相对于 CPU 的加速效果显而易见。实际上,随着数据量的增加,可以获得更好的性能加速。有趣的是,在这个区域,使用 thrust 的开销非常小,甚至可以忽略不计。然而,另一方面,不要在 CPU 端使用 thrust,无论是 thrust::transform_reduce 方法还是在 thrust::host_vector 上的纯循环;根据图表,带来的开销是巨大的。最好使用普通数组和循环。
从比较图中可以看出,thrust 的应用不仅简化了 CUDA 计算的代码,而且在 DATA_SIZE 相对较小的情况下弥补了效率的损失。因此,强烈推荐使用。
结论
基于所进行的测试,显然,通过采用并行,GPU 比 CPU 展现出更大的潜力,尤其是对于包含更多并行元素的计算。本文还发现,thrust 的应用并没有降低 GPU 端的代码执行效率,但却在 CPU 端的效率上带来了戏剧性的负面变化。因此,在 CPU 计算中使用普通数组更好。
总之,thrust 的使用感觉非常好,因为它提高了代码的效率,并且通过使用 thrust,CUDA 代码可以如此简洁和快速地开发。
代码说明
zip 包中包含的代码文件 thrustExample.cu,其中包括 GPU 和 CPU 上原始 CUDA 和 thrust 的算法。请注意,为了提取实际基准测试的平均值,必须重复执行计算足够多次;为了清晰和简化,我没有在附带的代码中包含此功能,但很容易添加。
该代码在 Windows 7 32 位系统、Visual Studio 2008、CUDA 3.0 和最新的 thrust 1.2 中构建和测试。还需要 NVIDIA 显卡以及 CUDA 工具包来运行程序。有关安装 CUDA 的说明,请参考其官方网站 CUDA Zone。
历史
- 2010/05/25:本文初版发布。
- 2010/05/26:附带源代码包,并相应更新了文章。
- 2010/06/05:将两个包合并,并根据近期读者的评论对代码进行了改进。文章也相应更新,特别是对实现算法的描述更加详细。
- 2010/06/27:在近期读者的帮助下修改了代码。特别是,添加了必要的
cudaThreadSynchronize()调用。同时,测试结果的呈现也进一步优化,使其清晰优雅。